
With the ubiquity of multicore processors in today’s computers, even on small devices such as cell phones, the ability to program effectively for multiple threads is a critical skill for all programmers.
There are essentially three reasons for using multiple threads:
- You do not want to block the main thread of a UI with some background work.
- You have so much work to do that you cannot afford to waste CPU time waiting for I/O to complete.
- You want to use all of the processors at your disposal.
The first reason does not have as much to do with performance as it does with not annoying the end user, which is vitally important, but is not the primary focus of this book. This chapter will focus on optimizing the second and third situations, which is all about efficient use of computing resources.
Computer processors have effectively hit a wall in terms of raw clock speed. The main technique we are going to use in the foreseeable future to achieve higher computing throughput is parallelism. Taking advantage of multiple processors is critical to writing a high-performance application, particularly servers handling many simultaneous requests.
There are a few ways to execute code concurrently in .NET. For example, you can manually spin up a thread and assign it a method to run. This is fine for a relatively long-running method, but for many things, dealing with threads directly is very inefficient. If you want to execute a lot of short-running tasks, for example, the overhead of scheduling individual threads could easily outweigh the cost of actually running your code. To understand why, you need to know how threads are scheduled in Windows.
Each processor can execute only a single thread at a time. When it comes time to schedule a thread for a processor, Windows needs to do a context switch. During a context switch, Windows saves the processor’s current thread’s state to the operating system’s internal thread object, picks from all the ready threads, transfers the thread’s context information from the thread object to the processor, and then finally starts it executing. If Windows switches to a thread from a different process, even more expense is incurred as the address space is swapped out.
The thread will then execute the code for the thread quantum, which is a multiple of the clock interval (the clock interval is about 15 milliseconds on current multiprocessor systems). When the code returns from the top of its stack, enters a wait state, or the time quantum is expired, the scheduler will pick another ready thread to execute. It may be the same thread, or not, depending on the contention for the processors. A thread can enter a wait state if it blocks on I/O of any kind, or voluntarily enters this state by calling Thread.Sleep.
Note Windows Server has a higher thread quantum than the desktop version of Windows, meaning it runs threads for longer periods of times before a context switch. This setting can be controlled to some extent in the Performance Options of Advanced System Settings.
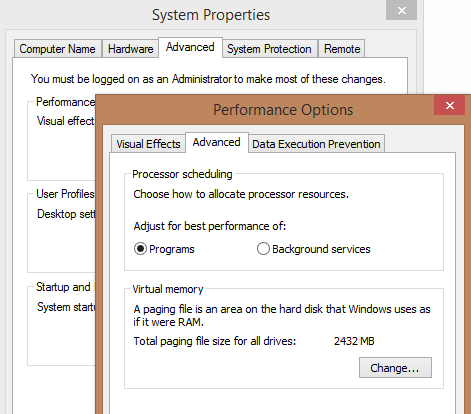
Setting the option to “Background services” will increase the default thread quantum for the system, possibly at the expense of program responsiveness. These settings are stored in the registry, but you should not manipulate them directly.
Creating new threads is an expensive procedure. It requires allocation in the kernel, the creation of stack space, and more context switching. For these reasons, .NET manages a thread pool for each managed process. These threads are created as needed and stick around to handle future needs, avoiding the recreation cost. See http://www.writinghighperf.net/go/19 for a good discussion of how the thread pool works. The program saves on the overhead of creation and deletion and there is almost always a thread ready to handle the asynchronous tasks that come up. The thread pool handles explicit worker thread tasks that run delegates as well as I/O completions (such as what happens when the file you requested from disk is now ready) from the underlying operating system.
If your program consists of pure CPU tasks longer than the length of the thread quantum, then creating and using threads directly is acceptable, though unnecessary as we will see. However, if your code consists of many smaller tasks that are unlikely to take this long, using threads directly is inefficient because the program will spend a significant time context switching rather than executing its actual code. While you can utilize the thread pool directly, it is no longer recommended to do so and I will not cover it here. Instead, you can use Tasks for both long and short actions.
- Use Tasks
.NET 4.0 introduced an abstraction of threads called the Task Parallel Library (TPL), which is the preferred way of achieving parallelism in your code. The TPL gives you a lot of control over how your code is run, allows you to determine what happens when errors occur, provides the ability to conditionally chain multiple methods in sequence, and much more.
Internally, the TPL uses the .NET thread pool, but does so more efficiently, executing multiple Tasks on the same thread sequentially before returning the thread back to the pool. It can do this via intelligent use of delegate objects. This effectively avoids the problem described previously of wasting a thread’s quantum with a single small task and causing too many context switches.
TPL is a large and comprehensive set of APIs, but it is easy to get started. The basic principle is that you pass a delegate to the Task’s Start method. You also optionally call ContinueWith on the Task and pass a second delegate, which is executed once the Task is complete.
You can execute Tasks with both CPU-bound computations as well as I/O. All of these first examples will show pure CPU processing. There is a section dedicated to effective I/O later in this chapter.
The following code listing from the Tasks sample project demonstrates creating a Task for each processor. When each Task completes, it schedules for execution a continuation Task that has a reference to a callback method.
class Program
{
static Stopwatch watch = new Stopwatch();
static int pendingTasks;
static void Main(string[] args)
{
const int MaxValue = 1000000000;
watch.Restart();
int numTasks = Environment.ProcessorCount;
pendingTasks = numTasks;
int perThreadCount = MaxValue / numTasks;
int perThreadLeftover = MaxValue % numTasks;
var tasks = new Task<long>[numTasks];
for (int i = 0; i < numTasks; i++)
{
int start = i * perThreadCount;
int end = (i + 1) * perThreadCount;
if (i == numTasks - 1)
{
end += perThreadLeftover;
}
tasks[i] = Task<long>.Run(() =>
{
long threadSum = 0;
for (int j = start; j <= end; j++)
{
threadSum += (long)Math.Sqrt(j);
}
return threadSum;
});
tasks[i].ContinueWith(OnTaskEnd);
}
}
private static void OnTaskEnd(Task<long> task)
{
Console.WriteLine("Thread sum: {0}", task.Result);
if (Interlocked.Decrement(ref pendingTasks) == 0)
{
watch.Stop();
Console.WriteLine("Tasks: {0}", watch.Elapsed);
}
}
}
If your continuation Task is a fast, short piece of code, you should specify that it runs on the same thread as its owning Task. This is vitally important in an extremely multithreaded system as it can be a significant waste to spend time queuing Tasks to execute on a separate thread which may involve a context switch.
task.ContinueWith(OnTaskEnd,
TaskContinuationOptions.ExecuteSynchronously);
If the continuation Task is called back on an I/O thread, then you might not want to use TaskContinuationOptions.ExecuteSynchronously, as this could tie up an I/O thread that you need for pulling data off the network. As always, you will need to experiment and measure the result carefully. It is often more efficient for the I/O thread to just do the quick continuation work and avoid the extra scheduling.
If do need a long-running Task, you can create it with the TaskCreationOptions.LongRunning flag with the Task.Factory.StartNew method. There is also a version of this flag for continuations:
var task = Task.Factory.StartNew(action,
TaskCreationOptions.LongRunning);
task.ContinueWith(OnTaskEnd, TaskContinuationOptions.LongRunning);
Continuations are the real power of the TPL. You can do all sorts of complex things that are outside the scope of performance and I will mention a few of them briefly here.
You can execute multiple continuations for a single Task:
Task task = ...
task.ContinueWith(OnTaskEnd);
task.ContinueWith(OnTaskEnd2);
OnTaskEnd and OnTaskEnd2 have no relationship with each other and execute independently, in parallel.
On the other hand, you can also chain continuations:
Task task = ...
task.ContinueWith(OnTaskEnd).ContinueWith(OnTaskEnd2);
Chained continuations have serial dependency relationships with each other. When task ends, OnTaskEnd will run. Once that completes, OnTaskEnd2 will execute.
Continuations can be told to execute only when their antecedent Task ends successfully (or fails, or is canceled, etc.):
Task task = ...
task.ContinueWith(OnTaskEnd, TaskContinuationOptions.OnlyOnRanToCompletion);
task.ContinueWith(OnTaskEnd, TaskContinuationOptions.NotOnFaulted);
You can invoke a continuation only when multiple Tasks are completed (or any one of them has):
Task[] tasks = ...
Task.Factory.ContinueWhenAll(tasks, OnAllTaskEnded);
Task.Factory.ContinueWhenAny(tasks, OnAnyTaskEnded);
To cancel a Task that is already running requires some cooperation. It is never a good idea to force-terminate a thread, and the Task Parallel Library does not allow you to access the underlying thread, let alone abort it. (If you do program directly with a Thread object, then you can call the Abort method, but this dangerous and not recommended. Just pretend this API does not exist.)
To cancel a Task, you need to pass the Task’s delegate a CancellationToken object which it can then poll to determine if it needs to end processing. This example also demonstrates using a lambda expression as a Task delegate.
static void Main(string[] args)
{
var tokenSource = new CancellationTokenSource();
CancellationToken token = tokenSource.Token;
Task task = Task.Run(() =>
{
while (true)
{
// do some work...
if (token.IsCancellationRequested)
{
Console.WriteLine("Cancellation requested");
return;
}
Thread.Sleep(100);
}
}, token);
Console.WriteLine("Press any key to exit");
Console.ReadKey();
tokenSource.Cancel();
task.Wait();
Console.WriteLine("Task completed");
}
You can find this code in the sample TaskCancellation project.
- Parallel Loops
One of the examples in the previous section demonstrates a pattern that is so common that there is an API just for parallel execution of loops.
long sum = 0;
Parallel.For(0, MaxValue, (i) =>
{
Interlocked.Add(ref sum, (long)Math.Sqrt(i));
});
There is also a version for foreach for handling generic IEnumerable<T> collections.
var urls = new List<string>
{
@"http://www.microsoft.com",
@"http://www.bing.com",
@"http://msdn.microsoft.com"
};
var results = new ConcurrentDictionary<string,string>();
var client = new System.Net.WebClient();
Parallel.ForEach(urls, url => results[url] =
client.DownloadString(url));
If you want to interrupt loop processing, you can pass a ParallelLoopState object to the loop delegate. There are two options for stopping the loop:
- Break—Tells the loop not to execute any iterations that are sequentially greater than the current iteration. In a Parallel.For loop, if you call ParallelLoopState.Break on the ith iteration then any iterations less than i will still be allowed to run, but any iterations greater than i will be prevented from running. This also works on a Parallel.ForEach loop, but each item is assigned an index, and this may be arbitrary from the program’s point of view. Note that it is possible for multiple loop iterations to call Break, depending on the logic you code inside the loop.
- Stop—Tells the loop not to execute any more iterations at all.
The following example uses Break to stop the loop at an arbitrary location.
Parallel.ForEach(urls, (url, loopState) =>
{
if (url.Contains("bing"))
{
loopState.Break();
}
results[url] = client.DownloadString(url);
});
When using parallel loops, you want to ensure that the amount of work you do per iteration is significantly larger than the amount of time you spend synchronizing any shared state. It is very easy to lose all of the benefits of parallelism if your loop spends all of its time blocked on access to a variable that all the loops use. You can avoid this by having each your loops iterate on local state as much as possible.
Another problem with parallel loops is that a delegate is invoked for each iteration, which may be wasteful if the work to be done is less than the cost of a delegate or method invocation (See Chapter 5).
Both problems can be solved with the Partitioner class which transforms a range into a set of Tuple objects that describe a range to be iterated over on the original collection.
The following example demonstrates just how much synchronization can negatively affect the effectiveness of parallelism.
static void Main(string[] args)
{
Stopwatch watch = new Stopwatch();
const int MaxValue = 1000000000;
long sum = 0;
// Naive For-loop
watch.Restart();
sum = 0;
Parallel.For(0, MaxValue, (i) =>
{
Interlocked.Add(ref sum, (long)Math.Sqrt(i));
});
watch.Stop();
Console.WriteLine("Parallel.For: {0}", watch.Elapsed);
// Partitioned For-loop
var partitioner = Partitioner.Create(0, MaxValue);
watch.Restart();
sum = 0;
Parallel.ForEach(partitioner,
(range) =>
{
long partialSum = 0;
for (int i = range.Item1; i < range.Item2; i++)
{
partialSum += (long)Math.Sqrt(i);
}
Interlocked.Add(ref sum, partialSum);
});
watch.Stop();
Console.WriteLine("Partitioned Parallel.For: {0}", watch.Elapsed);
}
You can find this code in the ParallelLoops sample project. On one run on my machine, the output was this:
Parallel.For: 00:01:47.5650016
Partitioned Parallel.For: 00:00:00.8942916
The above partitioning scheme is static in that once the partitions are determined, a delegate executes each range and if one finishes early there is no attempt to repartition to get other processors working. You can create static partitions on any IEnumerable<T> collection without specifying a range, but there will be a delegate call for each item, not for a sub-range. It is possible to get around this by creating a custom Partitioner, which can be quite involved. For more information and to see some extensive examples, see the article by Stephen Toub at http://www.writinghighperf.net/go/20.
- Avoid Blocking
You may notice that in some of the samples, I call task.Wait(). I do this for expediency in such small sample projects where I do not want the process to exit, but in real production code, you should never do this. Use continuations instead. Waiting on a Task is a subset of the larger problem of blocking calls.
To obtain the highest performance you must ensure that your program never wastes one resource while waiting for another. Most commonly, this takes the form of blocking the current thread while waiting for some I/O to complete. This situation will cause one of two things to happen:
- The thread will be blocked in a waiting state, get unscheduled, and cause another thread to run. This could mean creating a new thread to handle pending work items or tasks if all current threads are in use or blocked.
- The thread will hit a synchronization object which might spin for a few milliseconds waiting for a signal. If it does not get it in time, it will enter the same state as 1.
In both cases, it needlessly increases the size of the thread pool, and possibly also wastes CPU spinning in locks. Neither situation is desirable.
Locking and other types of direct thread synchronization are all explicit blocking calls and easy to detect. However, it is not always so obvious what other method calls may lead to blocking. They often revolve around I/O of various kinds so you need to make sure that any interactions with the network, the file system, databases, or any other high-latency service is done asynchronously. Thankfully, .NET makes it fairly easy to do that with Tasks.
When making use of any I/O API, whether it is for network, file system, databases, or anything else, make sure that it returns a Task; otherwise, it is highly suspect and probably doing blocking I/O. Note that older asynchronous APIs will return an IASyncResult and usually start with Begin-. Either find an alternate API that returns a Task instead, or use the Task.Factory.FromAsync to wrap these methods inside of Tasks to keep your own programming interface consistent.
- Use Tasks for Non-Blocking I/O
.NET 4.5 added Async methods to the Stream class so that now all Stream-based communication can be entirely asynchronous quite easily. Here is a simple example:
int chunkSize = 4096;
var buffer = new byte[chunkSize];
var fileStream = new FileStream(filename, FileMode.Open);
var task = fileStream.ReadAsync(buffer, 0, buffer.Length);
task.ContinueWith((readTask) =>
{
int amountRead = readTask.Result;
fileStream.Dispose();
Console.WriteLine("Async(Simple) read {0} bytes", amountRead);
});
You can no longer take advantage of the using syntax to clean up IDisposable objects such as Streams. Instead, you must pass those objects to the continuation method to make sure they are disposed along every path.
The above example is actually quite incomplete. In a real scenario, you will often have to make multiple reads to a stream to get the full contents. This can happen if the files are larger than the buffer you provide, or if you are dealing with a network stream instead of files. In that case, the bytes have not even arrived at your machine yet. To handle this situation asynchronously, you need to continue reading the stream until it tells you there is no data left.
An additional wrinkle is that now you need two levels of Tasks. The top level is for the overall read—the portion your calling program is interested in. The level below that is the Tasks for each individual chunked read.
Consider why this is so. The first asynchronous read will return a Task. If you return that up to the caller to wait or continue on, then they will continue executing after the first read is done. What you really want is for them to continue executing after all the reads are complete. This means you cannot return that first Task back to the caller. You need a fake Task that completes once all the reads are done.
To accomplish all of this, you will need to use the TaskCompletionSource<T> class, which can generate that fake Task for you to return. When your series of asynchronous reads are complete, you call the TrySetResult method on the TaskCompletionSource, which will cause it to trigger whoever is waiting or continuing on it.
The following example expands on the previous example and demonstrates the use of TaskCompletionSource:
private static Task<int> AsynchronousRead(string filename)
{
int chunkSize = 4096;
var buffer = new byte[chunkSize];
var tcs = new TaskCompletionSource<int>();
var fileContents = new MemoryStream();
var fileStream = new FileStream(filename, FileMode.Open);
fileContents.Capacity += chunkSize;
var task = fileStream.ReadAsync(buffer, 0, buffer.Length);
task.ContinueWith(
readTask =>
ContinueRead(readTask, fileStream,
fileContents, buffer, tcs));
return tcs.Task;
}
private static void ContinueRead(Task<int> task,
FileStream stream,
MemoryStream fileContents,
byte[] buffer,
TaskCompletionSource<int> tcs)
{
if (task.IsCompleted)
{
int bytesRead = task.Result;
fileContents.Write(buffer, 0, bytesRead);
if (bytesRead > 0)
{
// More bytes to read, so make another async call
var newTask = stream.ReadAsync(buffer, 0, buffer.Length);
newTask.ContinueWith(
readTask =>
ContinueRead(readTask, stream,
fileContents, buffer, tcs));
}
else
{
// All done, dispose of resources and
// complete top-level task.
tcs.TrySetResult((int)fileContents.Length);
stream.Dispose();
fileContents.Dispose();
}
}
}
- Adapt the Asynchronous Programming Model (APM) to Tasks
Older style asynchronous methods in the .NET Framework have methods prefixed with Begin- and End-. These methods continue to work fine and can be easily wrapped inside a Task for a consistent interface, as in the following example, taken from the TaskFromAsync sample project:
const int TotalLength = 1024;
const int ReadSize = TotalLength / 4;
static Task<string> GetStringFromFileBetter(string path)
{
var buffer = new byte[TotalLength];
var stream = new FileStream(
path,
FileMode.Open,
FileAccess.Read,
FileShare.None,
buffer.Length,
FileOptions.DeleteOnClose | FileOptions.Asynchronous);
var task = Task<int>.Factory.FromAsync(
stream.BeginRead,
stream.EndRead,
buffer,
0,
ReadSize, null);
var tcs = new TaskCompletionSource<string>();
task.ContinueWith(readTask => OnReadBuffer(readTask,
stream, buffer, 0, tcs));
return tcs.Task;
}
static void OnReadBuffer(Task<int> readTask,
Stream stream,
byte[] buffer,
int offset,
TaskCompletionSource<string> tcs)
{
int bytesRead = readTask.Result;
if (bytesRead > 0)
{
var task = Task<int>.Factory.FromAsync(
stream.BeginRead,
stream.EndRead,
buffer,
offset + bytesRead,
Math.Min(buffer.Length - (offset + bytesRead), ReadSize),
null);
task.ContinueWith(
callbackTask => OnReadBuffer(
callbackTask,
stream,
buffer,
offset + bytesRead,
tcs));
}
else
{
tcs.TrySetResult(Encoding.UTF8.GetString(buffer, 0, offset));
}
}
The FromAsync method takes as arguments the stream’s BeginRead and EndRead methods as well as the target buffer to store the data. It will execute the methods and after EndRead is done, call the continuation, passing control back to your code, which in this example closes the stream and returns the converted file contents.
- Use Efficient I/O
Just because you are using asynchronous programming with all I/O calls does not mean you are making the most out of the I/O you’re doing. I/O devices have different capabilities, speeds, and features which means that you often need to tailor your programming to them.
In the examples above, I chose a 16KB buffer size for reading and writing to the disk. Is this a good value? Considering the size of buffers on hard disks, the speed of solid state devices, maybe not. Experimentation is required to figure out how to chunk the I/O efficiently. The smaller your buffers, the more overhead you will have. The larger your buffers, the longer you may need to wait for results to start coming in. The rules that apply to disks will not apply to network devices and vice-versa.
The most crucial thing, however, is that you also need to structure your program to take advantage of I/O. If part of your program ever blocks waiting for I/O to finish then that is time not spent crunching useful data with the CPU or at least wasting the thread pool. While waiting for I/O to complete, do as much other work as possible.
Also, note that there is a huge difference between true asynchronous I/O and performing synchronous I/O on another thread. In the former case, you have actually handed control to the operating system and hardware and no code anywhere in the system is blocked waiting for it to come back. If you do synchronous I/O on another thread, you are just blocking a thread that could be doing other work while still waiting for the operating system to get back to you. This might be acceptable in a non-performance situation (e.g., doing background I/O in a UI program instead of the main thread), but it is never recommended.
In other words, the following example is bad and defeats the purpose of asynchronous I/O:
Task.Run( ()=>
{
using (var inputStream = File.OpenRead(filename))
{
byte[] buffer = new byte[16384];
var input = inputStream.Read(buffer, 0, buffer.Length);
...
}
});
For additional tips on doing effective I/O with the .NET Framework APIs specifically for disk or network access, see Chapter 6.
- Async and Await
In .NET 4.5, there are two new keywords that can simplify your code in many situations: async and await. Used together, they turn your TPL code into something that looks like easy, linear, synchronous code. Under the hood, however, it is really using Tasks and continuations.
The following example comes from the AsyncAwait sample project.
static Regex regex = new Regex("<title>(.*)</title>", RegexOptions.Compiled);
private static async Task<string> GetWebPageTitle(string url)
{
System.Net.Http.HttpClient client = new System.Net.Http.HttpClient();
Task<string> task = client.GetStringAsync(url);
// now we need the result so await
string contents = await task;
Match match = regex.Match(contents);
if (match.Success)
{
return match.Groups[1].Captures[0].Value;
}
return string.Empty;
}
To see where the real power of this syntax lies, consider a more complex example, where you are simultaneously reading from one file and writing to another, compressing the output along the way. It is not very difficult to use Tasks directly to accomplish this, but consider how trivial it looks when you use the async/await syntax. The following is from the CompressFiles sample project.
First, the synchronous version for comparison:
private static void SyncCompress(IEnumerable<string> fileList)
{
byte[] buffer = new byte[16384];
foreach (var file in fileList)
{
using (var inputStream = File.OpenRead(file))
using (var outputStream = File.OpenWrite(file+".compressed"))
using (var compressStream = new GZipStream(outputStream,
CompressionMode.Compress))
{
int read = 0;
while ((read = inputStream.Read(buffer, 0, buffer.Length)) > 0)
{
compressStream.Write(buffer, 0, read);
}
}
}
}
To make this asynchronous, all we have to do is add the async and await keywords and change the Read and Write methods to ReadAsync and WriteAsync, respectively:
private static async Task AsyncCompress(IEnumerable<string> fileList)
{
byte[] buffer = new byte[16384];
foreach (var file in fileList)
{
using (var inputStream = File.OpenRead(file))
using (var outputStream = File.OpenWrite(file + ".compressed"))
using (var compressStream =
new GZipStream(outputStream, CompressionMode.Compress))
{
int read = 0;
while ((read = await inputStream.ReadAsync(buffer, 0,
buffer.Length)) > 0)
{
await compressStream.WriteAsync(buffer, 0, read);
}
}
}
}
Your code can await any method that returns a Task<T>, as long as it is in a method marked async. With these keywords, the compiler will do the heavy lifting of transforming your code into a structure similar to the previous TPL examples. It looks like this code will get blocked waiting for the HTTP result, but do not confuse “await” for “wait”; they are similar, but deliberately just different enough. Everything before the await keyword happens in the calling thread. Everything from the await onwards is in the continuation.
Using async/await can dramatically simplify your code, but there are some Task-based situations for which they cannot be used. For example, if the completion of a Task is nondeterministic, or you must have multiple levels of Tasks and are using TaskCompletionSource, then async/await may not fit.
Story I ran into this determinism problem myself when I was implementing retry functionality on top of .NET’s HTTP client functionality, which is fully Task-enabled. I started with a simple HTTP client wrapper class and I used async/await initially because it simplified the code. However, when it came time to actually implement the retry functionality, I immediately knew I was stuck because I had given up control of when the tasks completed. For my implementation, I wanted to send the retry request before the first request had actually timed out. Whichever request finished first is the one I wanted to return up to the caller. Unfortunately, async/await will not handle this nondeterministic situation of arbitrarily choosing from multiple child Tasks that you are waiting on. One way to resolve this is to use the ContinueOnAny method described earlier. Alternatively, you could use TaskCompletionSource to manually control when the top-level Task is complete.
- A Note on Program Structure
There’s a crucial tidbit from the previous section: all awaits must be in methods marked async, which means those methods must return Task objects. This kind of restriction does not technically exist if you are using Tasks directly, but the same idea applies. Using asynchronous programming is like a beneficial “virus” that infects your program at all layers. Once you let it into one part, it will of necessity move up the layers of function calls as high as it can.
Of course, using Tasks directly, you can create the following (bad) example:
Task<string> task = Task<string>.Run(()=> { ... });
task.Wait();
But unless you are doing only trivial multithreaded work, this completely ruins the scalability of your application. Yes, you could insert some work between the task’s creation and the call to Wait, but this is missing the point. You should almost never wait on Tasks, unlike some of the examples here that do it for convenience. That wastes a thread that could otherwise be doing useful work. It may lead to more context switching and higher overhead from the thread pool as more threads are needed to handle the available work items.
If you carry this idea of never waiting to its logical conclusion, you will realize that it is very possible (even likely) that nearly all of your program’s code will occur in a continuation of some sort. This makes intuitive sense if you think about it. A UI program does essentially nothing until a user clicks or types—it is reacting to input via an event mechanism. A server program is analogous, but instead of mouse and keyboard, the I/O is via the network or file system.
As a result, a high-performance application can easily start to feel disjointed as you split logic based on I/O (or responsiveness in a UI) boundaries. The earlier you plan for this, the better off you will be. It is critical to settle on just a few standard patterns that most or all of your program uses. For example:
- Determine where Task and continuation methods live. Do you use a separate method or a lambda expression? Does it depend on its size?
- If you use methods for continuations, settle on a standard prefix (e.g., OnMyTaskEnd).
- Standardize error handling. Do you have a single continuation method that handles all errors, cancellations, and normal completions? Or do you have separate methods to handle each or some of these and use TaskContinuationOptions to selectively execute them?
- Decide whether to use async/await or Tasks directly.
- If you have to call old style Begin…/End… asynchronous methods, wrap them in Tasks to standardize your handling, as described earlier.
- Do not feel like you have to use every feature of the TPL. Some features are not recommended for most situations (AttachedToParent tasks, for example). Standardize on the minimal feature set you can get away with.
- Use Timers Correctly
To schedule a method to execute after a certain timespan and optionally at regular intervals thereafter, use the System.Threading.Timer object. You should not use mechanisms like Thread.Sleep that block the thread for the specified amount of time, though we will see below that it can be useful in some situations.
The following example demonstrates how to use a timer by specifying a callback method and passing in two timeout values. The first value is the time until the timer fires for the first time and the second value is how often to repeat it thereafter. You can specify Timeout.Infinite (which has value -1) for either value. This example fires the timer only once, after 15 milliseconds.
private System.Threading.Timer timer;
public void Start()
{
this.timer = new Timer(TimerCallback, null, 15, Timeout.Infinite);
}
private void TimerCallback(object state)
{
// Do your work
}
Do not create an excessive number of timers. All Timers are serviced from a single thread in the thread pool. A huge number of Timers will cause delays in executing their callbacks. When the time comes due, the timer thread will schedule a work item to the thread pool, and it will be picked up by the next available thread. If you have a large number of tasks, queued work items, or high CPU usage, this means your Timers will not be accurate. In fact, they are guaranteed to never be more accurate than the operating system’s timer tick count, which is set to 15.625 milliseconds by default. This is the same value that determines thread quantum lengths. Setting a timeout value less than that will not get you the results you need. If you need more precision than 15 milliseconds, you have a few options:
- Reduce the operating system’s timer tick resolution. This can result in higher CPU usage and severely impact battery life, but may be justified in some situations. Note that changing this could have far reaching impacts like more context switches, higher system overhead, and worse performance in other areas.
- Spin in a loop, using a high-resolution timer (See Chapter 6) to measure elapsed time. This also uses more CPU and power, but is more localized.
- Call Thread.Sleep. This will block the thread, and is generally accurate in my testing, but there is no guarantee this will always work. On a highly loaded system, it is possible the thread could be context switched out and you will not get it back until after your desired interval.
When you use a Timer, be aware of a classic race condition. Consider the code:
private System.Threading.Timer timer;
public void Start()
{
this.timer = new Timer(TimerCallback, null, 15, Timeout.Infinite);
}
private void TimerCallback(object state)
{
// Do your work
this.timer.Dispose();
}
This code sets up a Timer to execute a callback in 15 milliseconds. The callback just disposes the timer object once it is done with it. This code is also likely to throw a NullReferenceException in TimerCallback. The reason is that it is very possible for the callback to execute before the Timer object is assigned to the this.timer field in the Start method. Thankfully, it is quite easy to fix:
this.timer = new Timer(TimerCallback, null, Timeout.Infinite,
Timeout.Infinite);
this.timer.Change(15, Timeout.Infinite);
- Ensure Good Startup Thread Pool Size
Just because you are not programming directly against the thread pool does not mean you do not need to understand how it works. In particular, you may need to give the thread pool some hints for how it should allocate threads and keep them ready.
The thread pool tunes itself over time, but at startup it has no history and will start in a default state. If your software is extremely asynchronous and uses a lot of CPU, then it may be hit with a steep startup cost as it waits for more threads to be created and become available. To reach the steady state sooner, you can tweak the startup parameters to maintain a minimum number of threads ready upon startup.
const int MinWorkerThreads = 25;
const int MinIoThreads = 25;
ThreadPool.SetMinThreads(MinWorkerThreads, MinIoThreads);
You do need to exercise caution here. If you are using Tasks then they will be scheduled based on the number of threads available for scheduling. If there are too many threads then the Tasks can become overscheduled, leading to less CPU efficiency, not more, as more context switching happens. The thread pool will still eventually switch to using an algorithm that can reduce the number of threads to below this number, if the work load is lighter.
You can also set a maximum with the SetMaxThreads method and this has the same risks.
To figure out how many threads you really need, leave this setting alone and analyze your app during its steady state using the ThreadPool.GetMaxThreads and ThreadPool.GetMinThreads methods, or by using performance counters to examine how many threads are in the process.
- Do Not Abort Threads
Terminating threads without their cooperation is a dangerous procedure. Threads have their own clean up to do and calling Abort on them does not allow a graceful shutdown. When you kill a thread, you leave portions of the application in an undefined state. It would be better to just crash the program, but ideally, just do a clean restart.
If you are using Tasks, as you should, then this will not be an issue for you. There is no API provided to force-terminate a Task.
- Do Not Change Thread Priorities
In general, it is a bad idea to change thread priorities. Windows schedules threads according to their priority. If high priority threads are always ready to run, then lower priority threads will be starved and rarely given a chance to run. By increasing a thread’s priority you are saying that its work must have priority over all other work, including other processes. This notion is not a safe part of a stable system.
It is more acceptable to lower a thread’s priority if it is doing something that can wait until all the normal-priority tasks have completed. One good reason to lower a thread’s priority is that you have detected a runaway thread doing an infinite loop. You cannot safely terminate threads, so the only way to get that thread and processor resource back is by restarting the process. Until you can shut down and do that cleanly, lowering the runaway thread’s priority is a reasonable mitigation. Note that even threads with lower priorities are still guaranteed to run after a while because Windows will increase their dynamic priority the longer it goes without executing. The exception is Idle priority (THREAD_PRIORITY_IDLE), which the operating system will only ever schedule if literally nothing else can run.
You may find a legitimate reason to increase thread priority, such as reacting to rare situations that require faster responses, but this should be used with care. Windows schedules threads agnostic of the process they belong to, so a high-priority thread from your process will run at the expense not only of your other threads, but all the other threads from other applications running on your system.
If you are using the thread pool, then any thread priority changes are reset every time the thread reenters the pool. If you are using Tasks and still manipulating the underlying thread, then keep in mind that the same thread can run multiple tasks before being placed back in the pool.
- Thread Synchronization and Locks
As soon as you start talking about multiple threads, the question of synchronization among those threads is going to appear. Synchronization is the practice of ensuring that only a single thread can access some shared state, such as a class’s field. Thread synchronization is usually accomplished with synchronization objects such as Monitor, Semaphore, ManualResetEvent, and others. In aggregate, these are sometimes referred to informally as locks, and the process of synchronizing in a specific thread as locking.
One of the fundamental truth of locks is: locking never improves performance. At best, it can be neutral, with a well-implemented synchronization primitive and no contention. A lock explicitly stops other threads from doing productive work, wasting CPU, increasing context switching time, and more. We tolerate this because the one thing more critical than raw performance is correctness. It does not matter how fast you calculate a wrong result!
Before attacking the problem of which locking apparatus to use, first consider some more fundamental principles.
- Do I Need To Care About Performance At All?
Validate that you actually need to care about performance in the first place. This goes back to the principles discussed in the first chapter. Not all code is equal in your application. Not all of it should be optimized to the nth degree. Typically, you start at the “inner loop”—the code that is most commonly executed or is most performance critical—and work outwards until the cost outweighs the benefit. There are many other areas in your code that are much less critical, performance-wise. In these situations, if you need a lock, take a lock and don’t worry about it.
Now, you do have to be careful here. If your non-critical piece of code is executing on a thread pool thread, and you block it for a significant amount of time, the thread pool could start injecting more threads to keep up with other requests. If a couple of threads do this once in a while, it’s no big deal. However, if you have lots of threads doing things like this, then it could become a problem because it wastes resources that should be going to real work. If you are running a program that processes a heavy, constant workload, then even parts of your program that are not performance-sensitive can negatively affect the system by context switching or perturbing the thread pool if you are not careful. As in all things, you must measure.
- Do I Need A Lock At All?
The most performant locking mechanism is one that is not there. If you can completely remove your need for thread synchronization, than you are in the best place as far as performance goes. This is the ideal, but it might not be easy. It usually means you have to ensure there is no writable shared state—each request through your application can be handled without regard to another request or any centralized volatile (read/write) data.
Be careful, though. It is easy to go overboard in the refactoring and make your code a spaghetti mess that no one (including you) can understand. Unless performance is really that critical and cannot be obtained any other way, you should not carry it that far. Make it asynchronous and independent, but make it clear.
If multiple threads are just reading from a variable (and there is no chance at all of any thread writing to it), then no synchronization is necessary. All threads can have unrestricted access. This is automatically the case for immutable objects like strings or immutable value types, but can be the case for any type of object if you ensure its immutability while multiple threads are reading it.
If you do have multiple threads writing to some shared variable, see if you can remove the need for synchronized access by converting usage to a local variable. If you can create a temporary copy to act on, no synchronization is necessary. This is especially important for repeated synchronized access. You will need to convert repeated access to a shared variable to repeated access of a local variable followed by a single shared access, as in the following simple example of multiple threads adding items to a shared collection.
object syncObj = new object();
var masterList = new List<long>();
const int NumTasks = 8;
Task[] tasks = new Task[NumTasks];
for (int i = 0; i < NumTasks; i++)
{
tasks[i] = Task.Run(()=>
{
for (int j = 0; j < 5000000; j++)
{
lock (syncObj)
{
masterList.Add(j);
}
}
});
}
Task.WaitAll(tasks);
This can be converted to the following:
object syncObj = new object();
var masterList = new List<long>();
const int NumTasks = 8;
Task[] tasks = new Task[NumTasks];
for (int i = 0; i < NumTasks; i++)
{
tasks[i] = Task.Run(()=>
{
var localList = new List<long>();
for (int j = 0; j < 5000000; j++)
{
localList.Add(j);
}
lock (syncObj)
{
masterList.AddRange(localList);
}
});
}
Task.WaitAll(tasks);
On my machine, the second code fragment takes less than half of the time as the first.
- Synchronization Preference Order
If you decide you do need some sort of synchronization, then understand that not all of them have equal performance or behavior characteristics. If performance is not critical, just use lock for simplicity and clarity. Using anything other than a lock should require some intense measurement to justify the additional complexity. In general, consider synchronization mechanisms in this order:
- No synchronization at all
- Simple Interlocked methods
- lock/Monitor class
- Asynchronous locks (see later in this chapter)
- Everything else
These are roughly in order of performance impact, but specific circumstances may dictate or preclude the use of some of them. For example, combining multiple Interlocked methods is not likely to outperform a single lock statement.
- Memory Models
Before discussing the details of thread synchronization, we must take a short detour into the world of memory models. The memory model is the set of the rules in a system (hardware or software) that govern how read and write operations can be reordered by the compiler or by the processor across multiple threads. You cannot actually change anything about the model, but understanding it is critical to having correct code in all situations.
A memory model is described as “strong” if it has an absolute restriction on reordering, which prevents the compiler and hardware from doing many optimizations. A “weak” model allows the compiler and processor much more freedom to reorder read and write instructions in order to get potentially better performance. Most platforms fall somewhere between absolutely strong and weak.
The ECMA standard (see http://www.writinghighperf.net/go/17) defines the minimum set of rules that the CLR must follow. It defines a very weak memory model, but a given implementation of the CLR may actually have a stronger model in place on top of it.
A specific processor architecture may also enforce a stronger memory model. For example, the x86/x64 architecture has a relatively strong memory model which will automatically prevent certain kinds of instruction reordering, but allows others. On the other hand, the ARM architecture has a relatively weak memory model. It is the JIT compiler’s responsibility to ensure that not only are machine instructions emitted in the proper order, but that special instructions are used to ensure that the processor itself doesn’t reorder instructions in a way to violate the CLR’s memory model.
The practical difference between x86/x64 and ARM architectures has significant impact on your code, particularly if you have bugs in thread synchronization. Because the JIT compiler under ARM is more free to reorder reads and writes than it is under x86/x64, certain classes of synchronization bugs can go completely undetected on x86/x64 and only become apparent when ported to ARM.
In some cases, the CLR will help cover these differences for compatibility’s sake, but it is good practice to ensure that the code is correct for the weakest memory model in use. The biggest requirement here is the correct use of volatile on state that is shared between threads. The volatile keyword is a signal to the JIT compiler that ordering matters for this variable. On x86/x64 it will enforce instruction ordering rules, but on ARM there will also be extra instructions emitted to enforce the correct semantics in the hardware. If you neglect volatile, the ECMA standard allows these instructions to be completely reordered and bugs could surface.
Other ways to ensure proper ordering of shared state is to use Interlocked or keep all accesses inside a full lock.
All of these methods of synchronization create what is called a memory barrier. Any reads that occur before that place in code may not be reordered after the barrier and any writes may not be reordered to be before the barrier. In this way, updates to variables are seen by all CPUs.
- Use volatile When Necessary
Consider the following classic example of an incorrect double-checked locking implementation that attempts to efficiently protect against multiple threads calling DoCompletionWork. It tries to avoid potentially expensive contentious calls to lock in the common case that there is no need to call DoCompletionWork.
private bool isComplete = false;
private object syncObj= new object();
// Incorrect implementation!
private void Complete()
{
if (!isComplete)
{
lock (syncObj)
{
if (!isComplete)
{
DoCompletionWork();
isComplete = true;
}
}
}
}
While the lock statement will effectively protect its inner block, the outer check of isComplete is simultaneously accessed by multiple threads with no protection. Unfortunately, updates to this variable may be out of order due to compiler optimizations allowed under the memory model, leading to multiple threads seeing a false value even after another thread has set it to true. It is actually worse than that, though: It is possible that isComplete could be set to true before DoCompletionWork() completes, which means the program could be in an invalid state if other threads are checking and acting on the value of isComplete. Why not always use a lock around any access to isComplete? You could do that, but this leads to higher contention and is a more expensive solution than is strictly necessary.
To fix this, you need to instruct the compiler to ensure that accesses to this variable are done in the right order. You do this with the volatile keyword. The only change you need is:
private volatile bool isComplete = false;
To be clear, volatile is for program correctness, not performance. In most cases it does not noticeably help or hurt performance. If you can use it, it is better than using a lock in any high-contention scenario, which is why the double-checked locking pattern is useful.
Double-checked locking is often used for the singleton pattern when you want the first thread that uses the value to initialize it. This pattern is encapsulated in .NET by using the Lazy<T> class, which internally uses the double-checked locking pattern. You should prefer to use Lazy<T> rather than implement your own pattern. See Chapter 6 for more information about using Lazy<T>.
- Use Interlocked Methods
Consider this code with a lock that is guaranteeing that only a single thread can execute the Complete method:
private bool isComplete = false;
private object completeLock = new object();
private void Complete()
{
lock(completeLock)
{
if (isComplete)
{
return;
}
isComplete = true;
}
...
}
You need two fields and a few lines of code to determine if you should even enter the method, which seems wasteful. Instead, use a simple call to the Interlocked.Increment method:
private int isComplete = 0;
private void Complete()
{
if (Interlocked.Increment(ref isComplete) == 1)
{
...
}
}
Or consider a slightly different situation where Complete may be called multiple times, but you want only to enter it based on some internal state, and then enter it only once.
enum State { Executing, Done };
private int state = (int)State.Executing;
private void Complete()
{
if (Interlocked.CompareAndExchange (ref state, (int)State.Done,
(int)State.Executing) == (int)State.Executing)
{
...
}
}
The first time Complete executes, it will compare the state variable against State.Executing and if they are equal replace state with the value State.Done. The next thread that executes this code will compare state against State.Executing, which will not be true, and CompareAndExchange will return State.Done, failing the if statement.
Interlocked methods translate into a single processor instruction and are atomic. They are perfect for this kind of simple synchronization. There are a number of Interlocked methods you can use for simple synchronization, all of which perform the operation atomically:
- Add—Adds two integers, replacing the first one with the sum and returning the sum.
- CompareAndExchange—Accepts values A, B, and C. Compares values A and C, and, if equal, replaces A with B, and returns original value. See the LockFreeStack example below.
- Increment—Adds one to the value and returns the new value.
- Decrement—Subtracts one from the value and returns the new value.
- Exchange—Sets a variable to a specified value and returns the original value.
All of these methods have multiple overloads for various data types.
Interlocked operations are memory barriers, thus they are not as fast as a simple write in a non-contention scenario.
As simple as they are, Interlocked methods can implement more powerful concepts such as lock-free data structures. But a word of caution: Be very careful when implementing your own data structures like this. The seductive words “lock-free” can be misleading. They are really a synonym for “repeat the operation until correct.” Once you start having multiple calls to Interlocked methods, it is possible to be less efficient than just calling lock in the first place. It can also be very difficult to get it right or performant. Implementing data structure like this is great for education, but in real code your default choice should always be to use the built-in .NET collections. If you do implement your own thread-safe collection, take great pains to ensure that it is not only 100% functionally correct, but that it performs better than the existing .NET choices. If you use Interlocked methods, ensure that they provide more benefit than a simple lock.
As an example (from the accompanying source in the LockFreeStack project), here is a simple implementation of a stack that uses Interlocked methods to maintain thread safety without using any of the heavier locking mechanisms.
class LockFreeStack<T>
{
private class Node
{
public T Value;
public Node Next;
}
private Node head;
public void Push(T value)
{
var newNode = new Node() { Value = value };
while (true)
{
newNode.Next = this.head;
if (Interlocked.CompareExchange(ref this.head, newNode,
newNode.Next)
== newNode.Next)
{
return;
}
}
}
public T Pop()
{
while (true)
{
Node node = this.head;
if (node == null)
{
return default(T);
}
if (Interlocked.CompareExchange(ref this.head, node.Next, node)
== node)
{
return node.Value;
}
}
}
}
This code fragment demonstrates a common pattern with implementing data structures or more complex logic using Interlocked methods: looping. Often, the code will loop, continually testing the results of the operation until it succeeds. In most scenarios, only a handful of iterations will be performed.
While Interlocked methods are simple and relatively fast, you will often need to protect more substantial areas of code and they will fall short (or at least be unwieldy and complex).
- Use Monitor (lock)
The simplest way to protect any code region is with the Monitor object, which in C# has a keyword equivalent.
This code:
object obj = new object();
bool taken = false;
try
{
Monitor.Enter(obj, ref taken);
}
finally
{
if (taken)
{
Monitor.Exit(obj);
}
}
is equivalent to this:
object obj = new object();
lock(obj)
{
...
}
The taken parameter is set to true if no exceptions occurred. This is guaranteed so that you can correctly call Exit.
In general, you should prefer using Monitor/lock versus other more complicated locking mechanisms until proven otherwise. Monitor is a hybrid lock in that it first tries to spin in a loop for a while before it enters a wait state and gives up the thread. This makes it ideal for places where you anticipate little or short-lived contention.
Monitor also has a more flexible API that can be useful if you have optional work to do if you cannot acquire the lock immediately.
object obj = new object();
bool taken = false;
try
{
Monitor.TryEnter(obj, ref taken);
if (taken)
{
// do work that needs the lock
}
else
{
// do something else
}
}
finally
{
if (taken)
{
Monitor.Exit(obj);
}
}
In this case, TryEnter returns immediately, regardless of whether it got the lock. You can test the taken variable to know what to do. There are also overloads that accepts a timeout value.
- Which Object To Lock On?
The Monitor class takes a synchronization object as its argument. You can pass any object into this method, but care should be taken in selecting which object to use. If you pass in a publically visible object, there is a possibility that another piece of code could also use it as a synchronization object, even if the synchronization is not needed between those two sections of code. If you pass in a complex object, you run the risk of functionality in that class taking a lock on itself. Both of these situations can lead to poor performance or worse: deadlocks.
To avoid this, it is almost always wise to allocate a plain, private object specifically for your locking purposes, as in the examples above.
On the other hand, I have seen situations where explicit synchronization objects can lead to problems, particularly when there were an enormous number of objects and the overhead of an extra field in the class was burdensome. In this case, you can find some other safe object that can serve as a synchronization object, or better, refactor your code to not need the lock in the first place.
There are some classes of objects you should never use as a sync object for Monitor. These include any MarshalByRefObject (a proxy object that will not protect the underlying resource), strings (which are interned and shared unpredictably), or value type (which will be boxed every time you lock on it, prohibiting any synchronization from happening at all).
- Asynchronous Locks
Starting in .NET 4.5, there is some interesting functionality that may expand to other types in the future. The SemaphoreSlim class has a WaitAsync method that returns a Task. Instead of blocking on a wait, you can schedule a continuation on the Task that will execute once the semaphore permits it to run. There is no entry into kernel mode and no blocking. When the lock is no longer contended, the continuation will be scheduled like a normal Task on the thread pool. Usage is the same as for any other Tasks.
To see how it works, consider first an example using the standard, blocking wait mechanisms. This sample code (from the WaitAsync project in the sample code) is rather silly, but demonstrates how the threads hand off control via the semaphore.
class Program
{
const int Size = 256;
static int[] array = new int[Size];
static int length = 0;
static SemaphoreSlim semaphore = new SemaphoreSlim(1);
static void Main(string[] args)
{
var writerTask = Task.Run((Action)WriterFunc);
var readerTask = Task.Run((Action)ReaderFunc);
Console.WriteLine("Press any key to exit");
Console.ReadKey();
}
static void WriterFunc()
{
while (true)
{
semaphore.Wait();
Console.WriteLine("Writer: Obtain");
for (int i = length; i < array.Length; i++)
{
array[i] = i * 2;
}
Console.WriteLine("Writer: Release");
semaphore.Release();
}
}
static void ReaderFunc()
{
while (true)
{
semaphore.Wait();
Console.WriteLine("Reader: Obtain");
for (int i = length; i >= 0; i--)
{
array[i] = 0;
}
length = 0;
Console.WriteLine("Reader: Release");
semaphore.Release();
}
}
}
Each thread loops indefinitely while waiting for the other thread to finish its loop operation. When the Wait method is called, that thread will block until the semaphore is released. In a high-throughput program, that blocking is extremely wasteful and can reduce processing capacity and increase the size of the thread pool. If the block lasts long enough, a kernel transition may occur, which is yet more wasted time.
To use WaitAsync, replace the reader/writer threads with these implementations:
static void WriterFuncAsync()
{
semaphore.WaitAsync().ContinueWith(_ =>
{
Console.WriteLine("Writer: Obtain");
for (int i = length; i < array.Length; i++)
{
array[i] = i * 2;
}
Console.WriteLine("Writer: Release");
semaphore.Release();
}).ContinueWith(_=>WriterFuncAsync());
}
static void ReaderFuncAsync()
{
semaphore.WaitAsync().ContinueWith(_ =>
{
Console.WriteLine("Reader: Obtain");
for (int i = length; i >= 0; i--)
{
array[i] = 0;
}
length = 0;
Console.WriteLine("Reader: Release");
semaphore.Release();
}).ContinueWith(_=>ReaderFuncAsync());
}
Note that the loop was removed in lieu of a chain of continuations that will call back into these methods. It is logically recursive, but not actually so because each continuation starts the stack fresh with a new Task.
No blocking occurs with WaitAsync, but this is not free functionality. There is still overhead from increased Task scheduling and function calls. If your program schedules a lot of Tasks, the increased scheduling pressure may offset the gains from avoiding the blocking call. If your locks are extremely short-lived (they just spin and never enter kernel mode) or rare, then it may be better to just block for the few microseconds it takes to get through the lock. On the other hand, if you need to execute a relative long-running task under a lock, this may be the better choice because the overhead of a new Task is less than the time you will block the processor otherwise. You will need to carefully measure and experiment.
If this pattern is interesting to you, see Steven Toub’s series of articles of asynchronous coordination primitives at http://www.writinghighperf.net/go/21 which covers a few additional types and patterns.
- Other Locking Mechanisms
There are many locking mechanisms you can use, but you should prefer to stick with as few as you can get away with. As in many things, but especially multithreading, the simpler the better.
If you know that a lock is extremely short-lived (tens of cycles) and want to guarantee that it never enters a wait state, then you can use a SpinLock. It will just spin a loop until the contention is done. In most cases, Monitor, which spins first, then enters a wait if necessary, is a better default choice.
private SpinLock spinLock = new SpinLock();
private void DoWork()
{
bool taken = false;
try
{
spinLock.Enter(ref taken);
}
finally
{
if (taken)
{
spinLock.Exit();
}
}
}
In general, avoid other locking mechanisms if you can. They are usually not nearly as performant as the simple Monitor. Objects like ReaderWriterLockSlim, Semaphore, Mutex, or other custom synchronization objects definitely have their place, but they are often complex and error-prone.
Completely avoid ReaderWriterLock—it is deprecated and should never be used for any reason.
If there is a *Slim version of a synchronization object, prefer it to the non-Slim version. The *Slim versions are all hybrid locks which means they implement some form of spinning before they enter a kernel transition, which is much slower. *Slim locks are much better when the contention is expected to be low and brief.
For example, there is both a ManualResetEvent class and a ManualResetEventSlim class, and there is an AutoResetEvent class, but there is no AutoResetEventSlim class. However, you can use SemaphoreSlim with the initialCount parameter set to one for the same effect.
- Concurrent Collections
There are a handful of collections provided with .NET that allow concurrent access from multiple threads safely. They are all in the System.Collections.Concurrent namespace and include:
- ConcurrentBag<T>—unordered collection
- ConcurrentDictionary<TKey, TValue>—key/value pairs
- ConcurrentQueue<T>—first-in/first-out queue
- ConcurrentStack<T>—last-in/first-out stack
Most of these are implemented internally using Interlocked or Monitor synchronization primitives and I encourage you to examine their implementations using an IL reflection tool.
They are convenient, but you need to be careful—every single access to the collection involves synchronization. Often, that is overkill and could harm your performance if there is a lot of contention. If you have necessarily “chatty” read/write access patterns to the collection, this low-level synchronization may make sense.
This section will cover a few alternatives to concurrent collections that may simplify your locking requirements. See Chapter 6 for a discussion of collections in general, including those listed here, particularly for a description of the APIs unique to these collections, which can be tricky to get right.
- Lock at A Higher Level
If you find yourself updating or reading many values at once, you should probably use a non-concurrent collection and handle the locking yourself at a higher level (or find a way to not need synchronization at all—see the next section for one idea).
The granularity of your synchronization mechanism has an enormous impact on overall efficiency. In many cases, making batch updates under a single lock is better than taking a lock for every single small update. In my own informal testing, I found that inserting an item into a ConcurrentDictionary is about 2x slower than with a standard Dictionary.
You will have to measure and judge the tradeoff in your application.
Also note that sometimes you need to lock at a higher level to ensure that application-specific constraints are honored. Consider the classic example of bank transfer between two accounts. The balance of both accounts must be changed individually of course, but the transaction only makes sense when considered together. Database transactions are a related concept. A single row insertion by itself may be atomic, but to guarantee integrity of your operations, you may need to utilize transactions to ensure higher-level atomicity.
- Replace an Entire Collection
If your data is mostly read-only then you can safely use a non-concurrent collection when accessing it. When it is time to update the collection, you can generate a new collection object entirely and just replace the original reference once it is loaded, as in the following example:
private volatile Dictionary<string, MyComplexObject> data = new
Dictionary<string, MyComplexObject>();
public Dictionary<string, MyComplexObject> Data { get { return data; } }
private void UpdateData()
{
var newData = new Dictionary<string, MyComplexObject>();
newData["Foo"] = new MyComplexObject();
...
data = newData;
}
Notice the volatile keyword which ensures that data will be updated correctly for all threads.
If a consumer of this class needed to access the Data property multiple times and did not want this object swapped out from under it to a new one, it can create a local copy of the reference and use that instead of the original property.
private void CreateReport(DataSource source)
{
Dictionary<string, MyComplexObject> data = source.Data;
foreach(var kvp in data)
{
...
}
}
This is not foolproof, and it does make your code a little more complex. You also need to balance this replacement against the cost of incurring a full garbage collection when the new collection is allocated. As long the reload is a rare occurrence and you can handle the occasional full GC, this may be the right pattern for many scenarios. See Chapter 2 for more information on avoiding full GCs.
- Copy Your Resource Per-Thread
If you have a resource that is lightweight, not thread-safe, and is used a lot on multiple threads, consider marking it [ThreadStatic]. A classic example is the Random class in .Net, which is not thread-safe.
This example comes from the MultiThreadRand sample project:
[ThreadStatic]
static Random safeRand;
static void Main(string[] args)
{
int[] results = new int[100];
Parallel.For(0, 5000,
i =>
{
// thread statics are not initialized
if (safeRand == null) safeRand = new Random();
var randomNumber = safeRand.Next(100);
Interlocked.Increment(ref results[randomNumber]);
});
}
You should always assume that statics marked as [ThreadStatic] are not initialized at the time of first use—.NET will only initialize the first one. The rest will have default values (usually null).
- Measurement
One of the most difficult types of debugging to do is any issue relating to multiple threads. Spending the effort to get the code right in the first place pays huge dividends later as a lack of time spent debugging.
On the other hand, finding sources of contention in .NET is trivially easy and there are some nice advanced tools out there that can help with some general multithreading analysis.
- Performance Counters
In the Process category exists the Thread Count counter.
In the Synchronization category, you can find the following counters:
- Spinlock Acquires/sec
- Spinlock Contentions/sec
- Spinlock Spins/sec
Under System, you can find the Context Switches/sec counter. It is difficult to know what the ideal value of this counter should be. You can find many conflicting opinions about this (I have commonly seen a value of 300 being normal, with 1,000 being too high), so I believe you should view this counter mostly in a relative sense and track how it changes over time, with large increases potentially indicating problems in your app.
.NET provides a number of counters in the .NET CLR LocksAndThreads category, including:
- # of current logical Threads—The number of managed threads in the process.
- # of current physical Threads—The number of OS threads assigned to the process to execute the managed threads, excluding those used only by the CLR.
- Contention Rate / sec—Important for detecting “hot” locks that you should refactor or remove.
- Current Queue Length—The number of threads blocked on a lock.
- ETW Events
Of the following events, ContentionStart and ContentionStop are the most useful. The others may be interesting in a situation where the concurrency level is changing in unexpected ways and you need insights into how the thread pool is behaving.
- ContentionStart—Contention has started. For hybrid locks, this does not count the spinning phase, only when when it enters an actual blocked state. Fields include:
- Flags—0 for managed, 1 for native.
- ContentionStop—Contention has ended.
- ThreadPoolWorkerThreadStart—A thread pool thread has started. Fields include:
- ActiveWorkerThreadCount—Number of worker thread available, both those processing work and those waiting for work.
- RetiredWorkerThreadCount—Number of worker threads being held in reserve if more threads are needed later.
- ThreadPoolWorkerThreadStop—A thread pool thread has ended. Fields are same as for ThreadPoolWorkerThreadStart.
- IOThreadCreate—An I/O thread has been created. Fields include:
- Count—Number of I/O threads in pool.
See http://www.writinghighperf.net/go/22 for more information about thread-related ETW events.
- Which Locks Have The Highest Contention?
During development, you can use the Visual Studio profiler to collect this data. Launch the Profile Wizard and select the concurrency option.
For collecting data on a destination machine, I find PerfView is easiest. You can use the sample program HighContention to see this. Run the program and collect .NET events using PerfView. Once the .etl file is ready to view, open the Any Stacks view and look for an entry named “Event Microsoft-Windows-DotNETRuntime/Contention/Start” and double-click it. It will open a view that looks like this:
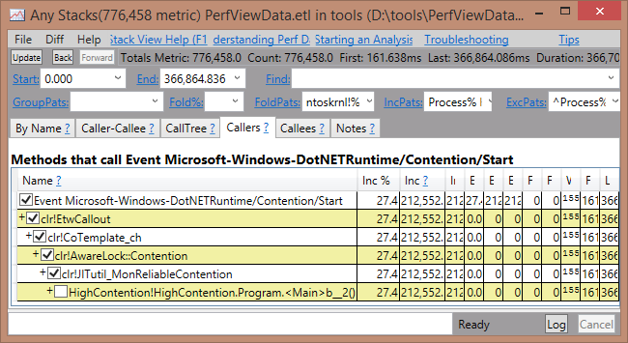
Figure 4-1. PerfView easily shows which stacks are leading to higher contention for all managed synchronization objects.
This will show you the stacks that caused lock contention. In this case, you can see that the contention comes from an anonymous method inside Main.
- Where Are My Threads Blocking On I/O?
You can use PerfView to collect information about threads such as when they enter various states. This gives you more accurate information about overall wall-clock time spent in your program, if it is not using the CPU. However, be aware that turning on this option slows down your program considerably.
In PerfView’s Collection dialog, check the “Thread Times” box as well as the other defaults (Kernel, .NET, and CPU events).
Once collection is done, you will see a Thread Times node in the results tree. Open that and look at the By Name tab. You should see two main categories at the top: BLOCKED_TIME and CPU_TIME. Double-click BLOCKED_TIME to see the callers for that group. Your view will look something like this:
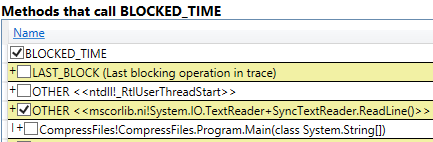
Figure 4-2. A PerfView stack of blocked time, caused by a call to the TextReader.ReadLine method.
This shows some blocked time in TextReader.ReadLine which is being called from the Main method.
- Visualizing Tasks and Threads with Visual Studio
Visual Studio ships with a tool called the Concurrency Visualizer. This tool captures the same type of events that PerfView does, but shows them in a graphical form so that you can see exactly what all the Tasks and threads do in your application. It can tell you when Tasks start and stop, whether a thread is blocked, doing CPU work, or waiting on I/O and a lot more.
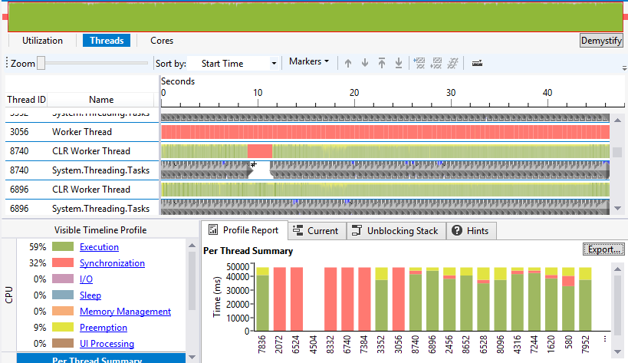
Figure 4-3. Visual Studio's Thread Times view combines threads, tasks, CPU time, blocked time, interrupts, and more into a single correlated timeline.
It is important to note that capturing this type of information can significantly degrade the application’s performance, as an event will be recorded every time a thread changes state, which is extremely frequent.
- Summary
Use multiple threads when you need to avoid blocking the UI thread, parallelize work on multiple CPUs, or avoid wasting CPU capacity by blocking threads waiting for I/O to complete. Use Tasks instead of pure threads. Do not wait on Tasks, but schedule a continuation to be executed when the Task is complete. Simplify Task syntax with async and await.
Never block on I/O. Always use asynchronous APIs when reading from or writing to Streams. Use continuations to schedule a callback for when the I/O completes.
Try to avoid locking if at all possible, even if you need to significantly restructure your code. When needed, use the simplest locking possible. For simple state changes, use Interlocked methods. For short or rarely contended sections, use lock/Monitor and use a private field as the synchronization object. If you have a highly contended critical section that lasts more than a few milliseconds, consider using the asynchronous locking pattern like SemaphoreSlim.