
Chapter 1. Basic Operations on Delta Lakes
In the previous chapter, we discussed the progression of databases to data lakes, the importance of data reliability, and how to easily and effectively use Apache Spark™ to build scalable and performant data processing pipelines. However, when building these data processing pipelines expressing the processing logic only solves half of the end-to-end problem of building a pipeline. For a data practitioner, the ultimate goal for building pipelines is to efficiently query the processed data and get insights from it. For a query to be efficient, the processed data must be saved in a storage format and system such that the query engine can efficiently read the necessary (preferably minimal) data to compute the query result. In addition, data is almost never static - it has to be continuously added, updated, corrected, and deleted when needed. It is important that the storage system and the processing engine can work together to provide atomic transactionality on the quality of the final result despite all the (possibly concurrent) read and write operations on the data.
Concisely, Delta Lake is an open-source storage layer that brings ACID transactions to Apache Spark™ and big data workloads. With Delta Lake providing atomic transactionality for your data, this allows you - the data practitioner - to need to only focus on building your data processing pipelines by expressing the processing.
What is Delta Lake?
As previously noted, over time, there have been different storage solutions built to solve this problem of data quality - from databases to data lakes. The transition from databases to data lakes had the benefit of decoupling business logic from storage as well as the ability to independently scale compute and storage. But lost in this transition was ensuring data reliability. Providing data reliability to data lakes led to the development of Delta Lake.
Built by the original creators of Apache Spark, Delta Lake was designed to combine the best of both worlds for online analytical workloads (i.e., OLAP style): the transactional reliability of databases with the horizontal scalability of data lakes.
Delta Lake is a file-based, open-source storage format that provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. It runs on top of your existing data lakes and is compatible with Apache Spark and other processing engines. Specifically, it provides the following features:
- ACID guarantees
-
Delta Lake ensures that all data changes written to storage are committed for durability and made visible to readers atomically. In other words, no more partial or corrupted files! We will discuss more on the acid guarantees as part of the transaction log later in this chapter.
- Scalable data and metadata handling:
-
Since Delta Lake is built on data lakes, all reads and writes using Spark or other distributed processing engines are inherently scalable to petabyte-scale. However, unlike most other storage formats and query engines, Delta Lake leverages Spark to scale out all the metadata processing, thus efficiently handling metadata of billions of files for petabyte-scale tables. We will discuss more on the transaction log later in this chapter.
- Audit History and Time travel
-
The Delta Lake transaction log records details about every change made to data providing a full audit trail of the changes. These data snapshots enable developers to access and revert to earlier versions of data for audits, rollbacks, or to reproduce experiments. We will dive further into this topic in Chapter 3: Time Travel with Delta.
- Schema enforcement and schema evolution
-
Delta Lake automatically prevents the insertion of data with an incorrect schema, i.e. not matching the table schema. And when needed, it allows the table schema to be explicitly and safely evolved to accommodate ever-change data. We will dive further into this topic in Chapter 4 focusing on schema enforcement and evolution.
- Support for deletes updates, and merge
-
Most distributed processing frameworks do not support atomic data modification operations on data lakes. Delta Lake supports merge, update, and delete operations to enable complex use cases including but not limited to change-data-capture (CDC), slowly-changing-dimension (SCD) operations, and streaming upserts. We will dive further into this topic in Chapter 5: Data modifications in Delta.
- Streaming and batch unification
-
A Delta Lake table has the ability to work both in batch and as a streaming source and sink. The ability to work across a wide variety of latencies ranging from streaming data ingest to batch historic backfill to interactive queries all just work out of the box. We will dive further into this topic in Chapter 6: Streaming Applications with Delta.
For more information, refer to the VLDB20 paper: Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores.
How to start using Delta Lake
Delta Lake is well integrated within the Apache Spark™ ecosystem so the easiest way to start working with Delta Lake is to use it with Apache Spark. In this section, we will focus on three of the most straightforward mechanisms:
-
Using Delta Lake via local Spark shells
-
Leveraging GitHub or Maven
-
Using Databricks Community Edition
Using Delta Lake via local Spark shells
The Delta Lake package is available as with the --packages option when working with Apache Spark shells. This option is the simplest option when working with a local version of Spark
# Using Spark Packages with PySpark shell ./bin/pyspark --packages io.delta:delta-core_2.12:1.0 # Using Spark Packages with spark-shell ./bin/spark-shell --packages io.delta:delta-core_2.12:1.0 # Using Spark Packages with spark-submit ./bin/spark-submit --packages io.delta:delta-core_2.12:1.0 # Using Spark Packages with spark-shell ./bin/spark-sql --packages io.delta:delta-core_2.12:1.0
Leveraging GitHub or Maven
In this book, we will not focus on building standalone applications with Apache Spark. For a good tutorial, please refer to Chapter 2 in Learning Spark 2nd Edition or building your own self-contained application.
As you build them, you can access Delta Lake via:
Using Databricks Community Edition
Aside from using your local machine or building your own self-contained application, you can try all of our examples in this book on the Databricks Community Edition for free (Fig. 2-15). As a learning tool for Apache Spark, the Community Edition has many tutorials and examples worthy of note. As well as writing your own notebooks in Python, R, Scala, or SQL, you can also import other notebooks, including Jupyter notebooks.

Figure 1-1. Databricks Community Edition
To get an account, go to https://databricks.com/try, and follow the instructions to use the Community Edition for free.
Basic operations
In this section, we will cover the basic operations of building Delta tables. As of writing this, Delta has full APIs in three languages commonly used in the big data ecosystem: SQL, Scala, and Python. It can store data in file systems like HDFS and cloud object stores including S3 and ADLS gen2. It is designed to be written primarily by Spark applications and can be read by many open-source data engines like Spark SQL, Hive, Presto (or Trino), Ballista (Rust), and several enterprise products like AWS Athena, Azure Synapse, BigQuery, and Dremio.
Creating your first Delta table
Let’s create our first Delta table! Like databases, to create our Delta table we can first create a table definition and define the schema or, like data lakes simply write a Spark DataFrame to storage in the Delta format.
Writing your Delta table
When creating a Delta table, you are writing files to some storage (e.g. file system, cloud object stores). All of the files together stored in a directory of a particular structure (more on this later) make up your table. Therefore, when we create a Delta table, we are in fact writing files to some storage location. For example, the following Spark code snippet takes an existing Spark DataFrame and writes it in the Apache Parquet storage format in the folder location /data using the Spark DataFrame API.
dataframe.write.format("parquet").save("/data")
Note
For more information on the Spark DataFrame API, a good reference is Learning Spark 2nd Edition.
With one simple modification of the preceding code snippet, you can now create a Delta table.

Figure 1-2. Instead of parquet, simply say delta
Let’s see how that looks in code by using Apache Spark to create a Delta table from a DataFrame. In the following code example, we will first create the Spark DataFrame data and then use the write method to save the table to storage.
%python# Create data DataFramedata=spark.range(0,5)# Write the data DataFrame to /delta locationdata.write.format("delta").save("/delta")
%scala// Create data DataFramevaldata=spark.range(0,5)// Write the data DataFrame to /delta locationdata.write.format("delta").save("/delta")
It is important to note that in most production environments when you are working with large amounts of data, it is important to partition your data. The following example partitions your data by date (a commonly followed best practice):
%python# Write the Spark DataFrame to Delta table partitioned by datedata.write.partitionBy("date").format("delta").save("/delta")
%scala// Write the Spark DataFrame to Delta table partitioned by datedata.write.partitionBy("date").format("delta").save("/delta")
If you already have an existing Delta table and would like to append or overwrite data to your table, include the mode method in your statement.
%python># Append new data to your Delta tabledata.write.format("delta").mode("append").save("/delta")# Overwrite your Delta tabledata.write.format("delta").mode("overwrite").save("/delta")
%scala// Append new data to your Delta tabledata.write.format("delta").mode("append").save("/delta")// Overwrite your Delta tabledata.write.format("delta").mode("overwrite").save("/delta")
Reading your Delta table
Similar to writing your Delta table, you can use the DataFrame API to read the same files from your Delta table.
%python# Read the data DataFrame from the /delta locationspark.read.format("delta").load("/delta").show()
%scala// Read the data DataFrame from the /delta locationspark.read.format("delta").load("/delta").show()
You can also read the table using SQL by specifying the file location after specifying delta.
%sqlSELECT*FROMdelta.`/delta`
The output of this table can be seen below.
+---+| id|+---+| 4|| 2|| 3|| 0|| 1|+---+
Reading your metastore defined Delta table
In the previous sections, we have been reading our Delta tables directly from the file system. But how would you read a metastore defined Delta table? For example, instead of reading our Delta table in SQL using the file path:
%sqlSELECT*FROMdelta.`/delta`
how would you read using a metastore-defined table such as:
%sqlSELECT*FROMmyTable
To do this, you would need to first define the table within the metastore using the saveAsTable method or a CREATE TABLE statement.
%python# Write the data DataFrame to the metastore defined as myTabledata.write.format("delta").saveAsTable("myTable")
%scala// Write the data DataFrame to the metastore defined as myTabledata.write.format("delta").saveAsTable("myTable")
Note, when using the saveAsTable method, you will save the Delta table files into a location managed by the metastore (e.g. /user/hive/warehouse/myTable). If you want to use SQL or control the location of your Delta table, then you initially save it using the save method where you specify the location (e.g. /delta) and then create the table using the following SQL statements.
%sql-- Create a table in the metastoreCREATETABLEmyTable(idINTEGER)USINGDELTALOCATION"/delta"
As noted previously, it will be important to partition your large tables.
%sqlCREATETABLEid(dateDATEidINTEGER)USINGDELTAPARTITIONBYdateLOCATION"/delta"
Note, the LOCATION property that points to the underlying files that make up your Delta table.
Unpacking the Transaction Log
In the previous section where we discuss the basic operations of Delta Lake, many readers may have been under the impression that there was more to ensuring data reliability from a usability or user experience perspective. The basic operations of Delta Lake appear to be simply Spark SQL statements. We have alluded to improved functionality such as time travel (chapter 3) and DML operations (chapter 5) but this may not seem apparent from those basic operations. But the real benefit of Delta Lake is that the operations themselves provide ACID transactional protection. And to understand how Delta Lake provides those protections, we need to first unpack and understand the transaction log.
For example, when running this notebook in Databricks Community Edition, note that there is little difference between the Parquet and Delta tables generated from the same source.

Figure 1-3. Difference between parquet and Delta tables
The key difference is the _delta_log folder which is the Delta transaction log. This transaction log is key to understanding Delta Lake because it is the underlying infrastructure for many of its most important features including but not limited to ACID transactions, scalable metadata handling, and time travel. In this section, we’ll explore what the Delta Lake transaction log is, how it works at the file level, and how it offers an elegant solution to the problem of multiple concurrent reads and writes.
What Is the Delta Lake Transaction Log?
The Delta Lake transaction log (also known as the Delta Log) is an ordered record of every change that has ever been performed on a Delta Lake table since its inception.
Single Source of Truth
Delta Lake is built on top of Apache Spark™ in order to allow multiple readers and writers of a given table to all work on the table at the same time. To show users correct views of the data at all times, the Delta Lake transaction log serves as a single source of truth – the central repository that tracks all changes that users make to the table. You could compare this transaction log feature in Delta Lake as a single source of truth to the .git directory in a git-managed source code repository.
The concept of a single source of truth is important because, over time, processing jobs will fail in your data lake. The result is that processing jobs or tasks will leave partial files that do not get cleaned up. Subsequent processing or queries will not be able to ascertain which files should or should not be included in their queries.

Figure 1-4. Partial file example
For example, the preceding diagram represents a common data lake processing scenario.
| Time Period | Table |
| t0 | The table is represented by 2 Parquet files |
| t1 | A processing job (job 1) extracts files 3 and 4 and writes them to disk. But due to some error (e.g. network hiccup, storage temporary offline, etc.), an incomplete part of file 3 and none of file 4 are written to storage. There is no automated mechanism to clean up this data; this partial of 3.parquet can be queried within your data lake. |
| t2 | A new version of the same processing job (job 1 v2) is executed and this time it completes its job successfully with 3'.parquet and 4.parquet. But because the partial 3.parquet exists alongside with 3'.parquet there will be double counting. |
By using a transaction log to track which files are valid, we can avoid the preceding scenario. Thus, when a user reads a Delta Lake table for the first time or runs a new query on an open table that has been modified since the last time it was read, Spark checks the transaction log to see what new transactions have posted to the table, and then updates the end user’s table with those new changes. This ensures that a user’s version of a table is always synchronized with the master record as of the most recent query and that users cannot make divergent, conflicting changes to a table.
Let’s repeat the same partial file example except for this time we run this on a Delta table with the Delta transaction log.

Figure 1-5. Partial file example with Delta transaction log
| Time Period | Table | Transaction Log |
| t0 | The table is represented by 2 Parquet files | Version 0: The transaction log records the two files that make up the Delta table. |
| t1 | A processing job (job 1) extracts files 3 and 4 and writes them to disk. But due to some error (e.g. network hiccup, storage temporary offline, etc.), an incomplete part of file 3 and none of file 4 are written to storage. There is no automated mechanism to clean up this data; this partial of 3.parquet can be queried within your data lake. |
Because the job fails, the transaction was NOT committed to the transaction log. No new files are recorded. Any queries against the Delta table at this time will be provided a list of the initial two files and Spark will only query these two files even if other files are in the folder. |
| t2 | A new version of the same processing job (job 1 v2) is executed and this time it completes its job successfully with 3'.parquet and 4.parquet. But because the partial 3.parquet exists alongside with 3'.parquet there will be double counting. |
Version 1: Because the job completes successfully, a new transaction is committed with the two new files. Thus any queries against the table will be provided with these four files. Because a new transaction is committed, it is saved as a new version (i.e. V1 instead of V0). |
The exact same actions happened as in the previous example but this time the Delta transaction log provides atomicity and ensures data reliability.
The Implementation of Atomicity on Delta Lake
One of the four properties of ACID transactions, atomicity, guarantees that operations (like an INSERT or UPDATE) performed on your data lake either complete fully or don’t complete at all. Without this property, it’s far too easy for a hardware failure or a software bug to cause data to be only partially written to a table, resulting in messy or corrupted data.
The transaction log is the mechanism through which Delta Lake is able to offer the guarantee of atomicity - if it’s not recorded in the transaction log, it never happened. By only recording transactions that execute fully and completely, and using that record as the single source of truth, the Delta Lake transaction log allows users to reason about their data, and have peace of mind about its fundamental trustworthiness, at petabyte scale.
How Does the Transaction Log Work?
This section provides internals of how the Delta transaction log works.
Breaking Down Transactions Into Atomic Commits
Whenever a user performs an operation to modify a table (e.g., INSERT, DELETE, UPDATE or MERGE), Delta Lake breaks that operation down into a series of discrete steps composed of one or more of the actions below.
- Update metadata
-
Updates the table’s metadata including but not limited to changing the table’s name, schema or partitioning.
- Add file
-
adds a data file to the transaction log.
- Remove file
-
removes a data file from the transaction log.
- Set transaction
-
Records that a structured streaming job has committed a micro-batch with the given ID.
- Change protocol
-
enables new features by switching the Delta Lake transaction log to the newest software protocol.
- Commit info
-
Contains information around the commit, which operation was made, from where, and at what time.
Those actions are then recorded in the transaction log as ordered, atomic units known as commits.
Delta Transaction Log Protocol
In this section, we describe how the Delta transaction log brings ACID properties to large collections of data, stored as files, in a distributed file system or object-store. The protocol was designed with the following goals in mind:
- Serializable ACID Writes
-
multiple writers can concurrently modify a Delta table while maintaining ACID semantics. (Watch this video on how each concurrent writes are handled)
- Snapshot Isolation for Reads
-
readers can read a consistent snapshot of a Delta table, even when multiple writers are concurrently writing.
- Scalability to billions of partitions or files
-
queries against a Delta table can be planned on a single machine or in parallel.
- Self-describing
-
all metadata for a Delta table is stored alongside the data. This design eliminates the need to maintain a separate metastore just to read the data and also allows static tables to be copied or moved using standard filesystem tools.
- Support for incremental processing
-
readers can tail the Delta log to determine what data has been added in a given period of time, allowing for efficient streaming.
Logstore
Think about the existence of the delta files for a second. The logs, versions, and files that are being generated must exist somewhere, some system or store for files. LogStore is the general interface for all critical file system operations required to read and write the Delta transaction log. Because most storage systems do not provide atomicity guarantees out-of-the-box, Delta Lake transactional operations go through the LogStore API instead of accessing the storage system directly.
-
Any file written through this store must be made visible, atomically. In other words, it should be visible in its entirety or not visible at all. It should not generate partial files.
-
Only one writer must be able to create a file at the final destination. This is because many processes can occur simultaneously and to ensure decent speed, many writers write to their own files in parallel.
-
The Logstore offers ACID consistent listing of files
The Delta Lake Transaction Log at the File Level
As noted previously, when a Delta table is created, that table’s transaction log is automatically created in the _delta_log subdirectory. As they make changes to that table, those changes are recorded as ordered, atomic commits in the transaction log. Each commit is written out as a JSON file, starting with 000000.json. Additional changes to the table generate subsequent JSON files in ascending numerical order so that the next commit is written out as 000001.json, the following as 000002.json, and so on. Each numeric JSON file increment represents a new version of the table.
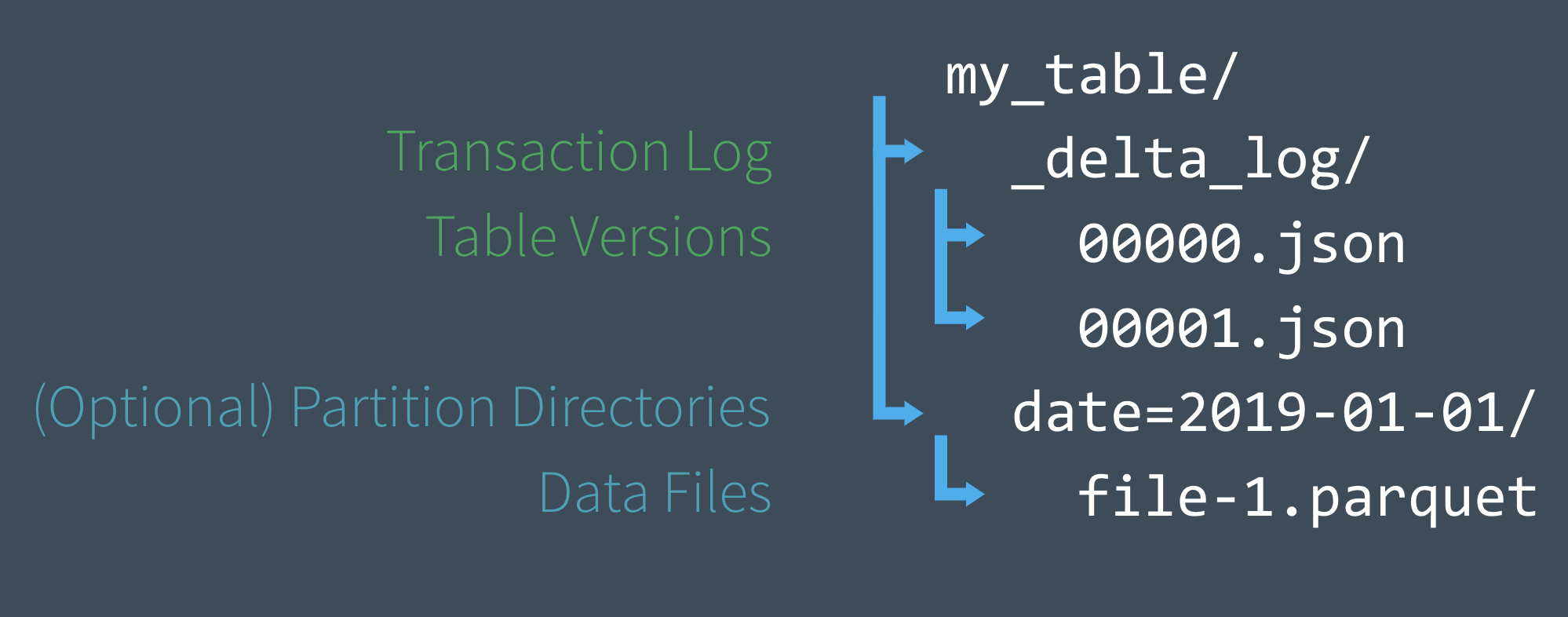
Figure 1-6. Delta on disk
Implementing Atomicity
An important thing to understand is the transaction log is the single source of truth for your Delta table. So any reader that’s reading through your Delta table, will take a look at the transaction log first. Therefore changes to the table are stored as ordered atomic units called commits.
To continue the above example, we add additional records to our Delta table from the data files 1.parquet and 2.parquet. That transaction would automatically be added to the transaction log, saved to disk as commit 000000.json. Then, perhaps we change our minds and decide to remove those files (e.g., run a DELETE from table operation) and add a new file instead (3.parquet) through an INSERT operation. Those actions would be recorded as the next commit - and table version - in the transaction log, as 000001.json, as shown in the following diagram.

Figure 1-7. Implementing atomicity in Delta
Even though 1.parquet and 2.parquet are no longer part of our Delta Lake table, their addition and removal are still recorded in the transaction log because those operations were performed on our table – despite the fact that they ultimately canceled each other out. Delta Lake still retains atomic commits like these to ensure that in the event we need to audit our table or use “time travel” (to discuss in chapter 3) to see what our table looked like at a given point in time, we could do so accurately.
To provide context, let’s continue with our notebook and read the JSON file that makes up the first transaction (version 1) inserting data into our Delta table.
>%python# Read the transaction log of version 1j0=spark.read.json("/.../000001.json")
%scala// Read the transaction log of version 1valj0=spark.read.json("/.../000001.json")

Figure 1-8. Reviewing the transaction log structure
The transaction contains many pieces of information stored as strings or columns within the transaction log JSON. Let’s focus on the commit, add, and CRC pieces.
Commit Information
The Delta transaction log commits metadata can be read using the following code snippets.
%python# Commit Informationdisplay(j0.select("commitInfo").where("commitInfo is not null"))
%scala// Commit Informationdisplay(j0.select("commitInfo").where("commitInfo is not null"))
The following is a text version of the JSON output read from the preceding command.
clusterId: "0127-045215-pined152"
isBlindAppend: true
isolationLevel: "WriteSerializable"
notebook: {"notebookId": "8476282"}
operation: "STREAMING UPDATE"
operationMetrics: {"numAddedFiles": "1", "numOutputBytes": "492", "numOutputRows": "0", "numRemovedFiles": "0"}
operationParameters: {"epochId": "0", "outputMode": "Append", "queryId": "892c1abd-581f-4c0f-bbe7-2c386feb3dbd"}
readVersion: 0
timestamp: 1603581133495
userId: "100599"userName: "denny[dot]lee[@]databricks.com"
The metadata contains a lot of interesting information, but let’s focus on the ones around the file system.
| metadata | description |
| operation | The type of operation that is happening, in this case, data was inserted via Spark Structured streaming writeStream job (i.e. STREAMING UPDATE) |
| operationMetrics | Notes how many files were added (numAddedFiles), removed (numRemovedFiles), output rows (numOutputRows), and output bytes (numOutputBytes) |
| operationParameters | From the files perspective, whether this operation would append or overwrite the data within the table. |
| readVersion | The table version associated with this transaction commit. |
| clusterID, notebook | Identifies which Databricks cluster and notebook that executed this commit |
| userID, userName | ID and name of the user executing this operation |
Add Information
The Delta transaction log add metadata can be read using the following code snippets.
%python# Commit Informationdisplay(j0.select("add").where("add is not null"))
%scala// Commit Informationdisplay(j0.select("add").where("add is not null"))
The following is a text version of the JSON output read from the preceding command.
dataChange:truemodificationTime:1603581134000path:"part-00000-95648a41-bf33-4b67-9979-1736d07bef0e-c000.snappy.parquet"size:492stats:"{"numRecords":0,"minValues":{},"maxValues":{},"nullCount":{}}"
The metadata is particularly important in that it lists the file that makes up the table version.
| metadata | description |
| path | A list of the file(s) added to a Delta table per a committed transaction |
| size | The size of the file(s) |
| stats | The statistics stored in the transaction log to help the reader understand the size and scope of data files that need to be read. |
Typically when reading files from storage, Spark (and other distributed processing frameworks) will simply read all of the files in a folder. Prior to reading the files, it must first list the files (listFrom) which can be extremely inefficient especially on cloud object stores.
But in the case of Delta Lake, the files are listed directly within the transaction log itself. So instead of Spark (or any other processing framework that can read the Delta transaction log), listing all the files, the transaction log provides all of the files that are associated with a table version. Therefore Spark can just query the files directly through their individual paths which can have a significant performance improvement than listFrom especially for internet-scale systems with petabytes of data.
CRC file
For each transaction, there is both a JSON file as well as a CRC file. This file contains key statistics for the table version (i.e. transaction) allowing Delta Lake to help Spark optimize its queries.
To review this data, let’s just review the file directly from the file system using the following command.
%sh head /dbfs/ml/loan_by_state/_delta_log/00000000000000000001.crc
Below are the results from this query
{"tableSizeBytes":1855, "numFiles":2, "numMetadata":1, "numProtocol":1, "numTransactions":1}
The two most notable pieces of metadata are:
-
tableSizeInBytes -
The table size in bytes so Spark and Delta Lake can optimize their queries
-
numFiles -
Important for Spark especially in scenarios like dynamic partition pruning
As you can read from the preceding high-level primer, the Delta Lake transaction log tracks the files and other metadata to ensure both atomic transactions and data reliability.
Note
Spark does not eagerly remove the files from disk, even though we removed the underlying data files from our table. Users can delete the files that are no longer needed using VACUUM (more on this later under the Table Utilities section).
Quickly Recomputing State With Checkpoint Files
Prior to this, our focus is that of a single transaction log in the form of JSON files. But for large-scale systems or any streaming system, this would result in creating the “small-file” problem where it becomes ever more inefficient to query the transaction log folder (i.e. _delta_log subdirectory).
To alleviate this issue, Delta Lake creates a checkpoint file in Parquet format after it creates the 10th commits (i.e. transaction).

Figure 1-9. Create transaction log after every 10th commit
These checkpoint files save the entire state of the table at a point in time – in native Parquet format that is quick and easy for Spark to read. In other words, they offer the Spark reader a sort of “shortcut” to fully reproducing a table’s state that allows Spark to avoid reprocessing what could be thousands of tiny, inefficient JSON files.
When recomputing the state of the table, Spark will read and cache the available JSON files that make up the transaction log. For example, if there have been only three committed operations or commits to the table (including the table creation), Spark will read all three files and cache the results into memory (i.e. cache version 2).

Figure 1-10. Spark caching after the third commit
Instead of continually reading the transaction log for this information, all of the Spark readers requesting data from this table can simply reference the cached copy of Delta’s state. As more commits are performed against the Delta table, more JSON files will be added to the _delta_log folder.

Figure 1-11. Spark caching after the eight commit
To continue this example, let’s say this table five additional commits, then Spark will cache version 7 of the data. Note, at this point, Spark will list all of the transactions from version 0 instead of reading from version 2 to ensure that earlier transactions have completed.

Figure 1-12. Spark caching after the 13th commit including checkpoint creation
As noted earlier, Delta Lake will create a checkpoint file (0000010.checkpoint.parquet) after the 10th commit. Delta Lake will still listFrom version 0 to avoid late transactions and cache version 12.
To read the checkpoint file, run the following statement.
%python# Review the transaction log checkpoint filechkpt0=spark.read.parquet("/ml/loan_by_state/_delta_log/000010.checkpoint.parquet")
%scala// Review the transaction log checkpoint filevalchkpt0=spark.read.parquet("/ml/loan_by_state/_delta_log/000010.checkpoint.parquet")
The metadata you will read is a union of all of the previous transactions. This becomes apparent when you read the query for the add information.
%python# Add Informationdisplay(chkpt0.select("add").where("add is not null"))
%scala// Add Informationdisplay(chkpt0.select("add").where("add is not null"))

Figure 1-13. Add information in the checkpoint file
In addition to the checkpoint file being in Parquet format (thus Spark can read it even faster) and containing all of the transactions prior to it, notice how the stats in the original JSON file were in string format.
stats: "{"numRecords":7,"minValues":{"addr_state":"IA","count":3,"stream_no":3},"maxValues":{"addr_state":"TX","count":9,"stream_no":3},"nullCount":{"addr_state":0,"count":0,"stream_no":0}}"
As part of the checkpoint creation process, there is a stats_parsed column that contains the statistics as nested columns instead of strings.
stats_parsed:{"numRecords": 7, "minValues": { "addr_state": "IA", "count": 3, "stream_no": 3 }, "maxValues": { "addr_state": "TX", "count": 9, "stream_no": 3 }, "nullCount": { "addr_state": 0, "count": 0, "stream_no": 0 }}
By using nested columns instead of strings, Spark can read the statistics significantly faster especially when it needs to read all of the files created for petabyte-scale data lakes.

Figure 1-14. Spark caching after the 15th commit including checkpoint creation
As it is important to note that once the Parquet checkpoint file has been created, subsequent listFrom calls are from the checkpoint file instead of going back to version 0. Thus after the 15 commits, Delta will cache version 14 but need only to listFrom the version 10 checkpoint file.
Dealing With Multiple Concurrent Reads and Writes
Now that we understand how the Delta Lake transaction log works at a high level, let’s talk about concurrency. So far, our examples have mostly covered scenarios in which users commit transactions linearly, or at least without conflict. But how does Delta Lake deal with multiple concurrent reads and writes? Because Delta Lake is powered by Apache Spark, the expectation is that multiple users concurrently modify a single table. To do this, Delta Lake employs optimistic concurrency control.
What Is Optimistic Concurrency Control?
Optimistic concurrency control is a method of dealing with concurrent transactions that assumes that transactions made to a table by different users can complete without conflicting with one another. It is incredibly fast because when dealing with petabytes of data, there’s a high likelihood that users will be working on different parts of the data altogether, allowing them to complete non-conflicting transactions simultaneously.
When working with tables, as long as different clients are modifying different parts of the table (e.g. different partitions) or performing actions that do not conflict (e.g. two clients reading from the table), those operations do not conflict so we can optimistically let them all complete their task. But for situations where clients modify the same parts of the table concurrently, Delta Lake has a protocol to resolve this.
Solving conflicts optimistically
Ensuring serializability
Another key piece that Delta requires for consistent guarantees is mutual exclusion. We need to agree on the order of changes, even when there are multiple writers and this provides a guarantee in databases called serializability. The fact that even though things are happening concurrently, you could play them as if they happened in a synchronous ordered manner.
For example, we have user 1 reading 000000.json

Figure 1-15. User 1 reading
And we have user2 that reads 000001.json
.

Figure 1-16. Users 1 and 2 reading the transaction log concurrently
As you’re trying to commit 000002.json, user2 two wins and user1 takes a look and sees that, 000002.json is already there. Due to this requirement of mutual exclusion, it will have to say, “Oh this commit failed” and let me try to commit 000003.json instead.

Figure 1-17. Ensuring serializability
Applying Optimistic Concurrency Control in Delta
In order to offer ACID transactions, Delta Lake has a protocol for figuring out how commits should be ordered (known as the concept of serializability in databases) and determining what to do in the event that two or more commits are made at the same time.
Delta Lake handles these cases by implementing a rule of mutual exclusion, then attempting to solve any conflict optimistically. This protocol allows Delta Lake to deliver on the ACID principle of isolation, which ensures that the resulting state of the table after multiple, concurrent writes is the same as if those writes had occurred serially, in isolation from one another.
In general, the process proceeds like this:
-
Record the starting table version.
-
Record reads/writes.
-
Attempt a commit.
-
If someone else wins, check whether anything you read has changed.
-
Repeat.
For example, if two users read from the same table and then both attempt to insert data at the same time.

Figure 1-18. Solving conflicts optimistically
-
Delta Lake records the starting table version of the table (version 0) that is read prior to making any changes.
-
Users 1 and 2 both attempt to append some data to the table at the same time. Here, we’ve run into a conflict because only one commit can come next and be recorded as
000001.json. -
Delta Lake handles this conflict with the concept of mutual exclusion, i.e. only one user can successfully commit
000001.json. User 1’s commit is accepted, while User 2’s is rejected. -
Rather than throw an error for User 2, Delta Lake prefers to handle this conflict optimistically. It checks to see whether any new commits have been made to the table, and updates the table silently to reflect those changes, then simply retries User 2’s commit on the newly updated table (without any data processing), successfully committing
000002.json.
In the vast majority of cases, this reconciliation happens silently, seamlessly, and successfully. However, in the event that there’s an irreconcilable problem that Delta Lake cannot solve optimistically (for example, if User 1 deleted a file that User 2 also deleted), the only option is to throw an error.
As a final note, since all of the transactions made on Delta Lake tables are stored directly to storage, this process satisfies the ACID property of durability, meaning it will persist even in the event of system failure.
Multiversion Concurrency Control
How all of this works within the file system is that Delta’s transactions are implemented using Multiversion Concurrency Control (MVCC). It is a concurrency control method commonly used by relational database management systems to provide concurrent access to the database (and its tables) within the context of transactions. As Delta Lake’s data objects and log are immutable, Delta Lake utilizes MVCC to both protect existing data, i.e. provides transactional guarantees between writes, as well as speed up query and write performance. It also has the benefit of making it straightforward to query a past snapshot of the data, as is common in MVCC implementations.
Under this mechanism, writes operate in three stages:
- Read
-
First the system reads the latest available version of the table to identify which rows need to be modified.
- Write
-
Stages all the changes by writing new data files. Note, all changes whether inserts or modifications are in the form of writing new files.
- Validate and commit
-
Before committing the changes, it checks whether the proposed changes conflict with any other changes that may have been concurrently committed since the snapshot that was read. If there are no conflicts, all the staged changes are committed as a new versioned snapshot, and the write operation succeeds. However, if there are conflicts, the write operation fails with a concurrent modification exception rather than corrupting the table as would happen with the write operation on a Parquet table.
As a table changes, Delta’s MVCC algorithm keeps multiple copies of the data around rather than immediately replacing files that contain records that are being updated or removed. MVCC allows serializability and snapshot isolation for consistent views of a state of a table so that the readers continue to see a consistent snapshot view of the table that the Apache Spark job started with, even when a table is modified during a job. They can efficiently query a snapshot by using the transaction log to selectively choose which data files to process when there are concurrent modifications being done by writers.
Therefore, writers modify a table in two phases:
-
First, they optimistically write out new data files or updated copies of existing ones.
-
Then, they commit, creating the latest atomic version of the table by adding a new entry to the log. In this log entry, they record which data files to logically add and remove, along with changes to other metadata about the table.
Other Use Cases
There are many interesting use cases that can be implemented because of Delta Lake’s transaction log. Below are a couple of examples that we will dive into in chapter 3.
Time Travel
Every table is the result of the sum total of all of the commits recorded in the Delta Lake transaction log – no more and no less. The transaction log provides a step-by-step instruction guide, detailing exactly how to get from the table’s original state to its current state.
Therefore, we can recreate the state of a table at any point in time by starting with an original table, and processing only commits made prior to that point. This powerful ability is known as “time travel,” or data versioning, and can be a lifesaver in any number of situations. For more information, read the blog post Introducing Delta Time Travel for Large Scale Data Lakes, or refer to the Delta Lake time travel documentation.
Data Lineage and Debugging
As the definitive record of every change ever made to a table, the Delta Lake transaction log offers users a verifiable data lineage that is useful for governance, audit, and compliance purposes. It can also be used to trace the origin of an inadvertent change or a bug in a pipeline back to the exact action that caused it. Users can run DESCRIBE HISTORY to see metadata around the changes that were made.
Diving further into the transaction log
In this section, we dove into the details of how the Delta Lake transaction log works, including:
-
What the transaction log is, how it’s structured, and how commits are stored as files on disk.
-
How the transaction log serves as a single source of truth, allowing Delta Lake to implement the principle of atomicity.
-
How Delta Lake computes the state of each table – including how it uses the transaction log to catch up from the most recent checkpoint.
-
Using optimistic concurrency control to allow multiple concurrent reads and writes even as tables change.
-
How Delta Lake uses mutual exclusion to ensure that commits are serialized properly, and how they are retried silently in the event of a conflict.
For more information, refer to:
-
Diving into Delta Lake: Unpacking the Transaction Log (blog)
-
Diving into Delta Lake: Unpacking the Transaction Log (video tech talk)
-
Diving into Delta Lake: Unpacking the Transaction Log v2 (Data + AI Summit EU 2020 session)
Table Utilities
If there is a central theme for reviewing the transaction log, MVCC, optimistic concurrency control, and the underlying file system when working with Delta Lake is that it is about the manipulation of the underlying files that make up the Delta table. In this section, we provide an overview of the various table utilities to simplify operations.
Review table history
You can retrieve information on the operations, user, timestamp, and so on for each write to a Delta table by running the history command. This history will tell us things like what type of write occurred (append, merge, delete, etc.), was it a blind append, was it restricted to a specific partition, and provides operational metrics on the amount of data written. All of this information is interesting, but the operational metrics provide the most insight into how your table is changing, showing how many files, rows, and bytes were added or removed.
Note, the operations are returned in reverse chronological order and by default, table history is retained for 30 days.
%sql-- Review history by Delta table file pathDESCRIBEHISTORYdelta.`/ml/loan_by_state`;-- Review history by Delta table defined in the metastore as `loan_by_state`DESCRIBEHISTORYloan_by_state;-- Review last 5 operations by Delta table defined in the metastore as `loan_by_state`DESCRIBEHISTORYloan_by_stateLIMIT5;
%pythonfromdelta.tablesimport*deltaTable=DeltaTable.forPath(spark,“/ml/loan_by_state”)# get the full history of the tablefullHistoryDF=deltaTable.history()# get the last 5 operationslast5OperationsDF=deltaTable.history(5)
%scalaimportio.delta.tables._valdeltaTable=DeltaTable.forPath(spark,pathToTable)// get the full history of the tablevalfullHistoryDF=deltaTable.history()// get the last 5 operationsvallastOperationDF=deltaTable.history(5)
The following is a screenshot of the full history of the Delta table stored in `/ml/loan_by_state` from this notebook.

Figure 1-19. Describe the history of a Delta table
Note:
-
Some of the columns may be nulls because the corresponding information may not be available in your environment.
-
Columns added in the future will always be added after the last column.
-
For the most current reference, refer to Delta Lake history schema and operation metric keys.
We will dive further into the application of table history to time travel in Chapter 3: Time Travel with Delta.
Vacuum History
Over time, more files will accumulate into your Delta table; many of the older files may no longer be needed because they represent previously overwritten versions of data (e.g. UPDATE, DELETE, etc.). Therefore, you can remove files no longer referenced by a Delta table and are older than the retention threshold by running the VACUUM command on the table. Important note, VACUUM is not triggered automatically. When it is triggered, the default retention threshold for the files is 7 days, i.e. no longer referenced files older than 7 days will be removed.
%sql-- vacuum files in a path-based table by default retention thresholdVACUUMdelta.'/data/events'-- vacuum files by metastore defined table by default retention thresholdVACUUMeventsTable-- vacuum files by metastore defined table that are no longer required older than 100 hours oldVACUUMeventsTableRETAIN100hours-- dry run: get the list of files to be deletedVACUUMeventsTableDRYRUN
%pythonfromdelta.tablesimport*# vacuum files in path-based tablesdeltaTable=DeltaTable.forPath(spark,pathToTable)# vacuum files in metastore-based tablesdeltaTable=DeltaTable.forName(spark,tableName)# vacuum files in path-based table by default retention thresholddeltaTable.vacuum()# vacuum files not required by versions more than 100 hours olddeltaTable.vacuum(100)
%scalaimportio.delta.tables._#vacuumfilesinpath-basedtablesvaldeltaTable=DeltaTable.forPath(spark,pathToTable)#vacuumfilesinmetastore-basedtablesvaldeltaTable=DeltaTable.forName(spark,tableName)#vacuumfilesinpath-basedtablebydefaultretentionthresholddeltaTable.vacuum()#vacuumfilesnotrequiredbyversionsmorethan100hoursolddeltaTable.vacuum(100)
Configure Log and Data History
Log history
How much history your Delta table retains is configurable per table using the config spark.databricks.delta.logRetentionDuration, defaulting to 30 days. The Delta Transaction Log is cleaned up during new commits to the table if the logs have passed the set retention period. This is done so that the Delta Log does not grow indefinitely, but the Delta Log only contains information about what files are in the table.
In conjunction with the Log retention period, there are also the data files to consider. Every time data is changed in a Delta table, there are old files marked for deletion and new files added. While the Delta Log is cleaned up automatically on write, data files must be deleted explicitly with a call to the vacuum API. VACUUM can be quite slow on cloud object storage but needs very little resources, so it makes sense to schedule this separately to run on some cadence, e.g. weekly.
Data history
The config spark.databricks.delta.deletedFileRetentionDuration controls how long ago the files were marked for deletion before they are deleted by VACUUM. The default here is 7 days, as an application must actively call the API for the files to be deleted.
Parallel deletion of files during vacuum
When using VACUUM, to configure Spark to delete files in parallel (based on the number of shuffle partitions) set the session configuration "spark.databricks.delta.vacuum.parallelDelete.enabled" to "true“.
Warning
We do not recommend that you set a retention interval shorter than 7 days because old snapshots and uncommitted files can still be in use by concurrent readers or writers to the table. If vacuum cleans up active files, concurrent readers can fail or, worse, tables can be corrupted when vacuum deletes files that have not yet been committed.
Delta Lake has a safety check to prevent you from running a dangerous vacuum command. If you are certain that there are no operations being performed on this table that take longer than the retention interval you plan to specify, you can turn off this safety check by setting the Apache Spark configuration property spark.databricks.delta.retentionDurationCheck.enabled to false. You must choose an interval that is longer than the longest-running concurrent transaction and the longest period that any stream can lag behind the most recent update to the table.
Retrieve Delta table details
DESCRIBE DETAIL functionality allows you to review the table metadata including (but not limited to) table size, schema, partition columns, and other metrics on file and file sizes. You can use the table name or file path to specify the Delta table as demonstrated below.
%sql-- Describe detail using Delta file pathDESCRIBEDETAILdelta.`/ml/loan_by_state`;-- Describe detail using metastore-defined Delta tableDESCRIBEDETAILloan_by_state;

Figure 1-20. Describe Delta table details
Below is a transposed view of these values.
| Column name | value |
| format | delta |
| id | 18ec29e5-7837-4c5f-a2ca-f05892b6298b |
| name | loan_by_state |
| description | null |
| location | dbfs://ml/loan_by_state |
| createdAt | 2021-02-03T05:17:00.146+0000 |
| lastModified | 2021-02-03T05:26:37.000+0000 |
| partitionColumns | [] |
| numFiles | 292 |
| sizeInBytes | 308386 |
| properties | {"delta.checkpoint.writeStatsAsStruct”: “true"} |
| minReaderVersion | 1 |
| minWriterVersion | 2 |
For the current schema of the columns described by DESCRIBE DETAIL, refer to Detail schema.
Note, while the following metadata queries are not specific to Delta Lake, they are helpful when working with metastore-defined tables.
DESCRIBE TABLE
Describe Table returns the basic metadata information of a table. The metadata information includes column name, column type and column comment. Optionally you can specify a partition spec or column name to return the metadata pertaining to a partition or column respectively.
Display detailed information about the specified columns, including the column statistics collected by the following command. Note, this command is applicable to only metastore-defined tables.
%sqlDESCRIBETABLEloan_by_state;#result
+---------------+---------+-------+| col_name|data_type|comment|+---------------+---------+-------+| addr_state| string| || count| bigint| || stream_no| int| || || || # Partitioning| | ||Not partitioned| | |+---------------+---------+-------+
Along with the basic metadata information and partitioning, DESCRIBE TABLE EXTENDED returns detailed table information such as parent database, table name, location of table, provider, table properties, etc.
%sqlDESCRIBETABLEEXTENDEDloan_by_state;
+--------------------+--------------------+-------+| col_name| data_type|comment|+--------------------+--------------------+-------+| addr_state| string| || count| bigint| || stream_no| int| || | | || # Partitioning| | || Not partitioned| | || | | ||# Detailed Table ...| | || Name|denny_db.loan_by_...| || Location|dbfs:/ml/loan_by_...| || Provider| delta| || Table Properties|[delta.checkpoint...||+--------------------+--------------------+-------+
For the current schema of the columns described by DESCRIBE TABLE, refer to Spark SQL Guide > DESCRIBE TABLE.
Generate a manifest file
To allow non-Spark systems to query Delta Lake without querying the transaction log, you can create a manifest file that those systems will query. To learn more about how to configure systems like Presto and Athena to read a Delta table, jump to Chapter 9: Integrating with other engines.
The following code generates the manifest file itself.
%sql-- Generate manifestGENERATEsymlink_format_manifestFORTABLEdelta.`<path-to-delta-table>`
%python# Generate manifestdeltaTable=DeltaTable.forPath(<path-to-delta-table>)deltaTable.generate("symlink_format_manifest")
%scala// Generate manifestvaldeltaTable=DeltaTable.forPath(<path-to-delta-table>)deltaTable.generate("symlink_format_manifest")
The preceding command creates the following file if the <path-to-delta-table> is defined as /ml/loan-by-state.
$/ml/loan-by-state.delta/_symlink_format_manifest
Convert a Parquet table to a Delta table
Converting an existing Parquet table to a Delta table in-place is straightforward. This command lists all the files in the directory, creates a Delta Lake transaction log that tracks these files, and automatically infers the data schema by reading the footers of all Parquet files. If your data is partitioned, you must specify the schema of the partition columns as a DDL-formatted string (that is, <column-name1> <type>, <column-name2> <type>, ...).
%sql-- Convert non partitioned parquet table at path '<path-to-table>'CONVERTTODELTAparquet.`<path-to-table>`-- Convert partitioned Parquet table at path '<path-to-table>' and partitioned by integer columns named 'part' and 'part2'CONVERTTODELTAparquet.`<path-to-table>`PARTITIONEDBY(partint,part2int)
%pythonfromdelta.tablesimport*# Convert non partitioned parquet table at path '<path-to-table>'deltaTable=DeltaTable.convertToDelta(spark,"parquet.`<path-to-table>`")# Convert partitioned parquet table at path '<path-to-table>' and partitioned by integer column named 'part'partitionedDeltaTable=DeltaTable.convertToDelta(spark,"parquet.`<path-to-table>`","part int")
%scalaimportio.delta.tables._// Convert non partitioned Parquet table at path '<path-to-table>'valdeltaTable=DeltaTable.convertToDelta(spark,"parquet.`<path-to-table>`")// Convert partitioned Parquet table at path '<path-to-table>' and partitioned by integer columns named 'part' and 'part2'valpartitionedDeltaTable=DeltaTable.convertToDelta(spark,"parquet.`<path-to-table>`","part int, part2 int")
Some important notes:
-
If a Parquet table was created by Structured Streaming, the listing of files can be avoided by using the
_spark_metadatasub-directory as the source of truth for files contained in the table by setting the SQL configurationspark.databricks.delta.convert.useMetadataLogtotrue. -
Any file not tracked by Delta Lake is invisible and can be deleted when you run a vacuum. You should avoid updating or appending data files during the conversion process. After the table is converted, make sure all writes go through Delta Lake.
Convert a Delta table to a Parquet table
In case you need to convert a Delta table to parquet you can follow the following steps:
-
If you have performed Delta Lake operations that can change the data files (for example, delete or merge), run
VACUUMwith a retention of 0 hours to delete all data files that do not belong to the latest version of the table. -
Delete the
_delta_logdirectory in the table directory.
Restore a table version
You can restore your Delta table to a previous version. As noted in the previous Review table history section, a Delta table internally maintains historic versions of the table that enable it to be restored to an earlier state.
%sql-- restore version 9 of metastore defined Delta tableINSERTOVERWRITEINTOloan_by_stateSELECT*FROMloan_by_stateVERSIONASOF9
Note
The RESTORE command is currently only available on Databricks
If you’re using Databricks, you can also use the RESTORE command to simplify this process.
%sqlRESTORETABLEloan_by_stateTOVERSIONASOF9RESTORETABLEdelta.`/ml/loan_by_state/`TOTIMESTAMPASOF9
%pythonfromdelta.tablesimport*# path-based Delta tablesdeltaTable=DeltaTable.forPath(spark,`/ml/loan_by_state/`)# metastore-based tablesdeltaTable=DeltaTable.forName(spark,`loan_by_state`)# restore table to version 9deltaTable.restoreToVersion(9)
%scalaimportio.delta.tables._// path-based Delta tablesvaldeltaTable=DeltaTable.forPath(spark,`/ml/loan_by_state/`)// metastore-based tablesvaldeltaTable=DeltaTable.forName(spark,`loan_by_state`)// restore table to version 9deltaTable.restoreToVersion(9)
Clone your Delta Tables
Table cloning or creating copies of tables in a data lake or data warehouse has several practical uses. But, given the expansive volume of data in tables in a data lake and the rate of its growth, making physical copies of tables is an expensive operation. Using CLONE makes the process simpler and cost-effective with the help of table clones.
What are clones anyway?
Clones are replicas of a source table at a given point in time. They have the same metadata as the source table: same schema, constraints, column descriptions, statistics, and partitioning. However, they behave as a separate table with a separate lineage or history. Any changes made to clones only affect the clone and not the source. Any changes that happen to the source during or after the cloning process also do not get reflected in the clone due to snapshot isolation. As of this writing, there are two types of clones: shallow or deep.
Note
The CLONE command is currently only available on Databricks
Shallow Clones
A shallow (also known as Zero-Copy) clone only duplicates the metadata of the table being cloned; the data files of the table itself are not copied. This type of cloning does not create another physical copy of the data resulting in minimal storage costs. Shallow clones are inexpensive and can be extremely fast to create. These clones are not self-contained and depend on the source from which they were cloned as the source of data. If the files in the source that the clone depends on are removed, for example with VACUUM, a shallow clone may become unusable. Therefore, shallow clones are typically used for short-lived use cases such as testing and experimentation.
Deep Clones
Shallow clones are great for short-lived use cases, but some scenarios require a separate and independent copy of the table’s data. A deep clone makes a full copy of the metadata and data files of the table being cloned. In that sense, it is similar in functionality to copying with a CTAS command (CREATE TABLE.. AS… SELECT…). But it is simpler to specify since it makes a faithful copy of the original table at the specified version and you don’t need to re-specify partitioning, constraints, and other information as you have to do with CTAS. In addition, it is much faster, robust, and can work in an incremental manner against failures.
With deep clones, we copy additional metadata, such as your streaming application transactions and COPY INTO transactions, so you can continue your ETL applications exactly where it left off on a deep clone.
Where do clones help?
There are many scenarios where you need a copy of your datasets – for exploring, sharing, or testing ML models or analytical queries. Below are some example use cases.
Testing and experimentation with a production table
When users need to test a new version of their data pipeline they often have to rely on sample test datasets that are not representative of all the data in their production environment. Data teams may also want to experiment with various indexing techniques to improve the performance of queries against massive tables. These experiments and tests cannot be carried out in a production environment without risking production data processes and affecting users.
It can take many hours or even days, to spin up copies of your production tables for a test or a development environment. Add to that, the extra storage costs for your development environment to hold all the duplicated data – there is a large overhead in setting a test environment reflective of the production data. With a shallow clone, this is trivial:
%sql-- Shallow clone tableCREATETABLEdelta.`/some/test/location`SHALLOWCLONEprod.events
%python# Shallow clone tableDeltaTable.forName("spark","prod.events").clone("/some/test/location",isShallow=True)
%scala// Shallow clone tableDeltaTable.forName("spark","prod.events").clone("/some/test/location",isShallow=true)
After creating a shallow clone of your table in a matter of seconds, you can start running a copy of your pipeline to test out your new code, or try optimizing your table in different dimensions to see how you can improve your query performance, and much more. These changes will only affect your shallow clone, not your original table.
Staging major changes to a production table
Sometimes, you may need to perform some major changes to your production table. These changes may consist of many steps, and you don’t want other users to see the changes which you’re making until you’re done with all of your work. A shallow clone can help you out here:
%sql-- Create a shallow cloneCREATETABLEtemp.staged_changesSHALLOWCLONEprod.events;-- Test out deleting table from shallow clone tableDELETEFROMtemp.staged_changesWHEREevent_idisnull;-- Update shallow clone tableUPDATEtemp.staged_changesSETchange_date=current_date()WHEREchange_dateisnull;...-- Perform your verifications
Once you’re happy with the results, you have two options. If no other change has been made to your source table, you can replace your source table with the clone. If changes have been made to your source table, you can merge the changes into your source table.
%sql-- If no changes have been made to the sourceREPLACETABLEprod.eventsCLONEtemp.staged_changes;-- If the source table has changedMERGEINTOprod.eventsUSINGtemp.staged_changesONevents.event_id<=>staged_changes.event_idWHENMATCHEDTHENUPDATESET*;-- Drop the staged tableDROPTABLEtemp.staged_changes;
Machine Learning result reproducibility
Training machine learning models is typically an iterative process. Throughout this process of optimizing the different parts of the model, data scientists need to assess the accuracy of the model against a fixed dataset. This is hard to do in a system where the data is constantly being loaded or updated. A snapshot of the data used to train and test the model is required. This snapshot allows the results of the ML model to be reproducible for testing or model governance purposes. We recommend leveraging Time Travel to run multiple experiments across a snapshot; an example of this in action can be seen in Machine Learning Data Lineage with MLflow and Delta Lake. Once you’re happy with the results and would like to archive the data for later retrieval, for example, next Black Friday, you can use deep clones to simplify the archiving process. MLflow integrates really well with Delta Lake, and the auto logging feature (mlflow.spark.autolog() ) will tell you, which version of the table was used to run a set of experiments.
# Run your ML workloads using Python and thenDeltaTable.forName(spark,"feature_store").cloneAtVersion(128,"feature_store_bf2020")
Data Migration
A massive table may need to be moved to a new, dedicated bucket or storage system for performance, disaster recovery, or governance reasons. The original table will not receive new updates going forward and will be deactivated and removed at a future point in time. Deep clones make the copying of massive tables more robust and scalable.
%sql-- Data migration using deep cloneCREATETABLEdelta.`zz://my-new-bucket/events`CLONEprod.events;ALTERTABLEprod.eventsSETLOCATION'zz://my-new-bucket/events';
With deep clones, since we copy your streaming application transactions and COPY INTO transactions, you can continue your ETL applications from exactly where it left off after this migration!
Data Sharing
It is common for users from different departments to look for data sets that they can use to enrich their analysis or models and you may want to share your data with them. But rather than setting up elaborate pipelines to move the data to yet another store, it is often easier and economical to create a copy of the relevant data set for users to explore and test the data to see if it is a fit for their needs without affecting your own production systems. Here deep clones significantly simplify this process.
%sql-- The following code can be scheduled to run at your convenience-- for data sharingCREATEORREPLACETABLEdata_science.eventsCLONEprod.events;
Data Archiving
For regulatory or archiving purposes all data in a table needs to be preserved for a certain number of years, while the active table retains data for a few months. If you want your data to be updated as soon as possible, but however you have a requirement to keep data for several years, storing this data in a single table and performing time travel may become prohibitively expensive. In this case, archiving your data in a daily, weekly, or monthly manner is a better solution. The incremental cloning capability of deep clones will really help you here.
%sql-- The following code can be scheduled to run at your convenience-- for data archivingCREATEORREPLACETABLEarchive.eventsCLONEprod.events;
Note that this table will have an independent history compared to the source table, therefore time travel queries on the source table and the clone may return different results based on your frequency of archiving.
For more on clones
For more information on clones:
-
How to Easily Clone Your Delta Lake Data Tables with Databricks
-
Attack of the Delta Clones (Against Disaster Recovery Availability Complexity)
-
We will have an Operational scenarios chapter for more examples
Summary
In this chapter, we began by covering the three simple steps for you to get started on Delta Lake: using --packages, building standalone applications via GitHub and maven, and using Databricks community edition. We provided the basic operations of Delta Lake which look suspiciously similar to Spark basic operations - because they are! We provided an intermediate-level primer on how the Delta Lake transaction log works and how it can provide ACID transactions to provide data reliability. Finally, we described some of the Delta Lake table utility commands.
Because the Delta transaction log uses MVCC, there can be many files associated with different versions of the Delta table. Fortunately, the table utility commands simplify this process. But there are distinct feature advantages such as Delta time travel (or data versioning), which we cover in our next chapter, Chapter 3: Time Travel with Delta.