
Chapter 4
Visual Sensing and Gesture Interactions
Achintya K. Bhowmik
Intel Corporation, USA
4.1 Introduction
Vision plays the dominant role in our interactions with the physical world. While all our perceptual sensing and processing capabilities, such as touch, speech, hearing, smell, and taste, are important contributors as we the humans understand and navigate in our daily lives, the visual perception process involving the sensing and understanding of the world around us based on the optical information received and analysed by the human visual system is the most important and utilized. There is a good reason why we have evolved to predominantly use the daytime for activities and rest after the sun goes down. Fittingly, significant portions of our brain are dedicated to processing and comprehending visual information.
Visual displays are already the primary human interfaces to most of the electronic devices that we use in our daily lives for computing, communications, entertainment, etc., presenting the system output and responses in the form of visual information to the user. Manipulating and interacting with the visual content on the display remains an intense field of research and development, generally referred to in the published literature as human-computer interaction or human-machine interface.
As reviewed in Chapter 1, the early commercially successful means of human interaction with displays and systems included indirect methods using external devices such as television remote control and the computer mouse. With the widespread adoption of touch screen-equipped displays and touch-optimized software applications and user interfaces in recent years, displays are fast becoming two-way interaction devices that can also receive direct human inputs. However, touch-based systems are inherently two-dimensional input interfaces, limiting human interaction with the content on the display to the surface of the device. In contrast, we visually perceive and interact in the three-dimensional world, aided by a 3D visual perception system consisting of binocular imaging and inference schemes. The addition of such advanced vision capabilities promises to expand the scope of interactive displays and systems significantly. Equipped with human-like visual sensing and inference technologies, such displays and systems would “see” and “understand” human actions in the 3D space in front of the visual display, and make the human-interaction experiences more lifelike, natural, intuitive, and immersive.
The functional block diagram of an interactive display, modified to focus only on the vision-based human interfaces and interactions, is shown below in Figure 4.1. The process begins with capturing of the user actions via real-time image acquisition. The image sensing subsystem converts the light rays originating from the scene into electrical signals representing 2D or 3D visual information and sends it to the computing subsystem. Software algorithms that are specially designed to extract meanings from the image sequences lead to the recognition of user actions, such as gestures with hands, facial expressions, or eye gazes. This intelligence is then supplied to the application layer as user inputs, which executes various processing functions on the computing hardware accordingly to generate system responses. Finally, the display subsystem produces visual output of the application in the form of rays of light that are reconstructed to form images with the eyes and the visual perception system of the user.
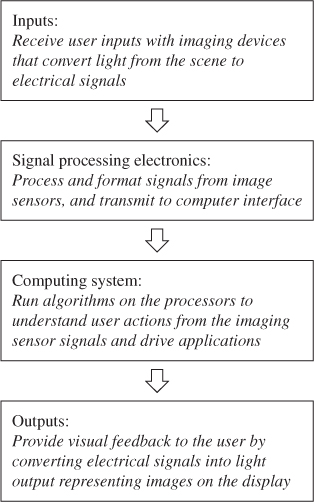
Figure 4.1 Functional block diagram of the system architecture of an interactive display focusing on vision-based sensing and interactions.
In this chapter, we review the fundamentals and advances in vision-based interaction technologies and applications, with a focus on visual sensing and processing technologies, as well as algorithmic approaches for implementing system intelligence to enable automatic inference and understanding of user actions. In the next section, we discuss image acquisition methods, covering both 2D and 3D imaging technologies. 3D sensing techniques are covered in details in the next three chapters. Following the overview of image acquisition technologies, we review gesture interaction techniques, including gesture modelling, analysis, and recognition methods with applications in interactive displays. Finally, we also provide a review of the advances in the development of techniques for automatic understanding of facial expressions.
4.2 Imaging Technologies: 2D and 3D
Image sensing devices, primarily digital cameras that capture two-dimensional images, are increasingly becoming ubiquitous and being built into devices of all form-factors along with the image displays. Cameras are now integral elements of most mobile devices, such as phones, tablets, and laptop computers, and are increasingly appearing in all-in-one desktop computers, modern flat-panel television sets, etc. Despite the widespread adoption of imaging devices in all these systems, their applications have mostly been limited to capturing digital media, such as pictures and videos for printing or viewing on display devices, and video conferencing applications, rather than vision-based user interactions.
Traditional image sensing and acquisition devices convert the visual information in the 3D scene into a 2D array of numbers, where points in the original 3D space in the real world are mapped to discrete 2D points on the picture plane (pixels) and digital values are assigned to indicate the brightness levels corresponding to their primary colors (pixel values). This process of generating 2D images from the visual information in the 3D world can be mathematically described by a homogenous matrix formalism involving the perspective projection technique:
where [x] represents the point in the 3D world, ![]() represents the transformed point on the 2D image, and [C] is the camera transformation matrix consisting of matrices corresponding to camera rotation and translation and the perspective projection matrix [1].
represents the transformed point on the 2D image, and [C] is the camera transformation matrix consisting of matrices corresponding to camera rotation and translation and the perspective projection matrix [1].
However, as a result of this transformation process, the 3D information cannot be truthfully recovered from the 2D images that are captured, since the pixels in the images only preserve partial information about the original 3D space. Reconstruction of 3D surfaces from single intensity images is a widely researched subject, and continues to make significant progress [2, 3]. Implementation of real-time interaction applications based on the single 2D image sensing devices, however, remains limited in scope and computationally intensive.
The human visual system consists of a binocular imaging scheme, and it is capable of depth perception. This allows us to navigate and interact in the 3D environment with ease. Similarly, rich human-computer interface tasks with complex interaction schemes are better accomplished using 3D image sensing devices which also capture depth or range information in addition to the color values for a pixel. Interactive applications utilizing real-time 3D imaging are starting to become popular, especially in the gaming and entertainment console systems in the living rooms and 3D user interfaces on personal computers [4, 5]. While there are various ways of capturing 3D visual information, three of the most prominent methods are projected structured light, stereo-3D imaging, and time-of-flight range imaging techniques [6]. Chapters 5, 6, and 7 provide in-depth reviews of these 3D sensing technologies.
In the case of structured light-based 3D sensing methods, a patterned or “structured” beam of light, typically infrared, is projected onto the object or scene of interest. The image of the light pattern deformed due to the shape of the object or scene is then captured using an image sensor. Finally, the depth map and 3D geometric shape of the object or scene are determined using this distortion of the projected optical pattern. This is conceptually illustrated in Figure 4.2 [7]. In Chapter 5, Zhang, et al., cover both the fundamental principles and state-of-the-art developments in structured light 3D imaging techniques and applications.
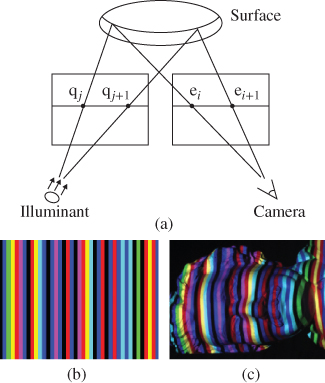
Figure 4.2 Principles of a projected structured light 3D image capture method. (a) An illumination pattern is projected onto the scene and the reflected image is captured by a camera. The depth of a point is determined from its relative displacement in the pattern and the image. (b) An illustrative example of a projected stripe pattern. In practical applications, infrared light is typically used with more complex patterns. (c) The captured image of the stripe pattern reflected from the 3D object.
Source: Zhang, Curless and Seitz, 2002. Reproduced with permission from IEEE.
The stereo imaging-based 3D computer vision techniques attempt to mimic the human-visual system, in which two calibrated imaging devices, laterally displaced from each other, capture synchronized images of the scene. Subsequently, the depth for the points, mapped to the corresponding image pixels, is extracted from the binocular disparity. The basic principles behind this technique are illustrated in Figure 4.3, where ![]() and
and ![]() are the two camera centers with focal length
are the two camera centers with focal length ![]() , forming images of a point in the 3D world, P, at positions A and B in their respective image planes.
, forming images of a point in the 3D world, P, at positions A and B in their respective image planes.
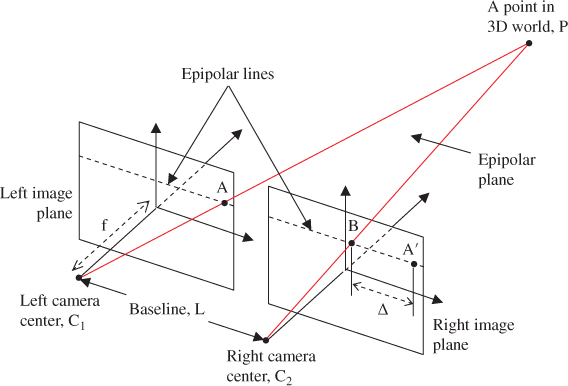
Figure 4.3 Basics of stereo-3D imaging method, illustrated with the simple case of aligned and calibrated camera pair with optical centers at 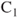 and
and 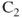 , respectively, separated by the baseline distance of L. The point, P, in the 3D world is imaged at points A and B on the left and the right cameras, respectively.
, respectively, separated by the baseline distance of L. The point, P, in the 3D world is imaged at points A and B on the left and the right cameras, respectively. 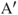 on the right image plane corresponds to the point A on the left image plane. The distance between B and
on the right image plane corresponds to the point A on the left image plane. The distance between B and 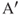 on the epipolar line is called the binocular disparity,
on the epipolar line is called the binocular disparity, 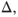 which can be shown to be inversely proportional to the distance, or depth, of the point P from the baseline.
which can be shown to be inversely proportional to the distance, or depth, of the point P from the baseline.
In this simple case, where the cameras are parallel and calibrated, it can be shown that the distance of the object, perpendicular to the baseline connecting the two camera centers, is inversely proportional to the binocular disparity:
Algorithms for determining binocular disparity and depth information from stereo images have been widely researched and further advances continue to be made [8]. In Chapter 6, Lazaros provides an in-depth review of the developments in stereo-imaging systems and algorithms.
The time-of-flight 3D imaging method measures the distance of the object points, hence the depth map, by illuminating an object or scene with a beam of modulated infrared light and determining the time it takes for the light to travel back to an imaging device after being reflected from the object or scene, typically using a phase-shift measurement technique [9]. The system typically comprises a full-field range imaging capability, including amplitude-modulated illumination source and an image sensor array.
Figure 4.4 conceptually illustrates the method for converting the phase shifts of the reflected optical signal to the distance of the point. The reflected signal, shown in the dashed curve, is phase-shifted by ![]() relative to the original emitted signal. It is also attenuated in strength and the detector picks up some background signal as well, which is assumed to be constant. With this configuration, it can be shown that the distance of the object that reflected the signal,
relative to the original emitted signal. It is also attenuated in strength and the detector picks up some background signal as well, which is assumed to be constant. With this configuration, it can be shown that the distance of the object that reflected the signal,
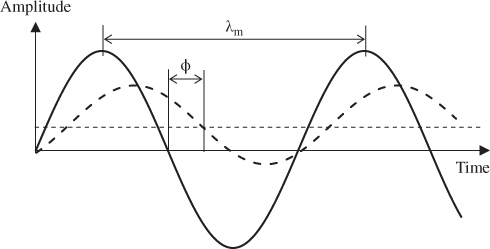
Figure 4.4 Principles of 3D imaging using the time-of-flight range measurement techniques. The solid sinusoidal curve is the amplitude-modulated infrared light that is emitted onto the scene by a source, and the dashed curve is the reflected signal that is detected by an imaging device. Note that the reflected signal is attenuated and phase-shifted by an angle 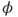 relative to the emitted signal, and includes a background signal that is assumed to be constant. The distance or the depth map is determined using the phase shift and the modulation wavelength.
relative to the emitted signal, and includes a background signal that is assumed to be constant. The distance or the depth map is determined using the phase shift and the modulation wavelength.
where ![]() is the modulation wavelength of the optical signal. In Chapter 7, Nieuwenhove reviews the principles of time-of-flight depth-imaging methods and system design considerations for applications in interactive displays and systems.
is the modulation wavelength of the optical signal. In Chapter 7, Nieuwenhove reviews the principles of time-of-flight depth-imaging methods and system design considerations for applications in interactive displays and systems.
Generally, the output of a 3D imaging device is a range image, also called depth map, often along with a corresponding color image of the scene. An example of this is shown in Figure 4.5, where the depth values are scaled to display as an 8-bit image, such that the points nearer to the sensing device appear brighter. As shown in the functional block diagram in Figure 4.1, generating the image and the range or depth information using any of these 3D sensing technologies is the first step to accomplish for an interactive display. The next step is to implement algorithms that can recognize real-time human actions and inputs using this data. In the next section, we review the methods for implementing gesture recognition tasks for interactive applications.
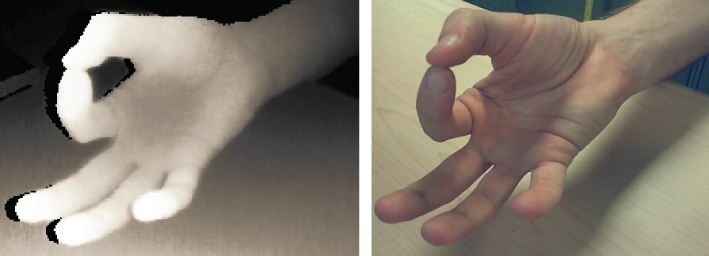
Figure 4.5 Output of a 3D imaging device. Left, range image, also called the depth map, for a hand in front of the 3D sensing device. The intensity values in the depth map decrease with the distance from the sensor, thus the nearer objects are brighter. Right, the corresponding color image. Note that the images are not of the same resolution, and have been scaled and cropped.
4.3 Interacting with Gestures
For inter-human interactions, we make abundant use of gestures and motions with fingers, hands, head and other body parts, facial expressions, and eye gazes, even as we use speech as the primary mode of communications. In contrast, the traditional computer input interfaces based on mouse, keyboard, or even touch screens allow limited interactive experiences. Thus, there has been significant interest and efforts made in adding gesture recognition capabilities in human-computer interactions using computer vision technologies, with a goal towards making the user experiences more natural and efficient.
The general objective of implementing a gesture recognition system is to make the computer automatically understand human actions, instructions, and expressions, by recognizing the gestures and motions articulated by the user in front of an interactive display.
Early implementations of systems developed to recognize human gestures in the 3D space were based on sensor-rich body-worn devices such as hand gloves. This approach gained popularity among the human-computer interaction researchers, following the commercial introduction of a data glove that was designed to provide hand gesture, position, and orientation information [10]. The data glove, connected to a host computer, allowed the wearer to drive a 3D hand model on the interactive display for real-time manipulation of objects in a 3D environment. A number of review articles provide in-depth surveys of the glove-based research and developments [11, 12].
While the glove-based approaches demonstrated the efficacy and versatility of 3D interactions, broad consumer adoption would require marker-less implementations that do not require wearing such tracking devices on the body. The recent developments of sophisticated and yet cost-effective and small form-factor imaging devices, advanced pattern recognition algorithms, and powerful computational resources, make computer-vision based natural gesture recognition schemes feasible.
In recent years, much research has been devoted to human gesture recognition using computer vision techniques, modelling and statistical methods based on real-time capture and analysis of 2D and 3D image sequences, and a vast number articles have been published detailing research results as well as broad reviews and surveys [13–16]. Broadly, the algorithmic approaches can be divided into two major categories: 3D model-based techniques that use shape or skeletal models of human hands and body, and view-based techniques that use 2D intensity image sequences or low-level features extracted from the visual images of the hand or other body parts. As each of these approaches has its strengths and limitations, the optimum solutions are likely to be hybrid methods that utilize relevant aspects of each technique. Figure 4.6 shows the typical algorithmic steps and flow in the vision-based gesture recognition processes.
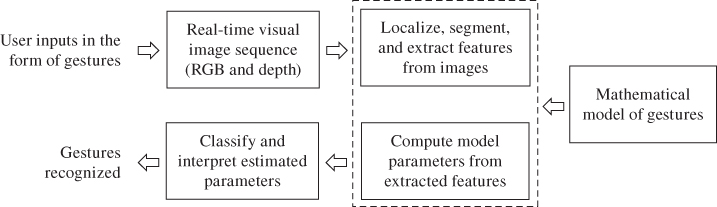
Figure 4.6 Block diagram showing the algorithmic steps and flow of vision-based gesture recognition processes.
The process starts with real-time acquisition of visual images of the user, providing inputs with gestures in the 3D space. The first step after receiving the visual images as inputs is to localize and segment the target object, such as the hand for recognizing gestures or the face for recognizing expressions. The traditional 2D camera-based systems use color or motion cues for image segmentation, which are prone to errors due to varying and unpredictable background color and ambient lighting conditions. The use of 3D-sensing cameras, such as those reviewed in the previous section, provides an additional important cue, such as the proximity of the hand to the imaging device for initial detection and tracking, and it allows segmenting based on depth.
As an example, Van den Bergh and Van Gool experimentally demonstrated the advantages of using a depth camera for hand segmentation in real-time gesture recognition applications over the color-based approaches [35]. As shown in Figure 4.7, the use of color probability approach does not segment the hand from the face when the hand overlaps the face. However, when a depth-based thresholding is added to remove the face, a clean segmentation is achieved.
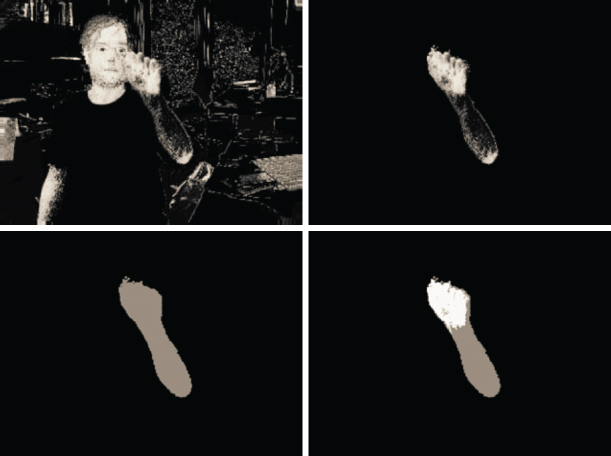
Figure 4.7 An example of using depth and color images for hand segmentation. Top left, skin color probability determined from the RGB image. Bottom left, depth image of the hand after thresholding to remove the background including the face. Top right, skin color probability limited only to foreground pixels determined from thresholded depth image. Bottom right, combined result showing segmented hand. Source: Van den Bergh & Van Gool 2011. Reproduced with permission from IEEE.
After the target objects are identified and segmented, specific features from the images are extracted, such as contours, edges, or special features such as fingertips, face, and limb silhouettes, etc. Generally, a mathematical model is developed for the target gestures, including both the temporal and spatial attributes of the gestures, modelled with a set of parameters. Subsequent to the feature detection and extraction process, the parameters of this model are computed, using the features extracted from the images. Finally, the gestures performed by the user are recognized by classifying and interpreting the model parameters that were estimated at the analysis step.
Early work on 3D model-based approaches generally focused on finding a set of kinematic parameters for the 3D hand or body model, such that the 2D projected geometries of the model would closely match the corresponding edge-based images [18]. Simply stated, the parameters of the 3D model are varied until the appearance of the articulated model resembles the captured image. The models that have been used can be categorized as either volumetric or skeletal in their construction. The volumetric models typically represent the human hands or body as a collection of adjoined cylinders, with varying diameters and lengths. In such cases, the matching exercise has the goal of determining the parameters of the cylinders that bring the 3D model into correspondence with the recorded images.
In contrast, the skeletal models consist of parameters based on joint angles and segment lengths. In both cases, use of constraints based on physiology to restrict the degrees of freedom for motions that are consistent with human anatomy helps to bound the analysis space. As an example, Figure 4.8 shows the representation of the same human hand pose using different models [13].
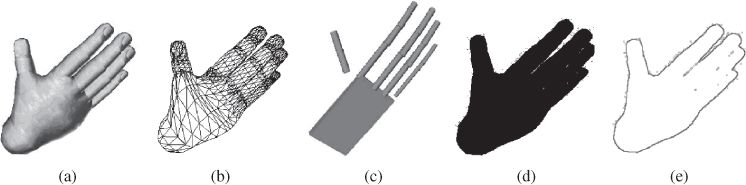
Figure 4.8 Different hand models to represent the same hand pose: (a) 3D textured volumetric model, (b) wireframe 3D model, (c) 3D skeletal model, (d) 2D silhouette, (e) 2D contour or edges. Source: Pavlovic, Sharma, and Huang 1997. Reproduced with permission from IEEE.
Recently, Stenger et al. used a Kalman filter-based method to estimate the pose of the human hand that minimizes the geometric errors between the 2D projections of the 3D hand model and the edges extracted from the hand images [19]. 3D model-based approaches have typically been computationally heavy, though their versatility in human-computer interactions have long been recognized [13].
With the advent of small-footprint and low-cost depth-sensing cameras, more efficient and robust methods are being developed. For example, Melax et al. recently reported a computationally-efficient method that fits a 3D model of the hand into the depth image or 3D point cloud acquired by a 3D imaging device, on a frame-by-frame basis, and imposes constraints based on physiology for tracking of the hand and the individual fingers, despite occasional occlusions [20]. As shown in Figure 4.9, this method enables versatile manipulation of objects in the 3D space visually represented in an interactive display system that is equipped with a real-time 3D sensing device. Similarly, robust tracking of human body poses using real-time range data captured by depth cameras has also been reported [21].

Figure 4.9 An articulated 3D model based hand skeletal tracking technique that enables fine-grain versatile manipulation of objects in the 3D space. A 3D model of the hand is fit to the depth map or point cloud acquired by a depth sensing device, taking into account physiological constraints.
While the view-based, also referred to as appearance-based, approaches have been reported to be computationally lighter than the model-based approaches, they have typically lacked the generality that can be achieved with the 3D model-based techniques, and thus so far have found relatively limited applicability in human-computer interaction schemes. However, promising developments are increasingly being reported in the recent years.
Generally, this approach involves comparing the visual images or features with a predefined template representing a set of gestures. Much of the early work focused on the relatively simpler cases of static hand pose recognition using algorithms adapted from general object recognition schemes. However, it is well recognized that the implementation of natural human-computer interactions requires the recognition of dynamic gesture inputs to understand the intent of human actions rather than just static poses. Various statistical modelling based approaches, along with image processing and pattern recognition techniques, have been reported for automatic recognition of human poses, gestures, and dynamic actions, including principal component analysis using sets of training data, hidden Markov models, Kalman filtering, particle filtering, conditional density propagation or “condensation” algorithms, finite state machine techniques, etc. [22–29].
Incorporating gesture-based interactions in practical applications requires careful consideration of human-factors aspects of physical interaction to ensure a comfortable and intuitive user experience. Clearly, the meaning and implication of gestures are subjective, different people may use different types of gestures to convey the same intention, and even the same person may use varying gestures at different times and context. Several researchers have reported detailed analysis of human motion behavior [30, 31].
An efficient approach to gesture recognition research has been to first understand and model human motion behavior, then proceed to developing the algorithms for recognition of user actions based on gesture motions. This is the underlying principle behind the hidden Markov model-based approaches, where the human behavior is treated as a large set of mental or intentional states that are represented by individual control characteristics and statistical probabilities of interstate transition [22–25]. In simple words, what we will do at the next moment is a smooth transition from our action at the current moment, and this transition can be represented by a statistical probability, since there would generally be a number of future actions to pick from that could follow the current action. So, the task of understanding the intended human interactions with gestures consists of recognizing the current hand and finger poses and a prediction of the next likely set of actions.
As an example, Pentland's work builds on the model that the basic elements of cortical processing can be described by Kalman filters that can be linked together to model the larger sets of behavior [25]. Using this hypothesis, they described the human motion behavior as a set of dynamic models represented by Kalman filters that are linked by a Markov chain of probabilistic transitions, and demonstrated the power of this technique in predicting the behavior of automobile drivers from their initial preparatory movements. The same approach would be applicable in general human-computer interfaces and interactions. This is conceptually illustrated in Figure 4.10, where a specific human action chain is described by a Markov dynamic model consisting of distinguishable states that are linked by probabilistic transitions. Generally, each state also consists of a number of sub-states, indicative of the complexity of mathematical models underlying human behavior. A combination of the recognition of user actions, coupled with successful predictions and anticipations of subsequent user motions, would make the interaction experience fluid by making the systems more responsive to human gesture inputs.
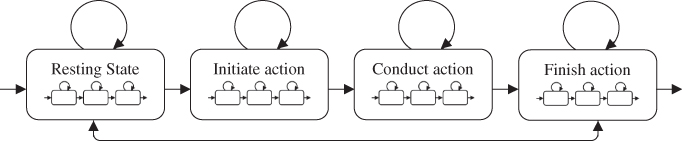
Figure 4.10 A simplified conceptual representation of a human action chain by a Markov dynamic model. The major states are linked by inter-state transition probabilities. Each state also consists of interlinked sub-states. A smooth gesture action recognition system would consist of interpretation of the current pose and prediction, along with the anticipation of the next set of actions.
In addition to the development of sensing technologies and recognition algorithms, human computer interaction researchers also continue to study and categorize classes of gesture interfaces for interactive displays and systems [32, 33]. As part of human discourse, we often perform non-specific gestures that are intended to accompany spoken language, such as waving of hands or fingers in space while speaking. By nature, this kind of gestures are not strictly defined, often unintentional, and vary widely between people and circumstances. We also often make deliberate gestures that are intended to imply specific communications or instructions, either independently articulated or reinforcing spoken discourses.
It is the second category of gesture articulations that is more relevant to the realm of implementing human-computer interactions. After reviewing the existing body of work on comprehending human gestures with the goal of advancing human computer interactions towards natural inter-human discourses and communications, Quek et al. [32] broadly classified gesture implementation into two predominant clusters: semaphoric and manipulative gestures. The semaphoric approach employs a stylized dictionary of static or dynamic poses or gesture sets, where the system is designed to record and identify the closest match of the performed poses or gestures from this predefined library. Practically, this approach can only provide the application of a small subset of the rich variety of daily interactions that humans deploy in real-life interactions with the physical world.
Manipulative gestures, on the other hand, involve controlling the virtual entities on an interactive display with hand or body gestures, where the movements of the displayed objects are correlated with the real-time user actions. While the manipulative gesture-based approaches are more versatile than the semaphoric approaches, Quek and Wexelblat [32, 33] also point to the shortcomings of current implementations when compared with our conversational and natural interactions. Implementations that are limited to and optimized for specific systems and applications perform reasonably well, but the goal remains to develop versatile methods that would make natural and intuitive lifelike gesture interactions possible between the humans and the content on an interactive display.
While much of the early research and implementation approaches focused only on the acquisition, analyses, and interpretation of color images, the additional use of range data from depth cameras provide comparatively more robust and efficient algorithmic pathways [34–37]. The recent advances in 3D sensing, modelling and inference algorithms, and user interfaces promise to take us nearer to the goal of achieving natural interactions in the near future.
Besides making gestures with hands, fingers, and other limbs, we also make abundant use of eye gazes, facial gestures and expressions in our interactions with fellow human beings. In Chapter 8, Drewes provides an extensive review of eye gaze tracking technologies, algorithms, and applications utilizing gaze-based interactions.
Detection and recognition of human faces and facial expressions are a widely researched area in the field of computer vision as well [38–45]. In Chapter 10, Poh et al. reviews face recognition technologies as part of multimodal biometrics. In addition to face detection and recognition, the importance of facial expressions in multimodal human communications cannot be overstated, as the emotions conveyed via facial gestures can amplify, or literally change the meaning of, the discourses conveyed via speech or hand gestures. It is not surprising that we always attempt to look at the person who is talking to us in order to properly understand his or her intent.
Early work on developing algorithms for automatic interpretation of human facial expressions were based on traditional 2D images and intensity-based analyses, such as those detailed in a number of comprehensive review articles that have been published in the recent years [40, 41]. Recently, advances are also being made that utilize 3D models and point cloud data generated by 3D sensing devices [42–45]. For example, Wang et al. reported a method to extract primitive 3D facial expression features and then use these features to classify expressions followed by a person-independent expression recognition method, as illustrated in the top of Figure 4.11 [42].
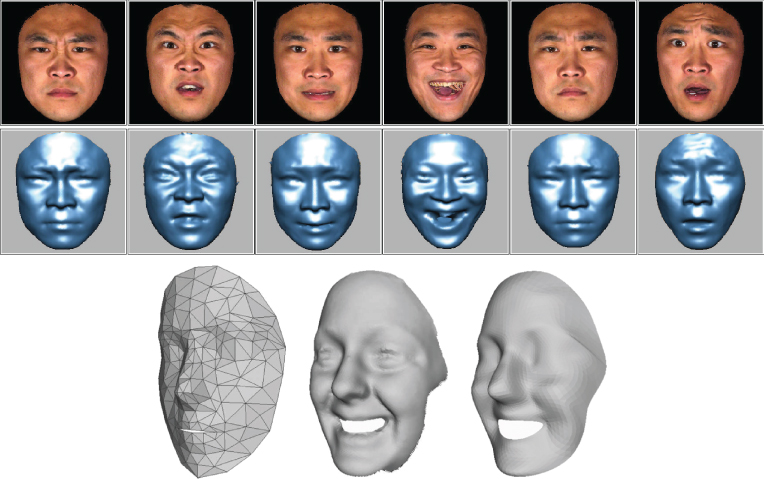
Figure 4.11 Top, an example of 3D facial range models developed by Wang et al., showing six expressions: anger, disgust, fear, happiness, sadness, and surprise (from left to right). Upper row shows the textured models and the row below shows the corresponding shaded models.
Source: Wang, Yin, Wei, and Sun 2006. Reproduced with permission from IEEE. Bottom, 3D face model approach used by Mpiperis et al. in face and expression recognition. Left, an initial 3D mesh model. Middle, 3D surface of a human face captured using 3D imaging technique. Right, the 3D mesh model fitted to the 3D surface. Source: Mpiperis, Malassiotis, Strintzis 2008. Reproduced with permission from IEEE.
As another example, Mpiperis et al. reported a 3D-model based approach that achieves both identity-invariant facial expression recognition and expression-invariant face recognition [43]. As shown in the bottom of Figure 4.11, this approach fits a deformable facial surface mesh model to the cloud of 3D points collected from the human face acquired by a 3D sensor. The initial mesh model is designed to be neutral, and it conforms to the exhibited expression, once fitted to the surface generated by the 3D point cloud of the face under study. The facial expression is then recognized by a mathematical procedure to find correspondence within a previously determined set. While further algorithmic developments continue to make progress in several research labs around the world, the incorporation of facial expression understanding, along with hand and body gesture recognition techniques, is set to significantly enhance vision-based human interface schemes for the future interactive displays and systems.
4.4 Summary
Science fiction pioneers have long envisioned computers that would understand and respond to human actions and instructions in natural settings in the 3D environment. As an example, the acclaimed 2002 American science fiction movie Minority Report, directed by Steven Spielberg, depicts a future in the year 2054, where the computer has a spatial operating interface that allows the user to interact with the multimedia content on the display with gestures of the hands in the 3D space in front of it. While this was considered prescient foretelling of the future at the time, scientists and engineers have already developed technologies and systems that are helping to realize this dream several decades sooner. In fact, the real-world implementations are already more elegant, as the advances in computer vision technologies allow 3D gesture interactions with the computers without having to use any special gloves or other body-worn devices, as envisioned in the movie.
In this chapter, we have reviewed the developments in vision-based 3D sensing and interaction technologies. While the early work on computer vision was largely based on the analysis of intensity images acquired by 2D cameras, the recent developments in 3D imaging techniques allow efficient and real-time acquisition of depth map and 3D point cloud. In parallel, developments in gesture recognition algorithms have also made significant progress in the recent years, on both 3D model-based approaches as well as image- or feature-based approaches. This, coupled with the research on understanding and modelling of human motion behavior, is bringing natural human-computer interactions in the 3D space in front of interactive displays close to reality. Interactive displays that can “feel” the touch of our fingers are already ubiquitous, and now the addition of advanced visual sensing and recognition technologies is allowing the development of a new class of interactive displays that can “see” and “understand” our actions in the 3D space in front of it.
References
- 1. Trucco, E., Verri, A. (1998). Introductory Techniques for 3-D Computer Vision. Prentice Hall.
- 2. Saxena, A., Sun, M., Ng, A. (2008). Make3D: Learning 3-D Scene Structure from a Single Still Image. IEEE Transactions on Pattern Analysis, Machine Intelligence.
- 3. Chen, T., Zhu, Z., Shamir, A., Hu, S., Cohen-Or, D. (2013). 3-Sweep: Extracting Editable Objects from a Single Photo. ACM Transactions on Graphics 32(5).
- 4. Microsoft Corporation (2013). www.xbox.com/en-US/kinect. Retrieved Nov 16, 2013.
- 5. Intel Corporation (2013). www.intel.com/software/perceptual. Retrieved Nov 16, 2013.
- 6. Bhowmik, A. (2013). Natural, Intuitive User Interfaces with Perceptual Computing Technologies. Inf Display 29, 6.
- 7. Zhang, L., Curless, B., Seitz, S. (2002). Rapid Shape Acquisition Using Color Structured Light, Multi-pass Dynamic Programming. IEEE Int Symp 3D Data Proc Vis Trans 24–36.
- 8. Brown, M., Burschka, D., Hager, G. (2003). Advances in Computational Stereo. IEEE Trans Pattern Analysis, Machine Int 25, 8.
- 9. May, S., Droeschel, D., Holz, D., Fuchs, S., Malis, E., Nuchter, A., Hertzberg, J. (2009). Three-dimensional mapping with time-of-flight cameras. Journal of Field Robotics – Three-Dimensional Mapping, Part 2, 26(11–12), 934–965.
- 10. Zimmerman, T., Lanier, J., Blanchard, C., Bryson, S., Harvill, Y. (1987). A hand gesture interface device, Proceeding of the Conference on Human Factors in Computing Systems. Graphics Interface, 189–192.
- 11. Sturman, D., Zeltzer, D. (1994). A survey of glove-based input. IEEE Computer Graphics, Applications 14(1), 30–39.
- 12. Dipietro, L., Sabatini, A., Dario, P. (2008). A Survey of Glove-Based Systems, Their Applications, IEEE Transactions on Systems, Man, Cybernetics, Part C: Applications, Reviews 38(4), 461–482.
- 13. Pavlovic, V., Sharma, R., Huang, T. (1997). Visual interpretation of hand gestures for human-computer interaction: A review. IEEE Trans Pattern Analysis, Machine Intelligence 19(7), 677–695.
- 14. Derpanis, K. (2004). A Review of Vision-Based Hand Gestures. Internal report, Centre for Vision Research, York University, Canada.
- 15. Mitra, S., Acharya, T. (2007). Gesture Recognition: A Survey. IEEE Transactions on Systems, Man,, Cybernetics – Part C: Applications, Reviews 37, 311–324.
- 16. Wu, Y., Huang, T. (1999). Vision-Based Gesture Recognition: A Review, Proceedings of the International Gesture Workshop on Gesture-Based Communication in Human-Computer Interaction, pp. 103–115, Springer-Verlag.
- 17. Garg, P., Aggarwal, N., Sofat, S. (2009). Vision Based Hand Gesture Recognition. World Academy of Science, Engineering, Technology 25, 972–977.
- 18. Rehg, J., Kanade, T. (1994). Visual tracking of high DOF articulated structures: An application to human hand tracking. European Conference on Computer Vision B 35–46.
- 19. Stenger, B., Mendonca, P., Cipolla, R. (2001). Model-based 3D tracking of an articulated hand. IEEE Conference on Computer Vision, Pattern Recognition II, 310–315.
- 20. Melax, S., Keselman, L., Orsten, S. (2013). Dynamics Based 3D Skeletal Hand Tracking. Proceedings of the ACM SIGGRAPH Symposium on Interactive 3D Graphics, Games, 184–184.
- 21. Ganapathi, V., Plagemann, C., Koller, D., Thrun, S. (2012). Real Time Human Pose Tracking from Range Data. Lecture Notes in Computer Science 7577, 738–751.
- 22. Yamato, J., Ohya, J., Ishii, K. (1992). Recognizing human action in time-sequential images using hidden Markov model. Proceedings of IEEE Computer Vision, Pattern Recognition, 379–385.
- 23. Kobayashi, T., Haruyama, S. (1997). Partly-hidden Markov model, its application to gesture recognition. IEEE International Conference on Acoustics, Speech, Signal Processing 4, 3081–3084.
- 24. Yang, J., Xu, Y., Chen, C.S. (1997). Human action learning via hidden Markov model. IEEE Trans on Systems, Man,, Cybernetics Part A: Systems, Humans 27(1), 34–44.
- 25. Pentland, A., Liu, A. (1999). Modelling and Prediction of Human Behavior. Neural Computation 11, 229 – 242.
- 26. Arulampalam, M., Maskell, S., Gordon, N., Clapp, T. (2002). A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Transactions on Signal Processing 50(2), 174–188.
- 27. Isard, M., Blake, A. (1998). Condensation – conditional density propagation for visual tracking. International Journal of Computer Vision 29(1), 5–28.
- 28. Bobick, A., Wilson, A. (1997). A State-based Approach to the Representation, Recognition of Gesture. IEEE Transactions on Pattern Analysis, Machine Intelligence 19, 1325–1337.
- 29 Imagawa, K., Lu, S., Igi, S. (1998). Color-based hands tracking system for sign language recognition. Proceedings of IEEE International Conference on Automatic Face, Gesture Recognition, 462–467.
- 30. Aggarwal, J., Cai, Q. (1999). Human Motion Analysis: A Review. Computer Vision, Image Understanding 73(3), 428–440.
- 31. Gavrila, D.M. (1999). The visual analysis of human movement: a survey. Computer Vision, Image Understanding 73, 82–98.
- 32. Quek, F., McNeill, D., Bryll, R., Duncan, S., Ma, X., Kirbas, C., McCullough, K.E., Ansari, R. (2002). Multimodal human discourse: gesture, speech. ACM Transactions on Computer-Human Interaction 9, 171–193.
- 33. Wexelblat, A. (1995). An approach to natural gesture in virtual environments. ACM Transactions on Computer-Human Interaction 2, 179–200.
- 34. Ye, M., Zhang, Q., Wang, L., Zhu, J., Yang, R., Gall, J. (2013). A survey on human motion analysis from depth data, Time-of-Flight, Depth Imaging Sensors, Algorithms,, Applications. Lecture Note in Computer Science 8200, 149–187.
- 35. Van den Bergh, M., Van Gool, L. (2011). Combining RGB, ToF cameras for real-time 3D hand gesture interaction. IEEE Workshop on Applications of Computer Vision, 66–72.
- 36. Kurakin, A., Zhang, Z., Liu, Z. (2012). A real time system for dynamic hand gesture recognition with a depth sensor. European Signal Processing Conference, 1975–1979.
- 37. Liu, X., Fuijimura, K. (2004). Hand gesture recognition using depth data. Proceedings of the Sixth IEEE international conference on Automatic face, gesture recognition, 529–534.
- 38. Yang, M., Kriegman, D., Ahuja, N. (2002). Detecting Faces in Images: A Survey. IEEE Transactions on Pattern Analysis, Machine Intelligence 24(1), 34–58.
- 39. Tolba, A., El-Baz, A., El-Harby, A. (2006). Face Recognition: A Literature Review. International Journal of Signal Processing 2(2), 88–103.
- 40. Fasel, B., Luttin, J. (2003). Automatic Facial Expression Analysis: a survey. Pattern Recognition 36(1), 259–275.
- 41. Pantic, M., Rothkrantz, L. (2000). Automatic Analysis of Facial Expressions: The State of the Art. IEEE Transactions on Pattern Analysis, Machine Intelligence 22, 1424–1445.
- 42. Wang, J., Yin, L., Wei, X., Sun, Y. (2006). 3D facial expression recognition based on primitive surface feature distribution. IEEE Conference on Computer Vision, Pattern Recognition 2, 1399–1406.
- 43. Mpiperis, I., Malassiotis, S., Strintzis, M.G. (2008). Bilinear Models for 3-D Face, Facial Expression Recognition. IEEE Transactions on Information Forensics, Security 3(3), 498–511.
- 44. Yin, L., Chen, X., Sun, Y., Worm, T., Reale, M. (2008). A High-Resolution 3D Dynamic Facial Expression Database. The 8th International Conference on Automatic Face, Gesture Recognition, 17–19.
- 45. Allen, B., Curless, B., Popovic, Z. (2003). The space of human body shapes: reconstruction, parameterization from range scans. Proceedings of ACM SIGGRAPH 22(3), 587–594.