
Chapter 3. The Cassandra Data Model
In this chapter, we’ll gain an understanding of Cassandra’s design goals, data model, and some general behavior characteristics.
For developers and administrators coming from the relational world, the Cassandra data model can be very difficult to understand initially. Some terms, such as “keyspace,” are completely new, and some, such as “column,” exist in both worlds but have different meanings. It can also be confusing if you’re trying to sort through the Dynamo or Bigtable source papers, because although Cassandra may be based on them, it has its own model.
So in this chapter we start from common ground and then work through the unfamiliar terms. Then, we do some actual modeling to help understand how to bridge the gap between the relational world and the world of Cassandra.
The Relational Data Model
In a relational database, we have the database itself, which is the
outermost container that might correspond to a single application. The
database contains tables. Tables have names and contain one or more
columns, which also have names. When we add data to a table, we specify a
value for every column defined; if we don’t have a value for a particular
column, we use null. This new entry adds a row to the table,
which we can later read if we know the row’s unique identifier (primary
key), or by using a SQL statement that expresses some criteria that row
might meet. If we want to update values in the table, we can update all of
the rows or just some of them, depending on the filter we use in a “where”
clause of our SQL statement.
For the purposes of learning Cassandra, it may be useful to suspend for a moment what you know from the relational world.
A Simple Introduction
In this section, we’ll take a bottom-up approach to understanding Cassandra’s data model.
The simplest data store you would conceivably want to work with might be an array or list. It would look like Figure 3-1.

If you persisted this list, you could query it later, but you would have to either examine each value in order to know what it represented, or always store each value in the same place in the list and then externally maintain documentation about which cell in the array holds which values. That would mean you might have to supply empty placeholder values (nulls) in order to keep the uniform size in case you didn’t have a value for an optional attribute (such as a fax number or apartment number). An array is a clearly useful data structure, but not semantically rich.
So we’d like to add a second dimension to this list: names to match the values. We’ll give names to each cell, and now we have a map structure, as shown in Figure 3-2.
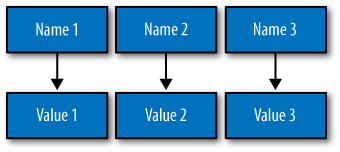
This is an improvement because we can know the names of our values.
So if we decided that our map would hold User information, we could have
column names like firstName, lastName,
phone, email, and so on. This is a somewhat
richer structure to work with.
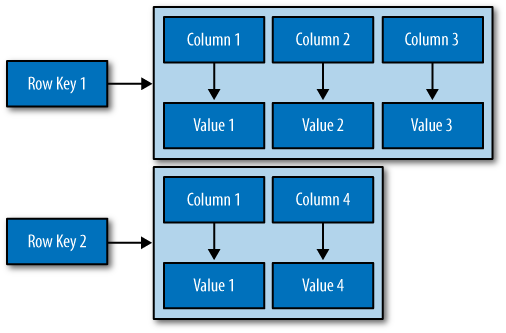
But the structure we’ve built so far works only if we have one instance of a given entity, such as a single Person or User or Hotel or Tweet. It doesn’t give us much if we want to store multiple entities with the same structure, which is certainly what we want to do. There’s nothing to unify some collection of name/value pairs, and no way to repeat the same column names. So we need something that will group some of the column values together in a distinctly addressable group. We need a key to reference a group of columns that should be treated together as a set. We need rows. Then, if we get a single row, we can get all of the name/value pairs for a single entity at once, or just get the values for the names we’re interested in. We could call these name/value pairs columns. We could call each separate entity that holds some set of columns rows. And the unique identifier for each row could be called a row key.
Cassandra defines a column family to be a logical division that associates similar data. For example, we might have a User column family, a Hotel column family, an AddressBook column family, and so on. In this way, a column family is somewhat analogous to a table in the relational world.
Putting this all together, we have the basic Cassandra data structures: the column, which is a name/value pair (and a client-supplied timestamp of when it was last updated), and a column family, which is a container for rows that have similar, but not identical, column sets.
In relational databases, we’re used to storing column names as strings only—that’s all we’re allowed. But in Cassandra, we don’t have that limitation. Both row keys and column names can be strings, like relational column names, but they can also be long integers, UUIDs, or any kind of byte array. So there’s some variety to how your key names can be set.
This reveals another interesting quality to Cassandra’s columns: they don’t have to be as simple as predefined name/value pairs; you can store useful data in the key itself, not only in the value. This is somewhat common when creating indexes in Cassandra. But let’s not get ahead of ourselves.
Now we don’t need to store a value for every column every time we
store a new entity. Maybe we don’t know the values for every column for a
given entity. For example, some
people have a second phone number and some don’t, and in an
online form backed by Cassandra, there may be some fields that are
optional and some that are required. That’s OK. Instead of storing
null for those values we don’t know, which would waste
space, we just won’t store that
column at all for that row. So now we have a sparse, multidimensional
array structure that looks like Figure 3-3.
It may help to think of it in terms of JavaScript Object Notation (JSON) instead of a picture:
Musician: ColumnFamily 1
bootsy: RowKey
email: [email protected], ColumnName:Value
instrument: bass ColumnName:Value
george: RowKey
email: [email protected] ColumnName:Value
Band: ColumnFamily 2
george: RowKey
pfunk: 1968-2010 ColumnName:ValueHere we have two column families, Musician and Band. The Musician column family has two rows, “bootsy” and “george”. These two rows have a ragged set of columns associated with them: the bootsy record has two columns (email and instrument), and the george record has only one column. That’s fine in Cassandra. The second column family is Band, and it also has a “george” row, with a column named “pfunk”.
Columns in Cassandra actually have a third aspect: the timestamp, which records the last time the column was updated. This is not an automatic metadata property, however; clients have to provide the timestamp along with the value when they perform writes. You cannot query by the timestamp; it is used purely for conflict resolution on the server side.
Note
Rows do not have timestamps. Only each individual column has a timestamp.
And what if we wanted to create a group of related columns, that is, add another dimension on top of this? Cassandra allows us to do this with something called a super column family. A super column family can be thought of as a map of maps. The super column family is shown in Figure 3-4.

Where a row in a column family holds a collection of name/value pairs, the super column family holds subcolumns, where subcolumns are named groups of columns. So the address of a value in a regular column family is a row key pointing to a column name pointing to a value, while the address of a value in a column family of type “super” is a row key pointing to a column name pointing to a subcolumn name pointing to a value. Put slightly differently, a row in a super column family still contains columns, each of which then contains subcolumns.
So that’s the bottom-up approach to looking at Cassandra’s data model. Now that we have this basic understanding, let’s switch gears and zoom out to a higher level, in order to take a top-down approach. There is so much confusion on this topic that it’s worth it to restate things in a different way in order to thoroughly understand the data model.
Clusters
Cassandra is probably not the best choice if you only need to run a single node. As previously mentioned, the Cassandra database is specifically designed to be distributed over several machines operating together that appear as a single instance to the end user. So the outermost structure in Cassandra is the cluster, sometimes called the ring, because Cassandra assigns data to nodes in the cluster by arranging them in a ring.
A node holds a replica for different ranges of data. If the first node goes down, a replica can respond to queries. The peer-to-peer protocol allows the data to replicate across nodes in a manner transparent to the user, and the replication factor is the number of machines in your cluster that will receive copies of the same data. We’ll examine this in greater detail in Chapter 6.
Keyspaces
A cluster is a container for keyspaces—typically a single keyspace. A keyspace is the outermost container for data in Cassandra, corresponding closely to a relational database. Like a relational database, a keyspace has a name and a set of attributes that define keyspace-wide behavior. Although people frequently advise that it’s a good idea to create a single keyspace per application, this doesn’t appear to have much practical basis. It’s certainly an acceptable practice, but it’s perfectly fine to create as many keyspaces as your application needs. Note, however, that you will probably run into trouble creating thousands of keyspaces per application.
Depending on your security constraints and partitioner, it’s fine to
run multiple keyspaces on the same cluster. For example, if your
application is called Twitter, you would
probably have a cluster called Twitter-Cluster and a
keyspace called Twitter. To my knowledge, there are currently
no naming conventions in Cassandra for such items.
In Cassandra, the basic attributes that you can set per keyspace are:
- Replication factor
In simplest terms, the replication factor refers to the number of nodes that will act as copies (replicas) of each row of data. If your replication factor is 3, then three nodes in the ring will have copies of each row, and this replication is transparent to clients.
The replication factor essentially allows you to decide how much you want to pay in performance to gain more consistency. That is, your consistency level for reading and writing data is based on the replication factor.
- Replica placement strategy
The replica placement refers to how the replicas will be placed in the ring. There are different strategies that ship with Cassandra for determining which nodes will get copies of which keys. These are SimpleStrategy (formerly known as RackUnawareStrategy), OldNetworkTopologyStrategy (formerly known as RackAwareStrategy), and NetworkTopologyStrategy (formerly known as DatacenterShardStrategy).
- Column families
In the same way that a database is a container for tables, a keyspace is a container for a list of one or more column families. A column family is roughly analagous to a table in the relational model, and is a container for a collection of rows. Each row contains ordered columns. Column families represent the structure of your data. Each keyspace has at least one and often many column families.
I mention the replication factor and replica placement strategy here because they are set per keyspace. However, they don’t have an immediate impact on your data model per se.
It is possible, but generally not recommended, to create multiple keyspaces per application. The only time you would want to split your application into multiple keyspaces is if you wanted a different replication factor or replica placement strategy for some of the column families. For example, if you have some data that is of lower priority, you could put it in its own keyspace with a lower replication factor so that Cassandra doesn’t have to work as hard to replicate it. But this may be more complicated than it’s worth. It’s probably a better idea to start with one keyspace and see whether you really need to tune at that level.
Column Families
A column family is a container for an ordered collection of rows, each of which is itself an ordered collection of columns. In the relational world, when you are physically creating your database from a model, you specify the name of the database (keyspace), the names of the tables (remotely similar to column families, but don’t get stuck on the idea that column families equal tables—they don’t), and then you define the names of the columns that will be in each table.
There are a few good reasons not to go too far with the idea that a column family is like a relational table. First, Cassandra is considered schema-free because although the column families are defined, the columns are not. You can freely add any column to any column family at any time, depending on your needs. Second, a column family has two attributes: a name and a comparator. The comparator value indicates how columns will be sorted when they are returned to you in a query—according to long, byte, UTF8, or other ordering.
In a relational database, it is frequently transparent to the user how tables are stored on disk, and it is rare to hear of recommendations about data modeling based on how the RDBMS might store tables on disk. That’s another reason to keep in mind that a column family is not a table. Because column families are each stored in separate files on disk, it’s important to keep related columns defined together in the same column family.
Another way that column families differ from relational tables is that relational tables define only columns, and the user supplies the values, which are the rows. But in Cassandra, a table can hold columns, or it can be defined as a super column family. The benefit of using a super column family is to allow for nesting.
For standard column families, which is the default, you set the type to Standard; for a super column family, you set the type to Super.
When you write data to a column family in Cassandra, you specify values for one or more columns. That collection of values together with a unique identifier is called a row. That row has a unique key, called the row key, which acts like the primary key unique identifier for that row. So while it’s not incorrect to call it column-oriented, or columnar, it might be easier to understand the model if you think of rows as containers for columns. This is also why some people refer to Cassandra column families as similar to a four-dimensional hash:
[Keyspace][ColumnFamily][Key][Column]
We can use a JSON-like notation to represent a Hotel column family, as shown here:
Hotel {
key: AZC_043 { name: Cambria Suites Hayden, phone: 480-444-4444,
address: 400 N. Hayden Rd., city: Scottsdale, state: AZ, zip: 85255}
key: AZS_011 { name: Clarion Scottsdale Peak, phone: 480-333-3333,
address: 3000 N. Scottsdale Rd, city: Scottsdale, state: AZ, zip: 85255}
key: CAS_021 { name: W Hotel, phone: 415-222-2222,
address: 181 3rd Street, city: San Francisco, state: CA, zip: 94103}
key: NYN_042 { name: Waldorf Hotel, phone: 212-555-5555,
address: 301 Park Ave, city: New York, state: NY, zip: 10019}
}Note
I’m leaving out the timestamp attribute of the columns here for simplicity, but just remember that every column has a timestamp.
In this example, the row key is a unique primary key for the hotel, and the columns are name, phone, address, city, state, and zip. Although these rows happen to define values for all of the same columns, you could easily have one row with 4 columns and another row in the same column family with 400 columns, and none of them would have to overlap.
Note
It’s an inherent part of Cassandra’s replica design that all data for a single row must fit on a single machine in the cluster. The reason for this limitation is that rows have an associated row key, which is used to determine the nodes that will act as replicas for that row. Further, the value of a single column cannot exceed 2GB. Keep these things in mind as you design your data model.
We can query a column family such as this one using the CLI, like this:
cassandra> get Hotelier.Hotel['NYN_042'] => (column=zip, value=10019, timestamp=3894166157031651) => (column=state, value=NY, timestamp=3894166157031651) => (column=phone, value=212-555-5555, timestamp=3894166157031651) => (column=name, value=The Waldorf=Astoria, timestamp=3894166157031651) => (column=city, value=New York, timestamp=3894166157031651) => (column=address, value=301 Park Ave, timestamp=3894166157031651) Returned 6 results.
This indicates that we have one hotel in New York, New York, but we see six results because the results are column-oriented, and there are six columns for that row in the column family. Note that while there are six columns for that row, other rows might have more or fewer columns.
Column Family Options
There are a few additional parameters that you can define for each column family. These are:
keys_cachedThe number of locations to keep cached per SSTable. This doesn’t refer to column name/values at all, but to the number of keys, as locations of rows per column family, to keep in memory in least-recently-used order.
rows_cachedThe number of rows whose entire contents (the complete list of name/value pairs for that unique row key) will be cached in memory.
commentThis is just a standard comment that helps you remember important things about your column family definitions.
read_repair_chanceThis is a value between 0 and 1 that represents the probability that read repair operations will be performed when a query is performed without a specified quorum, and it returns the same row from two or more replicas and at least one of the replicas appears to be out of date. You may want to lower this value if you are performing a much larger number of reads than writes.
preload_row_cacheSpecifies whether you want to prepopulate the row cache on server startup.
I have simplified these definitions somewhat, as they are really more about configuration and server behavior than they are about the data model. They are covered in detail in Chapter 6.
Columns
A column is the most basic unit of data structure in the Cassandra data model. A column is a triplet of a name, a value, and a clock, which you can think of as a timestamp for now. Again, although we’re familiar with the term “columns” from the relational world, it’s confusing to think of them in the same way in Cassandra. First of all, when designing a relational database, you specify the structure of the tables up front by assigning all of the columns in the table a name; later, when you write data, you’re simply supplying values for the predefined structure.
But in Cassandra, you don’t define the columns up front; you just define the column families you want in the keyspace, and then you can start writing data without defining the columns anywhere. That’s because in Cassandra, all of a column’s names are supplied by the client. This adds considerable flexibility to how your application works with data, and can allow it to evolve organically over time.
Note
Cassandra’s clock was introduced in version 0.7, but its fate is
uncertain. Prior to 0.7, it was called a timestamp, and was simply a
Java long type. It was changed to support Vector Clocks,
which are a popular mechanism for replica conflict resolution in
distributed systems, and it’s how Amazon Dynamo implements conflict
resolution. That’s why you’ll hear the third aspect of the column
referred to both as a timestamp and a clock. Vector Clocks may or may
not ultimately become how timestamps are represented in Cassandra 0.7,
which is in beta at the time of this writing.
The data types for the name and value are Java byte arrays,
frequently supplied as strings. Because the name and value are binary
types, they can be of any length. The data type for the clock is an
org.apache.cassandra.db.IClock, but for the 0.7
release, a timestamp still works to keep backward compatibility. This
column structure is illustrated in Figure 3-5.
Note
Cassandra 0.7 introduced an optional time to live (TTL) value, which allows columns to expire a certain amount of time after creation. This can potentially prove very useful.

Here’s an example of a column you might define, represented with JSON notation just for clarity of structure:
{
"name": "email",
"value: "[email protected]",
"timestamp": 1274654183103300
}In this example, this column is named “email”; more precisely, the value of its name attribute is “email”. But recall that a single column family will have multiple keys (or row keys) representing different rows that might also contain this column. This is why moving from the relational model is hard: we think of a relational table as holding the same set of columns for every row. But in Cassandra, a column family holds many rows, each of which may hold the same, or different, sets of columns.
On the server side, columns are immutable in order to prevent
multithreading issues. The column is
defined in Cassandra by the
org.apache.cassandra.db.IColumn interface, which
allows a variety of operations, including getting the value of the column
as a byte array or, in the case of a super column, getting its subcolumns
as a Collection<IColumn> and finding the time of the most
recent change.
In a relational database, rows are stored together. This wasn’t the case for early versions of Cassandra, but as of version 0.6, rows for the same column family are stored together on disk.
Note
You cannot perform joins in Cassandra. If you have designed a data model and find that you need something like a join, you’ll have to either do the work on the client side, or create a denormalized second column family that represents the join results for you. This is common among Cassandra users. Performing joins on the client should be a very rare case; you really want to duplicate (denormalize) the data instead.
Wide Rows, Skinny Rows
When designing a table in a traditional relational database, you’re typically dealing with “entities,” or the set of attributes that describe a particular noun (Hotel, User, Product, etc.). Not much thought is given to the size of the rows themselves, because row size isn’t negotiable once you’ve decided what noun your table represents. However, when you’re working with Cassandra, you actually have a decision to make about the size of your rows: they can be wide or skinny, depending on the number of columns the row contains.
A wide row means a row that has lots and lots (perhaps tens of thousands or even millions) of columns. Typically there is a small number of rows that go along with so many columns. Conversely, you could have something closer to a relational model, where you define a smaller number of columns and use many different rows—that’s the skinny model.
Wide rows typically contain automatically generated names (like UUIDs or timestamps) and are used to store lists of things. Consider a monitoring application as an example: you might have a row that represents a time slice of an hour by using a modified timestamp as a row key, and then store columns representing IP addresses that accessed your application within that interval. You can then create a new row key after an hour elapses.
Skinny rows are slightly more like traditional RDBMS rows, in that each row will contain similar sets of column names. They differ from RDBMS rows, however, because all columns are essentially optional.
Another difference between wide and skinny rows is that only wide rows will typically be concerned about sorting order of column names. Which brings us to the next section.
Column Sorting
Columns have another aspect to their definition. In Cassandra, you
specify how column names will be compared for sort order when results
are returned to the client. Columns are sorted by the “Compare With”
type defined on their enclosing column family, and you can choose from
the following: AsciiType, BytesType,
LexicalUUIDType, IntegerType, LongType,
TimeUUIDType, or UTF8Type.
AsciiTypeThis sorts by directly comparing the bytes, validating that the input can be parsed as US-ASCII. US-ASCII is a character encoding mechanism based on the lexical order of the English alphabet. It defines 128 characters, 94 of which are printable.
BytesTypeThis is the default, and sorts by directly comparing the bytes, skipping the validation step.
BytesTypeis the default for a reason: it provides the correct sorting for most types of data (UTF-8 and ASCII included).LexicalUUIDTypeA 16-byte (128-bit) Universally Unique Identifier (UUID), compared lexically (by byte value).
LongTypeIntegerTypeIntroduced in 0.7, this is faster than
LongTypeand allows integers of both fewer and more bits than the 64 bits provided byLongType.TimeUUIDTypeThis sorts by a 16-byte (128-bit) timestamp. There are five common versions of generating timestamp UUIDs. The scheme Cassandra uses is a version one UUID, which means that it is generated based on conflating the computer’s MAC address and the number of 100-nanosecond intervals since the beginning of the Gregorian calendar.
UTF8TypeA string using UTF-8 as the character encoder. Although this may seem like a good default type, that’s probably because it’s comfortable to programmers who are used to using XML or other data exchange mechanism that requires common encoding. In Cassandra, however, you should use
UTF8Typeonly if you want your data validated.CustomYou can create your own column sorting mechanism if you like. This, like many things in Cassandra, is pluggable. All you have to do is extend the
org.apache.cassandra.db.marshal.AbstractTypeand specify your class name.
Column names are stored in sorted order according to the value of
compare_with. Rows, on the other hand, are stored in an
order defined by the partitioner (for example, with RandomPartitioner, they are in random
order, etc.). We examine partitioners in Chapter 6.
It is not possible in Cassandra to sort by value, as we’re used to doing in relational databases. This may seem like an odd limitation, but Cassandra has to sort by column name in order to allow fetching individual columns from very large rows without pulling the entire row into memory. Performance is an important selling point of Cassandra, and sorting at read time would harm performance.
Note
Column sorting is controllable, but key sorting isn’t; row keys always sort in byte order.
Super Columns
A super column is a special kind of column. Both kinds of columns are name/value pairs, but a regular column stores a byte array value, and the value of a super column is a map of subcolumns (which store byte array values). Note that they store only a map of columns; you cannot define a super column that stores a map of other super columns. So the super column idea goes only one level deep, but it can have an unbounded number of columns.
The basic structure of a super column is its name, which is a byte array (just as with a regular column), and the columns it stores (see Figure 3-6). Its columns are held as a map whose keys are the column names and whose values are the columns.
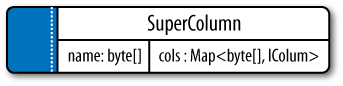
Each column family is stored on disk in its own separate file. So to optimize performance, it’s important to keep columns that you are likely to query together in the same column family, and a super column can be helpful for this.
The SuperColumn class implements both the
IColumn and the
IColumnContainer classes, both from the
org.apache.cassandra.db package. The Thrift API is the
underlying RPC serialization mechanism for performing remote operations on
Cassandra. Because the Thrift API has no notion of inheritance, you will
sometimes see the API refer to a
ColumnOrSupercolumn type; when data structures use
this type, you are expected to know
whether your underlying column family is of type
Super or Standard.
Note
Fun fact: super columns were one of the updates that Facebook added to Google’s Bigtable data model.
Here we see some more of the richness of the data model. When using regular columns, as we saw earlier, Cassandra looks like a four-dimensional hashtable. But for super columns, it becomes more like a five-dimensional hash:
[Keyspace][ColumnFamily][Key][SuperColumn][SubColumn]
To use a super column, you define your column family as type
Super. Then, you still have row keys as you do in a regular
column family, but you also reference the super column, which is simply a
name that points to a list or map of regular columns (sometimes called the
subcolumns).
Here is an example of a super column family definition called
PointOfInterest. In the hotelier domain, a “point of
interest” is a location near a hotel that travelers might like to visit,
such as a park, museum, zoo, or tourist attraction:
PointOfInterest (SCF)
SCkey: Cambria Suites Hayden
{
key: Phoenix Zoo
{
phone: 480-555-9999,
desc: They have animals here.
},
key: Spring Training
{
phone: 623-333-3333,
desc: Fun for baseball fans.
},
}, //end of Cambria row
SCkey: (UTF8) Waldorf=Astoria
{
key: Central Park
desc: Walk around. It's pretty.
},
key: Empire State Building
{
phone: 212-777-7777,
desc: Great view from the 102nd floor.
}
}
}The PointOfInterest super column family has two super
columns, each named for a different hotel (Cambria Suites Hayden and
Waldorf=Astoria). The row keys are names of different points of interest,
such as “Phoenix Zoo” and “Central Park”. Each row has columns for a
description (the “desc” column); some of the rows have a phone number, and
some don’t. Unlike relational tables, which group rows of identical
structure, column families and super column families group merely
similar records.
Using the CLI, we could query a super column family like this:
cassandra> get PointOfInterest['Central Park']['The Waldorf=Astoria']['desc'] => (column=desc, value=Walk around in the park. It's pretty., timestamp=1281301988847)
This query is asking: in the PointOfInterest column
family (which happens to be defined as type Super), use the
row key “Central Park”; for the super column named “Waldorf=Astoria”, get
me the value of the “desc” column (which is the plain language text
describing the point of interest).
Composite Keys
There is an important consideration when modeling with super columns: Cassandra does not index subcolumns, so when you load a super column into memory, all of its columns are loaded as well.
Note
This limitation was discovered by Ryan King, the Cassandra lead at Twitter. It might be fixed in a future release, but the change is pending an update to the underlying storage file (the SSTable).
You can use a composite key of your own design to help you with
queries. A composite key might be something like
<userid:lastupdate>.
This could just be something that you consider when modeling, and then check back on later when you come to a hardware sizing exercise. But if your data model anticipates more than several thousand subcolumns, you might want to take a different approach and not use super columns. The alternative involves creating a composite key. Instead of representing columns within a super column, the composite key approach means that you use a regular column family with regular columns, and then employ a custom delimiter in your key name and parse it on client retrieval.
Here’s an example of a composite key pattern, used in combination with an example of a Cassandra design pattern I call Materialized View, as well as a common Cassandra design pattern I call Valueless Column:
HotelByCity (CF) Key: city:state {
key: Phoenix:AZ {AZC_043: -, AZS_011: -}
key: San Francisco:CA {CAS_021: -}
key: New York:NY {NYN_042: -}
}There are three things happening here. First, we already have
defined hotel information in another column family called
Hotel. But we can create a second column family called
HotelByCity that denormalizes the hotel data. We repeat the
same information we already have,
but store it in a way that acts similarly to a view in RDBMS, because it
allows us a quick and direct way to write queries. When we know that
we’re going to look up hotels by city (because that’s how people tend to
search for them), we can create a table that defines a row key for that
search. However, there are many states that have cities with the same
name (Springfield comes to mind), so we can’t just name the row key
after the city; we need to combine it with the state.
We then use another pattern called Valueless Column. All we need to know is what hotels are in the city, and we don’t need to denormalize further. So we use the column’s name as the value, and the column has no corresponding value. That is, when the column is inserted, we just store an empty byte array with it.
Design Differences Between RDBMS and Cassandra
There are several differences between Cassandra’s model and query methods compared to what’s available in RDBMS, and these are important to keep in mind.
No Query Language
SQL is the standard query language used in relational databases. Cassandra has no query language. It does have an API that you access through its RPC serialization mechanism, Thrift.
No Referential Integrity
Cassandra has no concept of referential integrity, and therefore has no concept of joins. In a relational database, you could specify foreign keys in a table to reference the primary key of a record in another table. But Cassandra does not enforce this. It is still a common design requirement to store IDs related to other entities in your tables, but operations such as cascading deletes are not available.
Secondary Indexes
Here’s why secondary indexes are a feature: say that you want to find the unique ID for a hotel property. In a relational database, you might use a query like this:
SELECT hotelID FROM Hotel WHERE name = 'Clarion Midtown';
This is the query you’d have to use if you knew the name of the
hotel you were looking for but not the unique ID. When handed a query
like this, a relational database will perform a full table scan,
inspecting each row’s name column to find the value you’re looking for.
But this can become very slow once your table grows very large. So the
relational answer to this is to create an index on the name
column, which acts as a copy of the data that the relational database
can look up very quickly. Because the hotelID is already a
unique primary key constraint, it is automatically indexed, and that is
the primary index; for us to create another index on the name column
would constitute a secondary index, and Cassandra does not currently
support this.
To achieve the same thing in Cassandra, you create a second column family that holds the lookup data. You create one column family to store the hotel names, and map them to their IDs. The second column family acts as an explicit secondary index.
Note
Support for secondary indexes is currently being added to Cassandra 0.7. This allows you to create indexes on column values. So, if you want to see all the users who live in a given city, for example, secondary index support will save you from doing it from scratch.
Sorting Is a Design Decision
In RDBMS, you can easily change the order in which records are
returned to you by using ORDER BY in your query. The
default sort order is not configurable; by default, records are returned
in the order in which they are written. If you want to change the order,
you just modify your query, and you can sort by any list of columns. In
Cassandra, however, sorting is treated differently; it is a design
decision. Column family definitions include a
CompareWith element, which dictates the order in which your
rows will be sorted on reads, but this is not configurable per
query.
Where RDBMS constrains you to sorting based on the data type
stored in the column, Cassandra only stores byte arrays, so that
approach doesn’t make sense. What you can do, however, is sort as if the
column were one of several different types (ASCII,
Long integer, TimestampUUID,
lexicographically, etc.). You can also use your own pluggable comparator
for sorting if you wish.
Otherwise, there is no support for ORDER BY and
GROUP BY statements in Cassandra as there is in SQL. There is a query type
called a SliceRange, which we examine in Chapter 4; it is similar to ORDER BY in
that it allows a reversal.
Denormalization
In relational database design, we are often taught the importance of normalization. This is not an advantage when working with Cassandra because it performs best when the data model is denormalized. It is often the case that companies end up denormalizing data in a relational database. There are two common reasons for this. One is performance. Companies simply can’t get the performance they need when they have to do so many joins on years’ worth of data, so they denormalize along the lines of known queries. This ends up working, but goes against the grain of how relational databases are intended to be designed, and ultimately makes one question whether using a relational database is the best approach in these circumstances.
A second reason that relational databases get denormalized on purpose is a business document structure that requires retention. That is, you have an enclosing table that refers to a lot of external tables whose data could change over time, but you need to preserve the enclosing document as a snapshot in history. The common example here is with invoices. You already have Customer and Product tables, and you’d think that you could just make an invoice that refers to those tables. But this should never be done in practice. Customer or price information could change, and then you would lose the integrity of the Invoice document as it was on the invoice date, which could violate audits, reports, or laws, and cause other problems.
In the relational world, denormalization violates Codd’s normal forms, and we try to avoid it. But in Cassandra, denormalization is, well, perfectly normal. It’s not required if your data model is simple. But don’t be afraid of it.
The important point is that instead of modeling the data first and then writing queries, with Cassandra you model the queries and let the data be organized around them. Think of the most common query paths your application will use, and then create the column families that you need to support them.
Detractors have suggested that this is a problem. But it is perfectly reasonable to expect that you should think hard about the queries in your application, just as you would, presumably, think hard about your relational domain. You may get it wrong, and then you’ll have problems in either world. Or your query needs might change over time, and then you’ll have to work to update your data set. But this is no different from defining the wrong tables, or needing additional tables, in RDBMS.
Note
For an interesting article on how Cloudkick is using Cassandra to store metrics and monitoring data, see https://www.cloudkick.com/blog/2010/mar/02/4_months_with_cassandra.
Design Patterns
There are a few ways that people commonly use Cassandra that might be described as design patterns. I’ve given names to these common patterns: Materialized View, Valueless Column, and Aggregate Key.
Materialized View
It is common to create a secondary index that represents
additional queries. Because you don’t have a SQL WHERE
clause, you can recreate this effect by writing your data to a second
column family that is created specifically to represent that
query.
For example, if you have a User column family and you
want to find users in a particular
city, you might create a second column family called
UserCity that stores user data with the city as keys
(instead of the username) and that has columns named for the users who
live in that city. This is a denormalization technique that will speed
queries and is an example of specifically designing your data around
your queries (and not the other way around). This usage is common in the
Cassandra world. When you want to query for users in a city, you just
query the UserCity column family, instead of querying the
User column family and doing a bunch of pruning work on the
client across a potentially large data set.
Note that in this context, “materialized” means storing a full copy of the original data so that everything you need to answer a query is right there, without forcing you to look up the original data. If you are performing a second query because you’re only storing column names that you use, like foreign keys in the second column family, that’s a secondary index.
Note
As of 0.7, Cassandra has native support for secondary indexes.
Valueless Column
Let’s build on our User/UserCity
example. Because we’re storing the reference data in the
User column family, two things arise: one, you need to have
unique and thoughtful keys that can enforce referential integrity; and
two, the columns in the UserCity column family don’t necessarily need
values. If you have a row key of Boise, then the column names can be the
names of the users in that city. Because your reference data is in the
User column family, the columns don’t really have any
meaningful value; you’re just using it as a prefabricated list, but
you’ll likely want to use values in that list to get additional data
from the reference column family.
Aggregate Key
When you use the Valueless Column pattern, you may also need to
employ the Aggregate Key pattern.
This pattern fuses together two scalar values with a separator to create
an aggregate. To extend our example further, city names typically aren’t
unique; many states in the US have a city called Springfield, and
there’s a Paris, Texas, and a Paris, Tennessee. So what will work better
here is to fuse together the state name and the city name to create an
Aggregate Key to use in our Materialized View. This key would look
something like: TX:Paris or TN:Paris. By
convention, many Cassandra users employ the colon as the separator, but
it could be a pipe character or any other character that is not
otherwise meaningful in your keys.
Some Things to Keep in Mind
Let’s look briefly at a few things to keep in mind when you’re trying to move from a relational mindset to Cassandra’s data model. I’ll just say it: if you have been working with relational databases for a long time, it’s not always easy. Here are a few pointers:
Start with your queries. Ask what queries your application will need, and model the data around that instead of modeling the data first, as you would in the relational world. This can be shocking to some people. Some very smart people have told me that this approach will cause trouble for the Cassandra practitioner down the line when new queries come up, as they tend to in business. Fair enough. My response is to ask why they assume their data types would be more static than their queries.
You have to supply a timestamp (or clock) with each query, so you need a strategy to synchronize those with multiple clients. This is crucial in order for Cassandra to use the timestamps to determine the most recent write value. One good strategy here is the use of a Network Time Protocol (NTP) server. Again, some smart people have asked me, why not let the server take care of the clock? My response is that in a symmetrical distributed database, the server side actually has the same problem.
Summary
In this chapter we took a gentle approach to understanding Cassandra’s data model of keyspaces, column families, columns, and super columns. We also explored a few of the contrasts between RDBMS and Cassandra.