
![]()
Indexing Myths and Best Practices
In the past few chapters, I’ve defined indexes and showed how they are structured. In the upcoming chapters, you’ll be looking at strategies to build indexes and ensure that they behave as expected. In this chapter, I’ll dispel some common myths and show how to build the foundation for creating indexes.
Myths result in an unnecessary burden when attempting to build an index. Knowing the myths associated with indexes can prevent you from using indexing strategies that will be counterproductive. The following are the indexing myths discussed in this chapter:
- Databases don’t need indexes.
- Primary keys are always clustered.
- Online index operations don’t block.
- Any column can be filtered in multicolumn indexes.
- Clustered indexes store records in physical order.
- Indexes always output in the same order.
- Fill factor is applied to indexes during inserts.
- Deleting form heaps results in unrecoverable space.
- Every table should be a heap or have a clustered index.
When reviewing myths, it’s also a good idea to take a look at best practices. Best practices are like myths in many ways, in the sense that they are commonly held beliefs. The primary difference is that best practices stand up to scrutiny and are useful recommendations when building indexes. This chapter will examine the following best practices:
- Use clustered indexes on primary keys by default.
- Balance index count.
- Properly target database level fill factors.
- Properly target index level fill factors.
- Index foreign key columns.
- Index to your environment.
Index Myths
One of the problems that people encounter when building databases and indexes is dealing with myths. Indexing myths originate from many different places. Some come from previous versions of SQL Server and its tools or are based on former functionality. Others come from the advice of others, based on conditions in a specific database that don’t match those of other databases.
The trouble with indexing myths is that they cloud the water of indexing strategies. In situations where an index can be built to resolve a serious performance issue, a myth can sometimes prevent the approach from being considered. Throughout the next few sections, I’ll cover a number of myths regarding indexing and do my best to dispel them.
Myth 1: Databases Don’t Need Indexes
Usually when developers are building applications, one or more databases are created to store data for the application. In many development processes, the focus is on adding new features with the mantra “Performance will work itself out.” An unfortunate result is that there are many databases that get developed and deployed without indexes being built because of the belief that they aren’t needed.
Along with this, there are developers who believe their databases are somehow unique from other databases. The following are some reasons that are heard from time to time:
- “It’s a small database that won’t get much data.”
- “It’s just a proof of concept and won’t be around for long.”
- “It’s not an important application, so performance isn’t important.”
- “The whole database already fits into memory; indexes will just make it require more memory.”
- “I am going to use this database only for inserting data; I will never look at the results.”
Each of these reasons is easy to break down. In today’s world of big data, even databases that are expected to be small can start growing quickly as they are adopted. Besides that, small in terms of a database is definitely in the eye of the beholder. Any proof-of-concept or unimportant database and application wouldn’t have been created if there weren’t a need or someone wasn’t interested in expending resources for the features. Those same people likely expect that the features they asked for will perform as expected. Lastly, fitting a database into memory doesn’t mean it will be fast. As was discussed in previous chapters, indexes provide an alternative access path to data, with the aim of decreasing the number of pages required to access the data. Without these alternative routes, data access will likely require reading every page of a table.
These reasons may not be the ones you hear concerning your databases, but they will likely be similar. The general idea surrounding this myth is that indexes don’t help the database perform better. One of the strongest ways to break apart this excuse is by demonstrating the benefits of indexing against a given scenario.
To demonstrate, let’s look at the code in Listing 8-1. This code sample creates the table MythOne. Next, you will find a query similar to one in almost any application. In the output from the query, in Listing 8-2, the query generated 1,496 reads.
It could be argued that 1,496 isn’t a lot of input/output (I/O). This might be true given the size of some databases and the amount of data in today’s world. But the I/O of a query shouldn’t be compared to the performance of the rest of the world; it needs to be compared to its potential I/O, the needs of the application, and the platform on which it is deployed.
Improving the query from the previous demonstration can be as simple as adding an index on the table on the CarrierTrackingNumber column. To see the effect of adding an index to MythOne, execute the code in Listing 8-3. With the index created, the reads for the query were reduced from 1,496 to 15 reads, shown in Listing 8-4. With just a single index, the I/O for the query was reduced by nearly two orders of magnitude. Suffice it to say, an index in this situation provides a significant amount of value.
I’ve shown in these examples that indexes do provide a benefit. If you encounter a situation where there is angst for building indexes on a database, try to break down the real reason for the pushback and provide an example similar to the one presented in this section. In Chapter 11, I’ll discuss approaches that can be used to determine what indexes to create in a database.
Myth 2: Primary Keys Are Always Clustered
The next myth that is quite prevalent is the idea that primary keys are always clustered. While this is true in many cases, you cannot assume that all primary keys are also clustered indexes. Earlier in this book, I discussed how a table can have only a single clustered index on it. If a primary key is created after the clustered index is built, then the primary key will be created as a nonclustered index.
To illustrate the indexing behavior of primary keys, I’ll use another demonstration that includes building two tables. On the first table, named dbo.MythTwo1, I’ll build the table and then create a primary key on the RowID column. For the second table, named dbo.MythTwo2, after the table is created, the script will build a clustered index before creating the primary key. The code for this is in Listing 8-5.
After running the code segment, the final query will return results like those shown in Figure 8-1. This figure shows that PK_MythTwo1, which is the primary key on the first table, was created as a clustered index. Then on the second table, PK_MythTwo2 was created as a nonclustered index.

Figure 8-1. Primary key sys.indexes output
The behavior discussed in this section is important to remember when building primary keys and clustered indexes. If you have a situation where they need to be separated, the primary key will need to be defined after the clustered index.
Myth 3: Online Index Operations Don’t Block
One of the advantages of SQL Server Enterprise Edition is the ability to build indexes online. During an online index build, the table on which the index is being created will still be available for queries and data modifications. This feature can be extremely useful when a database needs to be accessed and maintenance windows are short to nonexistent.
A common myth with online index rebuilds is that they don’t cause any blocking. Of course, like many myths, this one is false. When using an online index operation, there is an intent shared lock held on the table for the main portion of the build. At the finish, either a shared lock, for a nonclustered index, or a schema modification lock, for a clustered index, is held for a short time while the operation moves in the updated index. This differs from an offline index build where the shared or schema modification lock is held for the duration of the index build.
Of course, you will want to see this in action; to accomplish this, you will create a table and use Extended Events to monitor the locks that are applied to the table while creating indexes with and without the ONLINE options. To start this demo, execute the code in Listing 8-6. This script creates the table dbo.MythThree and populates it with ten million records. The last item it returns is the object_id for the table, which is needed for the subsequent parts of the demo. For this example, the object_id for dbo.MythThree is 1319675749.
![]() Note The demos for this myth all require SQL Server Enterprise or Developer Edition.
Note The demos for this myth all require SQL Server Enterprise or Developer Edition.
To monitor those events in this scenario, you’ll use Extended Events to capture the lock_acquired and lock_released events fired during index creation. Open sessions in SSMS for the code in Listing 8-7 and Listing 8-8. Use the session_id from Listing 8-8 for the session_id in Listing 8-7; for this scenario, the session_id is 42. After the Extended Events session is running, you can use the live view to monitor the locks as they occur.
In the example from Listing 8-8, creating the index with the ONLINE option causes the lock acquired and the released events shown in Figure 8-2. In the output, the SCH_S (Schema_Shared) lock is held from the beginning of the build to the end. The S (Shared) locks are held only for a few milliseconds at the beginning and ending of the index build. For the time between the S locks, the indexes are fully available and ready for use.

Figure 8-2. Index create with ONLINE option
By default, only the name and timestamp appear in the live viewer. The live viewer allows for customizing the columns that are displayed. In Figure 8-2, the columns object_it, mode, resource_type, and sql_text have been added to the defaults of name and timestamp. To add additional columns, right-click a column header and select “Choose columns”.
With the default index creation, which does not use the ONLINE option, S locks are held for the entirety of the index build. Shown in Figure 8-3, the S lock is taken before the SCH_S lock and isn’t released until after the index is build. The result is that the index is unavailable during the index build.

Figure 8-3. Index create without ONLINE option
Myth 4: Any Column Can Be Filtered in Multicolumn Indexes
The next common myth with indexes is that regardless of the position of the column in an index, the index can be used to filter for the column. As with the other myths discussed so far in this chapter, this one is also incorrect. An index does not need to use all the columns in a table. It does, however, need to start with the leftmost column in an index and use the columns from left to right, in order. This is why the order of the columns in an index is so important.
To demonstrate this myth, I’ll run through a few examples, shown in Listing 8-9. In the script, a table is created based on Sales.SalesOrderHeader with a primary key on SalesOrderID. To test the myth of searching all columns through multicolumn indexes, an index with the columns OrderDate, DueDate, and ShipDate is created.
With the test objects in place, the next thing to check is the behavior of the queries against the table that could potentially use the nonclustered index. First, I’ll run a query that uses the leftmost column in the index. Listing 8-10 gives the code for this. As shown in Figure 8-4, by filtering on the leftmost column, the query uses a seek operation on IX_MythFour.

Figure 8-4. Execution plan for leftmost column in index
Next you’ll look at what happens when querying from the other side of the index key columns. In Listing 8-11, the query filters the results on the rightmost column of the index. The execution plan for this query, shown in Figure 8-5, uses a scan operation on IX_MythFour. Instead of being able to go directly to the records that match the OrderDate, the query needs to check all records to determine which match the filter. While the index is used, it isn’t able to actually filter the rows.

Figure 8-5. Execution plan for rightmost column in index
At this point, you’ve seen that the leftmost column can be used for filtering and that filtering on the rightmost column can use the index but cannot use it optimally with a seek operation. The last validation is to check the behavior of columns in an index that are not on the left or right side of the index. In Listing 8-12, a query is included that uses the middle column in the index IX_MythFour. As with any execution plan, the execution plan for the middle column query, shown in Figure 8-6, uses the index but also uses a scan operation. The query is able to use the index but not in an optimal fashion.

Figure 8-6. Execution plan for middle column in index
The myth of how columns in a multicolumn index can be used is one that can sometimes be confusing. As the examples showed, queries can use the index regardless of which columns of the index are being filtered. The key is to effectively use the index. To accomplish this goal, filtering must start on the leftmost column of the index.
Myth 5: Clustered Indexes Store Records in Physical Order
One of the more pervasive myths commonly held is the idea that a clustered index stores the records in a table in their physical order when on disk. This myth seems to be primarily driven by confusion between what is stored on a page and where records are stored on those pages. As was discussed in Chapter 2, there is a difference between data pages and records. As a refresher, you’ll see a simple demonstration that dispels this myth.
To begin this example, execute the code in Listing 8-13. The code in the example will create a table named dbo.MythFive. Then it will add three records to the table. The last part of the script will output, using sys.dm_db_database_page_allocations, the page location for the table. In this example, the page with the records inserted into dbo.MythFive is on page 24189, shown in Figure 8-7.
![]() Note The dynamic management function sys.dm_db_database_page_allocations is a replacement for DBCC IND. This function, introduced in SQL Server 2012, provides an improved interface to examining page allocations for objects in a database over its DBCC predecessor.
Note The dynamic management function sys.dm_db_database_page_allocations is a replacement for DBCC IND. This function, introduced in SQL Server 2012, provides an improved interface to examining page allocations for objects in a database over its DBCC predecessor.

Figure 8-7. sys.dm_db_database_page_allocations output
The evidence to dispel this myth can be uncovered with the DBCC PAGE command. To do this, use the PagePID identified in Listing 8-13 with page_type_desc of DATA_PAGE. Since there is only a single data page for this table, that is where the data will be located. (For more information on DBCC commands, see Chapter 2.)
For this example, Listing 8-14 shows the T-SQL required to look at the data in the table. This command outputs a lot of information that includes some header information that isn’t useful in this example. The portion that you need is at the end, with the memory dump of the page, as shown in Figure 8-8. In the memory dump, the records are shown in the order in which they are placed on the page. As the dump shows from reading the far-right column, the records are in the order in which they are added to the table, not the order that they will appear in the clustered index.

Figure 8-8. Page contents portion of DBCC PAGE output
Based on this evidence, it is easy to discern that clustered indexes do not store records in the physical order of the index. If this example were expanded, you would be able to see that the pages are in physical order, but the rows on the pages are not.
Myth 6: Indexes Always Output in the Same Order
One of the more common myths that pertain to indexes is that they guarantee the output order of results from queries. This is not correct. As previously described in this book, the purpose of indexes is to provide an efficient access path to the data. That purpose does not guarantee the order in which the data will be accessed. The trouble with this myth is that, oftentimes, SQL Server will appear to maintain order when queries are executed under certain conditions, but when those conditions change, the execution plans change, and the results are returned in the order that the data is processed versus the order that the end user might desire.
To explore this myth, you’ll first look at how conditions can change on a query that is using clustered index. In Listing 8-15, there is a single query, repeated twice, for the Sales.SalesOrderHeader and Sales.SalesOrderDetail tables that is performing a simple aggregation. This is something that might appear in many types of use cases for SQL Server.
The conditions in which the two queries execute vary a bit. The first query is running under the standard SQL Server cost model and generates an execution that performs a couple index scans and a stream aggregation to return the results, shown in Figure 8-9. The results from the query, provided in Figure 8-10, provide support that SQL Server will return data in the desired output, provided that the SaleOrderID column is the column that the users wants sorted.

Figure 8-9. Default aggregation execution plan

Figure 8-10. Results from default aggregation execution plan
But what happens if the conditions on the SQL Server change but the business rules do not? The second query executed in Listing 8-15 is the same query, but with a change in conditions. For this example, the DBCC command SETCPUWEIGHT is leveraged to change the cost of the execution plan. The change in cost results in a parallel execution plan being created and executed, shown in Figure 8-11. The effect of the new plan is a change in the results of the query, provided in Figure 8-12. While the results appear to still be ordered, the logic of the query hasn’t change, but the first number in both results is different. At some point in the second result set, those rows not appearing at the start of results appear. The danger in this is that the results look sorted when a validation of them proves that they are not.

Figure 8-11. Aggregation execution plan with parallelism

Figure 8-12. Aggregation execution plan with parallelism
![]() Warning Do not use DBCC SETCPUWEIGHT in production code to control parallelism or for any other reason. This DBCC command is strictly available to control environmental variables within SQL Server to test and validate execution plans.
Warning Do not use DBCC SETCPUWEIGHT in production code to control parallelism or for any other reason. This DBCC command is strictly available to control environmental variables within SQL Server to test and validate execution plans.
The other condition to consider is when business rules change for a query. For instance, maybe a set of results wasn’t originally filtered, but after a change to the application, the query may change to using a different set of indexes. This can result in a change in the order of the results, such as when a query changes from using a clustered index to a nonclustered index.
To demonstrate this change in behavior, execute the code in Listing 8-16. This code runs two queries. Both of the queries return SalesOrderID, CustomerID, and Status. For the purposes of the example, the business rule dictates that the results must be sorted by SalesOrderID. In this case, the results from the first query are sorted as the business rule state, shown at the top of Figure 8-13. But in the second query, when the logic changes to request fewer rows by adding a filter, the results are no longer ordered, shown at the bottom of Figure 8-13. The cause of the change comes from a change in the indexes that SQL Server is using to execute the query. The change in indexes drives the results to be processed, and ordered, in the manner in which those indexes sort the data.
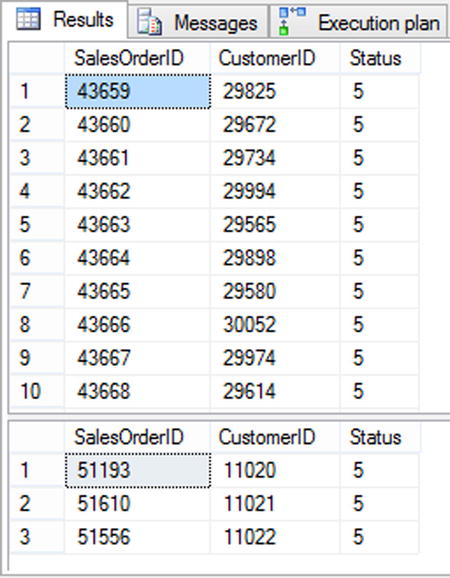
Figure 8-13. Query results demonstrating effect of filtering on order
In these examples, you looked at just a couple of the conditions that can change when it comes to how SQL Server will stream the results from a query. While an index might provide results from the query in the order desired this time, there is no guarantee that this will not change. Don’t rely on indexes to enforce ordering. Don’t rely on being clever to get the results ordered as desired. Rely on ORDER BY statements to get the results ordered as needed.
Myth 7: Fill Factor Is Applied to Indexes During Inserts
When the fill factor is set on an index, it is applied to the index when the index is built, rebuilt, or reorganized. Unfortunately, with this myth many people believe that fill factor is applied when records are inserted into a table. In this section, you’ll investigate this myth and see that it is not correct.
To begin pulling this myth apart, let’s look at what most people believe. In the myth, the thought is that if a fill factor has been specified when rows are added to a table, the fill factor is used during the inserts. To dispel this portion of the myth, execute the code in Listing 8-17. In this script, the table dbo.MythSeven is created with a clustered index with a 50 percent fill factor. That means that 50 percent of every page in the index should be left empty. With the table built, you’ll insert records into the table. Finally, you’ll check the average amount of space available on each page through the sys.dm_db_index_physical_stats DMV. Looking at the results of the script, included in Figure 8-14, the index is using 95 percent of every page versus the 50 percent that was specified in the creation of the clustered index.

Figure 8-14. Fill factor myth on inserts
Sometimes when this myth is dispelled, the belief is reversed, and it is believed that fill factor is broken or doesn’t work. This is also incorrect. Fill factor isn’t applied to indexes during data modifications. As stated previously, it is applied when the index is rebuilt, reorganized, or created. To demonstrate this, you can rebuild the clustered index on dbo.MythSeven with the script included in Listing 8-18.
After the clustered index is rebuilt, the index will have the specified fill factor, or close to the value specified, as shown in Figure 8-15. The average space used on the table, after the rebuild, changed from 95 to 51 percent. This change is in alignment with the fill factor that was specified for the index.

Figure 8-15. Fill factor myth after index rebuild
When it comes to fill factor, there are a number of myths surrounding the index property. The key to understanding fill factor is to remember when and how it is applied. It isn’t a property enforced on an index as it is used. It is, instead, a property used to distribute data within an index when it is created or rebuilt.
Myth 8: Deleting Form Heaps Results in Unrecoverable Space
Heaps are an interesting structure in SQL Server. In Chapter 2, you examined how they aren’t really an index but just a collection of pages for storing data. One of the index maintenance tasks that will be a part of the next chapter is recovering space from heap tables. As will be more deeply discussed in that chapter, when rows are deleted from a heap, the pages associated with those rows are not removed from the heap. This is generally referred to as bloat within the heap.
An interesting side effect of the concept of heap bloat is the myth that bloat never gets reused. The space stays in the heap and is not recoverable until the heap is rebuilt. Fortunately, for heaps and database administrators, this isn’t the case. When data is removed from a heap, the space that the data previously held is made available for future inserts into the table.
To demonstrate how this works, you’ll build a table using the code in Listing 8-19. The demonstration creates a heap named MythEight and then inserts 400 records, which results in 100 pages of data. This page count can be validated with the page_count column in the first resultset in Figure 8-16. The next part of the script deletes every other row that was inserted into the heap. Generally, this should leave each page with half as many rows as it had previously, shown in the second result set in Figure 8-16. The last part of the script re-inserts 200 rows into the MythEight table, returning the row count to 400 records and reusing the previously used pages that had data removed from them. There is a slight growth in the page count from the last resultset in Figure 8-16, but most of the new rows fit into the space already allocated.

Figure 8-16. Heap reuse query results
As the demonstration for this myth shows, space in a heap that previously held data is released for reuse by the table. For heaps that have a lot of data coming in and out of the table, there isn’t a significant need to monitor for page reuse, and the myth can be considered inaccurate. With heaps that have a lot of data removed without the intention to replace the data, you are able to recover the space with ALTER TABLE … REBUILD. The syntax and impact of this statement are discussed in the next chapter.
Myth 9: Every Table Should Have a Heap/Clustered Index
The last myth to consider is twofold. On the one hand, some people will recommend you should build all your tables with heaps. On the other hand, others will recommend that you create clustered indexes on all your tables. The trouble is that this viewpoint will exclude considering the benefits that each of the structures can offer on a table. The viewpoint makes a religious-styled argument for or against ways to store data in your databases without any consideration for the actual data that is being stored and how it is being used.
Some of the arguments against the use of clustered indexes are as follows:
- Fragmentation negatively impacts performance through additional I/O.
- The modification of a single record can impact multiple records in the clustered index when a page split is triggered.
- Excessive key lookups will negatively impact performance through additional I/O.
Of course, there are some arguments against using heaps.
- Excessive forwarded records negatively impact performance through additional I/O.
- Removing forwarded records requires a rebuild of the entire table.
- Nonclustered indexes are required for efficient filtered data access.
- Heaps don’t release pages when data is removed.
The negative impacts associated with either clustered indexes or heaps aren’t the only things to consider when deciding between one or the other. Each has circumstances where they will outperform the other.
For instance, clustered indexes perform best in the following circumstances:
- The key on the table is a unique, ever-increasing key value.
- The table has a key column that has a high degree of uniqueness.
- Ranges of data in a table will be accessed via queries.
- Records in the table will be inserted and deleted at a high rate.
On the other hand, heaps are ideal for some of the following situations:
- Data in the table will be used only for a limited amount of time where index creation time exceeds query time on the data.
- Key values will change frequently, which in turn would change the position of the record in an index.
- You are inserting copious numbers of records into a staging table.
- The primary key is a nonascending value, such as a unique identifier.
Although this section doesn’t include a demonstration of why this myth is false, it is important to remember that both heaps and clustered indexes are available and should be used appropriately. Knowing which type of index to choose is a matter of testing, not a matter of doctrine.
A good resource to consider for those in the “cluster everything camp” is the Fast Track Data Warehouse Architecture white paper (https://msdn.microsoft.com/en-us/library/hh918452.aspx). The white paper addresses some significant performance improvements that can be found with heaps and also the point in which these improvements dissipate. The white paper helps show how changes in I/O system technologies, with flash and cache-based devices, can change patterns and practices in regard to heaps and clustered indexes. This helps to promote the idea of validating myths and best practices from time to time.
Index Best Practices
Similar to myths are the indexing best practices. A best practice should be considered the default recommendations that can be applied when there isn’t enough information available to validate proceeding in another direction. Best practices are not the only option and are just a place to start from when working with any technology.
When using a best practice provided from someone else, such as those appearing in this chapter, it is important to check them out for yourself first. Always take them with a grain of salt. You can trust that best practices will steer you in the correct direction, but you need to verify that it is appropriate to follow the practice.
Given the preceding precautions, there are a number of best practices that can be considered when working with indexes. This section will review these best practices and discuss what they are and what they mean.
Use Clustered Indexes on Primary Keys by Default
The first best practice is to use clustered indexes on primary keys by default. This may seem to run contrary to the seventh myth presented in this chapter. Myth 7 discussed whether to choose clustered indexes or heaps as a matter of doctrine. Whether the database was built with one or the other, the myth would have you believe that if your table design doesn’t match the myth, it should be changed regardless of the situation. This best practice recommends using clustered indexes on primary keys as a starting point.
By clustering the primary key of a table by default, there is an increased likelihood that the indexing choice will be appropriate for the table. As stated earlier in this chapter, clustered indexes control how the data in a table is stored. Many primary keys, possibly most, are built on a column that utilizes the identity property that increments as each new record is added to the table. Choosing a clustered index for the primary key will provide the most efficient method to access the data.
As previously discussed in this book, indexes are extremely useful for improving the performance when accessing information in a record. Unfortunately, indexes are not without costs. The costs to having indexes go beyond just space within your database. When you build an index, you need to consider some of the following:
- How frequently will records be inserted or deleted?
- How frequently will the key columns be updated?
- How often will the index be used?
- What processes does the index support?
- How many other indexes are on the table?
These are just some of the first considerations that need to be accounted for when building indexes. After the index is built, how much time will be spent updating and maintaining the index? Will you modify the index more frequently than the index is used to return results for queries?
The trouble with balancing the index count on a table is that there is no precise number that can be recommended. Deciding on the number of indexes that it makes sense to have on an index is a per-table decision. You don’t want too few, which may result in excessive scans of the clustered index or heap to return results. Also, the table shouldn’t have too many indexes, where more time is being spent keeping the index current than returning results. As a rule of thumb, if a table has more than ten indexes on it in a transactional system, it is increasingly likely that there are too many indexes on the table.
Specify Fill Factors
Fill factor controls the amount of free space left on the data pages of an index after an index is built or defragmented. This free space is made available to allow for records on the page to expand with the risk that the change in record size may result in a page split. This is an extremely useful property of indexes to use for index maintenance. Modifying the fill factor can mitigate the risk of fragmentation. A more thorough discussion of fill factor is presented in Chapter 6. For the purposes of best practices, you are concerned with the ability to set the fill factor at the database and index levels.
As already mentioned, one of the properties of SQL Server is the option to set a default fill factor for indexes. This setting is a SQL Server–wide setting and can be altered in the properties of SQL Server on the Database Properties page. By default, this value is set to zero, which equates to 100. Do not modify the default fill factor to anything other than 0, or 100, which has the same impact. Doing so will change the fill factor for every index in the database to the new value; this will add the specified amount of free space to all indexes the next time indexes are created, rebuilt, or reorganized.
On the surface this may seem like a good idea, but this will blindly increase the size of all indexes by the specified amount. The increased size of the indexes will require more I/O to perform the same work as before the change. For many indexes, making this change would result in a needless waste of resources.
At the index level, you should modify the fill factor for indexes that are frequently becoming heavily fragmented. Decreasing the fill factor will increase the amount of free space in the index and provide additional space to compensate for the changes in record length leading to fragmentation. Managing fill factor at the index level is appropriate since it provides the ability to tune the index precisely to the needs of the database.
When a foreign key is created on a table, the foreign key column in the table should be indexed. This is necessary to assist the foreign key in determining which records in the parent table are constrained to each record in the referenced table. This is important when changes are being made against the referenced table. The changes in the referenced table may need to check all the rows that match the record in the parent table. If an index does not exist, then a scan of the column will occur. On a large parent table, this could result in a significant amount of I/O and potentially some concurrency issues.
An example of this issue would be a state and address table. There would likely be thousands or millions of records in the address table and maybe a hundred records in the state table. The address table would include a column that is referenced by the state table. Consider whether one of the records in the state table needed to be deleted. If there wasn’t an index on the foreign key column in the address table, then how would the address table identify the rows that would be affected by deleting the state record? Without an index, SQL Server would have to check every record in the address table. If the column is indexed, SQL Server would be able to perform a range scan across the records that match to the value being deleted from the state table.
By indexing your foreign key columns, performance issues, such as the one described in this section, can be avoided. The best practice with foreign keys is to index their columns. Chapter 11 includes more details on this best practice and a code example.
The indexing that exists today will likely not be the indexing that will be needed in databases in the future. For this reason, the last best practice is to continuously review, analyze, and implement changes to the indexes in your environment. Realize that regardless of how similar two databases are, if the data in the databases is not the same, then the indexing for the two databases may also be different. For an expanded conversation on monitoring and analyzing indexes, see Chapters 13 and 14.
Summary
This chapter looked at some myths surrounding indexes as well as some best practices. For both areas, you investigated what some commonly held beliefs are and presented some details around each of them.
With the myths, you looked at a number of ideas that are generally believed about indexes that are in fact not true. The myths covered clustered indexes, fill factor, the column makeup of indexes, and more. The key to how to view anything that is believed about indexes that may be a myth is to take it upon yourself to test them.
You also looked at best practices. The best practices provided in the chapter should be the basis on which indexes for your databases can be built. I defined what a best practice is and what it is not. Then I discussed a number of best practices that can be considered when indexing your databases.