
Chapter 16. Scribe Integration
Throughout this book, we discuss a variety of components and methods for integrating systems, data, and applications with Microsoft Dynamics CRM 4.0. In this chapter, we discuss a Microsoft independent software vendor (ISV) that focuses on data integration: Scribe Software.
Introduction
Although you have several options and solutions for integration, including Microsoft options such as BizTalk (see Chapter 14, “BizTalk Server Integration”), the Scribe Software toolsets offer a solution that we’ve found to be “best of breed.” Their products offer a level of customization that we’ve not found anywhere else, and their support for scaling means they work for implementations with only a few users and enterprise customers.
Benefits from using Scribe, which we explain further in this chapter (and the next two chapters), include the following:
• Use of Microsoft Message Queuing (MSMQ), which provides a mechanism for messages (in the form of data updates) to reliably reach their destination.
• Intuitive and easy-to-use graphic interface for development.
• Existing templates and adapters that allow for quick deployment, with minimal coding. The current templates and adapters include all the Microsoft Dynamics enterprise resource planning (ERP) products (AX, SL, NAV, GP), Salesforce, SalesLogix, and a few others.
Although we have extensive experience working with the Scribe products (and in fact have worked with them to develop some of the material in this chapter), it would be impossible to describe every integration option or solution. So instead, our goal in this chapter (as in the entire book) is to outline the toolsets and explain how the various tools work. We hope this clear outline explains the setup and configuration of the toolsets so that you can realize their benefits within your organization.
Integration Options
Generally speaking, companies implement three distinct levels of integration:
• Data replication: Moving data “one way,” into or out of CRM
• Data synchronization: Moving data “two ways,” into and out of CRM
• Process integration: Facilitating business processes that rely on consistent data across a broad range of business applications
Each category has its own characteristics, implementation requirements, benefits, risks, and costs.
With regard to costs (we cover the benefits, risks, and requirements in each section), there are varying levels, both during the initial project and on an ongoing basis. As a general rule, the complexity and resulting costs associated with an integration project will be exponentially greater for two-way or multidirectional integration projects versus one-way integrations. Complexity also rises dramatically as more and more dependencies between applications (and their respective user bases) are expanded. Costs tend to break down into two major categories: the technical implementation and support costs, and the organizational disruption costs (with the latter in many cases greatly underestimated).
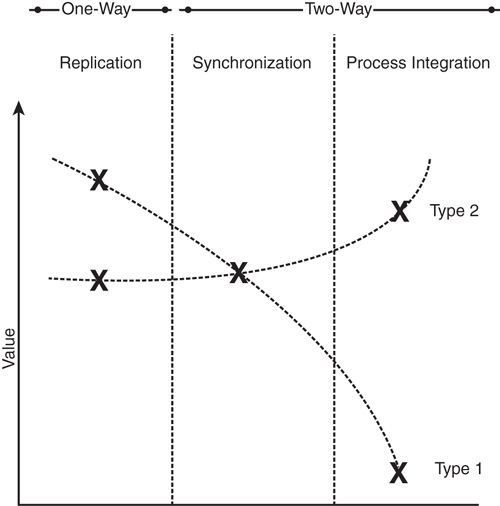
Figure 16.1 illustrates the relationship between value versus cost/disruption for companies across the three levels of integration.
Figure 16.1 Cost/disruption with integration levels.
The following list summarizes the costs you should consider when embarking on a CRM integration project:
• Technical implementation and support
• Integration requirements analysis and design
• Integration software (including maintenance, support, training, and upgrades), whether purchased from a vendor or developed internally
• Application “adapters,” particularly when applications are targets in the integration (another reason why one-way integrations can be simpler and less costly)
• The costs of ensuring data integrity across systems (especially costly with synchronization and process integration because of the need to maintain updatable data in multiple systems)
• Organization disruption costs
• User training and orientation around the use of the newly integrated systems (sometimes referred to as reengineering).
• Risks and costs of creating dependence between mission-critical transaction systems and CRM
• The political barriers of data ownership and coordinating activities across functional areas of the business (one of the most common being CFOs who don’t want salespeople messing with their back-office data)
The following table maps the three levels of CRM integration against the preceding criteria to represent the relative cost of each option.
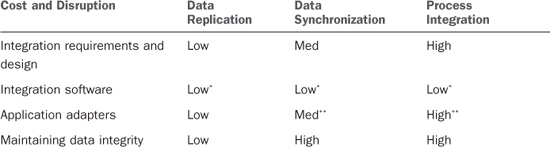

It becomes apparent that as we move from one level to the next, the cost and disruption of each grow exponentially.
So now that we understand the relative costs of the three different types of integration, how do we make sense of the relative benefit of each? To answer this question, it is important to understand how your company markets and sells its products. To illustrate how a company’s sales and marketing process impacts the value side of the equation, let’s define two types of companies at opposite ends of the spectrum. We refer to one category of company as Type 1 and the other as Type 2:
• Type 1: These companies have intensive, relationship-focused sales processes. They generally need to educate their buyers about their products, have longer sales cycles, and have direct and indirect sales teams skilled in the “art” of relationship, value-based selling. Industries that tend to fall in this category include financial services, professional services, health care, capital goods manufacturing, and much of high technology. These types of companies generally benefit the most when you provide their knowledge workers with information that enables them to target customers better and to more effectively manage customer relationships. Given that the transaction side of the customer relationship is generally an occasional event in the sales process that does not dominate the lion’s share of the sales team’s efforts, they tend to gain diminishing value from additional levels of integration. This is particularly true for process integration.
• Type 2: In these companies, the majority of the sales process is centered on transactions. Their customers generally require less information about the features and benefits of products and are more concerned about things such as quantity on hand, price, and availability. Industries that fall in this category include consumer goods, distribution, process manufacturing, and commoditized high technology. These types of companies generally benefit the most from integrated, coordinated, and efficient management of customer transactions. Type 2 companies still benefit from data replication and data synchronization, but ultimately realize the greatest strategic advantage through process integration.
After you’ve decided on the appropriate level of value versus cost, integration can be expanded to include additional data replication, data synchronization, or for Type 2 companies, expanded to include process integration.
With the right long-term plan implemented on a technology platform that can expand with your changing business, your CRM investment will be well positioned to deliver meaningful and sustainable competitive advantage.
Figure 16.2 summarizes the key capabilities required to support the integration requirements previously outlined.
Figure 16.2 Ongoing monitoring and management in batch and real-time automation.

As shown in this figure, you need five major capabilities to perform these data aggregations.
• Data extraction: You must have direct access to your source applications via a database or a proprietary application programming interface (API) from enterprise applications such as Microsoft Dynamics GP, JD Edwards, SAP, MAS 90/200/500, and Siebel. You must also be able to capture net changes either through source queries or via published messages from the source where available.
• Data translation: The semantics and format of many fields of your source data will likely differ from those in Microsoft Dynamics CRM. Important capabilities include parsing and concatenating text fields, performing date and numeric calculations, executing conditional logic, and performing lookups to resolve synonym values. You also need to maintain a cross reference of primary key values, to apply updates from one record in your source to the corresponding record in Dynamics CRM.
• Data update: This capability is the most crucial, yet complex area of your integration task. Capabilities you should look for include the following:
• Avoiding duplicates using fuzzy logic (like comparing elements of the company name and ZIP code to look for an account match) for record lookup
• Performing insert and update operations against multiple objects within Microsoft Dynamics CRM when processing a single source record
• Performing all target processing against the Microsoft Dynamics CRM integration API to ensure that all data imported has been validated by Microsoft Dynamics CRM’s application rules
• Automation: This is where using a customizable template model that incorporates a one-step process from source to target proves very useful. After you have designed your business process, you need to implement an automated event-detection mechanism to initiate an update to Microsoft Dynamics CRM. Look for a solution that supports both batch and message-based processing; each approach is appropriate in different integration scenarios.
• Monitoring and management: After you have developed and implemented your data aggregation solution, you need to consider the ongoing management of the solution. Look for a technology that
• Enables you to remotely support the solution (including start and stop processes, diagnose errors, and so on) via your web browser
• Automatically alerts an administrator via email when processes fail, error, or produce abnormal data conditions
• Can scale across multiple processors to support high-volume data scenarios
Traditional approaches to data aggregation for CRM cover a broad spectrum from custom development to the use of sophisticated technologies such as Microsoft’s BizTalk Server. Unfortunately, these choices represent approaches that are either way too little or way too much. In the case of custom development, someone has to code all the functionality outlined previously to deliver a workable solution. More often than not, these custom solutions are lacking in functionality, unreliable, or difficult to manage. In addition, they are inflexible to changes in your business.
BizTalk Server, on the other hand, may include some of the functionality required but is designed as more of an infrastructure backbone to support a wide range of integration scenarios. This poses two challenges. First, BizTalk Server lacks quite a bit of the specific CRM-focused functionality needed, forcing you to fill in the blanks with custom coding (with all the challenges of custom coding mentioned earlier). Second, it tends to be very complex to install, configure, and manage, and generally requires significant additional hardware and software infrastructure investments. You can quickly lose track of the fact that you just want to get customer data to the sales team.
For more information about BizTalk Server, see Chapter 14.
Data Replication
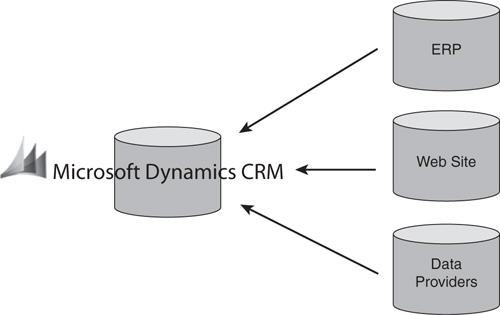
Data replication is by far the simplest and least interdependent type of integration. With replication, a copy of certain customer data that resides in one system is added to the customer records in the CRM application, with data moving in only one direction. Typically, the replicated data is “view-only” in CRM; that is, it cannot be modified by the user but provides more complete customer data to increase the effectiveness of CRM.
Figure 16.3 illustrates data replication.
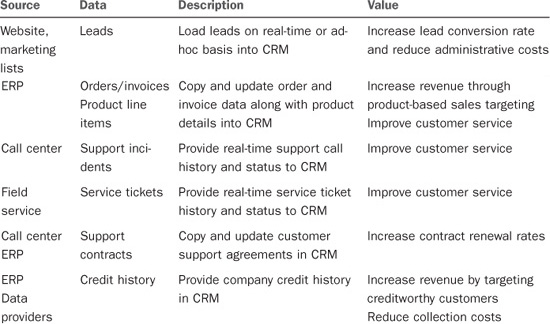
The following table outlines common replication scenarios and the benefits of each.
Bear in mind that implementing a replication scenario may involve extending the data model of a packaged CRM application if the key data elements you want to share do not exist in the base configuration of CRM.
By providing this additional information about customers within the CRM system, sales users can improve the quality of customer interactions and more effectively target customer opportunities.
Replication has another benefit that is not so obvious: It dramatically improves the adoption of CRM by users. CRM is one of those odd business applications where adoption by its “users” is difficult to mandate in most cases. It is rare to find a case where sales reps who were 200% of quota lost their job because they didn’t put their sales activities in a CRM system. So how do you get these individuals to adopt your CRM system? You provide them information in CRM that will help them sell more—information they couldn’t otherwise get. In many cases, this type of quid pro quo has formed the basis for successful CRM implementations.
Data Synchronization
The objective of synchronization is to maintain the same set of customer information in multiple systems, reflecting changes made in one system across the others. Synchronization typically focuses on the more basic demographic customer information that is common to multiple systems, such as company contacts, addresses, phone numbers, and so forth. Figure 16.4 depicts a typical customer synchronization scenario between a company’s ERP and CRM system.
Figure 16.4 Typical customer synchronization scenario.
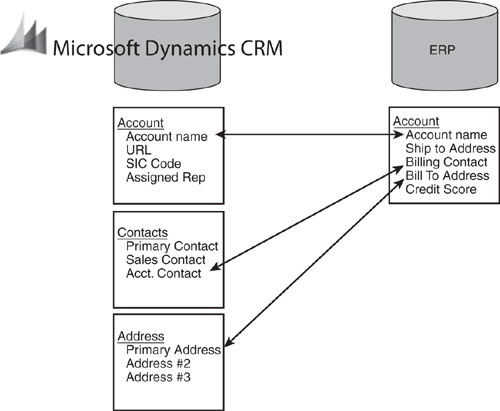
As you can see in Figure 16.4, only certain subsets of data within each system are being synchronized. Given the varying structures of these systems, it is not uncommon to see multiple integration “touch points” between systems to support a synchronization scenario.
Because changes made in one customer database are reflected across all customer databases, data entry effort is dramatically reduced, errors are eliminated, and your entire organization is working from the same information.
Process Integration
With process integration, data is shared from one system to the next based on each system’s role in an integrated customer process. The most commonly discussed customer process related to CRM systems is the “quote-to-order” process.
The following table outlines the integration steps required to support quote-to-order activities between a CRM system and a back-office system.

One thing to consider in process integration is that the order of the steps is extremely important. In the example shown here, if the quote is created from an invalid or out-of-date item from the product catalogue, the ERP system will not be able to support later steps of providing product availability dates or processing the order. In addition, in most cases, data replication and data synchronization are prerequisite integration requirements for implementing process integration.
Typically, process integration relates to those activities in the sales cycle that involve an event or transaction, such as a sales quote, an order, an invoice, a credit verification, a contract renewal, a product return, and so on. By coordinating these activities more efficiently across the users and systems involved in these processes, companies can accelerate revenue and cash flow, eliminate redundant effort, and provide a better experience to their customers.
Scribe Toolset Explained
Scribe Insight for Microsoft Dynamics CRM is a solution that has been specifically built for aggregating customer data into Microsoft Dynamics CRM from other applications. Its powerful, graphical design and management environment enables you to rapidly create solutions within your current infrastructure to provide your salespeople with one complete view of their customers within Microsoft Dynamics CRM.
Scribe Insight provides the following built-in technology capabilities that ensure a successful integrated solution:
• Change capture and event automation
• Conflict detection and resolution
• Maintain relational integrity
• Duplicate detection and resolution
• Data mapping and transformation
• Security and record ownership
• Diagnostics, monitoring, and remediation
Change Capture and Event Automation
The sharing of data and initiation of processes across multiple CRM tenants begins when a change is made to specified data elements within any one of the CRM databases. As discussed in earlier chapters, Microsoft Dynamics CRM uses plug-ins that can “publish” this data in the form of XML for processing. The capability to configure these plug-ins with a few mouse clicks and to organize these XML documents for processing across the other CRM tenants is important. When these changes are published, an automated, fault-tolerant, queue-based process can then be automatically initiated to apply the changes to the other CRM tenants. It is also important that the plug-ins be configured to ignore changes that come from another “federated” process, to avoid the endless bounce back of changes across the CRM tenants.
Support for Varying Latency
Different integration processes are going to have very different latency requirements. For example, in the case of synchronizing data in multiple directions between CRM tenants, latency should be as close to zero as possible, especially if the volume of changes to the data is high. This minimizes the chances that changes to the same record will pass by each other in process and thus create inconsistent updates across CRM tenants. In cases where data is being replicated in one direction and the time sensitivity of the data is not high (for example, the sharing of past activities across CRM tenants), it might be much more efficient to process these records in large batches during off hours. In any event, Scribe Insight enables you to dial the latency of individual integration processes up or down depending on the business need.
Conflict Detection and Resolution
As mentioned earlier, ownership of data is an important consideration for any federated CRM deployment. There might be certain data elements that can be updated only by specified CRM tenants. Scribe Insight enables you to compare a date and time stamp to ensure that only more recent changes are updated (which can mitigate the issue of changes passing by each, as mentioned previously). There might be a requirement to update only null values in the target application, so that another CRM tenant does not overwrite existing data, for instance.
Maintaining Relational Integrity
The relationships within each CRM tenant (for multiple-tenant implementations) are maintained by a series of unique primary keys for each record. When the same record (an account record, for example) is maintained across different CRM tenants, each instance of that record will have its own unique primary ID. Maintaining a cross reference of these keys for all instances of the record across the CRM tenants is critical to ensure the relational integrity of records within each CRM instance. For example, in the case where a new opportunity is created in one CRM tenant, when that opportunity is processed within another CRM tenant, the foreign key that identifies the account in the source needs to be replaced with the foreign key for the account record in the target to ensure relational integrity in the target. Dynamically maintaining the primary ID relationships across CRM tenants is essential and is an inherent feature in the Scribe Insight toolkit.
Duplicate Detection and Resolution
There is no bigger enemy to user adoption than duplicate records. Users will quickly get frustrated with a CRM application if they have to hunt through a significant number of duplicate records to use the system. When new master records are created in one CRM tenant, it is important to be able to ensure that the record does not exist in the other CRM tenants before a new record is inserted. The use of “fuzzy” logic to identify duplicate account and contact records is an important capability here.
Data Mapping and Transformation
The most obvious need here is the mapping and translation of data elements across the different CRM tenants. Another important requirement is the mapping and cross referencing of different pick-list values across different CRM tenants. For example, one CRM tenant may have a different set of sales stages than another, requiring a “best fit” mapping between the two tenants. In some cases, multiple CRM tenants can have different database designs requiring some level of structural remapping of data. For example, one tenant might have designed a many-to-many relationship between contacts and accounts, whereas the other tenant does not have this design. Object-level mapping, as provided by Scribe Insight, is required to resolve the design differences between the two.
State Management
The integration process needs to be able to dynamically update the state of records and transactions within each of the CRM tenants in real time. For example, a record that was changed in one CRM tenant could have a state value of “updated, not yet synchronized” until all other CRM tenant subscribers to that data have been successfully updated. At that point, the integration process could modify the value of the record to “synchronized.” The result is that Scribe Insight can be used to maintain state at the endpoints, and greater fault tolerance can be designed into the integration processes.
Security and Record Ownership
The integration process should fit within the existing security model of Microsoft Dynamics CRM, taking advantage of the predefined roles, permissions, and data ownership. This ensures data access is controlled and data integrity is maintained. With the ability to initiate data integration processes using the privileged user option, Scribe Insight supports predefined security roles and permissions already in existence within the Microsoft Dynamics CRM environment.
Diagnostics, Monitoring, and Remediation
Integration of data and business processes across multiple CRM tenants involves dependencies on network and application availability and the potential for user actions that were not designed into the integration processes. These are two common scenarios that can lead to exceptions and errors in even the best-designed integration processes. Having the capability to proactively monitor for exceptions, anomalies, or inconsistent data conditions and raising alerts to administrators when they occur, as Scribe Insight provides, is essential.
Scribe Insight Architecture
Scribe Insight is designed to support the effective deployment of a number of market-leading business applications, including Microsoft Dynamics CRM, Microsoft Dynamics GP, Microsoft Dynamics NAV, Salesforce, and SalesLogix.
Scribe Insight is the core technology that forms the basis for the migration and integration solutions using a unique and open template model that enables companies to quickly and efficiently configure any data integration or migration to meet their specific needs, all without having to write a single line of code. (See Figure 16.5.)
Figure 16.5 Data migration and integration.
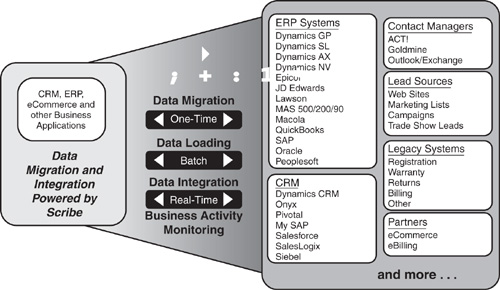
Because each customer configures their business applications differently and has different requirements for how the integration itself will work, Scribe Insight is designed to provide highly functional integration solutions that meet the specific needs of each customer.
Scribe Insight has five major design points:
• No programming required: The tool has a graphical user interface that enables business or data analysts (the people who know the issue best) to design and deploy sophisticated integration solutions.
• A single point of management: Companies can support and maintain the integration solution after it has been deployed.
• A consistent adapter model: The core Insight design environment views all applications in the same way, while presenting to the designer information about each application that is important to the integration task.
• Open connectivity: Lets companies integrate these core business systems with the wide variety of applications and data stores that are unique to their business.
• A template model: Users can quickly assemble reusable integration components and configure them for each deployment’s unique needs. After the initial deployment, required changes in the integration can be accommodated with a simple reconfiguration.
The core components of Scribe Insight are built using the Microsoft Visual Studio development platform for the Windows family of operating systems. The Scribe Server is the core engine that provides connectivity to the various applications, databases, and messaging systems within the integration environment. Communications between the Scribe components and the applications being integrated is provided using the appropriate technology. For example, Scribe adapters to those applications that support web services, such as Salesforce or Microsoft Dynamics CRM, use Simple Object Access Protocol (SOAP), whereas other on-premise APIs are worked with using Component/Distributed Component Object Model (COMDCOM).
Figure 16.6 shows the topology of Scribe Insight components. These items represent the five major Scribe Insight components:
• Scribe Server
• Scribe Workbench
• Scribe Console
• Adapters
• Templates
Figure 16.6 The Scribe topology.
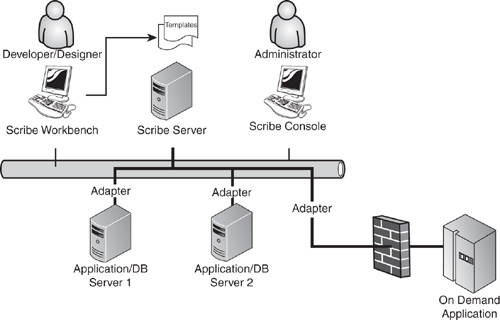
Scribe Insight is based on a loosely coupled, yet tightly integrated architecture that is highly adaptable to each customer’s unique and constantly changing business environment. For example, each adapter communicates to the Scribe Server in precisely the same way regardless of the application or database to which it is connecting. This abstraction of the application or database details provides for a highly productive design environment; once users learn to use the Workbench, they can design integrations with a wide variety of applications and data stores. This abstraction also means that templates (representing specific integration processes between applications or databases) are insulated from most changes/updates to the application or database interface. The same template that works with version x of an application will continue to work with version y, requiring no reconfiguration except to accommodate substantive changes in the schema or functionality of that application.
The Scribe Server
The Scribe Server is the core of Scribe Insight–supported integration processes and facilitates the exchange of data between two or more applications or databases. Because Scribe Insight, in essence, brokers a conversation between these applications and databases, it can support a highly heterogeneous server environment of Windows, UNIX, Linux, on-demand applications, and so on. All that it requires is a “connection” to these applications via a Windows client, a non-platform-specific middleware protocol such as Open Database Connectivity (ODBC), or via a Microsoft Message Queuing (MSMQ) message queue.
Underlying the Scribe Server are a number of Windows services designed to monitor and detect events, process messages, raise alerts, and provide an access point for the Scribe Console to the other services. The Scribe Server also includes its own internal database that stores all execution and error logging, persisted integration settings, cross-reference tables, and important integration statistics. The Scribe internal database can be configured to support the Microsoft SQL Server Express database (provided with Scribe Insight) or the other Microsoft SQL Server editions.
For more information about the Scribe Server, see Chapter 17, “Scribe Integration Components.”
The Scribe Workbench
The Scribe Workbench provides a rich graphical environment where users design and configure the data mappings and business rules that define the integration solution. All work completed in the Scribe Workbench is “saved” in a lightweight file that is referenced by the Scribe Server at runtime. This self-documenting, metadata-driven model allows for easy debugging during the deployment phase and rapid modification as the application environment or business needs change.
The Scribe Workbench enables you to connect to your applications, define a source result set, configure object-level target processing, and then just point and click to modify or add data mappings.
One of the key capabilities in the Scribe Workbench is the ability to “normalize” source data on-the-fly as it processes against the target application. In other words, single- or multi-row “source” data can have multiple operations executed per row on “target” data objects. These operations, referred to as steps, can be conditionally executed based on user-defined logic, allowing complex, transaction-enabled, multiple-object operations. (See Figure 16.7.)
Figure 16.7 The Scribe Workbench.
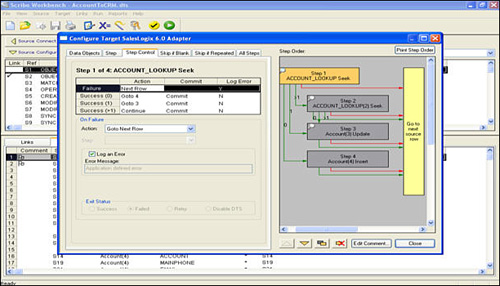
With the Scribe Workbench, designing complex data transformations is a simple task. The Scribe Workbench provides more than 150 Microsoft Excel-like functions for data translation, including the following:
• Parsing functions for names and addresses
• Date and time conversions
• String manipulation
• Database and file lookups for processing synonym values
• Logical if/then/else functions to support conditional processing
In the rare case where there is a need for data transformation beyond what is included in the Scribe Workbench, additional functions may be created using COM and simply added to the function list.
The Scribe Workbench was designed to support many advanced integration needs beyond data transformation and mapping and includes these additional capabilities:
• A Test window that shows the results of processing test data without committing the data to the target system. Users can view the results of data translations and object-level transaction processing for easy and efficient debugging of integration processes.
• Built-in system key cross reference and management, designed to dynamically maintain data integrity between records across two or more loosely coupled applications.
• Built-in support for foreign key value reference management, designed to dynamically maintain data integrity between related records within an application.
• Net change tracking by updating or deleting successfully processed source records or by comparing a source-side update stamp against a variable last run date/time in the source query.
• Conflict detection and resolution to support bidirectional data synchronization.
• Formula-based lookups for “fuzzy” record matching logic.
• Value cross-reference and lookup support.
• Automatic data type mismatch resolution.
• Transactional support for Header-Detail type data sets.
• Configuration of target-side commit and rollback.
• Rich error handling and logical flow control, including support for user-defined errors.
• Rejected row logging to support automated repair and recovery processes.
For more information about the Scribe Workbench, see Chapter 17.
The Scribe Console
The Scribe Console is a Microsoft Management Console snap-in that provides the user interface to an array of powerful features used to set up, organize, and manage key aspects of any number of integration processes. The Scribe Console is the main user interface to the capabilities underlying the Scribe Server.
The Scribe Console can be installed independently from the Scribe Workbench, and can be configured to connect to the Scribe Server using either COM/DCOM technology over a LAN or a provided SOAP-based web service connection hosted by Microsoft Internet Information Services (IIS).
The Scribe Console (shown in Figure 16.8) provides a single point of management for a company’s various integration points, organizing them as discrete units of work or collaborations. Each collaboration is a series of related integration processes and instructions for how and when these processes should be automatically executed. Collaborations are organized in a graphical, user-defined tree and can be managed as independent objects with their own reporting, monitoring, and diagnostic functions. The Scribe Console also provides easy access and control of all integration processes running on the system, through controls implemented at the integration server level.
Figure 16.8 The Scribe Console.
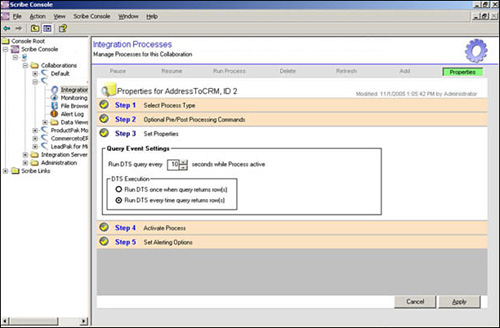
At the core of the Scribe Console are its sophisticated event management capabilities. The Scribe Console allows each company to precisely define the proper latency for each integration process, from scheduling batch processes to run on a predefined time period, to establishing near real-time polling intervals based on a file drop in a directory or the results of a source-side query, to the real-time processing of messages arriving in an in queue.
The Scribe Server is built with a modular, multithreaded architecture that allows for scaling of integration processes based on the available CPU processing strength. It also features efficient connection sharing to maximize performance, where possible.
Additional capabilities of the Scribe Console include the following:
• Access to the files on the Scribe Server that may need to be moved, copied, renamed, or deleted.
• Automated system monitoring of business-level events or integration errors with configurable alerts via email, page, and net send notification.
• For those data sources that do not have a built-in net change mechanism (including event-based message publishing, time and date stamps for updates, or other forms of update stamps), the Console provides a Query Publisher that compares time-based “snapshots” of a source system and publishes the differences as an XML message.
• Settings to launch an executable file to run before or after an integration process. One example where this pre- or post-execution processing can be useful is the ability to move files into an archive directory after the process is executed.
• Onscreen editable views of predefined queries that can be displayed in chart or list format.
• User interface for MSMQ management providing message viewing, moving, copying, and deleting.
• Review execution history of what processes succeeded or failed, including detailed error reporting.
For more information about the Scribe Console, see Chapter 17.
Scribe Adapters
Scribe adapters enable Scribe Insight to communicate seamlessly to a variety of applications, databases, messages, and files.
Scribe adapters present rich levels of schema information, which is available through the application interface (via a “declare” type function in an application API or in a Web Service Definition Language [WSDL] in the case of web services interfaces) to the Scribe Server and Scribe Workbench. This schema information includes object properties and interrelationships and detailed field attributes such as labels, data types, lengths, restrictions, and default/pick-list values. Combined with the rich features in the Scribe Workbench, this information provides for unparalleled control over integration processes and eliminates the “last-mile” coding required with other integration tools.
Scribe adapters are classified in two ways: enterprise application adapters and connectivity adapters.
Enterprise Application Adapters
Enterprise application adapters are adapters that have been designed and developed to optimize Insight for use with Scribe-targeted CRM and ERP applications, including Microsoft Dynamics CRM, Microsoft Dynamics GP, Microsoft Dynamics NAV, Microsoft Dynamics AX, Salesforce, and SalesLogix. Scribe’s enterprise application adapters are sold as add-ons to Scribe Insight. Key features of these application adapters include the following:
• The automation of common data loading tasks such as assigning primary ID values, setting default values, validating input data, and setting object relationships—all designed to eliminate runtime errors and provide for greater data integrity.
• Dynamic discovery that presents the unique configuration of each application or database instance to the Scribe Console and Scribe Workbench at runtime and adjusts to changes in the application or database schema without requiring recoding or recompiling.
• The seamless integration of application and database error messages to provide detailed exception reporting and handling from the Scribe Console’s single point of management.
Connectivity Adapters
Connectivity adapters are included in core Scribe Insight product. They are designed to complement the enterprise application adapters by providing a wide variety of integration options to support connectivity to the varied applications and data stores within each company’s computing environment. These connectivity adapters enable Scribe Insight to communicate with applications and databases in the following ways:
• Direct communication with database tables, views, and stored procedures through ODBC 3.0 or later and natively to SQL Server. Scribe leverages all the filtering and querying capability of these databases when employing this approach.
• The exchange of flat files or XML documents via a directory or FTP/HTTP location.
• The asynchronous exchange of XML messages via an industry-standard message queue, email, or integration broker.
• SOAP Messages via web-based transport protocols, such as http/https.
A common use of Scribe’s connectivity adapters is to support integration between the targeted applications served by Scribe’s application adapters and a wide variety of other packaged enterprise applications. These other enterprise applications include the following:
• ERP and CRM systems from SAP, Siebel, Oracle (Oracle, PeopleSoft, JD Edwards,) Sage (MAS 90/200/500,) Epicor, and so on
• Packaged applications that serve a particular niche or vertical market
• Custom in-house-developed systems
Scribe provides a number of approaches to integrating with these applications, depending on the business requirements and available technical resources, including the following:
• Directly to the database: This is a simple, straightforward approach if you are migrating from an application or your project is limited to a one-way feed of data from that application. Scribe Insight provides a number of methods using this approach to extract “net change” data from the application.
• Via interface tables: Many applications support a set of interface or staging tables that provide for a safe way to integrate data into that application. After data is passed into the interface tables, an application process is initiated that validates the data and applies appropriate application rules. With Scribe Insight, you can write to these tables and initiate the application process automatically.
• Via an XML/messaging interface: Many enterprise applications provide an XML interface that is incorporated into the workflow engine within the application. Using this method, Scribe Insight can publish XML messages into a message queue for real-time integration with the other application. Scribe Insight can also receive XML transactions published by the application’s workflow engine into a message queue in real time.
• Via the application’s API: Many applications expose a web services- or COM-based API where transactions can be passed to the application. Data can also be queried via this API. Out of the box, Scribe Insight cannot “natively” integrate with this API; however, custom code can be written to convert these calls into an intermediate format. This intermediate format can be an XML message, a flat file, or a record in a database staging table.
Scribe Insight also includes connectivity adapters for data migration from/to certain leading desktop applications, including ACT!, GoldMine, and Microsoft Outlook/Exchange.
Scribe Templates
Scribe templates represent complete or partial data integration or migration processes that have been developed using Scribe Insight technology. Scribe provides a number of these templates as free downloads from the Scribe Web Community to support the successful deployment of Scribe Insight.
Templates consist of the building blocks of a fully functional migration or integration solution as configured with Scribe Insight, including the following:
• Source-side “net change” processes and filtering
• Event and process automation
• Data mappings
• Record matching for updates and duplicate avoidance
• User/owner mappings
• Field ownership and update rules
• System key cross referencing and management
• Connection validation and security
• Data ownership and customizations
• Application customizations
• Transaction management
• Commit and rollback settings
• System monitors and alerts
• Business monitors and alerts
There are two distinct styles of Scribe templates: solution templates and component templates.
Solution Templates
Solution templates represent a complete, fully functional integration or migration solution between two applications. Examples of these include migration solutions for ACT! into Microsoft Dynamics CRM, SalesLogix, or Salesforce and “front to back-office” integration solutions between Microsoft Dynamics GP and Microsoft Dynamics CRM or Salesforce. Scribe’s unique template model provides out-of-the-box functionality for these integration scenarios, built over its industry-leading integration tool. Because most customers have business needs unique to them, these standard templates can be quickly extended and customized via the GUI-based mapping and development environment.
The component architecture of these solution templates also enables customers to implement templates in phases or pick and choose the elements of the templates that they require. In the front to back-office integration example, a customer might not want to implement order integration initially (or in some cases never) but can still synchronize customer activity (accounts, contacts, invoices) between the two systems. This modularity enables customers to implement an integration solution tailored to their exact needs.
Component Templates
Component templates are starting points for common integration processes used by customers that are implementing an integration solution for which Scribe has not developed a solution template.
For example, Scribe provides templates that integrate customers, products, orders, and invoices between a Scribe-developed sample ERP system and Scribe’s targeted CRM applications, including Microsoft Dynamics CRM, Salesforce, and SalesLogix. A customer that is looking to integrate one of these applications with their own ERP application can use the appropriate component template as a significant starting point. Typically, these component templates provide the bulk of the end solution, with the remainder easily configurable with Scribe Insight.
For more information about Scribe templates, see Chapter 17.
Summary
This chapter explained what integration means and when and how to consider different options related to integration options. The basics of the Scribe toolset were reviewed at a high level, as was the value of working with them. In the next few chapters, we delve deeper into the toolset to show and explain it in further detail.