
Chapter 1
Analysis of an Audiovisual Resource
1.1. Introduction
This book’s goal is to present a functional approach based on the semiotics* of the audiovisual text* [STO 03] for the analysis, i.e. the description, interpretation and indexing of digital audiovisual corpora.
The central notion used for this approach is of the model of description* of an audiovisual object, such as a video, based on a set of criteria which serve the semiotics to process the text object* and will be presented in greater detail in Chapter 3 of this book. Primarily, it is a question of the following criteria:
– the criterion of the text as a compositional entity (a text can, in principle, be broken down into “smaller” textual units, and in turn forms part of a textual environment, of what is, metaphorically speaking, a textscape or mediascape);
– the criterion of the text as a structural entity possessing a set of characteristic constituents (such as the thematic constituent, the narrative constituent, the rhetorical and discursive constituent, the multimodal expression of content, or the formal and physical organization of the content in the text); and finally,
– the criterion of the text as a historical entity (the text as a genre) and an evolutive entity (the text as the product of savoir-faire, in principle always modifiable).
The hypothesis behind this book is that any project of analysis of a textual corpus in general and an audiovisual corpus in particular – whatever its level of specialization – relies on representations, “visions”, or theories: 1) about the object text and 2) the activity of the analysis* of the text.
Thus, all told, a model of description is nothing more or less than the explicitized, formalized (in the broader sense of the word) part of a theory or vision which guides the task of analyzing a textual corpus (in our case, audiovisual).
The gap of “satisfaction” which may exist between the model and the theory or vision underlying the work of analysis can be explained either as a more or less significant implicit factor which guides the analyst in his work and which the model is not capable of taking into consideration, or by imperative simplifications which must be carried out in relation to a theoretical referential to develop an explicit and functional approach to the analysis of textual, or audiovisual, corpora.
The work of definition, development, validation and tracking of models of description of textual and, particularly, audiovisual corpora, still represents an entire occupation, i.e. a set of specialist skills and knowhow calling on a varied body of culture and knowledge which cover not only the practical and technological domains such as information and knowledge technology, applied sciences of documentation, archiving, library sciences or the management of cultural heritage lato sensu, but also – and, in our opinion, crucially – a set of disciplines in human sciences such as text sciences (and particularly semiotics*), linguistic sciences or even that heterogeneous emerging set of approaches and problems classified under the general umbrella label of “cultural sciences” (Kulturwissenschaften, in German).
The occupation in question is that of the concept designer*, sometimes also called concept-designer*, or information technician or engineer; indeed, the terminology is still very fuzzy and unstable. However, it is a central role of the workflow* [STO 11e] defining the constitution, analysis and publication/diffusion of bodies of knowledge heritage which are channeled by audiovisual corpora. The modelizer prepares, develops and manages all the metalinguistic resources necessary for the other actors involved to carry out their work.
1.2. Functionally different corpora
As part of the process of digitizing knowledge heritage, we can distinguish a series of categories of models (i.e. metalinguistic resources) needed to accomplish the various activities making up that process.
As set out in [STO 11e], the process of constituting a body of knowledge heritage in the form, e.g. of a digital archive, takes place in various canonic stages – notably:
1) the stage of preparation of a field for collection of data documenting a body of cultural heritage;
2) the stage of the realization of the field work1;
3) the stage of technical and auctorial treatment of the data collected (including, amongst other things, the derushing of audiovisual data, the montage and postproduction of the audiovisual data collected);
4) the stage of analysis (description, indexing but also pragmatic adaptation) of the data collected and documenting a terrain;
5) the stage of the publication and diffusion of the data collected and/or analyzed and, finally,
6) the stage of conservation of the data collected/analyzed/published.
However, each stage in this process of digitization of a body of knowledge heritage necessarily has to do with a certain functionally specialized type of corpus* (in our case, an audiovisual corpus):
1) The stage of preparation of a field for collecting audiovisual data can only be conceived of in reference to a pre-existing corpus, or by compiling the knowledge and sources of information necessary to the proper functioning of the field work (knowledge and sources which could cover bibliographical references, online resources, personal information, ‘good practices’, examples of similar projects underway or already carried out, directories, etc.).2
2) The stage of data collection leads to the creation or updating/enriching of a pre-existing field corpus*. The field corpus is made up not only of data produced within the boundaries of the field. Take the example of the recording of a field as circumscribed as a research seminar whose sessions to be filmed are spread out over a whole academic year. The corpus of data documenting the field research seminar is not (necessarily) restricted to the audiovisual recordings of the various sessions. It covers all the data deemed pertinent either to give an account of that field (i.e. to make it an archive of knowledge in the true sense of the term), to facilitate a highquality analysis of such-and-such an aspect of the filmed session, to have a documentary base in view of one or more publications (online) of the seminar, or to transform it (as it is, or after a process of selection of documents which must be preserved “absolutely”) into a heritage corpus (see below) documenting, e.g. the history of a discipline or of a research institution.3
3) The stage of technical and auctorial processing relies on a selection of collected data forming part of a field corpus, or else of several field corpora, or on data stemming from different periods in the life of a field corpus (a field corpus can be updated, enriched, etc.). In any case, a processing corpus* is composed of data selected, e.g., with a view to being cut together to constitute a new audiovisual creation corresponding to an authorial intention to publish (i.e. to a scenario defining such a creation). Thus, an intention to publish the recordings of a research seminar may be aimed at diffusing a certain problem dealt with during the said seminar. In this case, not the “entire” seminar is the object of an intention to publish, but rather just those parts of it in which the problem chosen is dealt with. Yet even when a decision is taken to publish “the entirety” of the seminar, the recordings made during the field phase have to undergo technical processing (encoding, checking of the image and sound quality, deletion of unusable passages, etc.) before being made available for publication of the seminar and its various sessions in the form, e.g., of a website. Hence, no matter whether the processing stage is reduced to a “simple” activity of processing or whether it also covers a genuine authorial activity per se, the question of the definition and constitution of the processing corpus arises every time. Note that in addition, in the context of digital archives of knowledge, a processing corpus can be fed not only by data from one or more field corpora, but also by data already published and “re-injected”, reused in the context of a new technical, and above all authorial, treatment. In concrete terms, a corpus documenting a scientific problem which is dealt with in a seminar and which is the object of a montage with a view to publication online, alongside original data (e.g. from a new field corpus), may perfectly well include parts from pre-published contributions.
4) The stage of analyzing the data collected is the one which interests us most, and to which this book is dedicated. For the moment, let us highlight that the analysis of a piece of textual information (or, in our case, audiovisual information) cannot be reduced to a “simple” free indexation, nor to indexation controlled according to this-or-that standard, this-or-that documentary language. The analysis includes all intellectual activities – from documentary indexation to the most personal interpretation, through the various forms of professional assessment of the information – which “use” and “exploit” the object text* to satisfy a need (a desire, or a simple curiosity) for knowledge. However, such a need or desire may stem from very variable motivations, and arise in extremely different social and cultural contexts. It is still true that analysis as an activity to satisfy a need or desire for knowledge can only be successfully carried out if the right object is available to it, as its primary material which is the text* or rather, the corpus of texts. In the context of the constitution and diffusion of a body of cultural/knowledge heritage, the analysis corpus*, i.e. in our case the corpus of audiovisual data being analyzed, is not necessarily coextensive with a field corpus – far from it, in fact. Indeed, everything depends on the goal of the analysis* and, more generally, on the analytical policy* (e.g. in the context of exploitation of the contents of an archive* of knowledge). If the analysis is conceived as an activity of description and classification of data collected beforehand and documenting a particular field with a view, e.g. to their publication online, the field corpus and analysis corpus become similar – although they do not merge. If the analysis is conceived independently of the activity of collection, the corpus of audiovisual data needed for the analysis to fulfill its goals, obviously, no longer has anything to do with this-or-that field corpus. The analysis corpus is constructed and enriched solely according to the objectives of the analysis itself. In [STO 11b], two examples are provided of the constitution of an analysis corpus fed by data from different field corpora: the first example is of the analysis of traditional bread-making in France and Portugal [DEP 11d]; the second of the comparative analysis of the view of the Arabian Nights and the creative uses certain artists make of the tales [CHE 11b]. In both cases, the analysis corpus is composed4 not only of data derived from different field corpora (fields created as part of the ARA Program)5 but also possesses its own dynamic of enrichment or updating.
5) The stage of publication/diffusion of the data in turn relies on a corpus of data – the publication corpus* – which is not necessarily coextensive with the field corpus or the analysis corpus. For instance, in the process of publishing a research seminar or interview, filmed and analyzed, the four functionally distinct corpora – the field corpus, the processing corpus, the analysis corpus and finally the publication corpus – may become similar, or even (partially) overlap. However, they remain functionally distinct, obey their own motives and objectives, evolve and are managed according to criteria specific to the requirements of the activities for which they are the main body of work. Thus, the publication corpus may be made up of, simultaneously, data from one or several analyzed corpora, of previously-published data, of data collected but not necessarily analyzed, etc. The essential criterion for evaluating the quality of a publication corpus is its capacity to satisfy an intention of publication (see [NAN 05]) and, more particularly, formal rules governing a given genre of publication [DEP 11b]. Let us stress here, that a publication corpus may be made up of already published data.6 Here, we touch on the problem which, nowadays, has become a widely debated problem in documentary repurposing7, the re-mediation of textual data which have already been mediatized – a problem which relates directly to the legal protection of the content and the traceability of the use to which certain content is put.8
6) Finally, the stage of conservation of the data collected, processed, analyzed or published in the context of a project or program to constitute or distribute a knowledge heritage database is more particularly concerned with selecting these data to create a patrimonial corpus in the true sense with the objective, among others, of safeguarding a set of knowledge and values, i.e. a culture and its traditions, and passing them down from one generation to the next. In formal terms, a patrimonial corpus may be similar to one or other types of corpus identified and discussed above, but functionally speaking, it is different from all the rest. In addition, this means that even if, technically, the constitution of a patrimonial corpus can be reduced to simply selecting data from the different corpora which characterize the task of constitution, analysis and distribution of a body of knowledge heritage, that technical activity of selection is necessarily subject to a patrimonial policy (in a strict or a broad sense). Thus, the constitution of a patrimonial corpus documenting a specific scientific problem, e.g. may have the aim of creating and changing a veritable culture in the matter with its values, its traditions, its doxa, it heterodoxies, but also its great discoveries and inventions, its “heroes”, its milestone events and dates, its savoir-faire, etc. The constitution – and enrichment – of a patrimonial corpus may also have the aim of promoting the identity and fame of an institution – its excellence, its competitiveness, its attraction, etc. As we know, the promotion of an institution’s identity is no longer the preserve of commercial companies and enterprises, but rather, following the drastic changes affecting the global framework of research and public-sector education, has become a major concern for universities and other public-sector establishments for research and higher education.9
1.3. Descriptive models
The actual work of constituting and exploiting these different, functionally distinct corpora is necessarily determined by (conceptual or metalinguistic) models making up the reference framework, both intellectual and practical, for the actors involved in that complex process which is the digitization of a body of knowledge heritage, i.e. the collection, processing and analysis, publication or republication and longer-term preservation of all sorts of documents bearing witness to the knowledge and savoir-faire, the beliefs and values, the norms and rules, the customs and behaviors, etc. of a person, a social group, an institution or even a country, a region, an era.
Now we perhaps have a fuller understanding of the strategic position occupied by the concept designer in the workflow of constitution and diffusion of bodies of knowledge heritage. The concept designer prepares, develops, manages, etc. all the models needed to bring to fruition the activities involved in the constitution, exploitation, diffusion and conservation of a body of knowledge heritage in the form of a corpus of textual data (more particularly, in our case, audiovisual data). In comparison to the different functionally distinct types of corpus which mark the process of constitution and diffusion of a knowledge legacy, in particular it is a question of:
– the models of description* needed by the analyst* (another key role in the working process in question) to carry out the description, indexation and annotation of audiovisual corpora;
– the models of collection needed by the field producer, i.e. the person or persons in charge of defining a field work (lato sensu), a task consisting of the reasoned collection of data to document a domain of knowledge, a manifestation or an event;
– the models used by the specialists in derushing and the editors to carry out a technical and authorial treatment of a corpus of collected data (in the case of audiovisual data, for instance, this may be a form to guide the selection of the relevant rushes and a scenario to guide the montage of those rushes into a new audiovisual production);
– the models of publication which serve to help the editor-author organize and create one or a series of publications/re-publications of an audiovisual corpus;
– and finally, the model or models enabling bona fide patrimonial corpora to be selected and created.
As has already been stated, in this book, we are concerned with one and only one type of models, namely the models of description which constitute the metalinguistic resource essential for analysis and indexation per se but also for annotation and more-or-less free interpretation of audiovisual corpora intended, e.g. for publication in the form of a portal site, a themed folder, a video-lexicon, etc. In [STO 12] we shall give a more in-depth examination on the question of models for creating field corpora and patrimonial corpora; [DEP 11b] contains elements relating to the definition of the models needed to constitute corpora of audiovisual data for publication according to particular genres (or formats).
Let us highlight the fact that the specification, development and monitoring of these different categories of models must rely on a single metalanguage of description. In our case, it is the ASW* metalanguage of description10 (which will also be called the ASW generic ontology). Even if we only use it here to develop the models of description needed by the analyst in order to carry out the description of the content and/or the visual and sound shots of a corpus of audiovisual texts, the purpose of this metalanguage is, ultimately, to be able to serve the definition and development of all the categories of models cited above.
1.4. On the activity of analysis of audiovisual corpora
As we have just seen, the analysis of an audiovisual text or corpus constitutes both a set of concrete activities aimed at filling a gap in knowledge or information, and one of the main stages in the process of compiling and distributing a body of knowledge heritage.
As has already been said, the objectives of analysis may be highly disparate, and obey extremely diverse and particular intentions. When speaking of the analysis of a textual or audiovisual corpus, one often thinks either of academic research activities on or based on a corpus11 or of professional assessments (e.g. in the context of the information monitoring [STO 11d] and critical and comparative analysis of “strategic” knowledge for an activity sector, an enterprise, an institution, etc.).
Yet the analysis of audiovisual corpora is just as important and unavoidable in other key activities of our economic, social and cultural existence. Thus, it is as much an indispensable element of “upstream” (preliminary) pedagogical activity as downstream (“in situ”, “in class”). Upstream, it forms part of the teaching preparation itself; downstream, it is one of the most important activities in the appropriation of knowledge – linguistic or otherwise (on this subject, see the very interesting studies and explanations in [MCK 06; BRA 07; HQS 07; PBR 07] or [KET 02].
Analytical activities also form a central activity in the constitution and monitoring of a digital library (or video-library). They serve the “traditional” objectives of description, classification and indexation of textual (and, more particularly, audiovisual) data making up the collection of a library or video-library. The objectives are manifold, including those forming part of the task of the librarian, the archivist or the documentary-maker. Analysis involves classifying the data (by collection, author, subject, genre, language, year, etc.), identifying and describing “paragraphs” or segments which are of particular interest and rendering them accessible to a given interested audience, producing enriched versions to make them pertinent to more specialized objectives (such as teaching or learning) or even, for certain select parts, to propose linguistic or pragmatic adaptations aimed at an audience who cannot appreciate the value of the original data for lack of adequate linguistic and cultural skills (also see [SAK 11]).
Let us also cite the case of publication and/or republication of a piece of audiovisual data or a whole corpus of audiovisual data. Analysis plays a crucial and unavoidable role “upstream” (in advance) of this activity – no publication wishing to have a certain intellectual value can afford to dispense with a preliminary analysis of the data it offers to a targeted or interested audience. Once again, the analysis may consist of a series of activities of identification, description and classification of data which are relevant for an envisaged publication. However, it may also consist of an in-depth assessment of the data selected for a publication – an assessment which serves the author (be they an individual or a collective) as a basis to support their point of view, their vision of the question which motivates the publication.
Finally, one last example showing the centrality of activities of analysis of textual and, more specifically, audiovisual corpora, is that of the constitution and monitoring of personal archives such as, for instance, the management of the audiovisual data to document the life (either the daily agenda or the narrative course of life) of a person or family in the form of incidental events such as parties, meetings and receptions, journeys, ritual activities, etc. It is well known that since audiovisual recording materials have become commonplace, innumerable photos and videos are constantly being created by an ever-growing number of individuals, families, informal groups of people, etc., to document the timeline of their daily lives. However, this gigantic mass of data produced necessarily has to undergo a certain minimum degree of selection, classification and description in order to “become” a personal/family/friends (etc.) archive in the proper sense of the term. In other words, the personal memory, the familial past documented in the form of the patrimonial corpora which make up the archive of a person, a family, a group of friends, etc., are the products of analysis – without analysis, there would be no archive, and no story either!
Analysis – whatever the context in which it is used and whatever its goals (scientific, pedagogical, professional or “simply” personal) – still necessarily relies on one or more metalinguistic systems, a metalanguage of description* without which it could not be carried out. The concrete use of such a metalanguage is most often found in the guise of (dynamic) forms, i.e. field interfaces categorized by a selection of concepts relevant to the use in question (see, e.g. Figure 4.2 in Chapter 4). In the following chapters, we shall demonstrate how such dynamic forms are alike and how to create them.
To conclude this general presentation devoted to the analysis of audiovisual data, note that it – that is, the task of analyzing an audiovisual text – can be compared to a “basic” piece of field work in human and social sciences (for instance, it can be compared perfectly well to a field investigation in ethnology or archaeology). In order to finish field work (whether it finishes in success or failure is another question), the analyst relies on models (either implicit or more-or-less explicit) to “give meaning” to his field and to a working methodology. Thus, an ethnologist working in a “village community” will use linguistic knowledge in order to be able to collect and classify data in the village parlance; he will use sociological knowledge in order to collect, classify and interpret data relating to the use of natural space in the village and to the construction of a common social space; he will use musicological knowledge to collect, classify and interpret data relevant to the villagers’ musical culture, and so on. These “pearls” of knowledge may be more or less implicit or, on the other hand, explicit; they may be appropriate or inappropriate to a greater or lesser degree in relation to the object; they may evolve over time, in accordance with the ethnologist’s experiences, or those of his colleagues either working with him or working on similar topics. Collection aside, the classification and interpretation of the data of a field necessarily reflects a conceptual schema which guides, orients, and frames the work of the analyst.
The same is true for the description or indexation of a textual corpus or, in our case, a corpus of audiovisual texts. The corpus is the field; the analyst may be a researcher, an educator, someone with a professional or just a personal interest in that field. However, we have invested a very great effort, both intellectual and technical, to make this “field” work as rich as possible, but also as flexible and adaptable to the analyst’s interests and objectives as possible. This book is dedicated to this issue which, as we shall see, is a fairly complex one.
1.5. On the activity of indexation
When we speak of indexation, we almost inevitably have a certain stereotyped vision in mind of that activity as it is practiced in the context of documentation, archiving or library cataloging.
In our approach, cataloging or classifying are only two particular activities in the process of a user’s appropriation of a textual object in general, and an audiovisual one in particular, i.e. in the process of the progressive transformation of that object into a resource* sui generis aimed at an audience, a particular group of users. The entirety of that transformation is supported by a series of typical and recurring activities. Those activities entail certain modifications to the text object:
– sometimes, it is a question of modifying the actual initial organization (formal, physical, etc.) of the text (for instance, this is the case for the activities of segmentation and extraction of segments* (passages) in a filmic object; it is also the case for the activity of montage);
– sometimes, it is a question of adapting the “intellectual” content to the limitations of a specific social context (this is especially so for the description of the object in its entirety or of a part of it, for its enrichment by comments, aids, references, etc.).
Generally, these modifications result in a repositioning of the original textual object within the intertextual field peculiar to the “textscape”) of a given social actor. Thus, they may relate to the organization, the textual structure of the original textual object such as, e.g. its syntagmatic and linear organization. They may also relate to the meta-textual relations between the original textual object and the perspective, the point of view about that source text expressed either by its author or by a third party in the form of comments, evaluations, comparisons, (re)-interpretations and (re)-classifications or, indeed, in the form of advice and (usage) guides. More specifically they may relate to a (re)-definition of the hypertextual relations that the source textual object maintains with other objects forming part of the textscape of a social actor in the form of citations, references, “links”, etc. They may also relate to the paratext of the source textual object: more specifically they may relate to the textual object’s “signaletic identity” – its peritext, to use Genette’s term [GEN 87] – which may be modified, for instance, with new titles, new prologs or epilogs. Finally, they may relate to the source text’s epitextual “impact” on its textual environment in the form, e.g. of targeted distribution (here, we are thinking of the new social networking media, of buzz and other opportunities to circulate and make a textual object known).
In any case, for all these activities of appropriation, and thus of modification of the organization of the textual object and its position within an intertextual field, indexation, in a manner of speaking, constitutes the material part of the task: on one occasion, it will manifest itself in the form of free production of keywords; on another, in the form of production of explanatory texts; on a different occasion, in the form of adding links, pointing to other online resources; on yet a another occasion it may entail visual or acoustic annotation of the text, and so on.
Thus, while we recognize the existence of an “orthodox” practice of indexation, we consider it here, in the broadest sense of the term, as the material part of the task of transforming a textual object into a resource, a bona fide asset for a group of users.
1.6. Some reflections on the subject of the theoretical reference framework
In our approach, the definition and elaboration of models of description for audiovisual corpora reflect the semiotic theory of the (audiovisual – see [STO 03]) text*. The main semiotic and cognitive facets of the audiovisual text (or, simply, of the text) which we are more particularly interested in here can be illustrated in an intuitive and simple manner with the following seven typical questions:
1 In a corpus/collection of audiovisual texts, which text*, or indeed which specific segment* – (part) of the text – arouses particular interest and attention (for the analyst or for a given audience)?
2 What is being spoken about, what is being demonstrated in the audiovisual text or in one of its identified segments (that is, what are the domains of knowledge thematized, what are the subjects being dealt with)?
3 From which point of view, and according to which authorial framework are these domains and subjects approached (that is, how are the subjects handled by their “author”, and how is discourse constructed around them)?
4 How does the author express a subject thematized and interpreted discursively in an audiovisual text or in a specific part thereof? How is that subject represented visually and acoustically (or indeed, what is the audiovisual mise en scène (staging) of a subject)?
5 How does a subject selected, interpreted and staged by its “author” develop into a coherent whole (both in terms of its textual linearity and of its syntagmatic (and narrative) integration to form a potential resource (of knowledge, information, etc.) for a given public and use context?
6 To which tradition does this textual “task” belong – this task consisting of the selection, discursive treatment, expression/audiovisual mise en scène of the subject and its linear and syntactic integration into a coherent and finalized whole? (In other words, what is the genre* which the text or that segment of it which arouses particular attention and interest (for a certain use context) refers to or is part of?)
7 Given, on the one hand, the cultural reference framework of a specific audience and their expectations/needs, and on the other, the specific profile (the authorial identity) of the text, what operations need to be carried out in order the bring the text and its audience together (i.e. what are the activities identified to transform the text from being a potential (intellectual) resource to being a real (intellectual resource?
These seven questions serve, above all, to “fix” and guide ideas and habits before the constitution (collection, production) of an audiovisual corpus as afterwards (that is, during the phases of analysis per se of a corpus or isolated text to turn it into a genuine cognitive resource: segmentation, description, classification, indexation, annotation or adaptation).
At the same time, these seven questions reflect the scaffolding of the semiotics of the audiovisual text which is built around three main approaches (see Figure 1.1), that complement one another: the approach which sees the textual object as a compositional entity, that which sees it as an internally stratified entity and that which considers the text in relation to a social practice. These three approaches indeed characterize any concrete analysis of an audiovisual text or corpus of texts.
Figure 1.1. Three approaches to the (audiovisual) text object
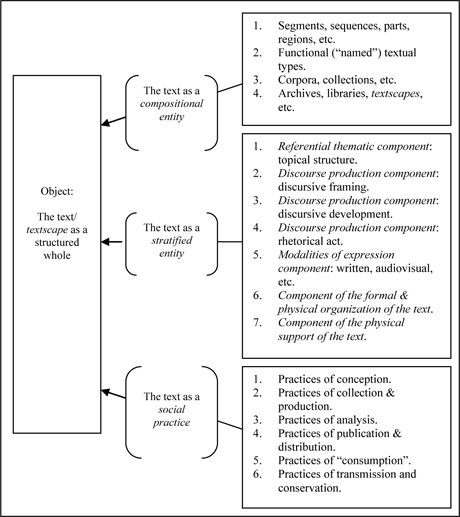
According to the approach which views the (audiovisual) text as a compositional entity (Figure 1.1), the text is an object which, in principle, is made up of “smaller” (more local) parts, whose purpose is to contribute to the progressive realization of an intention, an objective of communication. At the same time, any textual object may itself form part of a larger entity for which it is supposed to fulfill more or less precise functions (informative, communicative, etc.). Thus, for instance, an audiovisual text may be part of an audiovisual archive where it documents a set of subjects* which stem from the universe of discourse* of the archive in question.
In the context of our research on audiovisual archives, the approach considering the text as a compositional entity reflects the fact that an audiovisual text considered as a coherent whole may be broken down into units (sequences, segments, parts, etc.) which in turn “behave” like “complete” audiovisual texts, thus forming coherent wholes themselves. It also reflects the fact that an audiovisual text is not necessarily physically delimited by the beginning and end of a “video” – a text in the sense of an “information-carrying sign” [STO 99] may perfectly well take the form of “snippets” of videos, which are physically separate but which form a whole, semantically speaking. An audiovisual text on a digital support must therefore be apprehended rather as a functional and hierarchically-integrated network of textual parts which may in turn present themselves in the form of documents which in turn are made up of different parts or sequences.
For instance, an audiovisual text in the sense of a knowledge resource for a given audience may be an entire film, i.e. the recording of a class, or of an interview. It may also be a particular segment of that film (i.e. a moment during a seminar or class devoted to a particular theme, a subject). It may, finally, be a collection of segments belonging to different “films” (of classes, seminars, etc.) but which, together, form a new coherent whole from a thematic point of view or from the perspective of a specific use (e.g. a set of segments dedicated to a particular language “taken” from different films or recordings making up a new, re-linearized film or a hypermedia dossier of film segments destined (e.g.) for pedagogical use.
Let us take from this that, as a structural whole, the (audiovisual) text should not be reduced to a privileged material form – e.g. a book, a journal, a video, a photo, etc. As a structural whole, an (audiovisual) text may be made up of a whole variety and an infinite number of “privileged material forms” such as books, photos or films. In other words, a text in the sense of a structural whole may present itself in the form of a corpus, a collection, an archive, a library, etc.
Finally, the text may also be understood in the sense of a textscape. Similar to landscape, a textscape means an “environment” (spatial, temporal, epistemological and cultural) of information signs in which a social actor (an individual, a group, an institution) is “swimming”, and which serve that actor as a source and as cognitive resources for their various activities. We could, in fact, advance the viewpoint that every social actor is characterized, among other factors, by different types or genres of “landscapes”, of which the textscape is a part. Think of the urban space which serves as a scene to the daily agitations of thousands of people. This space is, so to speak, “decked out” with an enormous number of concrete texts in the form of posters, signs, adverts, instructions, information boards, photos, spots, sound supports and finally, mobile devices enabling us to complete this information landscape with information from elsewhere in space or time. Each textual representative part of such a textscape can be treated independently, as indeed is done in most studies dedicated to a textual genre. However, we can also question the overall organization of a textscape, its internal consistency, its meaning for a given audience or indeed its production (its generation), handling and evolution. We can clearly see that the approach for dealing with the “textual” object remains the same, no matter what its size or material complexity.
The second approach looks at the text as a stratified entity (as a “puff pastry”, to use the image which A.J. Greimas holds so dear). According to this approach, the text is made up of a set of specific levels which serve to process the information (lato sensu) communicated by the text: choice of an object, handling of a chosen object by the speaker, written, oral or indeed audiovisual expression of the vision offered by the author of the object in question, etc.
In other words, this second approach gives preferential treatment to the comprehension and analysis of the textual object’s internal organization, i.e. (in the tradition of structural linguistics going back to F. de Saussure) on the content of a text and its verbal (or in our case, audiovisual) expression. Thus, an (audiovisual) text can be described according to a set of different strata including, in particular (also see [STO 99]):
– the topical level: a level which serves for describing the selection and thematization of an object dealt with in a text or corpus of texts;
– the enunciative and discursive level: a level which serves for describing the way in which the speaker (the “author”) of the text “paints” and “frames” the object being discussed, and how it is handled in relation to its audience, the objectives being pursued, etc.;
– the narrative level: a plane which serves for describing the way in which the object selected and which forms the theme of the speaker’s (author’s) discourse, is introduced and developed “throughout the text”, in which order, according to what syntagmatic logic;
– the level of the verbal and audiovisual expression: a level which serves for describing the means of expression chosen to communicate the object being thematized and expressed in discourse;
– the level of the scenographic organization of the theme of the discourse: a level which serves for describing the inscription in space (e.g. on a two-dimensional surface) and time (e.g. over a given duration or at a precise moment) of the object being thematized, turned into discourse and expressed using one or several media;
– the materialization level: a level which serves for producing a material instance of the text – in the form, e.g. of a handwritten or printed text, a digital text, etc.
It is to this second approach that we shall give preference to in this book. From the third chapter onwards, we shall see how we tried to integrate the distinction between the different textual levels into the metalanguage of description* of the universe of discourse* of an audiovisual archive. As we shall see, such a metalanguage of description is made manifest in the form of a library of models of description* which forms fairly complex configurations from which stem the different elements of a set of metalinguistic resources* which we shall present in greater detail in Part Four of this book.
Finally, the third approach views the text as a social practice or as an entity around which a social practice is organized. According to that approach, greater consideration is given to the activities around the text (as a compositional and stratified entity) throughout its entire “lifetime”, i.e. from its conception and birth through to its eventual disappearance or transformation into another textual entity. In other words, all texts necessarily form part of a network of practices and activities. These practices and activities contribute to the format and profile of the text, and are themselves tributaries of its identity, its specific profile. Thus, an audiovisual text made up of a montage of a series of extracts from interviews with researches about a specific problem necessarily possesses its own particular identity, its own profile, which (a priori) renders it more or less apt for, or else resistant to, adaptation and exploitation in specific use contexts.
In the context of the Audiovisual Research Archives Program12 which we set up in 2001, we were interested in the text as a social practice. Given that the ARA program was an R&D program dedicated to the constitution, diffusion, conservation and exploitation of scientific and cultural heritage using digital audiovisual technology, one of its main goals was to define and “implement” the main stages and activities making up the workflow of production and diffusion of audiovisual heritage. This framework is described in greater detail in [STO 11a].
The crucial point we wish to underline here is the fact that, from one stage to another, not only the role but also the identity of the text changes, in accordance with the tasks and activities in question. However, this has direct consequences, e.g. on the way in which we consider what a corpus of texts (in our case, audiovisual texts) is, and how we treat it [STO 11a].
Thus, let us draw the distinction, as discussed above (see section 1.3), between functionally different specialized types of textual corpora: corpora which document a “field” (of research, for example), corpora which serve to document a body of heritage (for instance, with a view to being distributed on the Web in the form of an audiovisual archive) and which can vary greatly in relation to field corpora (in terms of their internal composition as well as the “nature” of the text which may make them up), functionally specific corpora serving a particular publication, or even specific corpora of texts chosen to be conserved over a long period of time. The profile of the text, its identity so to speak, varies depending on whether it belongs to one functionally specialized corpus or another. Thus, in a manner of speaking, it is futile to speak of the text “out of context” (and to handle it in that way).
1 As part of the research program ARA (Audiovisual Research Archives; http://www.archivesaudiovisuelles.fr/FR/) which we set up in 2001/2002 at the Fondation Maison des Sciences de l’Homme (FMSH) in Paris, we quite deliberately use the term “field (work)” in a very broad sense. Thus, this umbrella term covers the collection of data documenting – on the one hand – an “event” or a punctual and delimited “manifestation” (a punctual, delimited manifestation such as a seminar, a class, a conference, a work meeting, etc. punctuating day-to-day life in the worlds of research and higher education) and – on the other – field research, in the traditional sense of the term in human and social sciences (HSS) (such as, for instance, an ethnological mission aimed at collecting – usually in several stages, and with very variable durations – all sorts of data relating to the social organization of a community, of its social and cultural life).
2 Thus, for instance, as part of the ARA program, we put in place a whole procedure for collecting information, knowledge and other useful data to bring a project on interviews with a researcher to fruition – a project which may take the form of a single interview or a series of interviews, of interviews in situ (that is, in the researcher’s workplace), interviews constituted of different participants engaging in discussion with the guest researcher, etc. This procedure is based on a simple model defining the criteria to be taken into consideration when preparing an interview with a researcher – criteria such as being familiar with the researcher and his/her personal career, with his/her main fields of research, with the academic and scientific context, etc. However, this model also requires the person in charge of preparing the interview to collect data to facilitate the conducting of the interview itself, on the one hand, and the exploitation of the data documenting the interview in terms of its technical and auctorial processing, its analysis and its publication, on the other. Thus, the person in charge of the interview must identify the main subjects which will be developed, checking this with the researcher beforehand, while respecting the scenario-type of an interview in the context of the ARA program. For further information, see the documentation online on the website of the ARA program: http://www.archivesaudiovisuelles.fr/FR/about4.asp or the ASW-HSS research log (Carnet de recherche ASA-SHS) on the French-language portal hypotheses.org (http://asashs.hypotheses.org/category/programme-aar).
3 In the context of the ARA Program, we did indeed put in place a whole series of simple procedures for constituting such field corpora when recording what we call scientific events (interviews with a researcher, conferences or research seminars). Thus, a certain number of seminars, conferences and interviews filmed between 2002 and 2008 are documented in the form of a field corpus, only certain parts of which were published on the portal site of the ARA Program: http://www.archivesaudiovisuelles.fr/FR/.
4 For instance, as part of the ARA Program, in 2007, we developed a themed portal devoted solely to Latin America (http://www.amsud.fr/ES/). However, the corpus analyzed and published on this portal is made up of data from a whole variety of fields. In addition, these fields were partly created within the ARA program (and in accordance with the procedures defining the preparation and realization of a field as part of that program) but partly outside it as well – by individual actors (researchers, documentary-makers, etc.) or collectives (research institutions, etc.). This example is a good illustration of the lack of functional dependence between the field corpus* and the analysis corpus*.
5 For further explanations, see the research log of the ASW-HSS project on the Hypothèses.org portal: http://asashs.hypotheses.org/category/programme-aar.
6 Also as part of the ARA Program and thanks to various R&D projects both French and European (particularly the French project SAPHIR, financed by the Agence Nationale de la Recherche, and the European project LOGOS, financed as part of the 6th Framework Program – FP6), we were able to develop and test models for republication of research interviews which were initially published on the ARA site in the form of an interactive videobook. Thus, for instance, an interview with the ethno-musicologist Sabine Trebinjac, conducted by Aygun Eyyubova for the ARA in June 2007 at the FMSH in Paris, was re-published (following the appropriate adaptations and enrichments) in the form of bilingual folders (French/English; French/Chinese; French/Turkish, etc.), a Masters-level pedagogical folder, a themed folder dedicated to Uyghur music or even, along with other publications, in the form of a videolexicon dedicated to world music (see http://www.archivesaudiovisuelles.fr/1051/introduction.asp).
7 In particular, here, also see the experiments carried out by Jirasri Deslis [DES 11a; DES 11b; DES 11c] on her site on the ArkWork portal dedicated to the distribution of an audiovisual body of heritage in archaeology (http://semiolive.ext.msh-paris.fr/ada/). Jirasri Deslis demonstrates, in an exemplary manner, how to make use of new social media and the Web 2 for better diffusion of scientific knowledge, and how to contribute to a better scientific “acculturation” of the virtual communities making up this “new cultural diversity” (to use UNESCO’s expression) resulting from the digital revolution (also see [DES 11a; DES 11b; DES 11c]).
8 On this point, see a highly innovative experiment described by Francis Lemaitre and Valérie Legrand-Galarza, based on a new piece of technology (the V.D.I. – Versatile Digital Item; http://www.ict-convergence.eu/) enabling all use of a video to be tracked so that the proprietors of the content of a video used and reused can monitor the use to which it is put on the web [LEG 11b]. Here the experiment is based on the concrete case of the PCIA archives (Patrimoine Culturel Immatériel Andin; http://semiolive.ext.msh-paris.fr/pcia/; English equivalent AICH – Andean Intangible Cultural Heritage) created by Valérie Legrand-Galarza in collaboration with the Quechua communities concerned. One of the main goals of these archives is to enable all educators, all researchers, to exploit and use the videos making up the AICH collection while respecting the moral and actual legal rights of the communities involved – particularly the right to revoke content diffuse and/or reinterpretation and republication (see [LEG 11b]).
9 As (at least indirect) proof for this statement, we can cite the proliferation of video libraries and other “channels” online documenting the activities (research, teaching, etc.) of such-andsuch a university, such-and-such a research establishment. However, a strong impression of a certain degree of “naivety” persists when looking at many of these initiatives. This impression of naivety refers back to the fact that the designers of these institutional channels or video libraries seem to consider that the audiovisual collection being diffused in itself constitutes a patrimonial corpus (or another type of corpus: field, analyzed, published/republished, etc.). More generally, it is very rare to find initiatives which clearly distinguish between the collection of audiovisual data held in an institutional video library or channel, and the corpus of audiovisual resources – a corpus being a selection of audiovisual data drawn from a collection, which fulfill a function, and which obey an objective (to document a field work, interpret a subject, publish an event, promote an institution’s reputation, etc.).
10 The acronym “ASW” signifies “Audiovisual Semiotic Workshop” (a rendering of the French ASA, Atelier de Sémiotique Audiovisuelle) and relates partly to our main theoretical reference, which is the semiotics of the text (see [GRE 76; GRE 79; STO 83; STO 03]) and partly to the ASW-HSS Project (French acronym: ASA-SHS), financed by the ANR between the start of 2009 and the end of 2011, which enabled us to develop the aforementioned metalanguage of description and to test it in “real world” circumstances.
11 In linguistics, there is a whole specialized branch devoted to this goal; in rhetoric and discourse analysis, one relies on textual corpora in order to comprehend the syntagmatic development of particular genres of discourse (see e.g. [BIB 07; MCK 06]).
12 See the official portal of the ARA Program: http://www.archivesaudiovisuelles.fr.