
Chapter 6
Higher-Order Testing
When you finish module-testing a program, you have really only just begun the testing process. This is especially true of large or complex programs. Consider this important concept:
A software error occurs when the program does not do what its end user reasonably expects it to do.
Applying this definition, even if you could perform an absolutely perfect module test, you still couldn't guarantee that you have found all software errors. To complete testing, then, some form of further testing is necessary. We call this new form higher-order testing.
Software development is largely a process of communicating information about the eventual program and translating this information from one form to another. In essence, it is moving from the conceptual to the concrete. For that reason, the vast majority of software errors can be attributed to breakdowns, mistakes, and “noise” during the communication and translation of information.
This view of software development is illustrated in Figure 6.1, a model of the development cycle for a software product. The flow of the process can be summarized in seven steps:
Figure 6.1 The Software Development Process.

1. Translate the program user's needs into a set of written requirements. These are the goals for the product.
2. Translate the requirements into specific objectives by assessing feasibility, time, and cost, resolving conflicting requirements, and establishing priorities and trade-offs.
3. Translate the objectives into a precise product specification, viewing the product as a black box and considering only its interfaces and interactions with the end user. This description is called the external specification.
4. If the product is a system such as an operating system, flight-control system, database system, or employee personnel management system, rather than an application (e.g., compiler, payroll program, word processor), the next process is system design. This step partitions the system into individual programs, components, or subsystems, and defines their interfaces.
5. Design the structure of the program or programs by specifying the function of each module, the hierarchical structure of the modules, and the interfaces between modules.
6. Develop a precise specification that defines the interface to, and function of, each module.
7. Translate, through one or more substeps, the module interface specification into the source code algorithm of each module.
Here's another way of looking at these forms of documentation:
- Requirements specify why the program is needed.
- Objectives specify what the program should do and how well the program should do it.
- External specifications define the exact representation of the program to users.
- Documentation associated with the subsequent processes specifies, in increasing levels of detail, how the program is constructed.
Given the premise that the seven steps of the development cycle involve communication, comprehension, and translation of information, and the premise that most software errors stem from breakdowns in information handling, there are three complementary approaches to prevent and/or detect these errors.
First, we can introduce more precision into the development process to prevent many of the errors. Second, we can introduce, at the end of each process, a separate verification step to locate as many errors as possible before proceeding to the next process. This approach is illustrated in Figure 6.2. For instance, the external specification is verified by comparing it to the output of the prior stage (the statement of objectives) and feeding back any discovered mistakes to the external specification process. (Use the code inspection and walkthrough methods discussed in Chapter 3 in the verification step at the end of the seventh process.)
Figure 6.2 The Development Process with Intermediate Verification Steps.
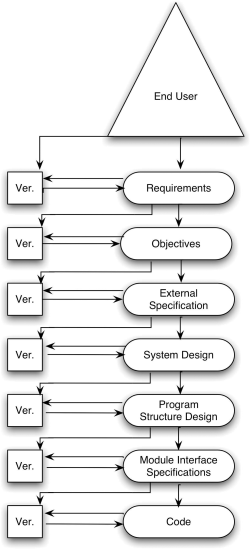
The third approach is to orient distinct testing processes toward distinct development processes. That is, focus each testing process on a particular translation step—thus on a particular class of errors. This approach is illustrated in Figure 6.3.
Figure 6.3 The Correspondence Between Development and Testing Processes.
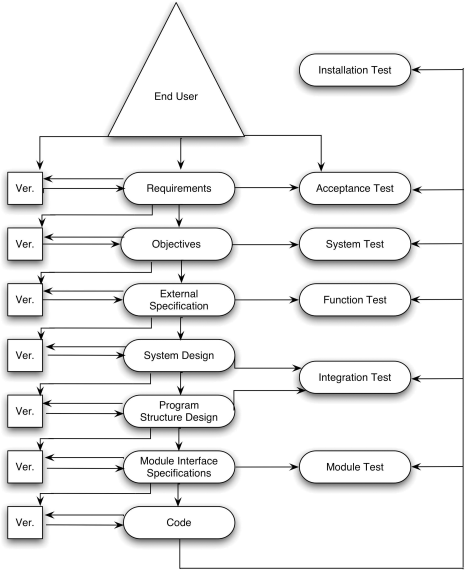
The testing cycle is structured to model the development cycle. In other words, you should be able to establish a one-to-one correspondence between development and testing processes. For instance:
- The purpose of a module test is to find discrepancies between the program's modules and their interface specifications.
- The purpose of a function test is to show that a program does not match its external specifications.
- The purpose of a system test is to show that the product is inconsistent with its original objectives.
Notice how we have structured these statements: “find discrepancies,” “does not match,” “is inconsistent.” Remember that the goal of software testing is to find problems (because we know there will be problems!). If you set out to prove that some form of inputs work properly, or assume that the program is true to its specification and objectives, your testing will be incomplete. Only by setting out to prove that some form of inputs work improperly, and assume that the program is untrue to its specification and objectives, will your testing be complete. This is an important concept we iterate throughout this book.
The advantages of this structure are that it avoids unproductive redundant testing and prevents you from overlooking large classes of errors. For instance, rather than simply labeling system testing as “the testing of the whole system” and possibly repeating earlier tests, system testing is oriented toward a distinct class of errors (those made during the translation of the objectives to the external specification) and measured with respect to a distinct type of documentation in the development process.
The higher-order testing methods shown in Figure 6.3 are most applicable to software products (programs written as a result of a contract or intended for wide usage, as opposed to experimental programs or those written for use only by the program's author). Programs not written as products often do not have formal requirements and objectives; for such programs, the function test might be the only higher-order test. Also, the need for higher-order testing increases along with the size of the program. The reason is that the ratio of design errors (errors made in the earlier development processes) to coding errors is considerably higher in large programs than in small programs.
Note that the sequence of testing processes in Figure 6.3 does not necessarily imply a time sequence. For instance, since system testing is not defined as “the kind of testing you do after function testing,” but instead as a distinct type of testing focused on a distinct class of errors, it could very well be partially overlapped in time with other testing processes.
In this chapter, we discuss the processes of function, system, acceptance, and installation testing. We omit integration testing because it is often not regarded as a separate testing step; and, when incremental module testing is used, it is an implicit part of the module test.
We will keep the discussions of these testing processes brief, general, and, for the most part, without examples because specific techniques used in these higher-order tests are highly dependent on the specific program being tested. For instance, the characteristics of a system test (the types of test cases, the manner in which test cases are designed, the test tools used) for an operating system will differ considerably from a system test of a compiler, a program controlling a nuclear reactor, or a database application program.
In the last few sections in this chapter we address planning and organizational issues, along with the important question of determining when to stop testing.
As indicated in Figure 6.3, function testing is a process of attempting to find discrepancies between the program and the external specification. An external specification is a precise description of the program's behavior from the end-user point of view.
Except when used on small programs, function testing is normally a black-box activity. That is, you rely on the earlier module-testing process to achieve the desired white-box logic coverage criteria.
To perform a function test, you analyze the specification to derive a set of test cases. The equivalence partitioning, boundary value analysis, cause-effect graphing, and error-guessing methods described in Chapter 4 are especially pertinent to function testing. In fact, the examples in Chapter 4 are examples of function tests. The descriptions of the Fortran DIMENSION statement, the examination scoring program, and the DISPLAY command actually are examples of external specifications. They are not, however, completely realistic examples; for instance, an actual external specification for the scoring program would include a precise description of the format of the reports. (Note: Since we discussed function testing in Chapter 4, we present no examples of function tests in this section.)
Many of the guidelines we provided in Chapter 2 also are particularly pertinent to function testing. In particular, keep track of which functions have exhibited the greatest number of errors; this information is valuable because it tells you that these functions probably also contain the preponderance of as-yet undetected errors. Also, remember to focus a sufficient amount of attention on invalid and unexpected input conditions. (Recall that the definition of the expected result is a vital part of a test case.) Finally, as always, keep in mind that the purpose of the function test is to expose errors and discrepancies with the specification, not to demonstrate that the program matches its external specification.
System testing is the most misunderstood and most difficult testing process. System testing is not a process of testing the functions of the complete system or program, because this would be redundant with the process of function testing. Rather, as shown in Figure 6.3, system testing has a particular purpose: to compare the system or program to its original objectives. Given this purpose, consider these two implications:
1. System testing is not limited to systems. If the product is a program, system testing is the process of attempting to demonstrate how the program, as a whole, fails to meet its objectives.
2. System testing, by definition, is impossible if there is no set of written, measurable objectives for the product.
In looking for discrepancies between the program and its objectives, focus on translation errors made during the process of designing the external specification. This makes the system test a vital test process, because in terms of the product, the number of errors made, and the severity of those errors, this step in the development cycle usually is the most error prone.
It also implies that, unlike the function test, the external specification cannot be used as the basis for deriving the system test cases, since this would subvert the purpose of the system test. On the other hand, the objectives document cannot be used by itself to formulate test cases, since it does not, by definition, contain precise descriptions of the program's external interfaces. We solve this dilemma by using the program's user documentation or publications—design the system test by analyzing the objectives; formulate test cases by analyzing the user documentation. This has the useful side effect of comparing the program to its objectives and to the user documentation, as well as comparing the user documentation to the objectives, as shown in Figure 6.4.
Figure 6.4 The System Test.
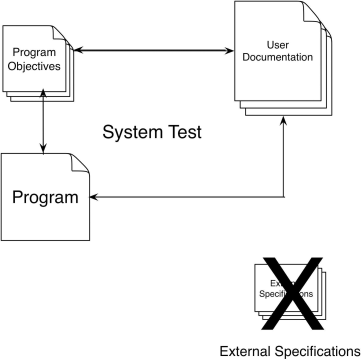
Figure 6.4 illustrates why system testing is the most difficult testing process. The leftmost arrow in the figure, comparing the program to its objectives, is the central purpose of the system test, but there are no known test-case design methodologies. The reason for this is that objectives state what a program should do and how well the program should do it, but they do not state the representation of the program's functions. For instance, the objectives for the DISPLAY command specified in Chapter 4 might have read as follows:
A command will be provided to view, from a terminal, the contents of main storage locations. Its syntax should be consistent with the syntax of all other system commands. The user should be able to specify a range of locations, via an address range or an address and a count. Sensible defaults should be provided for command operands.
Output should be displayed as multiple lines of multiple words (in hexadecimal), with spacing between the words. Each line should contain the address of the first word of that line. The command is a “trivial” command, meaning that under reasonable system loads, it should begin displaying output within two seconds, and there should be no observable delay time between output lines. A programming error in the command processor should, at the worst, cause the command to fail; the system and the user's session must not be affected. The command processor should have no more than one user-detected error after the system is put into production.
Given the statement of objectives, there is no identifiable methodology that would yield a set of test cases, other than the vague but useful guideline of writing test cases to attempt to show that the program is inconsistent with each sentence in the objectives statement. Hence, a different approach to test-case design is taken here: Rather than describing a methodology, distinct categories of system test cases are discussed. Because of the absence of a methodology, system testing requires a substantial amount of creativity; in fact, the design of good system test cases requires more creativity, intelligence, and experience than are required to design the system or program itself.
Table 6.1 lists 15 categories of test cases, along with a brief description. We discuss the categories in turn here. We don't claim that all 15 categories apply to every program, but to avoid overlooking something, we recommend that you explore all of them when designing test cases.
Table 6.1 15 Categories of Test Cases
| Category | Description |
| Facility | Ensure that the functionality in the objectives is implemented. |
| Volume | Subject the program to abnormally large volumes of data to process. |
| Stress | Subject the program to abnormally large loads, generally concurrent processing. |
| Usability | Determine how well the end user can interact with the program. |
| Security | Try to subvert the program's security measures. |
| Performance | Determine whether the program meets response and throughput requirements. |
| Storage | Ensure the program correctly manages its storage needs, both system and physical. |
| Configuration | Check that the program performs adequately on the recommended configurations. |
| Compatibility/Conversion | Determine whether new versions of the program are compatible with previous releases. |
| Installation | Ensure the installation methods work on all supported platforms. |
| Reliability | Determine whether the program meets reliability specifications such as uptime and MTBF. |
| Recovery | Test whether the system's recovery facilities work as designed. |
| Serviceability/Maintenance | Determine whether the application correctly provides mechanisms to yield data on events requiring technical support. |
| Documentation | Validate the accuracy of all user documentation. |
| Procedure | Determine the accuracy of special procedures required to use or maintain the program. |
Facility Testing
The most obvious type of system testing is to determine whether each facility (or function; but the word “function” is not used here to avoid confusing this with function testing) mentioned in the objectives was actually implemented. The procedure is to scan the objectives sentence by sentence, and when a sentence specifies a what (e.g., “syntax should be consistent. . .,” “user should be able to specify a range of locations. . .”), determine that the program satisfies the “what.” This type of testing often can be performed without a computer; a mental comparison of the objectives with the user documentation is sometimes sufficient. Nonetheless, a checklist is helpful to ensure that you mentally verify the same objectives the next time you perform the test.
Volume Testing
A second type of system testing is to subject the program to heavy volumes of data. For instance, a compiler could be fed an absurdly large source program to compile. A linkage editor might be fed a program containing thousands of modules. An electronic circuit simulator could be given a circuit containing millions of components. An operating system's job queue might be filled to capacity. If a program is supposed to handle files spanning multiple volumes, enough data is created to cause the program to switch from one volume to another. In other words, the purpose of volume testing is to show that the program cannot handle the volume of data specified in its objectives.
Obviously, volume testing can require significant resources, therefore, in terms of machine and people time, you shouldn't go overboard. Still, every program must be exposed to at least a few volume tests.
Stress Testing
Stress testing subjects the program to heavy loads, or stresses. This should not be confused with volume testing; a heavy stress is a peak volume of data, or activity, encountered over a short span of time. An analogy would be evaluating a typist: A volume test would determine whether the typist could cope with a draft of a large report; a stress test would determine whether the typist could type at a rate of 50 words per minute.
Because stress testing involves an element of time, it is not applicable to many programs—for example, a compiler or a batch-processing payroll program. It is applicable, however, to programs that operate under varying loads, or interactive, real-time, and process control programs. If an air traffic control system is supposed to keep track of up to 200 planes in its sector, you could stress-test it by simulating the presence of 200 planes. Since there is nothing to physically keep a 201st plane from entering the sector, a further stress test would explore the system's reaction to this unexpected plane. An additional stress test might simulate the simultaneous entry of a large number of planes into the sector.
If an operating system is supposed to support a maximum of 15 concurrent jobs, the system could be stressed by attempting to run 15 jobs simultaneously. You could stress a pilot training aircraft simulator by determining the system's reaction to a trainee who forces the rudder left, pulls back on the throttle, lowers the flaps, lifts the nose, lowers the landing gear, turns on the landing lights, and banks left, all at the same time. (Such test cases might require a four-handed pilot or, realistically, two test specialists in the cockpit.) You might stress-test a process control system by causing all of the monitored processes to generate signals simultaneously, or a telephone switching system by routing to it a large number of simultaneous phone calls.
Web-based applications are common subjects of stress testing. Here, you want to ensure that your application, and hardware, can handle a target volume of concurrent users. You could argue that you may have millions of people accessing the site at one time, but that is not realistic. You need to define your audience then design a stress test to represent the maximum number of users you think will use your site. (Chapter 10 provides more information on testing Web-based applications.)
Similarly, you could stress a mobile device application—a mobile phone operating system, for example—by launching multiple applications that run and stay resident, then making or receiving one or more telephone calls. You could launch a GPS navigation program, an application that uses CPU and radio frequency (RF) resources almost continuously, then attempt to use other applications or engage telephone calls. (Chapter 11 discusses testing mobile applications in more detail.)
Although many stress tests do represent conditions that the program likely will experience during its operation, others may truly represent “never will occur” situations; but this does not imply that these tests are not useful. If these impossible conditions detect errors, the test is valuable because it is likely that the same errors might also occur in realistic, less stressful situations.
Usability Testing
Another important test case area is usability, or user testing. Although this testing technique is nearly 30 years old, it has become more important with the advent of more GUI-based software and the deep penetration of computer hardware and software into all aspects of our society. By tasking the ultimate end user of an application with testing the software in a real-world environment, potential problems can be discovered that even the most aggressive automated testing routing likely wouldn't find. This area of software testing is so important we will cover it further in the next chapter.
Security Testing
In response to society's growing concern about privacy, many programs now have specific security objectives. Security testing is the process of attempting to devise test cases that subvert the program's security checks. For example, you could try to formulate test cases that get around an operating system's memory protection mechanism. Similarly, you could try to subvert a database system's data security mechanisms. One way to devise such test cases is to study known security problems in similar systems and generate test cases that attempt to demonstrate comparable problems in the system you are testing. For example, published sources in magazines, chat rooms, or newsgroups frequently cover known bugs in operating systems or other software systems. By searching for security holes in existing programs that provide services similar to the one you are testing, you can devise test cases to determine whether your program suffers from the same kind of problems.
Web-based applications often need a higher level of security testing than do most applications. This is especially true of e-commerce sites. Although sufficient technology, namely encryption, exists to allow customers to complete transactions securely over the Internet, you should not rely on the mere application of technology to ensure safety. In addition, you will need to convince your customer base that your application is safe, or you risk losing customers. Again, Chapter 10 provides more information on security testing in Internet-based applications.
Performance Testing
Many programs have specific performance or efficiency objectives, stating such properties as response times and throughput rates under certain workload and configuration conditions. Again, since the purpose of a system test is to demonstrate that the program does not meet its objectives, test cases must be designed to show that the program does not satisfy its performance objectives.
Storage Testing
Similarly, programs occasionally have storage objectives that state, for example, the amount of system memory the program uses and the size of temporary or log files. You need to verify that your program can control its use of system memory so it does not negatively impact other processes running on the host. The same holds for physical files on the file system. Filling a disk drive can cause significant downtime. You should design test cases to show that these storage objectives have not been met.
Configuration Testing
Programs such as operating systems, database management systems, and messaging programs support a variety of hardware configurations, including various types and numbers of I/O devices and communications lines, or different memory sizes. Often, the number of possible configurations is too large to test each one, but at the least, you should test the program with each type of hardware device and with the minimum and maximum configuration. If the program itself can be configured to omit program components, or if the program can run on different computers, each possible configuration of the program should be tested.
Today, many programs are designed for multiple operating systems. Thus, when testing such a program, you should do so on all of the operating systems for which it was designed. Programs designed to execute within a Web browser require special attention, since there are numerous Web browsers available and they don't all function the same way. In addition, the same Web browser will operate differently on different operating systems.
Compatibility/Conversion Testing
Most programs that are developed are not completely new; they often are replacements for some deficient system. As such, programs often have specific objectives concerning their compatibility with, and conversion procedures from, the existing system. Again, in testing the program against these objectives, the orientation of the test cases is to demonstrate that the compatibility objectives have not been met and that the conversion procedures do not work. Here you try to generate errors while moving data from one system to another. An example would be upgrading a database system. You want to ensure that the new release supports your existing data, just as you need to validate that a new version of a word processing application supports its previous document formats. Various methods exist to test this process; however, they are highly dependent on the database system you employ.
Installation Testing
Some types of software systems have complicated installation procedures. Testing the installation procedure is an important part of the system testing process. This is particularly true of an automated installation system that is part of the program package. A malfunctioning installation program could prevent the user from ever having a successful experience with the main system you are testing. A user's first experience is when he or she installs the application. If this phase performs poorly, then the user/customer may find another product, or have little confidence in the application's validity.
Reliability Testing
Of course, the goal of all types of testing is the improvement of the program reliability, but if the program's objectives contain specific statements about reliability, specific reliability tests might be devised. Testing reliability objectives can be difficult. For example, a modern online system such as a corporate wide area network (WAN) or an Internet service provider (ISP) generally has a targeted uptime of 99.97 percent over the life of the system. There is no known way that you could test this objective within a test period of months or even years. Today's critical software systems have even higher reliability standards, and today's hardware conceivably should support these objectives. You potentially can test programs or systems with more modest mean time between failures (MTBF) objectives or reasonable (in terms of testing) operational error objectives.
An MTBF of no more than 20 hours, or an objective that a program should experience no more than 12 unique errors after it is placed into production, for example, presents testing possibilities, particularly for statistical, program-proving, or model-based testing methodologies. These methods are beyond the scope of this book, but the technical literature (online and otherwise) offers ample guidance in this area. For example, if this area of program testing is of interest to you, research the concept of inductive assertions. The goal of this method is the development of a set of theorems about the program in question, the proof of which guarantees the absence of errors in the program. The method begins by writing assertions about the program's input conditions and correct results. The assertions are expressed symbolically in a formal logic system, usually the first-order predicate calculus. You then locate each loop in the program and, for each loop, write an assertion stating the invariant (always true) conditions at an arbitrary point in the loop. The program now has been partitioned into a fixed number of fixed-length paths (all possible paths between a pair of assertions). For each path, you then take the semantics of the intervening program statements to modify the assertion, and eventually reach the end of the path. At this point, two assertions exist at the end of the path: the original one and the one derived from the assertion at the opposite end. You then write a theorem stating that the original assertion implies the derived assertion, and attempt to prove the theorem. If the theorems can be proved, you could assume the program is error free—as long as the program eventually terminates. A separate proof is required to show that the program will always eventually terminate.
As complex as this sort of software proving or prediction sounds, reliability testing and, indeed, the concept of software reliability engineering (SRE) are with us today and are increasingly important for systems that must maintain very high uptimes. To illustrate this point, examine Table 6.2 to see the number of hours per year a system must be up to support various uptime requirements. These values should indicate the need for SRE.
Table 6.2 Hours per Year for Various Uptime Requirements
| Uptime Percent Requirements | Operational Hours per Year |
| 100 | 8760.0 |
| 99.9 | 8751.2 |
| 98 | 8584.8 |
| 97 | 8497.2 |
| 96 | 8409.6 |
| 95 | 8322.0 |
Recovery Testing
Programs such as operating systems, database management systems, and teleprocessing programs often have recovery objectives that state how the system is to recover from programming errors, hardware failures, and data errors. One objective of the system test is to show that these recovery functions do not work correctly. Programming errors can be purposely injected into a system to determine whether it can recover from them. Hardware failures such as memory parity errors or I/O device errors can be simulated. Data errors such as noise on a communications line or an invalid pointer in a database can be created purposely or simulated to analyze the system's reaction.
One design goal of such systems is to minimize the mean time to recovery (MTTR). Downtime often causes a company to lose revenue because the system is inoperable. One testing objective is to show that the system fails to meet the service-level agreement for MTTR. Often, the MTTR will have an upper and lower boundary, so your test cases should reflect these bounds.
Serviceability/Maintenance Testing
The program also may have objectives for its serviceability or maintainability characteristics. All objectives of this sort must be tested. Such objectives might define the service aids to be provided with the system, including storage dump programs or diagnostics, the mean time to debug an apparent problem, the maintenance procedures, and the quality of internal logic documentation.
Documentation Testing
As we illustrated in Figure 6.4, the system test also is concerned with the accuracy of the user documentation. The principal way of accomplishing this test is to use the documentation to determine the representation of the prior system test cases. That is, once a particular stress case is devised, you would use the documentation as a guide for writing the actual test case. Also, the user documentation itself should be the subject of an inspection (similar to the concept of the code inspection in Chapter 3), to check it for accuracy and clarity. Any examples illustrated in the documentation should be encoded into test cases and fed to the program.
Procedure Testing
Finally, many programs are parts of larger, not completely automated systems involving procedures people perform. Any prescribed human procedures, such as those for the system operator, database administrator, or end user, should be tested during the system test.
For example, a database administrator should document procedures for backing up and recovering the database system. If possible, a person not associated with the administration of the database should test the procedures. However, a company must create the resources needed to adequately test the procedures. These resources often include hardware and additional software licensing.
Performing the System Test
One of the most vital considerations in implementing the system test is determining who should do it. To answer this in a negative way, (1) programmers should not perform a system test; and (2) of all the testing phases, this is the one that the organization responsible for developing the programs definitely should not perform.
The first point stems from the fact that a person performing a system test must be capable of thinking like an end user, which implies a thorough understanding of the attitudes and environment of the end user and of how the program will be used. Obviously, then, if feasible, a good testing candidate is one or more end users. However, because the typical end user will not have the ability or expertise to perform many of the categories of tests described earlier, an ideal system test team might be composed of a few professional system test experts (people who spend their lives performing system tests), a representative end user or two, a human-factors engineer, and the key original analysts or designers of the program. Including the original designers does not violate principle 2 from Table 2.1, “Vital Program Testing Guidelines,” recommending against testing your own program, since the program has probably passed through many hands since it was conceived. Therefore, the original designers do not have the troublesome psychological ties to the program that motivated this principle.
The second point stems from the fact that a system test is an “anything goes, no holds barred” activity. Again, the development organization has psychological ties to the program that are counter to this type of activity. Also, most development organizations are most interested in having the system test proceed as smoothly as possible and on schedule, hence are not truly motivated to demonstrate that the program does not meet its objectives. At the least, the system test should be performed by an independent group of people with few, if any, ties to the development organization.
Perhaps the most economical way of conducting a system test (economical in terms of finding the most errors with a given amount of money, or spending less money to find the same number of errors), is to subcontract the test to a separate company. We talk about this more in the last section of this chapter.
Returning to the overall model of the development process shown in Figure 6.3, you can see that acceptance testing is the process of comparing the program to its initial requirements and the current needs of its end users. It is an unusual type of test in that it usually is performed by the program's customer or end user and normally is not considered the responsibility of the development organization. In the case of a contracted program, the contracting (user) organization performs the acceptance test by comparing the program's operation to the original contract. As is the case for other types of testing, the best way to do this is to devise test cases that attempt to show that the program does not meet the contract; if these test cases are unsuccessful, the program is accepted. In the case of a program product, such as a computer manufacturer's operating system, or a software company's database system, the sensible customer first performs an acceptance test to determine whether the product satisfies its needs.
Although the ultimate acceptance test is, indeed, the responsibility of the customer or end user, the savvy developer will conduct user tests during the development cycle and prior to delivering the finished product to the end user or contract customer. See Chapter 7 for more information on user or usability testing.
The remaining testing process in Figure 6.3 is the installation test. Its position in the figure is a bit unusual, since it is not related, as all of the other testing processes are, to specific phases in the design process. It is an unusual type of testing because its purpose is not to find software errors but to find errors that occur during the installation process.
Many events occur when installing software systems. A short list of examples includes the following:
- User must select a variety of options.
- Files and libraries must be allocated and loaded.
- Valid hardware configurations must be present.
- Programs may need network connectivity to connect to other programs.
The organization that produced the system should develop the installation tests, which should be delivered as part of the system, and run after the system is installed. Among other things, the test cases might check to ensure that a compatible set of options has been selected, that all parts of the system exist, that all files have been created and have the necessary contents, and that the hardware configuration is appropriate.
If you consider that the testing of a large system could entail writing, executing, and verifying tens of thousands of test cases, handling thousands of modules, repairing thousands of errors, and employing hundreds of people over a time span of a year or more, it is apparent that you are faced with an immense project management challenge in planning, monitoring, and controlling the testing process. In fact, the problem is so enormous that we could devote an entire book to just the management of software testing. The intent of this section is to summarize some of these considerations.
As mentioned in Chapter 2, the major mistake most often made in planning a testing process is the tacit assumption that no errors will be found. The obvious result of this mistake is that the planned resources (people, calendar time, and computer time) will be grossly underestimated, a notorious problem in the computing industry. Compounding the problem is the fact that the testing process falls at the end of the development cycle, meaning that resource changes are difficult. A second, perhaps more insidious problem is that the wrong definition of testing is being used, since it is difficult to see how someone using the correct definition of testing (the goal being to find errors) would plan a test using the assumption that no errors will be found.
As is the case for most undertakings, the plan is the crucial part of the management of the testing process. The components of a good test plan are as follows:
1.Objectives The objectives of each testing phase must be defined.
2.Completion criteria Criteria must be designed to specify when each testing phase will be judged to be complete. This matter is discussed in the next section.
3.Schedules Calendar time schedules are needed for each phase. They should indicate when test cases will be designed, written, and executed. Some software methodologies such as Extreme Programming (discussed in Chapter 9) require that you design the test cases and unit tests before application coding begins.
4.Responsibilities For each phase, the people who will design, write, execute, and verify test cases, and the people who will repair discovered errors, should be identified. And, because in large projects disputes inevitably arise over whether particular test results represent errors, an arbitrator should be identified.
5.Test case libraries and standards In a large project, systematic methods of identifying, writing, and storing test cases are necessary.
6.Tools The required test tools must be identified, including a plan for who will develop or acquire them, how they will be used, and when they will be needed.
7.Computer time This is a plan for the amount of computer time needed for each testing phase. It would include servers used for compiling applications, if required; desktop machines required for installation testing; Web servers for Web-based applications; networked devices, if required; and so forth.
8.Hardware configuration If special hardware configurations or devices are needed, a plan is required that describes the requirements, how they will be met, and when they will be needed.
9.Integration Part of the test plan is a definition of how the program will be pieced together (e.g., incremental top-down testing). A system containing major subsystems or programs might be pieced together incrementally, using the top-down or bottom-up approach, for instance, but where the building blocks are programs or subsystems, rather than modules. If this is the case, a system integration plan is necessary. The system integration plan defines the order of integration, the functional capability of each version of the system, and responsibilities for producing “scaffolding,” code that simulates the function of nonexistent components.
10.Tracking procedures You must identify means to track various aspects of the testing progress, including the location of error-prone modules and estimation of progress with respect to the schedule, resources, and completion criteria.
11.Debugging procedures You must define mechanisms for reporting detected errors, tracking the progress of corrections, and adding the corrections to the system. Schedules, responsibilities, tools, and computer time/resources also must be part of the debugging plan.
12.Regression testing Regression testing is performed after making a functional improvement or repair to the program. Its purpose is to determine whether the change has regressed other aspects of the program. It usually is performed by rerunning some subset of the program's test cases. Regression testing is important because changes and error corrections tend to be much more error prone than the original program code (in much the same way that most typographical errors in newspapers are the result of last-minute editorial changes, rather than changes in the original copy). A plan for regression testing—who, how, when—also is necessary.
One of the most difficult questions to answer when testing a program is determining when to stop, since there is no way of knowing if the error just detected is the last remaining error. In fact, in anything but a small program, it is unreasonable to expect that all errors will eventually be detected. Given this dilemma, and given the fact that economics dictate that testing must eventually terminate, you might wonder if the question has to be answered in a purely arbitrary way, or if there are some useful stopping criteria.
The completion criteria typically used in practice are both meaningless and counterproductive. The two most common criteria are these:
1. Stop when the scheduled time for testing expires.
2. Stop when all the test cases execute without detecting errors—that is, stop when the test cases are unsuccessful.
The first criterion is useless because you can satisfy it by doing absolutely nothing. It does not measure the quality of the testing. The second criterion is equally useless because it also is independent of the quality of the test cases. Furthermore, it is counterproductive because it subconsciously encourages you to write test cases that have a low probability of detecting errors.
As discussed in Chapter 2, humans are highly goal oriented. If you are told that you have finished a task when the test cases are unsuccessful, you will subconsciously write test cases that lead to this goal, avoiding the useful, high-yield, destructive test cases.
There are three categories of more useful criteria. The first category, but not the best, is to base completion on the use of specific test-case design methodologies. For instance, you might define the completion of module testing as the following:
The test cases are derived from (1) satisfying the multicondition- coverage criterion and (2) a boundary value analysis of the module interface specification, and all resultant test cases are eventually unsuccessful.
You might define the function test as being complete when the following conditions are satisfied:
The test cases are derived from (1) cause-effect graphing, (2) boundary value analysis, and (3) error guessing, and all resultant test cases are eventually unsuccessful.
Although this type of criterion is superior to the two mentioned earlier, it has three problems. First, it is not helpful in a test phase in which specific methodologies are not available, such as the system test phase. Second, it is a subjective measurement, since there is no way to guarantee that a person has used a particular methodology, such as boundary value analysis, properly and rigorously. Third, rather than setting a goal and then letting the tester choose the best way of achieving it, it does the opposite; test-case-design methodologies are dictated, but no goal is given. Hence, this type of criterion is useful sometimes for some testing phases, but it should be applied only when the tester has proven his or her abilities in the past in applying the test-case design methodologies successfully.
The second category of criteria—perhaps the most valuable one—is to state the completion requirements in positive terms. Since the goal of testing is to find errors, why not make the completion criterion the detection of some predefined number of errors? For instance, you might state that a module test of a particular module is not complete until three errors have been discovered. Perhaps the completion criterion for a system test should be defined as the detection and repair of 70 errors, or an elapsed time of three months, whichever comes later.
Notice that, although this type of criterion reinforces the definition of testing, it does have two problems, both of which are surmountable. One problem is determining how to obtain the number of errors to be detected. Obtaining this number requires the following three estimates:
1. An estimate of the total number of errors in the program.
2. An estimate of what percentage of these errors can feasibly be found through testing.
3. An estimate of what fraction of the errors originated in particular design processes, and during which testing phases these errors are likely to be detected.
You can get a rough estimate of the total number of errors in several ways. One method is to obtain them through experience with previous programs. Also, a variety of predictive modules exist. Some of these require you to test the program for some period of time, record the elapsed times between the detection of successive errors, and insert these times into parameters in a formula. Other modules involve the seeding of known, but unpublicized, errors into the program, testing the program for a while, and then examining the ratio of detected seeded errors to detected unseeded errors. Another model employs two independent test teams whose members test for a while, examine the errors found by each and the errors detected in common by both teams, and use these parameters to estimate the total number of errors. Another gross method to obtain this estimate is to use industrywide averages. For instance, the number of errors that exist in typical programs at the time that coding is completed (before a code walkthrough or inspection is employed) is approximately 4 to 8 errors per 100 program statements.
The second estimate from the preceding list (the percentage of errors that can be feasibly found through testing) involves a somewhat arbitrary guess, taking into consideration the nature of the program and the consequences of undetected errors.
Given the current paucity of information about how and when errors are made, the third estimate is the most difficult. The data that exist indicate that in large programs, approximately 40 percent of the errors are coding and logic design mistakes, and that the remainder are generated in the earlier design processes.
To use this criterion, you must develop your own estimates that are pertinent to the program at hand. A simple example is presented here. Assume we are about to begin testing a 10,000-statement program, that the number of errors remaining after code inspections are performed is estimated at 5 per 100 statements, and we establish, as an objective the detection of 98 percent of the coding and logic design errors and 95 percent of the design errors. The total number of errors is thus estimated at 500. Of the 500 errors, we assume that 200 are coding and logic design errors and 300 are design flaws. Hence, the goal is to find 196 coding and logic design errors and 285 design errors. A plausible estimate of when the errors are likely to be detected is shown in Table 6.3.
Table 6.3 Hypothetical Estimate of When the Errors Might Be Found
| Coding and Logic Design Errors | Design Errors | |
| Module test | 65% | 0% |
| Function test | 30% | 60% |
| System test | 3% | 35% |
| Total | 98% | 95% |
If we have scheduled four months for function testing and three months for system testing, the following three completion criteria might be established:
1. Module testing is complete when 130 errors are found and corrected (65 percent of the estimated 200 coding and logic design errors).
2. Function testing is complete when 240 errors (30 percent of 200 plus 60 percent of 300) are found and corrected, or when four months of function testing have been completed, whichever occurs later. The reason for the second clause is that if we find 240 errors quickly, it is probably an indication that we have underestimated the total number of errors and thus should not stop function testing early.
3. System testing is complete when 111 errors are found and corrected, or when three months of system testing have been completed, whichever occurs later.
The other obvious problem with this type of criterion is one of overestimation. What if, in the preceding example, there are fewer than 240 errors remaining when function testing starts? Based on the criterion, we could never complete the function test phase.
This is a strange problem if you think about it: We do not have enough errors; the program is too good. You could label it as not a problem because it is the kind of problem a lot of people would love to have. If it does occur, a bit of common sense can solve it. If we cannot find 240 errors in four months, the project manager can employ an outsider to analyze the test cases to judge whether the problem is (1) inadequate test cases or (2) excellent test cases but a lack of errors to detect.
The third type of completion criterion is an easy one on the surface, but it involves a lot of judgment and intuition. It requires you to plot the number of errors found per unit time during the test phase. By examining the shape of the curve, you can often determine whether to continue the test phase or end it and begin the next test phase.
Suppose a program is being function-tested and the number of errors found per week is being plotted. If, in the seventh week, the curve is the top one of Figure 6.5, it would be imprudent to stop the function test, even if we had reached our criterion for the number of errors to be found. Since in the seventh week we still seem to be in high gear (finding many errors), the wisest decision (remembering that our goal is to find errors) is to continue function testing, designing additional test cases if necessary.
Figure 6.5 Estimating Completion by Plotting Errors Detected by Unit Time.
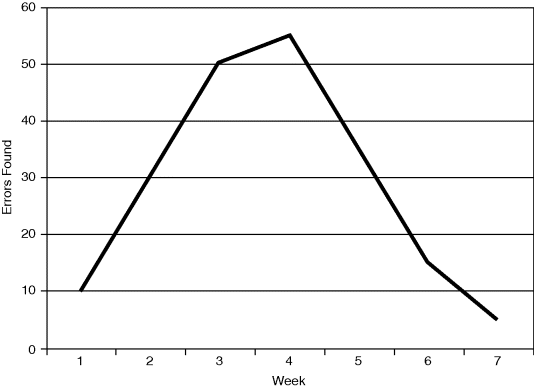
On the other hand, suppose the curve is the bottom one in Figure 6.5. The error-detection efficiency has dropped significantly, implying that we have perhaps picked the function test bone clean and that perhaps the best move is to terminate function testing and begin a new type of testing (a system test, perhaps). Of course, we must also consider other factors, such as whether the drop in error-detection efficiency was due to a lack of computer time or exhaustion of the available test cases.
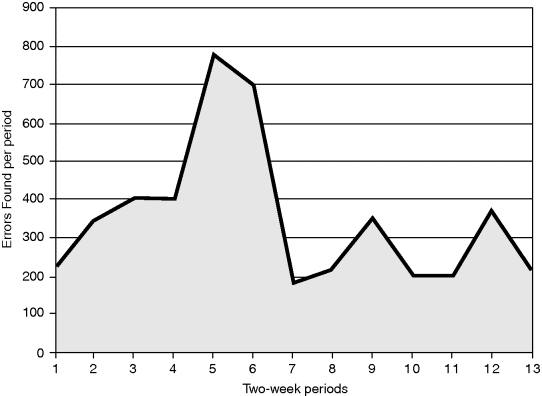
Figure 6.6 is an illustration of what happens when you fail to plot the number of errors being detected. The graph represents three testing phases of an extremely large software system. An obvious conclusion is that the project should not have switched to a different testing phase after period 6. During period 6, the error-detection rate was good (to a tester, the higher the rate, the better), but switching to a second phase at this point caused the error-detection rate to drop significantly.
Figure 6.6 Postmortem Study of the Testing Processes of a Large Project.
The best completion criterion is probably a combination of the three types just discussed. For the module test, particularly because most projects do not formally track detected errors during this phase, the best completion criterion is probably the first. You should request that a particular set of test-case design methodologies be used. For the function and system test phases, the completion rule might be to stop when a predefined number of errors are detected or when the scheduled time has elapsed, whichever comes later, but provided that an analysis of the errors-versus-time graph indicates that the test has become unproductive.
Earlier in this chapter and in Chapter 2, we emphasized that an organization should avoid attempting to test its own programs. Our reasoning is that the organization responsible for developing a program has difficulty in objectively testing the same program. The test organization should be as far removed as possible, in terms of the structure of the company, from the development organization. In fact, it is desirable that the test organization not be part of the same company, for if it is, it is still influenced by the same management pressures influencing the development organization.
One way to avoid this conflict is to hire a separate company for software testing. This is a good idea, whether the company that designed the system and will use it developed the system, or whether a third-party developer produced the system. The advantages usually noted are increased motivation in the testing process, a healthy competition with the development organization, removal of the testing process from under the management control of the development organization, and the advantages of specialized knowledge that the independent test agency brings to bear on the problem.
Higher-order testing could be considered the next step. We have discussed and advocated the concept of module testing—using various techniques to test software components, the building blocks that combine to form the finished product. With individual components tested and debugged, it is time to see how well they work together.
Higher-order testing is important for all software products, but it becomes increasingly important as the size of the project increases. It stands to reason that the more modules and the more lines of code a project contains, the more opportunity exists for coding or even design errors.
Function testing attempts to uncover design errors, that is, discrepancies between the finished program and its external specifications—a precise description of the program's behavior from the end-user's perspective.
The system test, on the other hand, tests the relationship between the software and its original objectives. System testing is designed to uncover errors made during the process of translating program objectives into the external specification and ultimately into lines of code. It is this translation step where errors have the most far-reaching effects; likewise, it is the stage in the development process that is most error prone. Perhaps the most difficult part of system testing is designing the test cases. In general you want to focus on main categories of testing, then get really creative in testing these categories. Table 6.1 summarizes 15 categories we detailed in this chapter that can guide your system testing efforts.
Make no mistake, higher-order testing certainly is an important part of thorough software testing, but it also can become a daunting process, especially for very large systems, such as an operating system. The key to success is consistent and well-planned test planning. We introduce this topic in this chapter, but if you are managing the testing of large systems, more thought and planning will be required. One approach to handling this issue is to hire an outside company for testing or for test management.
In Chapter 7 we expand on one important aspect of higher-order testing: user or usability testing.