
Chapter 7
Using Java Methods to Communicate
Now that we’ve discussed limiting access to fields and methods in Java, we can turn our attention more generally to communicating through methods. Programmers who write Java classes for others to reuse want to design methods that indicate their purpose. Programmers who write packages of classes may write methods to indicate how one object type applies to others in the same package. And some class-private methods may even take the appearance of a class talking to itself.
In method design, every aspect of the method’s signature counts: Its access modifier, return type, name, and parameters all communicate some aspect of the method’s utility. Thoughtful design will pay for itself again and again.
In this chapter, we’ll cover the following topics:
- Designing methods
- Overloading methods
- Declaring methods and fields static
- Passing data among methods
Designing Methods
Learning to communicate through well-designed methods, I’ll admit now, takes a long time. In the same sense that you’re taught over several years to use the words of a language, assemble them into sentences, and then arrange them in common (or novel) ways, so it is with programming. It takes time to learn, understand, apply, and improve. Don’t imagine that because method signatures are short, they’re easy to compose well. They take part in a much larger conversation. Designing a method isn’t just about correctness—it’s also about participating in that exchange.
You first learn style by mimicking what you see. For example, you compare two pieces of code that do the same work and learn by comparison what qualities you prefer. Some people prize brevity. Some value expressiveness (code that says what it does). Still others emphasize what they call power. Through adopting these or other virtues and applying their own preferences, serious programmers express a style.
For example, I still see Java methods like these from time to time:
public void LU62Xcvr() { … }
private char[] __parseFileObj(char[] strtok) { … }
public void iTakeIntArray(int[] p) { … }By looking at these methods, I can guess the programmers who wrote them are (a) familiar with IBM’s Logical Unit 6.2 protocol; (b) trained in C/C++ programming (probably on Windows); and (c) enamored with Hungarian notation, respectively. The technology in use influences style. The language in use influences style. Even old, outdated styles influence style.
With Java methods, it all starts with a simple form. In the abstract, it looks like this:
access_modifier other_modifiers returnType name(parameters) {
// statement body
}You first declare the visibility of a method, either with one of the keywords public, private, or protected or with no keyword, in which case you declare default (or package-private) access. Other modifiers refine the inherent properties of a method; I’ll review those in the next section. The return type specifies what kind of result the method issues to its callers. The name and parameter list, taken together, make up the method’s signature. The signature is what the compiler and JVM use to identify a method when it is called.
It’s a simple form but with many options that allow for many diverse possibilities. Let’s break them down one element at a time.
Understanding Method Modifiers
A modifier is any keyword that defines the role a method plays in a class. Given no modifiers at all, a Java method does the following:
- Provides default access
- Has a code body (with zero or more statements)
- May be overridden
- Is called with an object reference
There are other, more technical properties I haven’t listed that fall outside the scope of this book.
In Chapter 6, “Encapsulating Data and Exposing Methods in Java,” we covered the access modifiers: public, default (or package-private), protected, and private. There are six more modifiers that also apply to methods. Table 7-1 lists them and indicates if and where we discuss them.
Table 7-1: List of modifier keywords and coverage in this guide
| Modifier Keyword | Where Covered |
| abstract | Chapter 10 |
| final | Chapter 9 |
| native | Not covered |
| static | Chapter 7 |
| synchronized | Not covered |
| strictfp | Not covered |
The keywords native, synchronized, and strictfp relate to advanced topics: integrating Java with external code libraries; using Java’s built-in mechanism for managing threads in an application; and managing floating-point values in a way that keeps Java code portable across different platforms, respectively. You won’t need these keywords until you encounter the topics that require them.
In Chapter 10, “Understanding Java Interfaces and Abstract Classes,” I’ll discuss what it means to declare a class or method with the abstract keyword. You already know that final classes can’t be extended, which is similar for methods. In Chapter 9, “Inheriting Code and Data in Java,” I’ll show you how it applies.
You’ve already seen the keyword static a lot. The main() method requires it so the JVM can access it early in a program’s startup routine. In this chapter, I’ll discuss how and why you should use it with your own methods.
Choosing Modifiers
Now that I’ve deferred all but one modifier for discussion, you might wonder what else there is to talk about. The short answer is context. Once you settle on a method’s visibility—whether it represents its class to the outside world, to its package, or merely to its own class—that decision defines a context that has some bearing on its name. Let’s take a real-world context and diagram it as if we were going to transliterate it to code.
Figure 7-1 shows a hypothetical Sedan class and four actors that have some kind of relationship, or use case, with it. The diagram itself, by the way, uses UML-specified components. Those are approved, official stick figures I’m using to depict the actors. The lines are labeled to indicate each actor’s visibility. The class diagram lists methods, but I’ve separated them by visibility to emphasize my point: Method naming begins with the intended user (that is, accessibility) in mind.
Figure 7-1: Car diagram with four actors
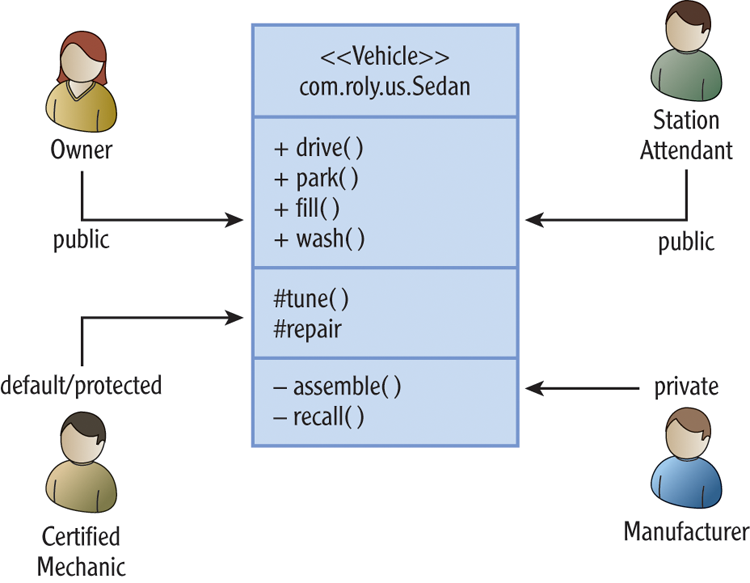
Let’s say a Sedan is one kind of Vehicle that the Roly company makes in the United States. In designing it, the Manufacturer actor provides and uses the methods assemble() and recall() to operate on the vehicle. It also supplies operations for servicing the vehicle (the tune() and repair() methods), operating it (the drive() and park() methods) and performing simple maintenance (the fill() and wash() methods).
The Manufacturer might use all these methods in the production, testing, and delivery of the car, restricting the visibility of operations it reserves for “private” use. To make servicing the car less of an ordeal, it permits a Certified Mechanic some visibility into the internals of the Sedan class. An Owner or Station Attendant may also use the Sedan as the Owner (or driver) would.
The method’s visibility adds to that context. It implies who should use it, and because you can assume a Certified Mechanic has proper skills and knowledge, the methods visible to that actor might be accordingly technical in nature, such as disconnectTensionerSpring() or advanceSparkTiming().
In each case, I’ve nonetheless applied legible method names anyone can grasp, and that’s part of the idea. A method should tell you plainly what it’s for. A name like LU62Xcvr isn’t bad. So long as you’re only talking to other veteran IBM programmers with System Network Architecture (SNA) experience who know that Xcvr is short for transceiver, it’s fine. The same goes for a __parse() method. If your colleagues know the double underscore signifies “internal use only,” they may not say anything.
The remaining modifiers are more technical in nature. If you declare a method static or final, it will have less to do with fulfilling an actor’s needs and more to do with your desire to change the way the method works.
Choosing Return Types
I have two beginner rules to lay down for choosing a method’s return type:
Roll those ideas around in your mind for a second. Highlight them in this book, write them down, put them in a small shrine for Java rules above your desk—do whatever you need to commit them to memory. As you learn to write Java programs that aren’t just main() methods of test code, these two rules will keep you out of trouble again and again. Both have to do with making sure each method does one thing, and does it well. Here’s why.
Rule 1: If the method changes the object’s state, it must return void. In short, when you write a method that performs a process, don’t make it report on that process at the same time. Consider the following methods for a Sedan class:
public TankLevel start() { … }
public TankLevel park() { … }
public TankLevel drive() { … }These methods are designed to tell you how much gas you have each time you call them. The designer thinks returning this information is a no-brainer. Without fuel, after all, it makes no sense to operate the car. Unfortunately, it’s very easy to get ahead of yourself with this kind of thinking. The idea seems to be that each action should have an immediate, measurable state change, which is not wrong. The idea that each method should immediately report that change is another matter.
Assume each of these methods has numerous statements to execute, including other method calls. Callers have no idea how simple or complex the call is; they are just looking for the response they’re told to expect.
After a bit of reflection, however, some callers will wonder, When exactly was it that the state of the TankLevel object was computed? What should the caller expect? Using the park() method, a caller may feel that reporting the gas level before the car shuts off makes the most sense. Another caller may think it should report zero, confirming that the gauge shuts off when the car does. When the drive() method is used, reading the gas level before starting seems reasonable. Someone else may call the drive() method repeatedly to get the current gas level. In my experience, it’s stunning how the callers assign their own meanings to some methods to get what they want from them. It is also a rule of the trade that method faults accrue to their programmer. Always.
Methods that combine the behavior of an object with a partial view of its state are problematic. When it’s done, the method’s context remains open to interpretation at best and misuse at worst. The temptation is the convenience of doing two things at once. The consequences come when programmers start looking more closely at the method to understand every aspect of its work. When that work proves to be two things instead of one, you run into trouble.
You should instead supply separate accessor methods for reporting part of the object’s state. The caller can assert the context they require, before and after they invoke a state change, if that’s what they need. Some test-oriented programmers may end up writing code like the following:
…
sedan.start();
System.out.println(“Gas: “ + sedan.getTankLevel());
sedan.drive();
System.out.println(“Gas: “ + sedan.getTankLevel());
sedan.park();
System.out.println(“Gas: “ + sedan.getTankLevel());
sedan.stop();
System.out.println(“Gas: “ + sedan.getTankLevel());
…Soothing that kind of anxiety is not your problem. There’s not much you can (or should) do to forestall this approach. A method interface that enables this kind of checking by making it possible with fewer lines of code only makes this wrong-headed approach more convenient.
On to Rule 2: If the method returns an object, it should return an interface instead of a value. This rule extends the idea of encapsulation I raised in Chapter 6. When you return an object reference, you want the caller to use behavior, not storage implementation.
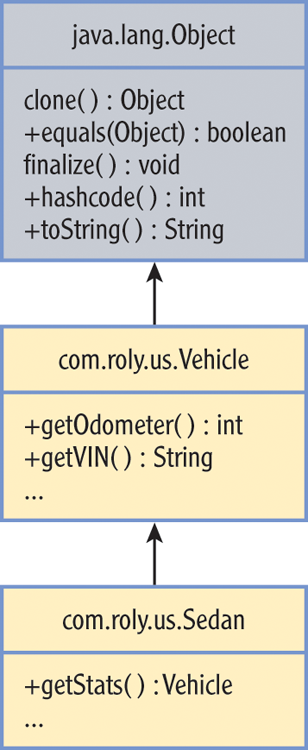
Let’s expand on that idea using Figure 7-2, which shows the Vehicle class from Figure 7-1 in some detail. Assume the Roly company uses this class as a general type, one that represents features that are common to all the cars it makes.
Figure 7-2: Vehicle class diagram

To keep it simple, I’ll consider just the odometer and vehicle identification number (VIN) as state values. These are data that could apply to any Vehicle, so it makes sense to assign them to a general type. Assume for the sake of discussion that the Sedan class will inherit from the Vehicle class and therefore share its accessible members, including these:
public int getOdometer() { … }
public String getVIN() { … }It makes sense to think of the Vehicle class as a type in its own right, one that is capable of reporting the odometer’s current reading or VIN. Why not just return the object reference and let the calling programmer use it to extract the information they require? Such a method might look like this:
public Vehicle getStats() { … }This idea takes encapsulation to another level. By using the Vehicle class to represent features the Sedan subclass inherits from it, you generalize the return type. To fully appreciate this benefit, you need to learn more about inheritance. That full discussion doesn’t take place until Chapter 9. For now, I ask you to take it on faith that this benefit is a good one.
So why not just return a Sedan type, if that class also has the methods you want to return to the caller? That would also serve the example at hand, and it’s easier to understand, given the topics we have covered so far, but the Sedan class is what I’ll eventually describe as a concrete type. It’s like a “what you see is what you get” kind of class, and that’s not a problem.
Think about it like this: You’re talking about cars with your friends. One of your friends has a habit of relating everything that’s being said to the Roly sedan. Your friend knows there are other cars, but if the Roly sedan doesn’t have a capability or feature you want to talk about, he doesn’t have anything to say. When you want to make an observation about cars in general, that friend doesn’t follow unless he can relate it back to the Roly sedan.
The point of Java’s inheritance model is that, on one level, every object behaves as the Object class requires. It also behaves as every parent class requires, as Figure 7-3 shows. If you want to direct a caller’s attention to what a parent type can do, return that type. Don’t be any more specific than necessary.
Figure 7-3: Method interfaces inherited by the Sedan class
Again, I’m asking you to take this rule on faith for now. To fully understand the rationale that supports this rule, you need more, including complete information on inheritance and using parent classes as types. You’ll get there soon enough.
Choosing Parameters
Choosing parameters is another key aspect of defining a method. If one method calling another is a form of communication, parameters represent the message. Along with a method’s name, parameters form what we call the method’s signature. The type, order, and number of parameters a method accepts all combine to create a unique lookup for each method in a class.
A method’s parameter list can have zero or more items. The number of items can be fixed or variable. Each parameter may be a primitive type or an object reference. The list for any method can mix these types as you wish.
What matters in design is the message: what the method requires (or should accept) to do its job and converse efficiently with its callers. That conversation is, in part, refined by its context: the information an object contains before its methods are called. Consider the following possible methods for the Sedan class:
public void start(Driver drvr, Key key) { … }
public void start(Owner owner) { … }
public void start() { … }There’s nothing wrong with any of these methods, but a moment of reflection might tell you the message in the first two methods is possibly redundant, or at least could have been established before getting to this operation. If so, are these methods asking the caller to confirm this information, or repeat it?
You want to make a parameter list as simple as it can be, but no simpler. I still think about the System.arraycopy() method and its five parameters all the time. Five parameters are a lot to remember, but to my mind, there’s just no better way of talking to that method. Fortunately, you and I don’t have to use it (directly) very often. It is buried in lots of methods you will use all the time, though.
When I review a colleague’s class code, I rely on a few simple categories based on each method’s use of return type and parameter list. Table 7-2 shows those categories as a combination of its return and parameters.
Table 7-2: Defining a method by its return and parameters
| Method Composition | Returns void | Returns a Type |
| No parameters | Procedural | Accessor |
| Has parameters | Mutator | Functional |
The terms procedural and functional are not terms accepted by the Java community. For the sake of introduction and as terms to apply in a code review, however, I find these categories very useful. They help me describe what I think the method should do based solely on these two elements. If the method’s name does not complement this categorization, it makes me wonder if the method’s intent is as clear as it could be.
A method that takes no parameters but returns a value should return something that pertains to its object. A method that accepts a parameter but returns nothing should modify the object. The terms accessor and mutator, which are widely used, describe those roles. Accessor and mutator methods don’t have to have the prefix get or set, respectively, but most Java programmers have no doubt what you mean when they see them.
A method that requires no information from the caller and returns none should change its object’s state. I call this kind of method procedural, but any term that implies a process that leads to state change works too. A procedural method is like a control button. You expect it to perform some kind of action, a change in the object state you’ll be able to observe in a subsequent interaction.
Finally, there are methods that accept parameters and return a value. I take a method of this form to be one of two things. First, I guess it’s a mistake, for the reasons I gave earlier in the chapter. Any method that appears to be both a mutator and an accessor is bound to appear ambiguous to some number of programmers and cause confusion.
Second, if the method behaves like a mathematical function—it returns a type that is only a computational result of operating on the supplied parameters, just like the operators you studied in Chapter 3, “Using Java Operators and Conditional Logic”—then it’s okay. Most Java programmers are taught to call these utility methods, but the common term across programming languages is functional.
I use these categories when I hear my students interpreting the term style to mean something free-form, groovy, and open to what their heart is feeling. No; style is not poetic license. There absolutely is a technical craft to it; you can define it, and you can lock it down. We can disagree on terms, but the discipline is not optional. Now that you know the anatomy of a method and categories by which to understand them, what remains is assigning the best possible name.
Naming Methods
Let’s start with the hard-and-fast rules:
- You cannot name a method the same as a Java reserved word.
- The name must begin with a letter or the symbol $ or _.
- Subsequent characters may also be numbers.
That’s it. These rules describe any legal identifier in Java and apply to anything you are free to name, including classes and fields. Prepare to be tested on these rules. The following examples are legal:
- okidentifier
- $OK2Identifier
- _alsoOK1d3ntifi3r
- __SStillOkbutKnotsonice$
These examples are not legal:
- 3DPointClass
- hollywood@vine
- *$coffee
- synchronized
Normally I’d say there’s no need to memorize Java’s reserved words unless you know how to use them. Like the synchronized keyword, however, all of them are illegal as identifiers. I’d be embarrassed to admit how many times a method called do() appears in example code I type off the top of my head, if it actually happened. But I’m a professional, so it never ever does. Be careful of terms you may have acquired elsewhere, like the goto and const reserved words. The Java Language Specification (JLS) reserves these terms to make sure no one muddies Java’s waters by using them.
Valid letters in Java are not just characters in the English alphabet. Java supports the Unicode character set, so there are more than 45,000 characters that can start a legal Java identifier. A few hundred more are non-Arabic numerals that may appear after the first character in a legal identifier. You don’t have to worry about memorizing those for an Oracle exam.
As a matter of style, also consider these guidelines:
- Use lowercase letters except to start a subsequent word.
- Put acronyms in uppercase.
- Don’t start identifiers with $. (The compiler also uses this symbol.)
The following are examples of conventional style:
- getGrossVehicleWeight
- parseVIN
- crimeaRiver
Some Java shops post their own guidelines on top of generally accepted style. The bottom line with any one codebase is consistency. When a large base of code has a clean, consistent style, it can significantly cut the burden on the reader to absorb it.
The rest of a good naming scheme, again, has everything to do with maintaining the context. What term or terms should come to mind for your caller when seeking the appropriate method in your class? Does the name you use express a clear idea? Does it suggest to someone examining your method interface that they’ve come to the right place?
These considerations go a long way toward conserving another programmer’s time and are well worth the effort because of that. My best advice: Learn to appreciate what it is that makes classes you like to use so agreeable, and teach yourself how to follow suit. If all else fails, start with these can’t-miss rules, and elaborate as needed:
Overloading Methods
Think about the System.out.println() method for just a second. You haven’t had reason yet to notice that it will take anything for a parameter—any primitive, any object reference:
class Println {
public static void main(String args[]) {
System.out.println("fred");
System.out.println(true);
System.out.println(55.55);
System.out.println(8);
System.out.println('a'),
System.out.println(new Object());
}
}
$ java Println
fred
true
55.55
8
a
java.lang.Object@5a25f3Regardless of type—a literal string, Boolean, integral, floating-point, or even object reference—the println() method knows how to print it. It’s no accident, nor is it a compiler trick. The println() method (located in the java.io.PrintStream class) has 10 different versions. One version takes no parameter and prints a line return, another version accepts an object reference, and another even takes an array. The remaining seven versions cover all the primitive types except for a short value.
This technique is called overloading. Properly used, it lets the programmer define multiple ways for a caller to pass a message to the method and get a result. The caller can save the trouble of having to cast or convert a parameter to one specific type allowed by a method that isn’t overloaded.
Understanding Method Signatures
Overloading relies on how the method’s signature is used to locate a method in a class. You can have methods with the same name in a class, but the compiler has to identify them as unique. It does that by using the number, type, and order of parameters specified by a caller to match an available method. So long as two methods with the same name vary by these criteria, the compiler can tell them apart.
The following method signatures are all different, or different enough, in the eyes of the compiler:
- myMethod(Object first, int second)
- myMethod(Object first)
- myMethod(int second)
- myMethod(long first, Object second)
Remember that legal identifiers are case-sensitive, so two methods with the same name but different capitalization cannot overload each other. If you aren’t accustomed to paying attention to case, you might fool yourself into thinking you’ve overloaded a method when you haven’t:
- myMethod(Object first)
- mymethod(Object second)
The compiler won’t complain because, as far as it’s concerned, there’s no confusion here. There are two different methods to begin with, so there’s not reason to compare their parameter lists. Your only safety in this case is to proofread your code carefully, test it thoroughly, and possibly use an editor that’s smart enough to warn you when you’ve done something like this.
Modifiers and return types are not part of the signature—these can vary all you want but only when they refer to methods with differing signatures. Parameter names have no bearing at all. The following examples are not distinguishable from each other. Different as they might appear, they are the same to the compiler:
- public void myMethod(Object inky)
- private int myMethod(Object blinky)
- protected Object myMethod(Object clyde)
Supporting Multiple Parameter Lists
You can overload a method by varying the type, number, and order of its parameters. That’s the rule. There are also some conventions on top of the rule that will help you avoid confusion.
It’s a bad idea, for example, to change what an overloaded method does based on the parameters provided. The name should advertise a single, consistent behavior. Overload a method only to make it easier to use. Here are some examples:
void addContact(String name, Phone ph, Address addr, Email addy) {…}
void addContact(String name, Phone ph, Address addr) { … }
void addContact(String name, Phone ph) { … }
void addContact(String name) { … }void deposit(Dollar amount, boolean receipt) { … }
void deposit(Dollar amount) { … }void addContact(String name, Phone ph, Address addr, Email addy) {…}
void addContact(String name, Email addy, Phone ph, Address addr) {…}
void addContact(Email addy, String name, Address addr, Phone p) {…}Name first, phone second versus name first, email second? You’d have to work pretty hard to devise a sequence of parameters that implies one clear meaning. Getting multiple sequences to do that is much harder. Remember, the compiler just makes this feature available. It doesn’t save you from going overboard with it and creating signatures with obscure meanings.
That’s all overloading has to offer, but it’s not a small thing. In return for varying the signature of a method a few times, you accept work your caller might otherwise have to do. Consequently, it’s difficult to know in advance when overloading saves anyone time. You can always add an overloaded method without breaking the existing method interface of a class, so perhaps the best approach is conservative: Add them when other users tell you it would really help.
Allowing for a Variable Number of Parameters
You can take overloading by number of parameters a step further using Java’s varargs feature. A varargs parameter allows for an arbitrary number of parameters so long as they share one type, just as an array does.
In fact, you could just populate an array with some values and pass it as a parameter. The varargs feature just makes it convenient to pass several literal values to a method on the fly. Underneath the hood, the compiler and JVM treats a varargs parameter list as an array.
Let’s say you wanted a functional method that lets the caller supply a list of integers and get their mean average, like the following:
float mean1 = avg(1, 3, 4, 8, 45, 233, 12, 11, 29);
float mean2 = avg(5, 9, 3, 11);
float mean3 = avg(25, 25, 31, 25, 32, 21, 29, 25, 45);These statements are an example of an expressive syntax. That is, you can infer what’s supposed to happen just by reading them. It’s a good way to improve code readability when you have to deal with many literal values, or even a few you want to manage on the fly. To accept a varargs parameter, create a parameter that declares its type, followed by an ellipsis (three dots), followed by the parameter name:
public float avg(int ... numbers) { … }That’s it! It’s not only simple, but it will also accept an array in lieu of a list of values. This overloading is built in. In the method body, you treat the varargs variable like an array, as shown here:
public void echo (int ... numbers) {
for (int i = 0; i < numbers.length; i++)
System.out.print(numbers[i]+ " ");
}And there’s more. If the varargs type is primitive, the compiler and JVM will box the values for you into their object form. You can then use a for-each loop to iterate over them, as shown here:
public void echo (int ... numbers) {
for (Integer i; numbers)
System.out.print(i + " ");
}Nice! You may not see a ton of opportunities to exploit this feature, but if you’ve written a few thousand for loops already, you’ll be happy for any shortcuts you can get your hands on.
In summary, a varargs parameter has the following characteristics:
- Accepts zero or more elements of the same type
- Can occur once in a method’s parameter list
- Must be the last parameter in the list
- Also accepts an array (including an empty one)
Chaining Overloaded Methods
Don’t imagine that each overloaded println() method has its own code; that would be foolish. Methods by the same name should have the same behavior, of course, but that’s hard to keep straight, and a bit mind-numbing, if you have to edit eight or nine methods each time you need to change the logic.
It’s easier to keep the core logic in one method. Let the overloaded methods process the parameters they receive as needed. Then call the method that contains the logic all the methods need to do the intended work. With method chaining, the two BankAccount methods that I described earlier could look like this:
final class BankAccount {
private Dollar balance;
private boolean receipt = true;
public void deposit(Dollar amount, boolean receipt) {
balance.add(amount);
// if receipt == true, print receipt
}
public void deposit(Dollar amount) {
// validate and chain to base method
deposit(amount, true);
}
}
final class Dollar {
private float amount;
private void setAmount(float amt) {
// make sure amt is a valid currency amount
amount = amt;
}
float getAmount() {
return amount;
}
public void add(Dollar amt) {
// validate amt
amount += amt.getAmount();
}
}Can you see why the method signatures have to be unique and why using a different return type alone isn’t enough? When chaining, methods can identify their overloaded counterparts only by passing the right parameters. Even then, it’s not always enough to make such calls unambiguous, but that’s another conversation that has to wait until you learn more about inheritance in Chapter 9.
Declaring Methods and Fields static
The static keyword modifies methods in a way that’s quite different from how an access modifier does. Recall when I said the main() method had to be declared static. Methods that are declared static can be called without constructing an object of the class. The JVM can invoke a main() method just by knowing which class to load into memory.
Viewed another way, you have an excellent candidate for a functional method if you want a method that
- Won’t change an object’s state
- Won’t report an object’s state
- Will return a value based on parameters
Methods written this way offer a utility that, while contained in a class by necessity, doesn’t provide an object-based service.
Classes that contain just these kinds of methods include
- java.lang.Math
- java.util.Collections
- java.nio.file.Files
These classes consist of methods that serve as helper tools to other classes. The Math class is like a big calculator, full of mathematical functions. In a similar manner, the other two are like a utility drawer for their respective packages, one place to keep an assortment of handy tools.
Objects themselves can still call static methods, including objects made from the same class. It’s more common to address static methods by their class name, such as Math.abs(-25), but it’s not required.
What you can’t do is use a static method to refer to any object’s data. Once constructed, an object has what is called a non-static context. That attempt crosses the boundary that separates the class from its objects.
A common beginner mistake with static methods involves confusing them with object methods. The rules of visibility tell you a method can see all other methods in its class. It can, but it can’t necessarily call all of them. To do that, the methods have to share a context, either class based (that is, static) or object based.
The following example illustrates a rookie mistake I see in virtually every introductory course I have taught:
public final class Static {
private String name = "Static class";
public static void first() {
System.out.print("first ");
}
public static void second() {
System.out.print("second ");
}
public void third() {
System.out.println("third");
}
public static void main(String args[]) {
first();
second();
third();
}
}If you try compiling this class, you’ll get this error message:
Static.java:18: error: non-static method third()
cannot be referenced from a static context
third();
^The compiler, as you can see, offers one of its least helpful messages in a spot almost every new Java programmer visits. If you take this error message as advice, it seems to hint that making the third() method static will fix the problem—which it does, but then none of these methods can be used to access a non-static field like name. We’ve only created a different problem.
It would be nice if the compiler said, “Did you want to construct a static object in the main() method and use it to access the non-static members of the class?” because that would work. Alas, the compiler is not in the business of guessing what you want. Its only job is to tell you if what you coded is legal and correct.
If you apply the static keyword instead to a field, it has a different effect than it does for a method. It associates the field with the class rather than any one instance. All static methods can access any static field.
A static field’s value is visible to all instances of a class at once. If we declare a class member like this, then every instance of the class shares that information:
private static String myHometown = "San Francisco";It’s not easy to come up with many uses for static fields, at least as they relate to objects. The typical example is a counter variable that’s incremented every time an object gets made, like this:
public class Counter {
private static int counter;
public Counter() {
counter++;
}
public int getCounter() {
return counter;
}
public static void main(String args[]) {
Counter ctr1 = new Counter();
Counter ctr2 = new Counter();
Counter ctr3 = new Counter();
System.out.println(ctr1.getCounter());
}
}
$ java Counter
3The getCounter() method can access the counter variable. So can all Counter objects. It won’t matter if you use ctr1, ctr2, or ctr3 with the println() statement. They’ll all report 3.
Passing Data among Methods
Up to this point, I’ve treated methods without much concern for the differences between primitive and object types. These next sections require more careful handling—it’s where beginners get confused one of two ways. The first is in misunderstanding what happens to a parameter after a called method returns. The second is getting lost in someone else’s explanation that sounds simple but isn’t.
Experience has taught me you can take this discussion too fast but almost never too slow, so I’m going to take it a piece at a time. When it’s done you’re going to see that Java methods handle all parameters the same way, but the effect it has is one thing for primitive types and another for object references.
Understanding Primitive Parameters
A primitive variable is nothing more than an alias for a literal value. When you write
int x = 7;it’s the same as saying, “x is another word for 7.” When the value of x changes to 25, it becomes another word for 25. That’s all a primitive type variable is: a name you assign to whatever is inside it.
When you use x as a parameter, you do not share it with the method you are calling; you pass along the content. The called method receives the value only, gives the thing a local name, and then operates on it.
Got it? Let’s find out: What is the value of x when it is printed in the main() method here?
public final class Doubling {
public void doubling(int x) {
x = x * 2;
}
public static void main(String args[]) {
int x = 7;
Doubling dbl = new Doubling();
dbl.doubling(x);
System.out.println(x);
}
}What do you think, 7 or 14? Running this program will give you the answer, but that doesn’t really help you unless you can verbalize the reason why. Here’s a hint: If you’re thinking 14, read this section again.
The variable x in the main() method is only an alias for its assigned value. The same is true for the variable x in the doubling() method. The two variables are not related. The doubling() method receives a literal value 7, which it assigns to its own local name, multiplies by two, and then exits. That’s it. The x declared in the main() method is unaffected.
Don’t move on until you are sure what’s happening here. If it helps to change variable names, add println() statements as you like, and so on, by all means do so.
Understanding Reference Parameters
I’m going to repeat the last section, but this time using a MyNumber object reference that contains a field x. Here’s the modified test code:
public final class Doubling2
{
public void doubling(MyNumber mnd) {
mnd.x = mnd.x * 2;
}
public static void main(String args[]) {
MyNumber mnm = new MyNumber();
Doubling2 dbl = new Doubling2();
dbl.doubling(mnm);
System.out.println(mnm.x);
}
}
final class MyNumber {
public int x = 7;
}What will the main() method print now? Let’s work it out.
In this program, I pass a referent to the doubling() method from the main() method. The variable mnm points to the reference in the main() method, and the variable mnd points to the reference in the doubling() method. Although they point to the same object, they are not related to each other. That is, an object reference is just like a primitive variable. The called method ignores the calling name and assigns its own.
What it contains, however, isn’t a literal; it’s a location in memory, with access to certain fields and methods. If the doubling() method mutates a value inside the referent, the reference mnm will see the change the next time it accesses the referent. Now our answer is 14.
Returning Object References
An object reference provides a layer of indirection that skirts the limits of a primitive variable. A calling method can pass an object to a called method, which can change it. The calling method can see the change after the called method returns. It’s (almost) that simple.
The called method still ignores the reference used by the calling method to pass the parameter. The difference is in the value, which is now a referent. If instead I tried to change the referent itself—for example, by trying to assign it to a different referent—the calling method would not notice.
To demonstrate this point, I’ll modify the test class once more:
public final class Doubling3
{
public void doubling(MyNumber mnd) {
// assign a new referent
mnd = new MyNumber();
mnd.x = mnd.x * 2;
}
public static void main(String args[]) {
MyNumber mynum = new MyNumber();
Doubling3 dbl = new Doubling3();
dbl.doubling(mynum);
System.out.println(mynum.x);
}
}
final class MyNumber {
public int x = 7;
}This doubling() method creates a new MyNumber object, operates on it, and then returns. You might now assume the method has replaced the referent it received with a new one and that mnm now points to it—but that’s not what happens. Once the doubling() method declares a different value for the mnd variable—here, a new referent—the mnd and mnm variables no longer have a referent in common. The value of mnd.x will change to 14, and the value of mnm.x will remain 7.
Understanding Pass-by-Value
Java’s behavior is the same for all cases. It’s called pass-by-value. The difference is that a primitive type holds a literal value while an object reference holds the location of a referent. It’s these intermediate values that cannot be changed by a called method.
What seems to makes understanding pass-by-value difficult is the term itself. Java programmers have argued over a correct and complete definition of this term for years, often to the point of violently agreeing with each other.
The second complication I’ve seen involves mock quiz questions that torture this point endlessly. While I agree it’s important to test for this understanding, I don’t think turning it into an exhausting time-bound puzzle proves anything, except perhaps who in a room is faster at reading a maze of twisty code. Tricky examples aside, the truth is simple. The value of a primitive type is always literal, like the number 5 or the keyword false. The value of an object reference is always a referent (or null). You cannot change a variable by passing it to another method—you only ever pass its value.
private double checkWeight(Object obj)