
Chapter 7
Large-Scale Data-Intensive Computing
7.1 DIGITAL DATA: CHALLENGE AND OPPORTUNITY
7.1.1 The Challenge
When historians come to write the history of the early part of the 21st century, they will almost certainly describe this period as one of the enormous transformations in the way human beings interact with each other and the world around them and how they store the information arising from those interactions.
The scientific community has managed large digital data sets, in particular in the particle physics and astronomy domains, for more than 30 years. Once the preserve of the scientific domain, over the past two decades, we have witnessed the steady digitization of information throughout our daily lives. From digital photography to bar coding in shops to our electronic tax return to mobile phones, we are surrounded by data derived from digital devices. This revolution has happened surprisingly quickly and is almost certainly still in its infancy. Today, we are generating more stored data in each year than in all of the preceding years combined. We are already struggling to deal with this data deluge and, as data volumes continue to double, this problem can only get more challenging. The challenges we face include
- managing the increasing volume and complexity of primary data and the increasing rate of data derived from that primary data,
- coping with the rapid growth in users of that data who want to make use of it in their professional and private lives, and
- balancing the pressures to accommodate new requirements within existing computational infrastructures to protect existing investments.
In order to meet these challenges, a new domain of large-scale data-intensive computing is emerging where distributed data and computing resources are harnessed to allow users to manage, process, and explore individual data sets and, where appropriate, join them with other data sets to answer previously unanswerable questions.
7.1.2 The Opportunity
The massive proliferation of digital data provides mankind with previously unimaginable opportunities to understand the world around us. Those who are prepared to move adroitly in this fast-changing field will reap the greatest rewards. The key to succeeding is the acceptance that we are reaching a tipping point with regard to digital data.
Until now, for most people, the way we deal with all of the new data in our day-to-day lives both at work and at home has been to self-manage much of it. We all spend many hours archiving e-mails and photographs and moving our scientific or business data around to where we need it. As this task has grown, it has become clear to many people that self-management is no longer tenable and new tools are needed to help. However, many of these tools do not exist or are in their infancy.
There are enormous opportunities to develop new methodologies for managing and using digital data to answer a myriad of questions. These opportunities will be enabled partly through computational technologies but also through a revision of how we think about ownership, provenance, and use of data: who owns it, who created it, who can use it, and what it can be used for.
The area of data-intensive computing is a very large one, and in the remainder of this chapter, it is only possible to consider two aspects of it. In the following section, we discuss efforts to build distributed computers specifically designed to process large quantities of data. In the final section, we discussed the work of the Advanced Data Mining and Integration Research for Europe (ADMIRE) project, which is seeking to develop software tools and techniques for advanced distributed data mining.
7.2 DATA-INTENSIVE COMPUTERS
Over the past two decades, the use of massively parallel computer architectures as the basis for all supercomputing systems has become dominant. This is true both for capability computing problems (such as weather modeling), which tend to be run on tightly coupled parallel systems (traditional supercomputers), and also for capacity computing problems (such as particle physics event processing), which tend to be run on highly distributed parallel systems (grid computing systems).
Neither of these types of system are particularly good at processing large quantities of coupled data that may be stored in databases. The traditional supercomputers are largely optimized for numerical calculations and lack input/output (I/O) bandwidth from disk to processor. In these systems, data stored on disk are often stored on a coupled storage area network (SAN) system, which is not designed for rapid random access reads and writes during computation. The grid computing systems often have local disks but are connected together over low-cost networking components and, while very good at processing uncoupled data, display poor performance when individual systems have to communicate between each other over any distance. For this reason, over the past decade, a third type of massively parallel architecture has been mooted that is specifically designed to explore large amounts of scientific and other data. Such systems are called data-intensive computers.
During the 1990s, the concept of Beowulf clusters became popular. Such clusters were built from cheap commodity components (often simply racks of cheap PCs) and were designed to fill the gap between desktop PCs and much more expensive supercomputers. Jim Gray, a Microsoft Research scientist, now sadly deceased, took the original Beowulf concept and, working with Prof. Alex Szalay of the Johns Hopkins University and colleagues, created the concept of the GrayWulf data-intensive computer. This system was specifically designed for large-scale data-intensive scientific computing using databases to store the scientific data and is reported by Szalay et al. (2010). The University of Edinburgh is currently building a system that takes this idea further and explores the most effective balance of storage technologies for low-power scientific data processing.
Gene Amdahl, famous for his law describing the relationship between parallelized and sequential parts of a software application (Amdahl, 2007), also published three further measures related to the design of a well-balanced computer system. These are the following:
- Amdahl Number: the ratio of the number of bits of sequential I/O per second capable of being delivered to the processor divided by the number of instructions per second
- Amdahl Memory Ratio: the ratio of bytes of memory to instructions per second
- Amdahl IOPS Ratio: the number of I/O operations capable of being performed per 50,000 processor instructions
In an ideal well-balanced computer system, the Amdahl number, memory ratio, and I/O operations per second (IOPS) ratio will be close to one. In most modern systems, this is not the case. For some classes of application, this does not matter. For example, many supercomputing applications have very low (O(10−5)) Amdahl numbers because they are focused on processing numerical data held in cache memory. However, for large data sets held on disk, perhaps in databases, an Amdahl number close to one is vital. Data-intensive computer designs attempt to optimize the Amdahl number by marrying low-power processors with large amounts of fast disk (including solid state disk). This not only makes better use of the available procession power but also vastly reduces energy consumption—a key design factor as data volumes increase worldwide.
However, well-designed hardware systems are only part of the data-intensive computing story. In order to manipulate and analyze the data on such systems, it is vital to employ advanced software tools, and leading European research in this area is discussed in the next section.
7.3 ADVANCED SOFTWARE TOOLS AND TECHNIQUES
7.3.1 Data Mining and Data Integration
Using computers to search digital data for patterns leading to new information embedded in whatever the data represent has become a widely used methodology. Generally referred to as data mining, over the past 20 years, the techniques associated with it have become commonplace in both the scientific and business domains. However, most data mining is performed by bringing data together in data warehouses of some description and then mining it for information. In reality, we live in a world of highly distributed data, and integrating data in data warehouses is time-consuming and difficult to automate.
Over the past decade, a key research theme at The University of Edinburgh has been the creation of a framework for the management and integration of highly distributed data that may be stored in databases or flat files. This framework, called the Open Grid Services Architecture–Data Access and Integration (OGSA-DAI) framework,1 has been designed to simplify the use of highly distributed data by scientific and business applications. The framework allows highly distributed data sets to be accessed over the Internet and the data integrated for analysis. The framework supports distributed database query processing and has many features that support optimization of such queries. OGSA-DAI allows applications to create virtual data warehouses. This is an important feature as it simplifies many of the social issues, such as ownership and access control, associated with data mining and the federation of data from multiple locations.
Although OGSA-DAI facilitates the federation of distributed data, it does little to support the analysis of that data. As discussed in Section 7.1.1, we are witnessing the creation of unprecedented amounts of digital data. In order to successfully use that data, we need automated methods of analysis that allow us to mine that data for information. The ADMIRE Project2 has been designed to explore advanced scalable distributed computing technologies for data mining. The remainder of this chapter discusses the ADMIRE data mining framework, which is built on top of OGSA-DAI.
7.3.2 Making Data Mining Easier
The premise behind ADMIRE is to make distributed data mining easier for those who use it and for those who have to provide the data services they make use of. As such, the project has carefully thought about the makeup of the groups of people who engage in data mining projects. A detailed description of the ADMIRE architecture can be found in the literature (Hume et al., 2009). Each data mining community can be partitioned into three groups of experts:
- Domain Experts. These experts work in the particular domain where the data mining and integration (DMI) activities are to take place. They pose the questions that they want to see their data answer, question such as the following: “How can I increase sales in this retail sector?” “What are the correlations in these gene expression patterns?” or “Which geographic localities will suffer most in times of flooding?” They are presented with DMI tools optimized and tailored to their domain by the following two groups of experts. Many of the technical and operational issues are hidden from them.
- DMI Experts. These experts understand the algorithms and methods that are used in DMI applications. They may specialize in supporting a particular application domain. They will be presented with a tool set and a workbench, which they will use to develop new methods or to refactor, compose, and tune existing methods for their chosen domain experts (or class of domain experts). DMI experts are core users of DISPEL (the ADMIRE language) and use this to develop new methods that can be installed in the ADMIRE context. They are aware of the structures, representations, and type systems of the data they manipulate.
- Data-Intensive Distributed Computing (DIDC) Engineers. These experts focus on engineering the implementation of the ADMIRE platform. Their work is concerned with engineering the software that supports DMI enactment, resource management, DMI system administration, and language implementations, and which delivers interfaces for the tools that the DMI and domain experts will use. A DIDC engineer’s role includes the dynamic deployment, configuration, and optimization of the data’s movement, storage, and processing as automatically as possible. DIDC engineers also organize the library of data handling and data processing activities, providing them with an appropriate computational context and methods of description.
In the same way that the people involved in DMI can be partitioned, so the ADMIRE architecture also partitions computational issues. This is crucial to simplifying and optimizing how end users can be supplied with effective DMI experiences. Computation in ADMIRE is partitioned into three levels of abstraction as a DMI process moves from creation or refinement via tools through a canonical intermediate model to a detailed representation suitable for enactment as shown in Figure 7.1:
- Tools Level. At this level, data sources, their components, and DMI process elements are nameable elements that users will have some knowledge of their parameters and what they do. Domain experts will use tools to compose and steer analyses such that they may be honed into tools regularly used by users. The available tools are used to study and interconnect prepackaged DMI process templates which will in general be tailored to their needs. Domain users can use the tools to specify what data resources are to be used, provide parameters, request enactments, and observe their progress. For DMI experts, the tools provide details of the representations, format, and semantics of the various data sources such that they can use the tools to specify generic patterns and to design, debug, and tune DMI processes using those patterns.
- Canonical Intermediate Model Level. This intermediate level is used to provide textual representations of DMI process specifications. These can be generated by the tools or by a DMI expert or DIDC engineer. These intermediate representations, in ADMIRE written in a new language called DISPEL, which the project has created, are then sent to an ADMIRE Gateway as a request for enactment. The gateway model is fundamental to ADMIRE because it decouples the complexity and diverse user requirements at the tools level from the complexity of the enactment level. It does this through the use of a single canonical domain of discourse represented by the DISPEL language.
- Enactment Level. The enactment level is the domain of the DIDC engineer. It deals with all of the software and process engineering necessary to support the full range of DMI enactments allowed by the DISPEL language and mediated through an ADMIRE Gateway. In ADMIRE, much of this level has been supported by the use of OGSA-DAI. By insulating the domain and DMI experts from this level, DIDC engineers can focus on delivering high-quality solutions to potentially complex issues while ensuring they are generic solutions that can be reused by many DMI domains.
Figure 7.1 Conceptual view of ADMIRE—separating tools and enactment complexity.
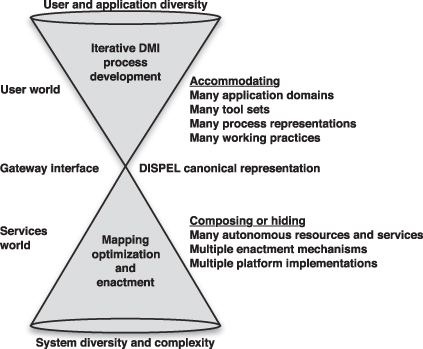
This section is entitled “Making Data Mining Easier,” which is the motto of the ADMIRE project. It would be wrong to interpret this motto as meaning it is simple to do data mining using these technologies. What ADMIRE delivers is easy-to-use patterns and models to express highly complex data mining, which would otherwise be extremely difficult to perform once and impossible to perform repeatedly.
7.3.3 The ADMIRE Workbench
The ADMIRE Workbench is central to user engagement with ADMIRE. It is described in detail by Krause et al. (2010). Figure 7.2 shows how the various workbench components are arranged and how they relate to an ADMIRE Gateway and the enactment level below this.
Figure 7.2 The ADMIRE Workbench.
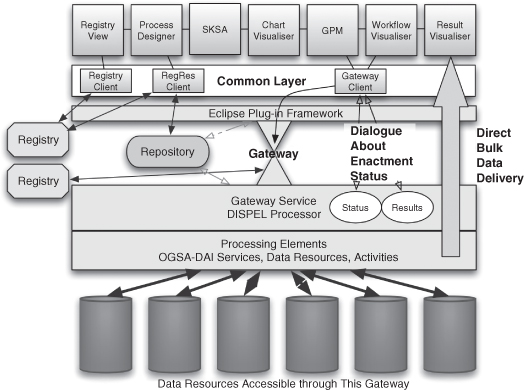
The components of the workbench are used to create complex data mining analyses by the domain experts and DMI experts. Much of the software engineering work to provide these tools is undertaken by DIDC engineers.
Workbench tools are used by domain or DMI experts to explore and analyze data (the Chart Visualiser), construct complex DMI workflows visually and edit documents written in the DISPEL language (the Process Designer), inspect and use context-related semantic information (the Semantic Knowledge Sharing Assistant [SKSA]), submit workflows to an ADMIRE Gateway and monitor its progress (the Gateway Process Manager [GRM]), access and query an ADMIRE registry (the Registry Client and Registry View), and visualize the data mining results (the DMI Models Visualiser and Chart Visualiser).
All of the workbench tools are built as plug-ins for the well-known Eclipse software development platform. The fundamental purpose of the workbench components is to create, submit, and monitor workflow processes in the form of DISPEL documents to the Gateway Process Manager for execution. The Gateway Process Manager makes use of a common Gateway Client component to send the DISPEL document to the gateway and to monitor its execution. Once completed, the results can be explored in the visualizers. The purpose of the registry components is to allow useful code snippets, intermediate results, and other useful information to be stored.
The layer below the gateway represents the enactment components of the architecture. An ADMIRE Gateway processes the DISPEL documents it is presented with and produces corresponding OGSA-DAI workflows which are executed on sites and resources known to the gateway. For performance reasons, when ready, the results are delivered directly from the data source to the client rather than via the gateway.
This is a highly parallel execution environment designed to allow for optimization of workflows in order to deliver results relying on multiple data sources quickly and conveniently.
7.4 CONCLUSION
There are many aspects to large-scale data-intensive computing and this chapter has only scratched the surface of this vast domain. The digitization of the world around us continues to gather pace. We are reaching a tipping point where traditional methods of data management and analysis will no longer be tenable. This has profound implications for how we manage, understand, and benefit from the data around us. In tandem with the vast increase in data, the world faces an uncertain future with regard to energy production and usage. It seems natural that we should look into low-power options for data-intensive computing, and this chapter has discussed some of the original work in this area currently being undertaken at the University of Edinburgh and elsewhere.
The computational technologies required to optimally store data are only one part of the story, however. We urgently need new data-intensive analysis technologies to make sense of all of the data. The latter part of this chapter therefore focused on the ADMIRE project, which has designed a framework to facilitate next-generation distributed data mining through a carefully designed architecture that separates the data domain experts from the data management experts (the so-called DMI experts and DIDC engineers) such that complexity can be managed and experts encouraged to focus on their specialisms.
The importance of distributed data-intensive computing will continue to expand over the next decade, delivering key insights to scientific research and business analysis. Through the work of projects like ADMIRE, Europe is well-placed to capitalize on this exciting new discipline.
ACKNOWLEDGMENTS
The ADMIRE Project is funded under the European Commission’s Seventh Framework Programme through Grant No. ICT-215024 and is a collaboration between the University of Edinburgh, the University of Vienna, Universidad Politécnica de Madrid, Ústav informatiky, Slovenská akadémia vied, Fujitsu Laboratories of Europe, and ComArch S.A.
While preparing the summary of ADMIRE presented here, I have drawn on the work of many project members and many of the project’s deliverables. I am grateful to my many colleagues in ADMIRE for all of their hard work on this interesting and engaging research project.
Notes
1 The OGSA-DAI software and detailed information are available at http://www.ogsa-dai.org.uk.
2 Detailed information on ADMIRE is available at http://www.admire-project.eu.
REFERENCES
G. Amdahl. Computer architecture and Amdahl’s law. IEEE Solid State Circuits Society News, 12(3):4–9, 2007.
A. Hume, L. Han, J. I. van Hemert, et al. ADMIRE—Architecture. Public report D2.1, The ADMIRE Project, Feb 2009.
A. Krause, I. Janciak, M. Laclavik, et al. ADMIRE—Tools development progress report. Deliverable report D5.5, The ADMIRE Project, Aug 2010.
A. Szalay, G. Bell, H. Huang, et al. Low-power Amdahl-balanced blades for data intensive computing. ACM SIGOPS Operating Systems Review, 44(1):71–75, 2010.