
13.4 Extensible Markup Language (XML)
XML uses tags within a document as a markup language to describe each node within a tree structure such as that of CUSTOMERLIST in Figure 13.1. An XML document can be a standalone document, meaning that there is no information external to the document that defines the markup language. Users can also explicitly define the markup language by writing a Document Type Definition (DTD) or by writing an XML Schema Definition (XSD). A DTD provides a way to define the grammar for specifying the structure of an XML document. An XSD also defines the grammar and, in addition, provides a way to define the format and integrity of the data.
Domain-specific DTDs have been developed for several fields. They allow seamless data exchange between documents with the same DTD. For example, MathML (Mathematics Markup Language) is a widely used DTD for documents in mathematics, specifying both the display of equations and the meaning of mathematical expressions. Although DTDs are still used for specialized fields, XSDs have largely replaced them for many applications.
13.4.1 Standalone XML Documents
FIGURE 13.4 shows an example of an XML document that corresponds to the CUSTOMERLIST tree of Figure 13.1. As illustrated in the first line of Figure 13.4, an XML document can begin with an optional declaration that identifies the XML version used for the document, and, optionally, the coding system used. The most common coding system for XML documents is Unicode, identified by UTF-8. A document without a DTD or an XSD to define the markup language also states that it is a standalone document.

FIGURE 13.4 XML Instance Document Showing CustomerList
The declaration is followed by one or more XML elements, each of which has a start tag showing the name of the element, some character data, and an end tag. An element is the basic component of an XML document. Elements can be subelements of other elements. Elements must be properly nested, so that if an element’s start tag appears inside the body of another element, its end tag must also appear before the end tag of the enclosing element. The first element in an XML document must be a single root element, in which every other element is nested.
Figure 13.4 shows the root element CUSTOMERLIST, which contains all the information about customers. Within this element, the element CUSTOMER gives all the information about one customer. An element can also be empty, which can be indicated using the self-terminating tag <EMPTYELEMENT/>.
Elements can have attributes whose names and values are shown inside the element’s start tag. Note that CUSTOMER has an attribute named TYPE whose values appear as either Corporate or Individual, and an attribute named STATUS whose values appear as Active or Inactive. The attribute values are shown in quotes. The designer has a choice of whether to represent data using an element or an attribute. Attributes occur only once within each element, whereas subelements can occur any number of times.
We can insert comments wherever we wish in the document. A comment starts with <!-- and ends with -->, and can contain any explanatory text except the string --, as shown in Figure 13.4 for the second customer.
We can refer to external files, common text, Unicode characters, or some reserved symbols by using an entity reference. The reference begins with the ampersand character, &, and ends with a semicolon, ;. When the document is displayed in a browser, the reference will be replaced by its content. To include reserved symbols that have special meaning in XML, it is necessary to use the &...; as an escape sequence. These predefined entities are &, <, >, ' and ", which we refer to by their mnemonic names amp, lt, gt, apos, and quot. For example, to indicate the string
![]()
we would write
![]()
and to write
![]()
we would write
![]()
References are also used to insert Unicode characters in the text. For example, to insert the symbol ©, we write &00A9; because the Unicode character for © is 00A9.
An XML document, such as the one shown in Figure 13.4, is case-sensitive and is said to be well formed if it obeys the rules of XML. In particular, an XML document must conform to the following guidelines:
The document starts with an XML declaration like the one shown in the first line of Figure 13.4.
The document has a root element that contains all the other elements, such as the element CUSTOMERLIST in Figure 13.4.
All elements of the document are properly nested. If the start tag of an element occurs within another element, the end tag occurs within the element as well. For example, each NAME element is nested within the CUSTOMER element.
13.4.2 Document Type Definition (DTD)
A DTD is a specification for a set of rules for the elements, attributes, and entities of a document. An instance document that obeys the rules of its associated DTD is said to be type-valid. Processors can validate XML instance documents by checking their DTDs. Several instance documents can share the same DTD. FIGURE 13.5 shows a sample DTD that describes the structure of the instance document CUSTOMERLIST in Figure 13.4.

FIGURE 13.5 Possible DTD for CUSTOMERLIST Document of Figure 13.4
A DTD specification must obey the following rules:
The DTD is enclosed in <!DOCTYPE name [DTDdeclaration]>.
name is the name of the outermost enclosing tag, which is CUSTOMERLIST in our example.
The DTDdeclaration, which is enclosed in square brackets, gives the rules for documents that use this DTD.
Each element is declared using a type declaration with the structure <!ELEMENT (content type)>, where the content type can be other elements that are subelements of the declared element. In Figure 13.5, the element CUSTOMERLIST has the subelement CUSTOMER; the element CUSTOMER has the subelements NAME, ADDRESS, and TELEPHONE; and the elements ADDRESS and TELEPHONE, in turn, have subelements.
The type of an element is #PCDATA, which means that the element value consists of parsed character data. In Figure 13.5, the element NAME has this content type, as do STREET, CITY, STATE, ZIP, AREACODE, and PHONE.
The empty element is indicated by <EMPTYELEMENT/>.
The symbol ANY can be used to indicate that any content is permitted.
The name of any subelement can optionally be followed by one of the symbols *, +, or ? to indicate the number of times the subelement occurs within its enclosing element. The meanings of each symbol are as follows:
* The element occurs zero or more times. In Figure 13.5, CUSTOMER elements can occur zero or more times, indicating that a CUSTOMERLIST could have no customers or many.
+ The element occurs one or more times. In Figure 13.5, ADDRESS can occur one or more times for each customer.
? The element occurs zero or one times. In Figure 13.5, TELEPHONE occurs zero or one time for each customer. The use of ? is different from the use of * by limiting the occurrence to one time only. In Figure 13.5, the DTD defines that a customer can have no phone number or only one phone number. If the specification is changed to TELEPHONE*, a customer can have no phone number or many telephone numbers.
Attribute list declarations for elements are declared outside the element. An attribute list declaration specifies which elements have attributes, the name of each attribute, the data type, possible values (optional), whether the attribute is required, and the default value, if any. An attribute list has the form <!ATTLIST elementName attName (attType) default>. Several attribute types exist, including string types and enumerated types. The string type is declared as CDATA. An enumerated type is shown by listing all of its possible values. An attribute declaration can also have a default specification. A required attribute is identified by writing #REQUIRED. If the attribute is not required, a default value may appear. The default value will be provided when no other value is specified for the attribute. In Figure 13.5, the CUSTOMER element has two attributes, TYPE and STATUS. The TYPE attribute is required and is an enumerated type having the possible values Corporate and Individual. The STATUS attribute is not required and has the possible values Active and Inactive, with Active being the default value.
A DTD can be external, which means it is stored separately from the instance documents that use it, or internal, embedded in the instance document. Using the DTD in Figure 13.5, the instance document in Figure 13.4 can be modified as follows for the internal format, where the DTD is embedded within the instance document

An external DTD is stored as a text file with a .dtd extension. The advantage of using an external DTD is that it can be used to specify the structure of many instance documents. Each document instance that uses an external DTD must contain a declaration identifying it by giving its name and storage location. For the instance document in Figure 13.4, the format for reference to the external DTD in Figure 13.5, which is stored in the file customerList.dtd, would be

This reference to the DTD assumes that customerList.dtd is in the same directory as the XML file. Otherwise, the directory path to the DTD file should be included as part of the file name in double quotes. When the instance document is opened in a browser, the user is given the option to see the source code for the DTD.
13.4.3 XML Schema Definition (XSD)
An Extensible Markup Language (XML) Schema Definition (XSD) is a more powerful way to describe the structure of documents than a DTD. It permits more complex structure, additional fundamental data types, user-defined data types, and user-created domain vocabulary (namespaces); it also supports uniqueness and foreign key constraints. An XSD defines the organization and data types of an XML structure. If an instance document conforms to an XSD, it is called schema-valid.
XSDs are themselves XML documents, and they can be schema-validated against the standards provided by the World Wide Web Consortium (W3C), as specified at w3.org. The W3C website contains an XML standard schema document for all user-defined XSDs. There are several sites and open-source software applications that can validate schemas, allowing users to upload documents to ensure that they are valid. XML schemas are a very large topic, and a comprehensive treatment of them is beyond the scope of this book, but a brief introduction to provide the basic flavor of an XSD follows.
A simple XSD is shown in FIGURE 13.6. Like a DTD, an XSD lists elements and attributes. Elements may be complex, which means they have subelements, or simple. In Figure 13.6, the element CUSTOMERLIST is a complex type, consisting of any number of CUSTOMER elements. CUSTOMER is also a complex-type element, consisting of NAME, ADDRESS, and TELEPHONE. NAME is a simple element of string type. ADDRESS is a complex type consisting of the simple string-type elements STREET, CITY, STATE, and ZIP. TELEPHONE is a complex type consisting of the simple string-type elements AREACODE and PHONE. CUSTOMER has two attributes, TYPE and STATUS. TYPE is a required attribute that is an enumerated type. Its base type is string, and its possible values are Corporate or Individual. STATUS is a string type with the default value of Active.

FIGURE 13.6 Possible XSD for CUSTOMERLIST Document of Figure 13.4
Attributes or elements can be used to store data values. Attributes can be used for simple values that are not repeated, such as TYPE and STATUS. Elements can be complex or simple and can occur multiple times. TYPE and STATUS could be represented as elements instead of attributes, as shown in the alternate XSD of FIGURE 13.7.

FIGURE 13.7 Another XSD for CUSTOMERLIST
An instance document for the XSD of Figure 13.7 is shown in FIGURE 13.8. The following information in the CUSTOMERLIST tag tells the parser that the document should be validated against an XSD
![]()
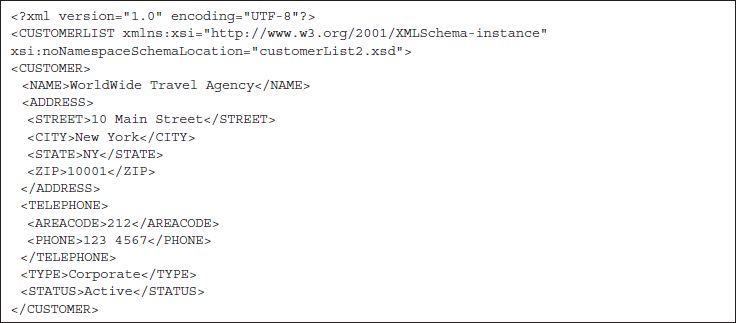

FIGURE 13.8 Instance Document for CUSTOMERLIST Schema of Figure 13.7
The location of the schema is specified in the following information within the CUSTOMERLIST tag
![]()
where customerList2.xsd is the file name of the XSD shown in Figure 13.7 and the .xsd extension indicates that the file is an XSD. Because no path name is specified as part of the file name, the file is assumed to be in the same directory as the XML file shown in Figure 13.8. We will assume that the name of the XML file is customerList2.xml, where the extension .xml indicates that the file is an XML document.
The main difference between the instance document in Figure 13.8 and the instance document in Figure 13.4 is with respect to the TYPE and STATUS attributes. In Figure 13.8, TYPE and STATUS are represented as elements, as defined in the schema of Figure 13.7

In the instance document of Figure 13.4, which corresponds to the schema in Figure 13.6, TYPE and STATUS are attributes within the CUSTOMER tag

13.4.4 XML Data Manipulation
XQuery is the current W3C standard query language for XML data. It uses the abstract logical structure of a document as it is encoded in XML, possibly in a DTD or an XSD. There are numerous tools and browsers identified on the W3C website that support the use of XQuery.
XPath Expressions
Query expressions in XQuery use the notion of a path expression, which comes from an earlier language, XPath. A path expression usually consists of the name of the document and a specification of the elements to be retrieved, using a path relationship. An example of a path relationship expressed over the CUSTOMERLIST document of Figure 13.8 is
![]()
The expression uses the doc function to specify the file name of the document that is to be searched. The expression also includes one or more steps specified by / or //. The separator // means the next element can be nested anywhere within the preceding one (i.e., any descendant of the preceding node), while the separator / means the next element named must be nested immediately under the preceding one (i.e., in the graph of the document, it must be a child node of the preceding one).
The steps in the path expression cause reading to advance through the document. The nodes of the graph for a structured XML document are ordered using preorder traversal, which is a depth-first, left-to-right order. For an XML document, the entire document is the root node, which is followed by element nodes, other node types (that are not discussed here), and attribute nodes. Each element precedes its children, and all children of an element node precede the node’s siblings. The nodes of the entire document are seen to be totally ordered by the language processor.
In FIGURE 13.9, the numbers in the nodes show the order in which each node is encountered using normal (forward) traversal. Each node is given an object identifier based on this order. In the instance document in Figure 13.8, the nodes are listed in the same order. The path expression is normally evaluated by reading forward in the document until a node of the specified type is encountered. For the path expression in this example, the first customer node is found and the name of that customer, WorldWide Travel Agency, is targeted. The result of traversing the entire document displays the following nodes:

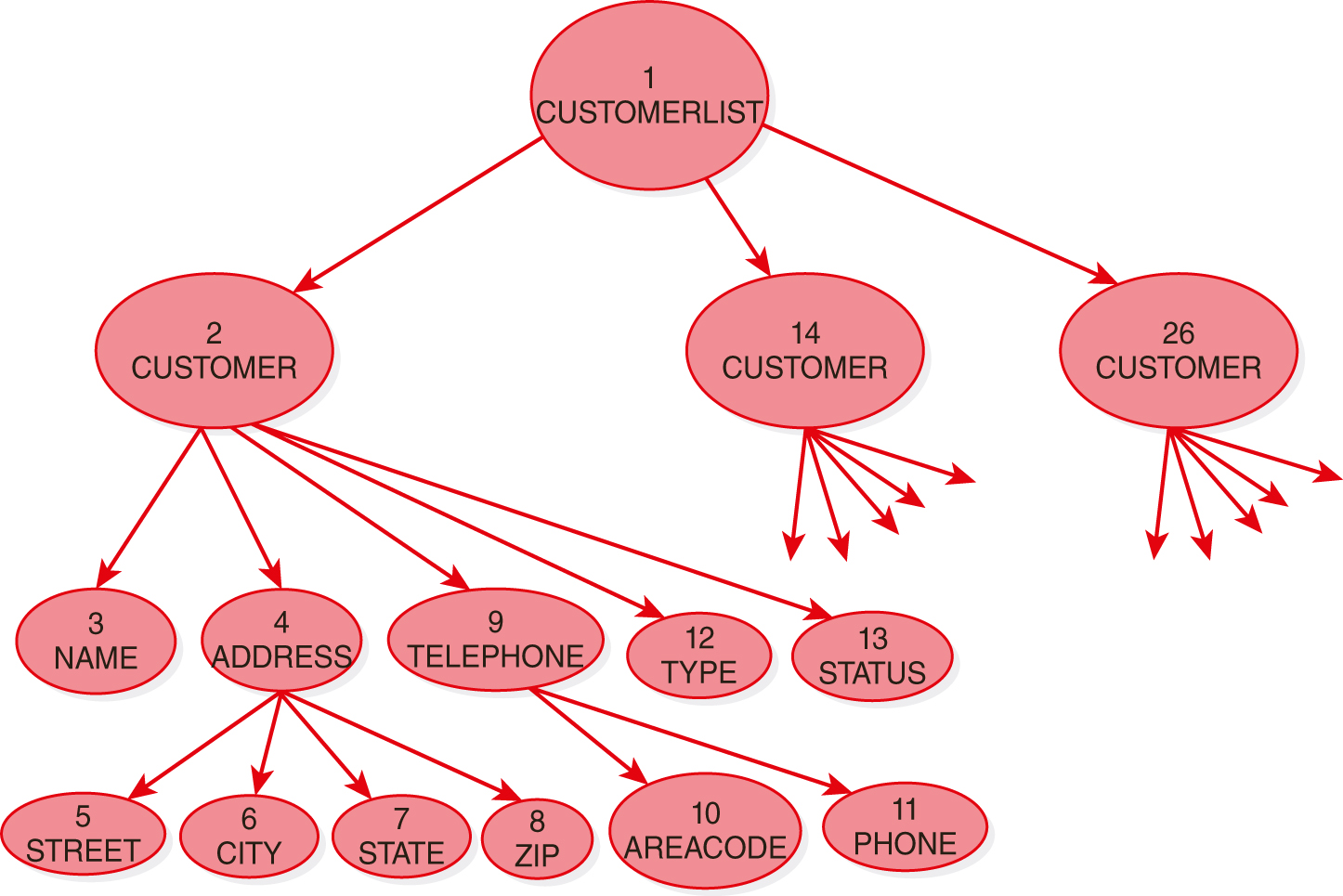
FIGURE 13.9 Preorder Traversal of a Graph
We can add conditions to any of the nodes in a path expression. For example, if we write
![]()
the first node that satisfies this condition is the ADDRESS node of the second customer. The condition forces the reading to advance through the nodes of the document until it finds one that satisfies the condition. The result of the this conditional XPath expression is

XQuery allows both forward and backward directions for reading. The user can specify an axis or direction for searching. A forward axis allows a search for a child, descendant, self, attribute, following sibling, and so on, and is indicated by / or // separators. A reverse axis allows a search for a parent, ancestor, self, preceding sibling, and so on, and is indicated by a .. separator. The notation for specifying XPath axes can be found at w3schools.com. In the examples that follow, we will illustrate the default forward direction using the / and // separators.
FLWOR Expressions
XQuery uses a general form of query specification called a FLWOR expression. FLWOR, pronounced flower, stands for for, let, where, order by, and return, which are the clauses found in such expressions. FLWOR expressions allow for binding of variables to results and for iterating through the nodes of a document. They also allow joins to be performed and data to be restructured. The let, where, and order by clauses are optional, depending on the conditions of the query expression.
As a simple example, consider the following query

The variable $N is bound to each STATE node in the XML file. Query evaluation begins by reading the root node, then advancing to the first CUSTOMER node, then advancing to the ADDRESS node that is a child of the customer, and then the STATE node that is a child of the address. This node becomes the context node, also called the current node, which is bound to the variable. From this position, reading advances to the next STATE node, which becomes the new context node, and so on. The query constructs a list of states, and the RETURN clause is used to display the values to which $N is bound
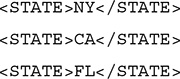
Queries can make use of the where clause to express conditions on the nodes, as in the following query
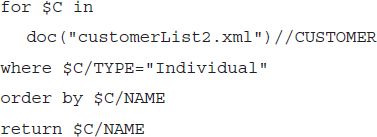
which produces the return value

The results are ordered alphabetically by NAME, as specified in the query. If no order is specified, results appear in the order in which they are encountered in the document.
The previous query expressed a condition on TYPE, which is used as an element in the instance document of Figure 13.8. Recall that TYPE is used as an attribute of the CUSTOMER element in the instance document of Figure 13.4. To express the same condition for TYPE as an attribute, the query is expressed as

where the @ symbol precedes TYPE to indicate a reference to an attribute rather than an element.
The query examples so far have returned a single element type. To return more than one element, create an enclosing tag for the return value and use curly braces around the list of elements to return. As an example, the following query returns the name and state of each customer of type Individual from Figure 13.8

The output of the query is

Constructing New Documents
XQuery supports the ability to construct new HTML or XML nodes. It also supports the join of multiple documents.
As an example of constructing new XML nodes, the following query returns a result that includes the NAME and STATUS of individual customers from the instance document in Figure 13.8

Because we are constructing new nodes, the return statement creates a new <RESULT> tag to enclose each output value. The data function is then used to extract the values (and not the original tags associated with the values) that we want to see in the result. Notice that use of the data function is enclosed in curly braces and embedded inside of new tags that we create for each data value in the result. The output produced by the above query is

To illustrate the use of XQuery to create a new document through the join of existing documents, let the XSD shown in FIGURE 13.10 describe a second XML document that represents orders placed by customers. An instance document is shown in FIGURE 13.11. The query “Find the name and address of the customer for each order” requires a join of these documents. We can use XQuery to form a join of the CUSTOMERLIST document with the ORDERSLIST document as shown below

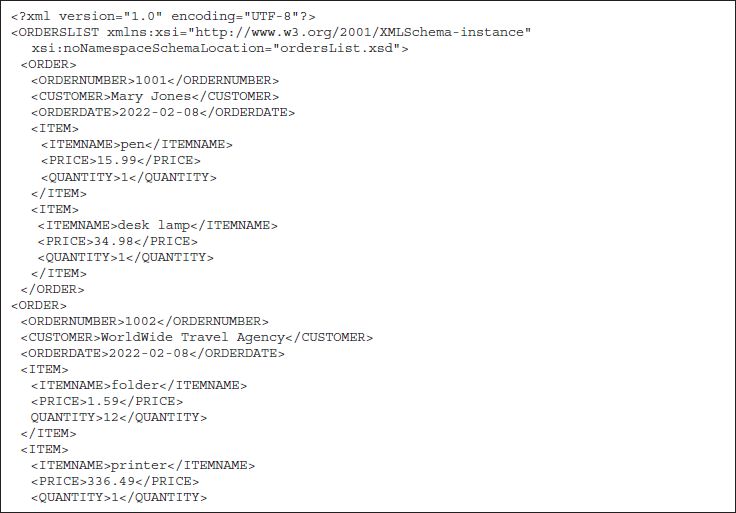
FIGURE 13.10 XSD for ORDERSLIST


FIGURE 13.11 Instance Document ORDERSLIST
The output of the previous query is

The result of executing the query constructs an XML document consisting of ORDERCUST elements, each of which has an order number, customer name, and customer state, arranged in order by the customer name. The condition [NAME=$O/CUSTOMER] specifies that the NAME node of the CUSTOMER element in the CUSTOMERLIST document matches the CUSTOMER element in the ORDERSLIST document, which is a join condition. The FLWOR expression is also enclosed in curly braces within the <RESULT> </RESULT> tags to create a new root tag for the result.
XQuery provides many predefined functions, including count, avg, max, min, and sum, which can be used in FLWOR expressions. Complete details of the current specifications for the language can be found on the W3C website.
13.4.5 XML Parsers
For XML to be used in an application, it is necessary to parse XML documents. An XML parser reads in the XML document as a string and uses a parsing technique based on either an event-driven model in which only a single pass is made through the document, or a tree-based model in which an entire parsing tree is built in memory. Parsers that implement slight variations of these two basic models also exist.
Document Object Model (DOM) is a W3C standard for the tree-based model, which implements the semistructured data model as shown in Figure 13.1, with nodes representing the elements of the XML document and the data. The parser has methods to restructure the tree, create nodes, modify nodes, and delete nodes. The DOM stores the entire tree in memory, which consumes both time and memory, but which allows the programmer to navigate the tree structure as needed and supports dynamic data updating.
Simple API (Application Programming Interface) for XML (SAX) parsing uses the event-driven model. As the parser reads the XML document and recognizes each fragment of XML syntax, it streams a series of events, which are sent to event handlers for processing the elements or data in the document. The basic types of event handlers are document handlers for processing DTDs, XSDs, and data, and error handlers for accessing errors generated in parsing. This approach is faster and less memory intensive, but because each fragment is seen only once, in document order, it does not permit revisiting or modification of segments.
A special type of language that is used in conjunction with XML parsers is Extensible Stylesheet Language Transformations (XSLT). XSLT is a declarative programming language that is used to transform XML documents into other formats. For example, XSLT can be used to transform one XML document into another XML document with a different format. XSLT can also be used to transform an XML document into HTML format for display on the web, or into the format of JSON documents as described in Section 13.3. An XSLT processor takes as input one or more XML documents, together with one or more XSLT stylesheets. A stylesheet uses pattern matching to match nodes within the tree structure of the XML document, using XPath to express the pattern to be matched. Templates are then applied to transform the matched nodes into the new target format. XSLT is part of the W3C standard for XML data. Tutorials on the use of XSLT, as well as all components of the XML standard, can be found at w3schools.com.