
Chapter 15 Implementing and Administering SQL Server Replication
Replication is a native SQL Server feature that allows a DBA to copy tables, views, indexed views, functions, stored procedures, and so on from one database to another, and allows a DBA to control how synchronized the two copies are. In other words, you can replicate changes to both data and schema objects (that is, table, view, or stored procedure changes, and so on). Some replication types allow for bidirectional replication, where changes made on the destination database can be replicated back to the source database.
Replication is best used for the following purposes:
![]() To move data closer to clients— For example, branch offices might need to access data in a central office, and the network hop involved makes the applications run very slowly. Having a local copy of the data will make their data access much faster.
To move data closer to clients— For example, branch offices might need to access data in a central office, and the network hop involved makes the applications run very slowly. Having a local copy of the data will make their data access much faster.
![]() To offload reporting to another server— Instead of having reporting clients accessing data from the production server, causing I/O and database user contention between the reporting users and the application users, data can be replicated to a reporting server and the reporting clients can access their data there. The end result is greater scalability for both sets of users.
To offload reporting to another server— Instead of having reporting clients accessing data from the production server, causing I/O and database user contention between the reporting users and the application users, data can be replicated to a reporting server and the reporting clients can access their data there. The end result is greater scalability for both sets of users.
![]() To scale out performance— Instead of having 1,000 users accessing a single server, 100 users can each access one of 10 servers with the end result being improved performance for all users.
To scale out performance— Instead of having 1,000 users accessing a single server, 100 users can each access one of 10 servers with the end result being improved performance for all users.
![]() To fulfill application requirements— This includes consolidating data from branch offices to a central location, replicating to tables with different schemas, replicating to different RDBMSs, replicating to handheld devices, and so on.
To fulfill application requirements— This includes consolidating data from branch offices to a central location, replicating to tables with different schemas, replicating to different RDBMSs, replicating to handheld devices, and so on.
Replication is also frequently used as a disaster recovery solution, but it is a poor choice for this for these reasons:
![]() There is no automatic failover of clients from the production server to the failover server.
There is no automatic failover of clients from the production server to the failover server.
![]() Latencies aren’t predictable, and consequently exposure to data loss can be much greater than with other disaster recovery technologies.
Latencies aren’t predictable, and consequently exposure to data loss can be much greater than with other disaster recovery technologies.
![]() Not every object is replicated (for example, logins), and new objects require special handling.
Not every object is replicated (for example, logins), and new objects require special handling.
![]() Replication requires licenses for both the production server and the failover server; the other Microsoft disaster recovery solutions for SQL Server do not.
Replication requires licenses for both the production server and the failover server; the other Microsoft disaster recovery solutions for SQL Server do not.
The focus of this chapter is how to design, implement, and monitor replication topologies.
Although the changes in replication between SQL Server 2000 and 2005 were radically different, the changes between SQL Server 2005 and 2008 are much smaller. The following features are new in SQL Server 2008:
![]() Radical improvements in snapshot delivery
Radical improvements in snapshot delivery
![]() A new interface for creating and modifying peer-to-peer topologies
A new interface for creating and modifying peer-to-peer topologies
![]() Peer-to-peer replication, which now supports conflict detection and replicates schema changes without having to go offline
Peer-to-peer replication, which now supports conflict detection and replicates schema changes without having to go offline
![]() Deeper replication integration with database mirroring
Deeper replication integration with database mirroring
![]() A class that developers can use for database synchronization that requires no DBA administration (Sync Services)
A class that developers can use for database synchronization that requires no DBA administration (Sync Services)
To be able to administer SQL Server replication, you will need to understand the concepts behind it. Replication also has many components. This section introduces the main concepts and components of replication.
Replication uses metaphors from the world of publishing. The main components are as follows:
![]() Publisher— The source of the data and/or objects you are replicating. This could be a SQL Server or an Oracle Server; SQL Server Express is not supported as a Publisher.
Publisher— The source of the data and/or objects you are replicating. This could be a SQL Server or an Oracle Server; SQL Server Express is not supported as a Publisher.
![]() Subscriber— The destination server; again this could be a database on the same server, another SQL Server (2000, 2005 or 2008) or an Oracle or DB2 RDBMS. SQL Server Express and CE are also supported subscribers.
Subscriber— The destination server; again this could be a database on the same server, another SQL Server (2000, 2005 or 2008) or an Oracle or DB2 RDBMS. SQL Server Express and CE are also supported subscribers.
![]() Distributor— Transactional and snapshot replication (these replication types are covered in the next section) use a store-and-forward metaphor. The Distributor is a server that stores the replication commands before they are executed on the Subscriber. In merge replication, the Distributor only holds historical data. In most topologies the Distributor will be on the same server as the Publisher; however, if you expect large workloads on your Publisher, you might want to use a remote distributor.
Distributor— Transactional and snapshot replication (these replication types are covered in the next section) use a store-and-forward metaphor. The Distributor is a server that stores the replication commands before they are executed on the Subscriber. In merge replication, the Distributor only holds historical data. In most topologies the Distributor will be on the same server as the Publisher; however, if you expect large workloads on your Publisher, you might want to use a remote distributor.
If you do not already have a Distributor, connect to your SQL Server in SQL Server Management Studio, and expand the Replication folder. If you do not see a folder labeled Local Publications, you are running SQL Server Express, which does not support the installation of a Distributor. If you see a menu item Distributor Properties, your SQL Server is already configured with a Distributor. If you do not have a Distributor, right-click and select Configure Distribution. Click Next and accept the default to create a local distributor. We will cover how to create a remote distributor in the section “Creating the Distributor.”
![]() Publications— Publications contain the objects you want to replicate. Group the objects you want to replicate into publications according to replication type, logical grouping (such as business unit), publications that have common properties, or common objects that need to go to a group of subscribers.
Publications— Publications contain the objects you want to replicate. Group the objects you want to replicate into publications according to replication type, logical grouping (such as business unit), publications that have common properties, or common objects that need to go to a group of subscribers.
![]() Articles— Articles are objects you can replicate. They include schema-only objects (functions, views, and stored procedures) and schema and data objects (tables and indexed views). Tables and indexed views can be vertically or horizontally partitioned; in other words, a subset of the columns or rows or a subset of both can be replicated.
Articles— Articles are objects you can replicate. They include schema-only objects (functions, views, and stored procedures) and schema and data objects (tables and indexed views). Tables and indexed views can be vertically or horizontally partitioned; in other words, a subset of the columns or rows or a subset of both can be replicated.
![]() Bidirectional replication— This metaphor is not from the world of publishing. In bidirectional replication, data modifications (DML) originating on the Publisher are applied on the Subscriber and DML originating on the Subscriber are applied on the Publisher. The most common type of bidirectional replication used is merge replication. Please refer to the section “Configuring Merge Replication.”
Bidirectional replication— This metaphor is not from the world of publishing. In bidirectional replication, data modifications (DML) originating on the Publisher are applied on the Subscriber and DML originating on the Subscriber are applied on the Publisher. The most common type of bidirectional replication used is merge replication. Please refer to the section “Configuring Merge Replication.”
![]() Push subscribers— The Publisher pushes the schema and data to the Subscriber. This is normally used with a small number of subscribers on a Local Area Network (LAN).
Push subscribers— The Publisher pushes the schema and data to the Subscriber. This is normally used with a small number of subscribers on a Local Area Network (LAN).
![]() Pull subscribers— The Subscriber pulls the schema and data from the Publisher. This is normally used with large numbers of subscribers and most often over the Internet.
Pull subscribers— The Subscriber pulls the schema and data from the Publisher. This is normally used with large numbers of subscribers and most often over the Internet.
![]() Publication Access List (PAL)— A database group of subscriber SQL or Windows accounts that have rights to access the publication.
Publication Access List (PAL)— A database group of subscriber SQL or Windows accounts that have rights to access the publication.
![]() Conflict— This metaphor is not from the world of publishing. In conflicts, a data modification occurs on one side of a replication topology that disagrees with a modification on another side of the replication topology. There are five basic types of conflicts:
Conflict— This metaphor is not from the world of publishing. In conflicts, a data modification occurs on one side of a replication topology that disagrees with a modification on another side of the replication topology. There are five basic types of conflicts:
![]() Primary key collision— An insert originating on the Publisher has the same primary key values as an insert on the Subscriber, and the primary key constraint is violated when replication attempts to synchronize the two.
Primary key collision— An insert originating on the Publisher has the same primary key values as an insert on the Subscriber, and the primary key constraint is violated when replication attempts to synchronize the two.
![]() Updating a deleted row— This conflict occurs when a row is updated on one side of the replication topology (the Publisher for instance) and deleted on the Subscriber. The conflict occurs when replication attempts to synchronize the two.
Updating a deleted row— This conflict occurs when a row is updated on one side of the replication topology (the Publisher for instance) and deleted on the Subscriber. The conflict occurs when replication attempts to synchronize the two.
![]() Lack of consistency— One row is modified on the Publisher, but when replication attempts to modify the same row on the Subscriber, it does not exist or there is more than one row with the same key values.
Lack of consistency— One row is modified on the Publisher, but when replication attempts to modify the same row on the Subscriber, it does not exist or there is more than one row with the same key values.
![]() Column-level tracking— A tuple or cell is updated on one side of a replication topology and updated with a different value on the other side of the replication topology.
Column-level tracking— A tuple or cell is updated on one side of a replication topology and updated with a different value on the other side of the replication topology.
![]() Row-level tracking— A row is updated on one side of a replication topology and the same row is updated on the other side of the replication topology. Unlike column-level tracking, row-level tracking does not track to see if the change occurred in the same column.
Row-level tracking— A row is updated on one side of a replication topology and the same row is updated on the other side of the replication topology. Unlike column-level tracking, row-level tracking does not track to see if the change occurred in the same column.
There are three types of replication: snapshot, transactional, and merge, with some variants on the snapshot and transactional replication types.
![]() Snapshot replication— This replication type generates an image of the data at a point in time (a snapshot) and distributes it to one or more subscribers. After the snapshot is deployed, no changes are replicated to the Subscriber(s) until the next time the snapshot is generated and distributed. This replication type is best used when your data changes infrequently and the bulk of it changes at one time, for example, catalog updates. There are no schema modifications using this replication type.
Snapshot replication— This replication type generates an image of the data at a point in time (a snapshot) and distributes it to one or more subscribers. After the snapshot is deployed, no changes are replicated to the Subscriber(s) until the next time the snapshot is generated and distributed. This replication type is best used when your data changes infrequently and the bulk of it changes at one time, for example, catalog updates. There are no schema modifications using this replication type.
![]() Snapshot replication with queued updating— This replication type is a variation of snapshot replication; however, changes that occur on the Subscriber are replicated back to the Publisher on a continuous or scheduled basis. This replication type is best used in the following situations:
Snapshot replication with queued updating— This replication type is a variation of snapshot replication; however, changes that occur on the Subscriber are replicated back to the Publisher on a continuous or scheduled basis. This replication type is best used in the following situations:
![]() When the majority of the changes occur on the Publisher.
When the majority of the changes occur on the Publisher.
![]() When there are fewer than 10 subscribers.
When there are fewer than 10 subscribers.
![]() This replication type is resilient to network interruptions; if a failure occurs, replication will pick up where it left off and replicate changes back to the Publisher.
This replication type is resilient to network interruptions; if a failure occurs, replication will pick up where it left off and replicate changes back to the Publisher.
![]() This replication type adds a GUID column and triggers to all tables that are replicated.
This replication type adds a GUID column and triggers to all tables that are replicated.
![]() Adjustments must be made for constraints, triggers, and the identity property with this replication type.
Adjustments must be made for constraints, triggers, and the identity property with this replication type.
![]() Conflicts will be detected, but there are no facilities to roll them back (more on conflict detection later). This variant is deprecated in SQL Server 2008. Microsoft recommends that you use peer-to-peer replication, although it is only supported in the Enterprise Edition of SQL Server.
Conflicts will be detected, but there are no facilities to roll them back (more on conflict detection later). This variant is deprecated in SQL Server 2008. Microsoft recommends that you use peer-to-peer replication, although it is only supported in the Enterprise Edition of SQL Server.
![]() Snapshot replication with immediate updating— This replication type is another variation of snapshot replication; however, changes that occur on the Subscriber are applied as a two-phase commit via Microsoft Distributed Transaction Coordinator (MS DTC) to the Subscriber. Essentially all transactions originating at the Subscriber are applied in a transactional context on the Publisher and then on the Subscriber. In addition to the same caveats with queued updating there are several important additional caveats to this replication type:
Snapshot replication with immediate updating— This replication type is another variation of snapshot replication; however, changes that occur on the Subscriber are applied as a two-phase commit via Microsoft Distributed Transaction Coordinator (MS DTC) to the Subscriber. Essentially all transactions originating at the Subscriber are applied in a transactional context on the Publisher and then on the Subscriber. In addition to the same caveats with queued updating there are several important additional caveats to this replication type:
![]() Latency of transactions originating on the Subscriber is increased. Now transactions have to make a network hop and be written on both sides. This latency can reduce scalability.
Latency of transactions originating on the Subscriber is increased. Now transactions have to make a network hop and be written on both sides. This latency can reduce scalability.
![]() If the link between the Subscriber and the Publisher goes down, transactions originating on the Subscriber will hang until the transaction is rolled back. The transactions typically hang between 15 and 20 seconds before being rolled back.
If the link between the Subscriber and the Publisher goes down, transactions originating on the Subscriber will hang until the transaction is rolled back. The transactions typically hang between 15 and 20 seconds before being rolled back.
![]() Snapshot replication with immediate updating and queued failover— This variant of snapshot replication uses immediate updating by default; however, if your Publisher goes offline, you have the option to manually switch to queued updating. The same caveats as queued updating apply here as well.
Snapshot replication with immediate updating and queued failover— This variant of snapshot replication uses immediate updating by default; however, if your Publisher goes offline, you have the option to manually switch to queued updating. The same caveats as queued updating apply here as well.
![]() The majority of the transactions originate at the Publisher.
The majority of the transactions originate at the Publisher.
![]() There should be fewer than 10 subscribers.
There should be fewer than 10 subscribers.
![]() Conflict detection but not conflict handling.
Conflict detection but not conflict handling.
![]() A GUID column will be added to your tables being replicated.
A GUID column will be added to your tables being replicated.
![]() Conflicts will be detected but there are no facilities to roll them back (more on conflict detection later). This variant is deprecated in SQL Server 2008. Microsoft recommends that you use peer-to-peer replication, although it is only supported in the Enterprise Edition of SQL Server.
Conflicts will be detected but there are no facilities to roll them back (more on conflict detection later). This variant is deprecated in SQL Server 2008. Microsoft recommends that you use peer-to-peer replication, although it is only supported in the Enterprise Edition of SQL Server.
![]() Transactional Replication— This is the most common replication type. It is chosen because it tracks changes and replicates them to the Subscriber. The latency with this replication type can be very low (typically slightly less than 3 seconds) even for large workloads that involve singletons (one-row inserts, updates, and deletes). However, latencies can be large for batch updates, inserts, and deletes. In transactional replication, transactions that occur on the Publisher are read from the transaction log and stored in the distribution database on the Distributor. They are then applied on the Subscriber via stored procedures or SQL statements, within a transactional context. This replication type requires a primary key on every table you are replicating and is resilient to network interruptions. Transaction replication does not make any modifications to the tables it replicates.
Transactional Replication— This is the most common replication type. It is chosen because it tracks changes and replicates them to the Subscriber. The latency with this replication type can be very low (typically slightly less than 3 seconds) even for large workloads that involve singletons (one-row inserts, updates, and deletes). However, latencies can be large for batch updates, inserts, and deletes. In transactional replication, transactions that occur on the Publisher are read from the transaction log and stored in the distribution database on the Distributor. They are then applied on the Subscriber via stored procedures or SQL statements, within a transactional context. This replication type requires a primary key on every table you are replicating and is resilient to network interruptions. Transaction replication does not make any modifications to the tables it replicates.
![]() Transactional Replication with Queued Updating— This replication type is very similar to Snapshot replication with queued updating. Changes that originate on the Publisher are replicated via a Distribution Agent (more on this later in the next section). Changes that occur on the Subscriber are replicated back to the Publisher via a queue reader (more later). The same caveats with snapshot replication with queued updating also apply here. This variant is deprecated in SQL Server 2008. Microsoft recommends that you use peer-to-peer replication, although it is only supported in the Enterprise Edition of SQL Server.
Transactional Replication with Queued Updating— This replication type is very similar to Snapshot replication with queued updating. Changes that originate on the Publisher are replicated via a Distribution Agent (more on this later in the next section). Changes that occur on the Subscriber are replicated back to the Publisher via a queue reader (more later). The same caveats with snapshot replication with queued updating also apply here. This variant is deprecated in SQL Server 2008. Microsoft recommends that you use peer-to-peer replication, although it is only supported in the Enterprise Edition of SQL Server.
![]() Transactional Replication with Immediate Updating— This replication type is very similar to snapshot replication with immediate updating. Changes that originate on the Publisher are replicated via a Distribution Agent (more on this later in the next section). Changes that occur on the Subscriber are replicated back to the Publisher using a two-phase commit via MS DTC. The same caveats with snapshot replication with immediate updating also apply here. This variant is deprecated in SQL Server 2008. Microsoft recommends that you use peer-to-peer replication, although it is only supported in the Enterprise Edition of SQL Server.
Transactional Replication with Immediate Updating— This replication type is very similar to snapshot replication with immediate updating. Changes that originate on the Publisher are replicated via a Distribution Agent (more on this later in the next section). Changes that occur on the Subscriber are replicated back to the Publisher using a two-phase commit via MS DTC. The same caveats with snapshot replication with immediate updating also apply here. This variant is deprecated in SQL Server 2008. Microsoft recommends that you use peer-to-peer replication, although it is only supported in the Enterprise Edition of SQL Server.
![]() Transactional Replication with Immediate Updating and Queued Failover— This is a variant of snapshot replication with immediate updating and queued failover. As the Subscriber will roll back all transactions that originate on the Subscriber when the Publisher is offline, the topology is designed to be failed over to queued updating until the Subscriber comes back online. The same caveats as in snapshot replication with immediate updating and queued failover hold here as well. This variant is deprecated in SQL Server 2008. Microsoft recommends that you use peer-to-peer replication, although it is only supported in the Enterprise Edition of SQL Server.
Transactional Replication with Immediate Updating and Queued Failover— This is a variant of snapshot replication with immediate updating and queued failover. As the Subscriber will roll back all transactions that originate on the Subscriber when the Publisher is offline, the topology is designed to be failed over to queued updating until the Subscriber comes back online. The same caveats as in snapshot replication with immediate updating and queued failover hold here as well. This variant is deprecated in SQL Server 2008. Microsoft recommends that you use peer-to-peer replication, although it is only supported in the Enterprise Edition of SQL Server.
![]() Oracle Publishing— In this type of replication, an Oracle RDBMs server replicates to SQL Server 2005 or 2008. This is supported on the Enterprise Edition of SQL Server. This is a variant of transactional replication. Support is deprecated for Oracle 8, with SQL Server 2008 you to run Oracle 9i and above as the Oracle Publisher.
Oracle Publishing— In this type of replication, an Oracle RDBMs server replicates to SQL Server 2005 or 2008. This is supported on the Enterprise Edition of SQL Server. This is a variant of transactional replication. Support is deprecated for Oracle 8, with SQL Server 2008 you to run Oracle 9i and above as the Oracle Publisher.
![]() Bidirectional Transactional Replication— This replication type is not available using the wizards and must be configured manually. Use transactional replication to replicate to the Subscriber, and then the Subscriber is configured as a Publisher to replicate back to the original Publisher. Set the
Bidirectional Transactional Replication— This replication type is not available using the wizards and must be configured manually. Use transactional replication to replicate to the Subscriber, and then the Subscriber is configured as a Publisher to replicate back to the original Publisher. Set the @loopback_detection parameter to True in sp_addsubscription when configuring your subscribers. You must set the Not For Replication property on all constraints, triggers, and identity columns. You will also need to set the identity property to have different seeds on either side so that you don’t get any primary key conflicts—configuring your primary keys or identity seeds to minimize primary key conflicts is called partitioning. This replication type does not require any schema modifications.
Although Microsoft recommends using peer-to-peer replication, which is an Enterprise Edition–only feature, bidirectional transactional replication is supported on the Standard Edition and above and is faster than peer-to-peer replication, but not scalable beyond a small number of nodes (two to three).
![]() Peer to Peer Transactional Replication— Peer-to-peer transactional replication is bidirectional replication extended to many more Publisher/Subscriber pairs called nodes. The limit is 10 nodes; however, this depends on available network bandwidth and workload. Peer-to-peer replication is popular because a node can drop off (for maintenance, or if the link goes down) and the other nodes can continue to synchronize with each other. When the disconnected node comes back on, it will synchronize with the other partners. If the node is disconnected, due to a failed Wide-Area Network (WAN) link for example, local users could access this node and do work, and when the WAN link comes back, the changes the users made when the node was disconnected from the WAN will be replicated to all other nodes. Peer-to-peer replication, like bidirectional transactional replication, does not require any schema changes. Peer-to-peer replication is only available in the Enterprise Editions of SQL Server 2005 and 2008.
Peer to Peer Transactional Replication— Peer-to-peer transactional replication is bidirectional replication extended to many more Publisher/Subscriber pairs called nodes. The limit is 10 nodes; however, this depends on available network bandwidth and workload. Peer-to-peer replication is popular because a node can drop off (for maintenance, or if the link goes down) and the other nodes can continue to synchronize with each other. When the disconnected node comes back on, it will synchronize with the other partners. If the node is disconnected, due to a failed Wide-Area Network (WAN) link for example, local users could access this node and do work, and when the WAN link comes back, the changes the users made when the node was disconnected from the WAN will be replicated to all other nodes. Peer-to-peer replication, like bidirectional transactional replication, does not require any schema changes. Peer-to-peer replication is only available in the Enterprise Editions of SQL Server 2005 and 2008.
![]() Merge Replication— Whereas all other bidirectional replication solutions are limited by the number of subscribers, merge replication is highly scalable. It has rich conflict detection and resolution features. Merge replication does tend to be slower than the other bidirectional replication options, but it is designed for low-bandwidth links. For example, it is an excellent fit where you have to replicate over phone lines. Merge replication is the only replication type that can be used with PDAs or handhelds running SQL Compact Edition.
Merge Replication— Whereas all other bidirectional replication solutions are limited by the number of subscribers, merge replication is highly scalable. It has rich conflict detection and resolution features. Merge replication does tend to be slower than the other bidirectional replication options, but it is designed for low-bandwidth links. For example, it is an excellent fit where you have to replicate over phone lines. Merge replication is the only replication type that can be used with PDAs or handhelds running SQL Compact Edition.
So which replication type should you use? If the bulk of your data changes infrequently but at regular intervals, and you need one-way replication, use snapshot replication. If your data changes continuously, use transactional replication. If you need near-real-time bidirectional replication and have 2 to 3 subscribers and have partitioned your data to minimize conflicts, use bidirectional transactional replication. If you need near-real-time bidirectional replication and have between 2 and 10 subscribers, are running Enterprise Edition, and have partitioned your data to minimize conflicts, use peer-to-peer replication. If you need bidirectional replication, have a large number of subscribers, and need rich conflict detection and resolution, use merge replication. Use Oracle Publishing if you are publishing from an Oracle RDBMs and your SQL Server is the Enterprise Edition.
Replication uses agents to detect changes and migrate them to the Subscriber and Publishers. These agents are executables that you can find in C:Program FilesMicrosoft SQL Server100Com, and they function as described in the following list:
![]() Log Reader Agent— This agent is used by transactional replication. Changes that occur to published articles are written to the transaction log. The Log Reader Agent reads these changes, constructs replication commands, and writes these commands to the distribution database, and also writes a marker in the distribution database indicating the last part of the log it read. The transaction log can be truncated to the last-read command. The distribution database is a repository on the Distributor that stores replication commands (for transactional replication only) and history and metadata for all replication types. The Log Reader Agent then writes a marker in the transaction log stating that it has read these changes out of the transaction log. This way, if the Log Reader Agent fails, it will retrieve the record from the distribution database indicating the last command read from the log and then start reading from this point on.
Log Reader Agent— This agent is used by transactional replication. Changes that occur to published articles are written to the transaction log. The Log Reader Agent reads these changes, constructs replication commands, and writes these commands to the distribution database, and also writes a marker in the distribution database indicating the last part of the log it read. The transaction log can be truncated to the last-read command. The distribution database is a repository on the Distributor that stores replication commands (for transactional replication only) and history and metadata for all replication types. The Log Reader Agent then writes a marker in the transaction log stating that it has read these changes out of the transaction log. This way, if the Log Reader Agent fails, it will retrieve the record from the distribution database indicating the last command read from the log and then start reading from this point on.
![]() Snapshot Agent— The Snapshot Agent is used by all replication types to create a base image of the published articles and all replication data necessary for the replication processes, for example, replication stored procedures, tracking and conflict tables, and tracking triggers.
Snapshot Agent— The Snapshot Agent is used by all replication types to create a base image of the published articles and all replication data necessary for the replication processes, for example, replication stored procedures, tracking and conflict tables, and tracking triggers.
![]() Queue Reader Agent— This agent is used in queued replication. Queued replication uses tracking triggers to capture changes that originate by user activity on the Subscriber database and writes them to a queue. The queue reader reads this queue and writes the changes in the publication database.
Queue Reader Agent— This agent is used in queued replication. Queued replication uses tracking triggers to capture changes that originate by user activity on the Subscriber database and writes them to a queue. The queue reader reads this queue and writes the changes in the publication database.
![]() Distribution Agent— The Distribution Agent reads the changes that the Log Reader has written to the distribution database and writes them to the Subscriber. It places a marker in the Subscriber database indicating the last transaction applied there, and also on the distribution database. This way, if the distribution agent fails, the next time it runs it will determine what the last command applied on the Subscriber was and pick up where it left off.
Distribution Agent— The Distribution Agent reads the changes that the Log Reader has written to the distribution database and writes them to the Subscriber. It places a marker in the Subscriber database indicating the last transaction applied there, and also on the distribution database. This way, if the distribution agent fails, the next time it runs it will determine what the last command applied on the Subscriber was and pick up where it left off.
![]() Merge Agent— The Merge Agent connects to Subscriber and Publisher and determines the last time both synchronized. It then will determine what changes occurred on both sides since the last time it synchronized. It then processes all deletes at one time, and then processes all inserts and updates. While processing these changes, it determines whether any of the changes have occurred on the same row, or if you are using column-level tracking, it determines whether any of the changes have occurred on the same row and column. If so, the Merge Agent invokes the conflict detection mechanism specified for the article to which the row belongs. The Merge Agent also will write tracking metadata so that if the agent is interrupted, it will be able to pick up where it left off the next time the Publisher and Subscriber synchronize.
Merge Agent— The Merge Agent connects to Subscriber and Publisher and determines the last time both synchronized. It then will determine what changes occurred on both sides since the last time it synchronized. It then processes all deletes at one time, and then processes all inserts and updates. While processing these changes, it determines whether any of the changes have occurred on the same row, or if you are using column-level tracking, it determines whether any of the changes have occurred on the same row and column. If so, the Merge Agent invokes the conflict detection mechanism specified for the article to which the row belongs. The Merge Agent also will write tracking metadata so that if the agent is interrupted, it will be able to pick up where it left off the next time the Publisher and Subscriber synchronize.
![]() Replication Monitor— The central point for monitoring publishers and subscribers. You can administer most agents in Replication Monitor; however you cannot modify the publishers, publications, subscribers, or subscriptions here. To access Replication Monitor, connect to your Publisher in SQL Server Management Studio and right click on the Replication Folder and select Launch Replication Monitor.
Replication Monitor— The central point for monitoring publishers and subscribers. You can administer most agents in Replication Monitor; however you cannot modify the publishers, publications, subscribers, or subscriptions here. To access Replication Monitor, connect to your Publisher in SQL Server Management Studio and right click on the Replication Folder and select Launch Replication Monitor.
![]() Conflict Viewer— The Conflict Viewer allows you to see conflicts that have occurred in merge replication of one of the updatable subscriber variants of snapshot and transactional replication. The Conflict Viewer also lets you roll back and forth between conflicts if you are using merge replication. To use the Conflict Viewer, connect to your Publisher in SQL Server Management Studio, expand the Replication folder, expand the Local Publishers folder, right-click on your publication, and select View Conflicts.
Conflict Viewer— The Conflict Viewer allows you to see conflicts that have occurred in merge replication of one of the updatable subscriber variants of snapshot and transactional replication. The Conflict Viewer also lets you roll back and forth between conflicts if you are using merge replication. To use the Conflict Viewer, connect to your Publisher in SQL Server Management Studio, expand the Replication folder, expand the Local Publishers folder, right-click on your publication, and select View Conflicts.
![]() Profiles— Profiles are groups of settings that you can configure for your agents to use. For example, if your link between your Publisher and Subscriber is unstable, you can select the Slow Link Profiler for your Merge Agent. To select a profile, you need to launch Replication Monitor by right-clicking on the Replication folder, and selecting Launch Replication Monitor. Add your Publisher if it is not already added, by selecting Add Publisher. Expand the Publisher and in the right-hand pane, click on the Subscriber. Then right-click on the Subscriber and select Agent Profile. By default the Default Agent Profile will be selected. At this point choose another Profile, or click the New button to create your own.
Profiles— Profiles are groups of settings that you can configure for your agents to use. For example, if your link between your Publisher and Subscriber is unstable, you can select the Slow Link Profiler for your Merge Agent. To select a profile, you need to launch Replication Monitor by right-clicking on the Replication folder, and selecting Launch Replication Monitor. Add your Publisher if it is not already added, by selecting Add Publisher. Expand the Publisher and in the right-hand pane, click on the Subscriber. Then right-click on the Subscriber and select Agent Profile. By default the Default Agent Profile will be selected. At this point choose another Profile, or click the New button to create your own.
There are basically five types of replication topologies:
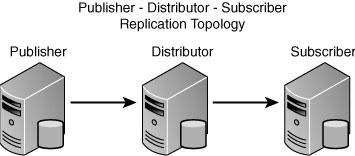
1. Publisher-Distributor-Subscriber— This is the most common replication topology and can be used by all replication types. This replication topology is illustrated in Figure 15.1. The publication originates at the Publisher, and the schema, its data, and related metadata are replicated to the Subscriber(s). Depending on your replication topology, data moves from the Publisher to the Subscriber (transactional and snapshot), and for all other replication types it moves both ways.
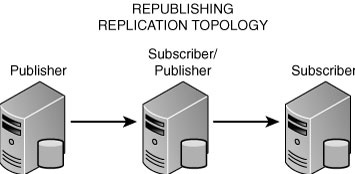
2. Republishing— Here a Publisher replicates to the Subscriber, which in turn publishes its schema, data, and related metadata to the downstream subscriber. The schema, data, and related metadata originate on the upstream Publisher. Data moves from the main Publisher downstream to the Subscriber for transactional and snapshot replication. For all other replication types it can move both ways. This replication topology is illustrated in Figure 15.2.
3. Central Publisher— In this replication topology, a central Publisher publishes to multiple subscribers. In some cases the subscribers may only get a subset of the data. This replication topology is illustrated in Figure 15.3.
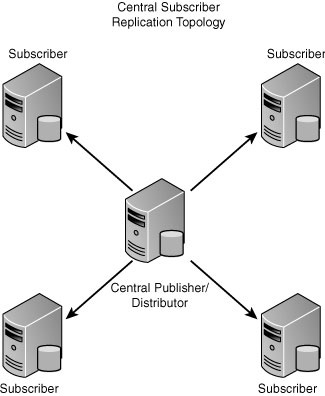
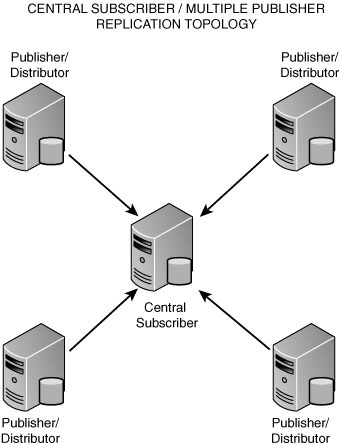
4. Central Subscriber— In this topology, multiple publishers replicate to the same Subscriber. This replication topology is illustrated in Figure 15.4.
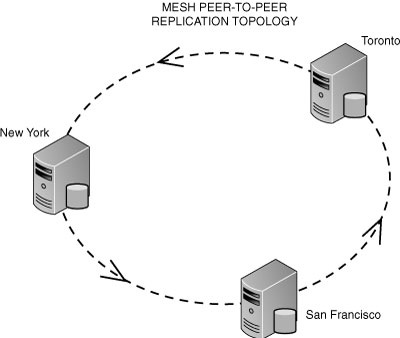
5. Mesh— This topology is used in peer-to-peer replication. The path taken by data from one Subscriber to another is unpredictable, and one node can drop off the replication topology and return with no interruption to the other nodes in the mesh. This replication topology is illustrated in Figure 15.5.
Configuring replication is not as simple as clicking through a few screens of a SQL Server installation wizard. A number of prerequisite steps must be fulfilled before replication can be configured and implemented.
Before you install SQL Server replication, ensure that the following prerequisites are met or understood:
1. All merge replication types require the installation of a local or remote distributor.
2. A snapshot folder must be accessible by all the agents and be large enough to store all the snapshot files for the publications.
3. Transactional replication requires primary keys on every table you replicate.
4. You cannot have a table published in an immediate-updating publication and merge replication.
5. You need to have a network connection between the Publisher and the Subscriber. This link does not need to be always connected for most replication types.
6. You need to have at minimum an account that is in the dbo role on the Subscriber for push replication, and an account that is in the dbo role on the Distributor and in the PAL in the publication.
7. If you are using web synchronization, you will need a certificate issued by a certificate authority (CA) from a trusted 3rd party like VeriSign or an internal certificate server, and have your IIS Server configured to use this certificate for SSL.
To initialize a subscription from a backup in SQL Server 2008, a user must be a member of the dbcreator server role. In SQL Server 2005, membership in the db_owner database role was sufficient.
There are several SQL Server edition–specific limitations to replication. SQL Server Express 2008 can only be used as a Subscriber. SQL Server 2008 Workgroup Edition can only have 5 Subscribers. SQL Server 2008 Standard Edition can have 25 Subscribers.
An organization can have many reasons for its implementation of SQL Server replication. Following are some of the situations organizations try to address by using SQL Server 2008 replication:
![]() Distributing data— This involves distributing data from one database to another database or one server to another server. For example, an organization must make data such as pricing or sales data residing at corporate headquarters readily available to all field offices.
Distributing data— This involves distributing data from one database to another database or one server to another server. For example, an organization must make data such as pricing or sales data residing at corporate headquarters readily available to all field offices.
![]() Consolidating data— An organization may be interested in consolidating data from many servers to one server for centralized reporting, analysis, or business intelligence. Examples include consolidating data from field offices, manufacturing facilities, or data residing in PDAs or mobile devices to a centralized SQL Server.
Consolidating data— An organization may be interested in consolidating data from many servers to one server for centralized reporting, analysis, or business intelligence. Examples include consolidating data from field offices, manufacturing facilities, or data residing in PDAs or mobile devices to a centralized SQL Server.
![]() Ensuring high availability— Replication is one of four SQL Server 2008 high-availability alternatives. It can be used to maintain redundant copies of a database on multiple servers residing in different locations. Peer-to-peer transaction replication was introduced in SQL Server 2005 and is discussed later in this chapter. When replication is used for high availability, it does not provide automatic failover or automatic client redirect as failover clustering or database mirroring does.
Ensuring high availability— Replication is one of four SQL Server 2008 high-availability alternatives. It can be used to maintain redundant copies of a database on multiple servers residing in different locations. Peer-to-peer transaction replication was introduced in SQL Server 2005 and is discussed later in this chapter. When replication is used for high availability, it does not provide automatic failover or automatic client redirect as failover clustering or database mirroring does.
![]() Reporting— If you want to minimize performance degradation on production databases/servers, it is advantageous to offload reporting from production database servers to dedicated reporting servers. Although there are a number of ways of achieving this goal, transactional replication provides a means of replicating data to one or more reporting servers with minimal overhead on the production database. Unlike with database mirroring, the reporting database can be accessed for reporting purposes in real time without the need for creating database snapshots.
Reporting— If you want to minimize performance degradation on production databases/servers, it is advantageous to offload reporting from production database servers to dedicated reporting servers. Although there are a number of ways of achieving this goal, transactional replication provides a means of replicating data to one or more reporting servers with minimal overhead on the production database. Unlike with database mirroring, the reporting database can be accessed for reporting purposes in real time without the need for creating database snapshots.
![]() Distributing or consolidating database subsets— Unlike other high-availability alternatives or data distribution methods such as log shipping or database mirroring, replication offers a means to copy or replicate only a subset of the database if needed. For example, you can choose to replicate only a table, rows based on a filter, specific columns, or stored procedures.
Distributing or consolidating database subsets— Unlike other high-availability alternatives or data distribution methods such as log shipping or database mirroring, replication offers a means to copy or replicate only a subset of the database if needed. For example, you can choose to replicate only a table, rows based on a filter, specific columns, or stored procedures.
![]() Ensuring scalability— The goal is to scale the workload across multiple databases with replication. This provides increased performance and availability.
Ensuring scalability— The goal is to scale the workload across multiple databases with replication. This provides increased performance and availability.
Replication is essentially copying or distributing data from one location to another. However, there are other technologies you can also use to accomplish this.
![]() SSIS— SQL Server Integration Services (SSIS) does rich ETL (Extract Transform and Load); however, it does not easily track changes. SSIS is best for moving copying data from heterogeneous data sources. Transactional replication can be used to transform data but it is an involved task. Look up “Custom Sync Objects” in Books Online for more information on how to do this.
SSIS— SQL Server Integration Services (SSIS) does rich ETL (Extract Transform and Load); however, it does not easily track changes. SSIS is best for moving copying data from heterogeneous data sources. Transactional replication can be used to transform data but it is an involved task. Look up “Custom Sync Objects” in Books Online for more information on how to do this.
![]() BCP— Bulk Copy Program (BCP) is used to copy data out of the file system and into another SQL Server. It does not track changes easily, but you can use it for high-performance data loads, which can perform much better than the other data load methods.
BCP— Bulk Copy Program (BCP) is used to copy data out of the file system and into another SQL Server. It does not track changes easily, but you can use it for high-performance data loads, which can perform much better than the other data load methods.
![]() Triggers— Triggers can be used to replicate or transform data; however, they add latency to each transaction, do not scale well over a network, and there is an administrative burden with this method.
Triggers— Triggers can be used to replicate or transform data; however, they add latency to each transaction, do not scale well over a network, and there is an administrative burden with this method.
![]() Two-phase commit— This technology involves writing to the source table and then writing to the destination table within a transaction. There is considerable latency associated with this; however, for some applications that have very high consistency requirements, two-phase commits are necessary.
Two-phase commit— This technology involves writing to the source table and then writing to the destination table within a transaction. There is considerable latency associated with this; however, for some applications that have very high consistency requirements, two-phase commits are necessary.
![]() Backup and Restore— Backup and restore can be used to replicate data; however, the source database is offline during the restore operation, and for large databases this can be unwieldy.
Backup and Restore— Backup and restore can be used to replicate data; however, the source database is offline during the restore operation, and for large databases this can be unwieldy.
![]() Log shipping— Log shipping is continuous backup and restore. The destination database is offline while the log is being applied. Microsoft does not require you to maintain a SQL Server license for the standby server as it is only fulfilling a standby role.
Log shipping— Log shipping is continuous backup and restore. The destination database is offline while the log is being applied. Microsoft does not require you to maintain a SQL Server license for the standby server as it is only fulfilling a standby role.
![]() Database mirroring— This can be considered to be contiguous log shipping. The destination database (called a mirror) is offline when participating in database mirroring. Database mirroring has two modes: high performance and high safety. With high performance some data loss is possible, but performance is better than with high safety. With high safety there will be no data loss. Microsoft does not require you to maintain a SQL Server license for the mirror server as it is only fulfilling a mirroring role. Database mirroring is the only technology that does client redirects on failover. So if clients are connected to your source server (called a principal), they will be automatically failed over to the mirror server when the principal goes down. Mirroring is most practical in high-performance mode, which is only available in Enterprise Edition. Note that Database Mirroring does not support FILESTREAM, whereas replication does.
Database mirroring— This can be considered to be contiguous log shipping. The destination database (called a mirror) is offline when participating in database mirroring. Database mirroring has two modes: high performance and high safety. With high performance some data loss is possible, but performance is better than with high safety. With high safety there will be no data loss. Microsoft does not require you to maintain a SQL Server license for the mirror server as it is only fulfilling a mirroring role. Database mirroring is the only technology that does client redirects on failover. So if clients are connected to your source server (called a principal), they will be automatically failed over to the mirror server when the principal goes down. Mirroring is most practical in high-performance mode, which is only available in Enterprise Edition. Note that Database Mirroring does not support FILESTREAM, whereas replication does.
For high-availability and disaster-recovery scenarios, database mirroring, log shipping, and in some cases backup and restore are a much better fit than replication, mainly due to the unpredictable latencies that replication offers and the lack of automatic and client failover. SSIS and BCP work best if there is some form of change tracking. Triggers are seldom a good solution. Two-phase commit fits best when your source and destination must be identical at all times. In all other scenarios, replication is a much better fit for copying data.
Frequently, high-availability and disaster-recovery plans require a combination of technologies. For example, you may require implementing database mirroring in conjunction with replication. Such a topology would keep the Publisher operational and redirect the clients to the mirror. Although clustering can achieve the same result, clustering has distance limitations, which mirroring can overcome. This section examines caveats associated with both technologies.
You can mirror a published database or a subscriber database. The complications occur at failover.
If your publication database is mirrored and you are using a remote distributor, you can configure your log reader, distribution, queue reader, and merge agents to fail over to the mirror and pick up where they left off by configuring the PublisherFailoverParameter parameter with the mirror name in the agents. This ensures that if the principal is failed over to the mirror, the Log Reader, Snapshot, or Merge Agent will continue to work. You will need to enable trace flag 1448, and you may need to issue a sp_replrestart in your publication database to get the log reader to work again.
If your Subscriber is mirrored and you need to fail over to the mirror, you will need to configure the Distribution Agent for the new Subscriber (the former mirrored database). You will then need to configure the Subscriber. To do this you will need to clean up the old subscription in the principal database (use sp_subscription_cleanup), and then obtain the last Log Sequence Number (LSN) from the distribution database on the Distributor. You will need to query the transaction_timestamp value from MSReplication_Subscriptions. Then add your subscription using the sp_addsubscription stored procedure and the subscriptionlsn parameter. The value you supply for the subscriptionlsn will be the value obtained in the transaction_timestamp column. After you have done this, your distribution database and new principal will be in sync, and you can start mirroring to the old principal.
Replication is a good fit with database mirroring as database mirroring is the only high-availability (HA) option that provides real-time synchronization with no data loss (in the high-safety mode). When replication is used with mirroring, the Publisher’s availability will be maximized.
If you have a remote distributor, you can configure the PublisherFailoverPartner parameter on the Log Reader Agent on your primary (the source database in your log shipping topology) with the name of your secondary (the destination database in your log-shipping topology). The PublisherFailoverPartner should be the secondary server name. On failover the Publisher will start to replicate to the remote distributor. Please refer to the section in Books Online titled “Strategies for Backing Up and Restoring Snapshot and Transactional Replication.”
Clustering is replication aware. You can create any type of publication on a clustered server. The only complication is that your snapshot folder must be on a clustered shared disk resource. If your snapshot folder is not shared, the active node may not be able to access the snapshot folder. This will only be a problem during snapshot generation and deployment.
There are four parts involved in administering SQL Server Replication:
![]() Creating the Distributor
Creating the Distributor
![]() Creating publications
Creating publications
![]() Creating subscriptions
Creating subscriptions
![]() Administering and monitoring the publications and subscriptions
Administering and monitoring the publications and subscriptions
This section will cover each part in turn.
For large workloads in a transactional replication topology, you should use a remote distributor on a clustered server. For merge replication, placement of the distribution database is not critical. Smaller transactional replication workloads can tolerate a local distributor without too much locking. If considerable locking occurs between Log Reader Agents and Distribution Agents, consider moving to a remote distributor. Locking occurs when two processes try to access the same resource (a table, index, page of a table, or index) simultaneously. A remote distributor is a SQL Server that hosts the distribution database, and is neither the Publisher or a Subscriber.
The topic of how to create a local distributor has already been briefly discussed in the “SQL Server 2008 Replication Roles” section. A remote distributor is essentially a server that is configured with a distributor database (in other words, is a Distributor), and then has remote publishers publishing to it.
There are three steps for configuring a remote distributor.
1. Configuring a Distributor.
2. Enabling the Distributor for remote publishers. This step must be performed on your distributor.
3. Enabling your publishers to use the remote distributor. This step must be performed on your Publisher.
To create a remote distributor, you would follow the guidelines on how to create a local distributor in the “SQL Server 2008 Replication Roles” section.
After you have configured the Distributor, you need to configure which publishers you want to publish to.
1. In SQL Server Management Studio, right-click on the Replication folder on the remote distributor, select Distributor Properties, and click on the Publishers page.
2. Click Add, select Add SQL Server Publisher, connect to the Publisher in SQL Server Management Studio, click Remote Publisher Warning, and click OK.
3. Right-click on the Replication folder and select Configure Distribution. Click Next at the splash screen and select the Publishers tab.
4. Click the Add button and select Add SQL Server, enter the name of the server you want to add as a Publisher to use the remote distributor, and select an authentication mechanism. Click Connect.
You will get a message telling you “Remote Publishers must use a password when automatically connecting to the Distributor to perform replication administrator operations. You must specify the administrative link password for this Distributor.”
The message is telling you that when you configure the Publisher to use this remote distributor, you must supply a password. You can configure the administrative link password in the Administrative Link Password text boxes displayed in Figure 15.6. Click OK to complete the operation.
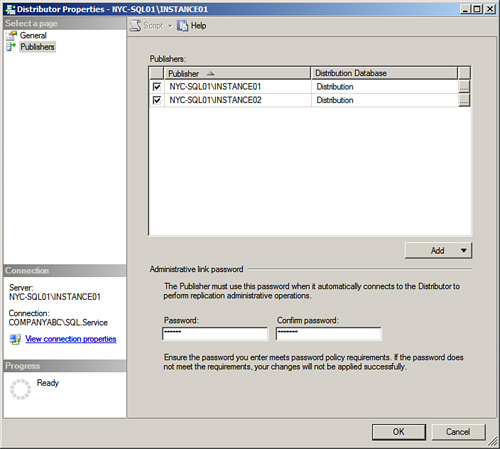
Notice that in Figure 15.6, the Publisher NYC-SQL01Instance01 uses the distribution database called Distribution. It is recommended that you use different distribution databases for each remote distributor to minimize contention.
1. In SQL Server Management Studio, connect to the SQL Server.
2. Right-click on the Replication folder, and click on Configure Distribution.
3. Click Next at the splash screen.
4. Select [Your Server Name] Will Act as Its Own Distributor. SQL Server will create a new distribution database and log. Click Next.
5. Accept the default for the snapshot folder, or locate it on a drive with ample room for your snapshots. During snapshot generation, there will be significant I/O activity; otherwise, there will be little. Click Next.
6. Accept the default for the distribution database name and folders. Click Next.
7. In the Publishers dialog, ensure that your server is enabled, and that your distribution database is selected. Click Next.
8. In the Wizard Actions dialog, ensure that Configure Distribution is selected.
9. Click Finish to create your distribution database and to configure this server as a Distributor, and click Close.
This will configure the Distributor for your Publisher.
You must now connect to the Publisher in SQL Server Management Studio, right-click on the Replication folder, select Configure Distribution, click Next, and then select the Use the Following Server as the Distributor option. Then click Add and in the connection dialog, enter the server name of your Distributor (for this example, NYC-SQL01Instance01) and select the correct authentication mechanism. You will then be prompted for the Administrative Link Password as illustrated in Figure 15.7.
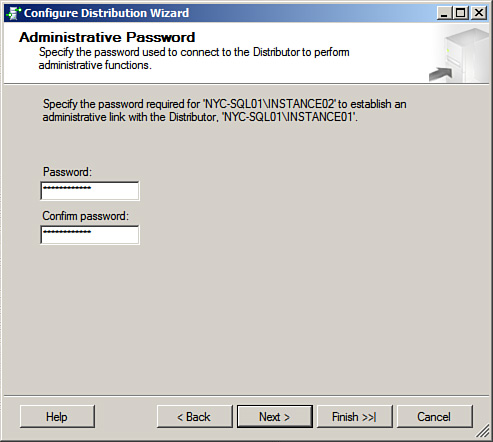
After you have entered the password, click Next, Next, Finish, and Close. Your Publisher is now configured to use your remote distributor.
The steps to create all replication types are very similar. We will create a Transactional Publication first as its setup is highly similar to that of a Snapshot publication. Along the way we will note the differences.
1. To create a publication, connect to your Publisher in SQL Server Management Studio (NYC-SQL01Instance02), expand the Replication folder, right-click on Local Publications, and select New Publication.
2. Click Next at the splash screen. If you get a dialog titled Distributor, follow the steps in the “SQL Server 2008 Replication Roles” section. In the Publication Database dialog box, select the AdventureWorks 2008 database.
3. In the Publication Types dialog, select Transactional Replication.
Note
Snapshot replication with Immediate Updating, Queued Updating, or Immediate Updating with Queued Failover is only available using replication stored procedures, which is beyond the scope of this chapter. Microsoft has deprecated updateable subscriptions in favor of using peer-to-peer replication. However Peer-to-peer replication is available only with the Enterprise Editions of SQL 2005 and SQL 2008.
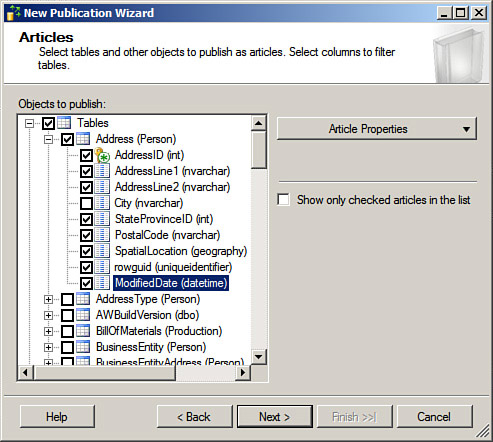
4. After you have selected the replication type, click Next. You will then see the Articles dialog box. This allows you to select the tables, stored procedures, user-defined functions, views, and indexed views you will be able to replicate. Select the objects you want to replicate. This option is illustrated in Figure 15.8.
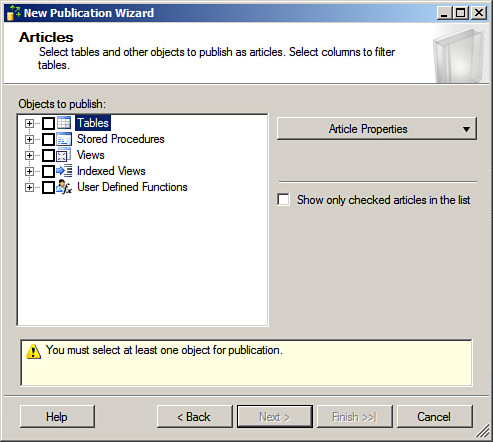
In general, you will want to replicate all objects to support the requirements of the applications using the subscriber database. This can be all tables or a subset of them.
You can expand each object type, for example the tables object, to select individual tables, or check the check box to the left of the table icon to replicate all tables. In the Article Properties dialog box, you can select properties of the articles you want to replicate, for example, the choice to replicate nonclustered indexes, or to replicate a table to a table with a different name or schema owner.
There are some differences in some of the Article Properties dialog settings between snapshot and transactional replication. For example, in transactional replication there is the Statement Delivery option, which allows you to determine how incremental changes will be applied on the Subscriber. This section does not appear in the snapshot publication creation dialogs. Statement Delivery refers to whether replication will use stored procedures or SQL statements to keep the two databases synchronized.
You also have the option to select which columns you want to replicate. Expand the Tables node, and then expand the individual table you want to vertically partition (only replicate some of the columns). Figure 15.9 illustrates vertically partitioning the Address table to not replicate the City column. (We are choosing not to replicate the City column purely for illustrative puposes.)
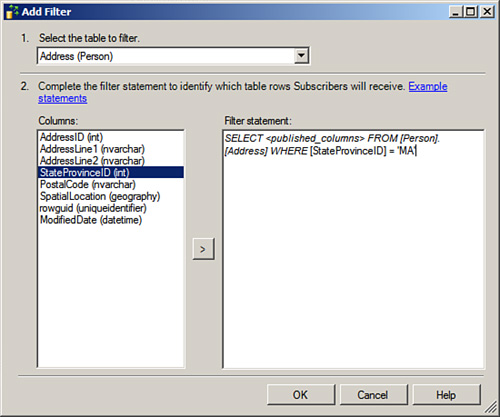
5. Click Next to launch the Filter Rows dialog illustrated in Figure 15.10. In Figure 15.10 we are now horizontally partitioning the Address table by only sending the rows with a StateProvinceID of 30 (Massachusetts) to the subscribers.
6. Click OK to complete the Filter Rows dialog.
7. Click Next to continue. In the Snapshot Agent dialog, select Create the Snapshot Immediately and Keep the Snapshot Available to Initialize Subscriptions.
8. Click Next to continue advancing to the Agent Security dialog box. This allows you to select the account or authentication mechanism to use by the publication. Leave the User Security Settings from the Snapshot Agent check box selected, and click the Security Settings button beside the Snapshot Agent. The Snapshot Agent Security dialog box will appear as illustrated in Figure 15.11.
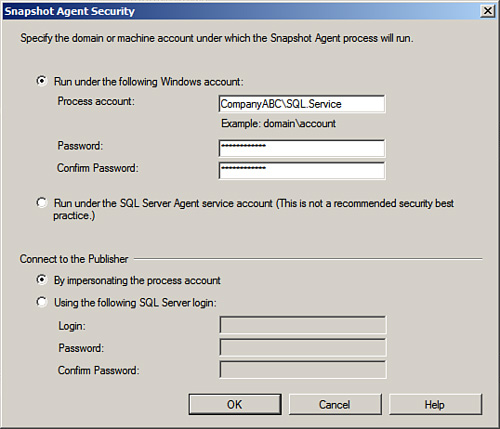
Note that for snapshot publications, this option will not appear as there is no Log Reader Agent.
You have two choices here for the security context that the Snapshot Agent will run under: The SQL Server Agent account’s security context, or the context of a low-privilege Windows account. Microsoft has the following recommendations for the security context under which your agent will run:
![]() Run each replication agent under a different Windows account, and use Windows Authentication for all replication agent connections.
Run each replication agent under a different Windows account, and use Windows Authentication for all replication agent connections.
![]() Grant only the required permissions to each agent.
Grant only the required permissions to each agent.
![]() Ensure that all Merge Agent and Distribution Agent accounts are in the publication access list (PAL).
Ensure that all Merge Agent and Distribution Agent accounts are in the publication access list (PAL).
![]() Follow the principle of least privilege by allowing accounts in the PAL only the permissions they need to perform replication tasks. Do not add the logins to any fixed server roles that are not required for replication.
Follow the principle of least privilege by allowing accounts in the PAL only the permissions they need to perform replication tasks. Do not add the logins to any fixed server roles that are not required for replication.
![]() Configure the snapshot share to allow read access by all Merge Agents and Distribution Agents. In the case of snapshots for publications with parameterized filters, ensure that each folder is configured to allow access only to the appropriate Merge Agent accounts.
Configure the snapshot share to allow read access by all Merge Agents and Distribution Agents. In the case of snapshots for publications with parameterized filters, ensure that each folder is configured to allow access only to the appropriate Merge Agent accounts.
![]() Configure the snapshot share to allow write access by the Snapshot Agent.
Configure the snapshot share to allow write access by the Snapshot Agent.
![]() If you use pull subscriptions, use a network share rather than a local path for the snapshot folder.
If you use pull subscriptions, use a network share rather than a local path for the snapshot folder.
If you do not select the SQL Server Agent accounts security context, ensure that the Windows account you chose has rights to read and list files and folders on the snapshot folder, or snapshot share. Microsoft recommends you do not use the SQL Server Agent account as it tends to run under an Administrator account, and if an exploit hijacks it, the exploit will have Administrator rights on your machine and possibly your domain. The Connect to Publisher dialog allows you to select how you want the Snapshot Agent executable to connect to the Publisher. You can use the account you specify the Snapshot Agent to run under, or a SQL login.
9. When you have finished configuring the Snapshot Agent Security, click OK, Next, and then Next (to create the publication).
10. In the Complete the Publication dialog, give your publication a meaningful name. In this case we will call it AdventureWorks. Click Finish. The wizard will then create your publication. Click Close to close the dialog. You are now ready to create your subscriptions.
Follow these steps to create your subscription:
1. In SQL Server Management Studio, connect to the Publisher, and expand the Replication folder.
2. Expand the Local Publications folder, locate your publication, right-click on it, and select New Subscriptions.
3. Click Next at the New Subscription Wizard splash screen. Select your publication (it should be highlighted—if not, you may need to expand the publication database to find it).
4. Click Next; this will launch the Distribution Agent Location. There are two choices:
![]() Run all of the Agents at the Distributor (push subscriptions). Use this option when you have a small number of subscribers or are replicating to a non–SQL Server RDBMs.
Run all of the Agents at the Distributor (push subscriptions). Use this option when you have a small number of subscribers or are replicating to a non–SQL Server RDBMs.
![]() Run each agent at the Subscriber (pull subscriptions). Use this option when you have a large number of subscribers.
Run each agent at the Subscriber (pull subscriptions). Use this option when you have a large number of subscribers.
Choose the option to run the agent at the Distributor.
5. Click Next to launch the Subscribers dialog. Click on the Subscriber if it appears in this dialog. If not, click the Add Subscriber button at the bottom (for push subscriptions) or the Add SQL Server Subscriber button (for pull subscriptions). You will need to connect to the Subscriber using Windows Authentication or a SQL Server login.
6. Click Connect and the Subscription database drop-down list will be populated. Select the subscription database here if it already exists—note that there is an option to create a new database on the Subscriber.
7. Click Next. You will then get the Distribution Agent Security dialog box. Click on the ellipsis button to set the accounts you want to use to connect to the Distributor and Subscriber. For the process login, enter a low-privilege Windows account that is in the dbo role on the Distributor. Note that if the Distributor is in an untrusted domain, you can use pass-through authentication, where the account has the same name and password and is a local machine or domain account on both the Distributor and the Subscriber. For the Connect to Subscriber dialog, either select to impersonate the process account (the SQL Server Agent account on the Distributor for push, or the SQL Server Agent account on the Subscriber for pull). You can select a SQL login here as well. This will use the security context of the SQL Server Agent account on the Subscriber to read the snapshot share.
8. After you have configured all of the accounts, click OK and then Next to launch the Synchronization Schedule. This will allow you to set a schedule for the Distribution Agent, have it run on demand, or have it run continuously.
9. Click Next to launch the Initialize Subscriptions dialog box. Notice the Initialize check box, which by default will be selected. This will create and distribute the snapshot to the Subscriber. This will be the metadata, replication objects, schema, and data that the Subscriber needs to be synchronized with the Publisher.
It is possible for you to configure the Subscriber for replication yourself by using a backup or by putting the schema and data in the Subscriber yourself. You will likely need to put the replication stored procedures in place: Use the stored procedure sp_scriptpublicationcustomprocs 'PublicationName' in your publication database to generate these stored procedures, and then copy and paste them into a query window on your Subscriber and execute them. You also have the option of selecting whether the snapshot should be generated immediately, or at first synchronization. If you select the Immediately option, the Snapshot Agent will be run after your publication is created. If you select At First Synchronization, it will be generated when the Distribution Agent first connects with the Subscriber. Click Next for the option to create the subscription now or to script it out, or both. Click Next and then Finish to complete the creation of your subscription.
To verify that your publication is replicating successfully, do the following:
1. In SQL Server Management Studio, connect to your Publisher.
2. Right-click the Replication folder, and select Launch Replication Monitor.
3. After Replication Monitor has launched, click on the Add Publisher hyperlink on the right-hand pane to monitor your Publisher.
4. When your Publisher has been added, expand it in the left-hand pane, so that your publication shows up. If there are any errors, your Publisher and publication will have a red circle with a white x on them.
5. After you have clicked on your publication, all subscriptions to that publication will be displayed in the right-hand pane. Click on the Publications and Agents tabs to see if there are any red circles with white x’s on them and observe any status messages that might be displayed.
Typical errors you will see are connection errors; for example, the Distribution Agent is unable to connect to the subscriber. To fix these errors, right-click on the agent with the error icon on it and select View Details. Read and evaluate the error message. Most errors can be solved by right-clicking on the publication and changing the publication’s properties, or in the case of a pull subscription, by right-clicking on the subscription and selecting Properties.
You can also run a validation to verify that your publication and subscription are consistent (that is, have the same data).
1. In SQL Server Management Studio, connect to your Publisher.
2. Right-click on your publication in SQL Server Management Studio and select Validate Subscriptions.
3. You will be offered a choice to validate all subscriptions or individual subscriptions. Make the appropriate choice and click the Validation Options button. The options are a fast row count based on cached information, an actual row count, or a fast row count and if differences are noted, an actual row count is done. You also have the option to perform a checksum and stop the Distribution Agent if a Subscriber fails validation. Click OK.
You can view the results on the validation in Replication Monitor in the Publications tab.
1. Launch Replication by right-clicking on your publication in the Replication folder for your SQL Server.
2. Drill down on the Publisher, and expand your publication.
3. Right-click on your subscription and select View Details.
4. Note the values in the Actions in the selected session—this appears as the lower half of the dialog.
If you are concerned with latency issues or want to verify that replication is working, click on the Tracer Tokens tab in Replication Monitor (you need to drill down on the Publisher, Publication, and Subscription and look in the right-hand pane of Replication Monitor to see this). Click on Insert Tracer and watch the tracer token being injected into the publication. Replication Monitor will track how long it takes for the tracer token to make its way from the Publisher to the Distributor and then from the Distributor to the Subscriber.
You’ll see the breakdown of the time it took the token to go from the Publisher to the Distributor, time from Distributor to Subscriber, and total latency. If latency is unacceptable, you may need to check network bandwidth, or attempt to optimize your replication topology performance. Optimizing your network link. is outside the scope of this book. Good values should be below a minute on a LAN (but can be as low as 2–4 seconds). WAN performance is highly variable and dependent on bandwidth and workloads. The tracer token can also be used to help determine the best QueryTimeout value. This can also be done by using TSQL.
Replication Monitor can also be used to view undistributed commands. If you view the details of a subscription, you can see how many commands are waiting to be distributed and an estimate of how long the distribution will take.
To configure peer-to-peer replication, you must first create a transactional publication. Follow the steps that you used previously in creating your transactional replication publication AdventureWorks for the AdventureWorks2008 database. Do not create a subscription. If you already have the subscription created, drop it by right-clicking on the AdventureWorks publication (you can find it in the Local Publications folder), selecting Delete, and selecting Yes at the confirmation prompt.
After the publication is created, follow these steps:
1. Right-click on the AdventureWorks publication in the Local Publications folder, and select Properties.
2. In the Subscription Options tab, change Allow Peer to Peer Subscriptions from False to True.
3. Click OK to close the dialog.
4. Right-click on your publication (the AdventureWorks one) again and select Configure Peer to Peer Topology.
5. Click Next at the splash screen, drill down on your publication database (AdventureWorks2008), select your AdventureWorks publication (it should already be highlighted), and click Next.
6. The Configure Topology dialog will display, as illustrated in Figure 15.12.
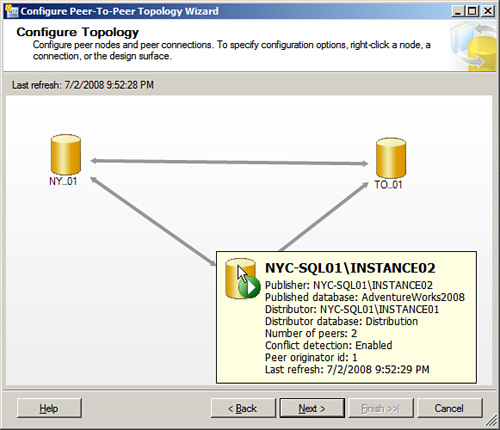
7. Right-click anywhere on the screen (except the database icon in the center) and select Add a New Peer node.
8. Enter the server name of a server that you want to participate in peer-to-peer replication, select the appropriate authentication mechanism, and click Next. In this case, pick NYC-SQL01.
9. You will then be prompted for a database and Peer Originator ID as illustrated in Figure 15.13.
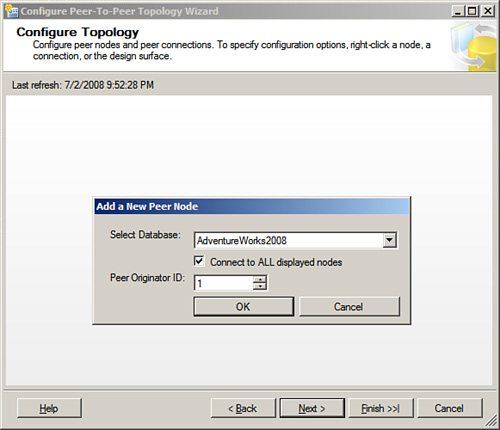
Let SQL Server auto-assign Peer Originator IDs. Click OK.
10. Right-click on the database icon in the center of the Configure Topology dialog box, and select Connect to All Displayed Nodes. Click Next.
11. The Log Agent Security dialog box, which is very similar to the Snapshot Agent Security dialog box, will display. Select an account that the Log Reader Agent should run under, and click Next.
12. You will then see a Distributor Security dialog box, which is very similar to the Snapshot Agent Security dialog box and the Log Reader Agent Security Dialog box. Select an account that the Distribution Agent should run under and how the Distribution Agent should connect to the Subscriber. You will need to do this for each node in the topology. Note that in this example we have only selected one node in our topology. We could have added multiple nodes at one time in the Configure Topology dialog and then selected Connect to All Displayed Nodes and Configure Security.
13. Click Next when you are done configuring security. This will launch the New Peer Initialization dialog as illustrated in Figure 15.14.
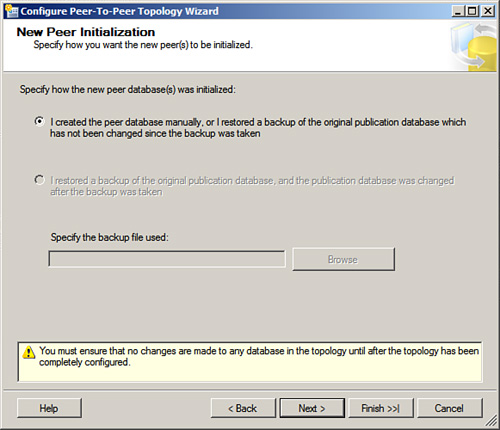
Either pre-create your subscriber databases by creating the tables and data, or restore them via a database backup. It is highly recommended that you restore the database from a backup as peer-to-peer replication can do conflict detection. Conflict detection is an optional feature, which is enabled by default.
14. Click Next and Finish to complete the Peer to Peer topology configuration.
If at any time you need to add a new node to your topology, right-click on one of the publications involved in peer to peer replication and select Configure Peer to Peer Topology. Then in the Configure Topology dialog box, right-click anywhere on the grey background and select Add a New Peer Node. Follow the dialogs as outlined in the preceding step sequences.
Creating merge publications is very similar to creating snapshot or transactional publications. Here are the steps to create a merge replication topology:
1. In SQL Server Management Studio, connect to the SQL Server that will be your Publisher.
2. Expand the Replication folder, right-click on Local Publications, and click Next through the splash screen titled New Publication Wizard.
3. Select the database that contains the tables and data you want to merge replicate in the Publication Databases dialog. In this case, select the AdventureWorks2008 database.
4. On the Publication Types splash screen, select Merge Publication and click Next to move to the Subscriber Types dialog.
5. Choose the appropriate Subscriber type. Be very careful with the selection you make here. If you choose SQL 2000 Subscribers, for example, all future merge publications you create in this database after this choice will be limited to that subscription type. It is possible to select multiple subscriber types, keeping in mind that the lowest subscriber type will limit all future subscriber types and some of the new merge replication features will be unavailable to you.
6. Click Next to Advance to the Articles dialog box. Here you can select which type of objects you want to replicate as well as individual articles. You also have the option of horizontally partitioning your tables by deselecting individual columns. The Article Properties button allows you to find grained control of article properties, for example, that you can select to replicate user triggers to your subscribers. Click Next. The wizard will then warn you that a unique identifier (GUID) column will be added to all tables you are indexing.
Note
This may cause unqualified inserts to fail. For example, the following command will fail if there is not also a unique identifier column on the table you are inserting into:
Insert into tableName
Select * from OtherTableName
To get around this problem you will have to list all the columns in the SELECT and INSERT statements.
7. Click Next to advance to the Filter Rows dialog box. Merge replication is designed with a low-bandwidth footprint. In other words, it is tuned to replicate over low-bandwidth lines like telephone lines. One of the features that minimizes network traffic is join filters. Basically a join filter is a filter you place on a table, and this filter can be extended to all other tables that join to the original table. Consider the SalesTerritory table in the AdventureWorks2008 database. It is joined to the SalesOrderHeader table by TerritoryID and the SalesOrderHeaderTable is joined to the SalesOrderDetail table by the SalesOrderID column.
Figure 15.15 illustrates this relationship. Consider what would happen if we were filtering on the Territory Name. Such a filter would ensure that only specific TerritoryIDs would go to specific Subscribers. The Territory names are Northwest, Northeast, Central, Southeast, Southwest, Canada, and so on. If you filter on Northwest, only sales that have a territory name of Northwest would go to the Northwest subscribers. The value of this is that the entire database would not have to go over the wire to the Northwest subscriber; only Northwest data would go there. Join filters ensure that all data related to the filter would also go to the Northwest subscriber—that is, all the orders (in the OrderHeader table) and order details from salespeople with a TerritoryName of Northwest.
And if, for example, there was consolidation of the Northwest into the Northeast and the Northwest Territory was now renamed Northeast, all of the sales orders that belonged to the Northwest would move to the Northeast subscriber. This is termed partition realignment and is normally a good thing. Join filters are what makes this happen; join filters will walk the relationships and ensure that all data that belongs to a filter will move with that filter. Without join filters, only the old Northeast row would move in the example, and none of the orders owned by the Northeast would move.
To use join filters, click the Add button in the Filter Table Rows dialog box and select Automatically Generate Filters (where SQL Server will walk the relationships in the tables you are publishing and automatically generate join filters), or click the Add Filter button and select the tables and rows you want to filter on. You then have the option of clicking the Add Button again and selecting Add Join to Extend the Selected Filter. You can also filter on Host_Name() and SUSER_NAME(), both of which can be overridden by the Merge Agent (HostName and PublisherLogin respectively).
8. Click Next to launch the Snapshot Agent dialog box; in most cases you will want to accept the default. Click Next to launch the Snapshot Security Agent dialog box and set the appropriate accounts for your Snapshot Agent.
9. Click Next to either generate your publication or script it out.
10. Click Next to name your publication and then click Finish. When your publication has been created, click Close.
Creating merge replication subscriptions is almost identical to creating subscriptions to transactional and snapshot publications. There are two differences. The first is that there is a Subscription type dialog box. This is illustrated in Figure 15.16.
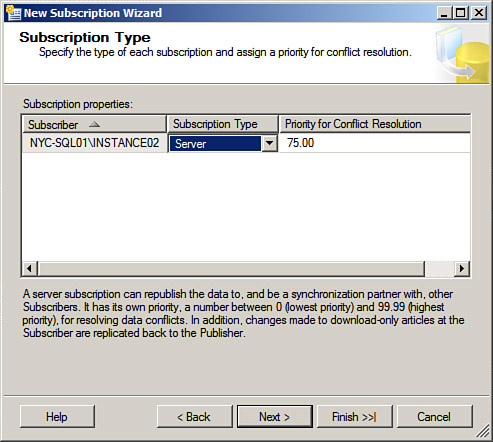
The Subscription Type dialog controls how conflicts “stick.” In this example we are using the Server-based subscription type with a priority of 75 percent. This means that a conflict caused by a Subscriber will have a priority of 75 percent. If the Publisher and this Subscriber conflict, the Publisher will win unless you use a different conflict resolver (you can set conflict resolvers in the Articles Properties dialog). If the Subscriber does win, its conflict has a priority of 75 percent. If other subscribers sync with a lower priority, the old value will win. If subscribers sync with a higher priority (90 percent, for example), the new value will win.
The other subscription type is Client, which means that the first value to the Publisher will stick and win any conflicts.
The other change is the Host_Name values, as illustrated in Figure 15.17.
If you are doing row filtering based on Host_name or PublisherLogin (SUser_Name), you can enter the value here to filter your subscription. This will ensure that your Subscriber only gets data that matches its filter, or data that is part of the extended join condition.
There are several options for the Distributor. Right-click on the Replication folder on your Distributor and select Distributor Properties. In the General tab click on the ellipsis button to the right of the distribution databases. There are several text boxes of interest here:
![]() Transaction Retention— Transaction Retention has two options:
Transaction Retention— Transaction Retention has two options:
![]() Store Transactions: At Least— This setting determines how long transactional replication commands remain in the distribution database after they are applied to all subscribers. In general, set this to 0, which means they are cleaned up the next time the distribution cleanup task runs. In some cases you will want to set this to higher values, normally when replication is involved in some disaster recovery scenario. Limit this setting as low as possible as it can cause performance degradation if set to high.
Store Transactions: At Least— This setting determines how long transactional replication commands remain in the distribution database after they are applied to all subscribers. In general, set this to 0, which means they are cleaned up the next time the distribution cleanup task runs. In some cases you will want to set this to higher values, normally when replication is involved in some disaster recovery scenario. Limit this setting as low as possible as it can cause performance degradation if set to high.
![]() Store Transactions: But Not More Than— This setting determines how long transactional replication commands can pool in the distribution database before the Subscriber expires. Again limit this setting as low as possible to cover any reasonable time periods your Subscriber could be offline so that it does not cause performance problems.
Store Transactions: But Not More Than— This setting determines how long transactional replication commands can pool in the distribution database before the Subscriber expires. Again limit this setting as low as possible to cover any reasonable time periods your Subscriber could be offline so that it does not cause performance problems.
![]() History Retention— Store replication performance history at least; history retention is frequently needed for debugging purposes. The more history you collect, the slower your agents will run. Accepting the defaults is the best choice here.
History Retention— Store replication performance history at least; history retention is frequently needed for debugging purposes. The more history you collect, the slower your agents will run. Accepting the defaults is the best choice here.
There is also an option to set default profiles on the General tab of the Distributor Properties dialog box. You can set a default profile here for each agent. For example, you could set the Continue on Data Consistency Error Profile if you continually have problems with data collisions.
The Publishers tab of the Distributor properties dialog allows you to add Publishers and set an administrative link password.
If you need to disable replication on a server, connect to the server in SQL Server Management Studio, right-click on the Replication folder, and select Disable Publishing and Distribution. Click Next at the splash screen. A dialog will ask if you want to disable publishing on the server, or continue using replication on this server. Make your selection and click Next. You will then be prompted to delete existing publications and subscriptions. Click Next, and you will then be prompted to disable publishing and distribution and/or create a script to do so. Make the appropriate choice and click Next, then Finish and Close.
Choose Disable Publishing if you no longer want to use this server as a Publisher or Distributor. If you still have active publications on this server or want to use it as a distributor, select No, Continue Using this Server as a Publisher.
If you need to delete a subscription, connect to the Publisher in SQL Server Management Studio and expand the Local Publications folder, expand your publication, right-click on your Subscription, and select Delete. Select Yes at the confirmation prompt. You can also delete the subscription by connecting to the Subscriber and expanding the Replication folder, expanding Local Subscriptions, right-clicking on the subscription, and selecting Delete. Click Yes at the confirmation prompt.
To delete a publication, connect to the Publisher in SQL Server Management Studio, expand the Replication Folder, expand the Local Publications folder, right-click on the publication you want to delete, select Delete, and click Yes.
To modify the Administrative Link Password to connect to a Remote Distributor, right-click on the Replication folder and Select Update Replication Passwords. Enter the passwords and click OK.
If you ever need to create a replication script, you can right-click on the publication or subscription and select Generate Script. In SQL Server 2008 you can generate a script to a file (the default), to the clipboard, or to a new query window. The dialog allows you to generate scripts to create the publication or subscription or to delete it.
You can also right-click on the Replication folder and generate scripts for selected databases or your entire server.
The central point to monitor and troubleshoot replication is through Replication Monitor. To launch Replication Monitor, right-click on the Replication folder. When Replication Monitor comes up, add your Publisher by clicking on the Add Publisher link. Then drill down on your Publisher in the left-hand pane and expand it to display all publications. As you click on each publication, all subscriptions to it will be displayed in the right-hand pane. Three to four tabs will be displayed depending on your replication type—these tabs are for monitoring and managing subscriptions.
![]() All Subscriptions— This tab is similar to the Publications tab; however, this tab displays information on subscriptions, of course, and not publications. The information displayed based on the columns available includes the status of each subscription, the subscription name, performance, and latency. In addition, it is possible to filter subscriptions based on All Subscriptions, 25 Worst Performing Subscriptions, 50 Worst Performing Subscriptions, Errors and Warnings Only, Errors Only, Warning Only, Subscriptions Running, and Subscriptions Not Running.
All Subscriptions— This tab is similar to the Publications tab; however, this tab displays information on subscriptions, of course, and not publications. The information displayed based on the columns available includes the status of each subscription, the subscription name, performance, and latency. In addition, it is possible to filter subscriptions based on All Subscriptions, 25 Worst Performing Subscriptions, 50 Worst Performing Subscriptions, Errors and Warnings Only, Errors Only, Warning Only, Subscriptions Running, and Subscriptions Not Running.
![]() Tracer Tokens— The second tab is a great utility to test the replication topology, including performance, by placing an artificial synthetic transaction into the replication stream. By clicking the Insert Tracer command button, you can review and calculate performance metrics between the Publisher to Distributor, Distributor to Subscriber, and finally the total latency for the artificial transaction.
Tracer Tokens— The second tab is a great utility to test the replication topology, including performance, by placing an artificial synthetic transaction into the replication stream. By clicking the Insert Tracer command button, you can review and calculate performance metrics between the Publisher to Distributor, Distributor to Subscriber, and finally the total latency for the artificial transaction.
![]() Agents— This tab provides job information and status on all publications on the Publisher. For each common job, the following information is displayed: Status, Job Name, Last Start Time, and Duration.
Agents— This tab provides job information and status on all publications on the Publisher. For each common job, the following information is displayed: Status, Job Name, Last Start Time, and Duration.
![]() Warnings and Alerts— When you’re monitoring subscriptions, the final tab allows you to configure warnings, alerts, and notifications on subscriptions. The two warnings are Warn If a Subscription Will Expire Within Threshold and Warn If Latency Exceeds the Threshold. Click on the Alerts button to display the alerts. Each of these predefined replication alerts can be configured and customized based on a SQL Server event, SQL Server performance condition alert, WMI event alert, error numbers, or severity. In addition, a response can be created for each alert. These responses can execute a specific job or notify an operator on each replication alert that has been customized. The predefined alerts include the following:
Warnings and Alerts— When you’re monitoring subscriptions, the final tab allows you to configure warnings, alerts, and notifications on subscriptions. The two warnings are Warn If a Subscription Will Expire Within Threshold and Warn If Latency Exceeds the Threshold. Click on the Alerts button to display the alerts. Each of these predefined replication alerts can be configured and customized based on a SQL Server event, SQL Server performance condition alert, WMI event alert, error numbers, or severity. In addition, a response can be created for each alert. These responses can execute a specific job or notify an operator on each replication alert that has been customized. The predefined alerts include the following:
![]() Peer-to-peer conflict detection alert
Peer-to-peer conflict detection alert
![]() Replication Warning— Long merge over dialup connection (Threshold:Mergelowrunduration)
Replication Warning— Long merge over dialup connection (Threshold:Mergelowrunduration)
![]() Replication Warning— Long merge over LAN connection (Threshold: mergefastrunduration)
Replication Warning— Long merge over LAN connection (Threshold: mergefastrunduration)
![]() Replication Warning— Slow merge over dialup connection (Threshold: mereslowrunspeed)
Replication Warning— Slow merge over dialup connection (Threshold: mereslowrunspeed)
![]() Replication Warning— Slow merge over LAN connection (Threshold: mergefastrunspeed)
Replication Warning— Slow merge over LAN connection (Threshold: mergefastrunspeed)
![]() Replication Warning— Subscription expiration (Threshold: expiration)
Replication Warning— Subscription expiration (Threshold: expiration)
![]() Replication Warning— Transactional replication latency (Threshold: latency)
Replication Warning— Transactional replication latency (Threshold: latency)
![]() Replication— Agent custom shutdown
Replication— Agent custom shutdown
![]() Replication— Agent failure
Replication— Agent failure
![]() Replication— Agent retry
Replication— Agent retry
![]() Replication— Agent success
Replication— Agent success
![]() Replication— Expired subscription dropped
Replication— Expired subscription dropped
![]() Replication— Subscriber has failed data validation
Replication— Subscriber has failed data validation
![]() Replication— Subscriber has passed data validation
Replication— Subscriber has passed data validation
![]() Replication— Subscription reinitialized after validation failure
Replication— Subscription reinitialized after validation failure
Replication in SQL Server 2008 is a mature technology and a great utility to distribute data among SQL Server instances. For the most part, replication is predominantly used for distributing data between physical sites within an organization. However, it is also commonly used for creating redundant read-only copies of a database for reporting purposes and for consolidating data from many locations.
Although replication can be used as a form of high availability or for disaster recovery, failover clustering, log shipping, and database mirroring are preferred alternatives because they guarantee transaction safety in the event of a disaster.
Some of the best practices that apply to replication include the following:
![]() Create a backup and restore strategy after the replication topology has been implemented. Don’t forget to include the distribution, MSDB, and master databases on the Publisher, Distributor, and all subscribers.
Create a backup and restore strategy after the replication topology has been implemented. Don’t forget to include the distribution, MSDB, and master databases on the Publisher, Distributor, and all subscribers.
![]() Script all replication components from a disaster recovery perspective. Scripts are also useful for conducting repetitive tasks. Finally, regenerate and/or update scripts whenever a replication component changes.
Script all replication components from a disaster recovery perspective. Scripts are also useful for conducting repetitive tasks. Finally, regenerate and/or update scripts whenever a replication component changes.
![]() Use Replication Monitor to create baseline metrics for tuning replication and validate that the hardware and network infrastructure live up to the replication requirements and expectations.
Use Replication Monitor to create baseline metrics for tuning replication and validate that the hardware and network infrastructure live up to the replication requirements and expectations.
![]() Familiarize yourself with modifying database schema and publications after replication has been configured. Some replication items can be changed on the fly, whereas others require you to create a new snapshot.
Familiarize yourself with modifying database schema and publications after replication has been configured. Some replication items can be changed on the fly, whereas others require you to create a new snapshot.
![]() Place the Distribution system database on either a RAID 1 or RAID 1+0 volume other than the operating system. Finally, set the recovery model to Full to safeguard against database failures, and set the size of the database to accommodate the replication data.
Place the Distribution system database on either a RAID 1 or RAID 1+0 volume other than the operating system. Finally, set the recovery model to Full to safeguard against database failures, and set the size of the database to accommodate the replication data.
![]() When configuring replication security, apply the principle of least privilege to ensure that replication is hardened and unwanted authorization is prevented.
When configuring replication security, apply the principle of least privilege to ensure that replication is hardened and unwanted authorization is prevented.
![]() To address performance degradation on the Publisher, configure a Distributor on its own server.
To address performance degradation on the Publisher, configure a Distributor on its own server.
![]() The Service Master Key needs to be available in order to recover from some HA scenarios.
The Service Master Key needs to be available in order to recover from some HA scenarios.