
Chapter 4
Crunching Categorical Data
IN THIS CHAPTER
![]() Summarizing categorical data effectively
Summarizing categorical data effectively
![]() Interpreting commonly used statistics
Interpreting commonly used statistics
![]() Realizing what statistics do and don’t say
Realizing what statistics do and don’t say
Every data set has a story, and if statistics are used properly, they do a good job of uncovering and reporting that story. Statistics that are improperly used can tell a different story, or only part of it, so knowing how to make good decisions about the information you’re given is very important.
A descriptive statistic (or statistic for short) is a number that summarizes or describes some characteristic about a set of data. In this chapter and the next one, you see some of the most common descriptive statistics and how they are used, and you find out how to calculate them, interpret them, and put them together to get a good picture of a data set. You also find out what these statistics say and what they don’t say about the data.
Summing Up Data with Descriptive Statistics
Descriptive statistics take a data set and boil it down to a set of basic information. Summarized data are often used to provide people with information that is easy to understand and that helps answer their questions. Picture your boss coming to you and asking, “What’s our client base like these days, and who’s buying our products?” How would you like to answer that question? With a long, detailed, and complicated stream of numbers that are sure to glaze their eyes over? Probably not. You want clean, clear, and concise statistics that sum up the client base for them, so they can see how brilliant you are and then send you off to collect even more data to see how they can include more people in the client base. (That’s what you get for being efficient.)
Summarizing data has other purposes, as well. After all the data have been collected from a survey or some other kind of study, the next step is for the researcher to try to make sense out of the data. Typically, the first step researchers take is to run some basic statistics on the data to get a rough idea about what’s happening in it. Later in the process, researchers can do more analyses to formulate or test claims made about the population the data came from, estimate certain characteristics about the population (like the mean), look for links between variables they measured, and so on.
Another big part of research is reporting the results, not only to their peers, but also to the media and the general public. Although a researcher’s peers may be anxiously waiting to hear about all the complex analyses that were done on a data set, the general public is neither ready for nor interested in that. What does the public want? Basic information. Statistics that make a point clearly and concisely are typically used to relay information to the media and to the public.
 If you really need to learn more from data, a quick statistical overview isn’t enough. In the statistical world, less is not more, and sometimes the real story behind the data can get lost in the shuffle. To be an informed consumer of statistics, you need to think about which statistics are being reported, what these statistics really mean, and what information is missing. This chapter focuses on these issues.
If you really need to learn more from data, a quick statistical overview isn’t enough. In the statistical world, less is not more, and sometimes the real story behind the data can get lost in the shuffle. To be an informed consumer of statistics, you need to think about which statistics are being reported, what these statistics really mean, and what information is missing. This chapter focuses on these issues.
Crunching Categorical Data: Tables and Percents
Categorical data (also known as qualitative data) capture qualities or characteristics about an individual, such as a person’s eye color, gender, political party, or opinion on some issue (using categories such as Agree, Disagree, or No Opinion). Categorical data tend to fall into groups or categories pretty naturally. “Political Party,” for example, typically has four groups in the United States: Democrat, Republican, Independent, and Other. Categorical data often come from survey data, but they can also be collected in experiments. For example, in an experimental test of a new medical treatment, researchers may use three categories to assess the outcome of the experiment: Did the patient get better, worse, or stay the same while undergoing the treatment?
Counting on the frequency
One way to summarize categorical data is to simply count, or tally up, the number of individuals that fall into each category. The number of individuals in any given category is called the frequency for that category. If you list all the possible categories along with the frequency for each of them, you create a frequency table. The total of all the frequencies should equal the size of the sample (because you place each individual in one category).
 Q. Suppose you take a sample of ten people and ask them all whether or not they own the latest smartphone. Each person falls into one of two categories: yes or no. The data is shown in the following table:
Q. Suppose you take a sample of ten people and ask them all whether or not they own the latest smartphone. Each person falls into one of two categories: yes or no. The data is shown in the following table:
Person # | Latest Smartphone | Person # | Latest Smartphone |
|---|---|---|---|
1 | Y | 6 | Y |
2 | N | 7 | Y |
3 | Y | 8 | Y |
4 | N | 9 | N |
5 | Y | 10 | Y |
- Summarize this data in a frequency table.
- What’s an advantage of summarizing categorical data?
A. Data summaries boil down the data quickly and clearly.
- The frequency table for this data is shown here:
Own the Latest Smartphone?
Frequency
Y
7
N
3
Total
10
- A data summary allows you to see patterns in the data, which aren’t clear if you look only at the original data.
1 You survey 20 shoppers to see what type of soft drink they like best, Brand A or Brand B. The results are: A, A, B, B, B, B, B, B, A, A, A, B, A, A, A, A, B, B, A, A. Which brand do the shoppers prefer? Make a frequency table and explain your answer.
You survey 20 shoppers to see what type of soft drink they like best, Brand A or Brand B. The results are: A, A, B, B, B, B, B, B, A, A, A, B, A, A, A, A, B, B, A, A. Which brand do the shoppers prefer? Make a frequency table and explain your answer.
2 A local city government asks voters to vote on a tax levy for the local school district. A total of 18,726 citizens vote on the issue. The Yes count comes in at 10,479, and the rest of the voters say No.
- Show the results in a frequency table.
- Why is it important to include the total number at the bottom of a frequency table?
3 A zoo asks 1,000 people whether they’ve been to the zoo in the last year. The pollsters count the results and find that 592 say yes, 198 say no, and 210 don’t respond.
- Show the results in a frequency table.
- Explain why you need to include the people who don’t respond.
Relating with percentages
Another way to summarize categorical data is to show the percentage of individuals that fall into each category, thereby creating a relative frequency. The relative frequency of a given category is the frequency (number of individuals in that category) divided by the total sample size, multiplied by 100 to get the percentage; hence, the calculated value is relative to the total surveyed. For example, if you survey 50 people and 10 are in favor of a certain issue, the relative frequency of the “in-favor” category is 10 ÷ 50 = 0.20 times 100, which gives you 20 percent. If you list all the possible categories along with their relative frequencies, you create a relative frequency table. The total of all the relative frequencies should equal 100 percent (subject to possible round-off error).
Q. Using the cellphone data from the following table, make a relative frequency table and interpret the results.
Person # | Latest Smartphone | Person # | Latest Smartphone |
|---|---|---|---|
1 | Y | 6 | Y |
2 | N | 7 | Y |
3 | Y | 8 | Y |
4 | N | 9 | N |
5 | Y | 10 | Y |
A. Following is a relative frequency table for the cellphone data. Seventy percent of the people sampled reported owning the latest smartphones, and 30 percent admitted to being technologically just a little behind the times.
Own the Latest Smartphone? | Relative Frequency |
|---|---|
Y | 70% |
N | 30% |
You get the 70 percent by taking ![]() , and you calculate the 30 percent by taking
, and you calculate the 30 percent by taking ![]() .
.
4 You survey 20 shoppers to see what type of soft drink they like best, Brand A or Brand B. The results are: A, A, B, B, B, B, B, B, A, A, A, B, A, A, A, A, B, B, A, A. Which brand do the shoppers prefer?
- Use a relative frequency table to determine the preferred brand.
- In general, if you had to choose, which is easier to interpret: frequencies or relative frequencies? Explain your answer.
5 A local city government asked voters in the last election to vote on a tax levy for the local school district. A record 18,726 voted on the issue. The Yes count came in at 10,479, and the rest of the voters checked the No box. Show the results in a relative frequency table.
6 A zoo surveys 1,000 people to find out whether they’ve been to the zoo in the last year. The pollsters count the results and find that 592 say yes, 198 say no, and 210 don’t respond. Make a relative frequency table and use it to find the response rate (percentage of people who respond to the survey).
7 Suppose that instead of showing the number in each group, you show just the percentage (that is, the relative frequency).
- What’s one advantage a relative frequency table has over a frequency table?
- Name one disadvantage that comes with creating a relative frequency table compared to using a frequency table.
Two-way tables: Summarizing multiple measures
You can break down categorical data further by creating two-way tables. Two-way tables (also called crosstabs) are tables with rows and columns. They summarize the information from two categorical variables at once, such as gender and political party, so you can see (or easily calculate) the percentage of individuals in each combination of categories and use them to make comparisons between groups.
For example, if you had data about the gender and political party of your respondents, you would be able to look at the percentage of Republican females, Republican males, Democratic females, Democratic males, and so on. In this example, the total number of possible combinations in your table would be ![]() , or the total number of gender categories times the total number of party affiliation categories. (See Chapter 20 for the full scoop, and then some, on two-way tables.)
, or the total number of gender categories times the total number of party affiliation categories. (See Chapter 20 for the full scoop, and then some, on two-way tables.)
The U.S. government calculates and summarizes loads of categorical data using crosstabs. Typical age and gender data, reported by the U.S. Census Bureau for a survey conducted in 2020, are shown in Table 4-1. (Normally age would be considered a numerical variable, but the way the U.S. government reports it, age is broken down into categories, making it a categorical variable.)
Table 4-1 U.S. Population, Broken Down by Age and Gender
Age Group | Total (in Mil.) | % | # Males (in Mil.) | % | # Females (in Mil.) | % |
|---|---|---|---|---|---|---|
< 5 | 19.30 | 5.86 | 9.86 | 6.07 | 9.44 | 5.65 |
5–9 | 20.24 | 6.14 | 10.35 | 6.38 | 9.89 | 5.91 |
10–14 | 20.75 | 6.30 | 10.59 | 6.53 | 10.16 | 6.08 |
15–19 | 20.96 | 6.36 | 10.69 | 6.59 | 10.27 | 6.14 |
20–24 | 21.59 | 6.55 | 11.03 | 6.80 | 10.56 | 6.32 |
25–29 | 23.24 | 7.05 | 11.88 | 7.32 | 11.36 | 6.79 |
30–34 | 22.84 | 6.93 | 11.57 | 7.13 | 11.27 | 6.74 |
35–39 | 21.83 | 6.63 | 10.94 | 6.74 | 10.89 | 6.51 |
40–44 | 20.31 | 6.16 | 10.11 | 6.23 | 10.20 | 6.10 |
45–49 | 19.97 | 6.06 | 9.87 | 6.08 | 10.10 | 6.04 |
50–54 | 20.39 | 6.19 | 10.05 | 6.19 | 10.34 | 6.18 |
55–59 | 21.60 | 6.56 | 10.51 | 6.48 | 11.09 | 6.63 |
60–64 | 20.80 | 6.32 | 9.98 | 6.15 | 10.82 | 6.47 |
65–69 | 17.87 | 5.42 | 8.39 | 5.17 | 9.48 | 5.67 |
70–74 | 14.67 | 4.45 | 6.79 | 4.19 | 7.88 | 4.71 |
75–79 | 9.98 | 3.03 | 4.47 | 2.76 | 5.51 | 3.30 |
80–84 | 6.47 | 1.97 | 2.75 | 1.70 | 3.72 | 2.22 |
85– | 6.65 | 2.02 | 2.41 | 1.49 | 4.24 | 2.54 |
Total | 329.46 | 100 | 162.24 | 100 | 167.22 | 100 |
You can examine many different facets of the U.S. population by looking at and working with different numbers from Table 4-1. For example, looking at gender, you notice that women slightly outnumber men — the population in 2020 was 50.76 percent female (divide the total number of females by the total population size and multiply by 100 percent) and 49.24 percent male (divide the total number of males by the total population size and multiply by 100 percent). You can also look at age: The percentage of the entire population that is under 5 years old was 5.86 percent (divide the total number under age 5 by the total population size and multiply by 100 percent). The largest group belongs to the 25- to 29-year-olds, who made up 7.05 percent of the population.
Next, you can explore a possible relationship between gender and age by comparing various parts of the table. You can compare, for example, the percentage of females to males in the 80-and-over age group. Because these data are reported in 5-year increments, you have to do a little math in order to get your answer, though. The percentage of the population that’s female and aged 80 and above (looking at column 7 of Table 4-1) is ![]() . The percentage of males aged 80 and over (looking at column 5 of Table 4-1) is
. The percentage of males aged 80 and over (looking at column 5 of Table 4-1) is ![]() . This shows that the 80-and-over age group for the females is about 49 percent larger than for the males (because
. This shows that the 80-and-over age group for the females is about 49 percent larger than for the males (because ![]() ).
).
These data confirm the widely accepted notion that women tend to live longer than men. However, the gap between men and women is narrowing over time. According to the U.S. Census Bureau, back in 2001 the percentage of women who were 80 years old and over was 4.36, compared to 2.31 for men. The females in this age group outnumbered the males by a whopping 89 percent back in 2001 (noting that ![]() ).
).
After you have the crosstabs that show the breakdown of two categorical variables, you can conduct hypothesis tests to determine whether a significant relationship or link between the two variables exists, taking into account the fact that data vary from sample to sample. Chapter 15 gives you all the details on hypothesis tests.
Interpreting counts and percents with caution
Not all summaries of categorical data are fair and accurate. Knowing what to look for can help you keep your eyes open for misleading and incomplete information.
Instructors often ask you to “interpret the results.” Your instructor wants you to use the statistics available to talk about how they relate to the given situation. In other words, what do the results mean to the person who collects the data?
With relative frequency tables, don’t forget to check whether all categories sum to 1, or 100 percent (subject to round-off error), and remember to look for some indicator as to total sample size. See the following for an example of critiquing a data summary.
Q. You watch a commercial where the manufacturer of a new cold medicine (“Nocold”) compares it to the leading brand. The results are shown in the following table.
How Nocold Compares | Percentage |
|---|---|
Much better | 47% |
At least as good | 18% |
- What kind of table is this?
- Interpret the results. (Did the new cold medicine beat out the leading brand?)
- What important details are missing from this table?
A. Much like the cold medicines we always take, the table about “Nocold” does “Nogood.”
- This table is an incomplete relative frequency table. The remaining category is “not as good” for the Nocold brand, and the advertiser doesn’t show it. But you can do the math and see that
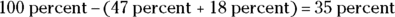 of the people say that the leading brand is better.
of the people say that the leading brand is better. - If you put the two groups in the table together, 65 percent of the patients say that Nocold is at least as good as the leading brand, and almost half of the patients say Nocold is much better.
- What’s missing? The remaining percentage (to keep all possible results in perspective). But more importantly, the total sample size is missing. You don’t know whether the surveyors sampled 10 people, 100 people, or 1,000 people. This means the precision of the results is unknown. (Precision means how consistent the results will be from sample to sample; it’s related to sample size, as you see in Chapter 13.)
8 Suppose you ask 1,000 people to identify from a list of five vacation spots which ones they’ve already visited. The frequencies you receive are as follows: Disney World, 216; New Orleans, 312; Las Vegas, 418; New York City, 359; and Washington, D.C., 188.
- Explain why creating a traditional relative frequency table doesn’t make sense here.
- How can you summarize this data with percents in a way that makes sense?
9 If you have only a frequency table, can you find the corresponding relative frequency table? Conversely, if you have only a relative frequency table, can you find the corresponding frequency table? Explain your answer.
Practice Questions Answers and Explanations
1 Eleven shoppers prefer Brand A, and nine shoppers prefer Brand B. The survey results are shown in the following frequency table. Brand A got more votes, but the results are pretty close.
Brand Preferred | Frequency |
|---|---|
A | 11 |
B | 9 |
Total | 20 |
2 Frequencies are fine for summarizing data as long as you keep the total number in perspective.
- The results are shown in the following frequency table. Because the total is 18,726, and the Yes count is 10,479, the No count is the difference between the two, which is
 .
.
Vote
Frequency
Y
10,479
N
8,247
Total
18,726
- The total is important because it helps keep the frequencies in perspective when you compare them to each other.
3 This problem shows the importance of reporting not only the results of participants who responded, but also what percentage of the total actually responded.
- The results are shown in the following frequency table:
Gone to the Zoo in the Last Year?
Frequency
Y
592
N
198
Nonrespondents
210
Total
1,000
- If you don’t show the nonrespondents, the total doesn’t add up to 1,000 (the number surveyed). An alternative way to show the data is to base it on only the respondents, but the results would be biased. You can’t definitively say that the nonrespondents would respond the same way as the respondents.
4 Relative frequencies do just what they say: They help you relate the results to each other (by finding percentages).
- Eleven shoppers out of the twenty prefer Brand A, and nine shoppers out of the twenty prefer Brand B. The survey results are shown in the following relative frequency table. Brand A got more votes, but the results are pretty close, with 55 percent of the shoppers preferring Brand A and 45 percent preferring Brand B.
Brand Preferred
Relative Frequency
A
55%
B
45%
- You often have an easier time interpreting percents, because when you need to interpret counts, you have to put them in perspective in terms of “out of how many?”
5 The results are shown in the following relative frequency table. The Yes percentage is ![]() percent. Because the total is 100 percent, the No percentage is
percent. Because the total is 100 percent, the No percentage is ![]() .
.
Vote | Relative Frequency |
|---|---|
Y | 55.96% |
N | 44.04% |
6 You can see the relative frequency table following this answer. Knowing the response rate is critical for interpreting the results of a survey. (The higher the response rate, the better.) The response rate is ![]() , that is, the total percentage of people who responded in any way (yes or no) to the survey. Note that 21 percent is the nonresponse rate.
, that is, the total percentage of people who responded in any way (yes or no) to the survey. Note that 21 percent is the nonresponse rate.
Gone to the Zoo in the Last Year? | Relative Frequency |
|---|---|
Y |
|
N | 19.8% |
Nonrespondents | 21.0% |
7 Showing the percentages rather than counts means making a relative frequency table rather than a frequency table.
- One advantage of a relative frequency table is that everything sums to 100 percent, making it easier to interpret the results, especially if you have a large number of categories.
- One disadvantage of a relative frequency table is that if you see only the percents, you don’t know how many people participated in the study; therefore, you don’t know how precise the results are. Remember the commercial about ‘four out of five dentists surveyed’? Maybe the company only asked five dentists! You can get around this problem by putting the total sample size somewhere at the top or bottom of your relative frequency table.
 When making a relative frequency table, include the total sample size somewhere on the table.
When making a relative frequency table, include the total sample size somewhere on the table.
8 Be careful how you interpret tables where an individual can be in more than one category at the same time.
- The frequencies don’t sum to 1,000, because people have the option to choose multiple locations or none at all, so each person doesn’t end up in exactly one group. If you take the grand total of all the frequencies (1,493) and divide each frequency by 1,493 to get a relative frequency, the relative frequencies sum to 1 (or 100 percent). But what does that mean? It makes it hard to interpret these percents because they don’t account for the total number of people.
- One way you can summarize this data is by showing the percentage of people who have been at each location separately (compared to the percentage who haven’t been there before). These percents add up to 1 for each location. The following table shows the results summarized with this method. Note: The table isn’t a relative frequency table; however, it uses relative frequencies.
Location
% Who Have Been There
% Who Haven’t Been There
Disney World

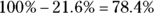
New Orleans


Las Vegas


New York City


Washington, D.C.


Not all tables involving percents should sum to 1. Don’t force tables to sum to 1 when they shouldn’t; do make sure you understand whether each individual can fall under more than one category. In those cases, a typical relative frequency table isn’t appropriate.
9 You can always sum all the frequencies to get a total and then find each relative frequency by taking the frequency divided by the total. However, if you have only the percents, you can’t go back and find the original counts unless you know the total number of individuals.
Suppose you know that 80 percent of the people in a survey like ice cream. How many actual people in the survey like ice cream? If the total number of respondents is 100, then ![]() people like ice cream. If the total is 50, then you’re looking at
people like ice cream. If the total is 50, then you’re looking at ![]() positive answers. If the total is 5, then you’re dealing only with 4 respondents
positive answers. If the total is 5, then you’re dealing only with 4 respondents ![]() . This illustrates why relative frequency tables need to have the total sample size somewhere.
. This illustrates why relative frequency tables need to have the total sample size somewhere.
Watch for total sample sizes when you’re given a relative frequency table. Don’t be misled by percentages alone, thinking they’re always based on large sample sizes. Many are not.
If you’re ready to test your skills a bit more, take the following chapter quiz that incorporates all the chapter topics.
Whaddya Know? Chapter 4 Quiz
Quiz time! Complete each problem to test your knowledge on the various topics covered in this chapter. You can then find the solutions and explanations in the next section.
1 A researcher orders 10 of the exact same pizzas for delivery from 10 different pizzerias on a given night. They note whether or not each pizza came on time and record the results in the following table.
Pizza # | On Time? | Pizza # | On Time? |
|---|---|---|---|
1 | N | 6 | N |
2 | N | 7 | Y |
3 | Y | 8 | Y |
4 | N | 9 | N |
5 | Y | 10 | Y |
- Organize the results in a relative frequency table.
- What does the researcher conclude about these 10 pizzas? Interpret the results.
2 Bob surveys 10 of his real-estate clients at random to see whether they are thinking of selling in the next year. The results are shown in the following table.
Person # | Selling | Person # | Selling |
|---|---|---|---|
1 | N | 6 | N |
2 | N | 7 | N |
3 | Y | 8 | Y |
4 | N | 9 | N |
5 | Y | 10 | Y |
- Make a frequency table that summarizes the results.
- Interpret the results.
- What do you get when you sum the frequencies in a frequency table?
- What do you get when you sum the relative frequencies in a relative frequency table?
3 Is the following table a frequency table or a relative frequency table? Why?
Voted ( | Results |
|---|---|
Y | 32% |
N | 68% |
4 Ten winter days were randomly chosen in the month of January in Columbus, Ohio. Each day, it was noted whether the temperature dipped below 32 or not. On 30% of the days, it did drop below 32, and on 70% of the days, it didn’t.
- Make a frequency table of the data.
- Show an example of what the data might have looked like for those 10 days.
5 Professor Charleston’s final grades for his class turned out to have 10 As, 8 Bs, 5 Cs, 2 Ds, and 0 Fs.
- Make a relative frequency table of the final grades.
- Interpret the results.
6 Explain how a pie chart is similar to a relative frequency table.
7 Susan gave a survey to 200 randomly chosen students in her statistics class. She asked the students whether they planned to go away from home for spring break. One hundred students said yes, 60 students said no, and 40 students did not respond.
- What was the response rate of Susan’s survey?
- Show the results in a relative frequency table.
- Interpret the results.
8 Hasan the quality control manager takes a random sample of 20 packages of frozen shrimp off the shelf. He determines whether each package has expired (yes, no), and checks to see if it has the proper weight (yes, no). He places the results in a table. What type of table will Hasan’s results be summarized in?
9 A survey asks for political party (Republican, Democrat, Independent, Other) and age group (18–30, 31–50, over 50) of 150 randomly chosen registered voters. How many categories (cells) will be in the resulting two-way table?
Answers to Chapter 4 Quiz
1 ![]() Yes;
Yes; ![]() No. Relative frequency table:
No. Relative frequency table:
 Pizzas
PizzasOn Time? Yes
On Time? No
Percent (Relative Frequency)
50%
50%
- Fifty percent of the 10 pizzas were delivered on time and 50% were not.
2
 Clients
ClientsThinking of Selling? Yes
Thinking of Selling? No
Count (Frequency)
4
6
- Four of the 10 clients are thinking of selling and 6 are not.
3
- When you sum the frequencies in a frequency table, you get the total sample size, n.
- When you sum the relative frequencies in a relative frequency table, you get 1.
4 The table is a relative frequency table because the results are shown in percentage form, and sum to ![]() .
.
5
 Days
DaysDropped below 32? Yes
Dropped below 32? No
Count (Frequency)


- yes, yes, no, no, no, no, no, no, yes, no. Note that any combination of 3 yeses and 7 nos works here.
6
- The total number of grades is 25; divide each frequency by 25 to get the relative frequency. The results should sum to 1.
Grade
A
B
C
D
F
Relative Frequency





- The 25-member class had 40% As, 32% Bs, 20% Cs, 8% Ds, and 0% Fs.
7 A pie chart is similar to a relative frequency table because each slice of the pie is a group and each group has a percentage attached to it that indicates the percentage of individuals in that group. The percents sum to 1. A pie chart is a graphical representation of a relative frequency table.
8
 .
.
Yes
No
No Response
Percent (Relative Frequency)



- The survey showed 50% of the students plan to go away from home for spring break; 30% do not plan to; and 20% did not respond.
9 A two-way table with rows and columns representing expired (yes, no), and proper weight (yes, no). One possible two-way table is the following:
Proper Weight? Yes | Proper Weight? No | |
Expired? Yes | ||
Expired? No |
10 The number of cells will be 4 (political parties) * 3 (age groups) = 12 category combinations = 12 cells.