
![]()
The Motivation to Create an API
Designing an API is neither easy nor cheap. Trying to create an API is definitely more work than releasing a product without any API at all. Still, in the context of “cluelessness,” the main message of this book is that with a proper API, you can design better systems while minimizing your own understanding of them. Properly designing and using the APIs of individual components of the system can improve the system engineering methodologies used to design them. Improving your system engineering skills is a way to maximize the benefits of cluelessness.
The cluelessness model is based on using big building blocks collected from software projects all over the world. By reusing as much as possible, and not writing everything entirely inhouse, product teams can concentrate on the most important differentiator: the actual logic of their application. They no longer need to spend time creating and writing the infrastructure; instead, they can reuse frameworks and other useful libraries produced by others. Nobody writes an SQL database server in-house anymore. People reuse database servers provided by established commercial vendors or emerging open source alternatives. Bothering with an implementation of an SQL database server for private use would be seen as an ineffective waste of resources. The same is happening in many other areas of software technology. Web and application servers, languages and their libraries, integrated development environments (IDEs), and rich client application frameworks are all becoming well-established building blocks. Just like prepackaged dinners or prefabricated blocks of apartments, they can just be taken off the shelf, assembled, and then polished as needed. This approach greatly shortens the development time necessary for producing a software system.
When assembling the whole application, you need to glue together individual building blocks. These blocks need to talk to each other somehow. Usually they do so by means of well-defined APIs. Each component’s API is an initial step toward increasing your cluelessness. It isn’t necessary to understand and know all the internals of each component; it’s usually enough to read the component’s documentation and use its API to include it successfully in your own application. The API minimizes the need to understand every detail of a component serving as a building block.
ABSTRACTIONS LEAK!
An API can be seen as an abstraction over the functionality and internal implementation of each component. Usually it’s enough to understand just the abstraction, but in some cases the internals of a component “leak out” through an API. As an example, let’s look at a filesystem abstraction. A common filesystem is a set of files and directories organized in a tree-like hierarchical structure. Knowing a resource, you can ask either for its content, or for a list of subresources. The content is represented as a stream. This is a well-known abstraction used in almost all operating systems available today. It helps isolate common application programmers from the internals of dealing with the actual storage and type of a filesystem. To read a file, it is not important to know whether it comes from a hard drive, CD-ROM, flash disk, or network. The abstractions are always the same.
However, sometimes the actual implementation behind these abstractions leaks out. For example, when dealing with flash drives, the disk can disappear while reading its content, as the end user unplugs it. Or, in the case of a network, you can observe big latencies if the network is slow or of poor quality. In these situations, you need to understand not only the abstraction, but also, at least partially, the implementation behind it.
On the other hand, this is quite acceptable from the viewpoint of selective cluelessness. The common API is just a basic abstraction and serves its function when you don’t care about latency or crashes when trying to read files from removed disks. If you care, then there are more advanced ways to detect and adapt to such situations. Therefore, the filesystem API helps us to be clueless, but it does not prevent us from increasing our knowledge when necessary. This should be true for any functioning API.
A typical application doesn’t consist of one or a few libraries. The applications developed today make use of many open source libraries available all around the world. The set of open source offerings starts with a Unix-like kernel, base C libraries, and command-line utilities. It continues with web servers and web browsers, to Java utilities such as Ant, Tomcat, JUnit, JavaCC, and many more. In fact, each of these libraries has its own API, and as a result, everyone writing such software is in the API design business, whether they are cognizant of the fact or not.
This kind of assembly approach is a common model of operations for Linux distributions. The software is written by various people, then simply taken, packaged, and glued together. Usually the distribution vendors write the central management utilities and provide some quality assurance to make sure all the selected components work well together. This seems to work well for most vendors and users, and it helps lower the cost of creating a distribution. As evidence of the success of this model, let’s note that Mac OS X is a FreeBSD Unix distribution with a bunch of add-ons from Apple.
Distributed development has its own specifics. The most obvious is that the source code for the whole application is no longer under the developer’s complete control. It is spread around the world. Building software in this way is unquestionably different from building an application entirely from source code within your in-house source repository.
You need to be aware that in this model you don’t fully control the whole product’s schedule. Not only the source code, but also the developers, are spread around the world and are working on their own schedule, which you cannot fully control. However, the situation is not as unusual or dangerous as it sounds: anyone who has tried to schedule a project with a team of more than 50 people knows that the idea that you ever have “full control” is at best a comforting illusion. You always have to be ready to drop a feature or release an older version. The same model works with distributed development. The basic right everyone has is the freedom to use newer or older versions of a library.
In fact, open source is not the only driving force behind the growing need for good APIs. Commercial vendors also produce a lot of shared libraries and frameworks. Many of them either implement existing standards, such as SQL, or provide their own APIs. However, the open source movement with its liberal licensing schemes has become the primary source of components to use as reusable building blocks. The open source solutions are well known by end users who can use them without any fee. However, because there are no licensing restrictions, they are also important for developers. It’s easy to take an existing component and use it as part of your own application. It’s almost always just a matter of time before someone does it. This means that every open source component sooner or later is going to need an API. These components are developed by a range of developers, from university students starting their own projects, to longtime developers playing with their own toy projects, to developers working for and being paid by companies that see the open source style of development as a business opportunity. These people have different skills and different working styles. Regardless, it’s important to create good APIs, because APIs are the first step to clueless usage of their libraries. The more libraries and frameworks we have, the better. However, it’s almost essential for the success of clueless reuse to let the APIs closely reflect the internal spirit of such libraries. That’s why API design is important, and that’s one of the main motivations for this book.
Modular applications are comprised of individual components developed by highly distributed teams. These components often provide an API, but they also require certain APIs or other features in their execution environment to be able to function properly. For example, a Tomcat server requires an implementation of the Java runtime. Similarly, the standard C++ templates library needs libc so that it can call printf. When the number of components becomes extensive, one of the most important challenges is to be able to see the whole picture. Only then are you able to “understand” the whole system, so that all its mutual component interactions are satisfied. We saw in the previous section that component APIs allow us to selectively choose what is important—ignore the internals in most cases and just concentrate on the APIs. However, if hundreds or thousands of components are in the system, even this is still too large an amount of information to be handled cluelessly. That’s why we’ll now look at possible ways to improve your ability to assemble a working system from these components, while minimizing your understanding of them.
The first and foremost lesson to learn is that you need names for your components. These names have to be unique, have to identify the component in the system, and should be descriptive. kernel is a good name for the Linux kernel; libc is a fine name for the basic C library; org.netbeans.api.projects is a perfect name for a NetBeans component describing how to work with projects. Generally, all existing components have a name, so it seems natural to expect that they need to have one. However, when you look at this aspect more closely, you can see that these names are more important for humans than for machines. If they were meant just for automatic processing, then you could simply use some hexadecimal form, such as 0xFE970A3C429B7D930E. The fact that components usually share human names is proof that they’re targeted primarily at people. Names are useful to customers and end users who use them to discover the functionality they should pull from the provider. They are also useful to providers and their assemblers who use these components to build their applications.
When you know how to name the individual components that you operate, it’s time to look at the required environment for each component. No component can live in a vacuum. It will inevitably require services from its surroundings. Once again, it’s possible to fully understand the actual needs of each component, most accurately by inspecting its internal implementation—or, even better, by observing what it needs from its environment during its execution. However, this is far from the selective cluelessness mode of operation, because it would imply that the assembler knows nearly every detail of each library, before using them as building blocks for newly created applications. If this was necessary, then it would be a massive showstopper to the acceptance of a library. In fact, most users of a library have little clue what is going on inside of it. That’s how it should be. They should have just a minimal understanding and still be able to get their job done. That can be achieved by properly writing and describing individual components. If each component carries the information about its required environment in such a way that it can be automatically processed, then the assembler can be as clueless as possible, because the necessary environment can be inferred without human interaction with compilers, linkers, or assembly time tools.
Each component in a modular system carries information about all the other components it requires. The author of the component needs to specify this set of information only once, or in certain cases the packaging tools may infer it automatically. For example, rpmbuild, the system used by Linux distributions such as Fedora, Mandriva, and SUSE to create individual packages of their distributions, automatically inspects each native dynamic library to discover which other libraries it is using and automatically adjusts dependencies on the packages that provide these libraries. Regardless whether this is done automatically or manually, this is done just once. It can be done by the developer who produces the individual component: the one who knows its internals, understands its required environment, and can correctly specify its dependencies. This is yet another example of selective cluelessness: one engineer thinks hard and spends time on specifying the component dependencies. Then all the users of such components—those assemblers of final applications or other developers who just want to depend on the component’s presence—can just cluelessly specify a dependency on the component’s name and let the automatic system handle the rest.
THE CLASSPATH ASSEMBLY NIGHTMARE
The days when every Java application was written on top of plain Java are gone forever. The set of useful open source libraries for Java is huge and growing daily. As a result, nearly every Java application written these days depends on an already written and packaged JAR, such as Apache Commons, HttpClient, JUnit, Swing widgets, and one or more of many others. Indeed, to start such an application, you need to set up its classpath correctly. It’s easy to include all the directly used libraries, but each of them often has its own additional dependencies that need to be satisfied as well, together with dependencies of these dependencies, and so on, which can turn into quite a dark nightmare.
Recently I had the opportunity to include FreeMarker, a nice templating engine, in the NetBeans sources as a library. Including the freemarker.jar was easy, but when I tried to verify that all its classes could be linked successfully, I was unpleasantly surprised. The JAR had additional references to many other projects, including Apache Ant, Jython, JDOM, log4j, and Apache Commons Logging. Were all these projects the required environment for FreeMarker? Or could FreeMarker run without these libraries? If the latter, what kind of functionality could trigger these classes or in fact crash execution? I didn’t know, and in fact I didn’t want to know. I wished I could be clueless; however, I could not. I needed to inspect the sources and verify that these classes were not used during our regular usage of FreeMarker. I prayed for FreeMarker to use some modular system to specify its needed dependencies, such as the one used by the NetBeans Runtime Container.
The technological answer to the challenges of distributed development is modularization of applications. A modular application—in contrast to one monolithic chunk of tightly coupled code in which every unit may directly interfere with any other—is composed of smaller, separated chunks of code. These are well isolated and uniquely identified, expose well-defined interfaces for others to use, and carefully describe the environment (such as the need for other components or units to function correctly) that they need to function correctly. It is believed, and also revealed by the Linux distribution vendors, that separate teams can then develop those chunks with their own life cycle and their own schedule. One central authority (the distributor) can then assemble the results, and this style of work helps to minimize risks related to schedule and team separation. Also, it allows operation in clueless mode: if developers producing their units manage to describe their dependencies correctly, the people assembling them need to have little to no knowledge about the component’s internals and still successfully compose the final application.
However, a new challenge is on the rise. Components are evolving. They aren’t static; they change. Due to bug fixes, enhancements, and new features, an API potentially changes on a continual basis, and as a result it isn’t enough to use just a name to identify it uniquely. To make sure that those independent components work together, you need to identify which API the component is actually supposed to offer.
For example, if a class written in Java references the String.contains(String) method, then it can run on Java 5, as that version of Java provides this method on the String class. However, it can also run on Java 6, as the same method is available in that version of Java as well. Due to the compatibility policy of the Java team, it also remains available in the latest builds of Java 7. On the other hand, such a class cannot run on older versions of Java, as those did not provide that method. Therefore, the class cannot be correctly linked in those Java versions.
In fact, when you need to capture the exact requirements of a class or of an application, you must enumerate all the methods that it calls, and all the classes and fields it references. Of course, such a description of dependencies would be too verbose, unreadable, and sometimes even larger than the actual source code itself. Just imagine a class saying, “I need a version of Java that provides java.lang.String with a constructor and length and indexOf methods, and my class also depends on java.io.Serializable, which it implements,” and so on. Indeed, such a detailed specification of the actual version of some component goes directly against the cluelessness approach that I want to emphasize. Even though a machine could verify these constraints automatically, for humans these are too hard to use. Humans prefer simple schemes; for example, using natural numbers to number each revision of a component. That way you would simply be able to say, “Give me Java 5 and my library will be fine.”
However, simply using numbers can also lead to complications. Imagine that you want to assemble your application from component A (which defines a dependency on Java 5), and component B (which defines a dependency on Java 6), as visualized in Figure 2-1. In this case, there can be just one Java running both A and B, so the question is which one to use. To solve this problem, most API development models work with the concept of compatibility. Usually this means that if some API is introduced in version N, it will be there in subsequent versions N+1, N+2, N+3, and so on. This solves the example in the figure, and means that the assembled application should run on Java 6: component B needs it explicitly, and component A requires just Java 5, but will also work in Java 6 due to the compatibility between these two versions. Indeed, this greatly simplifies the lives of the people assembling the final application. They can be pretty clueless when composing. Everything needs just one “little” prerequisite: to maintain backward compatibility. This is not a small task at all. It’s pretty complex, not something that can be done cluelessly, and therefore something that will be the center of our attention throughout this book. This is part of the “selective cluelessness” that we need to concentrate on: to maximize our cluelessness when assembling big applications from components created by distributed teams, we need those teams to develop the individual components and their APIs carefully, and moreover to do that in a compatible way.
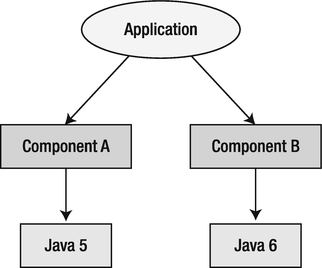
Figure 2-1. An application that needs two different versions of a component at once
The most frequently used software numbering system isn’t based on natural numbers. Instead, people use a dot-separated decimal system. This is needed to accommodate nonlinearities in software development, where there is no single direction of development, but many branches representing bug-fix releases, and bug-fix releases of bug-fix releases, and so on. As Figure 2-2 shows, a version such as 1.1.1—which you’d expect to contain less functionality than version 2—can in fact be released later than version 2.
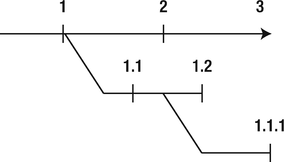
Figure 2-2. Version numbering forms a tree.
Each piece of a modular application has a version number, usually a set of natural numbers separated by dots, such as 1.34.8. When a new version is released, it should have a new and larger version number (according to lexicographic order), such as 1.34.10, 1.35.1, or 2.0.
You can express dependencies on other components of the modular system by specifying the identification name of such a component and the minimal needed version. You can request the presence of an Extensible Markup Language (XML) parser, installed database driver, text editor, or web browser, all of these providing a specific version of their interfaces. For example, a piece of functionality could require xmlparser >= 3.0 or webbrowser >= 1.5, and so on. This assumes full compatibility: that is, it is expected that the assembled system will work fine even with newer versions of its modular units.
Trying to encode the whole history of a library’s changes into a single version number seems a bit silly. Nevertheless, it is reasonably practical and, most importantly, it allows you to reach limitless levels of cluelessness, while giving the individual developers of each library a chance to encapsulate sets of changes into easily recognizable numbered versions.
Using a dependency scheme can work only if certain rules are followed. First, if a new version is released, all contracts that worked in the previous version will work in the new one as well. Of course, this is easier to say than do—otherwise nobody would need a quality assurance department. Rule number two is that as soon as a set of external dependencies changes, you need to communicate that. Therefore, if a piece of a modular system starts to rely on new functionality, such as an HTML editor, it needs to add a new dependency htmleditor >= 1.0. Also, if you start to use new features of a web browser introduced in version 1.7, you need to update the dependency to require webbrowser >= 1.7.
Some versions of components can contain bugs that need workarounds. For this reason, a secondary version—an implementation version—is usually associated with a component. In contrast to the specification version, this is usually a string, such as Build20050611, and can only be tested for equality. This is usually better for working around bugs because the fact that a bug is present in (specification) version 3.1 doesn’t mean it will also be in version 3.2. That’s why, for reasons of bug fixing or special treatment of certain versions, associating an implementation version with a library can be useful.
The system of versions and dependencies needs a manager to ensure that all requirements of every piece in the system are satisfied. Such managers can check when installing each piece that everything in the system will remain consistent. This is how Debian or RPM packages work in Linux distributions where the dpkg and rpm commands are used for installation and uninstallation of software packages. However, you can also use such dependencies to handle certain runtime aspects during execution.
For example, any NetBeans-based application is composed of modules that are loaded at runtime. The NetBeans module system uses the declared dependencies not just to find out what components need to be present, but also to determine the parent ClassLoaders needed for each module, thus isolating the selection of components from the composition of their classpath. This system also provides individual class loaders to each component, ensuring classpath isolation of independent modules. It also enforces the declared dependencies of each component: a module cannot call code in a foreign one unless it declares a dependency on that foreign module, and it won’t be loaded at all if some of its dependencies cannot be satisfied.
At this point, the contours of our ideal application should be clear. They are based on the concept of cluelessness, trying to take it to the limit for those who do the final assembly of an application. As a result, our ideal application is based on a modular architecture. It expects that each module is written by different groups of people spread around the world. It accepts contributors operating on their own schedules and doing their work for their own interests to fulfill their own goals. Such a setup clearly reveals the main problem.
Most modules don’t exist in isolation. They rely on an environment provided by other modules. Only a limited set of functionality can be written in a vacuum without using APIs someone else provides. In fact, most modular components need services offered by others. This means that the developer writing such modules needs to discover and understand how to use an API provided by a foreign module. As the other module is also written by a programmer, we’re facing a potential communication problem.
APIS ARE NOT FOR MACHINES
It took me a long time to realize that the primary target of an API is not the computer, but a human: the developer. My original expectation was the opposite. In fact, when you think about compiled programs, their primary and in fact only desired consumer is the computer. Programs are written and then compiled to be executed. As a result, it’s reasonable to expect that a programmer is supposed to communicate with the computer.
However, this isn’t true in the case of APIs. APIs are verbose, documented, and, in fact, very different from what a computer needs. When I realized this, I found that it isn’t enough to use the common coding practices I learned while being taught to program in school. Designing APIs is different. I hadn’t been taught to do it and I have a feeling that other programmers haven’t been taught to do it either.
The producers of shared libraries and various frameworks need to contact their users. They need to talk to developers who can potentially use their libraries. There are many ways to communicate. For example, they can exchange e-mails and participate in conference calls, but this requires face-to-face or ear-to-ear interaction. However, the most commonly used communication channel is the API itself and its documentation. It is the document that users of the API find and study most of the time. If the development of a modular application is to be successful and effective, a clear and easily understood, well-documented, and as far as possible, self-documented API is needed. This is what will facilitate the work of individual developers, regardless of where they are physically.
Such an API has to be based on shared knowledge and has to be easily understood by its potential users. If it is to be reliable, it must prevent its own misuses and has to be ready for evolution: few if any APIs are perfect in their first incarnation. Much of what we need to discuss here is how to avoid mistakes that will limit the possibility of improving an API in the future.
The important condition here is separation. With separation comes the need for rules for designing and maintaining an API. If there was no separation and the whole product was tightly coupled, built once and forgotten, there would be no need for bothering with an API. But because real-world products are developed in a modular manner, with componentized architecture and teams that don’t necessarily know about one another, operating according to independent schedules and building their projects independently, there is a need for a stable contract that can be used for such communication.
NOT ALL PROJECTS NEED API-LIKE QUALITY
Some time ago I talked to my cousin about our work, the projects we work on, and the way we organize them. I introduced him to the concept of cluelessness and the proposition that more selective cluelessness can help us create more reliable software systems. We agreed on that point for the most part, though he presented a slightly different point of view.
Sometimes, especially when delivering end-user functionality, it doesn’t seem necessary to strive for an API-like quality of code. The user of the system is “only” human, and humans are often more tolerant of slight errors than automated systems. Moreover, it’s unlikely the system will ever change after its deployment. It serves for a few years and then, if necessary, can be replaced with one that is completely rewritten, or actually assembled, from scratch.
This is different from writing modular units with APIs. These are here to stay like stars in the sky and cannot be easily thrown away and replaced with new ones. However, this means that not all projects need to adhere to the principles outlined in this book. These principles are mostly good for reusable components that play essential roles in the system. The leaves of functionality, on the outer reaches of the system, can be made to work without worrying about the future, which is an example of the “write once and then throw it away” software methodology.
However, these functional leaves are usually built around a central component that is the heart of the whole system. Such a component is the subject of this book, and is developed according to the best practices of API design. In fact, even my cousin had to admit that he had a core library in his system that needs to be treated properly, as it is likely to be in use for many years to come.
Few people approach a new API from a rational perspective. Nobody studies an API and tries to understand every idea that’s hidden within it. Quite the opposite: these days people want to get their job done quickly, without understanding everything that is possible. There’s no need to think about the API that much if it does what you need it to do.
The empiricist philosophers mentioned in Chapter 1 would be proud. Instead of considering, studying, and using reason to understand, developers often just try to call one method from an API, and if that works, they’re happy. If not, they call something else and see what happens. Among NetBeans developers, this has become known as empirical programming: perform an experiment using the API, and if that doesn’t work, try something else. Experience comes first; understanding may follow—but sometimes it need not.
This affects the structure of APIs. The API needs to be self documenting: in other words, usable without any documentation. It has to lead the user of its elements naturally through the tasks that need to be solved. Solutions should be easily discoverable while typing, and although an IDE offers various hints, they should be on topic, and should not distract the user from the right path. Only in this way can experiments using an API empirically succeed.
RETURN VALUE CANNOT BE NULL
I have to admit that I also prefer the empirical programming style to a deep understanding of the APIs that I use, especially with respect to return values of method calls.
The Java language null value is special. Any variable of any object type can be assigned to null. When dereferencing it, you get a NullPointerException. In a well-behaved program, it’s desirable to eliminate these exceptions. You can do this either by always checking obj != null before calling methods, or by accessing fields on obj. However, this clutters the source code and makes it hard to read.
This has led some groups of programmers to treat null as an exceptional value, and when designing libraries they avoid its usage as much as possible. This often leads to comments in the Javadoc saying, “This method never returns null.” The NetBeans project decided that this is in fact the default: unless a method declares in its documentation that null is accepted as a parameter or can be returned from a method as its result, then the method won’t accept it or it will never return it.
However, regardless of such promises made in documentation, it’s still possible to find a lot of checks for the returned values not being null. Such checks cannot be false—but no one knows for sure, especially if you don’t read the documentation.
This is a kind of defensive empirical programming, which I also use from time to time. It’s better to be safe than sorry. It’s easier to check for null and silently exit than to get a NullPointerException when a program is already released and distributed to thousands of users.
Sometimes it helps to create illustrative code samples that can be copied and easily modified for the purposes of a first-time evaluator of an API. If they cover the most frequent usages of the API, they increase the chance that the initial encounter with the API will be pleasant. After that, coding can become more complicated, and potentially it might become necessary to read some documentation. That is acceptable. If someone invests his own time in experimenting with the API and successfully gets the job done, then the attitude toward the API is already positive. And in a positive mood it might seem more useful to spend some time reading documentation and discovering more hidden features the API provides, because it has already proved its usefulness.
The empirical programming style is with us, and each API should be ready for this type of user. The more the API method names, class names, or grouping of methods support the creation of the right code, the greater is the likelihood that the empirical first-time user succeeds in using it and decides to learn more about it.
The First Version Is Always Easy
If you want to convince other programmers to use your API, then you first need to obtain their trust. You need to gain their confidence in your ability to produce and maintain a stable API for more than one release. Regardless of how hard it is to use the API, the fateful moment comes when a new version of the component is released and all the client code that depended on it suddenly needs to be rewritten. Consider how many vendors would write applications for Microsoft Windows if such applications wouldn’t work when the end user installed a new version of the operating system. Therefore, API design is about trust: by following the best practices I describe, you can maximize the probability that you will be able to avoid backward-incompatible changes, and thus earn and maintain that trust.
Compatibility breaks may sometimes be inevitable: we live in the real world, which is often imperfect. However, avoid compatibility breaks where possible. Users of a component might accept such a break, given a notice of deprecation, suitable advance warning to set expectations, and good documentation of how to migrate existing code that uses the deprecated component. However, if such a rewrite is needed with every release, clients are likely to abandon an API in favor of another project that won’t have such painful migration problems. Compatibility breaks incur a significant cost to the user of a component: they are in effect a punishment for having used the component in the first place. They are a breach of trust.
Some people say that if you try hard, you can achieve a perfect API in its first version. They might be right, but you have to work extremely hard to achieve that goal. In spite of your best efforts, the requirements that the API was created to satisfy are likely to evolve over time. If requirements change, the best-case scenario is that the API will be merely insufficient. The worst case is that it becomes completely useless. In any case, it’s much wiser to make the API ready for a world where requirements change and allow it to change as well without breaking existing clients. Therefore, a lot of what I will discuss relates to API future-proofing.
THIS IS NOT AN EXCUSE!
The fact that the first version will almost never be perfect is not supposed to be an excuse for intentionally designing it poorly the first time around! It’s always much easier to design the first version than to make changes to it. That’s why you should try to make the first version as perfect as possible, without forgetting that what seems perfect from today’s standpoint might be poor from tomorrow’s perspective. The time for change will come.
Producing the first version of an API is always easy. The challenge is in producing the later releases. Making changes and adding new possibilities to an API without compromising the way it used to work is a delicate art where you have to envision all possible usages of the older API and ensure that its contracts are still satisfied in newer versions.
Evolution is inevitable, and creating an API that is capable of evolving compatibly is necessary for API clients. We must maximize the probability that the component is reliable, and at the same time preserve the author’s ability to fix bugs and address new requirements. Colloquially, you want to avoid “painting yourself into a corner.” An API designed to be ready for evolution won’t require work on the part of clients when an upgrade is made.
LIKE FREE SPEECH
There are other important aspects of good API design besides the ability to evolve. An API has to be documented. It also has to be understandable and easy to use. However, of all these, the ability to evolve is paramount. If you can evolve an API, you can always fix the problems that the API had in its initial version.
This is much like human rights. Of all the human rights, the most important is the right to free speech. If you have the right to speak, you can talk about the other missing rights and ask to be given them. If something else is missing, you can fight for it and potentially get it.
If an API is ready for evolution—even if it is ugly, undocumented, and hard to use—you can release a new version and update the API to fix these problems. That’s why I see evolution as one of the most important aspects to consider when architecting a library and its interfaces.
Because developers don’t appreciate unnecessary work—especially work imposed by an inconsiderate library vendor—creating APIs that are poised to be evolved compatibly is critically important for anyone writing libraries that other software components will use.