
Chapter 6
Encapsulating Data and Exposing Methods in Java
It’s time to move past main() methods for writing programs and dig a bit deeper. This step has several elements to it, so I’ve broken the first big step into two chapters. This chapter covers the fundamentals of defining the interface to a class: restricting direct access to member variables and using methods to allow indirect access.
In Chapter 7, “Using Java Methods to Communicate,” I’ll build on this practice by designing methods that express the services a class offers.
In this chapter, we’ll cover the following topics:
- Encapsulating data
- Exposing data through methods
- Applying access modifiers
- Abstracting data
Encapsulating Data
As Chapter 7 will explain, in Java we use methods to communicate between objects in a program. Literally, we’re just passing data as parameters from one method to another, sometimes expecting a returned value, sometimes not. But learning to think in the figurative sense of communicating helps you to see your objects as actors, each playing a role or performing a service in your program. Learning to think this way takes time, but for some people it is the entire point of object-oriented programming. It contributes, among other things, to clearer design and deeper analysis when putting large programs together.
If your study of Java follows a path like mine, you may find yourself having “aha!” moments as the idea of communicating through methods kicks in. You may wonder how the code you’ve written before those realizations actually worked. And, if your experience is like mine, those revelations will keep coming as you take on bigger programming challenges.
This chapter is a first step toward that goal. You want to think of the data that makes up your classes as a private matter; a set of details, really, that give your Java class the means to do the work its methods support.
Understanding Data Hiding
Maybe data hiding is not the best term. Saying we hide data in an object is like saying we hide snacks in a vending machine or we hide circuitry in a remote control unit. It’s a legitimate aspect of what’s going on, of course, but the word hide makes it sound like some secretive nature is worth noting. Nonetheless, the term has stuck, a very large number of users accept it, and we’re obliged to follow along if we want to get in the conversation with them.
What I want to convey in this chapter has more to do with covering data: to protect it and to promote the appearance of a single object. I also want to remove from view something I see as a detail of small consequence in a class I write. I want to retain the freedom to change it later. At the very least, I want to suggest that how I stored my data is not as important as the means to use it. I want users to focus on the service I provide with my Java class.
The rest of this chapter will show you the what and the how of encapsulation. Interpreting well-designed Java classes and writing useful and intuitive methods yourself are the practical outcomes. But I’ll take a moment here to explain the motivation using accepted terms:
- Minimizing/localizing variable scope
- Cohesion
- Loose coupling
- Maintainability
I’ll discuss each of these in turn.
Figure 6-1: Complete diagram of the ArrayList class’s components

Figure 6-2: Degrees of coupling between two classes
Think data hiding. Then think encapsulation with methods. Then cohesion, factoring classes out as early in the process as you can. If you do that, loose coupling and easier maintenance will come to you.
Hiding the Data
You can hide data in a Java program with an access modifier. The access modifier private restricts visibility of a member to its class. A private field is visible to methods and constructors in the class. No other object may address it. Conversely, no member of a class can hide from a member of the same class.
I sidestepped this point in the first two chapters to describe the Point3D class in the simplest possible terms. Now that you know it’s important to hide fields, I will write class members like this:
public class Point3D {
private int x, y, z;
}Of course, without any methods to access these variables, they are hidden in the full sense of the word. You can still construct a Point3D object, however. The compiler will initialize x, y, and z to an int zero. Access modifiers don’t affect visibility to the compiler or the JVM. Other objects have no idea what Point3D is or does other than it inherits from java.lang.Object.
Now you need methods that are visible to a caller. Methods that will return the value of a hidden field are called accessor methods, or just get methods. Methods that let you change the values of hidden fields are called mutator methods, or just set methods. Adding the public access modifier to these methods will expose them to any potential caller.
I’ve applied the public keyword to most of the classes I’ve shown you so far. Declaring a class public is not precisely the same thing as declaring a class member public. If a class is public, other objects in the same program can refer to it by name. A visible class, bear in mind, does not imply its members are accessible. They must also be declared public.
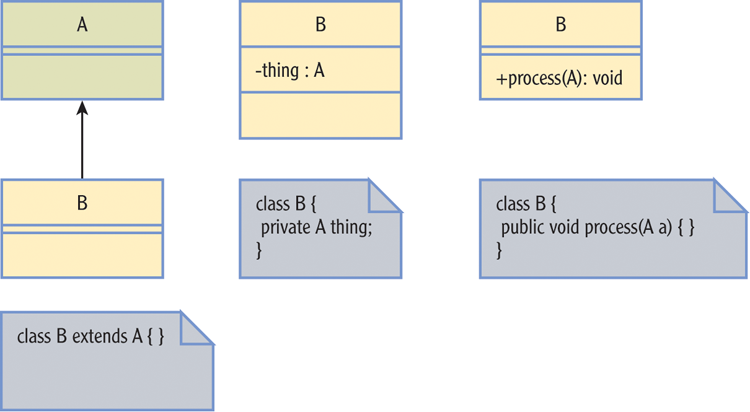
The methods we make visible outside a class will define that class’s interface. In a Unified Modeling Language (UML) diagram, we can signify the proper access by prefixing private members with a dash (or minus) and public members with a plus. Figure 6-3 shows the Point3D class with access modifiers added.
Figure 6-3: Class diagram of the Point3D class

The practice of hiding data is an understood practice in many shops. You may encounter many casual sketches of class diagrams in which fields are simply omitted if they are private, unless they are important to the meaning the diagram conveys.
It’s from diagrams like this that you can form a picture of the class’s cohesion and coupling. Do the methods appear to have a common purpose? Do they operate on one kind of data? Also, what dependencies (or couplings) does the class form with other types? It’s no mystery that these questions become more pressing as a class grows larger, but concerns over a class’s size should always be tempered by these criteria. If a class is as simple as you can make it, and it has many methods, and its utility would suffer from breaking it into smaller parts, then it may be that you have a class that is simple and cohesive—just not small.
Understanding Encapsulation
A lot of Java literature treats the term data hiding as a synonym of the term encapsulation, but there is a broader meaning to the latter. Encapsulating data means bundling it with methods that operate on it and provide indirect access to it. But that doesn’t mean there has to be a one-to-one relationship between a hidden field and the method(s) that expose(s) it, such as a get and set method pair for every field.
To encapsulate data in a broader sense, we need methods that access and manipulate each field in the ways the programmer intended. If it happens that a one-to-one relationship makes sense—and it sometimes does—then an accessor method is a logical choice. But we should not automatically provide an accessor for every field.
Consider a class called Circle. Its data could be represented by a radius field alone. Other values a Circle user might like to retrieve, like its area and circumference, may be derived from its radius field, so there’s no need to store them. There are then a couple of ways to represent a Circle object through its method interface, each with its own merits.
Figure 6-4 shows a simple data hiding approach on the left that makes the radius field private and its accessor method public. Anyone who wants to derive the area or circumference of a Circle object can implement the logic themselves. The chart on the right interprets encapsulation in its truest spirit, completely separating the services of the class from the data required to implement it.
Figure 6-4: Two class diagram views of the Circle class

The Circle class that includes the methods getArea(), getCircumference(), and getDiameter() doesn’t have any extra data, but data hiding isn’t the point driving this class. It’s the services the class offers that matter. Now the field is simply an implementation detail. Perhaps the programmer who looks at the source code will decide this approach is clever or surprising, but a caller to this interface just knows you can get all the information you need about a Circle object from its methods.
If users can get what they need through the method interface, the implementation shouldn’t matter to them. For the programmer who maintains this code, it’s a different matter. Through this separation of service and implementation, the class programmer has the freedom to modify the fields, or even a method’s code, without changing the method interface. Whatever the reason for those changes might be, the class programmer doesn’t have to worry that callers will see anything different from their view of the class.
I might be alone in suggesting encapsulation means more than data hiding. It’s not just an academic point, however. Data hiding is a plain phrase that, without further explanation, implies that writing a bit of boilerplate code is all that’s needed. To my mind, that’s mistaken thinking. I’d like to make sure you avoid it. Encapsulation, on the other hand, implies forethought in class design as one step and realizing that design as a second step. By putting some thought into giving the users of your code more freedom, you can make it so the class lets each of them work without getting in each other’s way.
Understanding Mutability
Before we add mutators, or methods that let the caller change an object’s state, I should say more about mutable and immutable classes. Objects of an immutable class, you may recall, don’t change state. What you haven’t heard yet is what’s good about them.
Immutable objects have two great benefits. One, they have a value that is always true; that is, always the same. There is never an additional cost to maintaining them and never a need to copy them. Two, they are always safe to pass as a parameter and always safe to return as a value. These properties are valuable in reducing the number of dimensions in which a state change can occur.
When programs crash, it could be for lots of reasons, but malformed logic and bad inputs cover most of the territory. When you can rule out parts of your program on the grounds they are correct and unchanging, that’s a big help. One way you can do that is by reducing available mutators to the smallest useful complement. And that means asking, among other things, why each and every set method you use is necessary.
Writing a class that guarantees immutable behavior goes beyond our scope, but it’s important to know they exist and do a lot to simplify large programs. Justifying your set methods before you add them is a solid beginning.
The String class is an immutable class, in part because of the way it’s implemented (with a character array). The JVM realizes some performance benefits by fixing the size of each String object at construction. There are also some drawbacks, in particular when using them for parsing, concatenation, inserting or removing characters, and other character-level string operations that don’t take advantage of constant values and instead add processing costs. The StringBuilder class is much better suited to those operations and was introduced to the core libraries for that reason.
In lieu of writing formally correct immutable classes, you can still write classes that limit mutability. The less mutable the object, the simpler it is. Which is a better approach for a Circle object, for example: Is it to fix its radius value once it’s constructed and let the caller make new ones as needed? Or is it to let a caller make one Circle object and change it as needed? The answer depends on how you expect the object to be used. There’s no single right answer for all applications.
As a rule, don’t allow set methods in your classes until you can justify their use. In many Java classes, programmers add them as a matter of habit because it’s easy and therefore seems to save time. Limited mutability is a far better prize, but it’s hard to appreciate. It’s like a printer that never jams; you’ll like it better when you have to use a printer that throws error codes every day.
Using Final Classes
Here’s another way to limit mutability: Declare your classes final. A final class cannot be extended, or subclassed; the compiler won’t allow it. By declaring a class final, you can also imply that your class is not designed for extension by another class:
public final class Point3D {
private int x = 5;
private int y = 12;
private int z = 13;
}
class Point4D extends Point3D {
private int q = 42;
}
$ javac Point3D.java
Point3D.java:7: error: cannot inherit from final Point3D
class Point4D extends Point3D {
^
1 errorIn this example, I declared the class Point4D a subclass of the class Point3D, using the keyword extends. This declaration tells the compiler that the Point4D class is-a type of Point3D (which itself is-a type of Object). As you’ll learn in Chapter 9, when you want to specialize an existing class and reuse its code, inheriting from it creates a type relationship and avoids duplication of effort.
What the compiler does to support inheritance, however, has nothing to do with ensuring that subclasses are safe or reliable extensions, and there is indeed a fair amount of work to ensure those qualities. Until we learn what that work entails, it’s a good idea to disallow subclassing in your own code.
Marking a class final can in fact serve a number of purposes. It may mean the author did not bother or did not want to allow inheritance. Perhaps a class contains logic that should not be altered in any way by other programmers. Perhaps it runs faster. The String class, you may have noticed, is marked final, perhaps with both reasons in mind. I’ll use it for the rest of the book to signify only that my sample classes should not be considered ready for that use.
This modifier can save your average try-and-see programmer time in experimenting. It can also save the class’s author a lot of time in documenting. The day will come that you have to debug some quirky bit of Java code. And you may work on it for a while before you realize that you wrote it. When that happens, you’ll understand that documenting code doesn’t just help other programmers. It’s also a way to leave notes for your future self, who might be a very different kind of programmer by then.
Be both kind and wary of this person, your future self. He or she will go through several profound changes while learning. That person, however well meaning, also gets disoriented and forgets what they were like, kind of like an old fisherman from a small village who’s suddenly grown 50 feet tall. They’ll want to test their new strengths and abilities on objects that are close at hand. Old code will look like a toy and probably won’t appear as fragile as it is. If the code can tell you it wasn’t designed with the future giant you in mind, it may seem stifling at first, but you’ll also appreciate not having it fall apart in your hands.
Exposing Data through Methods
Limiting mutability and making classes final aren’t part of encapsulation. By incorporating these habits, you’ll restrict yourself from using certain Java features until you better appreciate what to do with them. They do go hand in hand with an important rule of thumb: making fields private and methods public. This rule is (too) often interpreted to mean always use accessors (get methods) to retrieve an object’s state and mutators (set methods) to change it.
Now that we know why we shouldn’t do that automatically, let’s discuss where it makes sense to apply it: when we want a Java class to act as a data container, and not much more. This kind of class is called a bean, and it has some important applications.
Understanding the Bean Model
Some Java classes exist solely to expose their data as a list of properties. Let’s say you want to write a program that reads lines from a file one at a time. Each line is a record that follows a standard format. It therefore makes sense to think of each line as one object and the format as a type, such as a Record class. All you need from this class is access to each field, which you can expose using an accessor method for each part of the record.
A Java bean is this kind of class, exposing each underlying field with a method pair, one accessor and one mutator. The bean model also uses a naming scheme that is spelled out so helper classes in the core libraries know how to read the method as a property type. Classes in the java.beans package provide the means to examine the method interface of a Java bean and determine its properties.
To give an example of the naming scheme, I’ll write the Point3D class as a straightforward Point3DBean:
public final class Point3DBean {
private int x = 5;
private int y = 12;
private int z = 13;
public int getX() {
return x;
}
public void setX(int newX) {
this.x = newX;
}
public int getY() {
return y;
}
public void setY(int newY) {
this.y = newY;
}
public int getZ() {
return z;
}
public void setZ(int newZ) {
this.z = newZ;
}
}Each field has a method pair. The accessor method returns the same value as the underlying field. The set method requires a parameter of the type and returns void. The matching names—literally, the character sequence that follows the set and get portion of each method name—does the rest. This version of the Point3DBean class has three bean properties: X, Y, and Z.
Adding the word Bean to the class name doesn’t do any additional work. It just tells a knowledgeable Java programmer what purpose the class serves. Also, it’s nice if the method names match the field name, but it’s not required. You could have a field named x_coord and decide to name the property X instead. If you do vary the property name from a field name, however, make sure to document the variance with a comment to avoid confusion.
There are other rules that deal with capitalization (Java is case sensitive), beans with read-only properties, and other stuff, but that can wait for the day you need to learn the JavaBeans specification. Here I only wanted to explain why some classes are written this way.
For reasons not clear to me, some programmers apply this model well beyond its intended purpose. Do be wary of code where many classes seem to follow this pattern, as if every class should be considered a list of properties. Beans should not be taken for a default model of Java class development.
Distinguishing Methods from Data in a Class
Now that you understand the basics of the bean model, I want you to think broadly about the purposes a method can serve. Thinking of data as an implementation detail doesn’t, by itself, tell you how to write code but it does emphasize that a class’s services and its composition can run along separate paths. Even in the bean model, where the relationship between fields and methods seems tight, all the methods do is define bean properties.
How do we take advantage of that? By adding meaningful code, of course, but to what end? For starters, you can add code to accomplish the following:
- Validate incoming parameters
- Restrict the range of acceptable values
- Induce side effects
I’ll address each of these points in turn.
Validating Incoming Parameters
When a method receives a parameter, it has to make sure the parameter value is something it can use. In the main() method, for example, you can test the length value of the args array to see if it’s nonzero. If it isn’t, you can inform the user that some input was required before stopping the program.
Say you have a deposit(double amt) method in an Account class. It’s used with an ATM whose console, lucky for us, doesn’t allow a customer to enter a negative number. But what if the customer accidentally deposits zero dollars? It’s a nonnegative value, but it’s also not worth processing. The deposit method could return the current balance as a pseudo-update to the account, or it could just ignore that input value:
private double balance;
public void deposit(double amt) {
if (amt == 0) {
System.err.println("Zero dollar deposit!");
return;
}
} If the parameter is instead an object reference, there are two cases like this you have to consider: one, if the reference value is null; and two, if it is non-null but also empty of data, like an args array with a length value of zero or a String that refers to "".
Every public method that accepts parameters has to defend against unusable data. If we do accept bad data, what is the worst possible outcome? It isn’t a program crash. Program crashes aren’t bad. They’re inconvenient and sometimes frustrating, but they tell you something is wrong and needs attention. Bad data that goes on undetected for a long time—that’s bad.
How long before bad data in one part of our program propagates and corrupts data in another part of our program? How long before we figure out it’s happening? Once we figure it out, how do we determine its origin? That’s the nightmare scenario in programming.
Restricting Range
Types like the double primitive aren’t directly suitable for representing real-world objects like a dollar, so there are usually other adjustments to consider It’s one thing to rule out logically invalid ranges like negative and zero deposit amounts. It’s another to test both for unlikely values, such as a $2 billion deposit, and for an amount beyond two decimal places, such as $5.0014.
In traditional programming languages, it’s a common task to adapt the types provided to suit a specific use. Primitive types are a tempting choice because they are register-based, faster to access, and faster to compute than their object-based equivalents. Over millions of calls, the JVM will spend less time processing primitives than references. At the same time, you have to surround the primitive type with code to make it behave like a dollar.
Once you formulate the rules that govern your datum in Java, that’s when you think about designing a class, using methods to manage the data in a correct and logical manner.
Validating can weed out nonsense values much like restricting the numeric range does. I like to think of restricting range as applying a constraint, while validating protects the sanity of the data. Either way you’re using conditional statements to test your values, following one path of execution if they’re acceptable, another if they’re not. Methods protect your fields. If you allow direct access instead, you have no defense against assignments that are out of range or just don’t make sense.
Inducing Side Effects
Sometimes you want a method to change state in an object in a way that isn’t apparent to the caller. Let’s say you want to track how many times a customer makes a deposit— that is, invokes the deposit method. You could add an integer field to the Account class and increment it each time the deposit method is called. That data is not intended for the customer’s eyes, so there’s no reason to expose it:
public final class Account {
private int count;
private double balance;
public void deposit(double amount) {
count++;
// rest of method logic
}
public double getBalance() {
return balance;
}
public int getCount() {
return count;
}
// do we need a setBalance() to correct errors that occur?
// what about a setCount() to roll back a failed deposit?
}Every time the deposit() method is called, the count variable increments. This is an intended side effect. There are unintended ones, too, that can plague your code. Sometimes they come about because one method you use induces a change elsewhere (for example, by charging a service fee for too many deposits). Just as the plants you want to have in your garden are flowers and the ones you don’t want are weeds, the side effects that you want are good and all others are bugs. Unlike weeds, bugs can be hard to spot; yet another reason to keep the mutability of your classes to a minimum.
Choosing Methods to Make Public
One more point follows from our side-effects example. With the count field, we’ve added information and potential state behavior to the object in a way that would be hard to handle with just private fields and public methods. As the comments in the code example suggest, how can we allow for methods that let us correct an Account object without exposing too much control?
You probably don’t want the Customer object using an Account object to correct its own balance or set the number of deposits transacted in a statement period. This work is more appropriate to an AccountManager type. How do you allow an AccountManager object access to an Account object without also allowing a Customer object the same access?
There are a couple ways to think about this. One is to make the Account object something a Customer object cannot handle directly. You could use ATM and OnlineAcctManager classes to handle Account objects directly. You could then require the Customer object to use these objects to get access to their Account object. Figure 6-5 diagrams the key elements of this relationship. How you can limit access to some classes but not others is the subject of the next section.
Figure 6-5: Possible relationship between Customer and Account classes
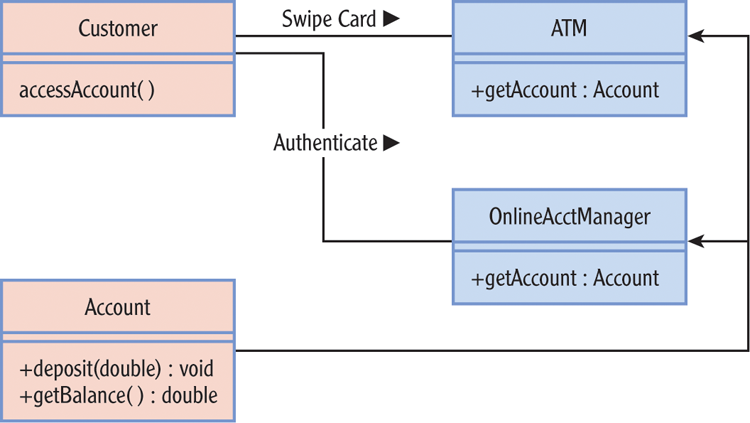
It’s easy to say you should limit exposure. Because the goals in mind are qualitative, it’s hard to come up with hard-and-fast rules for applying that principle. A few general questions can help you qualify these decisions and give you some insight to arranging your code in the clearest manner:
- Does the method change the state of the object?
- Will the method induce a side effect?
- Does the method create new objects?
- Will the method return a reference to its containing object?
I haven’t discussed the consequences of all these questions, so for now you can use them with a simple piece of advice: If your answer to these questions is yes, then ask which objects will have access to the method. If you mark that method with a private modifier, its only effective purpose is to help another method in the class. If you mark it with the public modifier, the method appears as a service anyone should be able to use. Be sure that’s what you intend.
So, how do we create different levels of access for different classes? It turns out that packages are more than just a namespace. Classes that share the same package also have a shared scope. That means you can declare class members so only other classes in their package can see them. Once you apply this technique to your advantage, you’ll appreciate packages on a whole new level.
Applying Access Modifiers
In Chapter 1, “Introducing the Basics of Java,” you learned to store multiple classes in one file. You can actually put as many classes in one file as you like, so long as none of them are declared public. If you declare one of them public, its name must match the file’s name, minus the .java extension. In writing code for this book, for example, I’ve created various files all named stuff.java, put them each in a different folder, one per chapter. If I find a class useful, I cut it from this file, put it in a separate namesake file, and declare it public. It’s not a common scheme, but with this approach I am not committing myself to naming classes until I have a clearer picture of what they’ll do.
In discussing how Java objects communicate, in fact, I am sometimes at a loss for a concrete example at the moment, and I’ll start writing in abstractions like Listing 6-1.
Listing 6-1: Class relationships without a specific program context
final class Test {
public static void main(String args[]) {
FirstThis myft = new FirstThis();
Other other = new Other();
myft.pokeThat(other);
}
}
final class FirstThis {
// object-level coupling
private ThenThat that;
// method-level coupling with Other
public void pokeThat(Other other) {
that = new ThenThat(other);
System.out.print("FirstThis to ThenThat: ");
System.out.println("is Other there?");
that.pokeOther();
}
}
final class ThenThat {
private Other other;
// constructor-level coupling
public ThenThat(Other other) {
this.other = other;
}
public void pokeOther() {
System.out.println("Hello, Other?");
System.out.println(other.respond());
}
}
final class Other {
public String respond() {
System.out.println("This is Other");
return "You want something?";
}
}
$ javac stuff.java
$ java Test
FirstThis to ThenThat: is Other there?
Hello, TheOther?
This is TheOther
You want something?There’s a lot going on in this example, so let me point out some key features before getting back to the point at hand (which is packages). First, I added comments to point out different degrees of coupling: Use them as a first look at tight and loose relationships. The degree of intertwining you form while sketching out classes in code can quickly take on a life of its own. It’s one motivation for starting with diagrams. It’s easier to erase and redraw lines of association than it is to refactor even a few dozen lines of code.
Second, there is real work in naming classes well. I punted on that issue in this example, but that doesn’t mean I didn’t trip over myself anyway. I started out thinking I’d make This, That, and TheOther classes. I didn’t think through the conflict with the this keyword; I saw how awkward it was when I needed a This variable. Oops. Starting a sentence with “the TheOther class” was another lesson in careful naming. Moral of the story: Don’t commit to code before you think about naming. Communicating clearly is the goal. You won’t get there by chance.
Those things said, take some time to walk through this code carefully. If you can verbalize clearly how it works, you have taken a big step. Examples like this abound in quizzes and exams, designed, it would seem, only to jellify your brain. It may not feel like fair game, but you’re going to encounter code like this, and worse, you’ll encounter it in your programming career. Start acclimating now.
Next, notice that all these classes can see each other, not including the private members they maintain. When you put two or more classes in the same file or the same directory, they share an implied package. That’s good news. It means you could put each of these classes in their own file and they’d still work together. And here’s the fun part: You still don’t have to declare them public. Something else is afoot that keeps these classes visible to each other.
Working with Packaged Classes
Using Listing 6-1, put each class in its own file. Don’t declare any class public. Compile them and run the Test class. It should all still work.
You don’t have to delete the original file. Just bear in mind that you will overwrite the .class files you have each time you recompile. So long as the code remains the same, there’s no difference to notice. Now, in the original stuff.java file, declare a package:
package stuff;
...The code will compile as before, but you’ll get errors trying to run it. If you declare a package but don’t tell the compiler to produce the class files in a package-aware way, it will write them to the current directory. Now, however, the JVM won’t find them:
$ javac stuff.java
$ java Test
Exception in thread "main" java.lang.NoClassDefFoundError:
Test (wrong name: stuff/Test)
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:791)
<more exception information omitted>
$ java stuff.Test
Error: Could not find or load main class stuff.TestIf you omit the package name from the class after compiling, the error message is more information than you want right now. I clipped some of it to conserve space, but you should try it and see the full effect on your computer. If you address the class by its new package scheme, you only get a shorter error message for your trouble.
To get back to running code, tell the compiler at which location you want to create the package structure:
$ javac -d . stuff.java
$ ls
stuff
$ ls stuff
FirstThis.class Other.class Test.class ThenThat.classSimple as that! The -d option tells the compiler that the current directory, symbolized by a dot, is the start of a classpath. The compiler uses the package name to create a directory structure and deposits the class files accordingly. To find a packaged class, you have to pass this information using the java program with the -cp flag:
$ java -cp . stuff.Test
FirstThis to ThenThat: is Other there?
Hello, Other?
This is Other
You want something?And we’re back in business!
What happened here? Java treats a source-code file with no package declaration as a default package and the current directory as an implied classpath. Once you declare a package, you have to handle the classpath explicitly. Java’s tools translate package naming to a filesystem structure in order to maintain a separate namespace for each declared package. The designers chose to remove this requirement for the simplest case (no explicit package declaration), but it’s still a confusing transition.
Now try to access a class in the stuff package from a class in another package I’ll call the miscellany package:
package miscellany;
import stuff.*;
public final class Misc {
private FirstThis fthis;
// add these fields if all goes well
// private ThenThat tthat;
// private Other other;
}
$ javac -d . -cp . Misc.java
Misc.java:6: error: FirstThis is not public in stuff;
cannot be accessed from outside package
private FirstThis fthis;
^
1 errorThe Misc class imports the contents of the stuff package. It compiles to its own miscellany directory and uses the classpath to locate the FirstThis class, but it doesn’t matter. None of the classes in the stuff package are public, so they are, in effect, package private. Without at least one public class, there’s no access from the outside world. What does it mean to have no access modifier keyword at all?
Using Access Modifiers with Package-Aware Classes
With explicit packaging, you gain two access modifiers. What you’ve observed in the previous section is the default access modifier, also known as package-private. When you want only classes in the same package to see each other’s members, declare those members without an access modifier.
Packaging helps you describe internal and external class relationships in greater relief. A diagram at the package level, such as Figure 6-6, makes it easier to define class relationships between two packages.
Figure 6-6: Package view of Customer and other classes
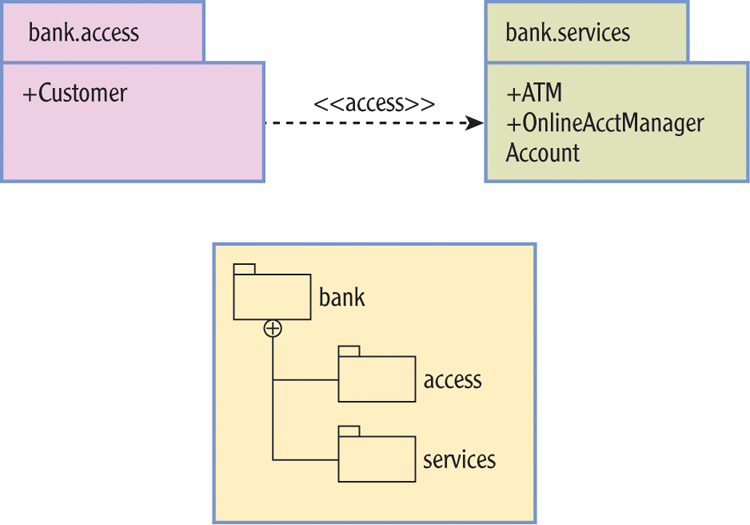
The bottom box shows the full package relationship. The top-level package bank holds two subpackages called access and services. The bank.access package contains a public Customer class that can see the ATM and OnlineAcctManager classes, as signified by the plus signs, but not the Account class, which has default access.
The Account class is not visible to any class outside its own package, expressing what I wanted to get across with the arrows I used in Figure 6-5. A Customer object can use an ATM or OnlineAcctManager object in principle. Now all I have to do is declare the proper import statements and set the correct classpath values. I can restrict access to the Account class itself to other classes I trust, that is, the classes I have designed to work with it the way I intended.
I used the bank package itself only for a namespace. It suggests the context of the packages and nothing more. I can add classes to it, but then I’d be treating it like a nameless, implied package, just as when I don’t use package names at all. That’s a condition I’m trying to get away from with named packages; it’s best to leave it unpopulated, except, of course, for other package names.
Using Default Access with Class Members
Once you start working with explicit packaging, you can also apply default access to class members. Fields and methods with default access are accessible to any caller in the same package.
Since I just made the case for data hiding at length, you might ask why I would now propose increasing the visibility of class data. It’s a fair question. Declaring a package gives you a way to expose data to a limited number of classes, presumably ones you can trust, but that doesn’t somehow make it a smart or safe thing to do. Let’s consider an example.
Say you wanted to add an Auditor class to your bank.services package. You want the Auditor class to debit each Account object if the number of deposits made to it exceeds 10 in a statement period. This action will rely on the side effect I added, in which the deposit() method increments a count field each time it is called.
You don’t have to remove the private declaration from the count field. A default access getCount() method gives the Auditor class the visibility it needs without adding mutability to the Account class:
package bank.services;final class Account {
private int count;
private double balance;
private int acctID; int getCount() {
return count;
} public double getBalance() {
return balance;
} void setBalance(double amt) { // needs error checking balance = balance - amt;
}
}final class Auditor {
private void charge(Account acct) {
if (acct.getCount() >= 10) {
System.out.println("Deposit limit exceeded");
System.out.println("Fee assessed");
acct.setBalance(acct.getBalance() - 3);
}
}
}If you want to charge an Account object a fee for exceeding 10 deposits from outside the package, however, that’s another matter.
Bear in mind any class in the bank.services package can use the getCount() method. If you want to make it so only the Auditor class can see this method, you’ll have to change the packaging or use facilities in Java you haven’t learned yet. Access modifiers help you limit visibility, but if you don’t control the remaining classes in the package, you don’t have any better protection, just fewer potential programmers hacking away at your code.
In my view, you should make an airtight case for declaring a field anything but private. Don’t think better performance from accessing a field directly is a benefit, as some programmers do. You have to deluge an object with many method calls to see an appreciable difference between a method call and field access. Then consider that savings, if any, against the abuse some programmer will surely visit on that field. Also compare it against the howling you’ll hear when you decide to change the field’s type and programmers who depended on your class find their code now breaks. Unless you can think of an even worse consequence than this, keep your fields private.
Understanding the protected Access Modifier
There’s one more access type I haven’t covered by the protected keyword. It is similar to default access but includes one more thing: A protected class member is also visible to any subclass of its type, regardless of the package the subclass resides in.
I said earlier that package-private access is more reliable if you control all a package’s contents. You can then decide which classes may use that access. One assumes you won’t abuse the privilege. In that sense, in a package you can relax the rules for yourself and you will use that license responsibly.
Let’s say you’re designing a class so others can inherit from it. You want to expose certain methods to those subclasses so they can change state in the parent class. By definition, these subclasses will reside in other packages, so default access won’t help them. The protected modifier will.
When would you use this extra leeway? Let’s say you invited a consultant to design an ExternalAuditor class to complement your bank package. You decide this class should reside in a separate client.audit package along with other external tools. A subclass inherits methods from its parent, but only the ones that are visible to it. If you want an ExternalAuditor class to inherit certain methods from your Auditor class, you must declare them protected.
// final modifier removed to allow subclassing
// public modifier added to increase visibility
public class Auditor {
// modifier changed to protected
protected void charge(Account acct) {
if (acct.getCount() >= 10) {
System.out.println("Deposit limit exceeded");
System.out.println("Fee assessed");
acct.setBalance(acct.getBalance() - 3);
}
}
}
<different file>
final class ExternalAuditor extends Auditor {
// inherits the charge() method
}You should, of course, know how the protected modifier works and how to interpret it and apply it in an exam. Unless you’re developing packages for other programmers to use, you may not use it much. Most of us write application code—programs—most of the time, not packages of software for others to use.
As a rule, expose class member outside their package, even to subclasses, with plenty of skepticism. (Take the lack of a diagram in this section as a hint.) It is always tempting to relax your access modifiers in the name of remaining flexible. Prefer to allow only what you need to satisfy your program’s requirements. The future is not entirely unpredictable, but it doesn’t have to be to foil most attempts at anticipating it.
Remember, you can always increase a class member’s visibility without harming classes that depend on it. When you restrict visibility, it’s a different story. You’ll break someone’s code somewhere. Young programmers, alas, seem inclined to believe that restrictive modifiers are like handcuffs and permissive modifiers are like blue skies. So, from me to you, old guy to new programmers, a word of wisdom: Handcuffs come off. Things fall out of the sky all the time, usually red-hot.
Abstracting Data
The semantic separation between the fields that make up a class’s data and the methods that make up its interface is called abstraction. We want a class to express some object-like concept—a dollar, a circle, or a point. The data we use to emulate that concept is storage with their own built-in services, nothing more.
A good method interface lets the programmer think in terms of an object’s services and states. The human brain is far better with that idea than with having to consider all of an object’s moving parts at once. Currency has everyday meaning to far more of us than floating-point values made to express dollars. We’re better at thinking about shapes, on the whole, than we are about locations in three-dimensional space with integer vertices.
As you adapt to an object-oriented view of programming, you’ll repeat this paradigm, assembling simple objects to make more complex ones and create more sophisticated abstractions. It is not a perfect scheme, mind you, but you’re also quite a ways from seeing where this system can break down under its own weight. For now you’ll have plenty to do learning the ropes.
In the next chapter, you’ll learn to design methods. After that, it’s a short step to thinking about the kinds of objects you need to write Java programs with objects: what you want your program to do, what objects you need to perform that work, and finally, which method names help make that work as easy on the brain as you can manage.