
![]()
Ever-Changing Targets
Many people think about the design and development of software systems, including APIs, as something that is complete at the release date. This is rarely the case. Few nontrivial pieces of software are ever “finished.” Usually the initial release is just the first step in the life cycle of a software system. Hopefully, many subsequent releases will follow. This applies also to APIs. The definition of a good API is not one that simply looks fine at the initial release, but one that has survived several years and is still in good shape.
The First Version Is Never Perfect
I already discussed in the section “The First Version Is Always Easy” in Chapter 2 that creating the first version is easy. I also mentioned that the first version is unlikely to be perfect. These two observations indicate that nearly every API needs to evolve over time. The requirements for the API will change as time goes by, and those that might have been valid in the past might no longer be applicable. Also, in every program there is at least one bug. Bugs need to be fixed from time to time, which leads to another commonly held belief: fixing a bug usually intro- duces two new ones. These common observations are true for any software system and APIs are no exception.
Now is the right time to give up and admit that “the first version is never perfect.” Regardless of how much you try, the released version will contain bugs and users will attempt to use it for valid tasks that are beyond the scope of your design. Short of owning a crystal ball, you can’t do much about this except accept it as a fact of life.
This observation need not lead to pessimism. The fact that the API needs to evolve isn’t a sign of anything bad, but simply a recognition of reality. If you design for evolution, preferably in the first version, evolution should be possible without causing problems for API users. Every API writer needs to have an evolution plan; that is, to know on a strategic level what will happen to the API in future releases. There are two possible approaches to such a plan. One extreme suggests giving up and rewriting everything from scratch, and the other prefers to try to fix reported problems and enhance the existing API while not changing behavior for existing clients.
The incremental improvements approach can, in ideal cases, deliver bug fixes and potentially also performance enhancements and a nicer look and feel, without any work on the side of the API clients. Clients can still rely on the old API and also work with the newer and better versions. This would be a winning strategy, except that every bug fix is likely to introduce two new ones. Every new release can introduce problems for existing API clients, which is why achieving this level of cooperation can be difficult.
Giving up and writing another API to perform the same task avoids the problem of incompatibility. The old API can stay the same, so no potential problems occur for its clients, and the new API can offer new and better possibilities. The only problem here is that old clients will stick with the old API unless they rewrite their code and upgrade to a new version of the API. Therefore, the drawbacks are also nontrivial.
The complete rewrite has the advantage of avoiding small incompatibilities, but has the disadvantage of locking your customers into a release that will never benefit from the improvements that a newer release would give. The improvements are important, but compatibility is more so. Balancing between these two extremes is the delicate art of making an API useful.
The ability of newer versions of an API to work with clients written and/or compiled against older versions is called backward compatibility. Being “backward compatible” is a mantra for nearly every API writer, as that increases the trust of the actual and potential users. However, there are multiple levels of backward compatibility, and achieving different levels is of differing importance and also complexity.
The first aspect you face with respect to compatibility is the ability to compile. If I write my program against, say, Java 1.3, will it compile on Java 1.4? If every possible program would do so, then the Java versions 1.3 and 1.4 could be called source compatible. However, source compatibility is hard to achieve. This is mostly caused by all the syntactic sugar that the language adds on top of the execution format: the class file. For example (and we faced this exact case in the NetBeans IDE), say someone wrote the following class against JDK 1.3:
public class WrappingIOException extends IOException {
private IOException cause;
public WrappingIOException(IOException cause) {
this.cause = cause;
}
public IOException getCause() {
return cause;
}
}
This would compile in Java 1.3, but would fail in Java 1.4, as the compiler would think that the code is trying to override a method that was introduced in Java 1.4. However, that method returns Throwable, so cannot be overridden by a method returning IOException. The Java 1.4 language rules forbid overriding a method by using the same name and also arguments, but a different return type, so compilation would fail. Surprisingly, in version 1.5 this would be okay, as the Java language evolved and accommodated changing the return type to be more specific as a valid step of evolution.
Adding new methods into classes that can be subclassed endangers source compatibility, but that’s not the only point I want to make here. Adding new classes into existing packages might also cause problems. Imagine the following code written in Java 1.1:
import java.awt.*;
import java.util.*;
/** Could be compiled on JDK 1.2, before java.util.List was created */
public class VList extends List {
Vector v;
}
This compiled without a problem in Java 1.1, but as soon as Java 1.2 appeared, the code snippet became invalid. Java 1.2 introduced new collection classes, among them java.util.List. As a result, the class name List became ambiguous in the preceding code snippet, as it can mean java.awt.List (as during the Java 1.1 compilation) as well as java.util.List. In short, adding new classes into existing packages isn’t source compatible.
You can see that adding new methods to classes can cause source incompatibility and that adding new classes can also cause incompatibility. Removing methods or classes is incompatible, so what can you do? Never make any changes at all? Give up on source compatibility? Faced with this dilemma, giving up on source compatibility is probably the better choice.
Of course, trying hard to make sources compilable with a new version if they could be compiled with previous version of an API is a reasonable goal, but as has been shown, it’s difficult and can be broken by syntactic language additions such as wildcard imports. That’s why it doesn’t make sense to try too much to ensure absolute source compatibility in Java. The language isn’t designed to extensively support source compatibility. It has different goals, and if someone is recompiling from source anyway, it isn’t that hard to fix mistakes. For example, replacing wildcard imports with explicit ones is relatively easy.
You can achieve binary compatibility if any program compiled with a previous version of a library can be linked with newer versions of the API without recompilation. This is a useful goal, as it supports two scenarios. First, you can write an application and then compile it with one version of the library, while letting people use it with any other version. This greatly simplifies maintenance, packaging, and distribution of an application. Second, it allows a user who only has the binary, built against the older version of the library, to migrate to the new library version without waiting for someone to recompile the application. Both these scenarios are desirable and useful as they increase the flexibility of configuration and give module writers and users more freedom. To achieve this level of interoperability, you should understand at least a bit of the binary format to which the sources are compiled. In the case of Java, this means understanding the format of the class file and the way it is loaded into the Java Virtual Machine (JVM). The next paragraphs give an overview and highlight some of the differences between source and binary compatibility.
The .class file format is close to—but not the same as—the original source code. The first difference to note is that the problem with wildcard imports experienced by source compatibility is gone, because all names in a class file are fully qualified. Also, the name of a field or method contains not just the name expressed in the source, but is also annotated with the actual type of the method or the field. For a method, this means the types of all arguments and, more surprisingly, also the return type. Consequently, it’s possible to have two methods with the same name and arguments, with different return types in the class file, although this isn’t possible in the Java source:
/** This is not Java code, but it is fine inside the bytecode */
public abstract class DoubleReturnType {
public abstract String getName(int x);
public abstract StringBuffer getName(int x);
}
The preceding source isn’t valid in Java and would be rejected by any Java compiler version I know. On the other hand, even though the preceding code won’t compile in Java, it’s perfectly valid if encoded into the class file. That is one of the most significant differences between the Java language and its binary format.
MANGLING THE CLASS FILE CONTENT
It’s fine to advise creating a class file that contains two versions of the same method, with each version having a different return type. However, the question is how to write the Java code that will actually compile to such bytecode.
The answer to this is to use a little bit of bytecode patching. For example, you can perform an operation directly on the content or the structure of the class file. This is a bit more complicated than changing the source code of a Java file, as .class is another binary format. However, its content is well documented and relatively easy to understand. Moreover, various tools help you analyze and modify bytecode with higher-level libraries, such as jasm, BCEL, classfile, and many others.
At one time, the NetBeans project needed to fix a backward compatibility problem. We needed two getIcon methods: one returning javax.swing.Icon and one javax.swing.ImageIcon. It turned out that the simplest way to do so was to name these methods differently and then do a search and replace on the resulting class file. That’s why we compiled the following, which is a valid Java source:
public static ImageIcon getIcon() { return null; }
public static Icon g3tIcon() { return null; }
We then replaced g3tIcon in the bytecode with getIcon. Simple and effective. Two methods with the same parameters and names and differing only in return type were created:
<!-- This is the target that does the whole trick – e.g. it compiles
the Java source and then replaces tokens
inside of the .class file
-->
<target name="-build-and-rename">
<mkdir dir="build/apimerge/classes"/>
<javac
srcdir="src-apimerge" destdir="build/apimerge/classes"
source="1.4" target="1.4" classpath="${cp}"
/>
<!-- this is the replace. As the replace is done textually,
we need to use some reasonable encoding that treats all
byte values as characters. E.g. it is not possible to
use UTF-8 as it does not like the standard Java header
0xCAFEBABE. Western Europe encoding is fine
-->
<replace
dir="build/apimerge/classes" casesensitive="true"
encoding="iso-8859-1" summary="true"
>
<include name="**/*.class"/>
<replacetoken>g3tIcon</replacetoken>
<replacevalue>getIcon</replacevalue>
</replace>
</target>
You should also be aware that access to a field encodes the name of the class the field is defined in. The virtual machine searches for the field only in the specified class, while the search for a method also checks all possible superclasses. Consequently, it’s better to expose a method instead of a field, as that gives you a bit more freedom for what you can do in the future.
When dealing with an object-oriented language, you must have an idea of what it means to declare a method and what it means to override it. Though in modern virtual machines such as HotSpot the implementation is different, the old “virtual methods table” description illustrates the concept well enough for our purposes. When you define a class with a set of nonfinal methods, you actually create a table. The table maps the names of methods, along with a description of the types of arguments and return value, to the actual piece of code that is to be executed when the method is invoked. If you create a subclass, then it creates the same table; it just fills it with different pointers to new pieces of code that are to be invoked when a given method is called. The calling code then always checks the table, finds out the right method from the signature, and invokes the actual piece of code registered in the table. Simple, yet powerful. In this way, the actual execution of a program is dynamic, as the actual piece of code that gets executed depends on the object, class, and its “virtual methods table.” It’s useful to keep this picture in mind, as it can explain a lot about inheritance behavior in object-oriented languages.
Table 4-1 demonstrates what will happen if certain base methods defined by java. lang.Object are called. For example, the "toString" row says that when you have an object of type Object and you call the toString method on it, it might actually end up in a method definition provided by String, if the actual type of the object is String. This kind of table is associated with every defined class. Whenever a virtual method—which in Java is any method not marked as final—is called on some class, you can see that as a lookup in the appropriate table. The correct table is deduced from the runtime type of the object on which the code makes the call. This is not magic. However, it’s useful to remind ourselves of the core technologies behind object-oriented programming. For example, it’s good to be reminded that the sole purpose of overridable methods is to replace a table mapping method name with actual code snippets.
Table 4-1. Sample Virtual Method Table for Basic Java Classes

Binary compatibility in Java has its own gotchas. For example, you might think that if a program compiles against two versions of a library, then the resulting bytecode will be the same. Well, sometimes it might be; however, often it won’t. The gotcha lies in the overloaded methods concept. Here, two methods are overloaded if they have the same name, but differ in their parameters. For example, java.util.Arrays has many toString methods, each accepting different array types, such as byte[], short[], and Object[]. These methods are therefore overloaded. When called, the compiler chooses the best one depending on the type of the parameter that is passed for method invocation. If multiple methods can be applied, the compiler selects the “closest” one, according to rules defined in the Java Language Specification.
INCOMPATIBLE ADDITIONS TO STRINGBUFFER
For several years the NetBeans project has supported the two latest versions of Java. This has the advantage that our users aren’t forced to upgrade to the latest Java version. However, it also has the drawback that we’re restricted to using features and APIs introduced in the previous release of the Java language and runtimes.
When Java 1.4 appeared, we were tempted to use some of its new libraries. We could have used reflection to invoke the newly added methods and classes that weren’t present in version 1.3. However, that wasn’t comfortable to use. Type control from the compiler is missing and you always need to catch a lot of exceptions when working with reflection. That’s why we decided to modify our build scripts to ignore source files ending with *14.java when compiling on Java 1.3, and compile them only when building on Java 1.4. That way we could stuff all the Java 1.4–only calls into those classes and still compile on both versions of Java. To demonstrate the idea, see the conditionaluseofapi sample project (available in the downloadable code), where a facade is defined:
interface AddString {
public void addString(String msg);
public String getMessage();
}
Now we have two different implementations and we need to select the right one, depending on whether we’re running on an older or newer version of Java:
AddString add;
try {
Class onlyOn15 = Class.forName("java.lang.StringBuilder");
Class codeOn15 = Class.forName(
"conditionaluseofapi.StringBuilderAdd15"
);
add = (AddString)codeOn15.newInstance();
} catch (ClassNotFoundException ex) {
add = new StringBufferAdd();
}
As a result, if we compile on the latest Java version, we have all the classes we need and we can use all its features. Meanwhile, when compiling with older versions, we get fewer classes, but their execution is guaranteed to work on those versions. We considered this quite a safe solution. Indeed, we were afraid of the accidental usage of APIs that are only available in the newer version of Java. That’s why we ran parallel compilations on both the supported versions. The parallel compilations guaranteed that no newer introduced API was used unconditionally, and the production build ran on both versions of Java, or so we thought.
To our surprise, we received a NoSuchMethodError from time to time. After some investigation we found that this was caused by the following:
StringBuffer sb = new StringBuffer();
StringBuffer another = new StringBuffer();
sb.append(another);
In fact, the problem was that Java 1.4 introduced the new StringBuffer append(StringBuffer sb) method, which wasn’t present in the 1.3 version. However, since Java’s earliest days, there used to be a StringBuffer append(Object obj) generic method. As a result, the preceding code compiled fine on both JDKs, although they compiled to a completely different method call!
As can be seen, the trick with double compilation didn’t work as expected. Code compiled on Java 1.4 couldn’t be run on 1.3. However, our desire to use 1.4 features was strong, so we improved our production build. Instead of compiling with 1.4 only, we compiled twice: first with Java 1.3, which ignored all **/*14.java classes, but correctly resolved all methods to the Java 1.3 API. Then we ran the compilation with JDK 1.4 again, which left the previously compiled classes untouched, but just added those **/*14.javas that were missing from the previous compilation.
Overloaded methods aren’t the only unexpected surprise you can run into when thinking about binary compatibility. For some reason, the bytecode format treats strings and primitive values such as integers in a special way. If you define a public static final string or integer constant in an API class, its value is not just referenced, as is usual in case of Object or other types, but instead it’s copied to the class that references it. This means that changing a value of such a primitive constant in a new version of an API doesn’t change the value that already compiled clients of such an API see. You can use this for some odd tricks, such as this one with versioning, used by the JBuilder APIs:
public abstract class API {
public static final int VERSION = 1;
protected API() {
System.err.println("Initializing version " + VERSION);
init(API.VERSION);
System.err.println("Properly initialized: " + this);
}
protected abstract void init(int version) throws IllegalStateException;
}
public class Impl extends API {
protected void init(int version) throws IllegalStateException {
if (version != API.VERSION) {
throw new IllegalStateException("Wrong API version error!");
}
}
}
Look at the preceding code snippet. Why is the strange check inside the init method? The passed-in value is VERSION, and then we verify this value to VERSION again. Indeed 1 == 1! These have to be equal. Well, yes, they have to be if the API and Impl classes are compiled simultaneously. But imagine that the Impl class is already written. For example, say someone has already written an extension module for JBuilder, and then tries to run it in a new version of the API without recompilation:
public static final int VERSION = 2;
Here the check in the Impl.init methods fails. The check actually compares 2 != 1, because the Impl class remembers the value of API.VERSION from the time of its compilation when it was 1. Surprising, yet true. So, just remember that changing values of primitive constants is not compatible!
The bytecode format is similar to the Java source. This is both good and bad. It’s good, because it is easy to understand. It’s bad, because it can easily be misleading. However, when writing APIs, the binary format is the final judge deciding whether an application will link to a library that it uses. This is why it’s important to understand what bytecode the Java code of your library translates to. When in doubt, disassemble your class and check its actual state. And be prepared for surprises!
Functional Compatibility—the Amoeba Effect
The fact that a new version of a library can replace previous ones, and still successfully link with the rest of the application, is not all that’s needed for achieving the cluelessness goal. Remember what I mean by cluelessness: the ability to assemble applications from modular pieces, while knowing just as little about the individual pieces as possible. If we have binary compatibility, the system is guaranteed to link, but linking doesn’t guarantee that the system actually works. Binary compatibility is just the initial prerequisite for this more important kind of compatibility.
The goal of clueless assembly and upgrading of a component-based system is to enable distributed development. Independent groups of programmers must be able to compile their applications at various times and against different versions of libraries, and still allow workable combinations of the resulting binaries to be deployed to their end users. For that purpose, it isn’t enough to make things link together. Of course, linking is a necessary condition, but the next additional level is to make the pieces work in such a way that they do what they are supposed to do. This can be called functional compatibility.
It’s simple to define functional compatibility. As discussed previously, a new version of a library is source compatible with a previous version if any code that can be compiled against the previous version can also be compiled with the new version. It is binary compatible if every application that could be linked, can still be linked. A library is functionally compatible if a program executed against the new version always produces the same results as against the previous one. This is a simple definition, but with terrifying implications.
Imagine that you know how your library should behave and that there is an excellent specification, perfect documentation, and other good descriptions of the expected behavior. Of course, this is just a fantasy. There is never something like excellent documentation. In reality, documentation is always out of date and usually describes just a piece of the whole real estate. But let’s suppose that someone did the ideal analysis and knows exactly how the application is supposed to look. For example, it could look like Figure 4-1.

Figure 4-1. What we think our application looks like
However, as a known truth of software development, you have to remind yourself that in every application there is at least one bug. But what does that mean? A bug is a violation of expected behavior. So in fact, even though people might believe that the application’s behavior matches Figure 4-1, the actual functionality will be different in some way from the expected state. In certain respects, the code doesn’t fully implement the expectations, and in others, it does more than was expected. The situation can be visualized better in Figure 4-2.
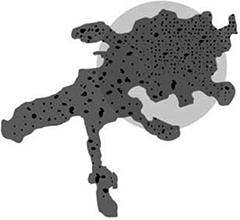
Figure 4-2. How it really looks
The problems are hidden in the deltas! Imagine that the picture describes the expected and actual behavior of a library. There is a clear specification and an implementation that sometimes doesn’t do what it should. Sometimes it does more. Programmers who code against that library are unlikely to read the specification. In practice, almost nobody actually reads the specification unless they are completely stuck. Until then, they use the “try and see” approach. For example, they write some code, try it, and if it works they’re done. But, of course, they observe the behavior of the implementation and not the specification. In this way they might end up relying on behavior that is either unspecified or contradicts the specification. Obviously, both these situations are dangerous for the smooth coexistence of future versions of the library and applications that are using it. When you release the new version of the library, with a few bug fixes and maybe also a few new features, the actual behavior shifts, as in Figure 4-3.
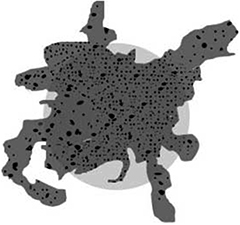
Figure 4-3 Look of the application in the next version
Again, implementation diverges from expectation. Moreover, it diverges in a different way than the previous version. Such a shift is likely to happen with each new version. The actual behavior of the library will change its shape like an amoeba changes its shape. As a result, certain usages of the library might no longer work, and the main goal of creating a compatible API is compromised. The API no longer supports communication between distributed teams, with distributed release schedules, allowing various versions to work together.
PROMISING THE UNKNOWN
My NetBeans experience tells me that people more easily accept source and binary compatibility than functional compatibility. There might be multiple reasons for this, but I’ll mention the one I feel is the main cause.
When exposing an API that can influence source or binary compatibility, you have to perform some action. For example, to create a class, you make it public and add a public method. Although some people object that not all their public classes are part of the API, it’s relatively easy to convince them that they are. In the case of functional compatibility, you don’t need to expose anything. The behavior just “happens.”
As the amoeba model shows, the actual behavior always differs from our expectations. Misbehavior is always present, though not because of any conscious actions. Unfortunately, consumers of the API have no way of distinguishing intended behavior from coincidence. The main problem arises when external developers write code against the original version of the library and start to rely on a functionality that is beyond the specification but works, and can therefore be used successfully to get the job done. In the next version of the library, this might stop working and the functional compatibility comes to an abrupt end. Who is to blame?
Any good shopkeeper knows that blaming customers is not a winning strategy. Similarly, if the user of an API uses it incorrectly and that usage fails in the next version of the API, the blame is likely to fall on the owner of the API, especially if the API is supposed to be successfully and widely used.
Accepting this is difficult. Nobody likes to sign blank checks with the promise that every behavior of the current version is part of the API. Nor do you want to swear an oath that every misbehavior falls under the contract of functional compatibility. Doing so feels unnatural. However, if the art of building huge systems using cluelessness is to become widely accepted, this is simply the attitude you have to adopt.
API designers need to become responsible for the entire amoeba, not just the parts they envisioned as part of the specification.
It’s tough to be responsible for your own actions. So, a primary goal for the API designer is to minimize the amoeba effect by bringing the behavior of the API as close to the specification as possible. This isn’t an easy task. It requires a clear understanding of what an API is supposed to do, having good techniques to express that in the actual programming language, and antici- pating how users of the API will use it (and how they will abuse it). The next sections outline the steps to achieve this and show you how to minimize the amoeba effect.
The Importance of Being Use Case Oriented
Be aware that if an API is widely used, it is unlikely that you will be able to know all its clients. For example, the writers of the Linux kernel cannot know all the motivations, goals, and ideas of everyone around the world trying to use ioctl calls to get something from the kernel. The only option they have is to anticipate and work with a vision of the user tasks when designing the kernel interfaces. Also, people who develop Java and its core libraries are unlikely to know all its users and the ways they use them. Still, these API writers, as well as any other API writer wishing to make successful and widely adopted APIs, need to attain a vision of the API user to understand what should be done with the API libraries, why, and how to do it.
Because you cannot speak to unknown clients, there are only two solutions: either find your users and do a usability study, or be use case oriented. Work with use cases—that is, visions of the API user’s action—and then optimize specifically for these. Getting responses from users via a usability study is good and can verify that your expectations about the use cases are correct. Anyway, the starting point for any design should be an analysis of the why, the what, and the how.
ERRORLESS API WITHOUT REAL USERS
I’ve heard some people express a concern that it is hard to imagine a perfect API, or at least an API without errors, designed artificially by a designer without interactions and comments gathered from real users. It’s true that the ultimate measure of success of any API is the satisfaction of its users. Users are usually satisfied when they can do what they need to and do it easily.
This is just like any other chicken and egg problem. You won’t have users without an API, and to create a good API, you need to listen to their comments and include them in the API design. You might think that this situation has no satisfactory solution. However, we need a solution, because we face this situation all the time. In fact, whenever you design any kind of system, you need to deliver the first version. This version can- not be based on comments of real users, as there are none yet. What can be done about that? You need to imagine your users—you need to think up and estimate what they are likely to do. You need to imagine their use cases.
Indeed, these use cases are only artificial. They might be far from the reality and differ quite a lot from the real requirements that you receive as soon as those real users of your API appear. From this point of view, the first version can never be perfect. However, it can still be errorless. An error in the API design is not because some API is incomplete. That is common—new requirements are being gathered all over the lifetime of any system—but the API cannot be extended in subsequent revisions to accommodate them. You can achieve this even with- out breaking the code written by early users of the first versions of the API, as you’ll learn throughout this book.
A use case is a description of the intended usage of the API, showing the problem that a potential user can have, without concrete solutions. Getting a set of potential problems as close as possible to the actual list of problems that people are likely to have is an excellent initial step to creating a genuinely useful solution, which in our case is the API. Let’s look at an example of a use case from the NetBeans database explorer API provided as part of NetBeans, showing how to register JDBC drivers:
An external module can register JDBC drivers. A typical example is a module that provides integration with a database server. In this case, the module contains the JDBC driver for that database server and uses the Database Explorer API to add it to the Database Explorer. Another client of this API could be a module providing integration with a J2EE application server. Sometimes a J2EE application server bundles a database server for improving the out-of-the-box experience.When the server is registered in the IDE, the JDBC drivers for the bundled database server are added to the Database Explorer.
Based on a use case such as this, you should start to think about ways of allowing this to happen in the API. Let’s call such a description of the actual steps that need to be done in the API a scenario. A scenario is in fact an answer to the question stated by the use case. The use case asks, “How do I do this?” and the scenario answers, “Well, you need to do this and that, and then you are done.” As an example, let’s see the answer to the use case for registering the JDBC driver:
The drivers are registered by making calls on JDBCDriverManager or by registering an XML file which describes the driver in the module layer. The XML file is described by the JDBC Driver DTD. An example of a registration file describing the JDBC driver for PostgreSQL follows:
<!DOCTYPE driver PUBLIC
'-//NetBeans//DTD JDBC Driver 1.0//EN'
'http://www.netbeans.org/dtds/jdbc-driver-1_0.dtd'
>
<driver>
<name value='postgresql-7'/>
<display-name value='PostgreSQL (v7.0 and later)'/>
<class value='org.postgresql.Driver'/>
<urls>
<url value='file:/folder1/folder2/drivers/pg74.1jdbc3.jar'/>
</urls>
</driver>
This file should be registered in the Databases/JDBCDrivers folder of the module layer. To address a bundled JAR inside the IDE the nbinst protocol can be used in the URLs: nbinst:/modules/ext/bundled-driver.jar.
The scenario links the abstract use case with its actual realization in the API. It describes which classes or interfaces you need to implement and where and how to put the declarative files to register them. Also, it provides links to deeper, more detailed APIs: the Javadoc of JDBCDriverManager and the Document Type Definition (DTD) for JDBC Driver. The idea behind this is that users of the API can quickly discover if they are interested in the use case, just by reading its abstract introduction. If so, you can get a basic idea of what needs to be done from the example described in the scenario. If that is not enough, the user knows where the ultimate source of documentation is found: in the Javadoc, DTDs, or sometimes also in the sources themselves.
The NetBeans documentation is structured in such a top-down way, and we believe that this organization helps our users to better navigate and find the information they need. However, we use the “use case,” “scenario,” and “Javadoc” separation for our internal purposes as well, because it helps us to evaluate whether the API is good.
The amoeba model shown earlier talks about the “differences” between the specification and actual implementation as the source of the most important problems in the maintenance of the APIs. That is why it’s reasonable to fight hard to make the differences as small as possible. However, to let this happen you need at least an adequate specification; otherwise there is nothing to measure the difference against.
Once upon a time, during the development of the NetBeans APIs, the only up-to-date specification we had was in the head of the programmer writing the code and the Javadoc. There was no way to check whether the result of the work was good or not. We couldn’t establish whether it satisfied what it should. We didn’t know if it overreached its aims. In other words, we couldn’t tell if the actual shape of the amoeba matched expectations. The only person capable of making such measurements was the actual author of the specification. However, the author was usually too emotionally attached to the implementation to do it independently. Of course, if the author was a good designer, everything would be done right. If you have skilled persons of this kind, then you should trust them. However, remember that “the first version is never perfect.” On top of that, if your guru moves away from your project, everyone else, regardless how skilled, will just inherit an unmaintainable mess. A library without enough documentation, missing high-level views, might be a work of genius in every way. However, it is potentially very fragile: any small effort to change its behavior will either do nothing or will push the whole amoeba completely out of shape. The new shape might mean that everything that used to work now fails.
Certainly, people work this way and are able to produce nice results. However, this is a better model for artists than engineers. And, like it or not, sustainable software engineering requires a different, more quantifiable precision than art typically does. When the NetBeans team finally realized this and began insisting more consistently on “use cases,” “scenarios,” and “Javadoc” separation, we didn’t need to work long to see the results. Our APIs now start with higher-level views and they can be evaluated by more reviewers in addition to the writer of the API. Now that we have better, more thoughtful, and more thorough documentation, our APIs are also more maintainable. All this is because to a far greater extent, we now understand the motivations behind our libraries.
NetBeans went through various levels of API development. Originally, the APIs were developed by one dedicated architect. Then we discovered that I was becoming a bottleneck, slowing the progress of the whole team. We switched the style and had a group of people with a benevolent dictator. Now the whole team develops APIs. Though each of these states has unbeatable support in software development theory, none is ideal.
It used to be thought that design cannot be done by committee—that it needs one architect to decide things. Although that can simplify things, it only does so to a certain degree. It definitely cannot scale. However, even before the scalability limits, the pressure on the lead architect is hard. His responsibility is to do the design, maintain the APIs, or at least properly communicate how the APIs should be, and this takes time and has its limits.
As the one who played that role for NetBeans in the first few years, I can confirm that it did not scale. As the team grew, it was harder and harder to satisfy all its requirements. The solution was to select the most skilled people and let them design the APIs they needed themselves. However, this caused a shortfall in consistency, as everyone ended up doing the API in their own personal style. This was not good for API quality.
The NetBeans team has recognized that the API exists primarily for communication with users. Also, we recognize that each good design must have general motivation. That’s why our current situation is a dedicated and open one, consisting of a group of people wanting to perform reviews, together with a lot of API writers. In fact, given the range of objects that can be considered to be part of an API, every developer is also, in fact, an API writer.
Whenever there is a need to change an API, anyone can submit a request for a change. Others then review it before integration, to make sure it has all the necessary attributes of being a good API. For example, we check to make sure that the “Rules for Successful API Design” are satisfied:
- Use case–driven API design: The motivation is stated on an abstract general level mapping the general design decisions against actual scenarios and the final realization of the API, for example via Javadoc.
- Consistent API design: The APIs produced by individual developers must match the general “good practices” shared by the whole team. An interface that is predictable serves better than one that is locally optimal but inconsistent across the whole set.
- Simple and clean API design: Simple and common tasks should be easy. If the use case–driven design is used, you can check whether naturally important use cases are satisfied by easy-to-implement scenarios.
- Less is more: Only the required functionality, as described in use cases, should be exposed. This prevents the deltas between the amoeba model’s expectations and reality.
- Evolution ready: The library must be maintainable in the future. When new requirements appear or the original maintainer leaves, the future of an API shouldn’t become compromised.
A focused, small team can check these aspects of API design. The good news is that the team doesn’t need to be expert in the area the API covers. As the questions are topic-neutral and more concerned with the general aspects of the API, anyone can measure them. So, Net-Beans currently does design by committee, but we can still achieve consistency and scalability through our large team. Lead reviewers can never stop to explain why and what to do, but the tasks are distributed and the API design is open to everyone. Join us at http://openide.netbeans.org/tutorial/reviews.
I’ve already mentioned a few times that the process of making APIs is about communication. There are people who consume the APIs and people who write them, and either side can initiate communication.
Possibly, people write code and then others discover its worth and want to plug into it. In this case, the API starts in a spontaneous way. Someone develops a feature; someone else finds it useful and starts to use it. Later they find out about each other, share their experiences, and likely find that the feature’s original design isn’t generic enough or that it was never intended to be treated as an API. To evolve it toward being an API, they discuss changes to improve the feature. After a few iterations it can become a useful and stable contract.
CONTRIBUTE, DO NOT HACK!
Common will to cooperate is a prerequisite of this style of API development and contributes to each developer’s success. At a minimum, new API users wishing to contribute should pass along information to the original developer on their particular use of some API functionality. Without this, the status of the API is unlikely to change. Its usage will continue to be more of a hack than a proper usage of the API.
On the other hand, the API’s provider needs to be ready for such requests and should know how to answer. It’s useless to say, for example, “Do not use this, it is not an API!” without giving an alternative. Instead, both sides should find a way to cooperate and maintain the API together. A common concern is that such maintenance is costly. However, as discussed in the section “Minimizing Maintenance Cost” in Chapter 14, this need not be the case.
On the other hand, some API designers do want to reach their readers without actually being asked to write or provide an API. This kind of API development looks more like being created by design, by vision. In this scenario, there is a known or at least expected need for a contract between two components in the system. The requirements are collected, the problem area investigated, the use cases understood, and then someone designs and writes the API. Now others can use it in the real world. Now they can comment, file bugs, and advise enhancements. All these comments help the API to evolve into a state where it is a useful and stable contract.
LONG-TERM INVESTMENT
APIs are needed. Without them, it is not possible to assemble applications cluelessly. However, you need to be aware that just creating an API might not automatically lead to its widespread use.
For instance, we had a need for a command-line API in NetBeans. At the least, we wanted it to support--open file name arguments sent to the NetBeans executable for opening the file in the editor. Due to Net-Beans’ modular nature, this cannot be coded in one place inside a single component. The module that knows about the command line is supposed to know nothing about files. The module that understands files was not able to access the command-line parameters. For several releases we had a private, undocumented API for connecting these two modules and handling the file open request appropriately. However, for the NetBeans IDE 6.0, I prepared a rewrite that created an official API that everyone could use.
No other module in NetBeans 6.0 IDE currently uses the command-line parsing API. Does that mean it was pointless to create the API? I don’t think so. Now that it is properly documented, I can already see questions on mailing lists about its usage. That means people are starting to discover it and are considering its usage. Its existence increases the viability of the NetBeans Platform and might attract new developers. However, it will take time before it will be widely adopted. The APIs created for public use—that is without a requestor who would use them immediately—are generally a long-term investment.
Despite these cases starting differently, they share the same attributes: both need time for feedback and evaluation before the API can be said to work. Not every effort ends its life as a stable API: sometimes the chosen way might lead nowhere. In such cases, it is better to abandon the work. Sometimes it might be found that the sides of the contract don’t need a real quality conversation. In that case, they can just chat. If their negotiations don’t work during the next release, they are close enough to each other to find a new way to talk to each other easily.
All this is possible. However, as the problem lies in the communication between developers, it’s important to express yourself clearly. If you create an API and it is not yet fully “baked,” there should be a clear warning saying, “Hey, this is not ready yet; try it, but be careful.” On the other side of the spectrum is the proud announcement, “Here is the most brilliant API that I’ve ever created! Use it! I guarantee you full support for your whole lifetime!” This can win the hearts of your API users, but the most important thing is to be clear and explicit about the state of your API.
For example, the Linux kernel and its external interfaces use the dot followed by an even number to label stable versions, and the dot followed by an odd number to mark development versions. So 2.0, 2.2, 2.4, and 2.6 are stable releases, while 2.1, 2.3, and 2.5 are used to denote those under development. This clearly establishes an expectation, and users select the release that suits their taste: either living dangerously on the edge of the new technology or having a stable release, but without some of the new features and improvements.
A transparent way of communicating with users of your library about a lack of stability is to mark your release as 0.x. It is commonly understood that something that has not reached version 1.0 is still under development and that it will probably change. Whatever style you choose, the most important thing is to make sure that users of the API understand it and its implications.
Here is a small attempt at explaining the NetBeans API’s stability rules. One of the complications that NetBeans—and probably also any other bigger project—has to face is that our APIs are not one big piece, but more like a set of relatively independent sets of APIs, each in a different state of evolution. Although some of our APIs would still like to fall into the 0.x category, other APIs are already grown up and we have no fear of committing them to the highest levels of stability.
To communicate clearly what stage an API is in, whether it is still evolving or whether it is stable and ready to use, the NetBeans team decided to use a system of stability classifications for APIs. The aim is to give API authors a way to express their intention with a particular library, and give the users of the API the information needed to decide if they want to rely on a particular API or wait till it becomes more mature. To do that, NetBeans annotates each of its APIs using one of the following categories:
- Private is a category for features that are accessible but are not intended for use outside of their modules and libraries. What kind of features belong to the private category? I have discussed what an API can consist of: environment properties, files that a code reads, and so on. In many cases code and even API libraries read properties and files that aren’t intended for public communication. An example can be properties that turn on logging, or files used as caches. The content of these external factors can influence the behavior of the libraries, but it is unreliable to depend on them. They might work in an existing version, but they are subject to change in each release; depending on them is risky and should be avoided. API review before change is not necessary, but is recommended as a way to ensure that the feature is properly hidden and documented as private, and also as a way to ensure that there is no better way to achieve similar behavior.
- The friend API is designed to be used by other parts of the system, but only by a restricted subset. This is often needed, as it is unlikely in a large system that a component could work on its own, without dependencies on any other part. NetBeans requires a “signing agreement” between the producer and consumer of an API, such that they agree on the contract and agree that it can be changed incompatibly. Such a “written agreement” can mean anything that the involved parties agree to. In NetBeans, we have a way to enforce this by allowing each module to specify a list of “friend” modules that can access its API, enforced during runtime. This encourages a conscious decision to make an API available to just a limited set of “testers.” Doing so makes sense only if there is a close personal relationship between the producers and users of the API, because often the sources and binary compatibility might be compromised if the API is changed in such a way as to require recompilation. That is why NetBeans encourages this kind of API relationship just for modules produced by the same team and built at the same time. Because the list of clients of the API is known and they agree to adapt to changes, a friend contract can change in every release.
- Under development denotes an incomplete contract expected to become a stable API. This category is the NetBeans version of Linux 2.3.x, 2.5.x annotations for unstable development releases or the 0.x releases of many libraries. Such an API is available to any client. However, incompatible changes might appear between releases, though they should be rare. Reasons for incompatible changes should be justified, such as unsolvable performance problems or a completely wrong design. In no way should we polish the look with “cosmetics” but improve nothing else. Users of the API are advised to subscribe to a proper mailing list, where all changes should be announced via proper API review before the actual change is integrated. The Javadocs for APIs with this stability level should be published daily for every build of the development version.
- The stable category is used for interfaces that have reached production quality and are ready for public usage. Clients can rely on such APIs without fearing incompatibility when a new version is released. This is similar to the stable kernel versions (2.4.x, 2.6.x) or libraries that announce they are 1.0 and later versions. Once such an API is released in a product, it should be maintained compatibly until it is deprecated and properly “end of lifed.” Stable contracts should preserve the investment of their clients, and their evolution should be guided from this point of view. All changes have to be announced and discussed via a proper API review before they become part of the code base. The Javadocs for stable APIs are published daily for the development version and they are also published for each release of the NetBeans IDE.
- Official APIs are stable and are also packaged into one of NetBeans’ official name-spaces: org.netbeans.api, org.netbeans.spi, or org.openide. By packaging a contract into this package and making it part of a release, we notify others that the contract is stable with all the related consequences. The goal is to give users a simple way to recognize what is a stable contract and what is not. By seeing a class in one of the official package namespaces, you can be sure that it represents a stable contract.
- Third-party interfaces are provided by other parties that don’t follow the NetBeans rules and thus are hard to classify. Try not to expose such interfaces as part of your own contracts, as discussed in the section “Beware of Using Other APIs” in Chapter 10.
- Standard is similar to the third party classification. Also, someone outside NetBeans provided it; however, that person is expected to evolve the interface in a compatible way, such as is the case with Java Community Process and their specification requests. The standard is not expected to change frequently or incompatibly.
- Deprecated is the final category. After some time, nearly every API, regardless of what state it is in, becomes obsolete. Usually newer, better support for the same task has been developed, replacing the old API. In such cases, mark the old API deprecated. A previously stable API that changed its stability to deprecated should be supported for a reasonable amount of time, such as the span of a release, to communicate to users that they should migrate from it to the new replacement. After that time, the API can be removed from the product, while trying to preserve it for old clients by making it available in alternative ways, such as in an available but not turned on library, or in a library that can be downloaded if need be from the online NetBeans module registry.
At the beginning of this chapter I discussed two different models of API development. Developing an API spontaneously means, in light of the preceding API categories, to introduce a private or friend API. When someone else discovers it and finds it useful, it evolves into a stable contract. On the other hand, an API developed by design is more likely to begin its life with an under development status and after a bit of work, preferably at the time of first release, change to stable status with all the promises and guarantees associated with that.
I’ve mentioned many times that the first version will not be perfect. In fact, no version will ever be perfect. At any point, something will no longer be accurate or will no longer match the previous scenarios. There are two extreme styles of responding to change: either by incremental evolution or by enacting a small big bang.
An incremental change is, for example, the addition of a new method or class, a new element into an XML DTD, or a new property that influences the functionality of the library. A new API then appears, although the previously available API continues to work.
On the other hand, a big bang usually describes an action that completely revamps the existing API and creates a new version. Obviously, clients using the previous version are unlikely to switch easily to the new version. They need to decide which version to use. A single component in the system can only work with one version; it is impossible to work with both versions at once. To use the new version, you have to do a painful and big rewrite.
However, seen from an optimist’s perspective, it is “just” a rewrite of a single module. A much more complicated situation might evolve when the two versions—before big bang and after big bang—cannot coexist. Then all the components in the system might either use the old or the new, but no mixture is allowed. This magnifies the migration problem, as all existing users of the API need to migrate to the new version at the same time. This huge reorganization project needs to be well coordinated. This is challenging, but possible. However, clearly it goes completely against the spirit of distributed development.
The problem with an incremental improvement is that it is a fallacy to believe that the clients of the previous version of the API will continue to work because the changes are “just minor.” Every change is potentially dangerous, as it can introduce one or more incompatibilities. Every incompatibility, even one that seems minor, can have severe effects on the ability of clients of the API to cooperate with the API. In terms of the amoeba model, you need to start with as close a match between the specification and the reality as possible. Only then can you reliably promise that the “minor” incremental changes will cause no harm.
The big bang is realistic with respect to backward compatibility, and clearly states that the users of the library, when migrating to a new version, need to spend time on adapting their code to the new API. At least this is an honest position. However, it is problematic on several levels. First of all, it is easy to switch to a new version of the library if you don’t need to do anything differently. However, if you have to invest time to rewrite an implementation completely, the reason to switch has to be genuinely compelling. If there are no compelling reasons to switch, users will simply stay with the older version. Remember that the toughest problem of every project is scheduling the required set of features. Nobody is interested in spending time upgrading to a new version of a library if there are more important things to do.
This type of attitude toward API clients doesn’t create the most cooperative environment. However, there are even worse levels of noncooperation. It is the all or nothing switch. Sometimes it is acceptable to perform a big bang if the clients can migrate one by one to a new version. However, the all or nothing attitude makes this impossible and says, “Either everyone stays and uses the older version or everyone immediately starts to use the new version.” Such a statement is difficult to enforce among distributed groups doing distributed development, as described at the beginning of this book. Making frequent big bang changes, and also requiring frequent all or nothing switches, is the best way to inform API clients that they need to find alternatives.
An example of an incremental update would be the evolution of the JDK libraries. Packages, classes, and methods are added in a newer version, but in a style that more or less guarantees that the previous clients of the APIs will continue to work in the newer version. As a result, you can run on newer versions of the JDK while still having code compiled against older versions of the libraries. This is a win-win situation.
An example of the big bang style of evolution can also be identified in the JDK. The language features in Java 5 force clients to make an important decision: either don’t use generics and run on the runtime of Java 1.4, or use them and also switch the runtime. The speed of adoption of the new Java 5 language features proves that this is a tough decision to make. Often it is delayed because there are more important things to do than to switch to a “nicer language,” especially if the application already works.
An example of the all or nothing dilemma is the switch from the Linux 2.4 to 2.6 kernel. These two kernels are not fully compatible, so applications need to be adapted to work with them. Moreover, it is impossible to run both versions of the kernel at the same time. That would let you use the 2.6 version with newer applications while older ones continue with the 2.4 version. All applications in one distribution had to be adopted during one release, which was not an easy task. Fortunately, the kernel layer is not that big, and incremental, phase-by-phase adoption was possible. At least some distributions managed to make almost all applications ready to run on both versions of the kernel at once.
THE ENTROPY OF SOFTWARE
One other important aspect is associated with big bang changes, which is the momentum of software development. My NetBeans colleague Tim Boudreau calls it the entropy of software, and invented the “funny faces model” that describes it. In contrast to the amoeba model, which sees the situation from a global, objective point of view, this model describes how the state of a software project looks from the point of view of its maintainers.
The first version of every software project is nice. It starts from scratch, building everything from zero. As there is nothing in “zero,” there are no inherited problems either. The first version always builds in a bugfree state. Of course, the developers doing the coding do their best. That means that looking with their own eyes, the result is perfect: beautiful, well designed, and organized, just like Figure 4-4. The application is split into modules organized into a nice star-like structure: the one in the middle provides all the APIs, while the others use it for mutual communication. The design, dependencies, and everything else are so nice and clean!
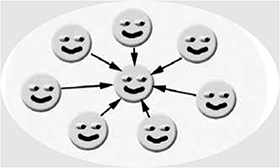
Figure 4-4. The first version is always nice.
As soon as the first version is released, bugs start to be discovered and reported. They need to be fixed. Immediately a much more difficult starting position is created for the second version. The second version builds on something that is known to be buggy. Moreover, as is usual in most software projects, there is not enough time to do things properly. As a result, the changes to the system are no longer as nice and clean as in the case of the older version. As shown in Figure 4-5, people introduce shortcuts, use libraries other than the official API, and so on.

Figure 4-5. Happiness does not last long.
This increase of entropy continues in subsequent releases (see Figure 4-6). Code becomes harder to maintain. Developers maintaining it complain all the time, especially if they inherit the code and the original creator has vanished.
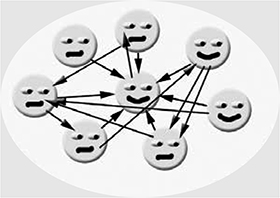
Figure 4-6. Entropy increases.
At some point, the project reaches a stage where developers just say, “Please don’t touch it!” (as shown in Figure 4-7). The code is so messy that any change causes a regression somewhere else. The problem might get so huge that it becomes apparent even to management that something is wrong, and they might approve the development of a complete big bang rewrite.

Figure 4-7. Oops, do not touch this!
More than likely, the new version will take more time than originally promised. It might not even have all the features of the previous one. However, it is nice and clean (as shown in Figure 4-8)! That’s obvious, because you started it from scratch. There is no reason for it to contain design flaws. It is as beautiful as the first version we used to have. And, now, we are finally where we wanted to be . . .

Figure 4-8. A rewrite is always nice.
Unless . . . what if we’re not? In fact, the same entropy that undid our first version is likely to apply to our rewrite as well, as shown in Figure 4-9. Once again, the code will become messy, will need to be maintained, hacks will be introduced, and slowly the first version’s decline will be repeated. As a result, the big bang change that was supposed to improve everything forever doesn’t deliver on this promise at all. Although it was a lot of pain to implement and finish the major rewrite, we are almost back to where we started. All the pain of the switch was useless.
Figure 4-9. Entropy strikes back.
The common problem with big bang changes is that we often expect to get better results, although we end up doing things afterward in the same way as before. There is no reason why this should work. If you need a better result, you need to change the way you develop. Maybe you need to change your coding style. Possibly, the problem lies in your design and testing practices. Only if you change the way you work can you expect better results. Only then can the big bang rewrite be successful. However, if you can change your working style, you can also likely improve your software project, even without undergoing a major rewrite. True, you can hardly make it slick and elegant unless you’re working on the first version. However, as discussed in the section “Beauty, Truth, and Elegance” in Chapter 1, beauty is not the most important quality of software engineering. More than that, we need the reliability of its components and the responsibility of its designers. Only then can we increase our cluelessness when assembling our applications.
HOW MANY PEOPLE HAVE TO DIE?
I grew up in the former communist bloc as a “young pioneer.” This was an organization for youth, similar to the Hitlerjugend in Nazi Germany. I look at that period of my life with ironic bitterness, especially when I see that the illusions common to us back then are still common today.
One of the most profound illusions was the vision of “making the world a better place.” Though the goal is laudable, the road taken is often unsound. Communism, as well as Nazism, started with identifying those responsible for the poor state of the world and claiming that all the evil in the world would disappear if we got rid of those people. Communism identified those who owned factories, farms, banks; Nazism identified Jews, among others. These categories were then scheduled for elimination—either physical or at least professional. The world was then supposed to be better. Needless to say, even 40 years later, in the case of Communism, the world is no better than before.
As a result, I always have to ask, “How many people have to die?” whenever I hear someone proposing to make the world a better place. If the answer is greater than zero, the idea is invalidated. If implemented, there will be victims, but the world will not improve at the end of it all. Making something better doesn’t happen just by killing someone. It requires hard work, and likely hard work by ourselves, not others. In my opinion, the only thing that has verifiably made the world a better place is hard work, such as Churchill’s promise of “blood, sweat, and tears” that helped England win the war.
This is the underlying reason why I don’t like big bang changes in API design. They always pretend to save the world. However, most of all they hurt people. All the users of an API are immediately punished for using the API. Only then, usually much later, while the project continues slipping, can you see the benefits that might make the world a better place. Sometimes they do—however, only if library developers also change their attitude and start to develop the API more responsibly. If not, the arrival of a better world is delayed. At least, until the next big bang . . .
In conclusion, get ready for incremental changes! They will be needed and they are typically the least harmful, especially when compared to big bang rewrites. If they are not possible because the API is in terrible shape, justifying a big bang change can only be predicated on a fundamental change in the style of development. This book mostly talks about proper API design practices for incremental modification. If we touch on the topic of big bang changes, we mostly stress the coexistence of multiple different “big” versions together. Only this style can guarantee that the API becomes better, while minimizing the suffering of the API’s clients.