
In this chapter, we will discuss encryption—the process of obfuscating data in such a way that it is only readable by someone or something that possesses a key that can be used to reverse this obfuscation. A definition I found on http://en.wikipedia.org/wiki/Encryption sums it up nicely:
In cryptography, encryption is the process of transforming information (referred to as plaintext) using an algorithm (called cipher) to make it unreadable to anyone except those possessing special knowledge, usually referred to as a key.
This chapter will describe the types of encryption available in the Oracle Database. There are two basic types of broad encryption capabilities available – encryption for data in motion (data on the network) and encryption for data at rest (data stored in datafiles). This book will only focus on encryption of data at rest, the data in datafiles. We'll look at the techniques available to accomplish this and their necessary impact on our applications. At one extreme, we'll see that manual "do it yourself" encryption using built-in database packages has a large, measurable impact on our applications—during development as well as during runtime in production. On the other extreme, with transparent tablespace encryption, we'll see how automatic, transparent encryption can be implemented without a single change to the existing application and with minimal impact on runtime performance.
It should be noted that with the exception of the manual "do it yourself" encryption, all of the encryption techniques discussed in this chapter require the use of the Advanced Security Option from Oracle Corporation, an extra cost option to the Enterprise Edition of the database.
There are two types of encryption in Oracle with different implementations. The first, and oldest in terms of implementation, is the encryption of data in motion—data moving across the network. The second is for data at rest—data in Oracle datafiles. The encryption techniques employed by both are very different in nature, as they solve two very different problems. In this section, we'll discuss what each implementation is designed to protect against and how it achieves this.
Data in motion has specific encryption needs, different from the encryption needs of someone that wants to simply encrypt a static file on a file system. Encryption of data in motion involves encrypting a constantly changing stream of information as it flows out of the database and then decrypting it as it arrives at the client. The process must also provide some ancillary features such as
Non-repudiation of the data: The server and the client both know for a fact that any network packet of data they receive definitely came from that known client or server. There can be no injecting of network packets by some third party that would alter the conversation between the client and server (i.e., the process prevents man in the middle attacks)
Data fidelity protection: The server and client both have the ability to verify that each and every packet they receive from the other has not been tampered with in any manner.
Data replay protection: The network stream of data cannot be replayed at a later date. It is only accepted in real time from the client to the server or vice versa.
Without encryption of data in motion, with these properties, it would be rather easy to subvert a stream of data. Imagine a banking application performing debits and credits to accounts. If someone could inject packets into the conversation between the client and server, they could inject a well formed SQL*Net (Oracle's networking protocol) packet in the stream of data requesting that client's account transfer money to their account. This is where non-repudiation comes into play: the third party attempting to inject packets into the stream would be rejected.
Another scenario: the third party becomes a man in the middle and modifies a packet of data, changing the number "1" in a packet to a number "9" and causing the transfer of $900 instead of $100. Data fidelity protection assures us that this can't happen. Lastly, if the client successfully transferred $100 from their account to some other account, and the man in the middle just sent those packets over and over again. Well, they came from the client, so non-repudiation wouldn't necessarily detect them because they haven't been tampered with. And data fidelity wouldn't catch it. However, the third test—that the packets are sent at least once and at most once—would send up a red flag.
The encryption of data in motion is an important topic. If there is even a remote possibility of someone having access to the network between the client and the server (typically between the application server and the database these days), we must consider encryption of data. We must consider it for the same reason that any web site that engages in ecommerce employs Secure Sockets Layer (SSL) encryption using the HTTPS protocol. SSL offers protection for data in motion much the same way SQL*Net encryption does. This book is not going to cover this type of encryption, however, since I focus on how things affect our applications, and, truth be told, network encryption in Oracle has little to no impact on our applications. The performance overhead is nominal, and the application itself has no idea that encryption is taking place. It is so transparent that we generally don't have to consider it during the design and development of our applications.
The second type of encryption available is encryption for data at rest—the data in our datafiles. This type of encryption is employed exclusively to protect our database against theft. Suppose you had a database on a portable device, such as a laptop, and that laptop was stolen or lost. Further, suppose this laptop contained sensitive data, such as identifying information (social security numbers, credit card numbers, addresses) or sensitive information, such as patient diagnoses, employee reviews, and the like. If this missing laptop was found by someone other than the owner and accessed, all of this information would be available to the person in control of the laptop. This is not a hypothetical "might happen someday" scenario; this exact situation has occurred many times in real life already. Unless the information was protected in some way, encrypted in some fashion, it would be freely available to anyone that stole your database.
Or consider someone that breaks into your server, into the physical machine in your data center hosting the database. They could steal your database (your datafiles) without your knowledge. Upon restoring that database on their own machines, and upon assuming the SYSDBA identity (the all-powerful account), they could access any data in any table in any manner they wanted—if the data is unencrypted.
Protection of your data in the event of theft is the protection provided by encrypting data at rest. If someone steals your datafiles and they are encrypted, then the thief hasn't really succeeded in stealing anything at all. They have nothing more than a pile of seemingly random bits. Even SYSDBA access buys them nothing.
If you have any sensitive information, information that if it fell into the wrong hands would spell a disaster, you must give consideration to encrypting data at rest. If the data is not encrypted, is not protected; it is extremely easy to extract information from the stolen datafiles. For example, suppose you have a table in some tablespace:
ops$tkyte%ORA11GR2> create tablespace in_the_clear 2 datafile '/tmp/in_the_clear.dbf' size 1m 3 / Tablespace created. ops$tkyte%ORA11GR2> create table t 2 ( id varchar2(30) primary key, 3 ssn varchar2(11), 4 address varchar2(80), 5 credit_card varchar2(30) 6 ) 7 tablespace in_the_clear; Table created. ops$tkyte%ORA11GR2> insert into t (id, ssn, address, credit_card ) 2 values ( 'Look for me', '123-45-6789', 3 '123 Main Street', '1234-5678-9876-5432' ); 1 row created. ops$tkyte%ORA11GR2> commit; Commit complete.
At some point in time, the data that is currently in the buffer cache (this new row we inserted) would be placed on disk. We can force that to happen right now with a user invoked checkpoint:
ops$tkyte%ORA11GR2> alter system checkpoint; System altered.
Now, if someone were to gain access to that file, they would be able to get a lot of data from it without any Oracle software at all. For example, using the simple Unix utility strings, we can see:
ops$tkyte%ORA11GR2> !strings -a /tmp/in_the_clear.dbf | egrep '(Look for me|123)' Look for me 123-45-6789 123 Main Street 1234-5678-9876-5432
It's all right there in clear text. Even if we stored some of these values in the Oracle NUMBER or DATE types, we know we could still read them. The NUMBER and DATE formats are explained in detail in Chapter 12 "Datatypes." The data in an Oracle datafile is stored as is.
Further, even if we deleted the data
ops$tkyte%ORA11GR2> delete from t where id = 'Look for me'; 1 row deleted. ops$tkyte%ORA11GR2> commit; Commit complete. ops$tkyte%ORA11GR2> alter system checkpoint; System altered. ops$tkyte%ORA11GR2> ops$tkyte%ORA11GR2> !strings -a /tmp/in_the_clear.dbf | egrep '(Look for me|123)' Look for me 123-45-6789 123 Main Street 1234-5678-9876-5432
it would still be there. It would remain in the datafile unless and until it was overwritten—which may happen today, tomorrow, next year, or never. Even if thieves didn't access our datafiles but somehow got a hold of some online redo log files or archived redo log files, they would have access to a wealth of information. In the following example, I'll go after the current online redo log file because I know it will have traces of the data we were just operating on:
ops$tkyte%ORA11GR2> column member new_val redo
ops$tkyte%ORA11GR2> select a.member
2 from v$logfile a, v$log b
3 where a.group# = b.group#
4 and b.status = 'CURRENT'
5 and rownum = 1;
MEMBER
-------------------------------------------------------------------------------
/home/ora11gr2/app/ora11gr2/oradata/orcl/redo01.log
ops$tkyte%ORA11GR2>
ops$tkyte%ORA11GR2> !strings -a &REDO | egrep '(Look for me|123)'
metrics71234
10,2091123407
EXEC_10123,
EXEC_10123
EXEC_10123
]123
]123
123-45-6789u1122 Main Street1234-5678-9876-5432t
Look for me
123-45-6789
1122 Main Street1234-5678-9876-5432
...You can see all of the sensitive data in the redo as well. Going a step further, it would be in the UNDO tablespace as well, which would further contribute to the REDO stream itself. As you can see, the values are recorded in many places. If you cannot find what you are looking for in one file, just go to another one!
I've just shown what could happen if you have access to just a single Oracle datafile—and it really only shows the tip of the iceberg. There are third party utilities, even utilities available from Oracle support, that can be used to read the database blocks in an Oracle datafile—with nothing but that datafile—and dump out the contents of those blocks. These tools were designed as a last ditch recovery method (in the event your backups were not available for whatever reason, to save some of your data) but can also be used by anyone to dump any datafile for any purpose. When you consider redo, there are documented Oracle tools (log miner) that can be used to inspect their contents, if they are unprotected.
Think about what would happen if someone got access to many of your datafiles, specifically the ones for the SYSTEM tablespace (the data dictionary) and any of your tablespaces containing sensitive information. It would not take a DBA of any level of expertise very long to have full access to the data in these datafiles using their own SYSDBA account. All they would have to do is "restore" these files to a new system, fire up the Oracle software, create a control file for them (if they didn't have that), and open up the database (resetting the logs if necessary). They would, by definition, be in as SYSDBA right then, able to bypass all discretionary access controls you had in place (things like GRANTS are not needed for SYSDBA; they have access to everything).
To protect against the sort of theft I've just described, there are three approaches we can take: manual application encryption (what I call the "do it yourself" approach) using built-in packages, transparent column level encryption, and transparent tablespace encryption. We'll briefly describe each next and we will visit each in great detail in later sections.
Manual Application Encryption is pretty much self-explanatory. The application developer will manually encrypt and decrypt data in the application itself, possibly via triggers during modification and via custom functions during data retrieval or in stored procedures or in the client application. However it is done, it will be in the application code.
This approach will have the highest cost in terms both of development effort and performance penalty. The act of encrypting and decrypting the data is very easy. The application program interfaces (APIs) for it exist, are well documented, and are easy to understand. That part is not hard, but what is hard is securely managing the keys to this encrypted data. The keys are necessary to encrypt the data going into the database and to decrypt the data flowing out of the database. Without access to the keys, the data could not be encrypted nor decrypted; so it is obvious they must be available. How do you make them available to the application code? How do you do that securely?
There is no simple answer to those questions. If you encrypt data in a trigger on the way into a table, for example, the trigger must have access to the encryption keys. In order for the trigger to have access to the key, the session the trigger is running in must have provided the key, which means either the application or end user provides the key. Obviously the end user cannot provide the key (that would imply everyone has the key, so why bother!). So, the application must provide the key. The question "Where will this key be stored?" immediately arises. Maybe the application would store this key in a database table. Storing the key in a table would be a huge mistake: if you store the keys in a table in the database with the data they are used to encrypt, and someone then steals your database, they have stolen your keys as well. (They'll have SYSDBA, remember, so they'll have access to every table). When I point this out in discussions, many times people say "we'll encrypt the keys using a different key." My response: "And how is that key provided to the database?" It becomes a chicken and egg problem—you cannot securely store the keys in the database.
So that would leave storing the keys in the application. Maybe you'll try to hide the key in a PL/SQL package. That won't work for the same reason as putting the key into a table would not work, even if you wrap the PL/SQL code or otherwise try to obscure this magic key. An intruder that wants it would be able to get it. Not only that, but if the application was designed to transparently get the key and transparently encrypt/decrypt data, and someone steals your database, they can just mimic your application—and your own code (which they stole along with your database) will provide them the data nicely.
So, you'll be tempted to put the keys in the application that resides outside of the database. That'll work to a degree; it'll solve the problem of "what happens when someone steals my database" because they won't have the keys. But you really haven't solved the problem; you still have to have a method to release the keys to the application itself. As connections are added by your application server, they would need access to this key to encrypt and decrypt information. How do they get it? Do you store it in a file so it could be automatically retrieved? If so, does that mean you are storing the key in an unprotected file in clear text? (Yes, it does.) So, maybe you'll encrypt that file with the keys in it, which leads us back to the problem of how to get the key to decrypt the file with the other keys in it. So you end up writing a key server process that can be started by someone and a password (key) passed to it so it can decrypt the file and serve keys out to the applications as they request them, but then this server must implement non-repudiation (be sure of valid clients only), anti-data tampering, and the network encryption.
In addition to that, you have to make sure the backup and recovery of this key store is managed in conjunction with the database. In order to properly restore a database, you'll need the keys that were in place at the time the database was backed up. If you don't have them, your data will be unavailable. So now there is coordination between the application server backup and the database backup.
And, just to keep going on this thread, there is the problem of periodic re-keying of data. Many standards and legal regulations mandate the periodic changing of the keys to protect data. The thought is, the longer a key is used, the higher the probability the key has been compromised. So there must be some way to change the keys used to encrypt data over time. You'll have to not only write the processes that re-keys (decrypt your data with the old key and encrypt with the new key), but ensure you can maintain the history of keys in the event you need to restore a database at some point. To compound this problem, consider an environment where you have some data sharing going on. Suppose your transaction system must feed data into an Operational Data Store which, in turn, feeds a Data Warehouse. If you encrypt the data in one, you better encrypt it in the other, and so on. Key management has just gone up another level in complexity.
In other words, you would be reinventing the entire framework Oracle provides and calls Transparent Data Encryption. I am not a fan of reinventing the wheel, and this is a really hard wheel to reinvent in a secure fashion, so I'm not going to spend much time on this approach in the "Implementing Manual Application Encryption" section beyond introducing the packages available and demonstrating how to measure their performance impact.
Hopefully you now have some appreciation for the complexity behind key management. Before we get into the two transparent encryption techniques offered by the database, we'll take a look at how Oracle has approached this key management issue and the implementation chosen.
The key management approach chosen by Oracle centers around a wallet. The wallet is simply a file containing the encryption keys in an encrypted format. This wallet might hold only encryption keys for the database, or it might hold other bits of information for other Oracle components. It is recommended by Oracle that you use multiple wallets instead of just one for everything. In this book, we'll be using a wallet only for the user of the database encryption keys.
This wallet is stored out of the database, so if someone steals your database, they have not necessarily stolen your wallet. Even if they do steal your wallet, they still haven't stolen your keys, really; they've only stolen the encrypted keys, which will be of no use to them. The wallet concept uses a proven security technique for providing secure access: in order to release the keys to the database, to decrypt the keys for use, you must have access to something physical (the wallet) and something intangible (a password). In security terms, this is referred to as "something you have and something you know." Just like your debit card for your bank, there is something you have (the physical card) and something you know (your PIN). If someone steals the card, they cannot use it to get cash because they do not know your PIN. Likewise, if someone steals your wallet, they must also kidnap one of your DBAs to make it useful, because the DBAs have knowledge of something (the password) that is necessary to unlock the wallet.
Typically, when using a wallet, the DBA team will release the wallet to the database using an ALTER SYSTEM command with a password. This makes the wallet follow the "something you have and something you know" paradigm. Having just one or the other does not provide you any access at all, as we'll see.
Another way to use the wallet would be to use an auto login wallet. That is, the DBA team can configure the wallet such that it would be released to the database immediately, without DBA intervention, whenever the database is opened. This might sound like a bad idea at first; it sounds like the wallet will be released to the database without having the password. The fact is that the auto login feature is designed to work only on the physical machine on which the database and wallet reside when the auto login feature is setup. In other words, the attacker would need to steal your database, your wallet, and your server. If you are in an environment where that is not likely to happen (a physically secure data center), using an auto login wallet might be acceptable. However, if there is a chance of your physical equipment being stolen, as there would be if your physical equipment is a laptop computer, you should not enable this capability.
The third way to use the wallet is to utilize an external hardware security module (HSM). This option is available only with Oracle 11g Release 1 and above. It allows for the keys to be stored on an external piece of hardware outside of the database—outside of the database server, in fact—and provides an even more secure key storage mechanism than a wallet stored on the file system. In addition to providing a secure external key stored in a hardware device, you can offload the encryption/decryption processing to this dedicated piece of hardware. Normally, the encrypt/decrypt processing takes place on the database server hardware itself.
Note
Exadata storage, mentioned in Chapter 14 "Parallel Execution," is another method to offload encryption processing and its associated overhead. The individual storage cells in an Exadata storage array can perform the encrypt/decrypt processing, offloading that work from the database server itself.
We will not be utilizing an auto login wallet nor implementing the HSM in this book; just the wallet released by the DBA using a password will be demonstrated. The other approaches will not materially affect the discussions on how the encrypted data is stored and processed or what impact this will have on your applications' performance profile.
The Oracle wallet is very easy to set up. It just requires a modification to the database server's SQLNET.ORA configuration file and the issuing of an ALTER SYSTEM command to create the wallet.
This is a copy of the SQLNET.ORA file I had in place during the writing of this chapter:
# sqlnet.ora Network Configuration File: /home/ora11gr2/network/admin/sqlnet.ora # Generated by Oracle configuration tools. #NAMES.DIRECTORY_PATH= (TNSNAMES) NAMES.DIRECTORY_PATH= (TNSNAMES, EZCONNECT)
ENCRYPTION_WALLET_LOCATION=(SOURCE=(METHOD=FILE)(METHOD_DATA=(DIRECTORY=/home/ora11gr2/network/admin/)))ADR_BASE = /home/ora11gr2/app/ora11gr2
The bit in bold represents the necessary SQLNET.ORA setup for the Oracle wallet. We must specify where this wallet will reside. Right now, after this setup and restart of the Oracle database instance, the wallet does not yet exist:
[ora11gr2@dellpe admin]$ pwd /home/ora11gr2/network/admin [ora11gr2@dellpe admin]$ ls -l total 16 -rw-r--r-- 1 ora11gr2 ora11gr2 488 Jan 29 19:58 listener.ora drwxr-xr-x 2 ora11gr2 ora11gr2 4096 Sep 14 2009 samples -rw-r--r-- 1 ora11gr2 ora11gr2 400 May 29 12:37 sqlnet.ora -rw-r----- 1 ora11gr2 ora11gr2 921 Apr 26 08:30 tnsnames.ora
We have to create it, and we accomplish that with the ALTER SYSTEM command, which in its simplest form can look like:
ops$tkyte%ORA11GR2> ALTER SYSTEM SET ENCRYPTION KEY identified by foobar;
System altered.
ops$tkyte%ORA11GR2> !ls -l $ORACLE_HOME/network/admin
total 20
-rw-rw-r-- 1 ora11gr2 ora11gr2 1573 May 29 13:44 ewallet.p12
-rw-r--r-- 1 ora11gr2 ora11gr2 488 Jan 29 19:58 listener.ora
drwxr-xr-x 2 ora11gr2 ora11gr2 4096 Sep 14 2009 samples
-rw-r--r-- 1 ora11gr2 ora11gr2 400 May 29 12:37 sqlnet.ora
-rw-r----- 1 ora11gr2 ora11gr2 921 Apr 26 08:30 tnsnames.oraThe ALTER SYSTEM command created the wallet file (ewallet.p12) and set the encryption key for this wallet to "foobar" (you would use a stronger password, of course). Subsequent startups of the database would need to have the following command executed before accessing any encrypted data:
idle> startup
ORACLE instance started.
Total System Global Area 849530880 bytes
Fixed Size 1339824 bytes
Variable Size 528485968 bytes
Database Buffers 314572800 bytes
Redo Buffers 5132288 bytes
Database mounted.
Database opened.
idle> ALTER SYSTEM SET ENCRYPTION WALLET OPEN IDENTIFIED BY foobar;
System altered.The ALTER SYSTEM command releases the wallet to the database instance; the instance now has full access to all of the keys contained within it. If you ever want to cut off access to the encrypted data, you can manually close the wallet:
idle> ALTER SYSTEM SET ENCRYPTION WALLET close IDENTIFIED BY foobar; System altered.
Now any data that is encrypted will be inaccessible, both from a read and a write perspective. Further, you will not be able to create any new encrypted information either.
The setup for an auto login wallet is not significantly different, nor is the setup for using an HSM. See the Oracle Database Advanced Security Administrator's Guide for details.
That's it! That is all you need to do to setup a wallet for use with Transparent Data Encryption (TDE). For the rest of this chapter, we'll assume that wallet is in place and the WALLET OPEN command was issued.
Column level encryption as part of TDE was introduced in Oracle Database 10g Release 2. It permits the creation of a table with a column that would be transparently encrypted on the database block whenever someone modified the data on the block and transparently decrypted whenever someone would access the data on the block. Additionally, all REDO, UNDO, or TEMP data associated with this column would be encrypted as well.
From a development perspective, all you need to do is use the new keyword ENCRYPT at the column level during a CREATE TABLE or ALTER TABLE statement:
ops$tkyte%ORA11GR2> create tablespace tde_test datafile size 1m
2 /
Tablespace created.
ops$tkyte%ORA11GR2> create table t
2 ( c1 varchar2(30),
3 c2 varchar2(30) ENCRYPT
4 )
5 tablespace tde_test
6 /
Table created.We created an empty tablespace, so when we look at the datafile associated with it, we know it only contains data for our table (table T in that tablespace). The column C1 is a "normal" column, just a varchar2(30). Column C2, however, is different; it has the keyword ENCRYPT as part of its definition. Any data stored in that column will be transparently encrypted (as well as all REDO, UNDO, and so on generated for that column). There are other options that may be used with the ENCRYPT keyword to specify things such as the encryption algorithm to use, for example, but it can be used standalone as we have it here.
We use Table T as we would any other table; that is the goal of the T in TDE, Transparent. So, since we own this table, we can freely INSERT and SELECT from it:
ops$tkyte%ORA11GR2> insert into t values 2 ( 'this_is_NOT_encrypted', 3 'this_is_encrypted' ); 1 row created.
ops$tkyte%ORA11GR2> commit; Commit complete. ops$tkyte%ORA11GR2> select * from t; C1 C2 ------------------------------ ------------------------------ this_is_NOT_encrypted this_is_encrypted
So far, it is not clear that we have achieved anything here; it is not clear what the keyword ENCRYPT has done for us yet.
Let's close the wallet to simulate the environment that would be in place if someone stole our database (they would not be able to open the wallet). So, we'll close the wallet and try to modify/retrieve encrypted data:
ops$tkyte%ORA11GR2> alter system set encryption wallet close identified by foobar;
System altered.
ops$tkyte%ORA11GR2> insert into t values
2 ( 'this_is_NOT_encrypted',
3 'this_is_encrypted' );
insert into t values
*
ERROR at line 1:
ORA-28365: wallet is not open
ops$tkyte%ORA11GR2> insert into t values
2 ( 'this_is_NOT_encrypted',
3 null );
1 row created.
ops$tkyte%ORA11GR2> select c1 from t;
C1
------------------------------
this_is_NOT_encrypted
this_is_NOT_encrypted
ops$tkyte%ORA11GR2> select c2 from t;
select c2 from t
*
ERROR at line 1:
ORA-28365: wallet is not openAs you can see, if we attempt to insert a value into the encrypted column, we receive the ORA-28365 error. If we attempt to retrieve the encrypted data, we receive the same error. I would like to point out that this error is not saying "No, you cannot have access to this data." Rather (and this is important), the error is saying "Sorry, but I cannot provide anyone access to this data. I don't have the keys necessary to access it." This is an important distinction because it is that fact that protects our data. This is not access control in place, restricting our access to the data via software; this is a physical limitation because the database itself cannot process the data. It just has the raw encrypted data and can't produce an unencrypted version of it.
Opening the wallet again will be the only way to provide access to that data:
ops$tkyte%ORA11GR2> alter system set encryption wallet open identified by foobar; System altered. ops$tkyte%ORA11GR2> select * from t; C1 C2 ------------------------------ ------------------------------ this_is_NOT_encrypted this_is_encrypted this_is_NOT_encrypted
The second thing to look at would be the contents of the datafile itself, the data at rest on disk. Previously, we saw how easy it was to view data in an Oracle datafile—just using the strings utility. If we attempt that on this datafile, this is what we might expect to see:
ops$tkyte%ORA11GR2> alter system checkpoint;
System altered.
ops$tkyte%ORA11GR2> column file_name new_val f
ops$tkyte%ORA11GR2> select file_name
2 from dba_data_files
3 where tablespace_name = 'TDE_TEST';
FILE_NAME
------------------------------
/home/ora11gr2/app/ora11gr2/or
adata/ora11utf/ORA11UTF/datafi
le/o1_mf_tde_test_602pjwy8_.db
f
ops$tkyte%ORA11GR2> !strings -a &F
}|{z
}ORA11UTFg?
TDE_TEST
this_is_NOT_encrypted,
this_is_NOT_encryptedDl
ops$tkyte%ORA11GR2>While this is not definitive proof that the data on disk is encrypted—you could dump database blocks or use a binary file editor to prove it further if you like—it is certainly an indication that the data is not stored in the clear on disk anymore. The encrypted data isn't stored in the clear on disk, that is; the non-encrypted data clearly is stored in the clear, easily viewable with or without the Oracle software.
What you've just seen is an introduction to column level encryption. In the section "Implementing Column Level Encryption," we'll be exploring details such as the storage overhead associated with column level encryption, indexing restrictions and limitations, restrictions with respect to referential integrity constraints, and performance implications.
Transparent tablespace encryption was introduced in Oracle Database 11g Release 1. Whereas column level encryption encrypted individual columns, tablespace encryption, as its name implies, encrypts the contents of an entire tablespace. Every database block stored in that tablespace will be encrypted, every byte of data on every block will be encrypted. Therefore, if you create a table in an encrypted tablespace, every single column in that table will be encrypted. In fact, every segment you create in that tablespace will be stored on disk in an encrypted format—INDEX, LOBSEGMENT, TABLE PARTITIONS-whatever is stored in that tablespace will be stored encrypted on disk.
Tablespace encryption is easy to implement once the Oracle wallet is in place. All it requires is the use of the ENCRYPTION clause (with or without any of the options available for it) on the CREATE TABLESPACE command. For example, we'll create two tablespaces, one without encryption named CLEAR and one with encryption enabled named ENCRYPTED:
ops$tkyte%ORA11GR2> create tablespace clear
2 datafile '/tmp/clear.dbf' size 1m;
Tablespace created.
ops$tkyte%ORA11GR2> create tablespace encrypted
2 datafile '/tmp/encrypted.dbf' size 1m
3 ENCRYPTION default storage ( ENCRYPT );
Tablespace created.Now, if we create a table in the tablespace named CLEAR and index it:
ops$tkyte%ORA11GR2> create table t 2 tablespace clear 3 as 4 select * 5 from all_users 6 / Table created. ops$tkyte%ORA11GR2> create index t_idx 2 on t(lower(username)) 3 tablespace clear; Index created.
We can definitely see that data stored on disk in a clearly readable format:
ops$tkyte%ORA11GR2> !strings /tmp/clear.dbf | grep -i ops.tkyte
OPS$TKYTE
ops$tkyte
ops$tkyte%ORA11GR2>You can definitely see the data from the table, OPS$TKYTE, in uppercase and the lower case version of it that was stored in the index. If this table was deemed to contain sensitive data and you wanted to protect it and all if its contents, you would have to move this data to a tablespace utilizing encryption. You could, if you desired, encrypt just the columns you wanted encrypted using the ALTER TABLE command to modify the columns, but that might introduce some restrictions having to do with column level encryption. Specifically, as we'll see in the section "Implementing Column Level Encryption," the use of a function based index would be prohibited. So for example, if you tried to use column level encryption on the USERNAME column, you would discover:
ops$tkyte%ORA11GR2> alter table t
2 modify username encrypt;
modify username encrypt
*
ERROR at line 2:
ORA-28348: index defined on the specified column cannot be encryptedIt just would not be possible. So, we want to encrypt the data in this table and in all indexes on this table—even indexes such as function based indexes. (Don't forget that when encrypting data, you had better encrypt it in all places it might be found, including indexes!) Moving the data to an encrypted tablespace will accomplish that for us:
ops$tkyte%ORA11GR2> alter table t move 2 tablespace encrypted; Table altered. ops$tkyte%ORA11GR2> alter index t_idx rebuild 2 tablespace encrypted; Index altered. ops$tkyte%ORA11GR2> alter system checkpoint; System altered. ops$tkyte%ORA11GR2> !strings /tmp/encrypted.dbf | grep -i ops.tkyte ops$tkyte%ORA11GR2>
As you can see, the strings command on that datafile no longer turns up any data. In fact, if you were to dump every string from that file, you would observe something like this:
ops$tkyte%ORA11GR2> !strings /tmp/encrypted.dbf | head
}|{z
}ORA11GR2
ENCRYPTED
.vJ6
'6d'
g#BA
)are
7nAbf
Y;Z<
1QM+G
ops$tkyte%ORA11GR2>The only two recognizable strings in that output are ORA11GR2, the name of our database, and ENCRYPTED, the name of our tablespace. They come from the datafile header which is not encrypted, but everything else in the datafile (all of the database blocks) are encrypted. Our data is nowhere to be found. Rather, our data is nowhere to be found in that datafile. What about the other datafile, where the data used to be? You'll probably find that it is still there
ops$tkyte%ORA11GR2> !strings /tmp/clear.dbf | grep -i ops.tkyte
OPS$TKYTE
ops$tkyte
ops$tkyte%ORA11GR2>as I did. Why? Because when you "move" data, it is not like moving a physical object such as a desk or a chair. When you move data, you actually copy it and then stop pointing to the old copy. So both copies exist still in the files after the copy. If I were to steal your /tmp/clear.dbf file right now, I could probably recreate the entire table by dumping database blocks out of that file. The move process does not erase the data in the old location. Further, the move process definitely does not wipe the old information out of the UNDO tablespace (any undo generated for that table in the CLEAR tablespace will be around), nor will it remove it from the REDO stream, and definitely not from the archived logs you have, nor the backups. It will not even remove it from TEMP where it might be recorded due to a large sort.
I bring up these facts—that the move leaves behind many copies of the data from before the move—because many people think that if they encrypt the data, they are done and it is secured. That is just the first step when employing encryption; you have to think about all of the legacy places this data might appear and do something to secure each of those. For example, if you move one table out of a tablespace into an encrypted tablespace in order to secure it, you may well consider moving all segments out of that tablespace into other tablespaces so you can ultimately drop that tablespace and wipe (erase) the datafiles. Then you have to think about what you want to do with the data that exists in old backups. You might have to take some action with those copies as well (or maybe not; only you can decide what level you need to go to protect your data).
In a later section "Implementing Tablespace Encryption," we'll look at the details of how it is implemented in the Oracle database. We'll look at what restrictions tablespace encryption might impose on your application and how it might affect performance. Do not expect any hard and fast "tablespace encryption will affect your performance by X%" numbers. The impact of tablespace encryption on your processing requirements will vary based on how your application uses the database. Having information about how Oracle implements tablespace encryption will allow you to judge to what degree it will impact your performance.
Before we get into the details of how Oracle implements encryption at rest and how you would go about using it, I want to make one important point about encryption. This point goes to why you are encrypting data in the first place. There is exactly one reason to employ database encryption (encryption of data at rest) and that reason is to protect the data in the event of theft or loss. That's it—to protect the data in the event the database itself is stolen.
I mention this—stress it, in fact—because many people think they can or should use encryption for access control. I get this question frequently on http://asktom.oracle.com/. It takes the form of comments/questions such as:
We are planning on upgrading to 10.2.0 and implementing Transparent Data Encryption to encrypt our credit card numbers in the database. But it looks like all TDE does is just to encrypt the data in the database at the column level but does not provide a way to limit access to the data at the column level...
One thing regarding TDE in 10gr2, I know it encrypts data and it is transparent, but does it do access control. Will it be able to restrict decryption to specific users...
But with TDE the data is still in clear text when you select it from the database...
It is a common theme—confusing encryption (used to protect data at rest from theft or loss) and access controls (limiting access to data in real time according to some rules).
Access control rules exist to provide the following functionality:
GRANTandREVOKE: This allows object level access on a user by user or system wide basis.Row Level Security: This prevents or allows access to specific rows in a given object either by user, by application, or by any developer dreamed of scheme. For example, in a medical records database, the developer could use row level security to allow access to a given row to a specific Doctor if the Doctor accesses that row from a certain hospital during a period of time that Doctor is scheduled to be working there. Otherwise, that Doctor will not have access.
Column Level Security: This takes place via column masking to prevent or allow access to specific columns row by row (the user can see the row, but they are not allowed to see a certain column on certain rows). This can be implemented user by user, application by application, or by any sort of scheme the developer wants to implement, just like row level security.
Encryption is used to protect the data when access controls are subverted, as they would be if someone has physical access to your database.
If encryption worked like access controls, it could not protect the data at rest from theft since SYSDBA, for example, is never subject to access controls. SYSDBA can bypass everything. We need encryption as a stopgap on top of access controls in the event that access controls are subverted. In that case, we just want to prevent all access to the data, period.
In this and the next two major sections, we'll look at the three approaches a developer/DBA can use to encrypt data in the database. We've had an overview of them already; now it is time to look at each in more depth. First up is Manual Application Encryption, which is achieved programmatically using one of two built-in packages:
DBMS_OBFUSCATION_TOOLKIT: A package supplied with the database since Oracle 8i, it employs the Data Encryption Standard (DES) and Triple DES (3DES) encryption algorithms only. It is also capable of generating MD5 checksums of data. It can only work withRAWandVARCHARdatatypes. It should not be used for two reasons: it is deprecated as of Oracle 10g and above (replaced by the next package in this list) and the name is really hard to type and say out loud.DBMS_CRYPTO: In addition to being much easier to type and say, this is the currently supported encryption API. It supports a broader range of encryption algorithms including DES, 3DES, Rivest Cipher 4 (RC4), and Advanced Encryption Standard (AES). It is also capable of generating a variety of hashes and message authentication codes (MAC) such as MD5, MD4, SHA-1. It is capable of working withRAW, CLOBandBLOBdatatypes.
I will not be discussing the DBMS_OBFUSCATION_TOOLKIT package directly, but everything I say about the DBMS_CRYPTO package will apply to it as well.
I firmly believe that if you have the documented need for encrypting data at rest, your best approach is to not use the manual approach. If you do manual application encryption, you are responsible for key management. As we discussed earlier in the section on "The Oracle Wallet," we know how code intensive that would be. Implementing a secure key store is a non-trivial exercise; in order to be somewhat sure that it is impervious to attack, you would need to expose it to a level of testing that is typically not feasible in a single organization. On the other hand, if you use off-the-shelf implementations such as the Oracle wallet, you know that it is extensively tested and probed on a daily basis.
In addition to the key management issue (which is a large one; to me, it's more than enough to not want to consider it), there is the fact that you have to code the encrypt/decrypt routines and make sure they are hooked into the application at the correct places. Whenever data comes into the database, you are responsible for encrypting the data, and whenever it leaves, you are responsible for decrypting it. This comes at the expense of yet more code to be developed as well as a definite performance impact, which we'll measure shortly.
A third reason to give serious thought before employing manual application encryption is that the application has to be involved in the process; in fact, every application that touches this data will have to be involved. This is because the column that will be encrypted must (I stress the word must here) use the RAW datatype as its underlying datatype. If you are to encrypt a LAST_NAME column that was originally defined as a VARCHAR2(70), you will be redefining that column to be a RAW(80). You must use a RAW datatype because the result of encrypting data is a binary set of bytes; they are not characters. You cannot store them in a character datatype such as VARCHAR2. I'll refer you to Chapter 12 "Datatypes" and the discussion on NLS character set conversion for the reason why this is so. The VARCHAR2 type is subject to character set conversion—and the bytes that one client sees can and will be different from the bytes another client sees in a VARCHAR2 string. When dealing with true character strings, it is definitely a bad thing; it's called "corrupting the data." Character set conversion would tend to change the encrypted data, making it so you cannot decrypt it anymore (that is, you just lost it forever). I've seen that happen more than once in real life. The developers used a VARCHAR2 to store encrypted data and the fact that the conversion had taken place was not detected for some time, effectively destroying that bit of data. If it had been detected early, near the point of the corruption being introduced, we could have resurrected the data from backups (before the implicit conversion corrupted it) but it would have been a non-trivial task.
Also, note that I said that a VARCHAR2(70) would require a RAW(80). This is because encrypted data is stored in multiples of 16 bytes. It takes five 16 byte pieces of raw data to store 70 single byte characters (or 71, 72 and so on). So unless your existing data attribute byte length is divisible by 16, you'll be computing a new field length. Again, a mistake I've frequently seen is for a developer to try to store the encrypted data in the existing VARCHAR2(70) field—it won't work because of the implicit character set conversion that will corrupt the data some day, and it won't work because it simply won't fit in that field. Sure, some of the data will—any of the data that was 64 bytes or less before encrypting would fit, but a value that was 65 bytes or more would need 80 bytes after encrypting. This gets even worse when you start considering multibyte data!
The last reason to avoid the manual approach is one of performance. There is a measurable overhead in application-implemented encryption. Any layer of code we as developers add between the client and the database will add some level of overhead—and encryption can be a very expensive one to implement. So, let's create a package to easily encrypt/decrypt with and compare the performance of a VARCHAR2(30) string stored non-encrypted and again encrypted. We'll just compare single row INSERT performance, bulk INSERT performance, and data retrieval (SELECT) performance. To begin with, we'll need a package to perform the encryption operations for us, a sample package specification that would just contain two entry points, one to encrypt and the other to decrypt:
ops$tkyte%ORA11GR2> create or replace package encryption_wrapper 2 as 3 function encrypt( p_string in varchar2, 4 p_key in varchar2 ) 5 return raw; 6 7 function decrypt( p_raw in raw, 8 p_key in varchar2 ) 9 return varchar2;
10 end; 11 / Package created.
For our package body, an implementation might start off like this:
ops$tkyte%ORA11GR2> create or replace package body encryption_wrapper 2 as 3 g_encrypt_typ constant PLS_INTEGER default 4 DBMS_CRYPTO.ENCRYPT_AES256 5 + DBMS_CRYPTO.CHAIN_CBC 6 + DBMS_CRYPTO.PAD_PKCS5; 7 8 function padkey( p_key in varchar2 ) return raw 9 is 10 begin 11 return utl_raw.cast_to_raw(rpad(p_key,32)); 12 end;
Note
You may have to have EXECUTE on DBMS_CRYPTO granted to you before using it.
The global variable G_ENCRYPT_TYP specifies the type of encryption we want; this would be implementation dependent (that is, something you would figure out). Here, I'm going with a standard AES with a 256-bit (32 byte) encryption key. I've added a convenience function PADKEY to convert a character string key into a RAW and ensure it is 32 bytes long.
Next is our implementation of the ENCRYPT function. It will begin by converting our string into a RAW type using a safe character set. Then it will invoke DBMS_CRYPTO to actually encrypt the string (which is now a RAW) and return the value:
14 function encrypt( p_string in varchar2, 15 p_key in varchar2 ) 16 return raw 17 is 18 begin 19 return DBMS_CRYPTO.ENCRYPT 20 ( src => UTL_I18N.STRING_TO_RAW (p_string, 'AL32UTF8'); 21 typ => g_encrypt_typ, 22 key => padkey( p_key ) ); 23 end;
Lastly, we implement the DECRYPT routine. This simply decrypts our RAW encrypted data using the same key and then returns the VARCHAR2 representation of that output:
24 25 function decrypt( p_raw in raw, 26 p_key in varchar2 ) 27 return varchar2 28 is 29 begin
30 return utl_i18n.raw_to_char( 31 dbms_crypto.decrypt 32 ( src => p_raw, 33 typ => g_encrypt_typ, 34 key => padkey(p_key) ), 35 'AL32UTF8' ); 36 end; 37 38 end; 39 / Package body created.
Now we'll create a table to test with, a column LAST_NAME to hold the data when it is not encrypted, and a column ENCRYPTED_NAME – implemented as a RAW with 2*16 bytes of storage, therefore capable of holding at least 30 bytes of character data. Also, we generate a set of data we can use to test with into a simple table. This is so when we time things later, we'll be timing just the operation we are performing, not the query against ALL_OBJECTS:
ops$tkyte%ORA11GR2> create table stage 2 as 3 select object_name from all_objects; Table created. ops$tkyte%ORA11GR2> create table t 2 ( last_name varchar2(30), 3 encrypted_name raw(32) 4 ) 5 / Table created.
And now we can start inserting. First, we'll do a row-by-row insert into this table, once with non-encrypted data and again with encrypted data. The non-encrypted insert would look like this:
ops$tkyte%ORA11GR2> declare
2 l_start number := dbms_utility.get_cpu_time;
3 begin
4 for x in (select object_name from stage)
5 loop
6 insert into t (last_name) values ( x.object_name );
7 end loop;
8 dbms_output.put_line( (dbms_utility.get_cpu_time-l_start) || ' hsecs' );
9 end;
10 /
431 hsecs
PL/SQL procedure successfully completed.As you can see, our code consumed 4.31 CPU seconds of computer time to generate and insert the data. If we perform the same operation using the encryption package
ops$tkyte%ORA11GR2> truncate table t; Table truncated. ops$tkyte%ORA11GR2> declare
2 l_start number := dbms_utility.get_cpu_time;
3 begin
4 for x in (select object_name from stage)
5 loop
6 insert into t (encrypted_name)
7 values ( encryption_wrapper.encrypt
8 (x.object_name,
9 'Secret Key Secret Key Secret Key'));
10 end loop;
11 dbms_output.put_line( (dbms_utility.get_cpu_time-l_start) || ' hsecs' );
12 end;
13 /
2502 hsecs
PL/SQL procedure successfully completed.it takes 25.02 CPU seconds to generate and insert the data. Thus, it takes almost six times more CPU to perform the encryption as opposed to leaving the data unencrypted. Even if we bulk up the operation, using an INSERT AS SELECT statement, we'll see a large disparity:
ops$tkyte%ORA11GR2> truncate table t; Table truncated. ops$tkyte%ORA11GR2> declare 2 l_start number := dbms_utility.get_cpu_time; 3 begin 4 insert into t (last_name) select object_name from stage; 5 dbms_output.put_line( (dbms_utility.get_cpu_time-l_start) || ' hsecs' ); 6 end; 7 /8 hsecsPL/SQL procedure successfully completed. ops$tkyte%ORA11GR2> truncate table t; Table truncated. ops$tkyte%ORA11GR2> declare 2 l_start number := dbms_utility.get_cpu_time; 3 begin 4 insert into t (encrypted_name) 5 select encryption_wrapper.encrypt 6 (object_name, 7 'Secret Key Secret Key Secret Key') 8 from stage; 9 dbms_output.put_line( (dbms_utility.get_cpu_time-l_start) || ' hsecs' ); 10 end; 11 /374 hsecsPL/SQL procedure successfully completed.
Yes, 374 seconds versus 8 seconds is a more striking disparity, an almost 47 times increase in CPU utilization because of encryption when we performed the more efficient bulk operation. Clearly, this increased demand on CPU will have an impact on our modifications to the column. INSERTS, UPDATES, and MERGES will surely be affected, (but probably not DELETEs).
What about data retrieval? To test the effects on data retrieval, we'll populate both columns at the same time
ops$tkyte%ORA11GR2> truncate table t; Table truncated. ops$tkyte%ORA11GR2> insert into t (last_name, encrypted_name) 2 select object_name, 3 encryption_wrapper.encrypt 4 (object_name, 5 'Secret Key Secret Key Secret Key') 6 from stage; 64588 rows created. ops$tkyte%ORA11GR2> commit; Commit complete.
and then retrieve them
ops$tkyte%ORA11GR2> declare 2 l_start number := dbms_utility.get_cpu_time; 3 begin 4 for x in (select last_name from t) 5 loop 6 null; 7 end loop; 8 dbms_output.put_line( (dbms_utility.get_cpu_time-l_start) || ' hsecs' ); 9 end; 10 /7 hsecsPL/SQL procedure successfully completed. ops$tkyte%ORA11GR2> declare 2 l_start number := dbms_utility.get_cpu_time; 3 begin 4 for x in ( select encryption_wrapper.decrypt 5 (encrypted_name, 6 'Secret Key Secret Key Secret Key') 7 from t ) 8 loop 9 null; 10 end loop; 11 dbms_output.put_line( (dbms_utility.get_cpu_time-l_start) || ' hsecs' ); 12 end; 13 /378 hsecsPL/SQL procedure successfully completed.
As you can see, the decryption overhead added a sizable amount of increased CPU utilization, around 50 times as much CPU was needed in this case (378 seconds versus 7 seconds).
So, when should you consider the manual approach of application encryption? If you ask me, the answer is pretty much "almost never." The only time it would be necessary is if you are using Oracle's Standard Edition (SE) or lower, which does not support the Advanced Security Option (ASO). Often, people will utilize SE as a cost savings approach, but if you find that you have to implement the functional equivalent of ASO yourself (doing the key management, implementing all of the code, and performing the necessary application modifications because this approach is definitely not transparent to the application), you might find the cost of Enterprise Edition justified. In-house-developed software is not "free" after all.
In this section, we'll explore the implementation of column level encryption introduced in Oracle Database 10g Release 2. First, we'll review how to use column level encryption and then look at the data storage implications due to Oracle's implementation, followed by a look at measuring the performance impact. (You'll find it to be a bit more performant than the prior manual approach!) Lastly, we'll look at the limitations the implementation of column level encryption imposes, of which there are a few.
In order to use column encryption, you must first enable the Oracle wallet as described in the section "The Oracle Wallet." Once you have done this, implementing column level encryption is as simple as specifying the ENCRYPT key word in the CREATE or ALTER TABLE statement, for example:
create table t ( x varchar2(30) ENCRYPT );
This syntax can be used to transparently encrypt any of the basic datatypes such as NUMBER, TIMESTAMP, VARCHAR2, NCHAR, and so on. If you want to compress a large object (CLOB or BLOB), you must implement your CLOB/BLOB as a SECUREFILE (an option not covered in this book) or store the BLOB/CLOB in an encrypted tablespace, described in the "Implementing Tablespace Encryption" section.
The ENCRYPT keyword may be followed by one of three options:
USING 'algorithm'to choose whether to use AES or DES encryption for the column and how many bits the key will consume.IDENTIFIED BY passwordto specify a particular key to be used to encrypt the data. You might use this when unloading the data via an external table. In that fashion, you can send the external table data to another location and inform them of the key you used. They can use that key to read the information. In short, you would use this in a data sharing environment to facilitate the movement of sensitive data that must be encrypted.SALTorNO SALT: Normally, the database will add some random bytes of data to your data prior to encrypting it. This has the effect of making the encryption stronger as no two rows will encrypt a column to the same value when they contain the same data. This prevents a probe-style attack whereby an attacker could look for certain data values. By using a SALT, you ensure that a given value would be uniquely encrypted each time it was placed in the database. You would useNO SALTwhen you wanted to index the encrypted column. Why this is and other restrictions regarding indexing will be covered in the "Limitations of Column Encryption" section.
Note
For a complete description of the syntax available for the encryption clause, please refer to the CREATE TABLE statement in the Oracle Database SQL Language Reference 11g Release 2 manual.
That's pretty much it. Once you use the ENCRYPT keyword, you have what I call "mostly, pretty much, almost Transparent Data Encryption." Column level encryption, when used with respect of the limitations it imposes, is 100 percent transparent. But, if the column you are encrypting is to be
In any index
Part of any foreign key
you will find this encryption method to perhaps not be 100 percent transparent. We'll discuss why in the section "Limitations of Column Encryption." If a column is not indexed and is not part of any foreign key, then column level encryption is 100 percent transparent.
We'll look at two issues surrounding column encryption and storage. The first one is the physical storage requirements of column level encryption. The second one is how the data is stored in the SGA. Column level encryption stores the data in the SGA in an encrypted fashion, which will mandate that we encrypt/decrypt it every time we access it. That encryption and decryption will have an impact on the performance of queries that frequently access the column and also necessarily impact indexes on the column. The indexes will be indexing encrypted data, not the original data. This fact will have a profound effect on the usefulness of indexes on encrypted columns, as we'll see in the "Limitations of Column Encryption" section.
Without a doubt, column encryption will increase your storage needs. This is due to two facts. The first fact is that data is stored in fixed width fields that are always a multiple of 16 bytes. This should sound familiar from the manual application encryption section "Reasons to Avoid the Manual Approach" where I describe how encrypted data is stored in 16 byte pieces. When you encrypt the string 'Hello' (5 characters), it will be converted into a binary string of 16 bytes—a fixed width binary string. So, instead of taking 6 bytes in the database (1 byte for the length attribute, 5 bytes for the characters), that string 'Hello' in an encrypted column will take 17 bytes (1 byte for the length, 16 bytes for the data). If you have 1,000,000 records in a table with a VARCHAR2(30) field whose average length is 5 characters, you will go from needing 6,000,000 bytes of storage to needing 17,000,000 bytes of storage.
The second reason stems from the SALT attribute we introduced above. Prior to encrypting the data and placing it on the database block, Oracle by default will add a SALT to the data—some random set of bytes in a predictable place (i.e. it might always put 10 random bytes of data on the front of the string)—and then encrypt it. In that fashion, if you insert the string 'Hello' one million times into the table, it will encrypt to one million different raw values. Each encrypted value would be unique. When Oracle decrypts the data, the salt would be present in the decrypted information, but the database would know to skip the first 10 bytes and return to you your original data. This would prevent someone from probing the data. If we always encrypted the string 'Hello' in the same exact way, an attacker might not need to decrypt it to understand it. All they would need to know is how we encrypted 'Hello' and then they would be able to find 'Hello' anywhere in the data file using a binary file editor. Adding the SALT increases the protection provided by encrypting the data. However, adding the SALT also necessarily increases the storage required to store the data!
We can observe the effect of SALT easily. We'll continue using the table from the manual application encryption approach
ops$tkyte%ORA11GR2> create table t 2 ( last_name varchar2(30), 3 encrypted_name varchar2(30) ENCRYPT 4 ); Table created.
and populate the non-encrypted column, measuring the space used with our SHOW_SPACE routine (introduced in the "Setting Up" section in the beginning of this book)
ops$tkyte%ORA11GR2> insert into t(last_name) 2 select object_name from stage; 64588 rows created. ops$tkyte%ORA11GR2> exec show_space( 'T' ) Unformatted Blocks ..................... 62 FS1 Blocks (0-25) ..................... 1 FS2 Blocks (25-50) ..................... 0 FS3 Blocks (50-75) ..................... 1 FS4 Blocks (75-100)..................... 42 Full Blocks ..................... 264 Total Blocks............................ 384 Total Bytes............................. 3,145,728 Total MBytes............................ 3 Unused Blocks........................... 0 Unused Bytes............................ 0 Last Used Ext FileId.................... 4 Last Used Ext BlockId................... 640 Last Used Block......................... 128 PL/SQL procedure successfully completed.
So, that table has about 322 used blocks right now (384 total allocated blocks minus 62 unformatted, never used blocks). If we truncate that table and populate the ENCRYPTED_NAME column instead
ops$tkyte%ORA11GR2> truncate table t; Table truncated. ops$tkyte%ORA11GR2> insert into t(encrypted_name) 2 select object_name from stage; 64588 rows created. ops$tkyte%ORA11GR2> exec show_space( 'T' ) Unformatted Blocks ..................... 62 FS1 Blocks (0-25) ..................... 3 FS2 Blocks (25-50) ..................... 0 FS3 Blocks (50-75) ..................... 0 FS4 Blocks (75-100)..................... 31 Full Blocks ..................... 652 Total Blocks............................ 768 Total Bytes............................. 6,291,456 Total MBytes............................ 6 Unused Blocks........................... 0
Unused Bytes............................ 0 Last Used Ext FileId.................... 4 Last Used Ext BlockId................... 1,152 Last Used Block......................... 128 PL/SQL procedure successfully completed.
you can see we jumped to having 706 used blocks (768 total blocks minus 62 never used blocks). That is, we doubled our storage. This does not mean that column encryption will double your storage needs—not at all. It means that for this column, we'll need twice as much storage after encrypting than before. If this column represented 1 percent of the data in the table, it won't have a large impact on the total size of the table. However, if this column represented 50 percent of the data in the table, it would. It's something to think about when deciding whether to encrypt a column: what effect will it have on the size of the table overall?
We can remove the SALT from the column during encryption and see what impact that would have on storage. Recall however that by removing the SALT from the column, we reduce the protection afforded by encrypting it. If the attacker knows something of the data (i.e. the attack is an inside job because an employee has stolen the datafiles but doesn't have the keys to decrypt it), they may be able to figure out the values associated with some rows in a table because they have access to those rows in the real system. Then they could recognize where else those same values were anywhere in the stolen datafile since that value would encrypt to the same exact bytes wherever they were encountered in the file.
If we redo the example without salting the column, we will observe
ops$tkyte%ORA11GR2> truncate table t; Table truncated. ops$tkyte%ORA11GR2> alter table t modify encrypted_name encrypt NO SALT; Table altered. ops$tkyte%ORA11GR2> insert into t(encrypted_name) 2 select object_name from stage; 64588 rows created. ops$tkyte%ORA11GR2> exec show_space( 'T' ) Unformatted Blocks ..................... 62 FS1 Blocks (0-25) ..................... 0 FS2 Blocks (25-50) ..................... 1 FS3 Blocks (50-75) ..................... 0 FS4 Blocks (75-100)..................... 50 Full Blocks ..................... 509 Total Blocks............................ 640 Total Bytes............................. 5,242,880 Total MBytes............................ 5 Unused Blocks........................... 0 Unused Bytes............................ 0 Last Used Ext FileId.................... 4 Last Used Ext BlockId................... 1,024 Last Used Block......................... 128 PL/SQL procedure successfully completed.
that it is smaller; it's only 578 blocks now. So it 128 blocks smaller than it was when encrypted with the SALT, but it is still 256 blocks larger than it was when stored non-encrypted. The largest overhead will typically come from the fact the data is stored in a fixed width field that is some multiple of 16 – not from the SALT.
Next, we'll look at how this data is managed and stored in the block buffer cache in the SGA.
Column level encryption stores the data in the block buffer cache in its encrypted form. When the database does a physical IO to retrieve the data from disk, the encrypted column remains encrypted in the SGA. What this implies is that every access to this column will result in having to perform a decrypt process on the data, and in the event of a modification, a subsequent encrypt process. In short, every time you touch this column with SQL, you will experience the extra processing required to transparently encrypt/decrypt this data.
Figure 16-1 depicts how the data would be stored in the SGA for a sample table before encryption and post-encryption of some columns. It graphically represents the fact that encrypted columns are stored in the SGA encrypted; they will therefore consume additional space in the SGA for the reasons we just discussed in the "Increased Storage with Column Encryption" section.
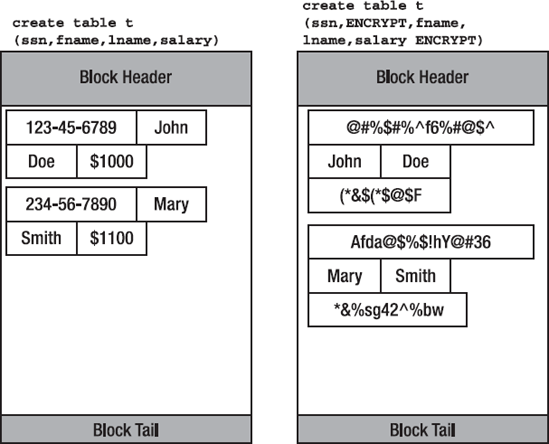
It should be clear from the figure that a query of the form SELECT * FROM T WHERE SALARY > 1050 would have to decrypt every single occurrence of SALARY in that table, row by row, and then for the matching rows, would decrypt the SSN column. This decryption activity will have a definite impact on performance, as we'll see in the "Measuring the Performance Impact of Column Encryption" section, but it won't be nearly as large an impact as manual, application-implemented decryption was.
You might look at that query and say "Obviously, we should index the SALARY column so that we don't have to inspect each and every row." This will work for the non-encrypted table, but not so for the encrypted table—and this has to do with the physical storage of the encrypted column itself. The data in an encrypted column is encrypted as it flows onto the database block; the data you insert is encrypted and then placed on the block. Any index you created on the encrypted column SALARY would be on the encrypted data itself! The encrypted version of the salary information would sort differently than the non-encrypted version. In the index on SAL, when it is encrypted, the number "1,100" might appear to sort lower than "1,000" would. You cannot use a typical INDEX RANGE SCAN on encrypted columns, only equality can be used to access data via an index when the index is on an encrypted column. We'll revisit this limitation in the "Limitations of Column Encryption" section shortly.
It is important to understand that the index would be on encrypted data itself. This implies that the data in the index is therefore encrypted, which would be mandatory. It would not make sense to encrypt the column in the table but not in the index; if we did not encrypt the column in the index, an attacker would be able to retrieve the clear text values of that column easily using a query such as "select /*+ index(t index_name) */ rowid, column from t where column is not null" without the encryption keys. So, if the index stored the data non-encrypted, a simple 'strings' command could be used to see the data (as observed previously in this chapter), a binary editor on the file could retrieve it, or the person who gained access to your datafiles could extract the column values from the index itself and join them back to the table later.
Here is one of the first questions I get asked when discussing data encryption: "What is the performance overhead?" The only truthful answer to that question is "It depends; anywhere from 0 percent to a lot." It depends on how you access the data, how frequently you access the data, and what you do to the data.
Suppose, for example, you have a table in your application that serves as an online store:
Create table customer ( cust_id number primary key, .. other data ... credit_card# varchar2(50) encrypt );
What performance impact could you expect after encrypting the CREDIT_CARD# column as compared to before encrypting it? Well, if you accessed the CREDIT_CARD# only when the customer checked out of your store, the overhead of encrypting the data would be very small, perhaps not even truly measurable.
Let's say that you access the CREDIT_CARD# column only in the following circumstances:
You retrieve it when the customer checks out. You access the credit card once for one row only, which you retrieved via the primary key index on CUST_ID. This is very infrequent on a per customer basis. A typical customer might buy something from you once a week or so.
You modify it when the customer updates their credit card information—approximately once every year or two when their card expires. In other words, almost never.
You modify it when you get a new customer and insert a customer record for them. Hopefully you add lots of new customers over time, but even if you do, this, too, is an infrequent occasion relatively speaking.
And that's about it. The bulk of the processing on your site does not touch this column at all. When the customer is browsing your online catalogue, you are not retrieving their credit card information. When the customer is adding items to your shopping cart, you are not accessing the credit card data. When the customer is interacting with your online shopping help desk, you are not touching the credit card data. If and only if they checkout will you access it, and then only once. The overhead of encryption will only be felt at that exact point in time, which hardly ever happens (again, relatively speaking—a very small percentage of the work processed by your application involves accessing the credit card number).
On the other hand, what if the table you utilized was created as follows:
Create table customer
( cust_id number primary key,
number_of_page_views number encrypt,
.. other data ...
credit_card# varchar2(50) encrypt
);Assume in your application the column NUMBER_OF_PAGE_VIEWS represents a hit counter that you update each and every time a customer clicks on a page on your site. The cost of encrypting the NUMBER_OF_PAGE_VIEWS column would be very high because you would be accessing that column frequently—with every page generated for a given user—and you would be accessing it in a read/write fashion. This would require you to decrypt that column—add one to its value—and write that value back to the table, causing the newly-computed value to be encrypted. The overhead would be measurable. Fortunately though, the requirement to encrypt that specific column is probably very low.
So, how can we measure the cost associated with column level encryption? You'll not only want to measure the additional CPU associated with the encryption operation, but also the increased REDO generation as well since we know that an encrypted column will be larger and hence will generate more REDO in general. Additionally (and this is not something I can show you how to measure), you will need to have a really good understanding of how the data is used in your application. While the following will show you how to measure a percentage difference between non-encrypted and encrypted data, a simple percentage number would be meaningless.
Suppose you measured that the overhead of encrypting the CREDIT_CARD# in the above example was 10 percent. What does that mean? Does it mean you will need 10 percent more CPU resources after encrypting than before? No, it doesn't, for the reason that very few transactions in your application will incur this extra 10 percent. So you need a metric that measures the overhead of encryption coupled with an understanding of how the encrypted data is used. In short, anyone that says "Column encryption adds X percent overhead" is only telling a very small part of the story. They are, in general, overstating the impact, because, in general, not every transaction will encounter this overhead. Typically, most transactions will not encounter the encrypt/decrypt processing.
Let's see how we can measure the impact. We'll use the following tables in this example: the STAGE table is used so that we measure the impact of encryption, not the impact of running a relatively complex query against the view ALL_OBJECTS, and table T is used to measure the impact of column level encryption:
ops$tkyte%ORA11GR2> create table stage 2 as 3 select object_name 4 from all_objects; Table created. ops$tkyte%ORA11GR2> create table t 2 ( non_encrypted varchar2(30), 3 encrypted varchar2(30) ENCRYPT 4 ); Table created.
Our goal is to measure redo generation and CPU utilization of various SQL operations against these columns. To that end, we'll use a small stored procedure that can capture that utilization for us. Our procedure will use dynamic SQL (so we'll be using AUTHID CURRENT_USER to avoid SQL Injection security issues) and measure the amount of redo generated and CPU used. It starts by truncating the table we are using, if necessary. Then our procedure sets about getting the starting redo/cpu metrics, performing an operation, committing (without the PL/SQL optimization we discussed in Chapter 11 "Indexes"), and printing out the totals for each of redo and CPU:
ops$tkyte%ORA11GR2> create or replace
2 procedure do_sql( p_sql in varchar2,
3 p_truncate in boolean default true )
4 authid current_user
5 as
6 l_start_cpu number;
7 l_start_redo number;
8 l_total_redo number;
9 begin
10 if (p_truncate)
11 then
12 execute immediate 'truncate table t';
13 end if;
14
15 dbms_output.put_line( p_sql );
16
17 l_start_cpu := dbms_utility.get_cpu_time;
18 l_start_redo := get_stat_val( 'redo size' );
19
20 execute immediate p_sql;
21 commit work write batch wait;
22
23 dbms_output.put_line
24 ( (dbms_utility.get_cpu_time-l_start_cpu) || ' cpu hsecs' );
25
26 l_total_redo :=
27 round((get_stat_val('redo size')-l_start_redo)/1024/1024,1);
28 dbms_output.put_line
29 ( to_char(l_total_redo,'999,999,999.9') || ' mbytes redo' );
30 end;
31 /
Procedure created.Now we can start by measuring the difference between a bulk insert into the NON_ENCRYPTED column versus the ENCRYPTED column:
ops$tkyte%ORA11GR2> begin 2 do_sql( 'insert into t(non_encrypted) ' || 3 'select object_name from stage' ); 4 do_sql( 'insert into t(encrypted) ' || 5 'select object_name from stage' ); 6 end; 7 / insert into t(non_encrypted) select object_name from stage13 cpu hsecs2.3 mbytes redoinsert into t(encrypted) select object_name from stage121 cpu hsecs5.3 mbytes redoPL/SQL procedure successfully completed.
So, column encryption had a definite impact here: almost 10 times as much CPU was used (on my hardware; your mileage may vary!) and more than twice as much redo was generated. While 10 times as much CPU sounds like a lot, we might want to compare that to the "do it yourself" approach where the CPU utilization was closer to 50 times higher.
Now, let's measure the impact of "slow by slow" processing—also known as row by row processing. This time we'll execute a dynamic PL/SQL block that will load the records from the STAGE table into T a row at a time, once referencing the non-encrypted column and then referencing the encrypted column:
ops$tkyte%ORA11GR2> declare 2 l_sql long := 3 'begin ' || 4 'for x in (select object_name from stage) ' || 5 'loop ' || 6 'insert into t(#CNAME#) ' || 7 'values (x.object_name); ' || 8 'end loop; ' || 9 'end; '; 10 begin 11 do_sql( replace(l_sql,'#CNAME#','non_encrypted') ); 12 do_sql( replace(l_sql,'#CNAME#','encrypted') ); 13 end; 14 / begin for x in (select object_name from stage) loop insert into t(non_encrypted) values (x.object_name); end loop; end; 411 cpu hsecs 16.5 mbytes redo begin for x in (select object_name from stage) loop insert into t(encrypted) values (x.object_name); end loop; end; 1039 cpu hsecs 19.4 mbytes redo
This time we needed about 2.5 times as much CPU and just a little more redo. This 2.5 times difference should be compared to the "do it yourself" encryption we saw previously; there we needed almost six times as much CPU. So again, transparent column level encryption is much more efficient than the "do it yourself" approach. This example points out the overhead of row by row operations in general, however. By doing things very inefficiently (loading a row at a time), some of the overhead of column level encryption is hidden, due to the fact that so much of our time is now spent processing the INSERTS, not performing the encryption itself.
The last performance test is to evaluate the cost of data retrieval. Since the column level encryption stores the information in the buffer cache encrypted, we know that every retrieval will incur the cost of performing a decryption on the data, and we'd like to know what that cost might be. In order to perform this test, we'll load both columns with data and then retrieve each column one at a time. We'll start by truncating the existing data, loading both columns, and gathering statistics on our table:
ops$tkyte%ORA11GR2> truncate table t; Table truncated. ops$tkyte%ORA11GR2> insert into t select object_name, object_name from stage; 64630 rows created. ops$tkyte%ORA11GR2> exec dbms_stats.gather_table_stats( user, 'T' ); PL/SQL procedure successfully completed.
Now we can run our retrieval tests in a manner very similar to the row by row test for insertions we just performed. The major differences between this test and the previous one are that we'll be selecting the data, not inserting it, and we will not be truncating the table in the DO_SQL routine:
ops$tkyte%ORA11GR2> declare 2 l_sql long := 3 'begin ' || 4 'for x in (select #CNAME# from t) ' || 5 'loop ' || 6 'null; ' || 7 'end loop; ' || 8 'end; '; 9 begin 10 do_sql( replace(l_sql,'#CNAME#','non_encrypted'); FALSE ); 11 do_sql( replace(l_sql,'#CNAME#','encrypted'); FALSE ); 12 end; 13 / begin for x in (select non_encrypted from t) loop null; end loop; end; 7 cpu hsecs .0 mbytes redo begin for x in (select encrypted from t) loop null; end loop; end; 69 cpu hsecs .0 mbytes redo PL/SQL procedure successfully completed.
As you can see, it took almost 10 times as much CPU to retrieve the encrypted column as the non-encrypted column. Again, while this sounds large, you must compare that to the cost associated with the "do it yourself approach" where the overhead was closer to 50 times!
The last topic I'd like to take a look at in this section concerns performance, but in a more subtle fashion. It has to do with statistics on encrypted columns. If you remember from the discussion on how column level encryption works, Oracle adds a SALT to the data, some random bytes of data, and pads out the resulting encrypted string to a fixed width string in multiples of 16 bytes. You can imagine that would have an impact on the statistics. We gather statistics on the existing data, and we store those statistics. Hence, the statistics are gathered on the encrypted data in those columns. This will have a definite impact on the query optimizer. Consider a simple query using equality against the non-encrypted and encrypted columns:
ops$tkyte%ORA11GR2> set autotrace traceonly explain ops$tkyte%ORA11GR2> select * from t where non_encrypted = 'ALL_OBJECTS'; Execution Plan ---------------------------------------------------------- Plan hash value: 1601196873 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | |2| 184 | 240 (1)| 00:00:03 | |* 1 | TABLE ACCESS FULL| T |2| 184 | 240 (1)| 00:00:03 | -------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("NON_ENCRYPTED"='ALL_OBJECTS') ops$tkyte%ORA11GR2> select * from t where encrypted = 'ALL_OBJECTS'; Execution Plan ---------------------------------------------------------- Plan hash value: 1601196873 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | |646| 59432 | 241 (2)| 00:00:03 | |* 1 | TABLE ACCESS FULL| T |646| 59432 | 241 (2)| 00:00:03 | -------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter(INTERNAL_FUNCTION("ENCRYPTED")='ALL_OBJECTS') ops$tkyte%ORA11GR2> set autotrace off
Notice how the estimated cardinality goes from 2 rows to 646 rows as we change from using the NON_ENCRYPTED column to the ENCRYPTED column. This is a necessary side effect of encrypting this individual column and may have the effect of changing query plans. That is, the plans your queries used before encrypting the column may be radically different from the plans used by the optimizer after encrypting the data due to this sudden inability to get a picture-perfect view of your data. This is a side effect that might happen; it is not a "definitely, this will happen to you" example. But it is something to keep in mind as you deploy column level encryption.
There are four major feature restrictions to be concerned with regarding the use of column level encryption. In the next section, "Implementing Tablespace Encryption," we'll see how these limitations can be avoided entirely. But for now, it's important that you understand them. Here they are:
Reduced ability to use indexes: Column level encryption will place encrypted values in the index. The index no longer stores data sorted in any useful fashion. The data is sorted, of course, but it is sorted by the encrypted values, not by the original data values. We can use the index for equality searches ("
where encrypted_column = ?" searches) but not for typical range scans ("where encrypted column > ?").Reduced protection when using indexes: If you index an encrypted column, you may not use the SALT Oracle normally adds to the encrypted values. This is because we need to make sure the value we place into the index is a value we can find later! If we added some random bytes to every string and then place them in the index, we would never be able to use the index to find that string again since we wouldn't know what SALT to use!
Inability to use function based indexes: Since an index is created against the encrypted data, the input to your function-based index would necessarily be the encrypted version of the data, which isn't very useful to you. Your function could not make any use of it. Creating function based indexes against encrypted columns is not supported in any sense.
Inability to use foreign key constraints: Declarative referential integrity is not supported against encrypted keys.
Many times, these restrictions are perfectly workable. Take our example from the preceding section with the CUSTOMER table and the encrypted CREDIT_CARD# column. In that example, CREDIT_CARD# would never be indexed (we find a credit card by customer, we do not look up who owns a given credit card), so the first three restrictions do not hit us. Also, CREDIT_CARD# would never be a primary key (it changes too frequently) and it is not unique; a husband and wife might have their own customer accounts with the same credit card on file, for example. Therefore, it could never be in a foreign key. So, in this case, the restrictions would not impact us at all.
However, sometimes there are attributes you would like to encrypt whereby these restrictions would play a large role. For example, I've seen systems where a social security number was used as a primary key to identify a person. It should not have been because social security numbers are not immutable; therefore, they are not a good candidate for a primary key. In these systems, the requirement to encrypt the social security number column would arise. Now, since the social security number was used as a primary key, we know there is an index on that column. Hence the first two restrictions may apply and the third one as well. Additionally, if an attribute is a primary key in some table, there is a good chance it will be used as a foreign key in some other table, therefore the fourth restriction would become an issue. To add insult to injury, since this was the primary key, it was accessed frequently, imposing the largest possible performance penalty because of the frequent accesses. In this system, column level encryption may well be a large burden. Remember, you need to understand how the data will be used in your application to make sensible decisions about the features you can use with it.
Tablespace encryption, introduced in Oracle Database 11g Release 1, is the ability to have each and every database block located in a given tablespace be stored in an encrypted format on disk. Every segment stored within that tablespace will be stored encrypted. This goes far beyond the column level encryption we just discussed. Every column in every table stored in this tablespace would be encrypted on disk, as would be the contents of every INDEX, LOBSEGMENT, and so on. Furthermore, the documented limitations of column encryption regarding statistics, indexes, and foreign keys do not apply to encrypted tablespaces. There are no restrictions when looking at tablespace encryption.
In this section, we'll look at how to setup and use tablespace encryption, how the data is physically stored on disk and in the SGA, and how to measure the performance impact of tablespace encryption.
In order to use tablespace encryption, you start off just as you would for column level encryption by setting up your Oracle wallet for the database to store and supply the encryption keys. Once that is done, you are ready to create an encrypted tablespace using the following syntax
create tablespacetablespace_namedatafile ...ENCRYPTIONUsing 'algorithm'(optional)default storage ( ENCRYPT );
where algorithm is one of 3DES168, AES128, AES192, and AES256 to specify the type of encryption to be used (AES128 is the current default). The algorithm is optional as it will default, but the two parts in bold are required to create an encrypted tablespace.
Note
You cannot encrypt an existing tablespace; you must create a tablespace in encrypted mode. In order to effectively encrypt an existing tablespace, you would have to create a new encrypted tablespace, move the segments from the old tablespace to this new one, drop the old tablespace, and optionally rename the new tablespace to the old name.
Once you have created an encrypted tablespace, you are ready to store data in an encrypted fashion. All you need to do now is create some segments (tables, indexes, and so on) in that tablespace. As the data is written to the datafiles for that tablespace, it will be encrypted transparently. As the data is read back in from those same datafiles, it will be decrypted transparently.
In this section, we'll take a look at how the encrypted database blocks are stored on disk and in the SGA. We'll look at the same considerations we did for column level encryption—any storage overhead as well as the impact of data retrieval and modifications due to the encryption. We'll start with how the data is stored on disk.
Unlike column level encryption, there is no storage overhead with tablespace compression. There is no need to pad the data out to any multiple of 16 bytes, since every database block is some multiple of a kilobyte already (by definition, a database block is already a multiple of 16 bytes). Additionally, since a database block is a fixed width data element (there is no such thing as a varying length database block), the fact that encryption would result in a fixed width output is not relevant either. Lastly, since each database block is a unique entity, the data on it is unique already, so the need to SALT the data does not exist; we need not add anything to the database block data in an attempt to make it unique to avoid issues with probing of the data, as we do with data at the column level.
So, with tablespace encryption, if a full, unencrypted tablespace consumes 5GB on disk, the same data stored in an encrypted tablespace would utilize the same 5GB of storage. In the datafiles, the datafile header itself would be stored unencrypted (so the database can identify and access the file with or without the wallet), but every database block in it would be stored encrypted, inaccessible by anyone when the wallet is not open in the database instance.
Again, unlike column level encryption, the data from an encrypted tablespace is stored in the SGA un-encrypted, in the clear. This is one of the major differences between the two approaches. When a database block is read from the disk into the buffer cache, the database block is decrypted and then placed into the buffer cache. When the database block is read out from the cache, no decryption need take place. Later, when the block is written out to disk, typically by the database block writer (DBWR), the data will be encrypted after retrieving it from the SGA and before writing it to disk.
Figure 16-2 depicts this processing. As blocks are read into the SGA, usually by a dedicated or shared server process, they are decrypted. As they are flushed to disk by a checkpoint or some other action, they will be encrypted once again before being written.
This alternate method of storing the data in the SGA unencrypted has two major ramifications. The first is on performance, as we'll see in the next section. If the data is stored in the cache unencrypted, when we access the data in the cache (without having to perform a physical IO), the overhead of this encrypted tablespace is approximately zero. Since the data is already decrypted, we do not have to go through the decryption process for each and every access. Therefore, if you do one physical IO to get the block into the cache and then perform 1,000,000 logical IOs against it (cached reads), you will have performed the decryption only once, not 1,000,000 times. Even modifications will benefit from this—not at a zero overhead level since the undo and redo generated must be encrypted, but they will benefit from this greatly.
Note
Temporary data for encrypted data is also stored on disk encrypted, so even for the reads, there could be overheads introduced by encryption if the PGA is not large enough to hold intermediate result sets.
The other ramification is that the data is stored in the SGA unencrypted. If someone can gain access to your physical server (as they must in order to steal your data files), there is a chance they could also access the shared memory of the instance and see the data in the buffer cache. This is something you must be aware of, and you must decide if it applies to you. In most cases, if an attacker can attach and see your SGA, that same attacker could probably assume the SYSDBA role, which is typically authenticated by the operating system. If they are using an account that can access the SGA, they are probably using an account that can become SYSDBA. Remember, though, the goal of data encryption is to protect data at rest, the data in the datafiles. So in most cases, the fact that the database blocks in the SGA are cached unencrypted is a feature, not a downside.
Now that we understand how encrypted tablespaces store data, we are ready to evaluate the impact on performance of this feature. We have to do a slightly different series of tests in addition to the ones we performed for column level encryption. This is because the largest impact of tablespace encryption comes at physical IO times. If we just ran the conventional path INSERTs and SELECTs, there is a good chance we would not incur any physical IO and hence would not see the majority of the overhead.
Again, much like column level encryption, before you can assign any percentage level of overhead to tablespace encryption, you must understand how your application uses the data. If you only use conventional path reads (as many applications do), you will not see a major impact from this feature. On the other hand, if you direct path load many gigabytes of data, you might notice a large impact. It all depends on how you use the data.
So, we'll start by creating two tablespaces for our tests: a tablespace named CLEAR that will not be encrypted and a tablespace named ENCRYPTED that will be. Do not let the name ENCRYPTED mislead you; it's just a name, and the name of the tablespace has nothing to do with tablespace encryption. The ENCRYPTION and DEFAULT STORAGE(ENCRYPT) clauses do all of the work for us:
ops$tkyte%ORA11GR2> create tablespace encrypted 2 datafile '/tmp/encrypted.dbf' size 1m 3 autoextend on next 1m4 ENCRYPTION5 default storage ( ENCRYPT );Tablespace created.
ops$tkyte%ORA11GR2> create tablespace clear 2 datafile '/tmp/clear.dbf' size 1m 3 autoextend on next 1m; Tablespace created.
Next, we'll create the tables for the simulation. We'll use a STAGE table once again as a copy of ALL_OBJECTS and then two tables each in one of the above tablespaces. Additionally, we'll create primary key indexes on these tables, placing the index in the same tablespace with the table data. Thus, the index on the encrypted data will likewise be encrypted. First the STAGE table
ops$tkyte%ORA11GR2> create table stage 2 as 3 select * 4 from all_objects 5 / Table created.
and then the NONENCRYPTED table and primary key index
ops$tkyte%ORA11GR2> create table nonencrypted 2 tablespace nonencrypted 3 as 4 select * 5 from stage 6 where 1=0 7 / Table created. ops$tkyte%ORA11GR2> alter table nonencrypted 2 add constraint nonencrypted_pk 3 primary key(object_id) 4 using index 5 (create index nonencrypted_pk 6 on nonencrypted(object_id) 7 tablespace clear ); Table altered.
followed by the ENCRYPTED table and index
ops$tkyte%ORA11GR2> create table encrypted 2 tablespace encrypted 3 as 4 select * 5 from stage 6 where 1=0 7 / Table created. ops$tkyte%ORA11GR2> alter table encrypted 2 add constraint encrypted_pk 3 primary key(object_id) 4 using index 5 (create index encrypted_pk
6 on encrypted(object_id) 7 tablespace encrypted ); Table altered.
Lastly, we'll use a slightly modified version of DO_SQL. The following just highlights the modifications from the copy we used in the column encryption section. The modifications allow us to pass in a table name since we are using two tables instead of two columns in this simulation. The rest of the code remains unchanged from before:
ops$tkyte%ORA11GR2> create or replace 2 procedure do_sql( p_sql in varchar2,3 p_tname in varchar2,4 p_truncate in boolean default true ) 5 authid current_user 6 as 7 l_start_cpu number; 8 l_start_redo number; 9 l_total_redo number; 10 begin 11 if (p_truncate) 12 then13 execute immediate 'truncate table ' || p_tname;14 end if; 1516 dbms_output.put_line( replace( p_sql, '#TNAME#', p_tname ) );17 18 l_start_cpu := dbms_utility.get_cpu_time; 19 l_start_redo := get_stat_val( 'redo size' ); 2021 execute immediate replace(p_sql,'#TNAME#', p_tname);22 commit work write batch wait; 23 24 dbms_output.put_line 25 ( (dbms_utility.get_cpu_time-l_start_cpu) || ' cpu hsecs' ); 26 27 l_total_redo := 28 round((get_stat_val('redo size')-l_start_redo)/1024/1024,1); 29 dbms_output.put_line 30 ( to_char(l_total_redo,'999,999,999.9') || ' mbytes redo' ); 31 end; 32 / Procedure created.
And now we are ready to go! We'll start with a bulk load using a conventional path load of the tables:
ops$tkyte%ORA11GR2> begin 2 do_sql( 'insert into #TNAME# select * from stage', 'nonencrypted' ); 3 do_sql( 'insert into #TNAME# select * from stage', 'encrypted' ); 4 end; 5 / insert into nonencrypted select * from stage 203 cpu hsecs
23.8 mbytes redo insert into encrypted select * from stage 225 cpu hsecs 23.8 mbytes redo PL/SQL procedure successfully completed.
As you can see, there was hardly any impact on the CPU utilization and no impact on redo generated as a result of this. Since our work was primarily done in the buffer cache, we didn't have to wait for physical IOs to take place, so we didn't see a measurable difference between the two. What if we introduce a direct path load, however, bypassing the buffer cache and writing directly to disk? It would look like this:
ops$tkyte%ORA11GR2> begin
2 do_sql( 'insert /*+ APPEND */ into #TNAME#
select * from stage', 'nonencrypted' );
3 do_sql( 'insert /*+ APPEND */ into #TNAME#
select * from stage', 'encrypted' );
4 end;
5 /
insert /*+ APPEND */ into nonencrypted select * from stage
135 cpu hsecs
15.9 mbytes redo
insert /*+ APPEND */ into encrypted select * from stage
184 cpu hsecs
15.9 mbytes redo
PL/SQL procedure successfully completed.Here we noticed a small but noticeable increase in CPU utilization—nothing on the order of the "do it yourself" encryption or even the column level encryption, however. Remember, your mileage may vary widely; it will be very specific to your hardware capabilities.
Now we'd like to see single row (slow by slow) insert performance. Using a simple for loop, we can see:
ops$tkyte%ORA11GR2> declare 2 l_sql long := 3 'begin ' || 4 'for x in (select * from stage) ' || 5 'loop ' || 6 'insert into #TNAME# values X; ' || 7 'end loop; ' || 8 'end; '; 9 begin 10 do_sql( l_sql, 'nonencrypted' ); 11 do_sql( l_sql, 'encrypted' ); 12 end; 13 / begin for x in (select * from stage) loop insert into nonencrypted values X; end loop; end; 951 cpu hsecs 40.0 mbytes redo begin for x in (select * from stage) loop insert into
encrypted values X; end loop; end; 1055 cpu hsecs 40.0 mbytes redo PL/SQL procedure successfully completed.
There is no real measurable difference between the two—again, due to the fact that most of the work takes place in the buffer cache itself. Lastly, what about retrieval performance? We'll read each row out of each table by its primary key value, which will make use of the buffer cache whenever possible:
ops$tkyte%ORA11GR2> declare 2 l_sql long := 3 'begin ' || 4 'for x in (select object_id from stage) ' || 5 'loop ' || 6 'for y in (select * from #TNAME# where object_id = x.object_id) ' || 7 'loop ' || 8 'null; ' || 9 'end loop; ' || 10 'end loop; ' || 11 'end; '; 12 begin 13 do_sql( l_sql, 'nonencrypted', FALSE ); 14 do_sql( l_sql, 'encrypted', FALSE ); 15 end; 16 / begin for x in (select object_id from stage) loop for y in (select * from nonencrypted where object_id = x.object_id) loop null; end loop; end loop; end; 625 cpu hsecs .0 mbytes redo begin for x in (select object_id from stage) loop for y in (select * from encrypted where object_id = x.object_id) loop null; end loop; end loop; end; 630 cpu hsecs .0 mbytes redo PL/SQL procedure successfully completed.
Again, since the vast majority of our buffer gets in each case were directly from the buffer cache without any physical IO, the penalty of encrypting the data never came into play. Only during the physical IOs would we see a performance overhead. So what if we flush the buffer cache and force physical IOs?
ops$tkyte%ORA11GR2> alter system flush buffer_cache; / ops$tkyte%ORA11GR2> .. rerun the above plsql block .. begin for x in (select object_id from stage) loop for y in (select * from nonencrypted where object_id = x.object_id) loop null; end loop; end loop; end; 646 cpu hsecs .0 mbytes redo begin for x in (select object_id from stage) loop for y in (select * from encrypted where object_id = x.object_id)
loop null; end loop; end loop; end; 659 cpu hsecs .0 mbytes redo
Again, a nominal difference; most of our time is spent doing the physical IO (not decrypting data). Hence the impact of encryption is hardly measurable. Lastly, what about the impact on the optimizer? With column encryption, we noticed a difference in cardinality estimations before and after encrypting. Will the same happen with encrypted tablespaces? Fortunately, the answer is "No, it will not." For example:
ops$tkyte%ORA11GR2> exec dbms_stats.gather_table_stats( user, 'NONENCRYPTED',
method_opt=> 'for columns object_name size 254' );
PL/SQL procedure successfully completed.
ops$tkyte%ORA11GR2> exec dbms_stats.gather_table_stats( user, 'ENCRYPTED',
method_opt=> 'for columns object_name size 254' );
PL/SQL procedure successfully completed.
ops$tkyte%ORA11GR2> set autotrace traceonly explain
ops$tkyte%ORA11GR2> select * from nonencrypted where object_name = 'ALL_OBJECTS';
----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 196 | 274 (1)| 00:00:04 |
|* 1 | TABLE ACCESS FULL| NONENCRYPTED | 2 | 196 | 274 (1)| 00:00:04 |
----------------------------------------------------------------------------------
ops$tkyte%ORA11GR2> select * from encrypted where object_name = 'ALL_OBJECTS';
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 196 | 274 (1)| 00:00:04 |
|* 1 | TABLE ACCESS FULL| ENCRYPTED | 2 | 196 | 274 (1)| 00:00:04 |
-------------------------------------------------------------------------------
ops$tkyte%ORA11GR2> set autotrace offNote
Above output was edited to remove lines of text for brevity
As you can see, the optimizer gets the same cardinality estimates regardless of which table we access. DBMS_STATS is gathering statistics on the blocks in the buffer cache in the clear, preserving the fidelity of the statistics.
Now that we've seen the three approaches to encryption of data at rest, which one should you use? That is another "It depends" answer. Each approach has advantages and disadvantages, with the manual approach having the least set of advantages.
Manual application implemented encryption would be appropriate if you simply do not have access to and will not get access to the Advanced Security Option (ASO) available with the Enterprise Edition of Oracle. If you do not have ASO and you must encrypt some data in order to be compliant with a policy in your place of work, then a manual "do it yourself" approach is warranted. Remember, however, that key management is not only hard, it's extremely hard to implement and even harder to implement thoroughly and completely. You must think about many things that are not immediately intuitive. For example, if you perform "do it yourself" encryption and attempt to do it transparently, how can you make sure the data values are not recorded by Oracle on disk at some stage (think temporary data, for example)? Are you quite sure that Oracle will never record your value in REDO or UNDO or your TEMP tablespace at sometime? This does not apply just to the Oracle RDBMS, it applies to any and every database product you use. Also, what about the data as it is being transferred on the network? Without ASO, you would have to worry about that data being intercepted at that time as well. In addition to the key management issue, we demonstrated a rather large negative performance impact as a result of manual "do it yourself" encryption.
So, that leaves the two automatic approaches. Column level encryption and tablespace encryption both have the key management issue solved for them via the Oracle database. In that regard, they are equals; they both get the full advantage of the Oracle wallet and its set of features. They differ in their implementations.
Column level encryption would be appropriate for data attributes such as a credit card number that is infrequently accessed, where indexing is typically not a concern, and the need to define a foreign key on the attribute is not a consideration. As demonstrated, if you need to access the column frequently, the cost of encrypting that column resource-wise goes up. Every time you access that attribute, a decrypt (and in the case of modification, encrypt) process will be executed. The more frequently you access the column, the higher the cost of encrypting the column. One of the major benefits of column level encryption is that it can be very finely applied; it is not an all-or-nothing approach like tablespace encryption. You can alter an existing column to be encrypted without having to relocate massive amounts of data. You can create a new table in an existing (non-encrypted) tablespace with some encrypted columns.
Tablespace encryption is appropriate for most any case, if you are willing to move all existing data (tables and indexes) that contain sensitive information from the tablespace they currently reside in into a new encrypted tablespace. This is perhaps the one drawback to tablespace encryption: it cannot be retroactively applied to existing tablespaces. It requires that you create a new tablespace and then place data into it. For many applications with existing large sets of data, this may not be feasible. Going forward for newly created data sets that need to have sensitive information encrypted, I would choose tablespace encryption over the other encryption techniques because of its low impact on performance and its total transparency. There are no indexing, foreign key, or size considerations with tablespace encryption as there are with column level encryption.
In this chapter, we described the two types of encryption—encryption for data in motion and encryption for data at rest, on disk. We spent the bulk of our time concentrating on data at rest—database encryption. We discussed key management and how it is a rather difficult problem to solve. Implementing a secure method to store encryption keys so that the data that has been encrypted can be securely decrypted by the right people and cannot be decrypted by the wrong people is a non-trivial task. It would be very expensive to implement yourself from a software design, testing, and maintenance perspective.
We then discussed what encryption is not about. Specifically, how encryption is not about access control—a common misconception held by many people. Encryption is not a technique you would use to prevent an end user of your application from accessing data. Access controls do that. Encryption is entirely about protecting your data in the event someone steals your database.
Lastly, we explored three methods of encrypting your data at rest: manual application encryption, transparent column encryption, and transparent tablespace encryption. We reviewed the performance impact of each as well as any limitations involved. We summarized the discussion of how to choose between the three approaches with the general recommendation that tablespace encryption, due to its total application transparency and low performance impact, would likely be the approach of choice.