
![]()
Spark Streaming
Batch processing of historical data was one of the first use cases for big data technologies such as Hadoop and Spark. In batch processing, data is collected for a period of time and processed in batches. A batch processing system processes data spanning from hours to years, depending on the requirements. For example, some organizations run nightly batch processing jobs, which process data collected throughout the day by various systems.
Batch processing systems have high latency. Depending on the volume of data, it may take anywhere from a few minutes to a few hours to process a batch. Some organizations run nightly batch processing jobs that run for 6 to 12 hours on a cluster of hundreds of machines. Thus, there is a long wait before you can see the results generated by a batch processing application. In addition, since data is not immediate processed, the gap between the time when data is collected and the time when the batch processing result becomes available is even longer. This time gap is acceptable for a certain class of applications.
However, sometimes data needs to be processed and analyzed as it is collected. For example, fraud detection in an e-commerce system must happen in real time. Similarly, network intrusion or security breach detection must be in real time. Another example is application or device failure detection in a data center. To prevent a long downtime, data must be processed right away.
One of the challenges with live data stream processing is handling high-velocity data in real time or near real time. A data stream processing application running on a single machine will not be able to handle high-velocity data. A distributed stream processing framework addresses this issue.
This chapter introduces Spark Streaming. The introduction is followed by a detailed discussion of the application programming interface provided by Spark Streaming. At the end of the chapter, you will develop an application using Spark Streaming.
Introducing Spark Streaming
Spark Streaming is a distributed data stream processing framework. It makes it easy to develop distributed applications for processing live data streams in near real time. It not only provides a simple programming model but also enables an application to process high-velocity stream data. It also allows the combining of data streams and historical data for processing.
Spark Streaming Is a Spark Add-on
Spark Streaming is a Spark library that runs on top of Spark. It extends Spark for data stream processing. It provides higher-level abstractions for processing streaming data, but under the hood, it uses Spark (see Figure 6-1).

Figure 6-1. Spark Streaming runs on top of Spark core
Since Spark Streaming runs on top of Spark, it provides a scalable, fault-tolerant, and high-throughput distributed stream processing platform. It inherits all the features and benefits of Spark core. The processing capability of Spark Streaming application can be easily increased by adding more nodes to a Spark cluster.
In addition, Spark Streaming can be used along with other Spark libraries, such as Spark SQL, MLlib, Spark ML, and GraphX. A data stream can be analyzed using SQL. Machine learning algorithms can be applied to a data stream. Similarly, graph processing algorithms can be applied to stream data. Thus, Spark Streaming makes the power of the complete Spark stack available for processing data streams.
High-Level Architecture
Spark Streaming processes a data stream in micro-batches. It splits a data stream into batches of very small fixed-sized time intervals. Data in each micro-batch is stored as an RDD, which is then processed using Spark core (see Figure 6-2). Any RDD operation can be applied to an RDD created by Spark Streaming. The results of the RDD operations are streamed out in batches.

Figure 6-2. Stream to micro-batches
Data Stream Sources
Spark Streaming supports a variety of data stream sources, including TCP socket, Twitter, Kafka, Flume, Kinesis, ZeroMQ, and MQTT. It can also be used to process a file as a stream. In addition, you can extend it to process data from a custom streaming data source.
The streaming data sources for which Spark Streaming has built-in support can be grouped into two categories: basic sources and advanced sources.
- Basic data stream sources include TCP sockets, Akka Actors, and files. Spark Streaming includes the libraries required to process data from these sources. A Spark Streaming application that wants to process data streams from a basic source needs to link only against the Spark Streaming library.
- Advanced data stream sources include Kafka, Flume, Kinesis, MQTT, ZeroMQ, and Twitter. The libraries required for processing data streams from these sources are not included with Spark Streaming, but are available as external libraries. A Spark Streaming application that wants to process stream data from an advanced source must link against not only the Spark Streaming library, but also the external library for that source.
Receiver
A Receiver receives data from a streaming data source and stores it in memory. Spark Streaming creates and runs a Receiver on a worker node for each data stream. An application can connect to multiple data streams to process data streams in parallel.
Destinations
The results obtained from processing a data stream can be used in a few different ways (see Figure 6-3). The results may be fed to another application, which may take some action or just display it. For example, a Spark Streaming application may feed the results to a dashboard application that is updated continuously. Similarly, in a fraud detection application, the results may trigger cancellation of a transaction. The results can also be stored in a storage system such as a file or a database.
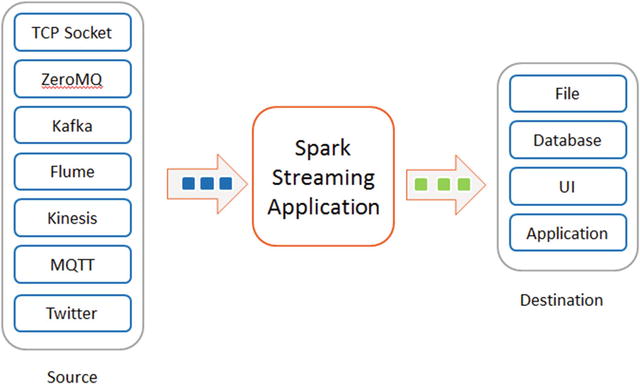
Figure 6-3. Stream data sources and destinations
Application Programming Interface (API)
The Spark Streaming library is written in Scala, but it provides an application programming interface (API) in multiple languages. At the time this book was written, the Spark Streaming API was available in Scala, Java, and Python.
The Spark Streaming API consists of two key abstractions, StreamingContext and Discretized Streams. A Spark Streaming application processes a data stream using these two abstractions.
This section covers StreamingContext and Discretized Streams in detail. It discusses the various operations supported by these abstractions and how you can create them. It also discusses the basic structure of a Spark Streaming application.
StreamingContext
StreamingContext, a class defined in the Spark Streaming library, is the main entry point into the Spark Streaming library. It allows a Spark Streaming application to connect to a Spark cluster. It also provides methods for creating an instance of the data stream abstraction provided by Spark Streaming.
Every Spark Streaming application must create an instance of this class.
Creating an Instance of StreamingContext
Creating an instance of StreamingContext is similar to creating an instance of SparkContext. It can be created using the same parameters that are required to create an instance of the SparkContext class. However, it takes an additional argument, which specifies the time interval for splitting a data stream into micro-batches.
import org.apache.spark._
import org.apache.spark.streaming._
val config = new SparkConf().setMaster("spark://host:port").setAppName("big streaming app")
val batchInterval = 10
val ssc = new StreamingContext(conf, Seconds(batchInterval))
Alternatively, if you already have an instance of the SparkContext class, you can use it to create an instance of the StreamingContext class.
import org.apache.spark._
import org.apache.spark.streaming._
val config = new SparkConf().setMaster("spark://host:port").setAppName("big streaming app")
val sc = new SparkContext(conf)
...
...
val batchInterval = 10
val ssc = new StreamingContext(sc, Seconds(batchInterval))
The second argument to the StreamingContext constructor specifies the size of a micro-batch using time as a unit. A data stream is split into batches of this time duration and each batch is processed as an RDD. The preceding example specifies a batch duration of 10 seconds. Spark Streaming creates a new RDD from a streaming source every 10 seconds.
The batch size can be as small as 500 milliseconds. The upper bound for the batch size is determined by the latency requirements of your application and the available memory. The executors created for a Spark Streaming application must have sufficient memory to store the received data in memory for good performance.
You will use the variable ssc in other examples in this chapter. Instead of repeating the preceding code snippet in every example, assume that the ssc variable is defined at the beginning of the program, as shown earlier.
The StreamingContext class defines methods for creating instances of classes representing different types of data streams. They are discussed in detail in later sections. The other commonly used methods from the StreamingContext class are briefly described next.
Starting Stream Computation
The start method begins stream computation. Nothing really happens in a Spark Streaming application until the start method is called on an instance of the StreamingContext class. A Spark Streaming application begins receiving data after it calls the start method.
ssc.start()
Checkpointing
The checkpoint method defined in the StreamingContext class tells Spark Streaming to periodically checkpoint data. It takes the name of a directory as an argument. For a production application, the checkpoint directory should be on a fault-tolerant storage system such as HDFS.
ssc.checkpoint("path-to-checkpoint-directory")
A Spark Streaming application must call this method if it needs to recover from driver failures or if it performs stateful transformations. The data processed by a Spark Streaming application is conceptually a never ending sequence of continuous data. If the machine running the driver program crashes after some data has been received but before it has been processed, there is a potential for data loss. Ideally, a Spark Streaming application should be able to recover from failures without losing data. To enable this functionality, Spark Streaming requires an application to checkpoint metadata.
In addition, data checkpointing is required when an application performs stateful transformation on a data stream. A stateful transformation is an operation that combines data across multiple batches in a data stream. An RDD generated by a stateful transformation depends on the previous batches in a data stream. Therefore, the dependency tree for an RDD generated by a stateful transformation grows with time. In case of a failure, Spark Streaming reconstructs an RDD using its dependency tree. As the dependency tree grows, the recovery time increases. To prevent recovery time from becoming too high, Spark Streaming checkpoints intermediate RDDs of a stateful transformation. Therefore, Spark Streaming requires an application to call the checkpoint method prior to using a stateful transformation. The stateful transformations supported by Spark Streaming are discussed later in this chapter.
Stopping Stream Computation
The stop method, as the name implies, stops stream computation. By default, it also stops SparkContext. This method takes an optional parameter that can be used to stop only the StreamingContext, so that the SparkContext can be used to create another instance of StreamingContext.
ssc.stop(true)
Waiting for Stream Computation to Finish
The awaitTermination method in the StreamingContext class makes an application thread wait for stream computation to stop. It’s syntax is
ssc.awaitTermination()
The awaitTermination method is required if a driver application is multi-threaded and the start method was called not from the main application thread but by another thread. The start method in the StreamingContext class is blocking method; it does not return until stream computation is finished or stopped. In a single-threaded driver, the main thread will wait until the start method returns. However, if the start method was called from another thread, you can prevent your main thread from exiting prematurely by calling awaitTermination.
Basic Structure of a Spark Streaming Application
Let’s create an outline of a Spark Streaming application using the classes and methods discussed so far. It shows the basic structure and does not have any processing logic yet. As you progress through the chapter, you will see code snippets for different types of stream processing. You can add those snippets to this skeleton to get a complete working Spark Streaming application.
import org.apache.spark._
import org.apache.spark.streaming._
object StreamProcessingApp {
def main(args: Array[String]): Unit = {
val interval = args(0).toInt
val conf = new SparkConf()
val ssc = new StreamingContext(conf, Seconds(interval))
// add your application specific data stream processing logic here
...
...
...
ssc.start()
ssc.awaitTermination()
}
}
Discretized Stream (DStream)
Discretized Stream (DStream) is the primary abstraction provided by Spark Streaming for working with data streams. It represents a data stream and defines the operations that you can perform on a data stream.
DStream is defined as an abstract class in the Spark Streaming library. It defines an interface for processing a data stream. Spark Streaming provides concrete classes that implement the DStream interface for stream data from a variety of sources. I use the term DStream generically to refer to both the abstract class and the classes implementing the interface defined by the DStream class.
Spark Streaming implements a DStream as a sequence of RDDs (see Figure 6-4). It translates DStream operations to operations on the underlying RDDs.
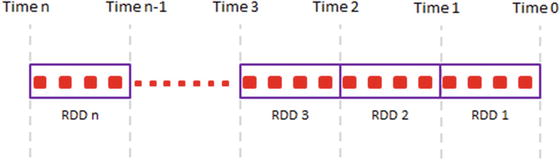
Figure 6-4. DStream is a never-ending sequence of RDDs
Since a DStream is a sequence of RDDs, it inherits the key RDD properties. It is immutable, partitioned, and fault tolerant.
Creating a DStream
A DStream can be created from a streaming data source or from an existing DStream by applying a transformation. Since DStream is an abstract class, you cannot directly create an instance of the DStream class. The Spark Streaming library provides factory methods for creating instances of the concrete classes that implement the interface defined by DStream.
Basic Sources
The factory methods for creating a DStream from basic sources are built-in. A Spark Streaming application needs to link only against the Spark Streaming library to use these methods. The StreamingContext class defines the methods for creating a DStream from a basic source. The commonly used methods for creating a DStream from a basic source are briefly described next.
socketTextStream
The socketTextStream method creates a DStream that represents stream data received over a TCP socket connection. It takes three input parameters. The first argument is the hostname of the data source. The second argument is the port to connect to for receiving data. The third argument, which is optional, specifies the storage level for the received data.
val lines = ssc.socketTextStream("localhost", 9999)
The default storage level is StorageLevel.MEMORY_AND_DISK_SER_2, which stores the received data first in memory and spills to disk if the available memory is insufficient to store all received data. In addition, it deserializes the received data and reserializes it using Spark’s serialization format. Thus, this storage level incurs the overhead of data serialization, but it reduces JVM garbage collection-related issues. The received data is also replicated for fault tolerance.
You can change the storage level for the received data by explicitly providing the third argument. For example, if the batch interval of your Spark Streaming application is only a few seconds, you can improve application performance by using the StorageLevel.MEMORY_ONLY storage level.
val lines = ssc.socketTextStream("localhost", 9999, StorageLevel.MEMORY_ONLY)
textFileStream
The textFileStream method creates a DStream that monitors a Hadoop-compatible file system for new files and reads them as text files. It takes as input the name of a directory to monitor. Files must be written to the monitored directory by moving them from another location within the same file system. For example, on a Linux system, files should be written into the monitored directory using the mv command.
val lines = ssc.textFileStream("input_directory")
actorStream
The actorStream method creates a DStream with a user-implemented Akka actor Receiver.
The factory methods for creating a DStream from advanced sources such as Kafka, Flume, or Twitter are not built-in, but available through extra utility classes. To process a data stream from an advanced source, an application needs to perform the following steps:
- Import the utility class for that source and create a DStream using the factory method provided by that class.
- Link against the library that contains the utility class for that source.
- Create an uber JAR that includes all application dependencies and deploy the application on a Spark cluster.
For example, to process tweets from Twitter, an application must import the TwitterUtils class and use its createStream method to create a DStream that receives tweets from Twitter.
import org.apache.spark.streaming.twitter._
...
...
val tweets = TwitterUtils.createStream(ssc, None)
Processing a Data Stream
An application processes a data stream using the methods defined in the DStream and related classes. DStream supports two types of operations: transformation and output operation. The transformations can be further classified into basic, aggregation, key-value, and special transformation.
Similar to RDD transformations, DStream transformations are lazily computed. No computation takes places immediately when a transformation operation is called. An output operation triggers the execution of DStream transformation operations. In the absence of an output operation on a DStream, Spark Streaming will not do any processing, even if transformations are called on that DStream.
Basic Transformation
A transformation applies a user-defined function to each element in a DStream and returns a new DStream. DStream transformations are similar to RDD transformations. In fact, Spark Streaming converts a DStream transformation method call to a transformation method call on the underlying RDDs. Spark core computes the RDD transformations.
The commonly used DStream transformations are briefly described next.
map
The map method takes a function as argument and applies it to each element in the source DStream to create a new DStream. It returns a new DStream.
For example, assume that you have an application running on local host and sending streams of text lines on TCP port 9999. The following code snippet shows how to create a stream of line lengths from an input stream of text lines.
val lines = ssc.socketTextStream("localhost", 9999)
val lengths = lines map {line => line.length}
flatMap
The flatMap method returns a new DStream created by applying a user-provided function that returns 0 or more elements for each element in the source DStream.
The following code snippet shows how to create a stream of words from an input stream of lines.
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines flatMap {line => line.split(" ")}
filter
The filter method returns a new DStream created by selecting only those element in the source DStream for which the user-provided input function returns true.
The following code snippet removes empty lines from an input stream of lines.
val lines = ssc.socketTextStream("localhost", 9999)
val nonBlankLines = lines filter {line => line.length > 0}
repartition
The repartition method returns a new DStream in which each RDD has the specified number of partitions. It allows you to distribute input data stream across a number of machines for processing. It is used to change the level of processing parallelism. More partitions increase parallelism, while fewer partitions reduce parallelism.
val inputStream = ssc.socketTextStream("localhost", 9999)
inputStream.repartition(10)
union
The union method returns a new DStream that contains the union of the elements in the source DStream and the DStream provided as input to this method.
val stream1 = ...
val stream2 = ...
val combinedStream = stream1.union(stream2)
Aggregation Transformation
The transformations described in this section perform aggregation on the underlying RDDs of a DStream.
count
The count method returns a DStream of single-element RDDs. Each RDD in the returned DStream has the count of the elements in the corresponding RDD in the source DStream.
val inputStream = ssc.socketTextStream("localhost", 9999)
val countsPerRdd = inputStream.count()
reduce
The reduce method returns a DStream of single-element RDDs by reducing the elements in each RDD in the source DStream. It takes a user provided reduce function as an argument.
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines flatMap {line => line.split(" ")}
val longestWords = words reduce { (w1, w2) => if(w1.length > w2.length) w1 else w2}
countByValue
The countByValue method returns a DStream of key-value pairs, where a key in a pair is a distinct element within a batch interval and the value is its count. Thus, each RDD in the returned DStream contains the count of each distinct element in the corresponding RDD in the source DStream.
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines flatMap {line => line.split(" ")}
val wordCounts = words.countByValue()
Transformations Available Only on DStream of key-value Pairs
DStreams of key-value pairs support a few other transformations in addition to the transformations available on all types of DStreams. The commonly used transformations on DStream of key-value pairs are briefly described next.
cogroup
The cogroup method returns a DStream of (K, Seq[V], Seq[W]) when called on a DStream of (K, Seq[V]) and (K, Seq[W]) pairs. It applies a cogroup operation between RDDs of the DStream passed as argument and those in the source DStream.
val lines1 = ssc.socketTextStream("localhost", 9999)
val words1 = lines1 flatMap {line => line.split(" ")}
val wordLenPairs1 = words1 map {w => (w.length, w)}
val wordsByLen1 = wordLenPairs1.groupByKey
val lines2 = ssc.socketTextStream("localhost", 9998)
val words2 = lines2 flatMap {line => line.split(" ")}
val wordLenPairs2 = words2 map {w => (w.length, w)}
val wordsByLen2 = wordLenPairs2.groupByKey
val wordsGroupedByLen = wordsByLen1.cogroup(wordsByLen2)
This example used the cogroup method to find the words with the same length from two DStreams.
join
The join method takes a DStream of key-value pairs as argument and returns a DStream, which is an inner join of the source DStream and the DStream provided as input. It returns a DStream of (K, (V, W)) when called on DStreams of (K, V) and (K, W) pairs.
val lines1 = ssc.socketTextStream("localhost", 9999)
val words1 = lines1 flatMap {line => line.split(" ")}
val wordLenPairs1 = words1 map {w => (w.length, w)}
val lines2 = ssc.socketTextStream("localhost", 9998)
val words2 = lines2 flatMap {line => line.split(" ")}
val wordLenPairs2 = words2 map {w => (w.length, w)}
val wordsSameLength = wordLenPairs1.join(wordLenPairs2)
This example creates two DStreams of lines of text. It then splits them into DStreams of words. Next, it creates DStreams of key-value pairs, where a key is the length of a word and value is the word itself. Finally, it joins those two DStreams.
Left outer, right outer, and full outer join operations are also available. If a DStream of key value pairs of type (K, V) is joined with another DStream of pairs of type (K, W), full outer join returns a DStream of (K, (Option[V], Option[W])), left outer join returns a DStream of (K, (V, Option[W])), and righter outer join returns a DStream of (K, (Option[V], W)).
val leftOuterJoinDS = wordLenPairs1.leftOuterJoin(wordLenPairs2)
val rightOuterJoinDS = wordLenPairs1.rightOuterJoin(wordLenPairs2)
val fullOuterJoinDS = wordLenPairs1.fullOuterJoin(wordLenPairs2)
groupByKey
The groupByKey method groups elements within each RDD of a DStream by their keys. It returns a new DStream by applying groupByKey to each RDD in the source DStream.
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines flatMap {line => line.split(" ")}
val wordLenPairs = words map {w => (w.length, w)}
val wordsByLen = wordLenPairs.groupByKey
reduceByKey
The reduceByKey method returns a new DStream of key-value pairs, where the value for each key is obtained by applying a user-provided reduce function on all the values for that key within an RDD in the source DStream.
The following example counts the number of times a word occurs within each DStream micro-batch.
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines flatMap {line => line.split(" ")}
val wordPairs = words map { word => (word, 1)}
val wordCounts = wordPairs.reduceByKey(_ + _)
Special Transformations
The transformations discussed so far allow you to specify operations on the elements in a DStream. Under the hood, DStream converts them to RDD operations. The next two transformations deviate from this model.
transform
The transform method returns a DStream by applying an RDD => RDD function to each RDD in the source DStream. It takes as argument a function that takes an RDD as argument and returns an RDD. Thus, it gives you direct access to the underlying RDDs of a DStream.
This method allows you to use methods provided by the RDD API, but which do not have equivalent operations in the DStream API. For example, sortBy is a transformation available in the RDD API, but not in the DStream API. If you want to sort the elements within each RDD of a DStream, you can use the transform method as shown in the following example.
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap{line => line.split(" ")}
val sorted = words.transform{rdd => rdd.sortBy((w)=> w)}
The transform method is also useful for applying machine and graph computation algorithms to data streams. The machine learning and graph processing libraries provide classes and methods that operate at the RDD level. Within the transform method, you can use the API provided by these libraries.
updateStateByKey
The updateStateByKey method allows you to create and update states for each key in a DStream of key-value pairs. You can use this method to maintain any information about each distinct key in a DStream.
For example, you can use the updateStateByKey method to keep a running count of each distinct word in a DStream, as shown in the following example.
// Set the context to periodically checkpoint the DStream operations for driver fault-tolerance
ssc.checkpoint("checkpoint")
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap{line => line.split(" ")}
val wordPairs = words.map{word => (word, 1)}
// create a function of type (xs: Seq[Int], prevState: Option[Int]) => Option[Int]
val updateState = (xs: Seq[Int], prevState: Option[Int]) => {
prevState match {
case Some(prevCount) => Some(prevCount + xs.sum)
case None => Some(xs.sum)
}
}
val runningCount = wordPairs.updateStateByKey(updateState)
The Spark Streaming library provides multiple overloaded variants of the updateStateByKey method. The simplest version of the updateStateByKey method takes a function of type (Seq[V], Option[S]) => Option[S] as an argument. This user-provided function takes two arguments. The first argument is a sequence of new values for a key in a DStream RDD and the second argument is previous state of the key wrapped in the Option data type. The user-provided function updates the state of a key using the new values and previous state of a key, and returns the new state wrapped in the Option data type. If the update function returns None for a key, Spark Streaming stops maintaining state for that key.
The updateStateByKey method returns a DStream of key-value pairs, where the value in a pair is the current state of the key in that pair.
Output Operations
Output operations are DStream methods that can be used to send DStream data to an output destination. An output destination can be a file, database, or another application. Output operations are executed sequentially in the order in which they are called by an application.
Saving to a File System
The commonly used DStream output operations for saving a DStream to a file system are briefly described next.
saveAsTextFiles
The saveAsTextFiles method saves a DStream to files. It generates a directory for each DStream RDD. In each directory, it generates a file for each RDD partition. Thus, the saveAsTextFiles method creates multiple directories, each containing one or more files. The directory name for each DStream RDD is generated using the current timestamp and a user-provided prefix and optional suffix.
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines flatMap {line => line.split(" ")}
val wordPairs = words map { word => (word, 1)}
val wordCounts = wordPairs.reduceByKey(_ + _)
wordCounts.saveAsTextFiles("word-counts")
saveAsObjectFiles
The saveAsObjectFiles method saves DStream elements as serialized objects in binary SequenceFiles. Similar to the saveAsTextFile method, it stores the data for each DStream RDD in a separate directory and creates a file for each RDD partition. The directory name for each DStream RDD is generated using the current timestamp and a user-provided prefix and optional suffix.
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines flatMap {line => line.split(" ")}
val longWords = words filter { word => word.length > 3}
longWords.saveAsObjectFiles("long-words")
saveAsHadoopFiles
The saveAsHadoopFiles method is available on DStreams of key-value pairs. It saves each RDD in the source DStream as a Hadoop file.
saveAsNewAPIHadoopFiles
Similar to the saveAsHadoopFiles method, the saveAsNewAPIHadoopFiles method saves each RDD in a DStream of key-value pairs as a Hadoop file.
Displaying on Console
The DStream class provides the print method for displaying a DStream on the console of the machine where the driver program is running.
The print method, as the name implies, prints the elements in each RDD in the source DStream on the machine running the driver program. By default, it shows the first ten elements in each RDD. An overloaded version of this method allows you to specify the number of elements to print.
val ssc = new StreamingContext(conf, Seconds(interval))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines flatMap {line => line.split(" ")}
val longWords = words filter { word => word.length > 3}
longWords.print(5)
Saving into a Database
The foreachRDD method in the DStream class can be used to save the results obtained from processing a DStream into a database.
foreachRDD
The foreachRDD method is similar to the transform method discussed earlier. It gives you access to the RDDs in a DStream. The key difference between transform and foreachRDD is that transform returns a new DStream, whereas foreachRDD does not return anything.
The foreachRDD method is a higher-order method that takes as argument a function of type RDD => Unit. It applies this function to each RDD in the source DStream. All RDD operations are available to this function. It is important to note that the foreachRDD method is executed on the driver node; however, the RDD transformations and actions called within foreachRDD are executed on the worker nodes.
Two things have to be kept in mind when saving a DStream into a database. First, creating a database connection is an expensive operation. It is recommended not to open and close database connections frequently. Ideally, you should re-use a database connection for storing as many elements as possible to amortize the cost of creating a connection. Second, a database connection generally cannot be serialized and sent from master to worker nodes. Since DStreams are processed on worker nodes, database connections should be created on worker nodes.
The RDD foreachPartition action can be used for storing multiple DStream elements using the same database connection. Since the foreachRDD DStream method gives you access to all RDD operations, you can call the foreachPartition RDD method within foreachRDD. Within foreachPartition, you can open a database connection and use that connection to store all elements in the source RDD partition. You can further optimize by using a connection pool library instead of opening and closing a physical connection directly.
The following code snippet implements the approach described earlier for saving a DStream to a database. It assumes that the application is using a connection pool library such as HikariCP or BoneCP. The connection pool library is wrapped in a lazily initialized singleton object named ConnectionPool, which manages a pool of database connections.
resultDStream.foreachRDD { rdd =>
rdd.foreachPartition { iterator =>
val dbConnection = ConnectionPool.getConnection()
val statement = dbConnection.createStatement()
iterator.foreach {element =>
val result = statement.executeUpdate("...")
// check the result
...
}
statement.close()
// return connection to the pool
dbConnection.close()
}
}
Another optimization that you can do is batch the database writes. So instead of sending one database write per element, you can batch all the inserts for an RDD partition and send just one batch update to the database per RDD partition.
The foreachRDD method comes handy for not only saving a DStream to a database, but it is also useful for displaying the elements in a DStream in a custom format on the driver node.
Window Operation
A window operation is a DStream operation that is applied over a sliding window of data in a stream. Successive windows have one or more overlapping RDDs (see Figure 6-5). A window operation is a stateful DStream operation that combines data across multiple batches.
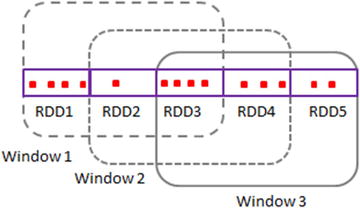
Figure 6-5. DStream windows
A window operation requires two parameters: window length and sliding interval (see Figure 6-6). The window length parameter specifies the time duration over which a window operation is applied. The sliding interval specifies the time interval at which a window operation is performed. It is the time interval at which new RDDs are generated by a window operation.
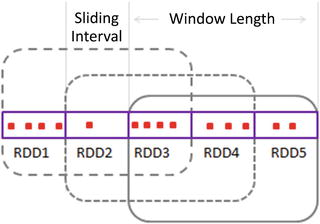
Figure 6-6. DStream windows
Both the window length and sliding interval parameters must be a multiple of a DStream’s batch interval.
The commonly used DStream methods for window operations are briefly described next.
window
The window method returns a DStream of sliding RDDs. It takes two arguments, window duration and sliding interval. Each RDD in the returned DStream includes elements from the source DStream for the specified duration and a new RDD is generated at the specified time interval. Successive RDDs in the returned DStream have overlapping data elements.
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines flatMap {line => line.split(" ")}
val windowLen = 30
val slidingInterval = 10
val window = words.window(Seconds(windowLen), Seconds(slidingInterval))
val longestWord = window reduce { (word1, word2) =>
if (word1.length > word2.length) word1 else word2 }
longestWord.print()
countByWindow
The countByWindow method returns a DStream of single-element RDDs. The single element in each returned DStream RDD is the count of the elements in a sliding window of a specified duration. It takes two arguments, window duration, and sliding interval.
ssc.checkpoint("checkpoint")
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines flatMap {line => line.split(" ")}
val windowLen = 30
val slidingInterval = 10
val countByWindow = words.countByWindow(Seconds(windowLen), Seconds(slidingInterval))
countByWindow.print()
countByValueAndWindow
The countByValueAndWindow method returns a DStream containing the counts of each distinct element within a sliding window that slides at the specified time interval.
ssc.checkpoint("checkpoint")
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines flatMap {line => line.split(" ")}
val windowLen = 30
val slidingInterval = 10
val countByValueAndWindow = words.countByValueAndWindow(Seconds(windowLen), Seconds(slidingInterval))
countByValueAndWindow.print()
reduceByWindow
The reduceByWindow method returns a DStream of single-element RDDs. Each RDD in the returned DStream is generated by applying a user-provided reduce function over the DStream elements in a sliding window. The reduceByWindow method takes three arguments: reduce function, window duration, and sliding interval.
The user-provided reduce function must be of type (T, T) => T. It takes two arguments of type T and returns a single value of type T. This function is applied to all the elements within a window to generate a single value. It can be used to aggregate elements within each sliding window.
ssc.checkpoint("checkpoint")
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines flatMap {line => line.split(" ")}
val numbers = words map {x => x.toInt}
val windowLen = 30
val slidingInterval = 10
val sumLast30Seconds = numbers.reduceByWindow({(n1, n2) => n1+n2},
Seconds(windowLen), Seconds(slidingInterval))
sumLast30Seconds.print()
reduceByKeyAndWindow
The reduceByKeyAndWindow operation is available only for DStreams of key-value pairs. It is similar to reduceByWindow, except that it does the same thing for a DStream of key-value pairs. It applies a user-provided reduce function to key-value pairs in a sliding DStream window to generate single key-value pair for each distinct key within a window.
ssc.checkpoint("checkpoint")
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines flatMap {line => line.split(" ")}
val wordPairs = words map {word => (word, 1)}
val windowLen = 30
val slidingInterval = 10
val wordCountLast30Seconds = wordPairs.reduceByKeyAndWindow((count1: Int, count2: Int) =>
count1 + count2, Seconds(windowLen), Seconds(slidingInterval))
wordCountLast30Seconds.print()
In a windowing operation, each new window overlaps with previous window. It adds some elements to and removes some from the previous window. For example, if the window duration is 60 seconds and sliding interval is 10 seconds, each new window removes 10 seconds of data from previous window and adds 10 seconds of new data. Successive windows share 40 seconds of data. Performing complete aggregation over 60 seconds for every window is inefficient. A more efficient approach is to add the aggregate for the 10 seconds of new data to the previous window’s result and remove the aggregate for the 10 seconds of data that is no longer in the new window.
Spark Streaming provides an efficient variant of the reduceByKeyAndWindow operation, which incrementally updates a sliding window by using the reduced value of the predecessor window. It requires an additional inverse reduce function as an argument. It reduces the new values that enter a windows and uses the inverse reduce function to remove the values that left the window.
ssc.checkpoint("checkpoint")
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines flatMap {line => line.split(" ")}
val wordPairs = words map {word => (word, 1)}
val windowLen = 30
val slidingInterval = 10
def add(x: Int, y: Int): Int = x + y
def subtract(x: Int, y: Int): Int = x -y
val wordCountLast30Seconds = wordPairs.reduceByKeyAndWindow(add, subtract,
Seconds(windowLen), Seconds(slidingInterval))
wordCountLast30Seconds.print()
A Complete Spark Streaming Application
At this point, you have learned the key classes and methods provided by the Spark Streaming API. You should be able to build a distributed stream data processing application using the material discussed earlier.
In this section, let’s develop a complete Spark Streaming application so that you can see how the classes and methods discussed in earlier sections come together in an application. You will create an application that shows trending Twitter hashtags.
The symbol # is called a hashtag. It is used to mark a topic in a tweet. People add the hashtag symbol before a word to categorize a tweet. A tweet may contain zero or more hashtagged words.
Twitter provides access to its global stream of tweets through a streaming API. You can learn about this API on Twitter’s web site at https://dev.twitter.com/streaming/overview.
To get access to the tweets through Twitter’s streaming API, you need to create a Twitter account and register your application. An application needs four pieces of authentication information to connect to Twitter’s streaming API: consumer key, consumer secret, access token, and access token secret. You can obtain these from Twitter. If you have a Twitter account, sign-in or create a new account. After signing-in, register your application at https://apps.twitter.com to get all the authentication credentials.
Let’s create a Spark Streaming application that tracks hashtagged words and shows the ones that are trending or gaining popularity. Application source code is shown next, followed by code explanation.
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.twitter._
import twitter4j.Status
object TrendingHashTags {
def main(args: Array[String]): Unit = {
if (args.length < 8) {
System.err.println("Usage: TrendingHashTags <consumer key> <consumer secret> " +
"<access token> <access token secret> " +
"<language> <batch interval> <min-threshold> <show-count> " +
"[<filters>]")
System.exit(1)
}
val Array(consumerKey, consumerSecret, accessToken, accessTokenSecret,
lang, batchInterval, minThreshold, showCount ) = args.take(8)
val filters = args.takeRight(args.length - 8)
System.setProperty("twitter4j.oauth.consumerKey", consumerKey)
System.setProperty("twitter4j.oauth.consumerSecret", consumerSecret)
System.setProperty("twitter4j.oauth.accessToken", accessToken)
System.setProperty("twitter4j.oauth.accessTokenSecret", accessTokenSecret)
val conf = new SparkConf().setAppName("TrendingHashTags")
val ssc = new StreamingContext(conf, Seconds(batchInterval.toInt))
ssc.checkpoint("checkpoint")
val tweets = TwitterUtils.createStream(ssc, None, filters)
val tweetsFilteredByLang = tweets.filter{tweet => tweet.getLang() == lang}
val statuses = tweetsFilteredByLang.map{ tweet => tweet.getText()}
val words = statuses.flatMap{status => status.split("""s+""")}
val hashTags = words.filter{word => word.startsWith("#")}
val hashTagPairs = hashTags.map{hashtag => (hashtag, 1)}
val tagsWithCounts = hashTagPairs.updateStateByKey(
(counts: Seq[Int], prevCount: Option[Int]) =>
prevCount.map{c => c + counts.sum}.orElse{Some(counts.sum)}
)
val topHashTags = tagsWithCounts.filter{ case(t, c) =>
c > minThreshold.toInt
}
val sortedTopHashTags = topHashTags.transform{ rdd =>
rdd.sortBy({case(w, c) => c}, false)
}
sortedTopHashTags.print(showCount.toInt)
ssc.start()
ssc.awaitTermination()
}
}
Let’s walk through the code.
import org.apache.spark._
import org.apache.spark.streaming._
These two import statements are required to import the classes and functions defined in the Spark Streaming library.
import org.apache.spark.streaming.twitter._
Twitter is an advanced source of data streams; therefore, an explicit import is required to use the classes defined in the Twitter utility library provided by Spark Streaming.
import twitter4j.Status
The Twitter-related utility classes provided by Spark Streaming use the open source Twitter4J library. Twitter4J makes it easy to integrate with the Twitter API. Since you will be using the Status class from the Twitter4J library, let’s import it here.
object TrendingHashTags {
def main(args: Array[String]): Unit = {
if (args.length < 8) {
System.err.println("Usage: TrendingHashTags <consumer key> <consumer secret> " +
"<access token> <access token secret> " +
"<language> <batch interval> <min threshold> <show-count> " +
"[<filters>]")
System.exit(1)
}
...
...
}
}
This is a basic outline of a Scala application. You create a singleton object and define a main method that takes an array of Strings as an argument. This array contains the command-line arguments passed to the application.
The application checks whether the minimum number of command-line arguments has been provided; otherwise it prints a message that shows the required arguments and quits. The application requires minimum eight arguments. The first four arguments are the Twitter credentials that the application needs to connect with Twitter’s streaming API. The fifth argument will be used to filter tweets by language. The sixth argument is the batch-interval in seconds for creating DStream RDDs. Each DStream RDD will include tweets for that duration. The seventh argument is a threshold for filtering hashtags by count. The eighth argument controls how many hashtags will be displayed on the console.
The remaining optional arguments will be passed to Twitter’s streaming API to limit received tweets to only those matching the specified keywords. The text of a tweet and a few tweet metadata fields are considered for matches. If the keywords are enclosed in double quotes then only tweets containing all the keywords will be sent to the application; otherwise, a tweet containing any keyword from the list will be sent. For example, “android ios iphone” will look for the presence of all three words in a tweet. These words need not be next to each other in a tweet.
val Array(consumerKey, consumerSecret, accessToken, accessTokenSecret,
lang, batchInterval, minThreshold, showCount ) = args.take(8)
The preceding code snippet extracts the mandatory arguments to local variables, which are used in the rest of the program. It is a concise way to extract multiple command-line arguments in a single expression.
val filters = args.takeRight(args.length - 8)
The remaining optional arguments are extracted as an array of filter keywords.
System.setProperty("twitter4j.oauth.consumerKey", consumerKey)
System.setProperty("twitter4j.oauth.consumerSecret", consumerSecret)
System.setProperty("twitter4j.oauth.accessToken", accessToken)
System.setProperty("twitter4j.oauth.accessTokenSecret", accessTokenSecret)
These lines pass the authentication credentials to the Twitter4J library through system properties. You set the system properties, which will be later read by the Twitter4J library.
val conf = new SparkConf().setAppName("TrendingHashTags")
Create an instance of the SparkConf class and set the name for the application. Spark monitoring UI will show the name that you specify here.
val ssc = new StreamingContext(conf, Seconds(batchInterval.toInt))
Create an instance of the StreamingContext class. This is where you specify the batching interval or the duration for each RDD in a DStream created using this instance of the StreamingContext class. A data stream will be split into batches at the time interval passed as the second parameter to the StreamingContext constructor.
ssc.checkpoint("checkpoint")
To track trending hashtags, stateful transformations will be used. Therefore, set the context to periodically checkpoint DStream operations at the specified location. In a production application, this path should point to a reliable file system such as HDFS.
val tweets = TwitterUtils.createStream(ssc, None, filters)
Use the factory method createStream in the TwitterUtils object to create a DStream that represents a stream of tweets. The filters variable restricts the tweets to only those that match the keywords in the filters array.
val tweetsFilteredByLang = tweets.filter{tweet => tweet.getLang() == lang}
Filter the tweets to only those that match the language specified in the command-line argument. Provide a function literal to the filter transformation method, and in this function literal, use the Twitter4J API to check the language of a tweet. The getLang method in the Twitter4J’s Status class returns the language of the status text, if available. Note that this method is not guaranteed to return the correct language.
val statuses = tweetsFilteredByLang.map{ tweet => tweet.getText()}
Use the map transformation to create a DStream of status texts.
val words = statuses.flatMap{status => status.split("""s+""")}
Split the status text into words to create a DStream of words from a DStream of status texts.
val hashTags = words.filter{word => word.startsWith("#")}
Since you are interested in hashtags, filter the hashtags from the DStream of words. The filter method will return a DStream of hashtags.
val hashTagPairs = hashTags.map{hashtag => (hashtag, 1)}
Next, create a DStream of key-value pairs from the DStream of hashtags that you created in the previous step. This step is required since you will be using a DStream transformation that is available only for DStream of key-value pairs.
val tagsWithCounts = hashTagPairs.updateStateByKey(
(counts: Seq[Int], prevCount: Option[Int]) =>
prevCount.map{c => c + counts.sum}.orElse{Some(counts.sum)})
This is the crux of the tweet processing logic. Use the updateStateByKey method to track the count of each distinct hashtag in a tweet stream. A function literal is passed to the updateStateByKey method. This function literal updates the count for each distinct hashtag by adding the number of its occurrences in the current RDD to its previous cumulative count. The first time this function is called, there will be no previous count, so it just returns the number of times a hashtag appeared in the current RDD. The returned value is wrapped in an Option data type. The updateStateByKey method returns a DStream of key-value pairs, where the key in a pair is a distinct hashtag and the value is its cumulative count from the time the application started processing a Twitter stream.
val topHashTags = tagsWithCounts.filter{ case(t, c) =>
c > minThreshold.toInt
}
Next, filter the DStream to keep only those hashtags with a count greater than the minimum threshold that was passed to the application as a command-line argument.
val sortedTopHashTags = topHashTags.transform{ rdd =>
rdd.sortBy({case(w, c) => c}, false)
}
Here you use the DStream transform method to sort the DStream of hashtag-count pairs by count. Note that the DStream API itself does not provide a method to sort the elements in a DStream. Therefore, you leverage the sortBy method provided by the RDD API. The transform method returns a DStream of hashtag-count pairs sorted by count.
sortedTopHashTags.print(showCount.toInt)
Next, print the specified number of top hashtags and their counts. Note that this print statement will be executed every time a new RDD is generated for the sortedTopHashTags DStream. A new RDD will be generated as per the batch interval that you specified when you created an instance of the StreamingContext. The application will print the top hashtags at those intervals.
ssc.start()
Finally, start the stream computation. No processing takes place until this step. The application starts receiving and processing tweets after you call the start method.
ssc.awaitTermination()
Wait for the stream computation to stop. The stream computation will stop when either the application throws an exception or if the user interrupts the application. Otherwise, the application will continue to run forever.
Summary
Spark Streaming is a library that extends Spark for processing live data streams. It runs on Spark and provides a higher-level API for processing data streams. It turns Spark into a distributed stream data processing framework.
The primary abstraction in Spark Streaming is DStream, which represents a data stream as a never-ending sequence of RDDs. Spark Streaming uses a micro-batching architecture, in which a data stream is split into micro-batches of a specified time duration.
In addition to all the operations that Spark core provides for a micro-batch, Spark Streaming also provides windowing operations on these micro-batches. It also allows an application to maintain state information for each distinct key in a DStream of key-value pairs.