
9.2 Aggregate Data Types
An aggregate data type is a data type composed of a combination of primitive data types. We both discuss and demonstrate in C the following four primary types of aggregate data types: arrays, records, undiscriminated union, and discriminated union.
9.2.1 Arrays
An array is an aggregate data type indexed by integers:

9.2.2 Records
A record (also referred to as a struct) is an aggregate data type indexed by strings called field names:

Records are called tuples in the Miranda family of languages, including Miranda, ML, and Haskell. Tuples are indexed by numbers and records are indexed by field names. A record can store at any one time any element of the Cartesian product of the sets of possible values for the data types included in the record. In other words, it can store any element of the Cartesian product of the set of all ints and the set of all doubles.
The parameter and argument list of any uncurried function in ML/Haskell is a tuple; thus, ML/Haskell use tuples to specify the domain of a function. In the context of a tuple or a parameter or argument list of an uncurried function of more than one parameter or argument, the * and comma (,) in ML and Haskell, respectively, are analogs of the Cartesian-product operator ×. The parameter and argument list of any function in C or C++ can similarly be thought of as a struct. In C, in the context of a function parameter or argument list with more than one parameter or argument, the comma (,) is the analog of the Cartesian-product operator ×. Thus, the Cartesian product is the theoretical basis for records. Two instances of records in programming languages are structs (in C and C++) and tuples (in ML and Haskell).
Before moving onto the next type of aggregate data type, we consider the process of declaring types and variables in C. In C, we declare a variable using the syntax <type> <identifier>. The <type> can be a named type (e.g., int or double) or a nameless, literal type as in the previous example. For instance:
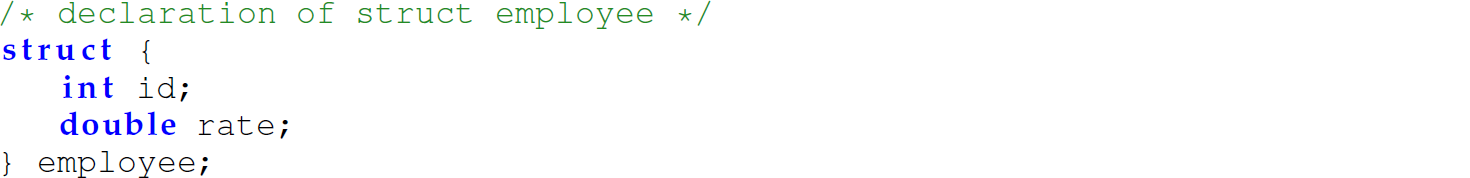
Here, we are declaring the variable employee to be of the nameless, literal type preceding it, rather than naming the literal type employee. The C reserved word typedef, with syntax typedef <type> <type-identifier>, is used to give a new name to an existing type or to name a literal type. For instance, to give a new name to an existing type, we write typedef int boolean;. To give a name to a literal type, for example, we write:

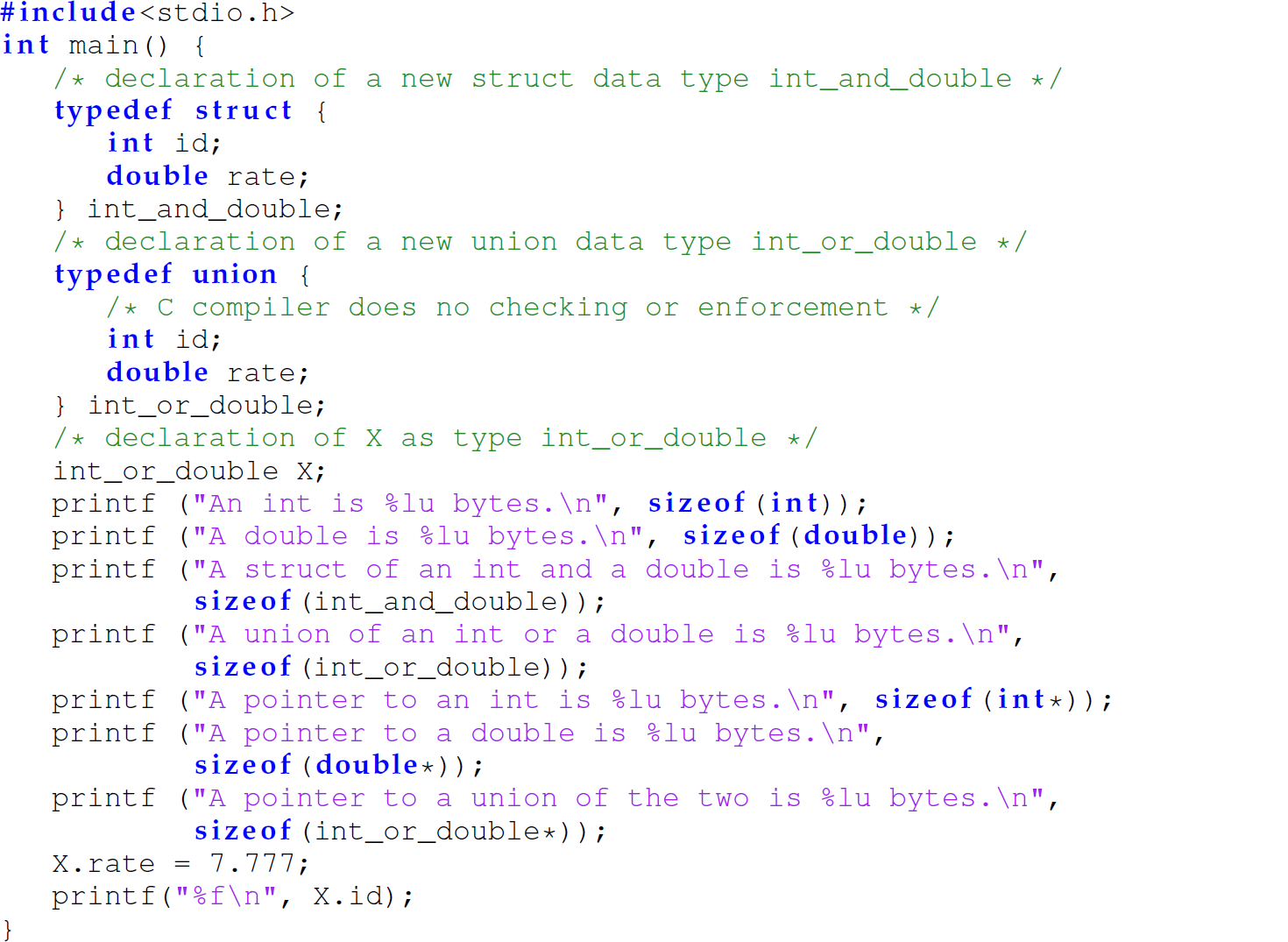
The mnemonic int_and_double can now be used to declare variables of that nameless struct type. The following example declares a variable int_or_double using a nameless, literal data type:

In contrast, the next example assigns a name to a literal data type (lines 2–5) and then, using the type name int_and_double given to the literal data type, declares X to be an instance of int_and_double (line 8):

ML and Haskell each have an expressive type system for creating new types with a clean and elegant syntax. The reserved word type in ML and Haskell introduces a new name for an existing type (akin to typedef in C or C++):

9.2.3 Undiscriminated Unions
An undiscriminated union is an aggregate data type that can only store a value of one of multiple types (i.e., a union of multiple types):
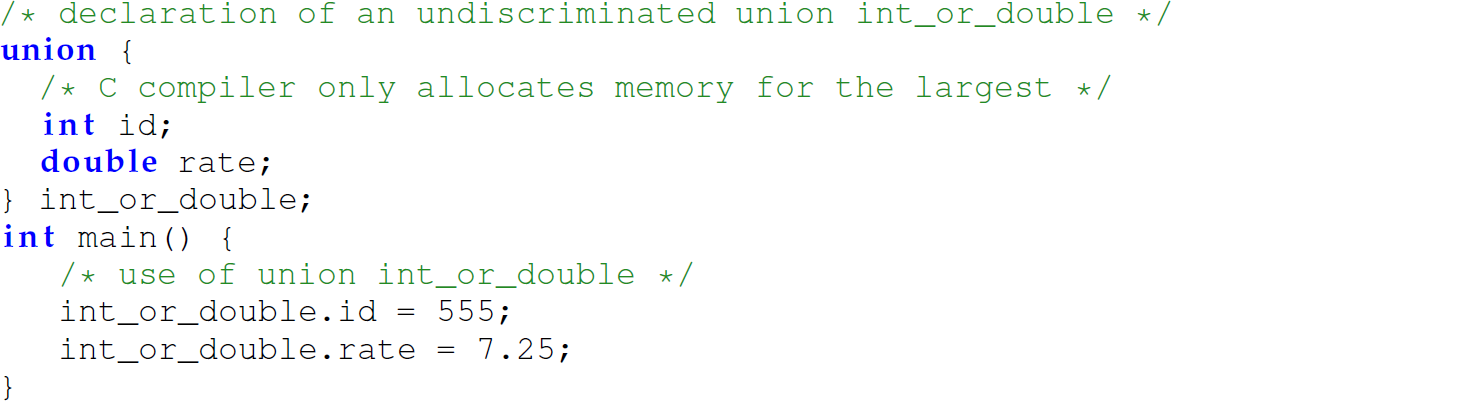
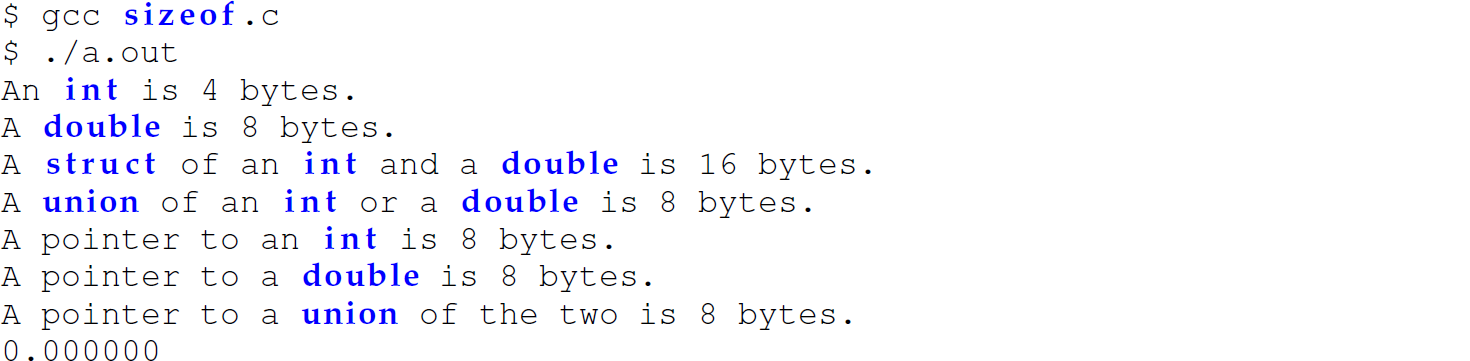
The C compiler allocates memory at least sufficiently large enough to store only the largest of the fields since the union can only store a value of one of the types at any time.1 The following C program, using the sizeof (<type>) function, demonstrates that for a struct, the system allocates memory equal to the sum of its types. This program also demonstrates that the system allocates memory sufficiently large enough to store only the largest of the constituent types of a union:
An identifier (e.g., employee_tag), if present, between the reserved words struct or union and the opening curly brace can also be used to name a struct or union (lines 8 and 17 in the following example). However, when declaring a variable of the struct or union type named in this way, the identifier (for the type) used in the declaration must be prefaced with struct or union (lines 14 and 22):
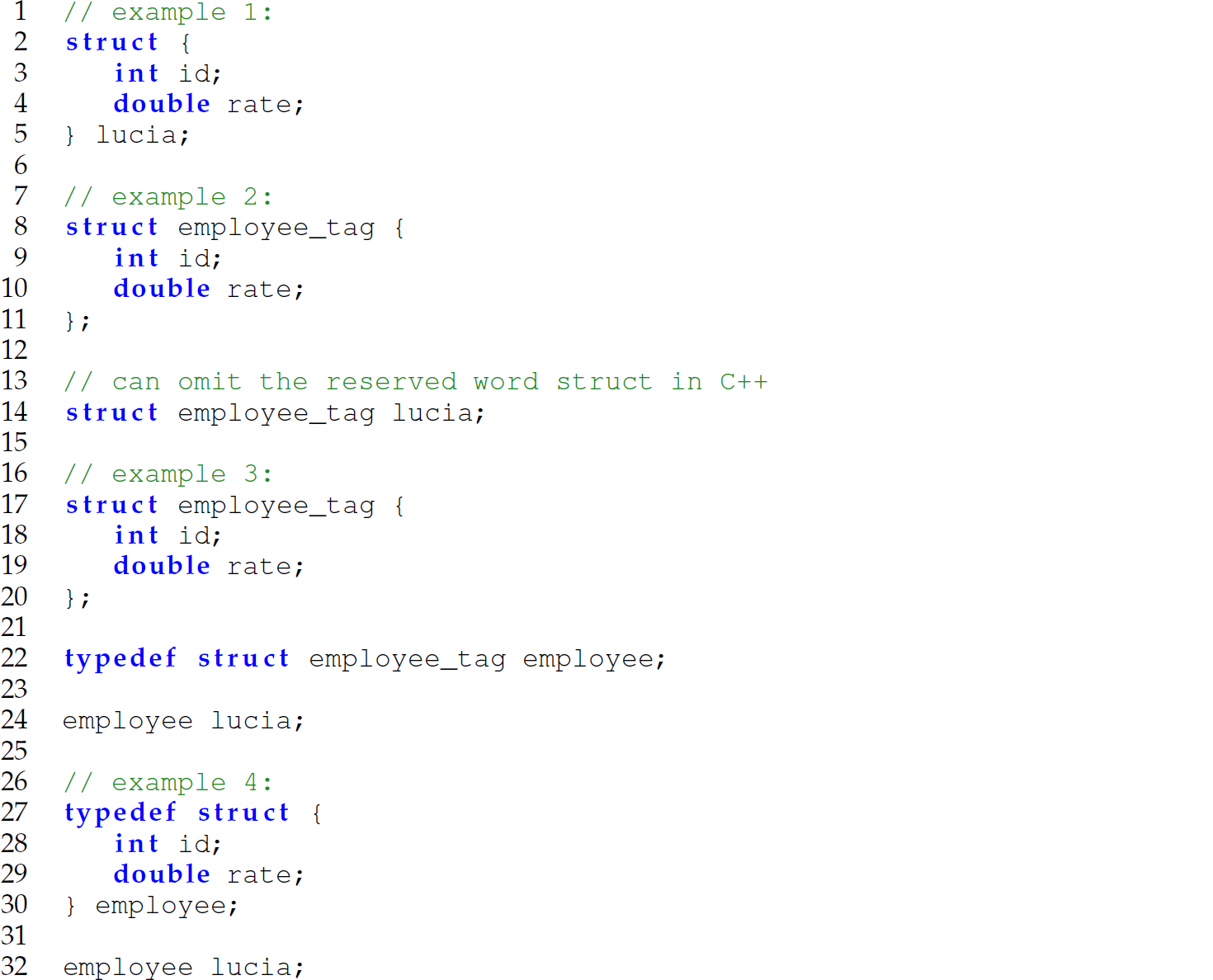
Each of the previous four declarations in C (or C++) of the variable lucia is valid. Use of the literal, unnamed type in the first example (lines 1–5) is recommended only if the type will be used just once to declare a variable. Which of the other three styles to use is a matter of preference.
While most readers are probably more familiar with records (or structs) than unions, unions are helpful types for nodes of a parse or abstract-syntax tree because each node must store values of different types (e.g., ints, floats, chars), but the tree must be declared to store a a single type of node.
9.2.4 Discriminated Unions
A discriminated union is a record containing a union as one field and a flag as the other field. The flag indicates the type of the value currently stored in the union:
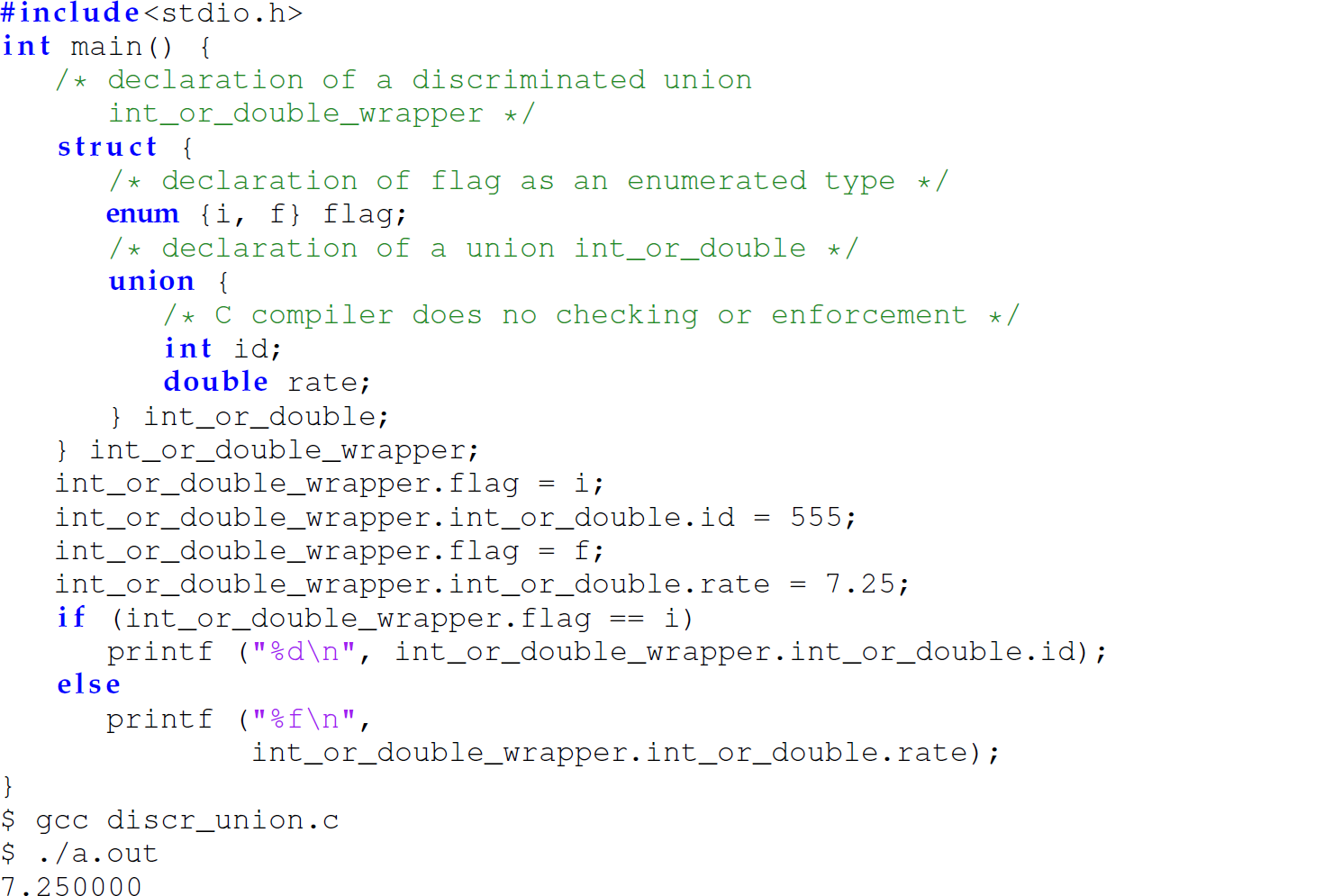
While we have presented examples of four types of aggregate data types in C, these types are not specific to any particular programming language and can be implemented in a variety of languages.
Programming Exercises for Section 9.2
Exercise 9.2.1 Consider the following two structs and variable declarations in C:

Do variables A and B require the same amount of memory? If not, why not? Write a program using the sizeof (<type>) function to determine the answer to this question, which should be given in a comment in the program.
Exercise 9.2.2 Can a union in C be used to convert ints to doubles, and vice versa? Write a C program to answer this question. Show your program and explain how it illustrates that a union in C can or cannot be used for these in a comment in the program.
Exercise 9.2.3 Can an undiscriminated union in C be statically type checked? Write a C program to answer this question. Show and use your program to support your answer to this question, which should be given in a comment in the program.
Exercise 9.2.4 Rewrite the ML program in Section 9.2.2 in Haskell. The two programs are nearly identical, with the differences resulting from the syntax in Haskell being slightly more terse than that in ML. See Table 9.7 later in this chapter for a comparison of the main concepts and features, including syntactic differences, of ML and Haskell.
1. Memory allocation generally involves padding to address an architecture’s support for aligned versus unaligned reads; processors generally require either 1-, 2-, or 4-byte alignment for reads.