
The objective of this chapter is to introduce the Sun Studio compiler and explain how to use it to get the best performance out of an application. The first part of the chapter discusses basic compiler options. This is followed by a section on more advanced compiler options. The chapter closes with a discussion of compiler pragmas, which are statements that you can insert into the source code to assist the compiler. By the end of the chapter, the reader will have a broad understanding of the ways compiler can be used to improve application performance.
One way to think about compiler options is to imagine three different sets of options, for three different requirements. These three sets are as follows.
Debug. During application development, typically you need a set of flags that enable full application debugging and rapid compile time.
Optimized code. Usually you want to have an optimized version of the application for development work (as the code becomes more stable) and for release.
Aggressively optimized code. Depending on the project’s performance requirements, it may be necessary to use aggressive optimizations to get the best out of the code, or it may be useful to test aggressive optimizations to see whether they provide significant performance improvements.
There are some simple rules to follow when building sets of compiler flags.
Always include debug information, because it is impossible to know when it will be necessary to debug or profile the application. The debug information can track individual instructions back to lines of source, even at high optimization.
Explicitly target the appropriate hardware architecture to ensure that the machine used to build the application can have no impact on the generated code. I discuss this is further in Section 5.4.4.
Use only the flags that improve application performance, and are safe for the application.
There are three things to consider when selecting compiler flags.
Using more aggressive optimizations will typically cause the compile time to increase. Therefore, you should use only optimizations that provide performance gains.
As more aggressive optimizations are used, the chance of them exposing a bug in the source code of the application increases. This is because as the optimization levels increase, the compiler will use less-forgiving assumptions about the application. Examples of this are variables that the programmer assumes are volatile but not marked as such; or places where two pointers alias, but the application has been compiled with the compiler flag to assume no such aliasing.
Some aggressive optimizations may cause differences in the results of floating-point computations.
For all these reasons, a comprehensive test suite is always recommended when experimenting with alternative choices of compiler options.
There is no such thing as a single set of flags that will work for all applications. It is always worth reviewing and revising the flags that are used. Table 5.1 lists a set of starting-point flags for the three levels of optimization suitable for compilers before Sun Studio 12.
Table 5.1. Optimization Flags for Compiler Versions Prior to Sun Studio 12
Optimization Level | Optimization Flags | Debug | Target Architecture |
|---|---|---|---|
Debug | None | -g | -xtarget=generic [32-bit SPARC] -xtarget=generic -xarch=sse2 [32-bit x64] -xtarget=generic64 [64-bit] |
Optimized | -O | -g [C/Fortran] -g0 [C++] | -xtarget=generic -xtarget=generic -xarch=sse2 -xtarget=generic64 |
High optimization | -fast -xipo | -g [C/Fortran] -g0 [C++] | -xtarget=generic -xtarget=generic-xarch=sse2 -xtarget=generic64 |
The Sun Studio 12 compiler can use a slightly different set of flags, as shown in Table 5.2.
Table 5.2. Optimization Flags for Compiler Versions of Sun Studio 12 and Later
Optimization Flags | Debug | Target Architecture | |
|---|---|---|---|
Debug | None | -g | -xtarget=generic [32-bit SPARC] -xtarget=generic -xarch=sse2 [32-bit x64] -xtarget=generic -m64 [64-bit] |
Optimized | -O | -g | -xtarget=generic -xtarget=generic -xarch=sse2 -xtarget=generic -m64 |
High optimization | -fast -xipo | -g [C/Fortran] -g0 [C++] | -xtarget=generic -xtarget=generic -xarch=sse2 -xtarget=generic -m64 |
There are three parts to these settings: the debug flags, the optimization flags, and the flags to specify the target hardware. I will discuss these in more detail in the following sections.
Sun Studio will target a 386 processor when given the -xtarget=generic option on x86 platforms. For many codes this may not be the best processor to select. For example, this processor does not have the SSE instruction set extensions. The option -xarch=sse2 will allow the compiler to use SSE2 instructions. These instructions first appeared in the Pentium 4 processor, so most commonly available x86 machines will support them. Binaries that use SSE or SSE2 instructions will not behave correctly when run on platforms without the hardware support for these instruction set extensions.
Use of these instructions requires at least Solaris 9 update 6; earlier versions of the operating system do not support them. If the application needs to run on an earlier operating system version, -xtarget=386 will generate code that does not use these instruction set extensions.
The optimization-level flags represent a trade-off between compile time and runtime. A lower optimization level tells the compiler to spend less time compiling the code, and consequently often leads to a longer runtime. A number of optimization levels are available, and these permit the compiler to do different degrees of optimization.
For many codes the -O flag represents a good trade-off between runtime and compile time. At the other end of the spectrum, the -fast flag represents a more aggressive set of optimizations, and you can use it in the process of estimating the best performance that the application can achieve. I will discuss the -fast compiler flag further in Section 5.4.3.
There are a range of optimization levels, and although it is not expected that a particular set of levels needs to be determined for any application, it is useful to see the progression from local optimizations at -xO1 to more global optimizations at -xO5. Table 5.3 lists the type of optimization performed at the various optimization levels.
Table 5.3. Optimization Levels
Optimization Level | Comment |
|---|---|
None specified | No significant optimization performed. Shortest compile time. Will generate code with roughly |
-xO1 | Minimal optimization |
-xO2 | Global variables are assumed volatile (I cover this in more detail shortly) |
-xO3 | Code is optimized at a function level. Variables are assumed not to be volatile unless declared as such. Typically |
-xO4 | Code is optimized at the file level. Functions are inlined if appropriate. |
-xO5 | Equivalent to |
-fast | A macro that contains a number of aggressive optimization flags, which may give improved application performance |
The other consequence of increasing the optimization level is that the compiler will have a lower tolerance for ambiguity in the source code. For example, at -xO2, all variables are assumed to be volatile, whereas at -xO3, only variables marked as being volatile are treated as such.
A volatile variable is a variable that may have its value changed by something other than the code that is referencing it. Typically, volatile variables occur when the value is being read from hardware and the state of the hardware may change over time, or when a variable is shared by multiple threads and another thread may change its value. The consequence of a variable being volatile is that the compiler has to store its value back to memory every time the value is changed and read its value from memory every time it is required, which introduces a large overhead on variable accesses. A nonvolatile variable can be held in a register, which means that operations on it are much cheaper. This means code that functions correctly at -xO2 may not function correctly at -xO3 if the behavior depends on a variable being treated as volatile, but the variable is not declared as such.
Many of the more advanced optimizations (such as cross-file inlining) require a level of optimization greater than -xO2. When the compiler encounters this requirement, it may either increase the level of optimization to do the necessary analysis, or ignore the option. In either case, it will emit a warning. Example 5.1 shows an example of this behavior.
A final point to observe is that if no optimization level is specified, no optimization is performed, unless one of the flags causes the compiler to increase the optimization level. So, it is critical to at least specify -O to ensure some degree of optimization.
The -O optimization flag represents a good trade-off between compile time and performance. Since the Sun ONE Studio 9 release of the compiler, it has corresponded to an optimization level of -xO3.
The -fast compiler flag is a macro option, that is, it enables a set of options designed to give best performance on a range of codes. There are three items to be aware of when using the -fast macro flag:.
-fastincludes the-xtarget=nativeoption, which tells the compiler to assume that the platform being used to generate the application is also the type that will run the application. This may be an issue if the application is compiled on a platform with a more modern CPU than the platform, which it is to be deployed. To avoid this issue, always specify the target platform when compiling. Often, this will be the-xtarget=genericflag, as discussed in Section 5.4.4.Because
-fastprovides a general set of options, it is important to be aware that it may not turn out to be the best set of options for a particular code. In particular,-fastcontains optimizations that simplify floating-point mathematical operations. These optimizations are very general, and most compilers do them, but in some circumstances they may not be appropriate. Another assumption that-fastmakes for C is that pointers to different basic types do not alias (i.e., a pointer to an integer would never point to the same location in memory as a pointer to a floating-point value).The definition of
-fastmay evolve from release to release. A new optimization will be introduced into-fastin one compiler release and the optimization will eventually percolate down to less-aggressive levels of optimization.
Because of these considerations, you can use -fast as a first stop when optimizing applications, before exploring the options that it enables in more detail. Be aware of what -fast means, and consider whether it is appropriate to continue using the whole macro or whether it would be better to hand-pick a selection of the options that -fast enables.
You should use the -fast flag when compiling and when linking the program. Some of the optimizations enabled (e.g., -dalign in Fortran) alter data alignment, and as such they require all the modules to be aware of the new layout.
The -fast compiler flag includes the -xtarget=native flag, which specifies that the type of machine used to compile the program is also the type of machine which will run the program. Obviously, this is not always the case, so it is recommended that you specify the target architecture when using -fast.
Example 5.2 shows the compile line to be used with -fast to specify that 32-bit code should be generated. It is essential to notice the order in which the flags have been used. The compiler evaluates flags from left to right, so the -xtarget setting overrides the setting applied by -fast. If the options were specified in the opposite order, -fast would override the -xtarget setting specified earlier on the command line.
Example 5.3 shows the compile line that you should use with -fast to specify that 64-bit code should be generated. With Sun Studio 12, the user also has the equivalent option of appending the -m64 flag to the command line shown in Example 5.3 to generate a 64-bit binary.
The objective of the “generic” target is to pick a blended SPARC or x64 target that provides good performance over the widest range of processors. When a generic target is requested, the compiler will produce code that requires at least an UltraSPARC-I on SPARC systems, or a 386 for x86 systems. On x86 systems, it may be appropriate to select a more recent architecture than 386 to utilize the SSE and SSE2 instruction set extensions. The generic keyword works for both x64 and SPARC systems, and is consequently a good flag to select when one Makefile has to target the two architectures. Although the compiler flag has the same name for both architectures, the generated binaries will of course be specific to the architecture doing the compilation. There is no facility to cross-compile (e.g., build a SPARC binary on an x64 system).
The definition of -fast may not be constant from release to release. It will gradually evolve to include new optimizations. Consequently, it is useful to be aware of what the -fast macro expands into. The optimizations that -fast enables are documented, but it is often easier to gather this information from the compiler. Fortunately, the compiler provides a way to extract the flags comprising -fast. The compiler has a flag that enables verbose output. For the C compiler it is the -# flag, and for the C++ and Fortran compilers it is the -v (lowercase v) flag.
The compiler is actually a collection of programs that get invoked by a driver. The cc, CC, or f90 command is a call to the driver, which translates the compiler flags into the appropriate command lines for the components that comprise the compiler. The output of the verbose flag (-# or -v) shows the details of these calls to these various stages, together with the expanded set of flags that are passed to the stages. Example 5.4 is the transcript of a session showing the output from the C compiler when invoked on a file with -# and -fast.
Example 5.4. Verbose Output from Compiler
$ cc -# -fast test.c cc: Warning: -xarch=native has been explicitly specified, or implicitly specified by a macro option, -xarch=native on this architecture implies -xarch=v8plusb which generates code that does not run on pre UltraSPARC III processors ... ### command line files and options (expanded): ### -D__MATHERR_ERRNO_DONTCARE -fns -fsimple=2 -fsingle -ftrap=%none -xalias_ level=basic -xarch=v8plusb -xbuiltin=%all -xcache=64/32/4:8192/512/1 -xchip=ultra3 -xdepend -xlibmil -xmemalign=8s -xO5 -xprefetch=auto,explicit test.c /opt/SUNWspro/prod/bin/acomp ... /opt/SUNWspro/prod/bin/iropt ... /usr/ccs/bin/ld ...
In the transcript in Example 5.4, most of the output has been edited out, because it is not relevant. The compiler’s components invocations have been left in, but the critical line is the one following the comment ### command line files and options (expanded). This line shows exactly what -fast was expanded to.
Table 5.4 lists the optimizations that -fast enables for the Sun Studio 12 compiler. These optimizations may have an impact on all codes. They target the integer instructions used in the application—the loads, stores, and so on as well as the layout of and the assumptions the compiler makes about the data held in memory.
Table 5.4. General Compiler Optimizations Included in -fast
C | C++ | Fortran | Comment | |
|---|---|---|---|---|
| Y | Y | Y | Set highest level of optimization |
| Y | Y | Y | Optimize for system being used to compile |
| Y | Assert that different basic C types do not alias each other | ||
| Y | Y | Recognize standard library calls | |
| Y | Y | Y | Perform dependency analysis |
| Y | Y | Y | Assume 8-byte memory alignment (SPARC only) |
| Y | Align common block data to 16-byte boundaries | ||
| Y | Select aggressiveness of prefetch insertion | ||
| Y | Optimize padding for local variables | ||
| Y | Y | Y | Use frame pointer register (x86 only) |
Table 5.5 lists the compiler optimizations included in -fast that specifically target floating-point applications. Chapter 6 discusses floating-point optimization flags in detail.
Table 5.5. Floating-Point Optimizations Included in -fast
Flag | C | C++ | Fortran | Comments |
|---|---|---|---|---|
| Y | Y | Y | Perform aggressive floating-point optimizations |
| Y | Y | Do not trap on IEEE exceptions | |
| Y | Trap only on common IEEE exceptions | ||
| Y | Y | Y | Use inline templates for math functions |
| Y | Y | Y | Use optimized math library |
| Y | Y | Y | Enable floating-point nonstandard mode |
| Y | Convert loops to vector calls (SPARC only) | ||
| Y | Do not promote single-precision variables to double | ||
| Y | Y | Y | Do not convert floating-point values to assigned size (x86 only) |
Tables 5.4 and 5.5 cover the set of generally useful performance flags. Even if -fast does not turn out to be the ideal flag for an application, it can be worth picking out one or more of the flags in -fast and using them. Flags in -fast normally perform optimizations on a broad range of applications, and it would not be surprising to find that only a few of the flags improve the performance of any particular application. Later sections on compiler flags will deal with these optimizations in greater detail.
The compiler will include debug information if the -g flag (or -g0 for C++) is used. There are a number of good reasons for including debug information.
If the application requires debugging, it is essential to have the compiler generate this data.
When performance analysis is performed (using Analyzer; see Section 8.2 of Chapter 8), having the debug information allows the tool to report time spent on a per-source-line basis.
The compiler generates commentary that describes what optimizations it performed and why, as well as including a range of other useful information. This commentary is shown in the Performance Analyzer and in the
er_srctool, as discussed in Section 8.20 of Chapter 8. Example 5.5 shows an example of compiler commentary.
The -g0 flag tells the C++ compiler to generate debug information without disabling these optimizations. The -g flag disables some optimizations for C++, hence it is recommended to use -g0 instead.
There is some interplay between the debug information available and the optimization level selected. With no optimization flags, the compiler will provide considerable debug information, but this does incur a runtime performance penalty. At higher levels of optimization, the amount of debug information available is reduced. At optimization levels greater than -xO3, performance is considered a higher priority than debug information. You can find more details on the interaction between debug and optimization in Section 9.4.2 of Chapter 9.
In general, it is very useful to include debug information when building an application, because it has little or no impact on performance (for binaries compiled with optimization), and it is extremely helpful for both debugging and performance analysis.
The compiler has some default assumptions about the type of machine on which the application it is building will run. By default, the compiler will build an application that runs well on a wide range of hardware, not taking advantage of any hardware features that are limited to only a few processors. The compiler will also generate a 32-bit application. The defaults may not be optimal choices for any given application. One of the key decisions to make is whether to target a 32-bit or a 64-bit application.
The major advantage of specifying a 64-bit architecture is that it will support a much larger address space than the 4GB limit for a 32-bit application.
When an application is compiled for 64-bit, various data structures increase in size. Long integers and pointers become 64 bits in size rather than 32 bits. Hence, the memory footprint for the application will increase, and this will often lead to a drop in performance. If the data is mainly pointers or long integers, the memory footprint can nearly double and the difference in performance can be significant.
On x64-based systems, the 64-bit instruction set is significantly improved over the 32-bit instruction set. In particular, more registers are available for the compiler to use. These additional registers can lead to a significant gain in performance, despite the increased memory footprint.
On SPARC-based systems, a 64-bit version of an application will typically run slightly slower than a 32-bit version of the same application. On x64-based systems, the 64-bit version of an application may well run faster.
By default, the compiler will select a generic 32-bit model for the processor on which the application will run. The idea of a generic model is that the compiler will favor code that runs well on all platforms over code that exploits features of a single platform. The generic target is the one to use when it is necessary to produce a single binary that runs over a wide range of processors. (Binaries targeted for generic targets are not cross-platform. A generic targeted binary compiled on a SPARC system will run only on SPARC-based systems, and will not run on an x86 system.)
A corresponding generic64 target will produce a 64-bit binary that has good performance over a wide range of processors.
The -xtarget flag is a macro flag that sets three parameters that control the type of code that is generated. It is also possible to set these parameters independently of the -xtarget flag. The three parameters are as follows.
The cache size. You can explicitly set cache configuration using the
-xcacheflag.The instruction selection and scheduling, which you can also set using the
-xchipflag.The instruction set, which you can explicitly set using the
-xarchflag.
In many cases the generic target is the best choice, but that does not necessarily exploit all the features of recent processors. It is possible to use the -xtarget compiler flag to specify a particular processor. This will favor performance on that processor over performance on other compatible processors. In some cases, it can result in a binary that does not run on some processors because they lack the instructions the compiler has assumed are present.
There are two reasons to specify an architecture other than generic.
The developer knows deployment of the application is restricted to a certain range of processors. This might be the case if, for example, the application will be deployed on only one particular machine. Even in this situation, it is appropriate to test the hypothesis that setting the specific target does lead to better performance than using the generic target.
The application uses features that are available on only a subset of processors; for example, if the application uses a specific instruction. However, it may be appropriate to implement the processor-specific part of the application as a library that is loaded at runtime depending on the processor’s characteristics. I discuss machine-specific libraries in Section 7.2.6 of Chapter 7.
For Sun Studio 12 and earlier, the generic option for x86 processors is equivalent to 386. Best performance for a more recent AMD64 or EMT64 processor is to use -xtarget=opteron, which builds a 32-bit application using features included in the SSE2 instruction set extensions.
The -fast compiler flag includes the -xtarget=native flag, which tells the compiler that the build machine is the same type of machine as the machine on which the code will be run. Consequently, it is best to always specify the desired build target for the application, to avoid the possibility that the choice may be made implicitly by the build machine.
The -xcache option tells the compiler the characteristics of the cache. This information is part of the information reported by the SPARC tool fpversion discussed in Section 4.2.7 of Chapter 4. Example 5.6 shows an example of the output from fpversion.
Example 5.6. Output from fpversion on an UltraSPARC IIICu-Based System
$ fpversion
A SPARC-based CPU is available.
Kernel says CPU's clock rate is 1050.0 MHz.
Kernel says main memory's clock rate is 150.0 MHz.
Sun-4 floating-point controller version 0 found.
An UltraSPARC chip is available.
Use "-xtarget=ultra3cu -xcache=64/32/4:8192/512/2" code-generation option.
Hostid = 0x83xxxxxx.The first three parameters the -xcache flag uses describe the first-level data cache (size in kilobytes, line size in bytes, associativity), and the next three parameters describe the second-level cache (size in kilobytes, line size in bytes, associativity). The example describes a 64KB first-level data cache with 32-byte line sizes that is four-way associative, and an 8MB second-level data cache with 512-byte line sizes that is two-way associative.
The compiler uses this information when it is trying to arrange data access patterns so that all the data that is reused between loop iterations fits into the cache. In general, this option will not have any effect on performance, because most code is not amenable to cache-size optimizations. However, for some code, typically floating-point loop-intensive code, this option does demonstrate a significant performance gain.
The -xchip option controls the scheduling of the instructions, and which instructions the compiler picks if alternative instruction sequences are equivalent in functionality. In particular, this flag controls the instruction latencies the compiler assumes for the target processor. For example, consider the floating-point multiply instruction. On the UltraSPARC II, this instruction has a three-cycle latency, whereas on the UltraSPARC III, this instruction takes four cycles. A binary scheduled for the UltraSPARC II would ideally have an instruction that uses the results of a floating-point multiply placed two cycles after the multiply upon which it depends. When this binary is run on an UltraSPARC III processor, the processor may sit idle for a single cycle waiting for the initial floating-point multiply to complete before the dependent instruction can be issued.
The -xarch=<architecture> flag specifies the architecture (or instruction set) of the target machine. The instruction set represents all the instructions that are available on the machine. A binary that uses instructions that are unavailable on a particular processor may not run (if it does run, the missing instructions will have to be emulated in software, which results in a slower-running application). The available options for this flag significantly change in Sun Studio 12. In compiler versions prior to Sun Studio 12, one of the purposes of this flag was to specify whether a 32-bit or 64-bit application should be generated.
In Sun Studio 12, the architecture has been separated from whether the application is 32-bit or 64-bit. The two new flags, -m32 and -m64, control whether a 32-bit or 64-bit application should be generated. The -xarch flag now only has to specify the instruction set that is to be used in generating the binary. For SPARC processors, the generic architecture is often a good choice; for x64 processors, selecting SSE2 as a target architecture will get the best performance and a reasonable coverage of commonly encountered systems.
Table 5.6 specifies some of the common architectures using the Sun Studio 11 options and the new Sun Studio 12 options.
Table 5.6. Common Architecture Options
Sun Studio 11 Options | Comment | Sun Studio 12 Options |
|---|---|---|
| Default option, 32-bit application |
|
| 64-bit application |
|
| 32-bit application, AMD64-based system |
|
| 64-bit application, AMD64-based system |
|
| 32-bit application, SPARC V9-based system with instruction set extensions |
|
| 64-bit application, SPARC V9-based system with instruction set extensions |
|
| 32-bit application, SPARC V9-based system with floating-point multiply accumulate instructions |
|
| 64-bit application, SPARC V9-based system with floating-point multiply accumulate instructions |
|
A number of optimizations lead to better code layout. These optimizations do not really change the instructions that are used, but they do change the way they are laid out in memory. These optimizations target the following things.
Branch mispredictions. The code can be laid out so that the branches that are probably taken are the straight path, and branch instructions represent “unusual” or “infrequent” events. This reduces branch misprediction rates, and the corresponding stalls in the flow of instructions.
Instruction cache or instruction translation lookaside buffer (TLB) layout. The code can be laid out in memory so that hot instructions are grouped together and cold instructions are put elsewhere. This means that when a page is mapped into the instruction TLB or a line is brought into the instruction cache, it will mainly contain instructions that will be used. This reduces instruction cache misses and instruction TLB misses.
Inlining of routines. When the compiler can determine that a particular routine is called frequently and that the overhead of calling the routine is significant when compared to the time spent doing useful work in the routine, that routine is a candidate for being inlined. This means the code from the routine is placed at the point at which the routine is called, replacing the call instruction. This removes the cost of calling the code, but does increase the size of the code.
One way to think about the options for code layout improvements is to consider them as a number of complementary techniques.
Crossfile optimization (discussed in Section 5.7.2) examines the code and locates routines which are small and frequently called. These routines get inlined into their call sites, removing the overhead of the call and potentially exposing other opportunities for optimization. Crossfile optimization will work without profile feedback information, but the presence of profile feedback information will help the compiler to make better decisions.
Mapfiles (discussed in Section 5.7.3) improve the layout of the code in memory, grouping all the hot (frequently executed) parts of the code together and placing the cold (infrequently executed) parts out of the way. This optimization improves code’s footprint density in memory.
Profile feedback (discussed in Section 5.7.4) is a mechanism that gives the compiler more information about the code’s runtime behavior. This helps the compiler make the correct decisions about which branches are usually taken, and which routines are good candidates for inlining.
Finally, on SPARC, link-time optimization (discussed in Section 5.7.5) can look at the whole program and, using profile feedback information, can perform the same optimizations as the mapfiles, as well as additional optimizations to reduce instruction count using information about how the code is laid out in memory. Link-time optimization renders the use of mapfiles unnecessary.
Crossfile optimization can be extremely important. At -xO4, the compiler starts to inline within the same source file, but not across source files. Using crossfile optimization, the compiler is able to inline across the source files.
The advantages of doing this are as follows.
The call overhead is removed. There are no call and return instructions, which means less branching and fewer instructions executed. Similarly, removing calls also removes stores and loads of function parameters to the stack.
The code is laid out in straighter blocks, which can improve instruction-cache locality and performance.
Inlining the code can expose opportunities for further performance gains.
Example 5.7 shows an example of a program that will benefit from inlining. In fact, there are a number of benefits from performing the inlining.
Example 5.7. Example of an Inlining Opportunity
void set(int* bitmap, int x, int width, int y, int height,int colour)
{
bitmap[y*width + x]=colour;
}
void main()
{
int x,y,height=1000,width=1000,colour=0;
int bitmap[height*width];
for (x=0; x<width; x++)
for (y=0; y<height; y++)
set(bitmap,x,width,y,height,colour);
}The
setroutine will be calledheight*widthtimes—in this case, 1 million times. Given that the routine contains little code, the overhead of the call is going to represent a large proportion of the time spent in the routine.Every time the routine is entered, the
yvariable has to be multiplied by thewidth, to calculate the correct position in the array. The integer multiplication operation will take a few cycles, so a large number of cycles will be spent repeatedly doing this calculation.Finally, the inner loop is over the
yvariable, and this means the memory in thebitmapis not accessed contiguously, but rather at intervals ofwidth. This striding through memory will also cost in terms of performance. Once the compiler inlines the routine, it can also determine that the memory access pattern is inefficient and perform the necessary loop reordering.
If the set and main routines are located in the same source file, compiling at -xO4 will cause the compiler to inline set and perform the optimizations suggested earlier. If they are located in separate source files, the compiler will need to be told to do crossfile optimization, using the -xipo flag, to get the performance. When the compiler optimizes the routine, it will produce code is similar to that shown in Example 5.8.
Two flags perform crossfile optimization: -xcrossfile and -xipo. -xcrossfile is the old flag that requires that all the files be presented to the compiler at the same time; in most circumstances, this is a severe restriction. -xipo enables the compiler to perform crossfile optimization at link time. This is normally much more convenient for build processes. The constraint with -xipo is that the compiler, and not the linker, must be invoked to do the linking. The flag also needs to be specified for both the compile and the link passes.
A further level of crossfile optimization is enabled with -xipo=2. At this level, the compiler attempts to improve data layout in memory. I discuss the types of memory optimizations the compiler attempts to improve in Section 11.4 of Chapter 11.
Mapfiles are a very easy way of telling the linker how to arrange the code in an application to place it most efficiently in memory. A mapfile works at the routine level, so the linker can sort the routines in a particular order but cannot specify the way the code is laid out within the routine. Two flags are necessary to enable the compiler to use mapfiles: the -M <name of mapfile> flag, which eventually gets passed to the linker, and the -xF flag, which tells the compiler to place every function in its own section. Example 5.9 shows an example command line.
Mapfiles are very easy to use. You can prepare them manually by editing a text file, or the Analyzer can output them (as shown in Section 8.12 of Chapter 8). Example 5.10 shows an example of a mapfile.
The structure of the mapfile, shown in Example 5.10, is relatively easy to understand. In this example, each file defines a function of the same name as the file (i.e., a.c contains the function a). The resulting executable will have the routines in the order c, a, b, and finally main. The structure of the mapfile is as follows.
The first line defines a section for the executable (called
section1). It is aLOADsegment, which means that it has a location in memory. The segment also has the following flags: read-only (R), executable (X), and ordered (O). Being an ordered segment means that the mapfile defines the order in which the routines appear in the final binary.The next lines define the order of the routines for the named section. Each line starts with the name of the section to which the line applies. Because the functions are being ordered, each function is specified as
.text%<function name>. If there are multiple functions of the same name within the executable, the object file that contains the function can also be specified, as shown in the example.
Mapfiles become more useful as the size of the program increases. This is because a small program may fit entirely in the instruction cache, or the second-level cache, and will be mapped by the instruction TLB. However, some programs are sufficiently large that they no longer fit into the caches, or incur instruction TLB misses. In either case, mapfiles can be an effective way to ensure that the critical code has as small a footprint in memory as possible.
Profile feedback gives the compiler a great deal of information about the probabilities and frequency with which a given branch is taken or untaken. This allows it to make sensible decisions about how to structure the code.
To use profile feedback, the program must be initially compiled with -xprofile=collect. Under the -xprofile=collect flag, the compiler produces an “instrumented” version of the binary, meaning that every branch instruction has code surrounding it that counts the number of times the branch was taken. The next step is to run this version of the program on data similar to the kind of data on which the program will typically be used. This can be a single run of the program, or multiple runs; the results will be aggregated. The data that is collected as a result of these runs is stored in the location specified. The program is then recompiled with the -xprofile=use flag, which tells the compiler to use the profile data that has been collected.
The -xprofile=[use|collect] flag can take a further specifier, which is the name and location of the directory that will contain the profile information. If this specifier is omitted, the compiler will place the profile information in the same place as the binary, and give the profile directory the same name as the binary but with “.profile” appended. If the name is omitted from the -xprofile=use flag, the compiler will default to using a.out (even if a name for the binary is specified using a -o flag). Therefore, it is best to specify a path to the profile directory when using profile feedback. This makes it easier to know during the -xprofile=use phase where the profile is located.
Example 5.11 shows the sequence of instructions for using profile feedback. It is important to keep the other compiler flags the same for both the collect and use runs, because changing the flags may result in a different ordering of the instructions, and it would no longer be possible for the compiler to determine which branches correspond in the two builds.
Profile feedback is useful for the following kinds of optimizations.
Laying out the application code so that branch statements are rarely taken. This allows the processor to “fall through” the branches without incurring the cost of fetching new instructions from a different address in memory.
Inlining routines that are called many times. This optimization eliminates the cost of calling the routine.
Moving code that is executed infrequently out of the hot part of the routine. This leads to fewer unused instructions in the caches, which means they are more effective in storing code that is likely to be reused.
Many other optimizations—for example, knowing which variables to hold in registers—also benefit from more detailed knowledge of frequently executed code paths.
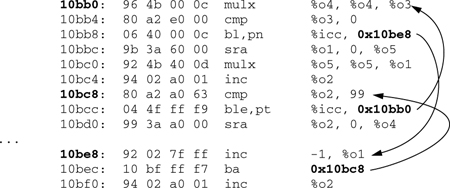
The code shown in Example 5.12 has branches with predictable behavior. However, the compiler is unlikely to be able to statically determine the branch pattern (although this particular instance is sufficiently simple that it could in the future). The computation on the usually taken path is a multiplication. If this computation were a simple addition or set operation, the compiler might be able to use conditional moves to replace the branch altogether.
Example 5.13 shows the disassembly from the code compiled without profile feedback. The compiler has no information to go on, so it has decided that each part of the if condition is equally likely. So, for each case, one branch is taken.

When compiled with profile feedback, the compiler has information that indicates which code path is most likely, and it is able to structure the code so that the common case has the shortest code path. Example 5.14 shows this code. In this rearrangement of the code, the frequently executed path has taken one branch back to the top of the loop, but the infrequently executed code has taken two branches.
Obviously, when using profile feedback, there is a concern that the program will end up “overoptimized” for the case used for the training—and consequently perform badly on other cases. A couple of points should be considered.
Always use a representative case for the training run. If the training data is not representative or if it does not cover all the common cases, it is possible to not get the best performance. You can use multiple training workloads to increase code coverage. Branches where the training data was inconclusive will be optimized as equally likely to be taken or untaken.
A lot of codes have tests in them to check for corner cases. Profile feedback allows the compiler to identify these kinds of tests, and work on the assumption that they will remain corner cases in the actual run of the program. This is often where the performance comes from—the fact that the compiler can take a block of
ifstatements and determine that one particular path through the code is likely to be executed many more times than other paths.
Consequently, it is very likely that using profile feedback will result in improvements in performance for the general case, because the profile will eliminate the obvious “unlikely code” and leave the “likely” code as the hot path.
One way to evaluate whether the data used for the training run is similar to the data used during real workloads is to use coverage tools (such as tcov, covered in Section 8.18 of Chapter 8, or BIT, covered in Section 8.17 of Chapter 8) to determine how much of the code has been exercised, and adding appropriate test cases to reach 100% coverage. Although coverage does not guarantee that the training code is taking the same pattern of branches as the real application would, it will at least indicate that the training run is executing the same parts of the code.
Another phase of the SPARC compiler is the link-time optimization phase. At link time, the compiler has seen all the code and produced the object files, but because it cannot see the entire application, it has to guess at the best thing to do. Here are some examples of things that cannot be determined until link time.
Global variables in programs are accessed using a combination of a base address plus an offset. At compile time, it is not possible to know how many global variables are going to be present in the program, and consequently, whether two variables are sufficiently close in memory that they can be accessed using the same base address.
In general, most branches in programs are short, but occasionally there are some long branches. The instructions to perform a long branch have a higher cost than the normal branch instructions. At compile time, it is not possible to tell whether the code might just fit into the range of a normal branch instruction. However, at link time it may be possible to replace a long-range branch with a lower-cost shorter-range branch instruction.
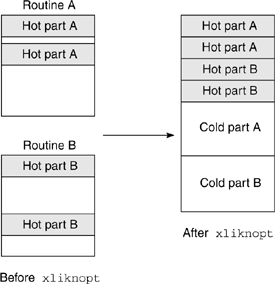
It is possible to improve instruction cache utilization by laying out the code better. However, you can do this only at link time, when all the code is known. This is similar to what you can achieve with mapfiles. However, link-time optimization has a big advantage over mapfiles. Mapfiles work at the level of laying out routines in memory, whereas link-time optimization can actually work within routines. Figure 5.1 shows two routines, A and B, each having a hot part and a cold part. With link-time optimization, the hot part of routine A can be placed with the hot part of routine B, and their cold parts can also be placed together. This leads to much higher efficiency when packing the instruction cache.
It is very easy to use link-time optimization: Just append the -xlinkopt[=2] flag to the compile line and link lines (see Example 5.15). It relies heavily on execution frequency information, so it will work most effectively in the presence of profile feedback information.
There are two levels for -xlinkopt. Level one, the default, just rearranges the code to use the instruction cache more effectively; level two does optimizations on the code to take advantage of the linker’s knowledge of the addresses of variables or other blocks of code.
Prefetch instructions are requests to the processor to fetch the data held at a memory address before the processor needs that data. Prefetch instructions can have a significant impact on an application’s performance. Consider a simple example in which all the data an application needs to use is resident in memory, and it takes 200 cycles for the data to get from memory to the CPU. When the processor needs an item of data it has to wait 200 cycles for the data to arrive from memory. You can use a single, well-placed prefetch instruction to fetch that data. In this case, the prefetch instruction will cost one cycle (to issue the instruction), but will save 200 cycles.
The -xprefetch flag controls whether the compiler generates prefetch instructions. Since Sun Studio 9, the compiler has defaulted to generating prefetch instructions on SPARC hardware when an appropriate target instruction set has been selected. On x64 processors it is necessary to specify a target architecture of at least SSE (e.g., using the -xarch=sse flag) to cause the compiler to generate prefetch instructions.
It can be difficult for the compiler to insert prefetch instructions for all situations in which they will improve performance. The x64 processors typically have a hardware prefetch unit that speculatively prefetches the address the processor expects to access next, given the previous addresses accessed. In simple cases, the memory access pattern is readily apparent, and a hardware prefetch unit can often predict these patterns with a high degree of accuracy. In more complex access patterns, the compiler cannot determine from the code exactly which memory operations would benefit from being prefetched, and hardware prefetch will struggle to predict these accesses. Given the potential gains from a successful prefetch instruction, it is often helpful for the compiler to generate more speculative prefetches. Speculative prefetches can useful in a number of situations.
Situations in which the compiler has difficulty predicting the exact address of the next memory reference—for example, where an array is strided through using an uneven stride.
Places where the compiler cannot determine whether a memory access is likely to be resident in the caches or whether it must be fetched from memory. This is common in cases where multiple streams of data are being fetched, some from memory and some that are short enough to fit into the caches.
Parts of the code where it is helpful to prefetch a memory location for a second time. For example, the data may have been knocked out of the on-chip caches before it was used, or the prefetch instruction may not have been issued due to resource constraints.
The -xprefetch_level flag increases the number of speculative prefetch instructions that are issued. For codes where the data mainly resides in memory, increasing the prefetch level will also improve performance. For codes where the data is rarely resident in memory, the benefits of issuing prefetch instructions are less clear.
If the data is mainly resident in the on-chip caches, including prefetch instructions can lead to a reduction in performance. The prefetch instructions do not provide any benefit, because the data is already available to the processor. Also, each prefetch instruction takes up an instruction issue slot that could have been used for other work. Finally, the prefetch instructions typically have some “bookkeeping” instructions, such as calculating the next address to be prefetched, and these instructions also take up some issue slots that could have used for useful work.
The compiler typically does a good job determining the appropriate trade-offs and puts prefetch instructions in the places where they will benefit the application’s performance. The -xprefetch_level flag provides some control in situations where the application has a large memory-resident data set that will benefit from more speculative use of prefetch instructions.
The code shown in Example 5.16 calculates a vector product. Both vectors need to be streamed through, so this is a natural place where prefetch can be useful.
Example 5.17 shows the flags necessary to enable prefetch generation for versions of the compiler prior to Sun Studio 9 on an UltraSPARC system. Sun Studio 9 and later compilers have prefetch generation enabled by default.
Example 5.18 shows the command line to build the same file on x64 with prefetch enabled.
Example 5.19 shows the disassembly code from the SPARC verison of the routine, and includes the two prefetches that the compiler generates to improve performance.
Example 5.19. SPARC Assembly Code with Prefetches Inserted
.L900000108: /* 0x0074 7 */ add %o3,8,%o3 /* 0x0078 */ ld [%o2],%f20 /* 0x007c */ add %o2,32,%o2 /* 0x0080 */ prefetch [%o0+272],0 /* 0x0084 */ cmp %o3,%o5 /* 0x0088 */ add %o0,32,%o0 /* 0x008c */ fmuls %f0,%f20,%f28 /* 0x0090 */ fadds %f2,%f4,%f26 /* 0x0094 */ ld [%o0-32],%f24 /* 0x0098 */ ld [%o2-28],%f22 /* 0x009c */ prefetch [%o2+244],0 /* 0x00a0 */ fmuls %f24,%f22,%f7 /* 0x00a4 */ fadds %f26,%f28,%f5 /* 0x00a8 */ ld [%o0-28],%f1 ... /* 0x0104 */ fadds %f10,%f12,%f2 /* 0x0108 */ ble,pt %icc,.L900000108 /* 0x010c */ ld [%o0-4],%f0
Example 5.20 shows part of the equivalent disassembly for x64.
Example 5.20. x64 Assembly Code with Prefetches Inserted
.CG3.15:
prefetcht0 128(%esi) ;/ line : 8
fldl (%esi) ;/ line : 8
fmull (%ebx) ;/ line : 8
fstpl (%esi) ;/ line : 8
fwait
prefetcht0 136(%ebx) ;/ line : 8
fldl 8(%esi) ;/ line : 8
fmull 8(%ebx) ;/ line : 8
fstpl 8(%esi) ;/ line : 8
fldl 16(%esi) ;/ line : 8
fmull 16(%ebx) ;/ line : 8
fstpl 16(%esi) ;/ line : 8
fldl 24(%esi) ;/ line : 8
fmull 24(%ebx) ;/ line : 8
fstpl 24(%esi) ;/ line : 8
fwait
addl $32,%ebx ;/ line : 8
addl $32,%esi ;/ line : 8
addl $4,%edx ;/ line : 8
.LU2.47:
cmpl $1023,%edx ;/ line : 8
jle .CG3.15 ;/ line : 8The -xprefetch_level flag provides a degree of control over the aggressiveness of prefetch insertion. By default, the compiler will attempt to place prefetches into loops which look sufficiently predictable that prefetch will work. Increasing the prefetch level allows the insertion of prefetches into codes where the loops are not quite so predictable. Therefore, the prefetches become more speculative in nature (the compiler expects the data to be used, but is not certain of this).
Example 5.21 shows the number of prefetch instructions in the binary when the code from Example 5.16 is compiled with various levels of optimization.
Example 5.21. The Impact of -xprefetch_level on the Number of Prefetches
$ cc -xtarget=ultra3 -xprefetch -xO3 -S ex5.16.c $ grep -c prefetch ex5.16.s 13 $ cc -xtarget=ultra3 -xprefetch -xO3 -S -xprefetch_level=2 ex5.16.c $ grep -c prefetch ex5.16.s 16 $ cc -xtarget=ultra3 -xprefetch -xO3 -S -xprefetch_level=3 ex5.16.c $ grep -c prefetch ex5.16.s 18
The -xprefetch_level flag controls the number of prefetch instructions generated. For some codes this will help performance, for other codes there will be no effect, and for still other codes the performance can decrease. The behavior depends on both the application and the workload run.
The -xdepend flag for C, C++, and Fortran switches on improved loop dependence analysis. (-xdepend is included in -fast for C, but appears in -fast for C++ only in Sun Studio 12. For Fortran, -xdepend is enabled at optimization levels of -xO3 and above.) With this flag, the compiler will perform array subscript analysis and loop nest transformations, and will try to reduce the number of loads and stores.
The code in Example 5.22 shows a hot inner loop that benefits from dependence analysis. The code is a calculation of a matrix d which has a number of “layers” of 3x3 elements. The calculation of d for each iteration depends on the calculation of d for a previous layer; there is some reuse of the d variable within each iteration.
Example 5.23 shows the effect of compiling with and without dependence analysis. The effect for this loop is quite pronounced.
In this situation, dependence analysis enables the compiler to do a number of optimizations. First, the compiler can look at identifying variables which are reused, and so can avoid some memory operations. It can also look at unrolling the loops, or otherwise changing the loops, to maximize the potential reuse of variables. The changing of the loops allows the compiler to better determine streams of data that can be prefetched.
The current UltraSPARC processors do not handle misaligned memory accesses in hardware. For example, an 8-byte value has to be aligned on an 8-byte boundary. If an attempt is made to load misaligned data, the program will either generate a SIGBUS error or trap to the operating system so that the misaligned load can be emulated. In contrast, the x64 family of processors handle misalignment in hardware.
Consequently, the compiler has a SPARC-specific flag, -xmemalign, which specifies the default alignment that the compiler should assume, as well as what behavior should occur when the data is misaligned. For 32-bit applications, since Sun Studio 9, the default is for the compiler to assume 8-byte alignment and to trap and correct any misaligned data accesses. For 64-bit applications, the compiler assumes 8-byte alignment, but the application will SIGBUS on a misaligned access.
Using the -xmemalign flag, it is possible to specify that the compiler should assume a lesser degree of alignment. If this is specified, the compiler will emit multiple loads so that the data can be safely loaded without causing either a SIGBUS or a trap.
If the application makes regular access to misaligned data, it is usually preferable to use the -xmemalign flag to specify a lower assumed alignment, because adding a few load instructions will be significantly faster than trapping to the operating system. If the data is rarely misaligned, it is more efficient to specify the highest alignment, and to take a rare trap when the data is found to be misaligned. Most applications do not have misaligned data, so the default will work adequately. Table 5.7 shows a subset of the available settings for -xmemalign, and summarizes the reasons to use them.
Table 5.7. Common Settings for -xmemalign
| Assumed Alignment | Will Correct Misaligned Data | Comment |
|---|---|---|---|
| 8-byte | No | Use when the application does not access misaligned data |
| 8-byte | Yes | Use when the application may have occasional misaligned accesses |
| 4-byte | No | Use when all memory operations are at least 4-byte aligned |
| 4-byte | Yes | Use when most accesses are 4-byte aligned, but there is still some access that is misaligned |
| 1-byte | No | Use when there are frequent accesses to misaligned data, and that data may even be misaligned at a byte level. Equivalent to |
The -dalign flag is an alternative way to specify 8-byte alignment. In C and C++, the -dalign flag is equivalent to -xmemalign=8s; in Fortran, -dalign expands to -xmemalign=8s -xaligncommon=16. The -xaligncommon=16 flag will cause the Fortran common block elements to be aligned up to a 16-byte boundary for 64-bit applications and an 8-byte boundary for 32-bit applications. In Fortran, if one module is compiled with -dalign or -xaligncommon, all modules have to be compiled with the same flag.
The default page size for SPARC systems is 8KB, which means virtual memory is mapped in chunks of 8KB in the TLB (see Section 1.9.2 of Chapter 1). The page size for x64 systems is 4KB. You can change the page size to a larger value so that more memory can be mapped using the same number of TLB entries. However, changing the page size does not guarantee that the application will get that page size at runtime. The operating system will honor the request if there are sufficient pages of contiguous physical memory.
The page sizes that are available depend on the processor; the flag will have no effect at runtime if the page size is not available on the processor. The common page size settings are 4KB, 8KB, 64KB, 512KB, 2MB, 4MB, and 256MB. Table 4.1 in Chapter 4 lists the page sizes for various processors. The pagesize command, discussed in Section 4.2.6 of Chapter 4, will print out the page sizes that are supported on the hardware.
The -xpagesize compiler flag will cause the application to request a particular page size at runtime. Example 5.24 shows an example of using this flag. The flag needs to be used at both compile time and link time. Two other related flags, -xpagesize_heap and -xpagesize_stack, allow the user to independently specify the page size used to map the heap and the stack.
There is a problem with pointers in that often the compiler is unable to tell from the context exactly what the pointers point to. In practical terms, this means the compiler must make the safest assumption possible: that different pointers may point to the same region of memory. Example 5.25 shows an example of a routine into which three pointers are passed.
Example 5.26 shows the results of disassembling the compiled code. For clarity, the loads and stores have been annotated with the structures being loaded or stored. The disassembly shows the entire loop. By counting the number of floating-point operations, it is easy to determine that this is a single iteration of the loop. For each iteration of the loop there should be three loads, of a[i], b[i], and c[i], and one store of c[i]. However, there are two additional loads in the disassembly shown in Example 5.26. These correspond to reloads of the variables b[i] and c[i]. The problem here is that there is a store to a[i] between the first use of b[i] and c[i] and their subsequent reuse. The compiler is unable to know at compile time whether this store to a[i] will change the value of b[i] or c[i], so it has to make the safe assumption that it will change their values.
Example 5.26. Compiling Code and Examining with Aliasing Problem
% cc -xO3 -S ex5.25.c % more ex5.25.s ... .L900000110: /* 0x00a4 8 */ ld [%o3],%f25 ! load c[i] /* 0x00a8 9 */ add %g3,1,%g3 /* 0x00ac */ add %o1,4,%o1 /* 0x00b0 */ cmp %g3,%o5 /* 0x00b4 */ add %o2,4,%o2 /* 0x00b8 8 */ fmuls %f0,%f2,%f29 /* 0x00bc 9 */ add %o3,4,%o3 /* 0x00c0 8 */ fmuls %f25,%f4,%f27 /* 0x00c4 */ fadds %f29,%f27,%f6 /* 0x00c8 */ st %f6,[%o1-8] ! store a[i] /* 0x00cc 9 */ ld [%o3-4],%f31 ! reload c[i] /* 0x00d0 */ ld [%o2-8],%f2 ! reload b[i] /* 0x00d4 */ fmuls %f2,%f31,%f4 /* 0x00d8 8 */ ld [%o1-4],%f0 ! load a[i+1] /* 0x00dc */ ld [%o2-4],%f2 ! load b[i+1] /* 0x00e0 9 */ bl .L900000110 /* 0x00e4 */ fadds %f6,%f4,%f4 ....
It is hard for the compiler to resolve aliasing issues at compile time. Often, insufficient information is available. Suppose that for a given value of i, the address of a[i] is different from the addresses of b[i] and c[i]. This would allow the compiler to avoid reloading b[i] and c[i] after the store of a[i]. However, the code snippet is a loop, and really the compiler would like to unroll and pipeline the loop. Unrolling and pipelining refer to the optimization of performing multiple iterations of the loop at the same time, much like a manufacturing pipeline. I discuss unrolling and pipelining further in Section 11.2.2 of Chapter 11. After performing this optimization, the store to a[i] might happen after the load of b[i+1] or c[i+2]. So, it is not sufficient to know that just one particular index in the arrays does not alias. The compiler has to be certain that it is true for a range of values of the index variable.
The basic rule is that if the code has pointers in it, the compiler has to be very cautious about how it treats those pointers, and how it treats other variables after a store to a pointer variable. As an example, consider the case where instead of passing the length of the array to the function by value, it is available to the routine as a global variable, as Example 5.27 shows.
Example 5.27. Global Variables and Pointers
extern int n;
void test(float *a, float *b, float *c)
{
int i;
float carry=0.0f;
for (i=1; i<n; i++)
{
a[i]=a[i]*b[i]+c[i]*carry;
carry = a[i]+b[i]*c[i];
}
}
...
/* 0x0030 11 */ ld [%o4],%f0 ! load b[i]
/* 0x0034 12 */ add %g3,1,%g3
/* 0x0038 11 */ ld [%g4],%f4 ! load c[i]
/* 0x003c */ fmuls %f2,%f0,%f12
/* 0x0040 */ fmuls %f4,%f18,%f6
/* 0x0044 */ fadds %f12,%f6,%f16
/* 0x0048 */ st %f16,[%o3] ! store a[i]
/* 0x004c 12 */ add %o3,4,%o3
/* 0x0050 */ ld [%o4],%f10 ! reload b[i]
/* 0x0054 */ add %o4,4,%o4
/* 0x0058 */ ld [%g4],%f8 ! reload c[i]
/* 0x005c */ add %g4,4,%g4
/* 0x0060 */ ld [%g2],%g1 ! reload n
/* 0x0064 */ fmuls %f10,%f8,%f14
/* 0x0068 */ cmp %g3,%g1
/* 0x006c */ fadds %f16,%f14,%f18
/* 0x0070 */ bl,a .L900000111
/* 0x0074 11 */ ld [%o3],%f2 ! load a[i+1]In this case, the compiler cannot tell whether the store to the a[i] array will change the value of n (the variable holding the upper bound for the loop) and cause the bounds of the loop to change. Consequently, with every iteration the loop bounds have to be reloaded. The situation would be worse if the index variable, i, were also a global. In this case, i would have to be stored before the loads of the values held in the arrays, and reloaded after the store of a[i].
The programmer will often know that a[i] does not point to the same memory as b[i] and c[i]. The remainder of this section discusses how to look for aliasing problems, and how to tell the compiler to avoid them.
One way to diagnose aliasing problems is to count the number of load operations in the disassembly, and compare it with the expected number of load operations. Unfortunately, this may not be an exact science, because some of the loads and stores might be required to free up or reload a register to make more efficient use of the available registers. For the code shown in Example 5.27, the source shows three loads and one store per iteration, whereas the disassembly shows six loads and one store—many more memory operations than would be expected.
An similar approach is to look for repeated memory accesses to the same address. In the code shown in Example 5.27, the load of the loop bound at 0x0060 is from memory pointed to by the loop-invariant register %g2. Similarly, the loads at 0x0050 and 0x0058 are reloading the same data as the loads at 0x0030 and 0x0038. The loads are before and after the store statement, which makes it very clear that the store statement has a potential aliasing problem with the loads.
A heuristic for identifying aliasing problems is to look for load operations hard up against store operations. Example 5.27 shows a very good example of this. Three load operations immediately follow the store at 0x0048. A better way to schedule the code would be to place these loads among the floating-point instructions at 0x003c-0x0044. This would allow the processor to start the memory operations while the floating-point operations completed. Because the compiler did not do this optimization, it indicates that either the code was compiled without optimization, or there was some kind of aliasing problem.
One way to make it easier for the compiler to optimize code containing pointers is to use restricted pointers. A restricted pointer is a pointer to an area of memory that no other pointers point to. There is support in the C and C++ compilers to declare a single pointer as being restricted, or to specify that pointers passed as function parameters are restricted.
In the example code shown in Example 5.27, the store to a[i] causes the compiler to have to reload b[i] and c[i]. If the pointer to a is recast as a restricted pointer, the compiler knows that a points to its own area of memory that is not shared with either b or c; hence, b and c do not need to be reloaded after the store to a. Example 5.28 shows the change to the function prototype. In this case, the number of loads per iteration is reduced to three—no variables are reloaded.
Example 5.28. Use of Restricted Specifier
void test(float *restrict a, float *b, float *c)
...
.L900000111:
/* 0x0070 12 */ add %o3,1,%o3
/* 0x0074 */ add %o2,4,%o2
/* 0x0078 11 */ ld [%g5],%f30 ! load b[i]
/* 0x007c 12 */ cmp %o3,%o5
/* 0x0080 */ add %g5,4,%g5
/* 0x0084 11 */ ld [%o2-4],%f28 ! load c[i]
/* 0x0088 */ fmuls %f0,%f30,%f1
/* 0x008c 12 */ add %o0,4,%o0
/* 0x0090 11 */ fmuls %f28,%f2,%f3
/* 0x0094 12 */ fmuls %f30,%f28,%f5
/* 0x0098 11 */ fadds %f1,%f3,%f7
/* 0x009c */ ld [%o0-4],%f0 | load a[i+1]
/* 0x00a0 */ st %f7,[%o0-8] ! store a[i]
/* 0x00a4 12 */ ble,pt %icc,.L900000111
/* 0x00a8 */ fadds %f7,%f5,%f2An alternative solution would be to define the b or c pointer as being restricted. In this situation, both b and c would have to be declared as restricted so that neither is reloaded.
It is also possible to use the -xrestrict compiler flag, which will specify that for the file being compiled, all pointer-type formal parameters are treated as restricted pointers.
Restricted pointers can be a very useful way to inform the compiler that memory regions do not overlap. However, if the compiler flag or the keyword is used incorrectly (i.e., the pointers do overlap), the application’s behavior is undefined.
The -xalias_level compiler flag is available in both C and C++. The flag specifies the degree of aliasing that occurs in the code between different types of pointers. The options in C and C++ are very similar, but the settings have different names.
As with the -xrestrict compiler flag, the -xalias_level flag represents an agreement between the developer and the compiler, which tells the compiler how pointers are used within the application. If the flag is used inappropriately, the resulting application will have undefined behavior.
Table 5.8 summarizes the various options for the -xalias_level flag for C.
Table 5.8. -xalias_levels for C
| Comment |
|---|---|
| Any pointer can point to anything (default) |
| Basic types do not alias each other, except |
| Structure pointers alias by offset in bytes |
| Structure pointers may alias by field index |
| Structure pointers to structures with the same field types can alias |
| Structure pointers to structures with the same field names can alias |
| Pointers do not alias with structure fields. |
-xalias_level=any is the default setting, which tells the compiler that any pointer can potentially alias any other pointer. This is the simplest level of aliasing—the compiler has to treat any pointer as being “wild”—and it could point to anything. Inevitably, this means that when there are pointers, the compiler is unable to do much (if any) optimization.
As an example of this consider the disassembly shown in Example 5.29. This is based on the code shown in Example 5.27, but this time one of the vectors is defined as type integer. To perform calculations on the integer values, they are loaded into floating-point registers and then converted from integer values into single-precision floating-point values using the fitos instruction.
Once again, the compiler has to reload both the vectors and the loop boundary variable, because it cannot tell whether the store to a[i] has changed them. The code has six load instructions and one store; optimally, the code would have three load instructions and one store.
Example 5.29. Example of Possible Aliasing between ints and floats
void test(float *a, int *b, float *c) ... /* 0x0030 11 */ ld [%g5],%f0 !load b[i] (integer) /* 0x0034 12 */ add %g3,1,%g3 /* 0x0038 11 */ ld [%g4],%f6 !load a[i] (float) /* 0x003c */ fitos %f0,%f2 /* 0x0040 */ fmuls %f4,%f2,%f14 /* 0x0044 */ fmuls %f6,%f22,%f12 /* 0x0048 */ fadds %f14,%f12,%f20 /* 0x004c */ st %f20,[%g1] ! store a[i] /* 0x0050 12 */ add %g1,4,%g1 /* 0x0054 */ ld [%g5],%f8 ! reload b[i] (integer) /* 0x0058 */ add %g5,4,%g5 /* 0x005c */ ld [%g4],%f10 ! reload c[i] (float) /* 0x0060 */ add %g4,4,%g4 /* 0x0064 */ ld [%g2],%o3 ! reload n /* 0x0068 */ fitos %f8,%f16 /* 0x006c */ cmp %g3,%o3 /* 0x0070 */ fmuls %f16,%f10,%f18 /* 0x0074 */ fadds %f20,%f18,%f22 /* 0x0078 */ bl,a,pt %icc,.L900000111 /* 0x007c 11 */ ld [%g1],%f4 ! load c[i] (float)
-xalias_level=basic is the default level for -fast. This tells the compiler to assume that pointers to different basic types do not alias. So, taking the example in Example 5.29, a pointer to an integer and a pointer to a float never point to the same address.
However, the pointer to a character (char*) is assumed to be able to point to anything. The rationale for this is that in some programs, the char* pointer is used to extract data from other objects on a byte-by-byte basis.
Example 5.30 shows the code generated when the source code from Example 5.29 is recompiled with the -xalias_level=basic compiler flag. The store is of a floating-point value; by the aliasing assertion used, it is not necessary to reload the integer values. This eliminates the need to reload n, the loop boundary value, and it eliminates the need to reload the integer array b (even though the integer array is actually loaded into a floating-point register to perform the calculation). This reduces the number of loads to four as only the array c is reloaded; this is a floating-point array and could potentially alias with the floating-point array a.
Example 5.30. Pointers to ints and floats under -xalias_level=basic
.L900000111: /* 0x007c 12 */ add %g3,1,%g3 /* 0x0080 */ add %o2,4,%o2 /* 0x0084 11 */ ld [%o0],%f11 ! load a[i] /* 0x0088 12 */ cmp %g3,%o5 /* 0x008c */ add %o1,4,%o1 /* 0x0090 11 */ ld [%o2-4],%f5 ! load c[i] /* 0x0094 */ fmuls %f11,%f8,%f9 /* 0x0098 12 */ add %o0,4,%o0 /* 0x009c 11 */ fmuls %f5,%f0,%f7 /* 0x00a0 */ fadds %f9,%f7,%f19 /* 0x00a4 */ st %f19,[%o0-4] ! store a[i] /* 0x00a8 12 */ ld [%o2-4],%f13 ! reload c[i] /* 0x00ac */ fmuls %f8,%f13,%f17 /* 0x00b0 11 */ ld [%o1-4],%f15 ! load b[i+1] /* 0x00b4 */ fitos %f15,%f8 /* 0x00b8 12 */ ble,pt %icc,.L900000111 /* 0x00bc */ fadds %f19,%f17,%f0
Moving to -xalias_level=weak, the major difference is in structures. This enables the compiler to assume that structure members can only alias by offset in bytes. So, two pointers to structure members will alias if both structure members have the same type and the same offset in bytes from the base of the structure.
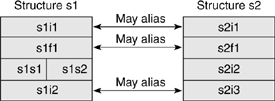
For the purposes of discussing the remaining -xalias_levels, consider the two structures shown in Example 5.31. Both are the same size and start with common fields, but one has two shorts, whereas the other has a single integer occupying the same position in the structure.
Under -xalias_level=weak, the first integer fields (s1i1 and s2i1), the floating-point fields (s1f1 and s2f1), and the final integer fields (s1i2 and s2i3) might alias because they are of the same type and all occupy the same offsets into the structures. However, the first integer field of one structure (s1i1) will not alias with the last integer field of the other structure (s2i3) because they occupy different offsets from the base of the structure. Although the two shorts (s1s1 and s1s2) occupy the same offset as the integer field in the other structure (s2i2), they do not alias because they are of different types. Figure 5.2 shows the aliasing between the two structures.
Example 5.32 shows some example code that uses the two structures and illustrates the kinds of aliasing issues that might be present. Under -xalias_level=any, all the variables in structure s2 need to be reloaded after every store because they could have been impacted by the store. Under -xalias_level=basic, the integer variables need to be reloaded after an integer store, and the floating-point variables need to be reloaded after a floating-point store.
Example 5.32. Potential Aliasing Problems Using Two Structures
void test( struct s1 *s1, struct s2 *s2)
{
s1->s1i1 += s2->s2i1 + s2->s2f1 + s2->s2i2 + s2->s2i3;
s1->s1f1 += s2->s2i1 + s2->s2f1 + s2->s2i2 + s2->s2i3;
s1->s1s1 += s2->s2i1 + s2->s2f1 + s2->s2i2 + s2->s2i3;
s1->s1i2 += s2->s2i1 + s2->s2f1 + s2->s2i2 + s2->s2i3;
}Under -xalias_level=weak, the compiler will assume that aliasing might occur by offset and type. For the store to s1i1, this is an integer at offset zero in the structure, so it might have aliased with s2i1, and therefore the compiler will reload that variable. Similarly, the store to s1f1 might have aliased with the variable s2f1, so that needs to be reloaded. The store to s1s1 matches the variable s2i2 by offset but not by type, so s2i2 does not need to be reloaded. Finally, the store to s1i2 might alias with the variable s2i3, but given that this store is the last statement, there is no need to reload s2i3.
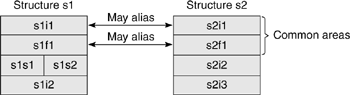
For -xalias_level=layout, the idea of a common area of the structure is introduced. The common area comprises the fields at the start of the structure that are the same in both structures. For the structures in Example 5.31, the common fields are the initial integer and float fields. For -xalias_level=layout, fields at the same offset in the common area may alias (note that to be in the common area, they must share the same type). Fields beyond the common area do not alias.
At -xalias_level=layout, s1i1 can alias with s2i1 because they both are the same type and are in the common area of the two structures. Similarly, s1f1 and s1f2 might alias because they are both of type float, at the same index of the common area. However, because s1s1 is of type short, and the variable s2i2 at the corresponding offset in the other structure is of type integer, this indicates the end of the common area, so they do not alias. Similarly, although s1i2 and s2i3 share both the same offset and the same type, they are no longer in the common area, so they do not alias. This is shown in Figure 5.3.
Under -xalias_level=strict, pointers to structures containing different field types do not alias. The structures shown in Example 5.31 would be considered as not aliasing because they do not contain an identical set of types in an identical order.
The difference between -xalias_level=std and -xalias_level=strict is that for -xalias_level=std the names of the fields are also considered. So, even if both structures have identical fields in them, pointers to them will be considered as not aliasing if the names of the fields are different. This is the degree of aliasing assumed possible in programs that adhere to the C99 standard.
Two additional changes come in at -xalias_level=strong. First, pointers are assumed not to point to fields in structures. Second, it is the only level where char* is treated as a pointer that can only point to characters and not to other types.
Table 5.9 shows the available settings for -xalias_level in C++.
For C++, the -xalias_level=simple level corresponds to -xalias_level=basic in C, that is, the pointers to different basic types do not alias.
-xbuiltin allows the compiler to recognize standard library functions and either replace them with faster inline versions or know whether the function could modify global data. The exact functions that the compiler is able to recognize and replace evolves with the compiler version. Example 5.33 shows an example.
In Example 5.33, the program uses a global variable n before and after a function call to abs. Because n is global, a call to another function might alter its value—in particular, the function abs might cause n to be modified. Hence, the compiler needs to reload n after the function call, as shown in Example 5.34.
Example 5.34. Code Compiled without -xbuiltin
$ cc -xO3 -S ex5.33.c $ more ex5.33.s ... /* 0x0008 9 */ sethi %hi(n),%i4 /* 0x000c 7 */ ld [%i5+%lo(n)],%i5 ! load n /* 0x0010 */ smul %i0,%i5,%i2 /* 0x0014 8 */ call abs /* 0x0018 6 */ or %g0,%i0,%o0 /* 0x001c 9 */ ld [%i4+%lo(n)],%i3 ! load n /* 0x0020 */ smul %o0,%i3,%i1
When compiled with -xbuiltin, the compiler recognizes abs as a library function and knows that the function cannot change the value of the variable n. Hence, the compiler does not need to reload the variable after the call. This is shown in Example 5.35.
There are a few things to consider when using -xbuiltin.
If the application were to include its own function
abs, the definition of this functionabswould override the definition in the header files, and the compiler would reload the variablen.If the compiler uses an inline template to replace a library function call, it is no longer possible to use a different library at runtime to handle that call.
This works only if the appropriate header files are included. In many cases, the
-xbuiltinflag only provides the compiler with additional information about the behavior of functions (such as whether they might modify global variables). This is achieved by having pragmas in the header files which contain this information.The
-xlibmilcompiler flag, which is discussed in Section 6.2.19 of Chapter 6, may provide inline templates for some of the routines-xbuiltinrecognizes.
There are two settings for -xpad: local and common. These affect the padding used for the local variables and for the common block in Fortran. Fortran specifies very tightly how the variables should be lined up in the common blocks, and to save space, it does not pad local variables; but this may not be optimal when performance is considered. For example, it may be necessary to load a floating-point double with two floating-point single loads, because the double is not correctly aligned. Telling the compiler to insert padding allows it to move the variables around to maximize performance. You can also use the flag to improve data layout in memory and avoid data thrashing in the caches.
Note that if there are multiple files, it is necessary to use the same -xpad flag setting to compile all the files. Otherwise, it is possible that one file may anticipate a different layout than another file, and the program will either crash or give incorrect results.
The -xstackvar flag places local variables on the stack. One advantage of doing this is that it makes writing recursive code significantly easier, because new copies of the variables get allocated for every level of recursion. Use of this flag is encouraged when writing parallel code, because each thread will end up with its own copy of local variables.
A downside of using -xstackvar is that it will increase the amount of stack space that the program requires, and it is possible that the stack may overflow and cause a segmentation fault. The default stack size is 8MB for the main stack. You can increase this using the limit stacksize command as shown in Example 5.36.
Pragmas are compiler directives that are inserted into source code. They make assertions about the code; they tell the compiler additional information that it can use to improve the optimization of the code.
When a pragma refers to variables, the pragma must occur before the variables are declared. However, when a pragma refers to functions, it must occur after the prototypes of the functions have been declared. When the pragma refers to a loop, the next loop the compiler encounters has the assertion.
You insert pragmas into code using #pragma in C/C++ and c$pragma in Fortran.
#pragma align <1,2,4,8,16,32,64,128> (<list of variable names>) specifies that the variables be aligned on a particular alignment. The code in Example 5.37 shows an example of the use of the pragma.
Example 5.38 shows the results of compiling and running code with the pragma. Variables a and b align on 128-byte boundaries (the addresses are printed as hex values).
#pragma does_not_read_global_data (<list of function names>) and #pragma does_not_write_global_data (<list of function names>) assert that a given function does not read or write (depending on the pragma) global data. This means the compiler can assume at the calling site that registers do not need to be saved before the call or do not need to be loaded after the call, or that the saving of registers can be deferred. Example 5.39 shows an example of these pragmas.
Example 5.39. Example of Global Data Pragmas
#include <stdio.h>
int a;
void test1(){}
void test2(){}
void test3(){}
#pragma does_not_read_global_data(test3)
#pragma does_not_write_global_data(test2,test3)
void main()
{
int i;
a=1;
test1();
a+=1;
test2();
for(i=0; i<10; i++)
{
a+=1;
test3();
}
printf("a=%d
",a);
}Example 5.40 shows the results of compiling the code shown in Example 5.39.
Before the call to test1, the a variable is stored in case it is read by the test1 routine. After the call to test1, the a variable is reloaded in case the test1 routine has changed the a variable.
Example 5.40. Example of Optimizations around Function Calls with Pragmas
$ cc -xO3 -S ex5.39.c ... /* 0x0004 0 */ sethi %hi(a),%i5 /* 0x0008 11 */ or %g0,1,%i4 /* 0x000c 12 */ call test1 /* 0x0010 11 */ st %i4,[%i5+%lo(a)] ! store a before call /* 0x0014 0 */ add %i5,%lo(a),%i2 /* 0x0018 15 */ or %g0,0,%i0 /* 0x001c 13 */ ld [%i2],%i5 ! load a after call /* 0x0020 */ add %i5,1,%i1 /* 0x0024 14 */ call test2 /* 0x0028 13 */ st %i1,[%i2] ! store a before call /* 0x002c 17 */ add %i1,1,%i1 .L900000409: /* 0x0030 18 */ call test3 /* 0x0034 */ add %i0,1,%i0 /* 0x0038 */ cmp %i0,10 /* 0x003c */ bl,a .L900000409 /* 0x0040 17 */ add %i1,1,%i1
The pragma informs the compiler that the test2 routine does not write global data, but it may read global data, so the compiler has to store a before test2 is called. However, it knows its value is not changed by the routine, so the variable does not have to be reloaded afterward. For test3, the compiler knows the routine neither reads nor writes the a variable, so the a variable does not need to be stored before the call to test3, or reloaded afterward.
#pragma no_side_effect (<list of function names>) tells the compiler that the function has no side effects—its return value depends only on the input parameters, and it does not access or modify any other data. Example 5.41 shows an example of this pragma.
The effects of this pragma are interesting. The compiler is now able to eliminate the calls to test2 and test3, because the pragma asserts that the routines only access the parameters passed in and do not cause changes to global state. For test2, there is no return value, so the call can be eliminated. For test3, a parameter is passed in, but there is no return value, so the call can be eliminated. For test4, however, the call has to remain because there is a return value. The a variable is stored before the call to test4, but it does not need to be reloaded afterward because the routine cannot have changed it. You can see this in the assembly code in Example 5.42, where the variable a is stored before the call to test1, reloaded, stored again before the call to test4 (having eliminated test2 and test3), and not reloaded after the call to test4.
Example 5.41. Example of the no_side_effect Pragma
#include <stdio.h>
int a;
void test1(){}
void test2(){}
void test3(int a){}
int test4(int a){return a;}
#pragma no_side_effect(test2,test3,test4)
void main()
{
int i;
a=1;
test1();
a+=1;
test2();
a+=1;
test3(a);
a+=1;
a+=test4(a);
printf("a=%d
",a);
}Example 5.42. Assembly Code of Calls with the no_side_effect Pragma Asserted
/* 0x0004 11 */ sethi %hi(a),%i5 /* 0x0008 */ or %g0,1,%i4 /* 0x000c 12 */ call test1 /* 0x0010 11 */ st %i4,[%i5+%lo(a)] ! store a /* 0x0014 13 */ sethi %hi(a),%i3 /* 0x0018 18 */ sethi %hi(a),%i0 /* 0x001c 13 */ ld [%i3+%lo(a)],%i5 ! load a /* 0x0020 19 */ sethi %hi(.L121),%l7 /* 0x0024 17 */ add %i5,3,%i2 /* 0x0028 */ st %i2,[%i3+%lo(a)] ! store a /* 0x002c 18 */ call test4 /* 0x0030 */ or %g0,%i2,%o0 /* 0x0034 */ add %i2,%o0,%i1 /* 0x0038 */ st %i1,[%i0+%lo(a)] ! store a /* 0x003c 19 */ add %l7,%lo(.L121),%i0
#pragma rarely_called (<list of function names>) tells the compiler that the functions are rarely called, and provides what amounts to static profile-feedback-type information. If a function is rarely called, the compiler will (probably) not inline it, and will assume that conditional calls to it are generally untaken. Example 5.43 shows an example of this pragma. The code shown has two similar statements, but the location of the call to the rarely called location is changed.
Example 5.44 shows the output from the compiler for this code. You can see that the compiler has arranged the code so that the call to the rarely executed routine is not the fall-through. To achieve this it had to invert the condition test on the second branch from a “greater than” comparison to a “less than or equal to” comparison. The calls to the infrequent function are not shown in this code snippet.
Example 5.44. Disassembly Code Resulting from the rarely_called Pragma
/* 0x0004 5 */ sll %i0,2,%i3 /* 0x0008 */ ld [%i1+%i3],%i0 ! load x[i] /* 0x000c */ cmp %i0,0 /* 0x0010 */ bg,pn %icc,.L77000020 ! branch on x[i] /* 0x0014 */ add %i0,1,%l6 .L77000021: /* 0x0018 5 */ st %l6,[%i1+%i3] /* 0x001c 6 */ ld [%i2+%i3],%i1 ! load y[i] .L900000109: /* 0x0020 6 */ cmp %i1,0 /* 0x0024 */ ble,pn %icc,.L77000024 ! branch on y[i] /* 0x0028 */ add %i1,1,%i4 .L77000023: /* 0x002c 6 */ st %i4,[%i2+%i3] /* 0x0030 */ ret ! Result = /* 0x0034 */ restore %g0,%g0,%g0
Pipelining is where the compiler overlaps operations from different iterations of the loop to improve performance. Figure 5.4 shows an illustration of this. In the figure, both loops complete four iterations of the original loop in a single iteration of the modified loop. When the loop is unrolled, these four iterations are performed sequentially. This optimization improves performance because it reduces the instruction count of the loop. When the compiler is also able to pipeline the loop, it interleaves instructions from the different iterations. This allows it to better schedule the instructions such that fewer cycles are needed for the four iterations.
#pragma pipeloop (N) tells the compiler that the following loop has a dependency at N iterations, so up to N iterations of the loop can be pipelined. The most useful form of this pragma is pipeloop(0), which tells the compiler that there is no cross-iteration data dependancy, so the compiler is free to pipeline the loop as it sees fit.
In the example shown in Example 5.45 the pragma is used to assert that there is no dependence between iterations of the loop. This allows the compiler to assume that stores to the a array will not impact values in either the b or the indexa array. Under this pragma, the compiler is able to both unroll and pipeline the loop.
#pragma nomemorydepend tells the compiler that there are no memory dependancies (i.e., aliasing) within a single interation of the following loop. This allows the compiler to move the instructions within a single loop iteration to improve the schedule, but it will not allow the compiler to mix instructions from different loop iterations.
#pragma unroll (N) suggests to the compiler that the loop following the pragma should be unrolled N times. This can be useful in situations where the developer has some information about the loop that the compiler is unable to derive.
This might be useful in the following situations:
When the compiler will aggressively unroll a loop, but the developer knows the trip count of the loop is very low, so the unrolled loop will never get executed
When the compiler could be more aggressive in unrolling a loop, or the exact trip count of a loop is known to the developer; in these cases, the developer may want to cause the compiler to unroll a loop more times
Example 5.46 shows an example of the use of this pragma.
In C, it is possible to insert pragmas into the source code to achieve a finer degree of control over the use of aliasing information by the compiler. For the compiler to take advantage of these pragmas it must be using at least -xalias_level=basic.
Example 5.47 shows code that has the potential for aliasing problems. In this code, the a array might alias with the b or c array, or might even alias with the externally declared variable n. As such, in the absence of any aliasing information, the compiler has to assume that the b and c arrays, and the n variable, have to be reloaded after every store to the a array.
Example 5.48 shows part of the assembly code generated by the compiler from the source code in Example 5.47. Recent compilers may produce multiple versions of this loop, each version making different aliasing assumptions. This version assumes that all the pointers may alias.
Example 5.48. Disassembly Code in the Absence of Aliasing Information
.L900000111: /* 0x0030 10 */ ld [%g5],%f0 ! load b[] /* 0x0034 11 */ add %g3,1,%g3 /* 0x0038 10 */ ld [%g4],%f4 ! load c[] /* 0x003c */ fmuls %f2,%f0,%f12 /* 0x0040 */ fmuls %f4,%f18,%f6 /* 0x0044 */ fadds %f12,%f6,%f16 /* 0x0048 */ st %f16,[%g1] ! store a[] /* 0x004c 11 */ add %g1,4,%g1 /* 0x0050 */ ld [%g5],%f10 ! reload b[] /* 0x0054 */ add %g5,4,%g5 /* 0x0058 */ ld [%g4],%f8 ! reload c[] /* 0x005c */ add %g4,4,%g4 /* 0x0060 */ ld [%g2],%o3 ! reload n /* 0x0064 */ fmuls %f10,%f8,%f14 /* 0x0068 */ cmp %g3,%o3 /* 0x006c */ fadds %f16,%f14,%f18 /* 0x0070 */ bl,a,pt %icc,.L900000111 /* 0x0074 10 */ ld [%g1],%f2 ! load a[]
Recompiling the code in Example 5.47 with the -xalias_level=basic compiler flag enables the compiler to eliminate the reload of the n variable, because n is an integer and the store is of a floating-point value.
Alternatively, the -xrestrict compiler flag would tell the compiler that each pointer passed into the function pointed to its own area of memory, so the reloads of the b and c arrays and the n variable would be unnecessary. Similarly, declaring pointer a as being restricted would tell the compiler that it pointed to its own area of memory and would avoid the reload of the other variables.
#pragma alias_level <level> (<list of types>) and #pragma alias_level <level> (<list of variables>) tell the compiler that for the current file, the variables or types listed behave as specified by the alias level; the same levels are used as those defined in Section 5.9.
This is useful for adjusting the alias level for a single file where the variables are either well behaved or badly behaved. For example, if two pointers are known to (potentially) alias, they can be pragma’d as having an alias level of any.
You can inform the compiler that the int type can be aliased by any pointer by modifying the code as shown in Example 5.49.
It is also possible to specify the alias level for a single variable for the scope of the file. The variable has to have file-level scope. Example 5.50 shows an example of this; in this example, the a variable has file-level scope, and the pragma tells the compiler that it may alias with anything. As a consequence, the external n variable will need to be reloaded after every store to a.
#pragma alias (<list of types>) and #pragma alias (<list of pointers>) tell the compiler that either the types or the variables will alias each other within the current scope. Example 5.51 shows an example of the use of this pragma. In this case, the compiler is told that integer and floating-point variables do alias. Under this pragma, the compiler will need to reload n after every store to a[].
If there are multiple pointers of different types, you can use the alias pragma to tell the compiler that the different pointer types do alias (even when the -xalias_level=basic flag is used). Example 5.52 shows an example of this. In this case, the c pointer is of type integer, and the alias pragma is used to specify that this particular pointer will alias with the pointer a. This means that stores to a will cause the compiler to have to reload c, which would not have been the case normally under -xalias_level=basic.
#pragma may_point_to (<pointer>,<list of variables>) informs the compiler that a pointer may point to any one of a list of variables. Example 5.53 shows an example of this. This pragma tells the compiler that the a pointer may point to (and therefore change) the n variable. As a result, each store to a[] causes the compiler to reload n.
#pragma noalias (<list of types>) and #pragma noalias (<list of variables>) tell the compiler that the variables or types do not alias each other within the current scope. The code in Example 5.54 shows the use of this pragma. With this pragma inserted into the code, the compiler is able to assume that the arrays a, b, and c do not alias; consequently, b and c do not need to be reloaded after every store to a.
#pragma may_not_point_to (<pointer>,<list of variables>) tell the compiler that the pointer does not point to any of the listed variables within the current scope. Example 5.55 shows an example of this pragma. In this case, carry is defined as an external variable of type float, which means that under -xalias_level=basic, stores to the a array might alias to to the carry variable. Hence, the carry variable will have to be reloaded after every store to the a array. Under the pragma, the compiler knows that stores to a do not impact the variable carry, so it is not necessary to reload carry after every store to the a array. There is an interesting twist here, in that the carry variable may be aliased by either array b or array c, which means that the assignment to carry must result in a store to memory, in case it changes a value in the b or c array.
The Sun Studio compiler handles an expanding subset of the GCC extensions. However, it is always possible that the particular idiom used in an application is not supported. For compilations on SPARC-based systems, it is possible to use the GCC for SPARC Systems compiler, which you can freely download from http://cooltools.sunsource.net/gcc/. This compiler uses the GCC frontend to parse the source files, together with the code generator from the Sun Studio compiler, to actually produce the object files.
The potential benefits of using the GCC for SPARC Systems compiler are as follows:
Compatibility with GCC
Improved code generation from the Sun Studio code generator
Support for additional optimizations, such as crossfile optimizations