
Appendix A. The Nonrelational Landscape
Cassandra is one of many new nonrelational database projects that have sprung up recently, and in order to understand their goals and the designs that have been shaped by those goals, it may prove useful to take a step back and understand what these different projects are about.
Note
We’ve lately become familiar with the term “NoSQL” to describe a set of databases that don’t use SQL. I have been using the term “nonrelational” in acknowledgment that these databases are frequently grouped together in the popular imagination. But part of the point of this appendix is to illustrate that we probably should stop talking this way. It is specious to compare NoSQL databases to relational databases; as you’ll see, none of the so-called “NoSQL” databases have the same implementation, goals, features, advantages, and disadvantages. So comparing “NoSQL” to “relational” is really a shell game.
So in this appendix we review a variety of popular nonrelational databases. Cassandra does certain things very, very well. It does other things less well. So my aim here is to help you understand Cassandra’s place in the constellation of competing nonrelational databases so that you are best armed to make the right choice of database for your needs. If you already know that you want to employ Cassandra, this survey should still prove useful in understanding some of the design decisions and trade-offs made in Cassandra.
Nonrelational Databases
Of course the world is full of popular databases that have never employed anything like a relational model. These include object databases, XML native databases, document-oriented databases, graph databases, and key-value stores. Some of these represent products that have been around for many years, and some are just starting to see production use. I examine a few of these nonrelational databases here.
Note
There are several other nonrelational databases that I don’t discuss, generally because they are less popular, are specialized projects, or are not yet very far along in their implementation and production use. One of these is the “semi-relational” database Drizzle, which is based on MySQL. Microsoft’s cloud database platform based on SQL Server is called SQL Server Data Services (SDS). Yahoo!’s PNUTS is definitely worth taking a look at. You can read the PNUTS paper at http://research.yahoo.com/files/pnuts.pdf. For a more comprehensive list, visit Alex Popescu’s wonderful site MyNoSQL at http://nosql.mypopescu.com.
You might be reading this book because you have already selected Cassandra for a database project. But perhaps you’ve simply heard of its use at popular web properties such as Twitter and Facebook and want to gain a better understanding of what it is. If that’s the case, it may prove helpful to understand some of the competing products so you can see what they emphasize, where they differ, and how Cassandra compares in this context.
So let’s take a brief look at some of these alternatives to help you see how they differ from what you might already be familiar with. I have tried to characterize each database in terms of the same general categories in order to make the comparison clear.
In general, these databases are distributed, which means that their design allows for more than one node of the database that contains copies of the data, and they handle the replication automatically for you. (There are some exceptions, however, such as Amazon’s SimpleDB.) They have a variety of features to help handle massive scale, which is important for many new web applications.
On the negative side, however, what these databases generally share is a lack of great tooling and framework support. Many of the solutions here are new, which means that the developers are focusing on the core product and that you’ll have to forego, at least for the time being, tools such as graphical consoles, which we’ve become used to in the RDBMS world. To employ any of these solutions, including Cassandra, you’ll need to feel comfortable working with a command-line interface, simple shell tools, and getting your hands dirty with some plumbing. Because many of these databases are becoming more popular and widely understood, you can expect such conveniences to be available in the near future.
Object Databases
The purpose of an object database is to avoid the object-relational impedance mismatch that occurs when trying to use a relational database under an application written in an object-oriented programming language. Object databases store data not in terms of relations and columns and rows, but in terms of the objects themselves, making it straightforward to use the database from an object-oriented application. This allows you to avoid writing extensive SQL code or stored procedures to map from application objects to database tables and avoid having to use an object-relational mapping (ORM) layer. ORM layers can be cumbersome, add complexity to your overall application, and slow down data operations.
Because you don’t have to translate data from application objects into the relational model, applications with object databases can be very fast. You also don’t need relational keys to help you join data to fulfill queries, because data is findable in the database as it is in your application: by following pointers.
Object databases have been with us since the mid-1970s and 1980s. They never really caught on for widespread business application use, but have found some success in niche areas such as computer-aided design (CAD) applications, spatial applications, telecommunications, and embedded systems.
InterSystems’ object database Caché is probably the best known commercial product, though Persistent Objects and Extended database Technology (POET), which is now the Versant Object Database, is also used for Java, .NET, and C++ applications.
There are some disadvantages to using object-oriented (OO) databases. Although there is often a performance boost to be realized from using an OO database, typically it also tightly couples your data store to your application, but the trade-off may be worth it, depending on your needs. Also, object databases typically will only deserialize objects into the same programming language used to serialize them, which can severely limit your architecture’s flexibility by introducing even tighter coupling.
In recent years, there has been less interest and movement in object databases than the other types of data stores discussed here, so I won’t go into more detail.
XML Databases
XML databases are a special form of document databases, optimized specifically for working with XML. The first working draft of XML was developed in 1996, and version 1.0 was published as a W3C standard in February of 1998. XML quickly enjoyed widespread use, as web applications found it expressive and easy to use as a transfer format across a wide variety of languages. So-called “XML native” databases soon sprang up, one of the first being Tamino from Software AG. They are now employed in a variety of use cases, such as content management and supply chain systems, document management, publishing, and support of SOA initiatives.
XML databases have proven useful in part because they allow developers to work with XML using specifications aimed at XML documents. Working directly with XML in the data tier can be a relief to developers facing the notorious “impedance mismatch” between object-oriented application languages and relational databases.
XML databases have one core function: to allow you to store and query XML documents. Although they are often not stored directly in their “native” format, developers can work with the documents using APIs as if they were. These include:
Use of XML-friendly query mechanisms such as XPath and XQuery. XPath is the mechanism to address the variety of data items in a document, such as elements and attributes. XQuery affords a robust querying mechanism in the form of FLOWR queries (so named because they allow you to use statements such as “For”, “Let”, “Where”, “Order,” and “Return”).
Performance improvements when you’re using XML directly within your application. Some applications that work with XML will map these documents to a relational database, but there are a variety of advantages to skipping this step and using an XML database instead. For example, XML documents typically represent hierarchical data structures, which may map poorly to a relational model.
Flexibility for accessing your data. XML databases frequently allow you to work with data in DOM, JDOM, SAX APIs, and SOAP. Each of these has its own strengths, and you’re not limited to the single query mechanism of SQL.
Responsive full-text searches.
Features that are familiar from working with relational databases, such as joins across document collections, user-defined functions, search support for metadata as well as data, and more.
Flexible use of XML throughout the stack, such as when using XForms in the presentation tier.
Other features, such as storage of non-XML documents (for example, full plain-text [unstructured] documents).
If you’re not familiar with XPath as a means to find data in an XML document, consider the following example XML document:
<catalog>
<plays>
<play name='Hamlet'><price>5.95</price></play>
<play name='King Lear'><price>6.95</price></play>
</plays>
</catalog>Given this XML document, the following XPath expression will give us
the value “6.95”, which is the result of navigating to the value of the
price element inside the play element whose value for the name attribute
is “King Lear”:
//catalog/plays/play/[@name='King Lear']/price
There are a variety of XML databases in open source projects and commercial offerings. They typically employ one of two data storage mechanisms: text-based or model-based. Text-based XML databases typically will store their data as large text files, character large objects (CLOBs), or even as a binary large object (BLOB) in an underlying relational database, performing the translation for you. Model-based XML databases don’t directly store the text of the XML document; instead, they parse documents into an internal proprietary object model that appears to the developer as an XML document. Often this boils down to breaking down the various parts of an XML document (elements, attributes, etc.) and storing them as fragments within a relational database.
The following sections offer a quick overview of some of the popular XML databases.
SoftwareAG Tamino
Tamino was one of the earliest XML-native databases. It’s a mature commercial offering that supports a wide variety of the kinds of functions you’d expect in an “enterprise-ready” database, such as high availability.
eXist
The eXist XML database started as a personal project of Wolfgang Meier in 2000 and continues to be actively developed today. It is an open source XML database written in Java. It features rich support for XPath and XQuery, as well as XInclude, WebDAV (Distributed Authoring and Versioning), XML Access Control Markup Language (XACML) for security, SOAP, REST, and XML-RPC. It also comes with an easy-to-use, web-based console to execute queries.
Oracle Berkeley XML DB
Berkeley XML DB is an open source database written in Java that started as a research project at Harvard and is now supported by Oracle. Berkeley XML DB is embeddable, so it can run as a JAR within your application. It supports C++, Java, XQuery, high availability, and transactions. The Berkeley database is specifically geared toward developers rather than DBAs, as the only way to interact with the database is to write code; it has no standalone server and no graphical tool such as SQL Server Management Studio. You can use Berkeley XML DB to store a mixture of XML documents and less-structured documents.
MarkLogic Server
MarkLogic is a server backed by an XML database that supports XQuery for Create, Read, Update, and Delete (CRUD) operations; full-text searching; XML searching; and transactions. It supports REST using XML or JavaScript Object Notation (JSON). Although MarkLogic is a commercial product, there is a free community license available for small projects and nonprofit organizations.
Apache Xindice
The Apache Xindice project was one of the early XML databases, with work beginning in 2001. It was designed for working only with small and medium-sized documents. Since its last release—version 1.1—in 2007, it has not been actively maintained, and version 1.2 has been a work in progress for years now.
Summary
There are many other XML databases, including TigerLogic, MonetDB, Sedna, and more. The importance of XML databases in this context is that some of this work serves as a predecessor to the more recent document-oriented databases, which we explore in a moment. More to the point, however, is that these databases highlight some of the advantages that can be realized by considering how your database maps to the specific needs of your application architecture, rather than simply assuming that a relational database is a one-size-fits-all solution.
Of course, if you are storing only small XML documents and your application doesn’t require document collections, then you are not likely to find any performance benefit in an XML database.
Document-Oriented Databases
In a relational database, data is stored in terms of tables, requiring data that might otherwise be repeated to be “broken apart” in order to use relational keys. You then can employ complex queries written to pull your relational data back together for a single query result that captures the data in a two-dimensional grid of rows and columns.
There are several advantages to document-oriented databases in general:
The basic unit of storage in a document database is a complete document itself. A document can store any number of fields of any length, and each field can store multiple values. This differs from a relational database, which requires all fields to be present for every record.
In a document-oriented database, you don’t need to store “empty” fields for which you have no data, as is required in RDBMS. This can save space in the database.
They are very free-form in that they do not require a schema.
Security can be assigned at the individual document level.
They typically include full-text search capabilities. This is sometimes provided as a special feature of RDBMS and is common in XML databases.
So what is meant by a “document”? It could be text, written and stored as JSON (see ); it could be XML, though there is a separate discussion around that specialized form of document database; it could be a YAML document (most JSON documents can be parsed by a YAML parser); and it could also be a different format, as there are a variety of alternatives. The technical implementations from one document database to another are not the same. For instance, CouchDB stores data as JSON, and Lotus Notes, which has been around much longer, uses its own internal format.
You can think of document-oriented databases as collections of key-value collections, making them a kind of predecessor to the key-value stores discussed later in Key-Value Stores and Distributed Hashtables. Although that’s easy to envision, consider a JSON document such as the one shown here:
{
"title": "I Heart LolCatz",
"author: "Inigo Montoya",
"ts": Date("31-Dec-99 11:59"),
"comments": [{
"author": "Robert Zimmerman",
"comment: "I'm just a song and dance man"}, {
"author": "Rogers Nelson",
"comment: "I'm just a song and dance man"}
]
}Consider the tables that might be required to represent even this very simple data structure in a relational database and what the queries might look like. With a document-oriented database, you store exactly that document, and queries are simple one-liners.
IBM Lotus
Lotus, first released in 1989, was perhaps the inspiration for all the other kinds of document-oriented databases, such as CouchDB and MongoDB. Lotus represents a family of products for collaboration, including Lotus Notes and Domino for email, discussion, and calendar; Lotus Sametime for messaging; and others.
Website: http://www.ibm.com/software/lotus
Orientation: Document
Created: Lotus was first released in 1989. The most recent version as of this writing is version 8.5, released in March 2010.
Schema: There is no required schema. Documents (“notes”) are stored in a native format called a Notes Storage File (NSF), but can be thought of for modeling purposes as JSON documents.
Client: The most recent versions of the Lotus client for end users have been created around Eclipse. To interact with a Domino database, you can access APIs provided in C, C++, or Java. Notes databases are not relational, but you can use a SQL driver with them, and the Domino XML Language provides XML views of all data so you can use these processing tools.
CAP: Lotus can be clustered and performs replication.
Production use: Lotus is used as an end-user collaboration tool throughout many enterprises.
Apache CouchDB
As a database, CouchDB is perhaps most similar to Lotus Notes. This is not entirely surprising, as its creator, Damien Katz, worked on Lotus Notes at IBM before deciding to embark on this project, with the idea that it would be a database ”of the Web.” The documents stored by CouchDB do not need to share the same schema, and query capabilities are made available via views, which are constructed as JavaScript functions.
CouchDB is interesting in part for what it terms Multi-Version Concurrency Control (MVCC). MVCC means that readers will not block writers and writers will not block readers. In order to support this, all writes occur as appends to the document store, making it much harder to corrupt datafiles. This implementation is somewhat similar to Cassandra; using an append-only model means that files can grow very large very quickly, requiring a background process to run compactions.
Note
If you’d like to read more about CouchDB, check out the O’Reilly book CouchDB: The Definitive Guide, by J. Chris Anderson, Jan Lehnardt, and Noah Slater.
Website: http://couchdb.apache.org
Orientation: Document
Created: Work was begun in 2005. In 2008, it became an Apache Incubator project.
Implementation language: Erlang
Distributed: Yes. Data can be read and updated by users and the server while disconnected, and any changes can then be replicated bidirectionally later.
Schema: There is no required schema. Documents are stored in their entirety using JSON. Each document is assigned a unique ID.
Client: RESTful JSON API that allows access from any language capable of making HTTP requests.
CAP: Eventually consistent. Replication is used to synchronize multiple copies of data on different nodes. CouchDB features ACID semantics similar to many relational database systems.
Production use: CouchDB is not yet in a 1.0 release as of this writing, but it is used in production in a variety of social websites and software applications. See http://bit.ly/dn73DY for a list of specific production instances.
Additional features: MapReduce, incremental replication, and fault-tolerance are all supported. Comes with a web console.
MongoDB
MongoDB is perhaps most similar to CouchDB. It purports to combine the best of key-value stores, document databases, object databases, and RDBMS. That is, it shards automatically as with a key-value store, allows JSON-based dynamic schema documents, and offers a rich query language in the manner of a relational database.
Note
If you’d like to read more about MongoDB, check out the O’Reilly book MongoDB: The Definitive Guide, by Kristina Chodorow and Michael Dirolf.
Website: http://www.mongodb.org
Orientation: Document
Created: Developed at 10gen by Geir Magnusson and Dwight Merriman
Implementation language: C++
Distributed: Yes
Schema: JSON-style documents are stored, and you can use dynamic schemas.
CAP: MongoDB uses a single master for any shard, making it completely consistent.
Production use: MongoDB is used in production at SourceForge, Bit.ly, Foursquare, GitHub, Shutterfly, Evite, The New York Times, Etsy, and many more.
Additional features: MapReduce is supported. There’s a very neat web interface that lets you try MongoDB in your browser using a JavaScript shell. Check it out at http://try.mongodb.org.
Riak
Riak is a hybrid database based on Amazon Dynamo that acts as a document-oriented database and also a distributed key-value store. It’s fault-tolerant and scales linearly, and it’s intended for use in web applications. It is similar to Cassandra in that it does not have a central controller, and therefore no single point of failure.
The design of Riak includes three basic elements: buckets, keys, and values. Data is organized into buckets, which are little more than flat namespaces for logically grouping key-value pairs. This much is similar in design and terminology to the Google Storage system.
Basho Technologies, the maker of Riak, offers both a commercial version and an open source version.
Riak runs on most Unix-based systems, but is not supported on Windows.
Website: http://wiki.basho.com
Orientation: Document and key-value store
Created: Basho Technologies in Cambridge, Massachusetts. This company was formed in 2008 by architects from Akamai.
Implementation language: Primarily Erlang, with some C and JavaScript
Distributed: Yes
Replication: Replication can be set at the bucket level.
Schema: Riak is schema-less and doesn’t use specific data types. The values associated with keys are objects. All data is stored as opaque BLOBs, so you can store just about any kind of data in Riak.
Client: Riak offers three primary ways of interacting with it: via a JSON over HTTP interface; drivers for Erlang, Python, Java, PHP, JavaScript, and Ruby; and, finally, a Protocol Buffers client interface. Protocol Buffers is a Google project that they use internally for very fast RPC, and is available at http://code.google.com/p/protobuf/.
CAP: Riak is similar to Cassandra in that the database allows for “tuneability” for desired levels of consistency, availability, and partition tolerance.
Production use: Customers include Comcast and Mochi Media.
Additional features: Easy integration with MapReduce/Hadoop. The commercial version, called Enterprise DS, also supports replication across data centers (the open source version supports replication only within a single data center), a web console, and Simple Network Management Protocol (SNMP) support.
Graph Databases
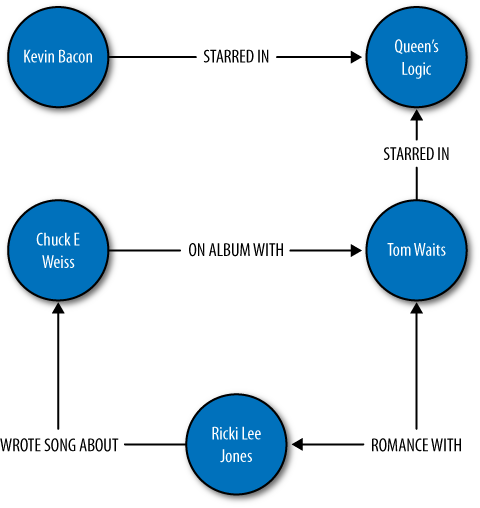
Graph databases present another alternative to the relational data model. You can think of a graph as a network. Instead of storing data in tables or columns, graph databases use three basic constructs to represent data: nodes, edges, and properties. In the graph database world, a node is a standalone, independent object that doesn’t depend on anything else. An edge is an object that depends on the existence of two nodes. Properties are straightforward: they’re the attributes of a node. For example, a person node might have a name property and an email property. Both nodes and edges can have associated properties.
Figure A-1 shows a graph database with five nodes and five edges. The edges describe a variety of relationships, but in this example, each has only a single property of the edge name. We can see that one of the edges is bidirectional. Each node in this example has a single property (“name”), but they could all have a variety of additional properties. One nice thing about a graph database is that it’s “whiteboard friendly”; that is, the data model looks like how we often think when mapping things out at the whiteboard, and we don’t need additional translation steps to make the data fit our database’s constraints.
Graph databases differ from other nonrelational offerings such as key-value stores in that they represent the edges as first-class citizens, and not just the nodes. That is to say that whereas many programming languages and databases we’re used to allow us to infer a relationship, the relationship itself is only indirectly represented (say, via a foreign key relation or a pointer). In graph databases, the relationships are given equal status with the nodes, as the relationship between the nodes is considered central to certain use cases. For example, graph databases have become more popular in recent years because they readily map to the social web domain and perform very well for the kinds of queries required in Web 2.0 social networking applications, where the relationships are really the point of the whole endeavor. A second important and growing use case for graph databases is the Semantic Web, where predicates are given equal status to subjects and objects in a triple.
Two key trends over the last 15 years have precipitated the rise of graph databases as an important form of data store. The first is a rise in the sheer volume of data, and the second is a rise in the interconnectedness of that data; both of these trends make graph databases an attractive choice.
Consider for example the rough time line shown in Figure A-2. Starting in the early 1990s, text documents and basic linked hypermedia represented the bulk of content on the Web. Such documents were straightforward to store and easy to generate using relational databases. Then, in the early part of this century, RSS feeds, blogs, and wikis started cropping up, adding automation and linking of reference data in new ways that stretched the relational model. As 2005 gave rise to the idea of Web 2.0 (or the Age of Participation, as it was termed by Jonathan Schwartz at Sun), we began to see folksonomies, tag clouds, and taxonomies, all optimized for machine consumption and inference as much as for direct human consumption. We started to shift away from thinking of the Web as a bunch of “pages” like those in a magazine whose content can be dynamically generated by pulling together entries in a relational database; we started thinking instead in terms of ways to represent that data so that it can be linked in terms of the ideas represented. The large-scale availability of the high-speed Internet infrastructure allowed social networking sites to blossom. Many more people were suddenly connected, and the Web was offering new ways for them to interact, rather than just read.
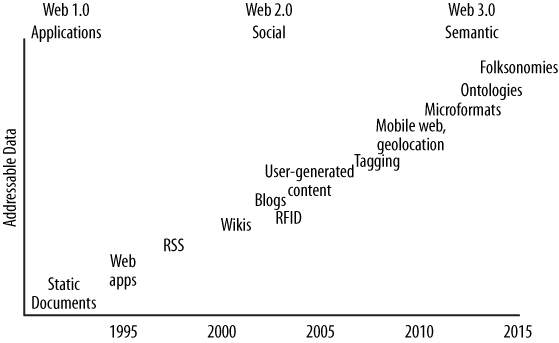
It is at this point where the Web starts to employ that important second layer of semantics, accompanied by the explosion in volume of data, and where the largest web properties are forced to start looking at alternatives to the relational database. Some semantic web researchers and enthusiasts have recently suggested that we are entering a new era, Web 3.0, where RDF, microformats, and ontologies will support a super-connected “web of data” culminating in a gigantic graph of the world’s knowledge base some years from now. As such, the usefulness of graph databases, which directly support the idea of a semantic relationship between two nodes, becomes more immediately apparent.
Like many document-oriented databases, graph databases typically allow for free-form schemas, allowing your application to evolve easily as your data set grows and changes. Because there is no relational model, joins are not necessary, which can offer more efficient queries as your data set grows.
The primary advantage of a graph database over RDBMS is that there’s no impedance mismatch; you can store your objects just as you would use them in your application and just as you would draw them on a whiteboard, which makes for straightforward, readily understandable, and quick modeling. As with key-value stores and document-oriented databases, graph databases allow you to represent semistructured data and naturally evolve your schemas according to newfound relationships and properties.
If you’re interested in exploring graph databases for a social web or Semantic Web application, you might want to check out the variety of other graph databases not explored here, including Dex, HypergraphDB, Infogrid, and VertexDB. I encourage you also to take a look at the Gremlin project at http://wiki.github.com/tinkerpop/gremlin. Gremlin is an open source programming language designed specifically for performing queries, graph analysis, and manipulation in graph databases. Gremlin can be invoked from a Java Virtual Machine via its implementation in accordance with JSR 223.
We look at only a couple of graph databases here, but if you’re a regular Hadoop user you might also check out the Hama project, which is in Incubator status as of this writing. Hama is a package on top of Hadoop that adds support for massive matrix and graph data. See http://incubator.apache.org/hama. There is also a Google project called Pregel, which they’ve been using internally for a couple of years and which they might open source. You can read Google’s announcement on Pregel at http://googleresearch.blogspot.com/2009/06/large-scale-graph-computing-at-google.html.
FlockDB
In April 2010, Twitter announced that they were open-sourcing to GitHub their new graph database called FlockDB. They created FlockDB to store the adjacency lists for followers on Twitter, so they could readily understand who follows whom and who blocks whom. It scales horizontally and is designed for online, low-latency, high-throughput environments. The Twitter FlockDB cluster stores 13+ billion edges and sustains peak traffic of 20,000 writes per second and 100,000 reads per second.
Website: http://github.com/twitter/flockdb
Orientation: Graph
Created: Created in 2010 by Twitter
Implementation language: Scala
License: Apache License v2
Distributed: Yes
Schema: The schema is very straightforward, as FlockDB does not attempt to solve every database problem, but only those relating to the set of problems Twitter faces with their relationship graphs and the size of their dataset. The graph contains entries with four attributes: a source ID, a destination ID, a position, and a state.
Client: FlockDB uses the Thrift 0.2 client, and Twitter has also written a Ruby frontend that offers a richer interface.
Replication: Yes
Storage: MySQL
Production use: Twitter
Additional features: FlockDB allows you to quickly page through result sets that contain millions of entries and to archive and later restore previously archived graph edges. It uses Kestrel as a loosely coupled, reliable message queue that picks a server at random to write to, so there is no cross-server communication (no clustering, no multicast, etc.).
Neo4J
Neo4J is an ACID-compliant graph database optimized for very fast graph traversals. It’s transactional, supporting JTA/JTS, two-phase commit, deadlock detection, and MVCC. It has been in production use since 2003, making it one of the older data stores presented here, and is capable of scaling to billions of entities (nodes, edges, properties) in a single JVM.
Neo4J can be embedded as a small JAR file, so it’s easy to get up and running and use in a flexible way in your applications.
Website: http://neo4j.org
Orientation: Graph
Created: Created and used in production since 2003 by Neo Technologies. Version 1.0 was released in February 2010.
Implementation language: Java
License: Apache GPLv3, with commercial licensing available for advanced features.
Distributed: Neo4J is partially distributed using RMI. Note that the free version of Neo4J is not distributable to multiple machines.
Schema: Schema-less graph of nodes, edges, and optional properties
Client: There are a few options here. You can run Neo4J as a REST server so that you can use simple HTTP operations with JSON; Neo4J has a shell client interface as well. There are language bindings available for Java, Python, Ruby, Clojure, Scala, and PHP. See Neo4j.py for the Jython and CPython interfaces, and Neo4jrb for the JRuby bindings. Neoclipse is a plug-in to the Eclipse IDE that offers a graphical representation of your graph and an interface with Grails.
Replication: As of this writing, Neo4J replication is still in the works. It uses a master/slave replication design based on the one used in MySQL, where you can write to any slave instance, and lock coordination and change distribution are handled by the master. You can tune the consistency level desired, so you can achieve strong consistency by having Neo4J write synchronously to the write master and slave, or you can improve performance using eventual consistency by propagating writes to slaves asynchronously.
Storage: Custom disk-based storage
Production use: Box.net, ThoughtWorks
Additional features: Because it is a graph database, Neo4J can be used to good advantage with semantic web applications. It allows you to execute SPARQL Protocol and RDF Query Language (SPARQL) queries for interacting with Resource Description Framework (RDF) and acts as a partial Web Ontology Language (OWL) store.
Integration with Apache Lucene/Solr is available to store external indexes and perform fast global searches. An index in distributed databases can be thought of like a dictionary—a direct pointer from a key to a value.
Key-Value Stores and Distributed Hashtables
In a relational model, we tend to first consider the tables that our domain requires, then think of how we can normalize the tables to avoid duplicate data. The tables with their defined columns and the relationships between the tables become our schema.
In a key-value store, however, typically you don’t define a schema as such. Your domain rather becomes a bucket into which you can drop data items; the data items are keys that have a set of attributes. All data relevant to that key is therefore stored with the key, resulting in a sharp contrast to the normalized model prized in relational databases: data is frequently duplicated. There are some variations here, though, and some conceptual overlap results with the columnar databases.
Another contrast is one of modeling. When working with relational databases, we tend to think hard about the schema, trusting that any question we want to ask the database will be answerable. Because the questions—the queries—are secondary in this model, they can become very complex. You’ve surely seen elaborate SQL statements that use several joins, subqueries, aggregate functions, temporary tables, and so forth. In the columnar model, however, we tend to think of the query first, and the queries we’ll execute help dictate the design of the buckets we’ll need. The assumption in columnar databases that supports this is that we want replication in order for the database to be available, and that data duplication is OK because disk space is inexpensive.
Data integrity is another point of difference. Data integrity is the extent to which the data in an application is complete and consistent. Relational databases have some built-in capabilities to help ensure data integrity, such as primary keys (which ensure entity integrity) and foreign key constraints (which ensure referential integrity). In a key-value store, however, the responsibility for data integrity resides entirely with the application.
Consider an example: your database might include Customers and Orders. In a relational database, referential keys must be defined in the database to allow you to join these tables and see, for example, all the orders a particular customer has placed. Although you could do this in a key-value store, typically you don’t define any relationships in the data model itself; your application is responsible for maintaining data integrity if, for example, you decide to delete a customer record.
One criticism of key-value stores is that they are terrific if you need to scale to billions of records, but that this use case is a concern only for very large, social-based web properties. The suggestion is that key-value stores mean by definition that your application will see the database as a single, enormous, globally accessible hashtable, which is difficult to maintain and hard on programmer productivity.
There are many key-value stores in the wild today, including Tokyo Cabinet, Amazon’s SimpleDB, and Microsoft’s Dynomite.
Amazon Dynamo
Dynamo is Amazon’s proprietary key-value storage system. Though it’s not usable by developers, it’s still important to discuss because it, along with Google Bigtable, inspired many of the design decisions in Apache Cassandra.
In October of 2007, Werner Vogels, CTO of Amazon, published a white paper for the Association of Computing Machinery (ACM) called “Dynamo: Amazon’s Highly Available Key-value Store.” This paper continues to be publicly available on his blog “All Things Distributed” at http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf. The paper is rather technical, but it is clear, concise, and very well written. I will just summarize the main points here.
Dynamo was born, as were many of the systems described in this chapter, from the need to honor strict requirements for realizing high performance under continuous growth, meeting service-level agreements (SLAs), remaining available under strenuous load and failures, gracefully handling those failures, and allowing horizontal scale. Therefore, with respect to the CAP theorem, Dynamo, like Cassandra, is highly available and eventually consistent. Failure handling in both of these systems is regarded as a “normal case without impacting availability or performance.” This is achievable because of the trade-off Dynamo makes with consistency.
Dynamo is used for Amazon’s shopping cart, and of course consistency is important to Amazon. For a service such as a web-based shopping cart, which does not have competing readers, it is more than worth the trade-offs and will not be problematic. Although consistency is not the main focus of this system, it is a “tuneable” property, such that “eventual” is perhaps a misnomer.
As in Cassandra, consistency in Dynamo works where a configurable property allows the user to decide what number of replicas must successfully respond before it can be determined that an operation was successful. To achieve this, communication between replicas is based on a peer-to-peer (P2P) communication protocol called “gossip,” which we’ll examine further in terms of Cassandra inherits.
The requirements for the Dynamo architecture were clear. In order to support a highly available model, the team decided to tune down the consistency “knob.” Again, this is perfectly acceptable for their given use case. They also wanted a very easy-to-use query model, so the data is referenced using unique keys and stored simply as byte arrays. This eliminates the need for any sophisticated schema design and allows Amazon to put effort toward low-latency and high-throughput performance optimizations and their other primary goals.
To achieve an acceptable level of consistency, Dynamo must support some sort of versioning mechanism so that replicas can know which node has the most recent (valid) copy of written data. So it employs something called a vector clock, in which each process maintains a numeric reference to the most recent event it’s aware of. Another facet of the architecture that Cassandra shares with Dynamo is the hinted handoff.
This section has summarized the basic points of the Amazon Dynamo paper in order to help you understand its architectural goals and features. Although I very much encourage you to read the Dynamo paper, be aware that Cassandra does diverge in its own ways, so don’t take for granted that something described there will necessarily apply to Cassandra. In short, Cassandra derives its design around consistency and partition tolerance from Dynamo, and its data model is based on Bigtable.
Project Voldemort
Voldemort was started as a project within LinkedIn when they encountered problems with simple data partitioning to meet their scalability needs, similar to how Cassandra was started within Facebook. Voldemort is a distributed, very simple key-value store, based on Amazon’s Dynamo and Memcached.
Performance numbers suggested by Jay Kreps of LinkedIn indicate approximately 20,000 reads and 17,000 writes per second with one client and one server.
Website: http://project-voldemort.com
Orientation: Key-value store
Created: Created in 2008 by LinkedIn’s Data and Analytics team for application to real-time problems
Implementation language: Java
Distributed: Yes
Schema: The primary aims of Voldemort are high performance and availability. As a result, the database supports only the most minimal schema. The following are essentially the only supported queries:
value = store.get(key),store.put(key, value), andstore.delete(key). Because Voldemort allows you to specify your schema with JSON, it supports all the data types that JSON supports.Client: Like Cassandra, Voldemort allows for pluggable interfaces. According to the Voldemort website, it supports pluggable serialization and integrates with Thrift, Avro, and Google Protocol Buffers.
Replication: Data is automatically replicated over multiple servers; this is configurable.
Storage: Voldemort allows for pluggable storage on disk using BerkeleyDB or MySQL.
Production use: LinkedIn
Additional features: Can be used in conjunction with Hadoop.
Redis
Redis is not a “plain” key-value store, as it supports a variety of values in different data structures such as binary-safe strings (strings that don’t contain a space or newline character), lists and sets of binary-safe strings, and sorted sets, which contain a floating-number score.
In March of 2010, VMWare took over as project sponsor of Redis.
Website: http://code.google.com/p/redis
Orientation: Key-value store
Created: Created in 2009
Implementation language: ANSI C
Distributed: No distribution or fault tolerance.
Schema: Key-value store, using
server:key-nameto store and retrieve values.Clients: Redis supports a wide array of clients, typically through contributed libraries, including Ruby, Python, Twisted Python, Erlang, Tcl, Perl, Lua, Java, Scala, Clojure, C#, C, Haskell, and Google’s new Go language.
CAP: Eventually consistent
Open source: Yes. Hosted in Google projects. There’s a neat web page that offers a Redis tutorial (based on the MongoDB tutorial) that allows you to try Redis directly from your browser using JavaScript. Give it a try at http://try.redis-db.com.
Columnar Databases
A columnar database simply means a data store that organizes data around columns instead of rows. This slight shift in focus optimizes the workload for certain kinds of problems—in particular, data warehouses and analytics applications that require computing aggregate values over very large sets of similar data. Columnar (or “column-oriented”) databases are well-suited to online analytical processing (OLAP) work, where queries are executed over a broad dataset.
Data storage works a little differently with columnar databases, in order to optimize disk space and the amount of time spent in IO. For example, columnar databases allow you to write a record containing a value for only one out of a large number of possible columns, and only that single column value will be stored and take up space. This is different from RDBMS, in which nulls are not stored for free. It can be useful to think of RDBMS tables like spreadsheets, in which all columns are of the same size for each row, and null values are maintained to keep the grid-like shape of the data structure. This model doesn’t work for columnar databases, though, because null values are not present. It’s more helpful to think of columnar data as tags: values can be of arbitrary length, and the names and widths of columns are not preset.
Columnar databases often require the data to be of a uniform type, which presents an opportunity for data compression.
Columnar databases have been around since the early 1970s. Sybase IQ, for example, is one of these, and was for many years the only commercial columnar database.
But of the recent (mostly open source) projects that are part of the NoSQL conversation, there are a few databases that are an evolution of basic key-value stores in that they feature a richer data model. You can think of these columnar databases as multidimensional key-value stores or distributed hash tables that, instead of supporting merely straight key-value pairs, allow for arrangements called column families to help organize columns and provide a richer model. These are Google’s Bigtable, HBase, Hypertable, and Cassandra.
Google’s Bigtable is really the parent of the modern columnar databases. It is proprietary, but there are a few published papers on its design, and each of the other columnar databases discussed are implementations that closely follow Bigtable’s design or, as in the case of Cassandra, take certain key ideas from Bigtable.
Google Bigtable
Bigtable is Google’s internally used custom database, designed to scale into the petabyte range. Bigtable is described in the paper published by Google in 2006 called “Bigtable: A Distributed Storage System for Structured Data.” The goals of the project are stated in that paper: “wide applicability, scalability, high performance, and high availability.” Bigtable is used extensively within Google as the underlying data store, supporting more than 60 projects, including Gmail, YouTube, Google Analytics, Google Finance, Orkut, Personalized Search, and Google Earth. Bigtable runs on top of the Google File System (GFS).
It is useful to understand Bigtable, at least to a certain degree, because many of its attributes and design decisions are explicitly copied in Cassandra. Although Cassandra gets its design for consistency and partition tolerance from Amazon Dynamo, Cassandra’s data model is based more closely on Bigtable’s. For example, Cassandra borrows from Bigtable (sometimes with modification) the implementation of SSTables, memtables, Bloom filters, and compactions (see the Glossary for definitions of these terms; they are explored in detail elsewhere in this book as appropriate). In this way, Cassandra supports a somewhat richer data model than Dynamo, something more flexible and layered than a simple key-value store, as it supports sparse, semistructured data.
Note
I very much encourage you to read the Google Bigtable paper; it’s an excellent read. However, keep in mind that although Cassandra borrows many key ideas from Bigtable, it is not generally a 1:1 correspondence in ideas or implementation. For example, Bigtable defines master and slave nodes, and while Cassandra’s data model and storage mechanism are based on Bigtable and use the same terminology in many places, it’s not always the case. For example, Bigtable reads and writes are close but not identical to their Cassandra implementations; Bigtable defines a Tablet structure that is not strictly present in Cassandra; and so on. You can read the paper at http://labs.google.com/papers/bigtable.html.
Cassandra does contrast with Bigtable in several areas, however, not least of which is that Cassandra maintains a decentralized model. In Bigtable there is a master server that controls operations using the Chubby persistent distributed locking mechanism; in Cassandra, all the nodes are on even par with no centralized control, and they communicate using a gossip model.
Bigtable relies on a distributed lock service called Chubby for several different things: ensuring that there is at most a single master replica at any given time; managing server bootstrapping, discovery, and death; and storing the schema information.
Website: None, but you might be interested in a related project called Google Fusion Tables, which is available at http://tables.googlelabs.com.
Orientation: Columnar
Created: By Google, Inc. Development started in 2004, with the paper published in 2006.
Implementation language: C++
Distributed: Yes
Storage: Google File System (GFS). Files are divided into 64-megabyte chunks, and a typical write operation will only ever append to the files in order to provide maximum throughput. GFS has as a driving principle that the filesystem must run on banks of inexpensive commodity servers, which can be prone to failure, and therefore it must be able to manage availability in such a scenario. Bigtable features two server types: one master node and many chunkservers. The chunkservers store the data chunk files, and the master node stores all of the metadata about the chunks, such as the location of some particular piece of data. This is a clear point where Cassandra diverges from Bigtable’s design, as Cassandra nodes are all the same and there is no master server centrally controlling the ring.
Schema: The data model in Bigtable is a sparse, distributed, multidimensional sorted map. It allows you to store data in a richer way than, say, Amazon SimpleDB, as you can use list types. The map is indexed using a row key, a column key, and a timestamp; the values themselves are uninterpreted byte arrays.
Client: C++. Queries are also sometimes written in a scripting language developed at Google called Sawzall. Initially, the Sawzall API did not support writing values to the database, but did allow data filtering, transformation, and summarizing. MapReduce is typically used as both an input source and an output source.
Open source: No
Additional features: While Bigtable itself is not directly available for your own use, you can use it indirectly if you build an application with Google App Engine. Bigtable was designed with use of the MapReduce algorithm in mind. There are a few clones of Bigtable, and Hadoop is an open source implementation of MapReduce.
HBase
HBase is a clone of Google’s Bigtable, originally created for use with Hadoop (it’s actually a subproject of the Apache Hadoop project). In the way that Google’s Bigtable uses the Google File System (GFS), HBase provides database capabilities for Hadoop, allowing you to use it as a source or sink for MapReduce jobs. Unlike some other columnar databases that provide eventual consistency, HBase is strongly consistent.
Perhaps it is interesting to note that Microsoft is a contributor to HBase, following their acquisition of Powerset.
Website: http://hbase.apache.org
Orientation: Columnar
Created: HBase was created at Powerset in 2007 and later donated to Apache.
Implementation language: Java
Distributed: Yes. You can run HBase in standalone, pseudodistributed, or fully distributed mode. Pseudodistributed mode means that you have several instances of HBase, but they’re all running on the same host.
Storage: HBase provides Bigtable-like capabilities on top of the Hadoop File System.
Schema: HBase supports unstructured and partially structured data. To do so, data is organized into column families (a term that appears in discussions of Apache Cassandra). You address an individual record, called a “cell” in HBase, with a combination of row key, column family, cell qualifier, and timestamp. As opposed to RDBMS, in which you must define your table well in advance, with HBase you can simply name a column family and then allow the cell qualifiers to be determined at runtime. This lets you be very flexible and supports an agile approach to development.
Client: You can interact with HBase via Thrift, a RESTful service gateway, Protobuf (see “Additional Features” below), or an extensible JRuby shell.
Open source: Yes (Apache License)
Production use: HBase has been used at Adobe since 2008. It is also used at Twitter, Mahalo, StumbleUpon, Ning, Hulu, World Lingo, Detikcom in Indonesia, and Yahoo!.
Additional features: Because HBase is part of the Hadoop project, it features tight integration with Hadoop. There is a set of convenience classes that allow you to easily execute MapReduce jobs using HBase as the backing data store.
HBase requires Zookeeper to run. Zookeeper, also part of the Hadoop project, is a centralized service for maintaining configuration information and distributed synchronization across nodes in a cluster. Although this does add an external dependency, it makes maintaining the cluster easier and helps simplify the HBase core.
HBase allows you to use Google’s Protobuf (Protocol Buffer) API as an alternative to XML. Protobuf is a very efficient way of serializing data. It has the advantage of compacting the same data two to three times smaller than XML, and of being 20–100 times faster to parse than XML because of the way the protocol buffer encodes bytes on the wire. This can make working with HBase very fast. Protobuf is used extensively within Google; they incorporate nearly 50,000 different message types into Protobuf across a wide variety of systems. Check out the Protobuf Google code project at http://code.google.com/p/protobuf.
The database comes with a web console user interface to monitor and manage region servers and master servers.
Hypertable
Hypertable is a Google Bigtable clone, very similar to HBase. It is used at Zvents, where the project originated, to write more than one billion cells per day. It can run on a distributed filesystem such as HFS or the Kosmos File System. Hypertable uses Multi-Version Concurrency Control (MVCC) to allow user transactions to execute in a private memory space, which are readable by other clients only once the transaction has committed.
Like Cassandra and other Bigtable derivatives, it uses Bloom filters and commit logs to minimize disk access and improve performance.
Hypertable is well-suited for analytics applications and processing. Unlike many of the other nonrelational solutions, it is not used frequently to back websites.
Website: http://www.hypertable.org
Orientation: Columnar
Created: Hypertable was started in February of 2007 at Zvents.
Implementation language: C
Distributed: Yes
Open Source: Yes
Schema: Hypertable stores data as a multidimensional table represented as a flat, sorted list of key-value pairs. The key is essentially the concatenation of four dimension keys (row, column family, column qualifier, and timestamp).
Clients: The primary Thrift API (also used by Cassandra before being replaced by Avro) is C++, with bindings for Java, Python, Ruby, PHP, Perl, Erlang, Haskell, C#, Perl, and Ocaml.
Additional features: Hypertable has its own query language called Hypertable Query Language (HQL). HQL is modeled on SQL, so you can express queries in a familiar manner, such as
select * from QueryLogByTimestamp WHERE ROW =^ '2010-03-27 17:05';. The query here looks a lot like SQL, but includes a modified syntax. For example, the^=operator means “starts with.”
Like Voldemort and Cassandra (before Avro, at least), Hypertable uses the Thrift API for client serialization.
Polyglot Persistence
The different styles of persistence that we’ve toured in this chapter highlight one fact: each of them is good at solving a particular problem, or has particular strengths where the others don’t. You may have heard the term “polyglot programming,” which is largely credited to Neal Ford. The idea with polyglot programming is that different programming languages are good at different things, and that you can combine programming languages in a single solution in order to realize the maximum benefit. Dean Wampler of http://polyglotprogramming.com offers the overwhelming success of Emacs as an example of how polyglot programming can be helpful: Emacs uses C for its kernel, which made it fast, and a scripting dialect of Lisp called Emacs Lisp (ELisp), which made it easy to extend. Polyglot programming as a concept has been enabled by a variety of advances in the last few years, including the ability of the Java Virtual Machine to run a variety of languages. We more frequently hear of large web applications that have parts that are implemented in Scala, Ruby, and PHP. For example, the most recent iteration of the eBay architecture is mostly Java, but the search engine is in C++.
I submit that we may see a similar trend in persistence. The NoSQL conversation has challenged the status quo—that RDBMS is the right tool for every job because it’s the tool we have. Some proponents of NoSQL suggest that RDBMS will be replaced with one or more of these solutions. I rather think it’s more likely that we’ll see polyglot persistence, or the use of a variety of data stores performing different tasks within an application. In this vision, relational databases will live side by side with nonrelational databases, and they will operate together within modular, service-oriented applications, each optimized to perform the tasks they do best.
Summary
In the previous sections, we took a whirlwind tour of a variety of nonrelational databases in order to properly contextualize Cassandra in light of the overall NoSQL movement. The purpose was to shed some light on how the industry has been thinking about data over the last few years and to compare and contrast some of these systems in order to understand their broader theoretical underpinnings.
We also took a tour of the many so-called NoSQL offerings in order to understand the alternatives to relational databases that have sprung up in recent years. These databases, in their variety of forms, are different ways of trying to respond to the growing need for handling data at massive “web scale.” Another purpose of this tour was to illustrate that NoSQL databases exist for a reason, though some pundits and industry experts may object. They are being used by many large companies with strenuous data requirements and cannot be dismissed as newfangled “art projects.” They are strongly rooted in important ideas surrounding data scalability from some of the best minds in the industry, sometimes going back decades. And, though it’s true that they have (very public) problems at times, that’s also the case with relational databases.
So my purpose in this book has not been to convince you to throw away all your relational databases and replace them with the new flavor of the month. It’s been to help you understand the advantages and disadvantages of alternatives to relational databases, and to understand Cassandra in-depth, so that when you’re presented with your next data problem, you’re ready to take a step back and select not just the default tool, but the best tool for the job.