
![]()
Runtime Aspects of APIs
So far, the chapters in this book have concentrated mostly on source or binary compatibility. Suggestions usually advise exposing fewer classes, methods, and fields and thereby help their evolution. This is indeed desirable, because if we want clueless assembly of applications built on top of our libraries, we need the applications to link and not throw UnsatisfiedLinkErrors. However, API design doesn’t end when applications link. At that point the real quest is just beginning! Then you need the linked pieces of an application to continue working together. Also, they shouldn’t only work once. Instead, they should continue when modular parts of the application are replaced by their newer versions. Only then are you aligned with the clueless application assembly approach. And you can only achieve this if you know and understand the implications of functional compatibility.
PERFORMANCE IMPROVEMENT ADVENTURES IN THE NETBEANS FILESYSTEM API
Our effort to speed up operations with java.io.File through the NetBeans FileSystem API brings up an interesting story about the implications of functional compatibility.
We found that some common operations, such as finding out if a file exists on disk, are much slower with the FileSystem API than when the check is done directly via java.io.File. As there was no architectural reason for that, we decided to investigate the problem and speed things up. The first area that needed optimization was caching and synchronizing the state of caches with the state on the local disk. The FileSystem API keeps some information about the disk in memory. Whenever you create or delete a file, the API updates not only the real files on disk, but also the caches in memory. So far, so good. However, users of our API are used to the bad habit of mixing the filesystem calls with java.io.File ones, bypassing the cache updates. They especially like to create a file using new File("…").createNewFile() and then immediately access it via FileObjects. Though this is a discouraged technique, malicious code uses it from time to time, because the previous versions of the java.io.File to FileObject mapping allowed this kind of conversion.
This is just another example of API users engaging in “empiric programming.” They don’t care about what is right or wrong, but only what works and what doesn’t. Because this coding style simply used to work, API users exploited it without any problems. However, we then needed to prevent this synchronization, because its frequent checks verifying that the state of cache still matches the state on disk were the reason for the FileSystem API being terribly slow.
The other reason for the slowness was that all drives on Windows systems, such as C:, D:, and even floppy drives and mapped network drives, were presented as one virtual filesystem. As a result, when you executed an external tool and needed to synchronize the caches in memory with the state on disk, you could only request a refresh of all the drives. This was inefficient, because a small change on the local hard drive might trigger extensive checks on all the network drives. Obviously, this was not a fast process. That is why we decided to change the mapping and create one virtual filesystem for each Windows system’s disk. No changes in signatures or new methods were needed. Just a small shift in internal implementation. At least, that’s what might have been assumed . . .
However, users of the API had a different opinion. We received many bug reports because a lot of code using that API was suddenly broken. Its maintainers were quite upset: “I haven’t touched this module for months and now it has suddenly stopped working! How can you do that to me?”, and so on. It was no help to show them their code and prove that it was incorrect to start with, or that it had violated the documentation all along. “It used to work; now it doesn’t. And it’s your fault!” We tried to fix the most visible misuses of the API ourselves. But we couldn’t find them all, because just like a star that doesn’t know who is observing it, we were unable to find all the places that incorrectly mixed java.io.File with FileObject. Instead, we provided a migration guide that explained how to map the old bad code patterns to new and better ones. It still wasn’t enough and the complaints were endless.
In the middle of the release cycle we decided to give up. We didn’t want to lose our performance enhancements. However, the complaints had become overwhelming. We needed to achieve the performance enhancements in a more compatible way. We then chose two different techniques to do that. In case of potential divergence between caches and the state of the disk, we performed the refresh. If there were no signs of such a distinction, we kept the new behavior; that is, we didn’t touch the disk at all. To do so, we needed to identify the symptoms of potential improper combinations of java.io.File and the FileSystem API. We did that with a little help from java.lang.SecurityManager. Desynchronizing caches can only occur if you create or delete a file on disk. You can do this either from inside the Java runtime or with external tools, such as /bin/rm. However, Java provides a sandbox execution environment and can prevent these two operations if unsecured code performs them. Therefore, there is a way to detect them. It’s enough to override checkWrite(String file) and checkExec(String cmd) in your own security manager and register it. We did exactly that. When developers worked with their files without the use of the FileSystem API, we noted in the cache that this file, or even the whole cache, was potentially no longer accurate. When, later in those circumstances, developers asked for such a FileObject, we did the refresh. In this way, we managed to retain our performance improvements compatibly with previous behavior.
However, we were unable to use the trick with the security manager to solve the problem with one versus multiple virtual filesystems on Windows systems. We decided to resolve to the compatible extension of the API. We returned to the previous behavior, where one virtual filesystem represents all the drives. We added a new method for a more optimal refresh. Then we identified all the places that caused excessive refreshes and modified them to use the new method. The old API stayed compatible, while simultaneously performance was enhanced.
Was this a happy ending? Yes, probably. Behavior is again compatible, while performance is improved. The only remaining irritant is our bad reputation. Recently, I was sitting in a meeting with a senior executive of a group building on top of the NetBeans Platform. I listened to his complaints about the need for stability and compatibility. “Some time ago,” he said, “our whole system was completely broken by some of your changes.” Of course, I immediately knew what he was talking about. Rather than explaining the technical details and informing him that his programmers probably never read a single line of our API documentation, I tried something like, “That might have been caused by your use of the development version of the NetBeans Platform. As soon as you migrate to the stable version, everything will be okay again!” My response was well received. And, in fact, it was also true, especially after our recent fixes.
We can try to master our skills and learn several API design patterns that can improve runtime compatibility. However, simply knowing what to do is not enough. You need to prevent the amoeba of your library from changing; that is, you need to prevent runtime differences between the shape of the application in one release (as described in Figure 4-2 in Chapter 4), and its functionality in a subsequent release (as shown in Figure 4-3 in Chapter 4). To do so, you need to take note of one important piece of advice: you need to be responsible.
Although this is not the primary topic of this book, and although it’s not directly related to API design patterns, this chapter will talk in detail about the relationship between selective cluelessness and the making of reliable code; that is, how to match the vision of your library’s functionality with your library’s functionality in real life. However, as there are many other good books on this topic, such as Pragmatic Unit Testing in Java with JUnit,1 I’ll concentrate as much as possible on the API aspects of the symbiosis between cluelessness and reliability.
The amoeba model described in the section “Functional Compatibility—the Amoeba Effect” in Chapter 4 is one way to capture the problems that you can face when designing a library. It puts the emphasis on the differences between various releases. However, you can also look at software engineering problems related to releases from the point of view of time and evolution. I call this model “the path of the lost warrior,” as it sometimes resembles the long and almost never-ending journey of Homer’s Odysseus.
At the beginning of a software project, we always know where we are and where we want to go. At least, this is true in most cases. We more or less know our current state. We can dream about improvements of the current state and where we’d like to be. As shown in Figure 11-1, we know that getting from our current state to the dreamed state will be simple. In fact, it will all be a piece of cake!
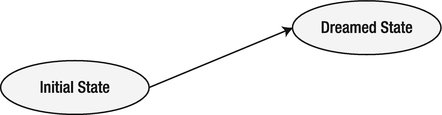
Figure 11-1. The project will be a piece of cake!
Obviously, things are never as simple as they seem. It’s usually almost impossible to hit your target state completely accurately. For example, you can try to develop a solution on a branch. However, as soon as you merge it into the main product line, it becomes clear that not everything will work as expected. There are bugs and missing features, some people are not happy with the new behavior, and so on. As a result, it’s unrealistic to expect that the dreamed state of a project can be reached in one cycle. However, that is acceptable. We can count on being able to perform multiple iterations, as illustrated in Figure 11-2. We know where we are heading. Certainly, sooner or later we’ll get there with just a few small steps.
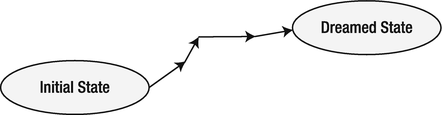
Figure 11-2. Maybe it just needs a few iterations!
We believe we’ll get there—one day. However, these steps might not be straightforward at all. As shown in Figure 11-3, there can be regressions. Each regression puts us further from our idealized dreamed state. Still, we might believe that one day we’ll get there. One day all the regressions will be eliminated! I am afraid that they won’t. That is simply not a realistic perspective. Though their effect can be minimized, regressions are here to stay. We need to learn to live with them. Let’s simply accept that our path from the initial state to the dreamed state won’t be straightforward. Let’s count on there being a number of regressions. That still gives us a chance, doesn’t it? It can take us a bit of additional time, but we’ll get there, eventually.
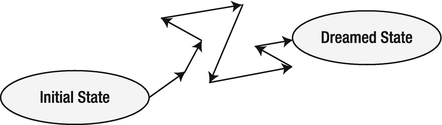
Figure 11-3. We’ll get there—one day.
Unless . . . What if we don’t ever get there? The software project might become so complex that it becomes impossible to actually reach the desired target state (see Figure 11-4). At that point, we find ourselves in a situation that I call walking in circles. Just like entering a vicious circle, we can move forward step by step with a vision of getting closer, without ever finding our way to the end. In terms of the amoeba model, we might push its shape endlessly, hoping that it will match our dreamed vision, without ever reaching that state. Real projects tend to be like that!
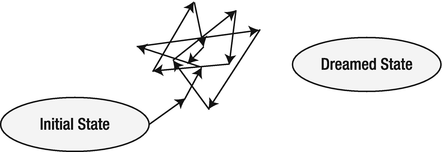
Figure 11-4. Oops!
In fact, real projects are worse! The model of an endless “fixing odyssey” follows only a single feature of a project. Real projects tend to have tens, thousands, or even more individual features. Those features can be watched individually. However, they don’t change synchronously and they don’t live in a vacuum. They influence each other. As a result, a fix that moves one feature closer to the dreamed state can cause a regression in another feature. That means that a single feature might even get to the target state, though it might leave that state as soon as you fix another feature (see Figure 11-5).
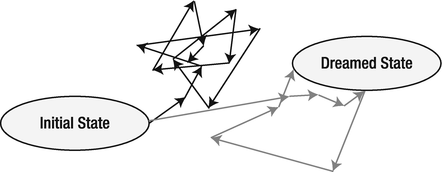
Figure 11-5. Real projects are more complex.
PREVENT UPDATES AS MUCH AS POSSIBLE
My wife used to work as an accountant in a company that used an accounting system produced by a software factory named after a wizard. They paid a lot of money for hotline support. After a few years of observing them, I realized that the hotline had only one piece of advice to give its users: “Okay, that is a bug. You can work around it like this. However, it’s better to wait for a new update; then it will be fixed.” That is advice perfectly in keeping with their wizard name: “Wait, I am preparing a magical update!”
I believe there were at least three updates while I was watching and as far as I can tell, they always fixed something, but simultaneously caused a number of regressions. My wife told me that she needed to spend hours on the hotline to learn how to perform various SQL selects and updates to fix the databases to work with the updated versions.
Software projects tend to walk simultaneously in many vicious circles. The amoeba model is an accepted reality. If there is a huge outstanding problem, it can always be fixed. You simply have to accept the collateral damage caused by regressions all around. That is why people are generally afraid of updates. Most of our experience tells us that it’s better to live with something that is sort of working than to risk an update to a new version, with unknown behavior: “Oops, just don’t touch that part of the application!”
UPGRADE X SERVER OR NOT?
All users running Linux on their own notebooks, two years before or after 2006, know the following feeling: “Okay, I have a sort of working system. It works. It can hibernate and most of the time it can also awake from hibernation. It doesn’t suspend, but that is probably acceptable. Should I risk an update to a new version of X server with the hope that suspend starts to work as well, while risking that I’ll lose the ability to hibernate?”
Needless to say, the fear of upgrades, and the real problems updates cause, greatly hurt the cluelessness motto of this book. How can you cluelessly assemble and evolve large applications based on modular libraries when each upgrade to a new version carries with it such large risks? Can we do something to reduce that risk and make upgrades a nonproblematic, semi-automated process, at least for frequently used libraries?
The problem of changing the behavior of a library or an application where its functionality shifts and shakes like the amoeba shape has not only technical, but also sociological implications. Nonprogrammers—that is, the users who consume our software—will become increasingly suspicious about the quality of the products we deliver. Though their expectations vary, they all share this belief: “If something worked in a previous version, it will continue to work in a later version.” The fact that almost all software projects fail in fulfilling this basic assumption results in users losing faith in our software products.
This is a bad situation. In fact, it’s even worse than that. Almost every upgrade of a software project is accompanied by the promise of more advanced features and improved behavior. Nobody promotes an update as a completely incompatible rewrite of an existing version, because that is unlikely to be the right strategy for selling a product. As a result, most development teams either promise compatibility or don’t mention it at all. Later, when users actually try the product, they usually find a range of incompatibilities that cause software engineers to lose a significant amount of credibility. We are seen as unreliable. We are seen as people who cannot perform their work correctly, as people who cannot deliver on their promises.
A side effect of this attitude is that our users are constantly expecting their pessimism to be reflected in reality. Instead of embracing us and our products, users are almost forced to build walls around their software products and departments, so that they can isolate themselves from our failures and incompatibilities. I don’t know about you, but I’m not very happy with this situation. I certainly don’t want to be considered unreliable and untrustworthy!
BAD REPUTATION!
As the original author of most of the NetBeans Platform APIs, I was one of the first NetBeans engineers to “enjoy” the full effect of having a bad reputation. As my APIs are at the heart of the whole NetBeans infrastructure, and every other module relies on them, they also become the central source of amoeba changes. Whatever change is made in the API, regardless of how small and gentle that shift in functionality is, the impact multiplies with every module that uses that API. In the end, a gentle tweak can result in a complete earthquake for the whole system.
There once was a period of time where I was notorious for breaking builds in a variety of ways. Not that I was a bad engineer, but code that many developers and their projects depend on deserves a lot of attention. It deserves a lot more careful treatment than a buried dialog without an API that is used by only a few faithful end users. However, at that time we used the same coding techniques for our APIs as we did for our almost “hidden” features. We found that this simply didn’t work. As a result, I deserved the bad reputation that I had at that time.
However, I didn’t like the bad reputation I had acquired much. I believed it was a bit unfair and that I could do a lot better. That is why I worked on ways of eliminating the amoeba shifts in our APIs completely. I believe I succeeded because these days I can make changes without fearing earthquakes all around me or walking in endless vicious circles. How is that possible? Am I smarter now than before? No, not at all. The only thing that I had to change was my attitude. I needed to be more careful and selective in choosing what to care about. I needed to become selectively clueless.
Software development in general, and the development of sharable libraries with APIs in particular, needs to earn more credibility. We need to become more reliable and we need to earn back the trust of the people around us. We need to prove to people that there is no longer a need to be afraid of future updates. We can achieve that by following the spirit of this book: by increasing our selective cluelessness!
Whenever we need to make a change in our libraries, we need to concentrate on the most important aspect of the change. What is it? It’s the changed behavior. We are likely making a change with some purpose. After all, we want to modify or extend some specific behavior, or we want to create new behavior. The most important aspect of change is that the modification will actually be achieved. This is even more important than the actual implementation of the change. In fact, the code that we create to do something is not important in and of itself if the “something” is really done—actually achieved.
It’s important to invest our energy, our time, and our intellect into ensuring that the change satisfies its purpose. For the rest, including the implementation, we can act completely cluelessly. The only aspect that matters is the creation of a guard. A guard is an objective: an automated entity that allows us to verify that there really is a problem that requires a change. In other words, it helps us determine whether our current situation initially differs from the dreamed state. After we move toward the target state, it enables us to verify that we are closer to where we want to be. Figure 11-6 illustrates that if you write a guard first and add an implementation afterwards, you cannot find yourself wandering in vicious circles. If with every new change, we ask our previous guards to verify that we are still closer to the dreamed state than we were before creating that guard, we can never regress to the state that we were in before.
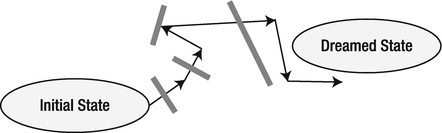
Figure 11-6. Writing guards
However, this doesn’t guarantee that we have reached the dreamed state. We can always move just a step closer to it, while never getting to it completely. However desperate this sounds, it’s much better than endless walking in vicious circles, and in fact, it probably reflects the reality of software projects. There are always some bugs; there is always a difference between the actual and the dreamed state. However, the important point is that guards can help us get closer with every step and even give us hope that we’ll get near our ultimate goal.
At this point I must apologize to people who might have become bored by the Odyssey and guards analogies, because they know the final point of this story. Yes, guards are automated tests. If you want to prevent unwanted changes in the runtime behavior of your libraries, simply write tests. If you want to increase the reliability of your code, selectively concentrate on writing good tests and then cluelessly write the implementation. The result will be much better than if you put 100 percent of your intellect into creating beautiful, elegant, and correct APIs. In fact, thinking about API design is good and is also the reason why this book talks about design patterns. However, nothing can replace careful engineering work. Only careful engineering work leads to reliability, which is why you should adopt cluelessness and write good tests.
Parallel behavior of programs and systems is one of the most difficult aspects to get right. There doesn’t seem to be a consistent theory or methodology for achieving deadlock-free programs. Of course, there are solutions. For example, it’s difficult to deadlock with pure functional languages, such as Haskell. However, for the rest of us—those who work with more traditional languages such as Java—the threat of deadlocks and improper synchronization is real. Still, it’s desirable to write multithreaded applications. Modern computers come with multiple processors, or at least multiple cores. If you need better performance, which is almost always the case, you cannot rely on single-threaded execution anymore.
It’s difficult to create a deadlock-free application when you control all its sources. In these “in-house” cases, you can enforce certain “good habits” and organize the whole application in a way that minimizes the likelihood of deadlocks. However, you can only know that there are no known deadlocks, not that there are no deadlocks at all. The source code of a system that has been successfully deployed for a few years without a single deadlock is worth its price in gold. Such sources are to be kept in a safe deposit box and modified only minimally and carefully.
However, we see the world from the point of view of a bulldozer. We assemble our applications from big modular pieces provided by others. We don’t want to know, and in fact cannot know all the synchronization details hidden within each library. We rely on the authors of the libraries to know what they are doing and to handle their synchronizations correctly. Moreover, we believe that when we mix multiple libraries, they will fit together and continue to stay deadlock free.
All this puts writers of shared libraries in a difficult position. They are supposed to design their APIs to work correctly in multithreaded environments, without knowing the whole of it. At the same time, they shouldn’t expose unnecessary levels of detail to API users, because those users want to remain as clueless as possible. This is not easy. In fact, it’s close to impossible, but a few design patterns and suggestions might prove useful.
The first and most common suggestion is to document the threading model properly—in other words, describe the assumptions that need to be fulfilled to use a library. In fact, this is something library writers neglect more than anything else. You can only add this info into the Javadoc’s prose section, as currently the Java platform doesn’t provide standard annotations or other Javadoc elements to document threading behavior of a class or method. Many libraries don’t do that at all. Those that do so suffer from the fact that the information is no more than free-form text that can be overlooked, missed, or ignored. There is also no way to enforce conformance to such informally described threading policies with automated tools.
FINDBUGS & CO.
There are tools that provide annotations for the threading behavior of a library and for verification that the threading behavior is being obeyed. As of this writing, these tools also need to define their own library with annotations. As these annotations are part of the documentation, they need to be visible at least in the Javadoc. Sometimes they are also present in the resulting binaries, which means that your library re-exports APIs of the testing tool. Because re-exporting foreign APIs should not be done lightly, as explained in the section “Beware of Using Other APIs” in Chapter 10, few people want to use these annotations until they are stabilized.
Recently we investigated this for the NetBeans APIs. We decided that we definitely didn’t want to leak these annotations into a binary class format. We wanted to keep things as they are today. However, as these “behavioral annotations” are handy, we decided to write our own, with source retention level only: they can be in the source and so the compiler validates them. However, they are removed before the class file is generated. We hope this is an acceptable tradeoff, before Java adopts a real, official, and stable alternative.
People say that a threading model should be easy to explain. They say it’s bad if it cannot be described in one sentence. I have to admit, I’ve always been a bit skeptical of being forced to condense it to that extent. However, this is probably possible with a certain level of cluelessness—by ignoring the details, at least in some cases.
An API is thread safe. That is the best description of a threading policy for every client making calls to an API. It means that you don’t need to care, or restrict the code from calling the API. Calling it in any state is acceptable. The API claims to be able to accumulate and handle such calls. On the other hand, this is slightly difficult for those who need to implement the API. A provider of the API needs to be ready to handle calls from anyplace, while the calling code holds any lock or resource. Nevertheless, the implementation needs to work. This can be complicated to write. That is why requiring a provider’s API to be thread safe doesn’t help toward the cluelessness of your providers at all. In fact, they need to be aware of what they’re doing and they also need to be very skilled to do so well, because even a small mistake can result in a deadlock of the whole system.
An unsynchronized API is usually only handy for objects that are not shared. These are objects that your calling code creates and keeps private. It’s fine not to synchronize anything and to delegate access control into the hands of the API’s user. An example is the java.util Collections API, and it seems to work well there. The client code only needs to be aware of the need to keep objects private and not to leak them out via method return types or calls.
Swing uses a dedicated thread policy. This is a relatively good balance for an API that is both client API as well as provider API, which is the case with Swing. Clients need to be aware of the restriction and always transfer control to the dedicated thread before making calls to the API. On the other hand, anyone who writes listeners or implements client components can expect the calls to be made from one thread. Then there is no need for synchronization and no need to worry about parallelism.
When two people do the same thing, the results are often quite different. The same can be said about Java synchronization primitives, called monitors. In fact, they are not monitors in the way the original authors intended them to be. This is partially caused by the difference between theory and reality and partially because of differences among object-oriented languages. Simply transferring the same solutions that worked in procedural languages might reveal surprising problems.
THE APRIL 2001 DEADLOCK
In April 2001, we ran into a problem with one of the NetBeans APIs. It deadlocked, suddenly and inexplicably. After a bit of investigation, I found a clash between our API locks and the locks used by the users of those APIs. This revealed that the standard synchronizations in Java have certain caveats that you have to be aware of when designing APIs.
The deadlock was quite obscure. Our API’s Children class used synchronized methods to keep its own private fields in a reasonable state. The synchronization of these structures was well thought out and there was no chance that this could deadlock, until we found the API being used in the definition of the EJBClassChildren subclass. There, it also used synchronized methods to protect the class’s own internal data structures.
However, according to the Java specification, defining a synchronized method is like synchronizing on this. Because the this for the Children class and its EJBClassChildren subclass was the same object, the two “monitors” accidentally merged into one. The two classes interfered with each other, and this unexpected interference resulted in a deadlock.
Per Brinch Hansen, who is one of the authors of monitors and who created Concurrent Pascal in the ’70s, wrote a paper called “Java’s Insecure Parallelism” in 1999.2 In the paper, he objected to Java’s attempt to call its synchronization model “monitor-based.” According to Hansen, a real monitor should allow a compiler to verify that the code is correct and thus help to eliminate programming mistakes. However, Java simply uses something that looks like a monitor, but doesn’t provide any of a monitor’s benefits. The Java compiler knows almost nothing about synchronization.
His primary objections were about insecurity, because you can mix synchronized and nonsynchronized methods into a class. So, it’s easy to allow access to internal structures without proper synchronization. Also, compared to the original monitor-based extension of Pascal, only private fields in a class are guarded from accidental unsynchronized access coming from outside the class. As a result, the amount of work put on a programmer’s shoulders is the same as when using the lowest synchronization primitives, such as semaphores. His argument is correct. Those of you who know what it takes to maintain a class that uses synchronized methods can only confirm that Java offers no comfort in this area.
When you maintain a class for a few years, over a few releases, you can easily forget to synchronize newly added methods. The only way to prevent this is always to use getters and setters, even for private fields, and to guard them with asserts:
private int counter;
private int getCounter() {
assert Thread.holdsLock(this);
return counter;
}
private void setCounter(int c) {
assert Thread.holdsLock(this);
counter = c;
}
This can guarantee that the field is never accessed without having a lock on the right object. It’s easy to see that this version lacks all the beauty and simplicity of the original Concurrent Pascal monitors. I know, yes, beauty is not important. However, here it also verifiably increases the likelihood of errors in multithreaded Java code.
Hansen was right. It’s easy to leak out internal data structures from an object that’s likely to be synchronized. This shouldn’t be compared to monitors at all. As far as I can see, Hansen didn’t know, or at least doesn’t mention, the most significant leakage, which is the fact that subclassing shares locks.
The original monitor design was done for a procedural language that had no concept of subclassing. Nobody even expected that if you have a monitor (a data structure with access methods) that it’s possible to extend the declaration. It’s quite the opposite, in fact. The monitor is supposed to be self-contained. All the data and all the operations are declared together, written in one place, by one person, completely isolated from the rest of the system.
THINGS ARE NOT HOW THEY SEEM
When I saw the synchronization approach in Java for the first time, I thought it was based on a monitor model that I knew from school. As far as I remember, it was explained as an extension to the Pascal record structure. You could create a new record and in its definition list all methods that should be synchronized with it. That is similar to Java synchronization. You define a class and can then synchronize its methods.
In Java there are two ways to synchronize: either you create a synchronized method or you use a synchronized block:
synchronized (anObject) {
// do the critical stuff
}
Ask yourself which of these ways is preferred. I have to admit that I used to think it was better to synchronize methods.
The suggested way is to use synchronized in the definition of a method. Fine, that can work for me. I am able to write my code in one class without deadlocks. But what if somebody subclasses my object and also uses synchronized methods? Well, in that case it uses the same lock as mine, usually without any knowledge as to how I should use the lock, because my synchronized methods can be private and thus not of interest to subclasses. The result? Deadlocks everywhere.
Subclassing and using synchronized methods sneaks into the superclass’s own synchronization model. That can completely invalidate any synchronization assumptions the superclass has made. Doing so is just plain dangerous. It can happen in any Java program. However, when writing APIs, this is almost a killer. APIs must be designed for simple, almost clueless use. By interfering with a subclass’s locking scheme, you expose the poor users of your API to many more details than necessary. You inherently hurt your own reputation, as your library is then known to be full of deadlocks.
The only way to prevent this is never to synchronize with a class that is visible in the API. That also means that you shouldn’t use any synchronized methods in classes exposed in the API. This is especially harmful in the case of subclassable classes, as users might still believe that synchronization in Java is monitor-based and that when writing a class they have the right to add their own synchronized methods. The only way to prevent such interference is to use internal locks, as follows, or similar locking mechanisms from the java.util.concurrent packages:
private final Object LOCK = new Object();
private int counter;
private int getCounter() {
assert Thread.holdsLock(LOCK);
return counter;
}
private void setCounter(int c) {
assert Thread.holdsLock(LOCK);
counter = c;
}
These are all low-level techniques, far from the concept of a monitor, but they at least guarantee that privileged synchronized sections won’t collide. This is not nice and a bit complicated. However, unless Java provides some syntactically nicer and still correct synchronization model, it’s more important to get the synchronization in an API right than to do it in a simple and comfortable way.
Fighting with deadlocks is the sad destiny of any multithreaded application. The problem field has been extensively researched because it causes huge problems for every writer of an operating system. Most applications are not as complex as operating systems. However, as soon as you allow foreign code to run in your application, you have to fight with the same set of problems.
In spite of the huge research efforts, no simple solution has yet been found. We know that a deadlock is created under four conditions:
- Mutual exclusion condition: There has to be a resource (lock, execution queue, and so on) that just one thread can own.
- Non-preemptive scheduling condition: It is not possible to take away or release a resource already assigned by someone other than its owner.
- Hold and wait condition: A thread can wait for a resource indefinitely and can hold it indefinitely.
- Resources can be acquired incrementally: You ask for a new resource (lock, execution queue), while already holding another one.
If we write code that breaks at least one of these conditions, then we know that we’ll get a deadlock-proof system. However, writing such code is not easy; there is no standard coding technique in Java to follow. From time to time we resolve to code breaking mutual exclusion— sometimes the hold and wait condition, sometimes the others. Then we merge our libraries and find out that they deadlock anyway. Moreover, we also don’t know how to do a static analysis over source code to check whether a deadlock can or cannot appear. It’s not easy to fight with deadlocks.
The basic advice for a programmer using a language with threads and locks, such as Java, is do not hold a lock while calling foreign code. If you follow this rule, you eliminate the fourth condition. Because all four conditions must be satisfied to create a deadlock, you might believe that you have now found the ultimate solution to deadlocks! However, it can sometimes be difficult to satisfy the restriction. For example, can the following code deadlock?
private HashSet<JLabel> allCreated = new HashSet<JLabel>();
public synchronized JLabel createLabel () {
LOG.log(Level.INFO, "Will create JLabel");
JLabel l = new JLabel ();
LOG.log(Level.INFO, "Label created {0}", l);
allCreated.add (l);
return l;
}
This piece of code feels safe, because the only real call is to HashSet.add. HashSet doesn’t use synchronized at all. In fact, though, there is a lot of room for failure here. The first problem is that JLabel extends JComponent. Somewhere in JLabel’s constructor, you acquire the AWT tree lock: JComponent.getTreeLock(). Say someone writes a component that overrides:
public Dimension getPreferredSize () {
JLabel sampleLabel = createLabel();
return sampleLabel.getPreferredSize ();
}
Then, you are in danger of a deadlock, because the getPreferredSize method is often called when a component is painted while the AWT tree lock is held. Even though you tried hard not to call foreign code, you’ve just done so. The second and even less visible problem is the implementation of HashSet. It uses Object.hashCode() and Object.equals, which again can call virtually anywhere because any class can override them. So, if the implementation acquires another lock, you can get into similar problems that are even less expected.
The advice here is simple: where possible, don’t hold locks while calling foreign code, especially if the code is “above” your library. What do I mean by “above”? Well, you cannot code without depending on other libraries. For example, in many cases you need to read files, manipulate strings, and use collection utilities. However, all these classes are on the “bottom” of the library hierarchy. The JDK’s rt.jar provides them, and their default implementations don’t call anything outside the JDK’s boot classpath. Your library is “above” the rt.jar, because it sees the JDK’s classes on the classpath and can make direct calls to them. This cannot deadlock unless the JDK is buggy or it calls back into some higher level, outside the JDK’s own classes.
Users of your library are in a similar position. They can see your classes on the classpath. They can make calls to you. However, unless your library is buggy or you make a call from outside your classes, there cannot be a deadlock. You’ve created a hierarchy of locks and you can guarantee that they are always obtained in the same order. There are two basic threats to this hierarchy ordering: subclassing and listeners.
If you allow subclassing, you essentially create one slot for each nonfinal method that can be filled in with foreign code. Therefore, in classes that allow subclassing, you should never call a method that can be overridden while holding a lock. Alternatively, as suggested in the section “Delegation and Composition” in Chapter 10, you should replace subclassable classes with more interfaces and you should replace delegation with a clear separation of concerns.
Listeners are just another path to creating slots. Whoever registers a listener into your object injects a piece of code in the middle of your methods’ execution. That code is completely unknown to you. You shouldn’t make assumptions about what the code will do. Moreover, in almost all cases, this code is “above” your library in the hierarchy created by the classpath dependencies. That code can likely see your classes, because it can call your addXYZListener methods. Therefore, it has full rights to call back to you at any time. As a result, you are asking for trouble if it’s called while you are holding some of your locks. Always make sure that you call your listeners without holding locks.
RUN ATOMIC ACTION
Fixing your code to never call a listener with a lock might not be enough. Let’s take as an example the NetBeans FileSystem library. As has already been noted a few times, NetBeans uses the FileObject abstraction to access files instead of directly using java.io.File. The advantage is that FileObject supports listeners. So, code in NetBeans can observe changes to files and adapt its views to reflect their state.
Listeners are notified synchronously. This is an advantage that simultaneously has negative side effects because it’s a huge source of deadlocks. Initially, our implementation of the library was buggy. Our implementation called back to the listeners while holding our own locks. This continually caused problems that we needed to fix. However, to our surprise, it wasn’t enough to fix the code of the FileSystem library to eliminate deadlocks.
The problem is that whoever calls the FileSystem API to write or remove a resource can trigger its listeners. Because listeners are unknown code, it’s not reasonable to call the FileSystem API methods under a lock. On the other hand, this is inevitable in certain situations. People need to keep their internal structures synchronized. Writing to disk is occasionally necessary. Calling an API at a “lower” level (on someone’s classpath) is safe and acceptable. However, because of listeners and the fact that in the NetBeans IDE almost everything listens on file changes, this was not safe at all.
Our solution to this problem is called atomic action. No, our filesystems don’t support transactions. However, they allow any code to postpone notifying listeners. You can enclose code within a Runnable, pass it to the FileSystem library, change the files, and remain sure that no events will be delivered from this thread while the runnable is not finished. Any code can start an atomic action, grab its own listener, and create or remove resources on disk, without the danger of unknown code being called.
It seems to me that almost any low-level library that supports synchronous listeners should provide support for atomic actions, similar to how our filesystems do. Otherwise, the risk of deadlocks exists. The danger increases with the number of users of the library. However, the support for atomic operations is not really straightforward. That is why if I had the chance to write the FileSystem API again, I would support only asynchronous listeners.
The other option, and according to our NetBeans experience probably the better one, is to always call a listener asynchronously in a dedicated dispatch thread. This is safer. The dispatch thread doesn’t hold locks. However, events are delivered “later,” when the state of the model might already be quite different. As a result, such events don’t need to—or even shouldn’t be able to—carry much information about the state when they were generated. The presence of this information is at least misleading, because the state of the model can already be quite different. A plain “I am changed” event is enough for the rest of the listeners to query the model.
Asynchronous execution is a powerful approach to fighting deadlocks. Just like the spooling of print jobs can prevent deadlocks when operating system processes want to use a printer, posting a piece of code to be executed “later” can prevent competition between threads for sparse resources. However, deferred execution is never as clean as deferred printing. The advantage of a printer is that processes cannot wait for the pages to be printed. Once the print job is sent, it’s up to humans to pick up the results, while programs continue to run without waiting for that to happen. This is not always true with deferred execution. There are situations when code needs to, and wants to, wait for successful completion of such deferred code. Then we are back where we started: at risk of deadlocks.
A nice example of the pros and cons in this area is the SwingUtilities.invokeLater method versus the SwingUtilities.invokeAndWait method. Both methods schedule a Runnable to be executed later in the AWT dispatch thread, which is the thread dedicated to operations on Swing components. While SwingUtilities.invokeLater is generally safe because it simply schedules execution and returns immediately, SwingUtilities.invokeAndWait could be renamed “invoke and deadlock.” It schedules execution and then blocks. If the calling thread already holds locks, especially an AWT tree lock, a deadlock is almost inevitable. Of course, bad code in a Runnable that is sent to SwingUtilities.invokeLater can also deadlock. However, in that case you need to make a conscious effort to create deadlocks. For example, you need to perform a few tricks with synchronization yourself. SwingUtilities.invokeAndWait causes deadlocks without much trouble at all. Such methods shouldn’t be a part of an API that is supposed to eliminate deadlocks. Sometimes they are necessary, such as in tests where it’s necessary to wait for asynchronous deferred execution to finish. In these cases, the method should look completely different and not be a sibling of safe methods such as SwingUtilities. invokeLater.
SCHEDULE VS. WAIT
The Java 5 concurrent utilities include support for deferred execution in the form of the ExecutorService class. This class makes it clear that posting code is different from waiting for it:
ExecutorService service = Executors.newSingleThreadExecutor();
// scheduling is quite different
Future<?> task = service.submit(someRunnable);
// compared to waiting
task.get(1000, TimeUnit.MILLISECONDS);
This builds on the expected knowledge that waiting is something that can cause deadlocks and that developers should do so with care.
However, it’s difficult to completely eliminate waiting. That would turn the whole system into a kind of message-based program. Various Java Messaging Servers prove that this kind of program is possible. However, it’s difficult to adopt this style with programs that are not message-based, or with libraries. You can defer as much execution as possible. However, there comes a time when it’s necessary to wait. The only way to prevent deadlocks while waiting is to allow only time-out waits: to allow a thread to block for a certain amount of time only. This breaks the third deadlock-creation condition where a thread can wait for a condition indefinitely. It prevents deadlocks as well, unless someone puts the wait into a while loop, of course.
EASY CLIENT API, DEFERRED PROVIDER API
The time-out trick can be useful if you want to create an API for callers that can be used from any thread and you want to bridge that into a more simple threading model for providers. Providers can then be sure that everything is processed in a single thread. This, in turn, minimizes parallel execution problems on the provider’s side.
Remember to create a single processor thread that is used to handle requests from clients. Whenever a client calls into the API, simply post a future task to the processor. Then either return immediately if the method has no return value or block for a certain time-out period, during which time the processor should handle the request. If the time-out period is exceeded, simply throw an exception to the caller to signal the cancellation of the request.
I prototyped this behavior when I tried to eliminate deadlocks in the NetBeans DataSystem API. Because almost all methods in that API deal with files, they can throw IOException. So, it was easy to create TimeoutException extends IOException and throw it after the time-out period. People already needed to check for IOException, so this code didn’t complicate anything further.
This solution would eliminate deadlocks as well. However, it might also increase the unpredictability of the system’s behavior. After all, sometimes the time-out can occur when there is no deadlock. That is why this code is currently not used in NetBeans. However, I am sure it can effectively, and together with proper testing, reliably eliminate deadlocks if needed in the future.
Another way to break the indefinite waiting (the third deadlock condition) is to take away a resource from a thread from outside. This is difficult to do when a thread is waiting for entry to a synchronized block or method. On the other hand, it’s possible in the case of SwingUtilities. invokeAndWait. For the latter, the AWT event dispatch thread is a resource as well, and various other threads compete to enter it. It’s possible to write a watch thread, or change the behavior of the invokeAndWait method itself, to watch for deadlocks. Do this by inspecting the stack traces obtained from Thread.getAllStackTraces. If the deadlock is observed, you can interrupt the thread, thereby breaking the deadlock.
As you can see, the possibilities when fighting deadlocks are endless. That, in turn, is probably because none of them are guaranteed to succeed. All of them can easily be violated, making them insufficient. We faced this problem with NetBeans too. Because deadlocks are fatal, we continued to search for a solution to prevent them. We gave up on beauty and elegance and instead focused on finding a consistent methodology. We applied the bulldozer by exterminating known deadlocks through writing tests.
Deadlock Test
Although it’s difficult to prevent deadlocks, analyzing them in Java is easy. In contrast to native C, whenever a Java application freezes you can still produce a thread dump. From the thread dump, you can get a picture of the problem. From there, it’s just a small step to fix the code, lock on another lock, or use the SwingUtilities.invokeLater method to reschedule the code from the dangerous section sometime “later.” We used this style for a few years, resulting in unpredictable code. We didn’t exterminate many of the deadlocks. When we modified the code to fix a deadlock, we often created a new one somewhere else. My favorite example is the change we made in our classes on June 26, 2000 and February 2, 2004, as shown in Figure 11-7. Both tried to fix a deadlock. The second returned us to the state that we had prior to the first integration. We had successfully shifted the amoeba shape of our code to fix a deadlock in 2000; four years later we simply shifted it again. We improved in one part, but regressed with respect to 2000’s fix. This would never have happened if, together with the first fix, we had acted in a selectively clueless manner by also writing and integrating a test!

Figure 11-7. Shifting the amoeba one way in 2000 and back in 2004
A test for a deadlock? Yes, a test for a deadlock. However surprising that might sound, it’s possible and often not difficult to write a test for a deadlock. We often write a test for a deadlock in about two hours; we’ve never needed more than a day. Beyond the automated nature of this kind of test, it also gives the developer the confidence to say that something has been fixed, which is usually not fully obvious due to the “esoteric” nature of deadlock fixes: they usually cannot be reproduced—definitely not by our quality department—so also cannot be verified. In addition, when there is a test, you can choose a simpler solution that fixes the problem, instead of inventing something that is both intellectually elegant and overcomplicated. The result is that the art of deadlock fixing turns into regular engineering work. And we all want our applications to be developed by engineers, don’t we?
Writing a test for a deadlock is not that difficult. In our imaginary situation with createLabel we could do that by writing a component, overriding getPreferredSize, stopping the thread, and waiting while another thread locks the resources in the opposite way:
public class DeadlockTest extends NbTestCase {
static final Logger LOG = Logger.getLogger(
DeadlockTest.class.getName()
);
public DeadlockTest(String n) {
super(n);
}
@Override
protected int timeOut() {
return 10000;
}
public static class StrangePanel extends LabelProvider {
@Override
public Dimension getPreferredSize () {
try {
Thread.sleep(1000);
JLabel sampleLabel = createLabel();
return sampleLabel.getPreferredSize();
} catch (InterruptedException ex) {
Logger l = Logger.getLogger(
DeadlockTest.class.getName()
);
l.log(Level.SEVERE, null, ex);
return super.getPreferredSize();
}
}
}
public void testCreateLabel() throws Exception {
final LabelProvider instance = new StrangePanel();
class R implements Runnable {
public void run() {
JFrame f = new JFrame();
f.add(instance);
f.setVisible(true);
f.pack();
}
}
R showFrame = new R();
SwingUtilities.invokeLater(showFrame);
Thread.sleep(500);
JLabel result = instance.createLabel();
assertNotNull("Creates the result", result);
}
}
The test works with two threads. One creates a component and shows it, which results in a callback to getPreferredSize under the AWT tree lock. At that point, we start another thread and wait a while for it to acquire the createLabel lock. Under the current implementation, this blocks in the JLabel constructor, and as soon as our thread continues (after 1000ms), we create the deadlock. There can be many fixes, but the simplest is probably to synchronize on the same lock as the JLabel constructor:
private HashSet<JLabel> allCreated = new HashSet<JLabel>();
public JLabel createLabel () {
synchronized (getTreeLock()) {
LOG.log(Level.INFO, "Will create JLabel");
JLabel l = new JLabel ();
LOG.log(Level.INFO, "Label created {0}", l);
allCreated.add (l);
return l;
}
}
The fix is simple; much simpler than the test. However, without the test, we wouldn’t make the shape of our amoeba more steady. The time spent writing the test is more than likely time well spent.
Often you can write the test by using an already existing API, such as in the case of the getPreferredSize method. Only in special situations do you need to introduce a special method that helps the test to simulate the problem. This is okay, as the tests are usually in the same package as the code and can use package private methods for communication, without exposing unnecessary details to the users of the API.
Deadlock tests are pure regression tests. You write them when a bug is reported; nobody will write them in advance. In the beginning, it’s much wiser to invest in good design, but as I explained earlier, because there is no universal theory on how to prevent deadlocks, you should know what you want to do when a deadlock appears. For that reason, I suggest that testing is the best way with respect to our amoeba shape.
A similar yet slightly different set of tests that relates to parallel execution is able to check for problems with race conditions. Just like deadlocks, problems with multiple threads and their synchronization are difficult to anticipate. However, once you get a bug report that something is wrong, it’s possible and useful to write tests to verify that various problems with parallel access to data structures are correctly handled. Sometimes it even makes sense to write these kinds of tests in advance.
We faced this problem when we were asked to write a startup lock for NetBeans. The goal was to solve the situation when a user starts the NetBeans IDE for the second time. Here, we needed to warn the user that another instance of the application was already running. After the warning, we needed the new process to exit. This is similar to the behavior of Mozilla or OpenOffice.org. We decided to allocate a socket server and create a file in a well-known location with the port number written to it. Each newly started NetBeans IDE can verify whether a previously running instance is active or not by reading the port number and trying to communicate with it.
DOES THIS HAVE ANYTHING TO DO WITH API DESIGN?
Yes, it does. The startup lock is an example of a file-based API, as well as a protocol-based one. It allows any process to communicate with an already running instance of NetBeans, and as such its proper behavior is an important factor that all third-party code can depend on. Moreover, in a recent version of NetBeans we also published a Sendopts API—a set of Java classes that allows each module in NetBeans to parse the command line. This API is more approachable by most developers, and as it relies on the startup lock to function properly, it makes it the subject of thorough testing.
The major problem we had to optimize for was to solve the situation where the user starts multiple NetBeans IDEs simultaneously. This can happen when the user clicks multiple times on the NetBeans desktop icon or when multiple files are dragged and dropped onto it. This causes multiple processes to start and compete with one another for the file and its contents. The sequence of one process looks as follows, but the system can interrupt it at any time:
public static int start(File lockFile) throws IOException {
if (lockFile.exists ()) {
// read the port number and connect to it
int alive = readPortNumber(lockFile);
if (alive != -1) {
// exit
return alive;
}
}
// otherwise try to create the file yourself
lockFile.createNewFile();
DataOutputStream os = new DataOutputStream(
new FileOutputStream(lockFile)
);
ServerSocket server = new ServerSocket();
int p = server.getLocalPort();
os.writeInt(p);
return p;
}
Then, instead of executing as an atomic operation, control can be passed to the competing process that performs the same action. What happens when one process creates the file, while another tries to read it, before a port number is written? What if a file left from a previous execution has been killed? What happens when a test for the existence of a file fails, but when you try to create it, the file already exists?
You need to ask all these questions if you want to be confident about your application code. To get the confidence we were looking for, we inserted several checkpoints into our implementation of locking. The code became a modified version of the previous snippet, where the enterState method does nothing in the real production environment, while in the test environment it can be instructed to block at a specific checkpoint:
public static int start(File lockFile) throws IOException {
enterState(10);
if (lockFile.exists ()) {
// read the port number and connect to it
enterState(11);
int alive = readPortNumber(lockFile);
if (alive != -1) {
// exit
return alive;
}
}
// otherwise try to create the file yourself
enterState(20);
lockFile.createNewFile();
DataOutputStream os = new DataOutputStream(
new FileOutputStream(lockFile)
);
ServerSocket server = new ServerSocket();
enterState(21);
int p = server.getLocalPort();
enterState(22);
os.writeInt(p);
enterState(23);
return p;
}
We can write a test when we start two threads and instruct one of them to stop at 22 and then let the second run and observe how it handles the case in which a file already exists but the port is not yet written.
This approach worked well, and despite the concerns of some initial skeptics, we got about 90 percent of the behavior right before we integrated the first version. Yes, there was still more work to do and bugs to fix after that. However, because we had well-automated tests for the behavior we had implemented, our amoeba edge was well-formed. We had enough confidence to enable us to fix all the outstanding problems.
As is to be expected, the 10 percent of random failures mentioned in the previous section cause more work than simply the next 10 percent of additional tests and fixes. In fact, they have inspired this whole part of the book. Dealing with failures that happen randomly from time to time, and usually on a computer that you don’t own, requires more sophisticated tracking techniques.
The problem with parallel execution is that there is not much information to help anyone to analyze what is not working properly. Existing methodology is either weak, missing, or just too concentrated on specific cases. Debuggers are not ready to push debugged applications to their “parallel limits.” To really move somewhere, people resort to the oldest solution: to println and logging. This usually gives the best results. Just add log messages into your code, run it a few times, wait until it starts to misbehave, then try to figure out from the log file what went wrong and fix it. Luckily, testing can take a similar approach. Enhance the application code and also the tests with logging, and if the test fails, output all the collected log messages as part of the failure report.
We achieved this by writing our own implementation of Handler, which is a JDK class for processing log and error reports. Because the base API is in the JDK, in java.util.logging, it means that you can use this code in any test or application code, without the need to require any special libraries in your own execution environment. To capture the produced messages, just implement your own Handler. The implementation has to be registered at the beginning of the test and has to capture all logged messages. In case of failure, you must make them part of the failure message:
public class CLIHandlerBlockingTest {
public CLIHandlerBlockingTest() {
}
@BeforeClass
public static void initHandler() {
Logger.getLogger("").addHandler(new H());
Logger.getLogger("").setLevel(Level.ALL);
}
@Before
public void setUp() {
H.sb.setLength(0);
}
@Test
public void start() throws Exception {
File lockFile = File.createTempFile("pref", ".tmp");
int result = CLIHandlerBlocking.start(lockFile);
assertEquals("Show a failure" + H.sb, -10, result);
}
private static final class H extends Handler {
static StringBuffer sb = new StringBuffer();
@Override
public void publish(LogRecord record) {
sb.append(record.getMessage()).append('
');
}
@Override
public void flush() {
}
@Override
public void close() throws SecurityException {
}
} // end of H
}
Logging can be done by the test to mark important sections of its progress. The main advantage of this approach is that your code won’t contain any alien elements related to testing. At most it will be full of standard Java logging calls to java.util.logging.Logger.log. The test then collects all the messages, and in the case of a failure, provides a complete and detailed description of the failure. The problem can then be analyzed. You can then either fix the problem or make the logging more detailed to help to track the problem more effectively.
Sometimes people are reluctant to analyze random failures in tests because these are assumed not to affect production code. While it might turn out that the problem is in the test and the code is okay, relying on this outcome is risky. Without a deeper understanding, you risk having a problem in the application code. Even if it’s not reproducible all the time, it could have extremely negative consequences on the rare occasions it arises. If you want to trust your application’s behavior, it’s a good idea to add a logging message to the application code and to write logging-friendly tests.
The NetBeans project started to introduce tests that collect logged output. Only the most exposed places were focused on, meaning places where failures often occurred due to overly complicated usage of multiple threads. However, bear in mind that every application written in Java is nondeterministic, even if it consciously uses only a single thread. Depending on conditions external to the tested program, the garbage collector might start. When dealing with visual components, there is at least the AWT event dispatch thread, which can also receive events in a not strictly defined order. As a result, it turned out that logging support is useful in almost any test. The NetBeans project decided to support it in its NbJUnit extensions. This is a general library, not specific to NetBeans at all, that can be used in any project.
The simplest add-on is to support message collection during the running of a test. You can simply override the logLevel method in any subclass of NbTestCase. Let’s look at the following example:
public class CLIHandlerBlockingWithNbTestCaseTest extends NbTestCase {
public CLIHandlerBlockingWithNbTestCaseTest(String s) {
super(s);
}
@Override
protected Level logLevel() {
return Level.ALL;
}
public void testStart() throws Exception {
File lockFile = File.createTempFile("pref", ".tmp");
int result = CLIHandlerBlocking.start(lockFile);
assertEquals("Show a failure", -10, result);
}
}
Here the logging of all message levels is collected. If any of the test methods fail, the reported exception will contain the output of all messages logged during the program’s execution, in the following format:
[name.of.the.logger] THREAD: threadName MSG: The message
The text in the exception message is truncated to a reasonable length. The full log report is also available. In NbTestCase.getWorkDir(), which would usually be /tmp/tests/ testLogCollectingTest/testMethodOne, a file called testMethodOne.log is found. The file contains the last 1MB of logged output. That should be enough for cases where you need a deeper analysis of complex logging code because most of the recently logged information will be available.
COMPARING FAILURE AND SUCCESS
Sometimes logged messages can get fairly long, and especially in cases of random failures, it might not be easy to analyze what happened in the test. Based on our experience, the best strategy for such situations is to add a fail("Ok"); line to the place in the test where the execution randomly fails. This will generate a log file, as well. The two log files—the one from the real failure and the one from the correct run—can then be compared and diffed against each other. It’s wise to replace all @543dac5f messages in the output with something more neutral, because each run will have different memory locations. After resolving the difference, it’s generally possible to understand the difference between the two runs and the root cause of the failure.
One of two reasons might explain why gaining an understanding of the differences between log files might not be possible. The first is that there might not be enough logs. Information recorded in a log file could simply be too coarse to provide meaningful information about what happened during the test run. Here the fix is to insert more logging messages into the test code. Using the NbTestCase.logLevel method, you can add more logging on various levels, such as Level.FINE, Level.FINER, and Level.FINEST. In different test cases, you can enable different test messages. When working with suspicious random failures that can potentially influence a critical piece of code, you might even need to log information about each line of code that is executed. You’ll possibly need to send arguments to various methods and states of your local variables. Doing so should generate enough information to allow a detailed understanding of the reasons for the random failures occurring.
On the other hand, there is a subtle catch: the more log messages you add to your application, the further its behavior will change. Every call to Logger.log adds additional delays, and formatting your recorded messages also takes time. In fact, a failure that only occurs one-third of the time might almost completely disappear because of all the logging code added to your application. Increasingly, a failure becomes more difficult to repeat, and therefore more difficult to evaluate. Sometimes, you almost want to give up trying to emulate the problem, even with a debugger. However, from time to time the failure might reappear on someone else’s machine. In NetBeans, we have a farm of machines that run tests on a daily basis in various configurations. This frequently helps to track down even the rarest of errors. Even when we don’t find the bug on the developer’s workstation, we tend to receive bug reports from the testing infrastructure, enabling us to hunt the bug down there.
Another problem arises when there are too many logging messages in your application. In this scenario, it’s difficult to pinpoint where the messages are coming from. For example, if the test executes a series of steps that result in repeated calls to the same piece of application code, the same log messages are printed and you can find yourself completely lost. This is especially difficult if the application performs a computation in a loop, where it repeats the same or similar messages over and over again. In such cases, my advice is to put your logging messages into the testing code itself. Those messages anchor the base orientation in the log output. When comparing the differences between the successful and unsuccessful runs, you can first locate the test messages and compare the differences between the application messages inserted among them. The best advice when fighting random failures is to do a lot of logging, capturing your messages in tests, and printing enough messages from the application as well as from tests. As a result, the likelihood of understanding the root cause of the failure will increase dramatically.
A slightly different approach is to test that something has been logged. For example, when a new method in your API should be overridden by subclasses, you might want to let the existing classes (those that are compiled against a previous version of the class) know about it during runtime:
protected boolean overideMePlease() {
Logger.getLogger(OverrideMePlease.class.getName()).warning(
"subclasses are supposed to override overrideMePlease() method!"
);
// some default
return true;
}
Anyone focused on testing wants to ensure that the warning will be printed only in the appropriate situations. You can either play the trick with your own logger, or you can use a special utility method in the NbJUnit library that will handle everything itself. So, you can simply do the following:
CharSequence log = Log.enable("org.apidesign", Level.WARNING);
OverrideMePlease instance = new OverrideMePlease() {
@Override
protected boolean overideMePlease() {
return true;
}
};
if (log.length() != 0) {
fail("There should be no warning: " + log);
}
This is simply a small utility method, but it helps to easily access and analyze what is logged from inside the test case. Together with the rest of the support in the org.netbeans.junit. NbTestCase and org.netbeans.junit.Log classes, this should provide sufficient support to use logging when fighting the unwanted shifting of the amoeba’s edges.
Execution Flow Control Using Logging
The earlier sections that discussed race conditions and the simulation of deadlocks implied a need for hooks in the code to allow the testing environment to simulate “obscure situations.” The hooks would stop threads in critical sections while modifying internal structures either to corrupt internal data or to stop the thread in places that cause a deadlock with other executing threads. The previous sections suggested that you should insert special methods accessible from the testing code. These should allow for the execution control you need. Either you need to have your code filled with inserted statements such as enterState(10), or you need to provide overridable methods that let the tests provide the hook. However, you need to let these methods do something “insane” during the test, and who wants to have insane methods in their own code, anyway? Though this is possible, there is a small, and by this stage, obvious enhancement: instead of putting special methods into the code, simply insert logging messages!
Logging messages? Yes, logging messages! The beauty of this solution lies in the fact that logging is, or at least should be, a natural part of even the least complicated program. So, you don’t need to obscure your code with enterState. Instead, you can simply use the following:
LOG.log(Level.INFO, "Will create JLabel");
JLabel l = new JLabel ();
LOG.log(Level.INFO, "Label created {0}", l);
These log messages are completely natural. Logging simply fits naturally into your programming work.
Now, the testing code can register its own Handler. In the Handler’s publish method, it can do all the “wild” things. Instead of polluting your application code with all kinds of special hacks, you can achieve the same result by adding a logging handler. Then analyze the messages passed to your handler during the execution of your tests. Meanwhile, your application code stays clean and the test is as powerful as the messages logged in the application code. Each logged message is a chance for the test to influence the application’s behavior. Taken to an extreme, it’s possible to completely control a multithreaded program’s behavior by suspending all threads other than the one that should be executed. For example, imagine the following program:
class Parallel implements Runnable {
public void run() {
Random r = new Random();
for (int i = 0; i < 10; i++) {
try {
Thread.sleep(r.nextInt(100));
} catch (InterruptedException ex) {}
Logger.global.log(Level.WARNING, "cnt: {0}", new Integer(i));
}
}
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(new Parallel(), "1st");
Thread t2 = new Thread(new Parallel(), "2nd");
t1.start(); t2.start();
t1.join(); t2.join();
}
}
The program runs two threads, each counting from one to ten, while pausing for random milliseconds. The threads run in parallel. The speed of counting is random. You can easily verify this with a simple NbTestCase, with enabled logging:
public class ParallelTestextends NbTestCase {
public ParallelTest(String testName) {
super(testName);
}
@Override
protected Level logLevel() {
return Level.WARNING;
}
public void testMain() throws Exception {
Parallel.main(null);
fail("Ok, just print logged messages");
}
}
When executed once, the output might be similar to the following:
[global] THREAD: 2nd MSG: cnt: 0
[global] THREAD: 1st MSG: cnt: 0
[global] THREAD: 2nd MSG: cnt: 1
[global] THREAD: 2nd MSG: cnt: 2
[global] THREAD: 2nd MSG: cnt: 3
[global] THREAD: 2nd MSG: cnt: 4
[global] THREAD: 1st MSG: cnt: 1
[global] THREAD: 1st MSG: cnt: 2
[global] THREAD: 2nd MSG: cnt: 5
[global] THREAD: 2nd MSG: cnt: 6
[global] THREAD: 1st MSG: cnt: 3
[global] THREAD: 1st MSG: cnt: 4
[global] THREAD: 2nd MSG: cnt: 7
[global] THREAD: 1st MSG: cnt: 5
[global] THREAD: 2nd MSG: cnt: 8
[global] THREAD: 2nd MSG: cnt: 9
[global] THREAD: 1st MSG: cnt: 6
[global] THREAD: 1st MSG: cnt: 7
[global] THREAD: 1st MSG: cnt: 8
[global] THREAD: 1st MSG: cnt: 9
However, subsequent executions create output that looks different. When the program is executed again and again, the output is unlikely to look exactly the same as in the previous iteration. That is acceptable. When two threads run in parallel, the result is obviously nondeterministic. However, imagine that one of the execution orders is “special” in some way. For example, imagine that an execution order is known to cause a race condition or a deadlock. Wrong behavior of this kind should be fixed. However, as discussed throughout this book, wrong behavior should also be simulated. Otherwise the struggle with the amoeba will never end. You should try to write a test that simulates the order of execution that is known to be broken. For example, let’s try to generate a highly unlikely sequence where each thread increments and prints one number, goes to sleep, and then lets the other thread run. It’s highly improbable for this kind of output to happen randomly. Therefore, it’s reasonable to question whether this kind of test can be written at all. But . . . it can! With a little help from logging messages, here is the code that forces the threads to behave deterministically and always outputs only one number from the sequence:
public class ParallelSortedTest extends NbTestCase {
public ParallelSortedTest(String testName) {
super(testName);
}
@Override
protected Level logLevel() {
return Level.WARNING;
}
public void testMain() throws Exception {
Logger.global.addHandler(new BlockingHandler());
Parallel.main(null);
fail("Ok, just print the logged output");
}
private static final class BlockingHandler extends Handler {
boolean runSecond;
public synchronized void publish(LogRecord record) {
if (!record.getMessage().startsWith("cnt")) {
return;
}
boolean snd = Thread.currentThread().getName().equals("2nd");
if (runSecond == snd) {
notify();
runSecond = !runSecond;
}
try {
wait(500);
}catch (InterruptedException ex) {
}
}
public void flush() {
}
public void close() {
}
}
}
When the test is executed, you can see that each thread adds 1 to its counter and gives execution control to the other thread. This behaves deterministically in almost all cases. Nearly every execution of the test yields ascending output. The basic trick that allows the miracle to happen is the interception of the output messages. The special BlockingHandler, which the test registered before the application code started, analyzes the messages sent to it by the application threads. It suspends and then resumes the threads to simulate the execution order, where each thread adds one number and is then suspended by the operating system in favor of the other thread.
The beauty of this solution is that the application code doesn’t know that the test controls its execution flow. If you were to look at the application code itself, you wouldn’t be able to guess that a test does these kinds of “wild” things to the code, because the actual application code looks natural. Only due to the possibility of intercepting the logging messages is the test given the chance to influence the execution flow. As a result, the test is able to simulate even the “wildest” and least probable execution order.
Writing the BlockingHandler correctly might not be easy, especially when more than two threads need to interact. It’s even more difficult if the messages that need to be analyzed are not simple. That is why the NetBeans JUnit extensions library contains a support method called Log.controlFlow, which registers the handler itself and performs all its own thread manipulations. You only need to specify the expected message order. A nice bonus is that the format of the expected messages is "THREAD: name MSG: message", which exactly matches the output reported by NbTestCase when you enable capturing log messages by overriding the logLevel method. You can simply copy the output and feed it to the controlFlow method, possibly without any modifications. However, as the real-world messages sent to a logger often contain some content specific to each run (such as @af52h442, which identifies the location of the object in memory), it’s possible to use regular expressions to describe the expected messages. Here is one possible rewrite of your test that uses the Log.controlFlow method to simulate the “one by one” order of execution:
public void testMain() throws Exception {
org.netbeans.junit.Log.controlFlow(Logger.global, null,
"THREAD: 1st MSG: cnt: 0" +
"THREAD: 2nd MSG: .*0" +
"THREAD: 1st MSG: ...: 1" +
"THREAD: 2nd MSG: cnt: 1" +
"THREAD: 1st MSG: cnt: 2" +
"THREAD: 2nd MSG: cnt: 2" +
"THREAD: 1st MSG: cnt: 3" +
"THREAD: 2nd MSG: cnt: 3" +
"THREAD: 1st MSG: cnt: 4" +
"THREAD: 2nd MSG: cnt: 4" +
"THREAD: 1st MSG: cnt: 5" +
"THREAD: 2nd MSG: cnt: 5" +
"THREAD: 1st MSG: cnt: 6" +
"THREAD: 2nd MSG: cnt: 6" +
"THREAD: 1st MSG: cnt: 7" +
"THREAD: 2nd MSG: cnt: 7" +
"THREAD: 1st MSG: cnt: 8" +
"THREAD: 2nd MSG: cnt: 8" +
"THREAD: 1st MSG: cnt: 9" +
"THREAD: 2nd MSG: cnt: 9",
500
);
Parallel.main(null);
fail("Okay, just print the logged output");
}
This might not look like a significant simplification. However, usually the key elements of the execution order are only affected by a single place in the code. If that’s the case, the size of the script to replay the execution flow can be simplified further. For example, imagine that we only want the 1st thread to print 5 first, then the 2nd thread to print 2, and then the 1st thread to continue with 6. The script would be as follows:
public void testFiveAndThenTwo() throws Exception {
org.netbeans.junit.Log.controlFlow(Logger.global, null,
"THREAD: 1st MSG: cnt: 5" +
"THREAD: 2nd MSG: cnt: 2" +
"THREAD: 1st MSG: cnt: 6",
5000
);
Parallel.main(null);
fail("Ok, just print the logged output");
}
As you can see, log messages inside an application can be a valuable tool for preventing unwanted shifts of the amoeba’s edge. Your messages can be enabled not only during the application’s execution, but also when the code is executed in a testing environment. Having the log for failed tests not only helps in analyzing a failure’s root cause, but if needed, the log can also serve as a script to control execution flow. It thus becomes useful in simulating the extreme situations that the application code can attain.
You can take this style of logging control even further with better log generation and better replay of log files. In terms of log capturing, it’s good to know that tools such as dtrace can be helpful when a context switch is taking place; that is, when execution transfers from one thread to another. The interesting implication of knowing about context switches and being able to replay them is that this can turn a parallel, nondeterministic application into a deterministic one, though only on single processor machines. Another possible improvement might include the use of AOP, or any other bytecode patching technique, to insert logging code throughout your application. In the process, you’ll receive information about the application even when it’s not fully ready to provide it. Everything is possible, and only time can tell which of these improvements will be of use to you. For now, it’s enough to say that NetBeans successfully uses logging, and controls flows based on logging, to fight the amoeba effect on its APIs.
Inconsistency due to parallel access to an API is unfortunate. However, this has an easy fix. It’s enough to add the synchronized keyword and your inconsistency will be gone. Of course, you risk deadlocks, but the bigger problem is that even this doesn’t guarantee consistency. You need to prepare to accept or prevent reentrant access.
ABSTRACT LOOKUP BROKEN DESPITE BEING SYNCHRONIZED
The Lookup class is at the heart of almost everything in NetBeans. It’s queried about everything, all the time, from various locations, and for almost anything. I knew that when I wrote the implementation and that is why I correctly guarded all the manipulations inside the lookup with synchronized. At the time, I expected that everything would be fine and consistent. To my surprise, I was wrong, because from time to time we received mysterious bug reports with almost impossible stack traces showing that the internal structures had become corrupted.
After a few weeks of wondering what was going on, a colleague realized that the problem related to reentrant calls to the modification methods. He inserted the debugging asserts there, just like in the following:
private boolean working;
public synchronized int sumBigger(Collection<T> args) {
assert !working : "Shall not be working yet in order to be consistent";
working = true;
try {
return doCriticalSection(args);
} finally {
working = false;
}
}
And, yes, instead of mysterious stack traces, we received several failed assertion errors. Good; at least we could now find out what was wrong. doCriticalSection could call into foreign code under certain situations. This code could then obtain the global instance of Lookup by calling Lookup.getDefault() and then call somemethod() on it again. As you can see, there was no mystery at all. It was simply a case of reentrant access.
The problem arises whenever you call into foreign code from inside a guarded section that would preferably run atomically. The foreign code can then call back to the same method. To complicate things, usually the callback occurs with different parameters and then almost all assumptions about atomicity are gone. There seem to be just two possible fixes. Either you need to use a non-reentrant lock to guard the critical section, or you make the section ready for reentrant access.
REENTRANT MISTAKES ARE COMMON
Mistakes with reentrant access are easily made. Even those who care about correctly synchronizing their code often forget to shield themselves from reentrant access.
For example, listeners and their listener support can often be a source of reentrant behavior. If you write a listener that, in reaction to a received event, calls a setter on a bean, does anyone know what the result will be and how many events have been received? This is not the first target to aim for, yet it’s often the result.
Even if you define a reasonable threading policy, which is what Swing does, it’s not true that you are shielded from the reentrancy because Swing is not reentrant. It’s not wise to interrupt its own painting while inserting another call into the Swing APIs. When you ignore this advice, a magical thing usually appears on the screen because the painting buffer becomes completely confused by the additional injected reentrant access.
This solution with a non-reentrant lock has only two problems:
private Lock lock = new NonReentrantLock();
public int sumBigger(Collection<T> args) {
lock.lock();
try {
return doCriticalSection(args);
} finally {
lock.unlock();
}
}
First of all, you cannot do it after using reentrant locks first, as this would be an incompatible change. Before applying that solution, the clients of your API were able to call into your methods in a reentrant way and have something happen (although the result was mostly unpredictable). After applying that solution, such a call would be forbidden: it throws an exception now, which is an incompatible change in the behavior compared to the previous version. Of course, correctness of the API is probably more important than 100 percent backward compatibility, so you can justify a slight incompatibility. However, there is a more serious problem. If you prevent reentrant calls, then you can get unsolvable results and sometimes paint yourself into complicated unsolvable situations. That’s because now the code’s validity depends on which callers are on the execution stack:
@Test
public void testCriticalSectionWith15() {
final CriticalSection<Integer> cs = create();
testFor15(cs);
}
// if this runnable is called from inside the critical section
// and the locks are non-reentrant then it throws an exception
public void run() {
testFor15(cs);
}
Calling the testFor15 method is fine by itself, but if called from code that is already holding the lock, the call might fail. If this is in the same class, this can easily be prevented. However, if the lock is accessible to public code, even indirectly, foreign code might completely destroy otherwise well-functioning code by enclosing its invocations within an additional critical section.
That is why it’s probably better to allow reentrant access and make the critical method ready for it, as well as for mutual thread access. The trick is the same as with any code that would rather run in a synchronized block, but cannot as it calls external foreign code. At the beginning, obtain an immutable copy of the internal state, work with it, produce results, and at the end somehow merge the computed result with the global state. In case of an integer the merge is easy:
private AtomicInteger cnt = new AtomicInteger();
public int sumBigger(Collection<T> args) {
T pilotCopy = this.pilot;
int own = doCriticalSection(args, pilotCopy);
// now merge with global state
cnt.addAndGet(own);
return own;
}
In the case of more complicated internal structures than numbers, you cannot do much else than to repeat the execution again and again until it’s not interrupted with a reeentrant or parallel call:
public int sumBigger(Collection<T> args) {
T pilotCopy = this.pilot;
for (;;) {
int previous = cnt.get();
int own = doCriticalSection(args, pilotCopy);
// if there was no parallel or reentrant change,
// apply and return. Otherwise try once more.
if (cnt.compareAndSet(previous, own + previous)) {
return own;
}
}
}
However, this code can be potentially never-ending, because it contains an unlimited cycle. That is why there needs to be some additional attribute in the data structures that guarantees that with each reentrant call the internal structures get into a “more stable” state. Then the code repeats the given operation until it “stabilizes,” meaning until there is a call to doCriticalSection(args, internalParam) that doesn’t call the method once again in a reentrant way. The internal structure can be anything that represents the state of the object, but it’s supposed to be immutable. If any operation needs to change the state of this structure, then it should create a new clone and work on it. With style like this and data structures that “stabilize” with each computation you can be sure that the code is absolutely ready for reentrant access.
Because Java has a garbage collector, memory management is different than in traditional languages. Unlike in C or C++, you need just a constructor. There doesn’t appear to be a need for a destructor. As a result, you can say goodbye to X Window functions such as XCreateWindow and XDestroyWindow and to C++ destructors. However, that doesn’t mean you shouldn’t pay attention to the memory management characteristics of an API. In spite of the common hope that the garbage collector removes the need to care about memory deallocation, this is true only in the simplest cases. For all the others you still need to care, especially when designing a shared library.
In contrast to languages with classical memory management where you need to design destructors or destroy functions, you need to pay as much attention as possible to runtime characteristics and the structure, mutual organization, and references between objects in memory. The API’s designer needs to ensure proper runtime behavior, usually without any additional cleanup or destructor methods.
Let’s start with the simplest possible cases. Classes that cannot be instantiated, such as java.lang.Math, appear not to need any cleanup. However, this is not absolutely true. There cannot be instances of the class, but still the class itself can be unloaded (garbage collected) from the virtual machine. That doesn’t happen often, though, and I haven’t come across many situations where an API would benefit from the unloading of one particular class.
NULLPOINTEREXCEPTION ON STATIC FIELD ACCESS
We faced a funny situation with class unloading in 1997. JDK 1.1 had just been released, and unlike the previous version, it knew how to unload classes when they were not needed. The central API of NetBeans at that time was a class called TopManager. It had a static field, a getter public static TopManager getDefault(), and an appropriate setter. During initialization, NetBeans injected the default implementation of this class via its setter. The other code then used the getter to gain access to all NetBeans functionality.
To our surprise, from time to time the getter returned null. “Impossible!” we said. We had definitely called the setter before and passed in a non-null value. Moreover, things sometimes worked and sometimes not. When we tried it in the debugger, everything worked. In normal execution, we received a NullPointerException from time to time. Why? It took us a few hours or days to find that the cause was the garbage collector. From time to time, the class was released from memory. Then, when it was needed later, it was loaded again. However, it was loaded without the field being initialized. That is why we received NullPointerExceptions.
So we knew what was going on, but it wasn’t easy to find a fix. We somehow needed to prevent unloading of the class. At the end it was enough to hold the instance of the TopManager from a different class. However, the behavior was unintuitive, and as we later found out, it was also buggy. A week or two later Sun released an update to the virtual machine that prevented unloading of classes with static fields if their classloader was still in memory. That has remained the behavior since then. If you want to unload a class, you need to garbage collect all other classes loaded by the same classloader and the classloader itself at the same time.
However, sometimes it’s necessary to garbage collect all a library’s classes, such as when a module in NetBeans is disabled or about to be deleted. As each class has an internal reference to its classloader, this usually means getting rid of the classloader. For the classloader to be able to disappear, there cannot be any classes and their instances either. As you can see, this is a simple scenario.
The second simplest case happens when there can be instances of a class that don’t have any special references outside themselves. As an example, let’s imagine java.awt.Dimension or java.awt.Rectangle. These classes contain only a few integer fields and no references to other objects. This is the case where garbage collection works the best. The user of the API somehow creates these instances, keeps a reference to them, works with them, and when they are no longer needed, simply forgets the reference. As soon as nobody references the object, it can be collected from memory. There is no need for destructors; they cannot be called prematurely. Because of that, you cannot accidentally access memory that has already been deallocated. Memory management is greatly simplified. This is precisely the case in which garbage collection pays off in a big way.
However, this is the best scenario, and when designing an API with more complicated data structures, you can face far more complicated situations. The first happens when the data structure still remains relatively simple but is backed by a limited resource, such as an OutputStream file descriptor or an AWT window handle. In such cases, it’s not possible to rely on the garbage collector to free the resource, as it might kick in too late or not at all if you have the reference to the object. In such situations, you need to add a kind of destructor. In the case of streams, there is the close() method, which closes the underlying file descriptor. AWT windows have the dispose method to release the handles behind the windows. Both these cases act like destructors. They don’t release the object from memory, but force it to clean up its internal data. The object can then either become nonfunctional after calling the method, as in the case of streams, or it can simply release its data temporarily, and reallocate it if it’s needed again. However, even in this case it’s good to cooperate with the garbage collector. If a stream or window is no longer used and it disappears from memory, it should also do some kind of cleanup. For that purpose, it’s necessary to be informed about the object vanishing from memory. Here you have two choices: either use finalize or use WeakReference with ReferenceQueue. The finalize method is a slightly worse choice. First, it’s visible in the API. Second, it’s logically unsound. How can a method be called on an object when it’s not supposed to exist any longer? What if it makes itself accessible again? Also, the finalizers are called in a dedicated thread, but only “sometime later.” It’s not guaranteed that you’ll really receive the information about the object being reclaimed. For all these reasons, the reference queue is a better choice. The essential information that needs to be cleaned up is kept in the reference. As soon as the object is garbage collected, the reference is put in the queue. You then poll the queue and do the cleanup.
These are simpler cases, because the API is encapsulated. Its users keep objects in memory and the API doesn’t reference any external objects. When the API references external objects, the memory characteristics can get much more complicated. Many APIs, and especially those that mimic the JavaBeans specification, allow a kind of inversion of references. They allow the client of the API to inject a reference to itself into some objects in memory. For example, when you add a listener to a bean, in practice you are making the bean object hold a reference to your own objects. As soon as something like this happens, the life cycle of such objects becomes part of the API. If those objects have a long life, such as singletons that never disappear from memory, all the listeners added to them will be kept around the whole time as well. This can introduce memory leaks. If changed, it can also change the behavior of the code (shift the amoeba shape of the system), so things that worked before might no longer function correctly.
LISTENERS SHOULD HAVE BEEN HELD BY WEAK REFERENCES
Whenever we talk about the design of JavaBeans, we end up discussing the listeners and often come to the conclusion that it would have been much better if the specification stated that listeners are supposed to be held via weak references. This would remove the injection of references problem and also set a good example up for others to follow. Chances are that then all listeners and other callback interfaces would be held with weak references too.
However, the JavaBeans specification is silent on memory management. That’s not quite surprising, as it was written for Java 1.1 and has since remained stable, whereas weak references were introduced in a subsequent version of Java. Rewriting the specification later would be likely incompatible or useless, as the change to weak references could only be suggested, but not enforced. In any event, no existing beans would use it.
The NetBeans project has faced these problems often. To address them, we created support for weak listeners:
public static <T extends EventListener> T create(
Class<T> type, T listener, Object source
) {
return org.openide.util.WeakListeners.create(
type, listener, source
);
}
This method allows anyone to wrap an existing listener and create a new one that has a weak reference to the original. This in effect creates behavior you would get were the JavaBeans specification to be rewritten to use weak references. This is a useful method in certain situations. However, it doesn’t solve all problems. You still need at least a bit of understanding of the basic life cycle of the objects and the behavior you want to get from their interaction with the garbage collector.
One of the least specified things in conventional project documentation is your application’s memory model. It’s not surprising, given the fact that there is no generally known methodology for designing an application’s memory model. However, it’s surprising, as you can hardly write an application that is supposed to run for days without ensuring that you manage your memory effectively.
Again, the classic model is to code the application, start the profiler, and search for possible memory leaks. When found, return to the code, fix it, and on and on and on, until the application is in releasable shape. Again, as described many times, this is not effective if you plan to release more than one version of the application. As time passes, all the improvements from the “profiler hunting” phase will regress, unless you make sure they are continuously tested.
The JUnit testing framework doesn’t offer much in this area, so we’ve had to write a few extensions for our NbTestCase both based on, or supported by, our memory inspection library called Insane (http://performance.netbeans.org/insane).
The first memory management problem with which you have to cope in modern object-oriented languages such as Java is memory leaks. The problem is not that an application would address an unknown area in memory—that is not possible due to the garbage collector. Rather, sometimes (also due to the garbage collector), objects that you would like to disappear still remain in memory as somebody from somewhere continues to reference them. If a certain operation always leaves garbage after its execution, after a few executions you might find that the free memory starts shrinking and the whole application gets progressively slower. The NbTestCase offers the assertGC method for this:
WeakReference<Object> ref = new WeakReference<Object>(listener);
listener = null;
NbTestCase.assertGC("This listener can disappear", ref);
If you believe that after some operation an object should no longer be needed in memory, you just create a WeakReference to it, clear your reference to the object, and ask assertGC to try to release the object from memory. assertGC tries hard to force garbage collection of the object. It does a few iterations of System.gc, allocates some memory, explicitly invokes finalizers, and if the WeakReference is cleared, successfully returns. If not, it invokes the Insane library and asks it to find a reference chain that keeps the object in memory. A failure might then look like the following:
Of course, this listener cannot disappear, because it is held from long living
JavaBean:
private static javax.swing.JPanel
org.apidesign.gc.WeakListenersTest.longLivingBean->
javax.swing.JPanel@779b3e-changeSupport->
java.beans.PropertyChangeSupport@1e91259-listeners->
sun.awt.EventListenerAggregate@a553e2-listenerList->
[Ljava.beans.PropertyChangeListener;@16bc75c-[0]->
org.apidesign.gc.WeakListenersTest$PropL@11bed71
From this you can read that there is a longLivingBean static field, which points to PropertyChangeSupport. Through some internal Java implementation, it holds on to the listener that you wanted to garbage collect from memory.
Another thing that might affect performance is the size of its data structures. If you know that a certain object will be simultaneously kept in memory in thousands of instances, you don’t want it to occupy 1,000 bytes or more. You want to minimize its size. Again, this might be observed in profiling, or this can be a decision thought out well in advance, but the usual problem remains: you need to ensure that from release to release the size constraint won’t regress. Our NbTestCase provides the assertSize check for that:
private static final class Data {
int data;
}
Data d = new Data();
NbTestCase.assertSize(
"The size of the data instance is higher than 16", 16, d
);
assertSize uses the Insane library to traverse the graph of all objects referenced from the root instance passed in as an argument and computes the amount of occupied memory. Then it compares the value with the expected one. If lower or equal, it passes. Otherwise it fails and prints the sizes of the individual elements to let you analyze the failure.
The size of a simple java.lang.Object instance that has no fields is 8 bytes. When adding one field with an integer or a reference to another object, the size increases to 16 bytes. When adding a second field, the size stays at 16 bytes. When the third field is added, its size increases to 24 bytes. From that, it follows that it makes sense to round up the number of fields in an object to two. In fact, we do that in particularly sensitive places. However, note that the computed sizes are “logical” ones. The actual amount of occupied memory depends on the implementation of the virtual machine and can be different. However, that should be fine. The test of “logical size” expresses the programmer’s intention, which is independent of the actual virtual machine architecture.
We’ve found both assertGC and assertSize to be valuable in stiffening the edge of our application’s amoeba. By writing tests using these asserts we can specify and verify the expected memory model behavior of our application. So, these tests became part of the functional specification of our APIs. Not only that, as automated tests, they are an active specification that verifies its validity every time we execute them.
________________
1. Andy Hunt and Dave Thomas, Pragmatic Unit Testing in Java with JUnit (Raleigh, NC and Dallas, TX: Pragmatic Bookshelf, 2003).
2. Per Brinch Hansen, “Java’s Insecure Parallelism” (1999), http://brinch-hansen.net/papers/1999b.pdf.