
Chapter 2
The Audiovisual Semiotic Workshop (ASW) Studio – A Brief Presentation
2.1. A working environment for analyzing corpora of audiovisual texts
Before discussing the issues relating to the conception and development of models for describing audiovisual corpora using a metalanguage of description, we shall give a brief overview of the working environment of an analyst of audiovisual corpora – an environment called the ASW Studio1 (for a detailed presentation of the ASW Studio, see [STO 11a]).
The ASW Studio relies, on the one hand, on an overall vision of the activities which make up the process of appropriation of an audiovisual text by the analyst for a specifically-targeted user and, on the other hand, on the semiotic approach to the (in our case, audiovisual) text, which we described briefly in the first chapter of this book (also see [STO 03]).
The representation and simulation of the activities of appropriation, i.e. qualitative transformation of an audiovisual text into a resource, an asset for a specific audience, takes the shape of one or more scenarios of activities guided by models of description (see also [STO 11a]). The basic scenario of activities being that which defines the main stages of a project of production, analysis and diffusion of a body of knowledge heritage [STO 11e], the scenario defining a project to qualitatively transform an audiovisual text into a resource per se (an intellectual asset) for a given audience is that which defines the main activities which are part of the analysis stage of the audiovisual text or corpus of texts (we shall come back to this later on in this book; see Chapter 5). The model of description in turn takes account of the specificity both of the part of the audiovisual text which has to be dealt with by the analyst, and of the type of results the analyst has to provide.
By way of a simple example, the identification of an audiovisual segment (that is, a chosen moment in a video which the analyst deems pertinent for his purpose) is a specific task which covers a set of intellectual decisions and technical gestures such as isolating the audiovisual segment (i.e. virtually “cutting” it) within the audiovisual flow, attributing a title to the segment, producing a textual notice summarizing the content and/or indicating the reason why that segment was singled out by the analyst, and so on (see also [DEP 11c]).
“Isolating an audiovisual segment”, “attributing a title to it”, “producing an explanatory notice”, etc. are concrete activities which are carried out in a certain order (not necessarily linear nor entirely predetermined) and which take on meaning firstly in reference to the objective they are intended to satisfy (i.e. identify the segment(s) which are most important in the eyes of the analyst) and secondly in reference to the models of description which guide the work of segmentation and which, in a manner of speaking, “force” the various activities to provide answers for “problematic places” such as the “beginning of the segment”, the “end of the segment”, the “title”, “subtitle”, etc.
A particular analysis (essentially made up of a series of intellectual decisions and technical gestures guided by models) of an audiovisual text is based on a certain number of (dynamic) forms which are material representations of the underlying models of description and constitute the analyst’s working interface. As Figure 2.1 shows, a form is a sort of interactive text which guides the analyst in entering the information the computer system needs in order to carry out the qualitative transformation the analyst desires so as to produce a knowledge resource either for himself or for a target audience, based on an existing audiovisual text.
Figure 2.1 shows part of the form which invites the analyst wishing to describe the subject Civilizations in Asia in a video to carry out a specific set of activities. We shall discuss these activities in detail throughout this book.
Figure 2.1. Example of an interactive form for inputting information relating to an audiovisual segment which the analyst has identified as pertinent

However, the overall meaning of these analytical activities seems intuitively obvious. In reference to Figure 2.1, it is a question, primarily, of:
– denoting the civilization in question by name;
– possibly producing a textual presentation;
– if applicable, giving expressions in the original language;
– developing the cultural characteristics dealt with in the audiovisual segment being analyzed;
– using a micro-thesaurus to identify the type or types of cultural constructs in question;
– as well as, which is not shown in Figure 2.1, locating the civilization or civilizational phenomenon in question, in space and time; and
– finally, possibly producing an analysis of the specificity of the discourse given over to the civilizational phenomenon (e.g. in the context of an audiovisual recording of a conference, seminar, interview, etc.).
The organization and function of a form as shown in Figure 2.1 will be explained later on (see Chapter 5). Let us highlight here that the ASW Studio is presented as an interface composed of a series of forms which the analyst can use to carry out a fairly simple and rapid, or alternatively, a detailed and systematic, task of appropriating an audiovisual text.
A form is an interactive meta-text which serves the analyst to produce a description of a text-object – a video or a part thereof.
It should be highlighted that the interactive form necessarily refers to a model of description* of which it is a “material” representation, so to speak. The model of description in turn forms part of the metalanguage of description peculiar to a domain of knowledge or expertise such as that of the CCA audiovisual portal (Culture Crossroads Archives (in French, Archives Rencontre des Cultures, ARC))2 devoted to cultural diversity and intercultural dialog.
Figure 2.2 offers an overall view of the working interface in the ASW Description Workshop. The Description Workshop is one of the four components making up the ASW Studio, the other three being the textual Segmentation Workshop, the Publishing Workshop for audiovisual text corpora previously described and indexed, and the Modeling Workshop reserved for those in charge of preparing the metalinguistic resources (the models of description for the analysis) necessary for the work of the analyst and the writer/editor of a publication. We shall present this briefly in Chapter 11 (section 11.8).
The component of the ASW Studio called the Publishing Workshop – per se – is based on a piece of software (over a Web application) called Semiosphere, which allows a person or group (a community) of people to create and manage their own audiovisual archives (also called “channels” in the sense of YouTube or Daily Motion) and publish their own collections there in the form, for example, of themed video libraries, thematically organized lexicons and glossaries, specialized folders, bi- or multi-lingual folders, etc.
Figure 2.2. General view of the working interface of the ASW Description Workshop
The component of the ASW Studio called the Segmentation Workshop allows the analyst to view the videos making up his corpus, one by one, and identify the segment or segments (“passages”) thereof which are of interest to him and which he wishes to describe and analyze further (of course, the analyst may also content himself with analyzing a video “in its entirety”, without cutting it up into pertinent segments, etc.). The structure and possible uses of the Segmentation Workshop are described in greater detail in [DEP 11c].
2.2. Brief presentation of the ASW Description Workshop
Now let us take a very brief look at the component of the ASW Studio called the Description Workshop – a detailed presentation is provided in [STO 11a].
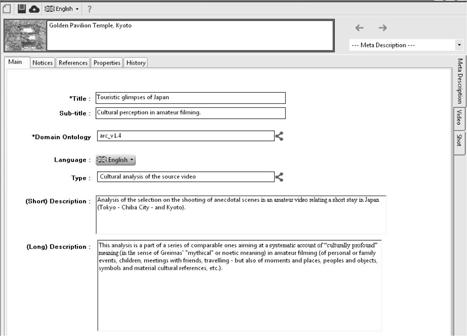
As Figure 2.2 shows, this workshop contains three options for analysis or description and, for each option, various sections which identify the facets according to which the analyst can approach each of the three levels of analysis.
Figure 2.3. The working interface for creating a meta-description
In particular, Figure 2.2 presents the working interface along with its different sections allowing a meta-description to be carried out. The sections making up this option enable the analyst to further detail the object and objectives of his analysis. Thus, it is not a question of an analysis per se of the audiovisual text, but rather of an explanation of the context of that analysis – hence the rather judicious term metadescription.
As the different sections of this option show (Figure 2.2), the analyst mentions, for example, the title of his project; he can provide a summary of it, specify the copyright and usage rights governing the results of his analysis, produce references, etc. (For a fuller understanding of this interface, see [CHE 11a]).
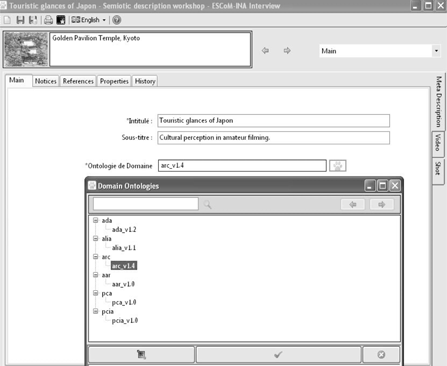
A particularly important factor here is the choice of the domain of expertise the analyst is referring to in his work – his choice of metalinguistic resources, and more particularly the library* of models of description of an audiovisual text or corpus defining an archive’s universe of discourse. The domains of expertise of different archives may, however, overlap. Thus, even if each archive has “its own” library of models of description, a model taken in isolation may appear – just as it is, or with a few local adaptations – in different libraries of models of description.
Figure 2.3 shows the eight domains of expertise which are currently available for the analyst to choose from – assuming he has the appropriate rights to do so:
– ada is the (French) abbreviation for the domain of expertise Arkeonauts’ Workshop devoted to research in archaeology (this is version 1.2 of the metalinguistic resources devoted to the analysis of audiovisual corpora documenting the ArkWork domain);
– alia is the acronym for the domain of expertise Literature from Here and Elsewhere, dedicated to literary heritage;
– arc is the acronym for the domain of expertise Culture Crossroads Archives, given over to cultural diversity and intercultural dialog;
– aar is the acronym for the domain of expertise covered by the audiovisual collection of the video-library owned by the FMSH in Paris;
– pca is the acronym for the domain of expertise of the video-library Azerbaijani Cultural Heritage;
– pcia is the acronym for the domain of expertise of the video-library Andean Intangible Cultural Heritage.
These different domains of expertise correspond to the experimentation workshops of the ASW-HSS Project. This is a completely open-ended list – there is nothing to stop new domains of expertise from being added, although the appropriate metalinguistic resources and models of description must be defined and conceived for these new additions. These resources and models are made up partly of pre-existing resources and models (i.e. which are already defined and used in one of the six experimentation workshops cited above) and partly of new resources and models.
Figure 2.4 offers a view of the working interface of the second and third options in the ASW Description Workshop. The second option is entitled Video. It invites the analyst to describe the audiovisual text in its entirety – in contrast to the third option, reserved for the analysis of one or more specific segments making up an audiovisual text.
This third option effectively allows the analyst to describe an audiovisual text shot by shot, subject by subject, in as much detail as he wishes, from different points of view, etc. It also enables the analyst only to take account of certain segments, or even just one.
However, both analytical options are approached in the same way – a passage, a segment of an audiovisual text being a structural entity in itself, a text* in the same way as the audiovisual text taken “in its entirety”.
Figure 2.4. The working interface for carrying out a description of the audiovisual text “in its entirety” and/or of a specific audiovisual segment
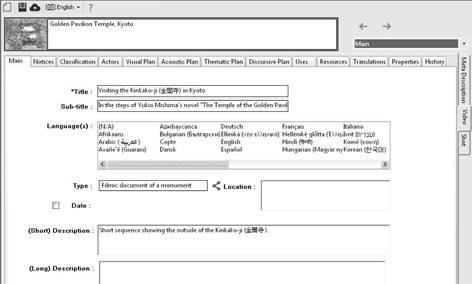
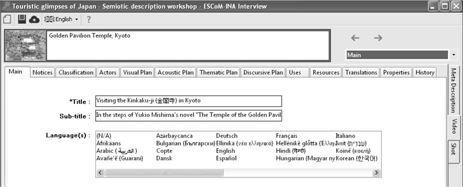
Figure 2.5 shows the main sections offered to the analyst to carry out an analysis of an audiovisual text in its entirety or of a particular passage (“segment”). They are grouped together to form the four main types of analysis distinguished below:
1) The Main, Notices, Classification and Actors sections make up what we call the paratextual analysis* of an audiovisual text in its entirety or of one of its segments. Paratextual analysis relates to the description and explicitation of the identity of an audiovisual text and/or of its different segments. It also includes the description of aspects relating to intellectual property rights and usage rights of an audiovisual text (or one of its segments), etc.
Figure 2.5. The main sections for carrying out an analysis of an audiovisual text and/or specific segments which make it up
2) The Visual Plan and Acoustic Plan sections form what we call the audiovisual analysis* of a video or a segment thereof. This involves analyzing the image staging or sound staging techniques used to represent an object or situation in a video, shot by shot. This type of analysis is particularly interesting in the context of building a library of segments classified by types of shots, framing techniques, visual and/or sound shifts, etc.
3) The Thematic Plan and Discursive Plan sections form what we call the content analysis* of an audiovisual text – analysis of the subjects dealt with, and how they are dealt with, in an audiovisual text or corpus. This form of analysis constitutes the main topic of this book.
4) Finally, the Uses, Resources and Translations sections form what we call the pragmatic analysis* of an audiovisual text or segment thereof. In particular, this includes:
– explicitizing the contexts for which an audiovisual text (or one or other of its segments) seems to be appropriate;
– readying the video for a particular use (in the form of comments, references, etc.);
– adapting the video, linguistically speaking, to the language skills of a particular target audience (this adaptation can be carried out either as a translation in the conventional sense, or in the sense of a change in the register of language/terminology, etc.; see [STO 07; STO 10a; SAC 11]).
In addition, at the beginning of his concrete work on an audiovisual text or corpus, the analyst has to take an important decision, which is to specify the genre of analysis he intends to carry out. Figure 2.6 shows the different types from which the analyst can choose. This list includes the four main types of analysis we have just identified:
– paratextual (or “basic”) analysis;
– thematic analysis (of the content);
– audiovisual analysis;
– pragmatic analysis.
Figure 2.6. The interface enabling the analyst to select the type of analysis which best characterizes his work
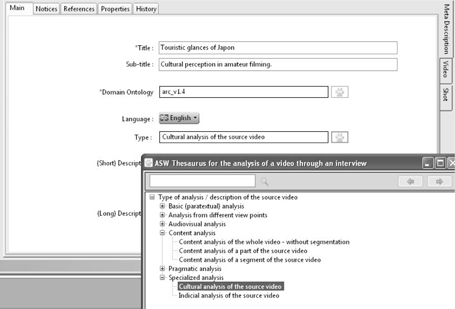
However, there are several additional forms of analysis which attempt to give a fuller account of the different interests and objectives of the stakeholders in the analysis of an archive. Thus, for example, we have identified:
– the type of analysis relying on different angles (i.e. combining audiovisual, thematic, pragmatic, etc. interests in a single analysis);
– the type of specialized analysis such as cultural analysis (i.e. analysis of the cultural preconceptions which are behind a particular shot or a particular part of a source video) or indeed indicial analysis, in the sense of the Italian historian Carlo Ginzburg (i.e. a particular visual object as an indicator for a particular figurative meaning [GIN 86]).
This list is open-ended – it may be enriched by new types of analysis, with each type of analysis referring to one or more sections, one or more interactive forms in the ASW Description Workshop.
It should be stressed, however, that even though it was our intention from the very start to include this function, the current version of the ASW Description Workshop does not allow dynamic selection of the sections and interactive forms corresponding to a specific type of analysis.3 We hope to have the opportunity of rectifying this weakness in the future.
2.3. Four approaches to analyzing an audiovisual text
These four types of analysis constitute as many approaches to explicitizing, annotating and finally qualitatively transforming any audiovisual object into an (intellectual, for example) resource in the context of a (online) library or archive for a certain audience and for a use context.
Figure 2.7. Analysis of the audiovisual text – an overall view
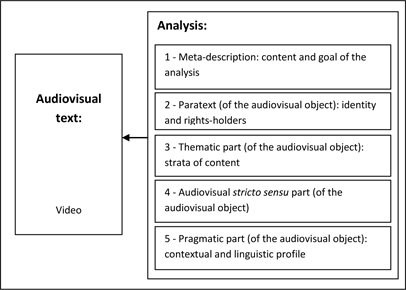
Figure 2.7 shows the general vision underlying the sections and forms in which the ASW Description Workshop is organized. According to this vision, the analysis may relate either to the whole of an audiovisual corpus, to a single video or even to a single part thereof in which the analyst has a particular interest.
A simple paratextual description* may be the only analysis required. Technically speaking, this corresponds, grosso modo, to producing the basic information required by standards as widespread and unavoidable as Dublin Core4 with its 15 elements of description, the Open Archive Initiative (OAI)5 or the semantic schema of the Europeana library6.
Yet the analysis may also go a great deal further than a “simple” paratextual identification. In this case, it may set out for example to describe the content* of a corpus or a video. As we know, this covers a whole range of approaches, interests and issues which the ASW Studio must allow for. A particular, but very important, set of such approaches, interests and issues corresponds to the analysis of the content of an audiovisual object using a documentary language such as Web Dewey7 or RAMEAU8 employed at the Bibliothèque nationale de France (BnF, French National Library), using a thesaurus9, and controlled glossaries and vocabularies10 or indeed using an ontology11 in order to be able to participate in the evolution of the semantic Web toward a global library of knowledge resources.
Yet this is not a very particular view of the description of the content, firmly anchored in a certain tradition of indexation as is practiced in documentation (scientific, technical and professional), and library sciences or archiving.
It should not be forgotten that content description also refers to analysis in the sense of a genuine professional assessment of a piece of content, or in the sense of an interpretation and critical evaluation of a given piece of content. We, for instance, in the context of our teaching and research activities on audiovisual semiotics, are particularly interested in the (hermeneutic) interpretation of cultural representations, connotations or “preconceptions”, which lend an “added meaning” to the anecdotal plane of the usually completely conventional images of the social and natural world. These images make up the filmic material of amateur videos produced by ordinary people to document their experiences, memories and emotions [STO 10b].
[LEG 11a] offers a discussion of another issue for the systematic analysis of the content of an open-ended audiovisual corpus, relating to its use in the context of a program to evaluate, distribute and preserve a body of cultural heritage. The example expounded in [LEG 11a] is of the assessment of community achievements and practices (here, those of Quechua-speaking communities in Peru and Bolivia) in accordance with an approach put forward by UNESCO12 for its program to preserve intangible cultural heritage. Two other very interesting examples are offered in [DEP 11d; CHE 11b] which show thematic assessment in the context of the pedagogical republication of a selection of audiovisual shots about a chosen subject, including a set of basic references in accordance with the LOM13 standard.
However, this type of analysis (i.e. analysis of the audiovisual content) is not really the center of interest, for instance, of large banks of visual or sound data. These databases are more interested in classifying their collections and making them accessible, based on “formal” criteria such as types of visual/sound objects, framing, shots and visual panning to represent a filmed situation/object, the duration of a visual or sound shot, etc. Such a classification can only be carried out by way of an audiovisual description* (to the detriment of a description of the content).
However, none of the approaches mentioned here genuinely takes account of the circulation of content and resources on the Web, the fact that the Internet is an intrinsically multilingual digital space, covering the most diverse contexts and uses and constituting the basis for the expression and exchange but also the confrontation of a multitude of identities and cultural references. However, every audiovisual object possesses its own identity, its own specificity. It is the goal of the pragmatic description* of the audiovisual object to explicitize, or adapt (i.e. modify to a greater or lesser degree) that specificity in terms of potential interest for a particular audience, a particular use in order to support and accompany its mediatization (and/or re-mediatization) on the various digital networks.
In the following parts of this book, we shall take a look at how we have attempted to take account of this incredible multitude of requirements, interests, expectations, stakes, needs, objectives, etc. of an analysis, while dealing with them in reference to a common theoretical and methodological framework.
2.4. Models of description and interactive working forms
As we have just seen, the working interface of the Description Workshop is made up of sections, and each section in turn is made up of an interactive form or a library of forms. Let us now take a more detailed look at the interactive form itself.
Every interactive form making up the working interface of the ASW Description Workshop, as has already been discussed, represents a model of description. A model of description* forms part of a library of models of description*. Each domain of knowledge or expertise has its own library of models of description. Certain models are transversal to the different domains, others are specific to a given domain, and still more can be found in several (but not all) domains.
A model of description is, in turn, completely defined by the ASW metalinguistic resources. As we shall see again in Part 4 of this book, the ASW metalinguistic resources consist of:
1. Aconceptual meta-lexicon (or vocabulary)* representing the two central dimensions which make up all domains of knowledge/expertise: a) the objects of analysis* and b) the activities* or actions of analysis, i.e. the activities by way of which we identify, locate, name, designate, interpret, comment upon (etc.) a particular object, or type of object. Of course, the affirmation that the objects of analysis and the activities of analysis are two central dimensions in the definition and development of models of description, does not mean that they are the only dimensions to be taken into consideration. Other, equally important, dimensions are the agents of the analysis (the people, groups or other actors carrying out an analysis), the context of the analysis (e.g. the temporal context) or the modalities determining an analysis (such as the intentions, instructions and other obligations which determine an analysis, the level of knowledge and “know-how”, etc.). In our work, we chose primarily to systematize, as far as possible, the approach to the first two dimensions (the objects and procedures of the analysis) while keeping in mind the importance of the other dimensions cited above, both for an appropriate vision of any analytical activity and for the enrichment of the ASW Studio, to become a veritable “workshop of knowledge engineering and management”.
2. A faceted thesaurus* which, for certain conceptual terms (or concepts) of the meta-lexicon, pre-determines lists of values in the form of descriptors which can be used by the analysts of audiovisual corpora. The use of a thesaurus is particularly helpful in order to obtain a certain degree of homogeneity in the results of the analysis, either for data which are already standardized or highly structured a priori (as is the case for example with the indexation of countries, districts, regions or administrative provinces of a country, chronological periods, languages, etc.), or for data for which we wish to obtain “controlled” results, i.e. analytical results obtained because of a choice of terms or “descriptors” imposed on the analyst.
3. Libraries of blocks* of pre-existing models (called sequences* or schemas*) which can be re-used just as they are or following certain modifications for a specific analysis project. Thus, there are sequences of geographical and temporal location of the object of an analysis, sequences of discourse analysis, sequences of analysis of the visual/sound shot, schemas defining the object of analysis*, schemas defining the procedures of free* or controlled description* of an object of analysis, etc. All these blocks can be re-used as they are, or following certain modifications in the process of developing models of description for a given domain of knowledge/ expertise.
Conceptual meta-lexicons, thesauruses and libraries of blocks of models of description enable us to define the metalanguage of description* which is apt for analyzing the audiovisual corpora documenting a given domain of knowledge/ expertise, i.e. the universe of discourse of a particular audiovisual archive.
A metalanguage of description* manifests itself in the form of a dynamic library of models of description which differ, as we have seen, in terms of the object of the analysis*. Thus:
1. a class of models of description is reserved for the actual production of the meta-description, i.e. the explicitation of the content, objectives, authors, target audience, etc. of a particular analysis (on this subject, see [CHE 11a]);
2. a class of models of description is reserved for the explicitation of the paratextual data of the audiovisual objects being subjected to the analysis: the object’s title, author(s), genre, language, intellectual property, etc. (see [CHE 11a]);
3. an important class of models of description is given over to the actual analysis of the content conveyed by an audiovisual corpus (this is the main topic of this book);
4. just as important a class of models is devoted, more particularly, to the audiovisual mise en scène of the content conveyed by an audiovisual corpus (these are models facilitating the systematic analysis of the visual and acoustic shots, which are presented in greater detail in [DEP 11a]);
5. a class of models is reserved for the contextual adaptation of an audiovisual corpus, its preparation for use in specific contexts envisaged by a project of analysis (these are models which enable the analyst to suggest specific uses, provide explanatory references, produce bi- or multi-lingual versions, and so on; see [SAK 11]).
Of these different classes of models of description, some may be considered relatively common to any work of analysis – no matter what the nature of the analysis, and indeed no matter what the type of audiovisual text being analyzed.
In particular, these are models which relate to the description of the visual or sound shots and those which serve to annotate an audiovisual text so as to enrich it with references and comments for example, and demonstrate the interest it holds for a specific use context. “Relatively common” means that these models can be adapted to the particular requirements of a particular type of analytical task but, all told, these modifications relate only to the level of sophistication required of the analysis.
However, there is a category of models which depends entirely on the domain of knowledge which is documented by the corpus of audiovisual texts being analyzed – this is the category of thematic models which enable the analyst to describe the particular content (the subject(s), the purpose, the message, etc.) of an audiovisual text, a corpus of audiovisual texts or even a specific part of an audiovisual text. These models are essential and indispensable for the description and interpretation of an archive’s universe of discourse*. It is unsurprising, therefore, if we state that they constitute the “core” of our research and experimentation – the rest of this book will bear witness to this.
1 The acronym ASW is a reference to the research project which facilitated the development of this environment. As stated in the introduction to this book, we refer here to the Audiovisual Semiotic Workshop for describing audiovisual corpora in human and social sciences (ASW-HSS), financed by the Agence Nationale de la Recherche (ANR) from the start of 2009 to the end of 2011 (for further information, see the project’s website: http://www.asa-shs.fr/ or the research log devoted to this project on the Hypothèses.org portal: http://asashs.hypotheses.org/).
2 CCA (French, ARC) is an experimentation lab in the ASW-HSS Project, created and coordinated by Elisabeth de Pablo and used, amongst other contexts, in the context of teaching international communication to 2nd- and 3rd-year undergraduate students and 1st- and 2nd-year Masters students at INALCO (Institut National des Langues et Civilisations Orientales – National Institute of Oriental Languages and Civilizations) in Paris: http://semiolive.ext.msh-paris.fr/arc/.
3 As has already been mentioned in the introduction to this book, the ASW working environment has benefited from substantial support from the ANR, which has enabled us, with a small team of collaborators, to produce an operational prototype, which was used in the context of our ARA program. However, as it currently stands, the ASW environment remains a prototype.
4 See http://dublincore.org/.
5 See http://www.openarchives.org/.
6 See http://www.europeana.eu/schemas/ese/.
7 See http://www.oclc.org/ca/fr/dewey/versions/webdewey/default.htm.
8 See http://rameau.bnf.fr/.
9 In view of our fields of knowledge, we think immediately of UNESCO’s thesaurus devoted to human and social sciences and culture (http://databases.unesco.org/thesfr/), the Arts & Architecture Thesaurus (AAT) from the Getty Foundation (http://www.getty.edu/ research/tools/vocabularies/index.html), the MOTBIS thesaurus for education (http://www.cndp.fr/motbis/index.php/bibliographied/34-litterature-grise.html), etc.
10 The glossaries of the site Ethnologue – Languages of the World (http://www.ethnologue.com/home.asp), for instance, have been particularly important for work on our audiovisual corpora [STO 11a; STO 11b].
11 A whole series of ontologies have proven important for our work. We can cite, for instance, the DOLCE (Descriptive Ontology for Linguistic and Cognitive Engineering) from the Laboratory for Applied Ontology at ISTC-CNR in Trento, Italy (http://www.loa.istc.cnr.it/DOLCE.html) which helped us to organize our own metalinguistic resources; GOLD (General Ontology for Linguistic Description) which provided us with the basic concepts for describing the content of videos dedicated to linguistic research (http://linguistics-ontology.org/); or indeed the CIDOC Conceptual Reference Model (http://www.cidoc-crm.org/scope.html) which provided the metalinguistic references needed to describe the audiovisual content relating to cultural heritage.
12 This is the framework put forward by UNESCO for analyzing and evaluating intangible cultural heritage: http://www.unesco.org/culture/ich/index.php?lg=fr&pg=00001.
13 In our case, this refers to the French version, LOMFR, of the Learning Objects Metadata.