
7
Theoretical Considerations: Inferring and Enforcing Use Patterns for Mobile Cloud Assurance
Gul Agha, Minas Charalambides, Kirill Mechitov, Karl Palmskog, Atul Sandur and Reza Shiftehfar
Department of Computer Science, University of Illinois at Urbana-Champaign, Urbana, IL, USA
The mobile cloud is the integration of smart sensors, mobile devices, and cloud computers in a well-connected ecosystem. Such integration can improve the efficiency of services. However, such integration also leads to security and trust issues. For example, the security of cloud spaces has sometimes been breached through accessing of peripheral devices, such as HVAC systems. This chapter will show how mobile cloud security and trust can be improved while maintaining the benefits of efficiency by supporting fine-grained mobility. Specifically, we discuss an actor-based programming framework that can facilitate the development of mobile cloud systems in a way that improves efficiency while enforcing security and privacy. There are two key ideas here. First, by supporting fine-grained units of computation (actors), a mobile cloud can be agile in migrating components. It does so in response to a system context (including dynamic variables such as available bandwidth, processing power, and energy) while respecting constraints on information containment boundaries. Second, by specifying constraints on interaction patterns, information flow between actors can be observed and suspicious activity flagged or prevented. We introduce the concepts and discuss their realization in notations and prototypes. Finally, we will discuss open research issues such as inference of interaction patterns.
7.1 Introduction
Mobile devices and smart sensors have become ubiquitous. Such devices are relatively inexpensive but have limited computational resources (memory, processing capability, and energy). These limitations currently preclude the use of connected devices in many complex applications [1]. At the same time, cloud computing provides elastic on-demand access to virtually unlimited resources at an affordable price. To provide the functionality and quality of service that users demand, mobile devices and smart sensors need to be integrated into a broader context of cloud computing. We call such an integrated system a mobile cloud.
We propose to consider computation in the mobile cloud as an interaction between mobile agents or actors [2]. Each actor isolates state and can be accessed only through a message-passing interface. Moreover, actors are the units of migration. This makes migration efficient, as an actor's behavior is not affected by another's internal state. Thus, a mobile cloud based on actors provides many opportunities for improving energy efficiency and timeliness of services.
However, while actor (code and data) offloading can improve application user experience, it must be performed while respecting user security and privacy requirements. In an environment with both trusted (private) and untrusted (public) cloud resources, the origin and destination of data and code sent from devices, for example, during code offloading, must be taken into account. To support such hybrid cloud environments, actor frameworks for the mobile cloud must allow specification of fine-grained security policies that are monitored and enforced by the application runtime.
With actors as the unit of migration, data and code that manipulates the data are treated as a single entity. This facilitates security, for example, through prevention of actor migration when such migration violates security and privacy requirements. Actor migration can be favorably contrasted with the common practice of computation migration at the level of virtual machines (VM); virtual machines are relatively coarse-grained, incorporating a substantial amount of code and data. This not only complicates migration but also makes it more difficult to enforce boundaries between different pieces of code and data that happen to reside on the same VM.
Runtime monitoring may be used to collect observations on application intent, which in turn can be used to infer and adapt (constrain) behavior of application components. For example, actor migration may be triggered when communication patterns suggest offloading to specific cloud resources for better application latency, or to prevent violations of interaction protocols between actors. Monitoring of interaction between actors can also be used to prevent violations of interaction protocols or to flag them. Coordination constraints can represent the permitted order of operations. Such constraints may be explicitly specified, or they may be inferred. Coordination constraints can be encoded using actor synchronization constraints [3]. They can also be translated to actor session types [4,5]. Session types allow us to check whether the behavior of participant actors in an interaction conforms to specific interaction patterns that implement a protocol.
In this chapter, we discuss an actor-based approach to programming mobile hybrid clouds. Our approach facilitates holistic Assured Cloud Computing (ACC). It is realized in the Illinois Mobile Cloud Manager (IMCM), a prototype mobile hybrid cloud platform. We describe this platform, and then discuss how suitable formalisms can be used to capture interaction patterns to improve the safety and security of computation in the mobile cloud.
The chapter is organized as follows. Section 7.2 outlines the vision of the IMCM framework, and how its use can mitigate current problems in mobile cloud computing (MCC). Section 7.3 gives an overview of the relevant state of the art. Section 7.4 describes the framework's offloading model, architecture, and security policy language in more detail. Section 7.5 covers actor coordination using synchronization constraints. Section 7.6 describes actor session types that can abstractly encode many application constraints. Finally, Section 7.7 discusses future work and concludes.
7.2 Vision
Consider a mobile application that should perform facial recognition of a given image using a database of known faces, of which some must remain confidential. Since this kind of image processing is computationally expensive, tasks should be offloaded to the cloud whenever possible. We assume that application developers would want to deploy this application in a hybrid cloud environment, spanning both a public and a private cloud. Using existing frameworks, engineers would face a number of difficult issues in the development, deployment, and maintenance of such an application:
- Productivity. The application may have to be decomposed in specific ways to enable fine-grained code offloading, and the decomposition may be different depending on the deployment scenario. Developers may have to translate high-level application requirements into executable imperative code. To programmatically access sensor data, knowledge of low-level interfaces may be required.
- Security and Privacy. To achieve requirements on security and privacy, developers may have to use specific knowledge about the deployment environment, for example, whether a specific offloading task is sent to a certain public cloud. Developers may also need to add security checks at specific places in the application code, for example, where a photo that should remain confidential is accessed.
- Maintainability. The application may have to be rearchitected and redeployed because of small changes in the environment, for example, if the cloud provider changes or the average network latency increases. When application requirements on energy consumption and availability change, developers may have to manually adjust parameters inside imperative code.
We address these issues by programming applications using the actor model. The approach does not commit developers to a specific computation offloading policy; the granularity of actor components can be adapted for offloading efficiency. When requirements are encoded as declarative constraints enforced by the framework, application evolution becomes less involved and prone to failures; developers no longer carry the burden of inserting code for checking security policy conformance. The framework also hides low-level sensor interfaces. In addition, programmers need not write any logic for deciding when it is beneficial (with respect to energy consumption, latency, etc.) to offload actors into the cloud. Instead, using information about runtime variables such as energy requirements for a service, communication bandwidth and latency, and available energy on a device, as well as applicable policies, a middleware framework can make offloading decisions on-the-fly.
We realize this approach in the IMCM framework. Figure 7.1 illustrates the application scenario at a high level. The image application runs on one or more mobile devices that may offload certain actors to either a private or a public cloud. Meanwhile, the framework runtime performs monitoring of devices and can provide the data to determine when it is appropriate to perform offloading.
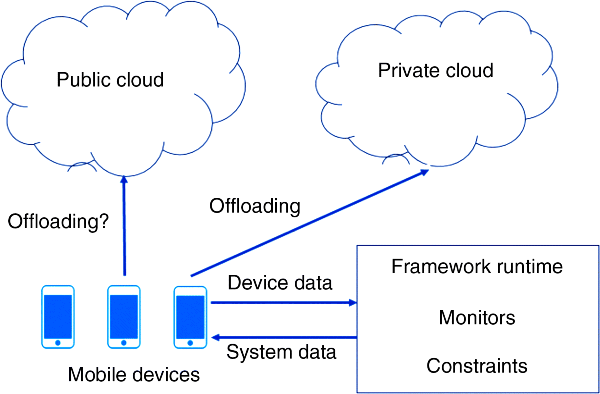
Figure 7.1 Application scenario using the IMCM framework.
Actors also isolate state, allowing information flow boundaries to be mediated through message-passing interfaces. These interfaces allow us to observe and enforce interaction patterns, thus forcing actors to conform to protocols. We express the requirements of a protocol as constraints in the form of coordination constraints between actors, or as multiparty session types. We describe in the following section how such constraints may be used to improve assurance in the mobile cloud.
7.3 State of the Art
Before delving into the details of the IMCM framework, coordination constraints, and session types, we first review state-of-the-art work in these three domains so as to set the context for understanding the contributions of our work.
7.3.1 Code Offloading
In recent years, offloading of computations between mobile devices and the cloud has been proposed to address the limitations of mobile platforms. For example, Kumar et al. [1] discuss program partitioning to support offloading, while Rahman et al. [6] suggest using virtual machine migration. In mobile cloud computing systems using the former approach, the application developer manually partitions a program and then specifies how to offload parts of an application to remote servers. In MCC systems using the latter approach, the entire process or entire OS is moved to a cloud space [7]. However, program partitioning requires substantial developer effort, while VM migration can be prohibitively inefficient [8].
An alternative is to provide automatic data-partitioning solutions for fine-grained, energy-aware offloading of computations. Mobile cloud systems such as MAUI [9] use a combination of virtual machine migration and automatic code partitioning to decide at runtime which methods of an object's code should be executed remotely. The goal of MAUI is to minimize energy consumption on mobile devices by offloading computations. However, MAUI has several limitations. First, it only supports sequential execution: The object in a mobile device is paused while it awaits the results from offloaded code. Second, MAUI only supports a single remote server and requires manual annotation of methods by the programmer and offline static analysis of the source code before execution. Other systems for offloading computations include CloneCloud [10], ThinkAir [11], and COS [8]. Each of these systems has its own limitations. For a good review, we refer interested readers to Ref. [12].
IMCM supports a concurrent application model, enabling simultaneous execution on both mobile device and multiple remote cloud resources.
7.3.2 Coordination Constraints
Actors are autonomous and decentralized, so they must explicitly synchronize when they need to coordinate their actions. A number of frameworks have been developed to simplify the expression of coordination. We review some of the important frameworks. A hierarchical model of coordination was defined in Ref. [13]. In the Directors coordination model, actors are organized into trees. Messages sent between two actors (say A and B) that need to be coordinated are delivered through the closest common ancestor: They are forwarded to a parent node (representing a director), which forward it to its parent, and so on, until a common ancestor of A and B is reached. Then the message is sent down to subdirectors until it reaches the target. This enables enforcement of hierarchical policies. Directors do not support arbitrarily overlapping constraints. Furthermore, the model does not provide semantics for dynamic reconfiguration; actors are inserted into the tree when they are constructed.
Another approach is to use computational reflection and meta-programming. An actor's mail queue buffers messages when they arrive and dispatches them to the actor. The mail queue can be programmed to reject or reorder messages, thus enforcing constraints on acceptable ordering of messages. Similarly, messages are sent to other actors through a dispatcher. The dispatcher can also be customized to reorder messages, or to communicate with a mail queue before sending a message in order to synchronize the state. In this framework, an actor's mail queue and dispatcher are considered separate actors. Astley and Agha [14] and Sturman [15] propose using actor systems with meta-actors, which require a two-level semantics. Such a semantic formalization has been developed in Refs [16,17].
In the Actor-Role-Coordinator (ARC) model [18], coordination is transparent to base-level actors; coordination tasks are divided into intrarole and interrole communication. While this hierarchical design provides load balancing for highly dynamic systems, the coordination structure itself is static. ARC systems therefore avoid security issues through reconfiguration, but require a restart to adapt to changing specifications.
A scalable coordination model must be able to cope with uncooperative actors. We discuss scoping of synchronization constraints to handle scenarios such as permanent locking of a target actor because of a malicious or buggy actor.
7.3.3 Session Types
Interaction types, used to capture communication protocols among parallel processes, were first introduced in the context of the π-calculus [19] by Honda [20]. Targeting two-party interactions, Honda's system could statically ensure that the participants have compatible behavior, by requiring dual types; that is, behaviors in which each participant expects precisely the message sequence that the other participant sends and vice versa.
Many real-world protocols involve more than two participants, which makes their description in terms of multiple two-party sessions unnatural. The Web Services Choreography Description Language [21] is an XML-based language that allows the description – from a global perspective – of protocols that involve multiple concurrent entities (Web services and clients). The notion of an end-point projection of such a global specification was first studied by Carbone et al. [22], along with the associated correctness requirements. The idea was further studied by Honda et al. [23], whose session types support multiple participants: A global type specifies the interactions among all participants from a global perspective, and a projection algorithm then mechanically derives the behavior specification of each individual participant, that is, its local type. A subtyping relation for Honda's system was first studied by Gay and Hole [24], who dealt with recursive types through an unfold function. Their system treats the substitutability concept in a syntactic manner, making subtyping statically decidable.
Asynchronous session types were first studied by Gay and Vasconcelos [25], who proposed session types for an asynchronous flavor of the π-calculus. Parameters were introduced to session types by Yoshida et al. [26], enabling type-safe interactions among a fixed, but not statically known, number of participants.
Castagna et al. [27] proposed a specification language for global types that is closer to regular expressions; they investigated the requirements for correctness after projection, and guarantee certain liveness properties. Their work was the starting point for the full version of the material in Section 7.6, by Charalambides et al. [4,28]. The theoretical foundations of runtime monitoring of protocols with assertions were laid by Bocchi et al. [29], who studied the conditions under which localized, end-point runtime checks suffice to enforce globally specified assertions. In a similar manner, Neykova et al. [30] extended Scribble [31] with timing constraints, and studied the conditions that enable purely local, end-point runtime monitoring of distributed systems with real-time constraints.
Conventional session types are not suitable for typing interactions in actors, so we discuss a programming language and session type system that capture the inherent asynchrony of actor programs.
7.4 Code Offloading and the IMCM Framework
The first widespread use of computation offloading was in the context of cluster and grid computing. By migrating processes between different nodes in a computing network, it was possible to improve performance through load balancing [32]. Another impetus for cloud computing is the offloading of computations – both data and code – in order to support elasticity of resources. Moving computations onto the cloud was facilitated by virtualization technology; this allowed cloud vendors to run different applications from many customers at the same time.
IMCM, the framework we have developed, improves application performance by using information from the dynamic runtime environment, the end-user context, and the application's behavior. Overcoming the limitations of earlier systems, IMCM supports a concurrent application model that facilitates offloading of computations to multiple remote locations and simultaneous execution on both mobile devices and remote cloud resources.
Mobile cloud systems are constrained because of a number of factors, such as limited energy, communication bandwidth, latency, processor speed, and the memory available on mobile devices. However, energy is particularly interesting, since estimation of energy use by an application and its components is complicated; many applications may be running on a device. Research in our group has shown that the energy consumption of the individual components of an application can be estimated using application-related logs and regression [33]. An interesting alternative approach is to use crowd-sourced measurements of system state parameters such as CPU usage or battery voltage to build a model of energy use – an approach taken by CARAT [34].
7.4.1 IMCM Framework: Overview
Many organizations, developers, and users benefiting from cloud resources have privacy requirements, expectations, and policies in terms of how different private or public cloud resources can be used by a mobile application. Without having enough flexibility in the offloading framework to address these requirements, many users will not be able to benefit from the cloud resources. In order to accommodate these requirements, we describe a language to define policies, and explain how the IMCM framework can be customized to address them.
While addressing these policies is critical, other quantitative properties, such as performance and energy characteristics on the mobile device, greatly affect the quality of an application in meeting overall user requirements. The framework allows for configuration of policies that need to be enforced, but such policies may affect the performance and energy usage of the application. On the other hand, it may be possible to leverage optimized performance and energy to provide stronger privacy guarantees. Through the framework, we discuss mechanisms that allow developers or users to control all privacy, performance, and energy aspects of their applications via code offloading.
7.4.2 Cloud Application and Infrastructure Models
In order to formulate the application component offloading problem, a comprehensive mobile-hybrid-cloud application model is needed. This section summarizes our views on clouds, cloud applications, and mobile-cloud applications.
Over time, cloud services have moved from the model of public cloud spaces to private clouds and, recently, to a hybrid model combining both [35]. Cloud infrastructure has traditionally been provided by large third-party organizations, and thus has been referred to as the public cloud. However, storing data on third-party machines suffers from a potential lack of control and transparency in addition to having legal implications [36]. In order to address this problem, cryptographic methods are usually used to encrypt the data stored in public clouds, while decryption keys are disclosed only to authorized users. However, those solutions inevitably introduce heavy computational overhead for continuous encryption and decryption of data, distribution of decryption keys to authorized users, and management of data when fine-grained data access control is desired. Thus, cryptographic methods do not scale well, have significant overhead, are expensive to maintain, and are often slow, especially in widely geographically distributed environments such as clouds.
To address some of those limitations, several techniques, such as attribute-based encryption (ABE), proxy re-encryption and lazy re-encryption, and homomorphic encryption techniques, have been developed to provide attribute-based encryption while delegating part of the required decryption to the cloud or providing limited in-cloud computations on the ciphered text (encrypted data) without revealing data content. However, these efforts have had the traditional data-centric view of cloud computing, focused on storing data and providing services to access the stored data. If data storage is the primary use for the cloud, the required data access control is already mature enough that a fine-grained access control system can be implemented effectively.
However, in modern cloud applications, the resources stored in the cloud contain more than just data. These resources contain part of the application code that results in access operations for execution of the code inside the cloud. It is obvious that the certificate-based authorization systems fail to address these types of applications, as an encrypted piece of code within the cloud cannot be executed without decryption, thus revealing the content to the cloud provider. As a result, companies have gradually moved toward building their own private clouds [36]. Storing sensitive data within private clouds aligns with the traditional on-premises application deployment model whereby sensitive data reside within the enterprise boundary and are subject to its physical, logical, and personnel security and access control policies [35]. However, owning and maintaining a private cloud is usually not as efficient, scalable, reliable, or elastic as using one of the public ones that are offered, supported, and maintained by large third-party companies.
In recent years, a combination of both private and public cloud spaces has been used that allows users to benefit from all the advantages of the public cloud while keeping their confidential or sensitive data and algorithms in-house [37]. In order to cover different applications, our framework simply views the cloud as the most general form that combines one or multiple private and public cloud spaces. This allows the creation of a general, flexible, elastic hybrid cloud space to address the different needs of a specific organization while different users (including both internal staff and external clients) can access cloud resources with different access levels and limitations.
7.4.3 Cloud Application Model
Although the benefits of cloud computing for enterprise consumers and service providers have been thoroughly explored over the past few years, its effect on end users, applications, and application developers is still not clear. As mentioned in the previous section, the traditional data-centric view of cloud services needs to be replaced with a more general data/computation-centric view. To achieve that transition, the current common client-server-based, service-oriented architecture [38], which provides services on data stored in the cloud to external users, needs to be replaced with a more general, elastic architecture that dynamically and transparently leverages cloud resources to provide services and support resource limitations on the end user. In such an elastic application development environment, components that store data or perform computations are transparently scattered among the private clouds, public clouds, and end-user devices. When such an application is launched, an elasticity manager monitors the execution environment and resource requirements of the application to make decisions about where components should be launched and when they should migrate from device to cloud, or from cloud to device, according to changes in user preferences. Rather than a simple and rigid solution wherein nearly all processing and storage are either on the device or in the cloud, an elastic mechanism should have the ability to migrate functionality between the device and the cloud. This ability would allow the device to adapt to different workloads, performance goals, and network latencies.
An important design objective of this modern application development approach is to build an infrastructure with enabling functions such as network protocols, secure communication, and resource management, so that the new elastic computing model will introduce minimal extra considerations for application developers. Unnecessary details of distribution and move-around of application components should be masked from the programmers, while access to different components and resources is still restricted for different users. Elastic components need to access sensitive or restricted resources, and thus an authorization system is needed to give the required component access privileges. For access control, elastic application components on the cloud should adhere to the property of least privileges. Which permissions a component might have may depend on its execution location. Implicit access to device resources may require additional scrutiny when the component is no longer running local to the device.
End users interact with that elastic architecture system by using their mobile devices. That inevitably requires us to address the problem of minimizing energy usage on the mobile device (as detailed in Section 7.4.8) to support complex applications. In order to do so, we need to be able to attribute energy consumption to components of an application. The actor model lends itself naturally to defining the granularity for energy monitoring at the level of individual or groups of actors. We leverage it as the application programming model for the IMCM framework. Actors can be the primitive units for targeting energy measurements, while groupings of actors of a particular type can be considered for aggregations/higher level metrics like average energy consumption. Schedulers for actor-based languages also view actors as basic computational entities for scheduling decisions, so the underlying runtime can be instrumented to track actors running at different time intervals.
As a result, our view of a mobile-cloud application consists of actors distributed across local mobile devices and different cloud spaces.
7.4.4 Defining Privacy for Mobile Hybrid Cloud Applications
We want to enable developers and users to restrict access to different resources, and enable the mobility of a sensitive or confidential application component's resources, based on required policies. This requires the framework to follow authorization rules defined by the organizations, developers, or users. Elastic application components on the cloud should adhere to the property of least privileges. Which permissions a component should have may depend on its execution location, application requirements, or user concerns. Implicit access to device resources may require additional scrutiny when the component is no longer running local to the device [39]. A comprehensive security solution requires authentication, access control, and auditing. There has been a significant amount of work on authentication and auditing for cloud applications in the past, and the existing solutions are mature enough to address most applications [39–43]. Therefore, we focus on an approach for adding policy-based privacy to our framework that restricts the accesses, actions, and mobility of components.
Before we delve into the details of the authorization system and its language, policy description, and evaluation rules, we describe in detail the image recognition application that was first introduced in Section 7.2 as an example to demonstrate the usage of the privacy-related capabilities of our system.
7.4.5 A Face Recognition Application
An image-processing application, called Image, recognizes faces in a given image by using a database of known faces. Figure 7.2 shows a summary of different modules involved in the Image application.

Figure 7.2 Modules involved in the Image image-processing application.
In order to respect the privacy of the clients and prevent potential vulnerabilities in storing private data on third-party machines, the owner organization breaks down the database of all known faces into two main categories: (i) faces that are publicly known, such that the data contain no sensitive or confidential information and can be stored on public cloud space; and (ii) facial data that contain sensitive or confidential information and should never be placed on third-party machines, even if encrypted. In order to make this more interesting, different subcategories are also considered for each main category. Let us assume that the goal is to recognize people entering the country at an airport through image-processing of photos taken by security officers at the airport. Based on this scenario, the two main subcategories for the database of known faces would include (i) known criminals whose faces have been publicly announced, and (ii) normal people/citizens whose faces should not be stored on any third-party machines. Furthermore, faces of known criminals might be divided into international criminals and national criminals. Similarly, faces of “normal” people might be divided into citizens, permanent residents, and visa holders. Figure 7.3 shows how these databases would be stored in different public and private cloud spaces.

Figure 7.3 Organization of databases within private and public cloud spaces for Image application.
In the figure, DB1 stores faces of citizens, DB2 stores faces of permanent residents, DB3 stores faces of visa holders, DB4 stores faces of international criminals, and DB5 stores faces of national criminals. The image-processing application makes it possible to compare a photo taken with a phone to these databases and thereby identify the person in the photo. The main design goal of developing an authorization policy for this application is to keep confidential data away from unauthorized users and provide different levels of restrictions for different types of users, ranging from security officers (who have access to all databases) to normal airport staff (who should only be able to recognize criminals). In the next section, we use this privacy-sensitive application to demonstrate the policies that can be defined using our framework.
7.4.6 The Design of an Authorization System
Since we want to provide fine-grained authorization systems for application components, we have adopted a hierarchical approach whereby organizations can enforce an organization-wide policy, while developers and end users can fine-tune it. An organization is the primary owner of the data and resources and must be able to keep private and public cloud components separate from each other and define an overall policy in terms of resource usage for different users or different applications. Specific applications may also need to further tighten those organization-wide policy rules. End users or programmers must also be able to further restrict resource usage and component distributions for specific applications. As a result, our framework supports two types of policies: hard policies and soft policies.
Hard policies are organization-wide authorization rules defined per user or application by the organization. Users include different developers inside the organization in addition to external clients. On the other hand, soft policies are application-specific authorization rules defined in addition to the organization-wide hard policy. Despite the fact that these two types of policies have complementary roles in increasing system flexibility, a soft policy can only tighten the organization-wide policy and not vice versa. In other words, if the organization-wide hard policy allows a specific user or a specific application to access resources A and B, a soft policy can only further restrict the access to one of the resources A or B; it can never loosen the restrictions by allowing access to a new resource such as C. Separating the restriction policy definition from the application logic in this way allows organizations to define their hard policies without programmers' having to worry about compromising the predefined organization-wide policy.
Each application instance initially authenticates itself with a Policy Manager Machine (PMM) and receives a locked unchangeable hard policy that contains the organization-wide authorization rules defined by the organization. Each organization can define its authorization policy as one policy for all users, one policy for all applications, one policy per application, one policy per user, or one policy per application instance. In the end, each application instance can acquire one locked hard policy from the policy manager machine. In addition, each application instance can have one soft policy. Developers can define the initial soft policy per application or per application instance. They can also allow end users to change all or part of this soft policy through the application. To implement these rules, we follow the XACML usage model [44] and assume a Policy Enforcement Point (PEP) as part of our elasticity manager. The PEP is responsible for protecting authorization rules by sending a request that contains a description of the attempted action to a Policy Decision Point (PDP) for evaluation against available hard and soft policies. The PDP evaluates the requested action and returns an authorization decision for the PEP to enforce.
Our authorization framework needs to be able to apply the restriction rules at the granularity of actors. It still allows those rules to be defined at higher level entities, such as groups or sets of actors, but it recursively propagates all those specified authorizations (permissions or denials) to all actors contained within a set at runtime. This makes it easy to specify authorizations that hold for a larger set of actors (on the whole system, if “all” is used) and have them propagated to all the actors within that set until stopped by an explicit conflicting restriction rule [45]. Actor frameworks allow multiple actors to be placed together in a container, called the actor system or theater, to share common attributes. We respect this structuring in our language and allow authorization rules to be defined on actors, actor systems, sets of actors (each called a Group), a set of actor systems (called a Location), or a subset of multiple actors and actor systems (called a Selection).
While access control models restrict access to different components or resources, our mobile hybrid cloud framework provides more than access restriction. The actor programming paradigm allows an actor to send and receive messages, create new actors, or migrate to new locations. As a result, our authorization grammar must allow for definition of rules regulating all those actions. Note that these actions are usually bidirectional, meaning that if Actor 1 is allowed to send to Actor 2, then Actor 2 must also be allowed to receive from Actor 1 in order for the policy to be consistent. If either of those two actions is not explicitly allowed as part of the policy, the framework automatically rejects both actions, as they will always happen together.
7.4.7 Mobile Hybrid Cloud Authorization Language
Authorization decisions are made based on the attributes of the requester, the resource, and the requested action, using policy-defined rules. As a result, defining an authorization policy means defining the authorization entities and their required attributes in addition to defining rules and desired rule orderings.
In the cloud application model in which actors are the smallest entities in an application, actors are the finest granularity on which we can define access restriction. In order to provide location transparency, multiple actors running on one runtime instance on one machine are placed inside a container, called an actor system or theater as in SALSA [46]. Our language supports definition of both actors and actor systems. Every actor is defined by its related reference and a logical path to reach the actor in the runtime environment, in addition to its containing actor system. The authorization framework uses these attributes to bind the actors defined in the policy to their real-world application components.
In order for our language to be able to account for the existence and activities of to-be-developed application-specific components (while enabling the writing of organization-wide policies), anonymous types of entities are defined as part of the proposed language grammar. A rule called anonymous-actor allows restriction of the creation and number of unknown actors in a reference-actor system. Similarly, a rule called anonymous-actor system allows control of the creation and the number of unknown actor systems.
The following shows how the above supported entities can be used to define the components of the face recognition example from Section 7.4.5.
{Name: ActorSysUser, Static (URL:98.123.123.456, Port:1979)}The above clause defines an actor system called ActorSysUser that is statically bound to the given IP address and port number.
{Name: UserImageLoader, Static(Reference:actor.tcp://[email protected]/Image-Loader, ActorSystem:ActorSysUser)}The above clause defines an actor called UserImageLoader for the component that loads an image from disk, with the reference providing the logical path to reach the element in the runtime environment. The clause also provides the actor system to which the actor belongs. We can have similar definitions for Face-Detector, Feature-Extractor, and Face-Recognizer.
{Name:AnonymousUser, Ref-ActorSystem:ActorSysUser, Existence:FORBIDDEN}The above clause defines an anonymous actor within the ActorSysUser actor system, to prevent the creation of additional actors within the actor system. The grammar also supports limiting of the maximum number of anonymous actors that can be created within an actor system.
{Name:Other-ActorSys-User, URL:98.123.123.456, Creation:FORBIDDEN}Finally, the above clause defines an anonymous actor system to restrict the creation of unknown actor systems at the given URL. Note that anonymous URLs for dynamic binding can also be created to support arbitrary architecture of to-be-developed applications.
7.4.7.1 Grouping, Selection, and Binding
Although definitions like those in the previous section can be used to define individual actors and actor systems, in many cases it is easier to group several entities and treat them as one. A Group definition puts several actors together into one virtual container and allows placement of both known actors and unknown, anonymous actors together into one group. Similarly, we can have a Location definition to provide the same grouping functionality but for actor systems. One or several previously defined actor systems, locations, or even unknown anonymous actor systems can be placed into one container location entity.
Instead of specifying individual entities to form a container, a Selection definition can be used to pick entities based on a condition. In order to bind previously defined dynamic actors and actor systems to specific runtime components, an Assignment definition can be used. Any remaining unbound dynamic actor or actor system is in a passive state and will be ignored while the policy is being enforced. An Assignment definition can then be used to bind the runtime components to specific actors or actor systems and change their passive state to active at any time.
The following clause utilizes some of the above definitions to define groupings for components of an application:
{Name:FaceActors,Actors:UserFaceDetector,UserFeatureExtractor,UserFaceRecognizer}The above clause defines a group of actors that are used for face-specific processing in an image. This group could be used to restrict the actors to run in private clouds only. Suppose we have previously defined two actor systems (ActorSysPrivate1 and ActorSysPrivate2) that are made of actors restricted to run in a private cloud only. We can group these actor systems into a Location definition, as the next clause shows:
{Name: PrivateActorSystems, ActorSystems:ActorSysPrivate1, ActorSysPrivate2}The next clause is a Set-Operation definition for extracting face-specific processing actors by removing the image loader from the face recognition actor system. Note that other conditions, such as selecting the list of actors with “Face” in the actor name attribute, are also supported.
{Name: FaceActors, Subject (ActorSystems:ActorSysUser), Object(Actors:UserImageLoader), Operator (REMOVE)}7.4.7.2 Policy Description
The main goal of writing a policy file is to define required authorization rules on actions among actors. The previously defined grammar allows one to define entities and group or select them, which are prerequisites for defining restriction rules. We now look at using them to express authorization rules and their evaluation ordering.
Each rule definition regulates one action from subject entities to be performed on object entities. Actions include all allowable actions within an actor framework: sending, receiving, migrating, and creating. This allows one to regulate actions, move-around, and communication between the actor components of a mobile hybrid cloud application.
The following are examples of such rules defined for the face recognition application from Section 7.4.5.
{Name: ActorSystemIsolation-Rule, Subject(ActorSystems:ActorSysUser), Object(ALL), Actions:ALL, Permission:DISALLOWED}The above rule restricts all actions between actors that are in the ActorSysUser actor system and any other actors in the system.
{Name: Actor-Gateway-Rule, Subject(Actors:UserFaceRecognizer), Object(Actors:ActorPublicGate, ActorPrivateGate), Actions:SEND-TO, RECEIVE-FROM, Permission:ALLOWED}The above rule allows the UserFaceRecognizer actor to send/receive messages from public and private gateway actors (assuming that such actors have been defined previously).
{Name: UserFaceRecognizer-Rule-Order, Subject(Rules: Actor-Gateway-Rule), Object(Rules: ActorSystemIsolation-Rule), Order: PRECEDENCE}This is a rule evaluation order definition that allows UserFaceRecognizer to communicate with public/private gateway actors but not with any other actors.
Note that other actions that are supported, such as MIGRATE−TO, CREATE−AT, BE−MIGRATED−FROM, and BE−CREATED−AT−BY, can be used to restrict the creation/migration of private actors (such as the database with faces of known criminals) to public cloud servers in the face-recognition application (from Section 7.4.5).
7.4.7.3 Policy Evaluation
In a mobile hybrid cloud framework with authorization restrictions, every requested action by the subject has to be approved by the authorization framework before being performed on the object. To make a decision, the authorization system has to evaluate the defined policy rules. However, it is possible for different policy rules to contradict each other, as rules are human-defined by different parties, organizations, and developers, at different times, at different levels, and for different purposes. Our framework prioritizes hard policy rules, which are defined at a higher level by the organization, over soft policy rules, which are defined by programmers for individual applications or instances. Prioritizing hard policy restriction rules over soft policy rules resolves any potential conflict between hard and soft policies. In other types of conflicts between rules of the same type, we always prioritize action denials over permissions.
Every authorization rule can be summarized as a five-tuple of the form <Subject, Object, Action, Sign, Type>. Here, Subject and Object are the entities between which the specific action is being restricted. Sign can be allowance (+) or prohibition (−), and Type covers hard policy (H) or soft policy (S). In order to decide on any requested action, the authorization system has to process rules in a meaningful way from the most prioritized one (usually the most specific rule), to the least prioritized one (the most general one).
7.4.8 Performance- and Energy-Usage-Based Code Offloading
In the previous section, we saw the need to support code mobility to enforce policies for the privacy guarantees of an application. The target offloading goals can affect the component distribution plan in a hybrid cloud environment with multiple public and private cloud spaces in addition to fully parallel application execution. So we next examine application performance and energy usage on mobile devices as target offloading goals and create an offloading decision-making model for the same.
As an alternative to the expensive option of full-VM migration (see Section 7.3.1), we propose a code-offloading mechanism that is more selective, intelligently identifying and migrating only those parts of the mobile application that would most benefit from migration to a more powerful computing platform while keeping communication overhead low. This approach masks the details of the migration process from both users and developers, while providing for a natural partitioning of an actor-based mobile application. The key challenge is that of identifying and selecting the groups of application components (actors) that would be most beneficial to offload based on the current state of the mobile platform and the application, the application behavior, and the primary purpose of the offloading (energy or performance optimization).
7.4.8.1 Offloading for Sequential Execution on a Single Server
There can be wide variation in the goals for the offloading, depending on the usage scenario; they may range from maximizing the application performance, for example, in video games and vision-based applications, to minimizing the energy consumption on the mobile device, for example, in background processes. Regardless of the offloading purpose, however, the implementation costs are highly dependent on the remote platform on which the offloaded components are to be executed. Key factors include both the performance of the target platform and the communication properties, such as latency and bandwidth.
The goals for maximizing application performance [1] and minimizing energy use on mobile devices are shown in Equations 7.1 and 7.2, respectively. First, let
 execution time on mobile device
execution time on mobile device duration of data transfer
duration of data transfer execution time on remote server
execution time on remote server
then
Second, let
 energy cost on mobile device
energy cost on mobile device energy cost of data transfer
energy cost of data transfer idle energy cost while waiting for result
idle energy cost while waiting for result
then
These equations lead naturally to the pause-offload-resume model [9], which results in sequential execution. For this reason, using CloneCloud [10] or ThinkAir [11] ostensibly to enable opportunistic parallelism results in sequential execution in practice. Furthermore, such models only have to consider a single remote location for offloading. We consider parallelism wherein multiple remote servers work concurrently with mobile devices.
Expanding Equations 7.1 and 7.2, we observed that they are structurally similar and usually result in close decisions, if power consumption on mobile devices for computation, transfer of data to remote servers, and waiting in idle mode are all proportional. That is the case for sequential execution and is the result of assuming that the mobile screen will be on, even in the idle state [9–11].
7.4.8.2 Offloading for Parallel Execution on Hybrid Clouds
Deciding on an optimized offloading plan for parallel applications in a hybrid cloud environment requires consideration of the application type, the available resources at different remote machines, and the effects of offloading on future application behavior.
7.4.8.3 Maximizing Performance
Fully parallel execution refers to both parallel execution on multiple remote locations and simultaneous local and remote execution. As a result, the total application execution time is the maximum time required for any of the mobile or remote spaces to finish executing program code for all of its assigned components. Since local communication between components located on the same machine is relatively fast, we can ignore local communication and only consider communications between components placed at different locations. The offloading goal can be summarized as maximizing application performance (![]() ) or minimizing application execution time (
) or minimizing application execution time (![]() ) using:
) using:

A mobile application consists of ![]() components, and each component
components, and each component ![]() is located at
is located at ![]() at time t. Having M different cloud spaces results in
at time t. Having M different cloud spaces results in ![]() where 0 represents the local mobile device and
where 0 represents the local mobile device and ![]() corresponds to different cloud spaces. Assuming that we know the application component distribution between the local mobile device and the hybrid cloud spaces at time
corresponds to different cloud spaces. Assuming that we know the application component distribution between the local mobile device and the hybrid cloud spaces at time ![]() , our goal is to find the component distribution for the next time interval
, our goal is to find the component distribution for the next time interval ![]() such that application performance is maximized.
such that application performance is maximized.
Thus, different parts of Equation 7.3 can be extended so that the first term ![]() captures the maximum (across
captures the maximum (across ![]() different cloud spaces) execution time for all components on each of those locations
different cloud spaces) execution time for all components on each of those locations ![]() . This maximum can be obtained using monitoring and previous profiling for the execution time of each component in its location at time
. This maximum can be obtained using monitoring and previous profiling for the execution time of each component in its location at time ![]() .
.
Similarly, the second term ![]() of Equation 7.3 captures the maximum required time for one of the locations to send out all its communications. This maximum can be obtained using the profiled amount of communication between the members of each pair of components during the elasticity manager's running time interval
of Equation 7.3 captures the maximum required time for one of the locations to send out all its communications. This maximum can be obtained using the profiled amount of communication between the members of each pair of components during the elasticity manager's running time interval ![]() and the location of components across locations in time
and the location of components across locations in time ![]() .
.
However, not all components of an application are offloadable, so a few constraints must be added to the above optimization problem. As we are considering a hybrid cloud that consists of multiple private and public cloud spaces, application developers or users can specify additional constraints in terms of how different components can be offloaded to different locations. These additional constraints can also address privacy issues in terms of not offloading sensitive or confidential components to public cloud spaces.
7.4.8.4 Minimizing Energy Consumption
Let us now examine the differences in terms of minimizing mobile device energy consumption instead of performance. This goal can be defined as below. Let
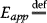 application mobile energy consumption
application mobile energy consumption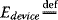 energy saved on mobile device
energy saved on mobile device total mobile energy saving by remote component execution
total mobile energy saving by remote component execution energy loss because local communication became remote communication
energy loss because local communication became remote communication energy saved because remote communication became local communication
energy saved because remote communication became local communication
then
![]() in Equation 7.4 can be further elaborated into
in Equation 7.4 can be further elaborated into
where Energy(i) is the profiled energy consumption of component ![]() as it runs locally on the mobile device during the time interval Δ, and
as it runs locally on the mobile device during the time interval Δ, and ![]() returns 1 if two given locations are identical and 0 otherwise. Note that the first term of the equation considers only components that are currently on the device, and the second term adds the condition that those elements must now be at a remote location. Thus, energy savings are counted only for components that have been migrated from the local device to a remote location. It should be noted again that our goal is to minimize energy consumption at the mobile device and not the total energy. The migration of components between remote locations does not help with that goal and therefore is not considered in the equation.
returns 1 if two given locations are identical and 0 otherwise. Note that the first term of the equation considers only components that are currently on the device, and the second term adds the condition that those elements must now be at a remote location. Thus, energy savings are counted only for components that have been migrated from the local device to a remote location. It should be noted again that our goal is to minimize energy consumption at the mobile device and not the total energy. The migration of components between remote locations does not help with that goal and therefore is not considered in the equation.
![]() and
and ![]() in Equation 7.4 are obtained using the profiled amount of communication between each pair of components and the profiled mobile power during communication with remote servers.
in Equation 7.4 are obtained using the profiled amount of communication between each pair of components and the profiled mobile power during communication with remote servers.
To maximize performance, we can add constraints, for example, that offloading of components to remote locations to save local energy must not affect the performance of the application. In other words, we can specify that energy savings are allowed only as long as a certain level of service performance is maintained. An important observation we made in our fully parallel application model is that the results of our offloading goals are very different for application performance improvement and for energy savings on mobile devices. This is unlike the sequential case in which the models lead to similar configuration results. Therefore, we use the constraints to add restrictions on how much improvement in support of one goal is allowed to negatively affect the other.
7.4.8.5 Energy Monitoring
The difficulty in solving Equation 7.5 arises from Energy(i). As mentioned, Energy(i) is the profiled energy consumption of component i while it is running locally on the mobile device. Evaluating this term requires fine-grained profiling of energy consumption per application component on a mobile device. However, most mobile devices do not provide any tool for direct measurement of the consumed energy. Almost all previous research in this area has relied on external power meters to measure energy consumption. Although use of expensive external power meters works for an experimental setting, we cannot expect end users to carry such devices with themselves to profile the energy consumption of their mobile devices. This is a big challenge in optimizing energy consumption of mobile hybrid cloud applications. Even if the total energy consumption of the mobile device can be measured, there are multiple applications running on a mobile device at any one time. That requires distribution of the total measured energy among those applications. Furthermore, multiple components within our target application are running at any given time, and distributing energy among these components is a challenge. The solution we explore here can scalably profile runtime energy consumption of an application, while treating it as a black box. This approach can detect complex interactions and dependencies between components or actors in an application that affect energy consumption on mobile devices.
We consider mobile applications written using the actor-model-based programming language SALSA [46], which natively supports migration of actors between mobile and cloud platforms. We built the mechanism to profile running applications from an underlying SALSA runtime layer in order to enable attribution of battery drops to subsets of actor types. The mechanism first instruments the SALSA runtime to enable determination of which actors are scheduled in the application at each (predefined) interval of time. Based on the corresponding battery drops in those intervals, a combination of linear regression and hypothesis testing techniques is used to infer battery drop distribution of subsets of actor groups within an execution context.
Note that different subsets of actors would be active in each interval, so if we observed these data for an application from a large number of smartphones, it would then be possible to collect measurements that would help us generate a distribution of battery drop characteristics for different actor types with increasing accuracy. Apart from speeding up the availability of battery drops for subsets of actor types, this crowdsourcing-based approach could handle noise in the sensor readings. We would have to partition the data by execution context, however, which includes hardware context, such as the screen or GPS's being turned on or off, along with software context, such as other applications running on the device. The additional data available would then also have to be used to handle large variability of the context in which different application instances are running, before energy attribution can be done. We leave this crowdsourcing-based monitoring approach as an extension for future work.
7.4.8.6 Security Policies and Energy Monitoring
One use case of the IMCM infrastructure is an authorization system that respects a specified energy policy. Such a policy is enforced through runtime restrictions on the actors that are executing on a mobile cloud platform. Some examples of policies that can be specified include the following:
- Policies that prevent malicious actors from draining batteries on mobile devices to prevent secure actors from carrying out their tasks.
- Energy-consumption-based policies to restrict sending or receiving of messages from abusive actors, and to manage DoS attacks by enforcing maximum-energy-threshold-based restrictions on actor creation within a container.
- Organization-wide policies for abusive actors (based on energy characteristics) as the actor signature. This is useful when runtime actor information is unavailable when such policies are being written.
- Track the energy consumption of an actor over time, in order to detect any large deviations in energy characteristics that may occur because the actor has been compromised.
7.5 Coordinating Actors
Applications on the mobile cloud involve a large amount of concurrent activity. As we described in the last section, dividing a computation into actors isolates its state, enabling security while facilitating parallelism, distribution, and mobility. However, because actors are autonomous and decentralized, not globally controlled, they must explicitly synchronize when they need to coordinate their actions. For example, such synchronization is needed if an action by one actor must precede an action by another.
Synchronization between actors follows a message-passing semantics: When an actor sends a message to another actor, the events leading up to the first message send precede the events that happen after the message has been received. For example, consider a deposit into one bank account that requires a withdrawal from another bank account. These actions must be atomic. One way to implement the atomicity is to require the two actors to explicitly exchange a sequence of messages that implement a two-phase commit protocol.
Synchronization protocols can grow complicated. For example, atomicity may be realized using a two-phase commit protocol, or it may be implemented using a three-phase commit to guard against failure of one of the participants. The atomicity protocol may be optimistic (and undo actions if there is a violation of atomicity), or it may be conservative. Expressing complex protocols via message-passing leads to complex code. Such complexity can introduce software bugs, thus compromising safety, and also make it difficult to monitor a system in order to detect anomalies in the interaction patterns. Moreover, because the same high-level synchronization policy may be implemented using different protocols, the policy may be buried in the code. This means that one has to reason about the code to understand the policy.
7.5.1 Expressing Coordination
A number of methods have been developed to express coordination between actors separately from the functional behavior of an actor. Observe that coordination policies affect the behavior of participant actors locally. Thus, multiple policies can be specified separately and enforced. However, such policies could interfere with each other. Moreover, policies must be enforced by trusted actors and implemented through mediation of the messages between actors, so formal methods are required to support reasoning about coordination.
7.5.1.1 Synchronizers
The oldest framework for declarative expression of coordination behavior is synchronizers [3]. A synchronizer is a collection of constraints that enforce an ordering between messages processed by different actors that belong to some interacting group. Such groups may overlap, as an actor may participate in different activities with different groups of actors. When a message does not meet the constraints required for it to be processable, message dispatch is delayed until the state of the system changes (because other messages are processed) and the constraints governing the blocked message are satisfied. Synchronizers are implemented through creation of the appropriate meta-actors, and this process can be automated.
Two types of constraints that provide generality are disabling constraints and atomicity constraints. Disabling constraints prevent an actor from handling messages that match a given pattern. For example, if all types of messages except an initialization message are disabled, the actor must first receive an initialize message before it processes other messages. Atomicity constraints implement atomic processing of messages by different actors, as in the example discussed earlier.
Programmers declare synchronizers as templates. Similar to classes or actor behaviors, these templates are dynamically instantiated at runtime with concrete values filled in for the parameters. Consequently, synchronizers can have local state that changes with the observed messages. They may also overlap, that is, multiple synchronizers can constrain the same actor. Figure 7.4 shows the effects of a possible synchronizer.

Figure 7.4 Constraints enforced by synchronizers. Synchronizers (dashed ovals) support combinations of atomicity and disabling constraints. Atomicity constraints ensure that a set of messages is dispatched as a whole and without causally intervening events. Messages m_atomic1 and m_atomic2 satisfy the atomicity constraint together and are therefore dispatched together by their synchronizer at the respective target actors. Message m_block matches a disabling pattern in the other (lower) synchronizer and therefore cannot be dispatched. Message m_pass matches no pattern and thus is unconstrained.
Consider a sliding window protocol. The protocol prevents a sender from sending more than a specified number of messages at a time. More messages can be sent only after some of the messages sent have been processed. The protocol can prevent denial of service attacks. It is straightforward to express such a protocol using a synchronizer.
In the code below (Figure 7.5), no more than a given number of messages – as determined by the parameter size (representing the size of a “window”) – from a specified sender to a specified receiver may be pending at any one time. Each time one message within the window is processed, the number of acknowledged messages is updated, permitting another message to be sent.

Figure 7.5 Sliding window synchronization constraint.
7.5.1.2 Security Issues in Synchronizers
As systems are continually evolving, synchronizers may be dynamically added or removed. As systems scale, the chance that some actor will be compromised or be malicious increases. A scalable coordination model must be able to cope with uncooperative actors and gracefully degrade in the presence of failures. It must also guard its reconfiguration mechanisms against abuse. Installation of a synchronizer can lead an actor to wait for a message that never arrives, leading to failure. For example, suppose that an actor A can handle messages of types message1, message2, and so on, up to messageN. A malicious actor M can prevent A from receiving any further messages by installing a synchronizer, as shown in Figure 7.6, that disables all message handlers in A.

Figure 7.6 Disabling attack.
To address the problem, we need synchronization constraints to be scoped. A suitable scoping mechanism was introduced in Ref. [47], and the discussion in the rest of this section follows that work. The idea is to restrict the ability of a synchronization constraint to be able to limit messages only if they are coming from actors within a scope. This scoping rule means that messages from outside the scope of a synchronizer can still be received by a target actor, thus preventing the target actor from being permanently locked by a malicious or buggy actor that fails to follow the agreed-upon interaction protocol.
Synchronization constraints are complementary to object capabilities [48]. Object-capability security is a natural model of security in actor systems. An actor's address works like a capability: One cannot send a message to an actor without knowing its address, and these addresses can be guessed. If the address of an actor a0 is provided to an actor a1, the recipient a1 is provided with the capability to send a0 a message. This provides a level of security: By carefully restricting the distribution of addresses, one can prevent malicious or buggy actors from affecting the behavior of actors with which they should not be able to interact.
In contrast, synchronization capabilities determine the scope of synchronization constraints: They provide actors with the capability to join an interaction and be restrained to follow the synchronizer's constraints. Figure 7.7 shows the scoping effects of synchronization capabilities.

Figure 7.7 Scoped synchronizers enforcing constraints. Scoped synchronizers (dashed boxes) constrain only messages sent by actors for which they hold the synchronization capability. These actors are shaded in dark gray in the diagram. Their sent messages must satisfy the constraints before they can be dispatched at the recipients (shown in light gray). Since message m_block matches a disabling pattern of the inner synchronizer, it cannot be dispatched. However, the respective synchronizer lacks control over the sender message m_pass, so m_pass can be dispatched despite having the same shape as m_block.
As with object capabilities, we assume that synchronization capabilities are unique across the system and cannot be guessed. The distribution of synchronization is similar to that of actor addresses: Actors obtain synchronization capabilities through initialization and introduction by an actor that has the capability. However, synchronization capabilities are “inherited” from the creator: When a new actor is created, it is subject to the same synchronization rules as its creator. This prevents an actor from escaping its synchronization constraints by simply creating a new actor that circumvents the constraints on its messages.
Synchronization capabilities can prevent a buggy or malicious actor from intentionally creating a deadlock through installation of a synchronizer. In the DisablingAttack synchronizer from Figure 7.6, scoping the synchronization constraint results in behavior similar to that of the lower right actor in Figure 7.7: If the synchronizers do not have a synchronization capability that affects an actor's messages, these messages will pass through. Moreover, accidental interference of constraints also becomes less likely [47].
When a message is dispatched, all synchronizers that belong to matching update patterns receive information about the event. For example, consider cooperating resource administrators that share a limited number of resources. When a resource is released by one administrator, it enables another administrator to service requests that require the resource. Synchronizers that are not constraining the sender of a message (and thus that type of message) may still need to receive information about the dispatch of a message by an actor whose other messages are being constrained. It needs that information in order to have a correct view of the state of the target actor, since it needs the information to be able to receive a specific type of message (that may need to be constrained). Although a visible message dispatch provides a consistent view of the system, it can enable malicious actors to spy on other actors, as shown in Figure 7.8. This security issue remains an open problem.

Figure 7.8 Information leak through updates. Scoping only limits the constraining power of synchronizers. To guarantee a consistent view on the system, synchronizers can observe all messages that an actor dispatches, regardless of the synchronization capabilities the synchronizer holds. An attacker actor exploits this fact to gather information about the target actor. First, the attacker creates a trampoline actor and installs a synchronizer on the target and the trampoline. The synchronizer disables the dispatch of message m_block at the trampoline until it observes message m_pass at the target. Then, the attacker sends message m_block to the trampoline. Once the trampoline has dispatched m_block, it bounces a message back to the attacker, providing the attacker with the knowledge that the target has dispatched message m_pass.
7.6 Session Types
One way to reason about the constraints discussed above is in terms of the interface of the actors involved in an interaction. An interface is expressed in terms of abstract data types in programming languages. For example, the type of a bounded buffer is the operations the buffer accepts: put, get, full? and empty?. In sequential languages, such types do not account for when an operation may take place. For example, a bounded buffer may not perform a put when it is full, and the buffer may not perform a get when it is empty. The programmer must explicitly check whether the buffer is full or empty before performing a put or get operation, respectively. Such a check does not help us in a concurrent system; while one actor checks (by sending a message) whether the buffer is full, another actor may perform a put that changes the state to full.
Synchronizers provide a high-level specification of interaction protocols. They are related to the evolution of types based on communication between actors. One theoretical framework for capturing interaction protocols is to consider the communication protocols that they represent. Session types [5] describe communication protocols among parallel processes in terms of the evolution of types of participant actors. The general methodology starts with the specification of a global type, which captures the permissible sequences of messages that participants may exchange in a given session.
Note that a “global type” is so called because it expresses the evolution of type properties of the behavior of a group of actors involved in an interaction. It is not global in the sense of saying something about the behavior of every actor in a system. Based on a global type, a projection algorithm is needed to generate the necessary session types for each participant. The session types for participants are known as end-point types or local types. These local types describe the evolution of the expected behavior of the individual participants in the protocol.
A type checker can compare the projected localized specification against the implementation of each participant's behavior. Conventional session types can be generalized to typing coordination constraints in actor programs, which can then be enforced using, for example, synchronizers.
7.6.1 Session Types for Actors
Typing coordination constraints in actors pose two challenges: first, asynchronous communication leads to delays that require consideration of arbitrary shuffles; second, parameterized protocols must be considered. For example, assume that two actors are communicating through a sliding window protocol; the actors agree on the length of the window (i.e., the number of messages that may be buffered) and then proceed to a concurrent exchange of messages. Conventional session types are not suitable for typing interactions such as the sliding window protocol. The reason for this limitation is that their respective type languages depend on other formalisms for type checking (such as typed λ-calculus [49] or System T [50]), and these formalisms do not support a concurrency construct.
To overcome such limitations, we propose a programming language, Lang-A, along with a session type system, System-A, that allows type parameters in novel constructs that capture the inherent asynchrony of actor programs. In particular, the system includes novel parameterized typing constructs for expressing asynchrony, concurrency, sequence, choice, and atomicity in protocols. An inference algorithm derives local System-A types from Lang-A programs, and a type system checks those types against conformance criteria.
7.6.1.1 Example: Sliding Window Protocol
Recall the sliding window protocol. Assume that an actor a sends messages of type m to an actor b, which acknowledges every received message with an ack message. The protocol determines that at most n messages can be unacknowledged at any given time, so that a ceases sending until it receives another ack message. In this example, the window size n is a parameter, which means that we need a way to express the fact that n sending and acknowledging events can be in transit at any given instant in time. The global type of the protocol is as follows:

Here ![]() means that a sends a message of type m to b. The operator ; is used for sequencing interactions. Operator ∥ is used for the concurrent composition of its left and right arguments, while the Kleene star has the usual semantics of an unbounded – yet finite – number of repetitions.
means that a sends a message of type m to b. The operator ; is used for sequencing interactions. Operator ∥ is used for the concurrent composition of its left and right arguments, while the Kleene star has the usual semantics of an unbounded – yet finite – number of repetitions.
The above type can be expressed using the notation of Castagna et al. [27,51], albeit with a fixed window size n. In System-A, on the other hand, we can parameterize the type in n and statically verify that participants follow the protocol without knowing its runtime value. Using ![]() to denote the concurrent composition of n processes, we obtain the following type:
to denote the concurrent composition of n processes, we obtain the following type:
7.6.2 Global Types
A global type describes a protocol to which the whole system must adhere.
For example, the sliding window protocol specification is a global type, since it describes the behavior of all participants. Table 7.1 presents the grammar that generates the syntactic category ![]() of global types. The elements of
of global types. The elements of ![]() , which are instances of global types, will be denoted by variations of the variable G. Intuitively, the rules capture the following concepts:
, which are instances of global types, will be denoted by variations of the variable G. Intuitively, the rules capture the following concepts:
- (G-Interaction) denotes the sending and receiving of a message. For instance,
 means that participant a sends a message of type m to participant b.
means that participant a sends a message of type m to participant b. - (G-Seq) is used for the sequential composition of events.
- (G-Choice) denotes exclusive choice between the arguments. For G1,2 ∈
 , G1 ⊕ G2 means that only one of G1, G2 will be executed.
, G1 ⊕ G2 means that only one of G1, G2 will be executed. - (G-Paral) means that the arguments run concurrently. Interleavings are allowed, as long as the order established by the ; operator is respected. For example,
 means that all interleavings ABC, ACB, CAB are possible, where
means that all interleavings ABC, ACB, CAB are possible, where  and
and  . Note that B is not allowed to precede A because of how operator ; orders them. (Hence, BAC, BCA, and CBA are not valid interleavings in this example.)
. Note that B is not allowed to precede A because of how operator ; orders them. (Hence, BAC, BCA, and CBA are not valid interleavings in this example.) - (G-Shuffle) means that both arguments are executed atomically, in an unspecified order. Formally, G1 ⊗ G2 = (G1; G2) ⊕ (G2; G1) with the = relation denoting semantic equivalence, as detailed in the original work of Charalambides et al. [4].
- (G-KleeneStar) has the usual semantics of zero or more repetitions of the argument. We assume a finite number of repetitions.
Table 7.1 The syntax of global types.
 |
| We use a and b to denote possibly indexed actor names; m to denote possibly indexed message types; variants of n for type parameters; and i for index names. For parsing purposes, we assume operators associate with the right, and that operator precedence <p is ⊗ <p || <p ⊕ <p;. |
The n-ary versions of the operators express behaviors for which the values of n, n1, and n2 are unknown at compile time. Intuitively, the rules (G-Seq-N), (G-Choice-N), (G-Paral-N), and (G-Shuffle-N) apply the respective binary operator n2 − n1 times, generating a global type for each of the n2 − n1 + 1 values of i. (G-Exp) denotes the n-fold, sequential repetition of the argument. Note that for known parameter values, these expansions can take place during program compilation.
For parsing purposes, operators associate with the right. In terms of semantics, however, all of the operators are commutative, with the exception of sequencing. Furthermore, all operators are associative, with the exception of shuffling. In particular,
because the meaning of ![]() is that all arguments Gi are executed atomically, but in an unspecified order. Instead, the right-hand side above prevents, for example, G3 from occurring between G1 and G2.
is that all arguments Gi are executed atomically, but in an unspecified order. Instead, the right-hand side above prevents, for example, G3 from occurring between G1 and G2.
The distinction between the Kleene star and exponentiation is fundamental. The use of Gn means that the protocol conformance checker will have to prove that the system is correct for any fixed value of the parameter n. G*, on the other hand, refers to an unbounded number of repetitions of G. There is no parameter fixing this number, and it may be different from instance to instance of the Kleene star and/or among executions of the same program with the same runtime values for its parameters; the Kleene star entails a choice as to when to exit the loop.
We define an event to be a single interaction ![]() and a trace to be any finite sequence e1
and a trace to be any finite sequence e1![]() ek of events. Given a global type
ek of events. Given a global type ![]() , the set of possible traces tr(G) that it can produce determines the permissible sequences of messages that participants may exchange. We omit the full semantics of global types in this text, and refer the interested reader to the original work of Charalambides et al. [4].
, the set of possible traces tr(G) that it can produce determines the permissible sequences of messages that participants may exchange. We omit the full semantics of global types in this text, and refer the interested reader to the original work of Charalambides et al. [4].
7.6.3 Programming Language
Global types by themselves provide no implementation of protocols; implementations are given in the language Lang-A, which is used in the example in Figure 7.9. The figure shows an implementation of the sliding window protocol described earlier. The spawn statement launches n parallel instances of its block argument, one for each value of the provided index expression. Sends and receives coming from different spawned operations can be interleaved in any way possible. In this example, both the sender and the receiver spawn n parallel operations, each consisting of a repeating send/receive pair. This allows any interleaving of sends and receives, as long as no more than n sends are left unacknowledged.

Figure 7.9 The sliding window example in Lang-A.
In general, a Lang-A program begins with the declaration of the program parameters, akin to type parameters n, n1, n2, and so on, from Table 7.1. Then come message structure definitions, and the code for each actor. Both actor and message definitions can include an optional array syntax after their name. In the case of actors, this syntax declares as many actors as does the array parameter.
In the case of message structures, the syntax declares as many message types as does the array parameter. This allows the expression of protocols for which both actor names and message types are parameterized, such as ![]() . Lang-A is defined such that there is an almost one-to-one correspondence between the language constructs and the syntax of local types; the precise syntax and semantics are detailed in the work of Charalambides et al. [4].
. Lang-A is defined such that there is an almost one-to-one correspondence between the language constructs and the syntax of local types; the precise syntax and semantics are detailed in the work of Charalambides et al. [4].
7.6.4 Local Types and Type Checking
A local type specifies the abstract behavior of a single protocol participant, for example, one of the actors in the program in Figure 7.9. This section discusses System-A local types [4,28], whose syntax is shown in Table 7.2. In the grammar,
- (L-Send) denotes sending of a message of type m to actor a.
- (L-Recv) denotes receiving of a message of type m from actor a.
- (L-Seq), (L-Choice), (L-Shuffle), (L-Exp), (L-KleeneStar) describe the same concepts as for the global types.
- (L-Paral) is also defined as for global types. As before, the local type (a!t; a!u) || a?v allows three orderings of the events T = a!t, U = a!u, and V = a?v, namely, TUV, TVU, and VTU. As above, the specification a!t; a!u ensures that T happens before U.
Table 7.2 The syntax of local types.
 |
| As in the syntax of global types, we use a to denote possibly indexed actor names; m for possibly indexed message types; variants of n for type parameters; and i for index names. For parsing purposes, we assume operators associate with the right, and that operator precedence <p is ⊗ <p k <p ⊕ <p;. |
Projecting a global type onto each participant in a protocol results in a set of local types, one for each actor. For example, projecting ![]() onto a, written
onto a, written ![]() , gives the local type b!m. Similarly,
, gives the local type b!m. Similarly, ![]() . These can then be checked against the types inferred from the Lang-A code.
. These can then be checked against the types inferred from the Lang-A code.
Some (local) type inference rules are shown in Table 7.3. Rule (Inf-Skip) assigns the type τ to the skip construct and to all value computations, since those do not involve interactions between processes. Rules (Inf-Send) and (Inf-Recv) assign the (L-Send) and (L-Recv) constructs to send and receive actions, respectively. Sequencing is straightforward, but typing the spawn construct is a little more involved: The index i as well as the range c1![]() c2 transfers into the inferred type, which includes the parameterized construct ||.
c2 transfers into the inferred type, which includes the parameterized construct ||.
Table 7.3 Rules for inferring local types from Lang-A programs.
 |
 |
 |
 |
| The environments S and Π contain sorts of variables and actor names, respectively. Γ assigns local types |
|
The type-checking methodology requires the comparison of local types projected from the global type with those inferred from the program code. In order to perform the comparison on a syntactic level, local types are reduced to a normal form, in a semantics-preserving manner. For a detailed discussion of the projection function, the full list of type inference rules, and the semantics of local types and their relation to the semantics of Lang-A programs, we refer the interested reader to the original work of Charalambides et al. [4].
7.6.5 Realization of Global Types
A global type must satisfy certain properties in order to be projectable. Applying the projection function to a projectable global type will result in local types for the participants whose combined behavior is consistent with the global type.
First, to be projectable, the sequential constructs of a global type must retain their sequential semantics after projection. For example, the type ![]() does not preserve said semantics after projection, because c has to send m′ after b receives m, and programming this sequence requires interactions not captured in the above type.
does not preserve said semantics after projection, because c has to send m′ after b receives m, and programming this sequence requires interactions not captured in the above type.
In addition, a global type G1 ⊕ G2 is projectable if all participants can recognize which branch of the choice operator they need to take during execution. Similar requirements apply to G1 ⊗ G2, for which it must be possible for the constituents to be sequenced both ways, and for the participants to distinguish the two possible orderings.
Concurrent composition requires special care to prevent actions in one concurrent branch from affecting choices made on another, while for the Kleene star we need to ensure that the entry and exit conditions to the starred type can be identified by all participants.
If a global type G is projectable according to the criteria sketched above, the projection function generates local types that are functionally consistent with the global type. We use ΔG to denote the set of local types that result from the projection of G onto each one of the participants. That is, ![]() where Π is the set of participating actors. The set of traces tr(ΔG) producible by ΔG is the union of the sets of traces producible by the local types in ΔG. Now, let PR be the set of projectable global types. The key correctness property is then that G ∈ PR ⇒ tr(G) = tr(ΔG). The proof is by induction on the structure of global types [4].
where Π is the set of participating actors. The set of traces tr(ΔG) producible by ΔG is the union of the sets of traces producible by the local types in ΔG. Now, let PR be the set of projectable global types. The key correctness property is then that G ∈ PR ⇒ tr(G) = tr(ΔG). The proof is by induction on the structure of global types [4].
7.7 The Future
Our mobile cloud framework can enable effective balancing of resource use with performance while preserving security. A particular concern is energy management in mobile devices. Further research is needed in techniques to infer the energy consumed by a specific application on a mobile device. While the execution times of different components can be individually recorded using the system clock, a mobile device reports only lump-sum energy consumption. Figuring out the behavior thus requires inferential techniques based on a larger pool of data.
Monitoring techniques that infer coordination constraints and session types are another area of research. This would allow patterns of interaction in a running system to be inferred. System assurance will be enhanced by flagging suspicious deviations as well as preventing harmful actions. Moreover, the current notations to represent session types are formal in nature and not suitable for use by system developers. A friendly interface could help programmers visualize the interaction behaviors as well as reduce errors in the system. Moreover, session types may help detect information leaks, as certain sequences may reveal more information than a single message interaction would. In addition, statistical sampling can help detect violations of quantitative coordination constraints when not just information sequences, but the sum total of information revealed from a very large number of sources needs to be constrained.
The challenge of addressing the impact of failures and faults on interaction patterns needs to be studied further. Such failures are not explicitly incorporated either into the language of synchronizers or into session types. Adding support for dynamic process creation is an important direction for future work in session types for actor systems. In its current form, System-A cannot express actor creation as a behavior, and global types assume that all participants already exist. Matching a created actor with its subsequent use in a type requires an extra step that is not obvious. Furthermore, System-A omits support for session delegation, and does not deal with issues of progress. In addition, it does not consider overlapping indexed names when they are nested in multiple operators. That omission disallows some cases, such as all-to-all communication.
Acknowledgments
The authors would like to thank the members of the Open Systems Laboratory (OSL) group at the University of Illinois at Urbana-Champaign for their valuable discussion and insight. This chapter was made possible in part by sponsorship from the Air Force Research Laboratory and the Air Force Office of Scientific Research under agreement FA8750-11-2-0084, and the material is based upon work supported by the National Science Foundation under grants NSF CCF 14-38982 and NSF CCF 16-17401. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.
References
- 1 Kumar, K., Liu, J., Lu, Y.-H., and Bhargava, B. (2013) A survey of computation offloading for mobile systems. Mobile Networks and Applications, 18 (1), 129–140.
- 2 Agha, G. and Hewitt, C. (1985) Concurrent programming using actors: exploiting large-scale parallelism, in Foundations of Software Technology and Theoretical Computer Science, FSTTCS 1985 (ed. S.N. Maheshwari), Lecture Notes in Computer Science, vol. 206, Springer, Berlin, pp. 19–41.
- 3 Frølund, S. (1996) Coordinating Distributed Objects: An Actor-Based Approach to Synchronization, MIT Press.
- 4 Charalambides, M., Dinges, P., and Agha, G. (2016) Parameterized, concurrent session types for asynchronous multi-actor interactions. Science of Computer Programming, 115 (C), 100–126.
- 5 Honda, K., Vasconcelos, V.T., and Kubo, M. (1998) Language primitives and type discipline for structured communication-based programming, in Proceedings of the 7th European Symposium on Programming: Programming Languages and Systems (ESOP) (ed. C. Hankin), Lecture Notes in Computer Science, vol. 1381, Springer, Berlin pp. 122–138.
- 6 Rahman, M., Gao, J., and Tsai, W.-T. (2013) Energy saving in mobile cloud computing, in Proceedings of the IEEE International Conference on Cloud Engineering (IC2E), pp. 285–291.
- 7 Satyanarayanan, M., Bahl, P., Caceres, R., and Davies, N. (2009) The case for VM-based cloudlets in mobile computing. IEEE Pervasive Computing, 8 (4), 14–23.
- 8 Imai, S., Chestna, T., and Varela, C.A. (2012) Elastic scalable cloud computing using application-level migration, in Proceedings of the IEEE 5th International Conference on Utility and Cloud Computing, pp. 91–98.
- 9 Cuervo, E., Balasubramanian, A., Cho, D.-k., Wolman, A., Saroiu, S., Chandra, R., and Bahl, P. (2010) MAUI: making smartphones last longer with code offload, in Proceedings of the 8th International Conference on Mobile Systems, Applications, and Services, pp. 49–62.
- 10 Chun, B.-G., Ihm, S., Maniatis, P., Naik, M., and Patti, A. (2011) CloneCloud: elastic execution between mobile device and cloud, in Proceedings of the 6th European Conference on Computer Systems, pp. 301–314.
- 11 Kosta, S., Aucinas, A., Hui, P., Mortier, R., and Zhang, X. (2012) ThinkAir: dynamic resource allocation and parallel execution in the cloud for mobile code offloading, in Proceedings of the IEEE INFOCOM, pp. 945–953.
- 12 Shifteh Far, S. (2015) A flexible fine-grained adaptive framework for parallel mobile hybrid cloud applications, Ph.D. dissertation, University of Illinois at Urbana-Champaign.
- 13 Varela, C.A. and Agha, G. (1999) A hierarchical model for coordination of concurrent activities, in Proceedings of the 3rd International Conference on Coordination Languages and Models: COORDINATION ‘99 (eds. P. Ciancarini and A.L. Wolf), Lecture Notes in Computer Science, vol. 1594, Springer, Berlin, pp. 166–182.
- 14 Astley, M., and Agha, G.A. (1998) Customization and composition of distributed objects: middleware abstractions for policy management, in Proceedings of the 6th ACM SIGSOFT International Symposium on Foundations of Software Engineering (FSE-6), pp. 1–9.
- 15 Sturman, D.C. (1996) Modular specification of interaction policies in distributed computing, Ph.D. dissertation, University of Illinois at Urbana-Champaign.
- 16 Meseguer, J. and Talcott, C. (2002) Semantic models for distributed object reflection, in 16th European Conference on Object-Oriented Programming (ECOOP 2002) (ed. B. Magnusson), Lecture Notes in Computer Science, vol. 2374, Springer, Berlin pp. 1–36.
- 17 Venkatasubramanian, N. and Talcott, C. (1995) Reasoning about meta level activities in open distributed systems, in Proceedings of the 14th Annual ACM Symposium on Principles, PODC, pp. 144–152.
- 18 Ren, S., Yu, Y., Chen, N., Marth, K., Poirot, P.-E., and Shen, L. (2006) Actors, roles and coordinators: a coordination model for open distributed and embedded systems, in Proceedings of the 8th International Conference on Coordination Models and Languages: COORDINATION 2006, Lecture Notes in Computer Science, vol. 4038, Springer, pp. 247–265.
- 19 Milner, R., Parrow, J., and Walker, D. (1992) A calculus of mobile processes, I. Information and Computation, 100 (1), 1–40.
- 20 Honda, K. (1993) Types for dyadic interaction, in Proceedings of the 4th International Conference Concurrency Theory (CONCUR) (ed. E. Best), Lecture Notes in Computer Science, vol. 715, Springer, Berlin, pp. 509–523.
- 21 W3C: The Web Services Choreography Description Language, Version 1.0, 2005. Available at http://www.w3.org/TR/ws-cdl-10/.
- 22 Carbone, M., Honda, K., and Yoshida, N. (2007) Structured communication-centred programming for web services, in Proceedings of the 16th European Symposium on Programming (ESOP) (ed. R. De Nicola), Lecture Notes in Computer Science, vol. 4421, Springer, pp. 2–17.
- 23 Honda, K., Yoshida, N., and Carbone, M. (2008) Multiparty asynchronous session types, in Proceedings of the 35th Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages (POPL), pp. 273–284.
- 24 Gay, S. and Hole, M. (2005) Subtyping for session types in the pi calculus. Acta Informatica, 42 (2–3), 191–225.
- 25 Gay, S.J. and Vasconcelos, V.T. (2010) Linear type theory for asynchronous session types. Journal of Functional Programming, 20 (1), 19–50.
- 26 Yoshida, N., Deniélou, P.-M., Bejleri, A., and Hu, R. (2010) Parameterised multiparty session types, in International Conference on Foundations of Software Science and Computational Structures (FoSSaCS) (ed. L. Ong), Lecture Notes in Computer Science, vol. 6014, Springer, Berlin, pp. 128–145.
- 27 Castagna, G., Dezani-Ciancaglini, M., and Padovani, L. (2011) On global types and multi-party sessions, in Formal Techniques for Distributed Systems (eds. R. Bruni and J. Dingel), Lecture Notes in Computer Science, vol. 6722, Springer, Berlin, pp. 1–28.
- 28 Charalambides, M., Dinges, P., and Agha, G. (2012) Parameterized concurrent multi-party session types, in Proceedings of the 11th International Workshop on Foundations of Coordination Languages and Self Adaptation (FOCLASA), Newcastle, UK, Sep. 8, 2012, Electronic Proceedings in Theoretical Computer Science (EPTCS), vol. 91, pp. 16–30. Available at http://eptcs.web.cse.unsw.edu.au/content.cgi?FOCLASA12.
- 29 Bocchi, L., Chen, T.-C., Demangeon, R., Honda, K., and Yoshida, N. (2017) Monitoring networks through multiparty session types, in Theoretical Computer Science, vol. 669, pp. 33–58.
- 30 Neykova, R., Bocchi, L., and Yoshida, N. (2017) Timed runtime monitoring for multiparty conversations. Formal Aspects of Computing, 29 (5), 877–910.
- 31 Honda, K., Mukhamedov, A., Brown, G., Chen, T.-C., and Yoshida, N. (2011) Scribbling interactions with a formal foundation, in Proceedings of the Distributed Computing and Internet Technology (ICDCIT 2011) (eds. R. Natarajan and A. Ojo), Lecture Notes in Computer Science, vol. 6536, Springer, Berlin, pp. 55–75.
- 32 Noble, B.D., Satyanarayanan, M., Narayanan, D., Tilton, J.E., Flinn, J., and Walker, K.R. (1997) Agile application-aware adaptation for mobility. ACM SIGOPS Operating Systems Review, 31 (5), 276–287.
- 33 Moinzadeh, P. (2013) I-AdMiN: a framework for deriving adaptive service configuration in wireless smart sensor networks, Ph.D. dissertation, University of Illinois at Urbana-Champaign.
- 34 Oliner, A.J., Iyer, A.P., Stoica, I., Lagerspetz, E., and Tarkoma, S. (2013) Carat: collaborative energy diagnosis for mobile devices, in Proceedings of the 11th ACM Conf. Embedded Networked Sensor Systems, Article No. 10.
- 35 Subashini, S. and Kavitha, V. (2011) A survey on security issues in service delivery models of cloud computing. Journal of Network and Computer Applications, 34 (1), 1–11.
- 36 Chow, R., Golle, P., Jakobsson, M., Shi, E., Staddon, J., Masuoka, R., and Molina, J. (2009) Controlling data in the cloud: outsourcing computation without outsourcing control, in Proceedings of the ACM Workshop on Cloud Computing Security, pp. 85–90.
- 37 Grewal, R.K. and Pateriya, P.K. (2013) A rule-based approach for effective resource provisioning in hybrid cloud environment, in New Paradigms in Internet Computing (eds. S. Patnaik et al.), Advances in Intelligent Systems and Computing, vol. 203, Springer, Berlin, pp. 41–57.
- 38 Kumar, K. and Lu, Y.-H. (2010) Cloud computing for mobile users: can offloading computation save energy? Computer, 43 (4), 51–56.
- 39 Zhang, X., Schiffman, J., Gibbs, S., Kunjithapatham, A., and Jeong, S. (2009) Securing elastic applications on mobile devices for cloud computing, in Proceedings of the 2009 ACM Workshop on Cloud Computing Security (CCSW’09), Chicago, IL, pp. 127–134.
- 40 Chow, R., Jakobsson, M., Masuoka, R., Molina, J., Niu, Y., Shi, E., and Song, Z. (2010) Authentication in the clouds: a framework and its application to mobile users, in Proceedings of the ACM Cloud Computing Security Workshop (CCSW'10), Chicago, IL, pp. 1–6.
- 41 Huang, D., Zhang, X., Kang, M., and Luo, J. (2010) MobiCloud: building secure cloud framework for mobile computing and communication, in Proceedings of the 5th IEEE International Symposium on Service Oriented System Engineering, pp. 27–34.
- 42 Khan, A.N., Kiah, M.L.M., Khan, S.U., and Madani, S.A. (2013) Towards secure mobile cloud computing: a survey. Future Generation Computer Systems, 29 (5), 1278–1299.
- 43 Yu, X. and Wen, Q. (2012) Design of security solution to mobile cloud storage, in Knowledge Discovery and Data Mining (ed. H. Tan), Advances in Intelligent and Soft Computing, vol. 135, Springer, Berlin, pp. 255–263.
- 44 Jansen, W. and Grance, T. (2011) Guidelines on Security and Privacy in Public Cloud Computing. National Institute of Standards and Technology (NIST), U.S. Department of Commerce, Special Publication 800-144, Computer Security Division, Information Technology Laboratory, NIST, Gaithersburg, MD.
- 45 Damiani, E., De Capitani di Vimercati, S., Paraboschi, S., and Samarati, P. (2002) A fine-grained access control system for XML documents. ACM Transactions on Information and System Security, 5 (2), 169–202.
- 46 Varela, C. and Agha, G. (2001) Programming dynamically reconfigurable open systems with SALSA. ACM SIGPLAN Notices, 36 (12), 20–34.
- 47 Dinges, P. and Agha, G. (2012) Scoped synchronization constraints for large scale actor systems, in Proceedings of the International Conference on Coordination Languages and Models: COORDINATION 2012 (ed. M. Sirjani), Lecture Notes in Computer Science, vol. 7274, Springer, Berlin pp. 89–103.
- 48 Miller, M.S. (2006) Robust composition: towards a unified approach to access control and concurrency control, Ph.D. dissertation, Johns Hopkins University.
- 49 Barendregt, H. (1992) Lambda calculi with types, in Handbook of Logic in Computer Science, Vol. II: Background: Computational Structures (eds. S. Abramsky, D.M. Gabbay, and T.S.E. Maibaum), Oxford University Press, pp. 117–309.
- 50 Gödel, K. (1958) Über eine bisher noch nicht benützte Erweiterung des finiten Standpunktes. Dialectica, 12 (3–4), 280–287.
- 51 Castagna, G., Dezani-Ciancaglini, M., and Padovani, L. (2012) On global types and multi-party sessions. Logical Methods in Computer Science, 8 (1), Available at https://lmcs.episciences.org/773.