
![]()
Utilizing In-Memory OLTP
This chapter discusses several design considerations for systems utilizing In-Memory OLTP and shows a set of techniques that can be used to address some of In-Memory OLTP’s limitations. Moreover, this chapter demonstrates how to benefit from In-Memory OLTP in scenarios when refactoring of existing systems is cost-ineffective. Finally, this chapter talks about systems with mixed workload patterns and how to benefit from the technology in those scenarios.
Design Considerations for the Systems Utilizing In-Memory OLTP
As with any new technology, adoption of In-Memory OLTP comes at a cost. You will need to acquire and/or upgrade to the Enterprise Edition of SQL Server 2014, spend time learning the technology, and, if you are migrating an existing system, refactor code and test the changes. It is important to perform a cost/benefits analysis and determine if In-Memory OLTP provides you with adequate benefits to outweigh the costs.
In-Memory OLTP is hardly a magical solution that will improve server performance by simply flipping a switch and moving data into memory. It is designed to address a specific set of problems, such as latch and lock contentions on very active OLTP systems. Moreover, it helps improve the performance of the small and frequently executed OLTP queries that perform point-lookups and small range scans.
In-Memory OLTP is less beneficial in the case of Data Warehouse systems with low concurrent activity, large amounts of data, and queries that require large scans and complex aggregations. While in some cases it is still possible to achieve performance improvements by moving data into memory, you can often obtain better results by implementing columnstore indexes, indexed views, data compression, and other database schema changes. It is also worth remembering that most performance improvements with In-Memory OLTP are achieved by using natively compiled stored procedures, which can rarely be used in Data Warehouse workloads due to the limited set of T-SQL features that they support.
The situation is more complicated with systems that have a mixed workload, such as an OLTP workload against hot, recent data and a Data Warehouse/Reporting workload against old, historical data. In those cases, you can partition the data into multiple tables, moving recent data into memory and keeping old, historical data on-disk. Partition views can be beneficial in this scenario by hiding the storage details from the client applications. We will discuss such implementation later in this chapter.
Another important factor is whether you plan to use In-Memory OLTP during the development of new or the migration of existing systems. It is obvious that you need to make changes in existing systems, addressing the limitations of memory-optimized tables, such as missing support of triggers, foreign key constraints, check and unique constraints, calculated columns, and quite a few other restrictions.
There are other factors that can greatly increase migration costs. The first is the 8,060-byte maximum row size limitation in memory-optimized tables without any off-row data storage support. This limitation can lead to a significant amount of work when the existing active OLTP tables use LOB data types, such as (n)varchar(max), xml, geography and a few others. While it is possible to change the data types, limiting the size of the strings or storing XML as text or in binary format, such changes are complex, time-consuming, and require careful planning. Don’t forget that In-Memory OLTP does not allow you to create a table if there is a possibility that the size of a row exceeds 8,060 bytes. For example, you cannot create a table with three varchar(3000) columns even if you do not plan to exceed the 8,060-byte row size limit.
Indexing of memory-optimizing tables is another important factor. While nonclustered indexes can mimic some of the behavior of indexes in on-disk tables, there is still a significant difference between them. Nonclustered indexes are unidirectional, and they would not help much if the data needs to be accessed in the opposite sorting order of an index key. This often requires you to reevaluate your index strategy when a table is moved from disk into memory. However, the bigger issue with indexing is the requirement of case-sensitive binary collation of the indexed text columns. This is a breaking change in system behavior, and it often requires non-trivial changes in the code and some sort of data conversion.
It is also worth noting that using binary collations for data will lead to changes in the T-SQL code. You will need to specify collations for variables in stored procedures and other T-SQL routines, unless you change the database collation to be a binary one. However, if the database and server collations do not match, you will need to specify a collation for the columns in temporary tables created in tempdb.
There are plenty of other factors to consider. However, the key point is that you should perform a thorough analysis before starting a migration to In-Memory OLTP. Such a migration can have a very significant cost, and it should not be done unless it benefits the system.
SQL Server 2014 provides the tools that can help during In-Memory OLTP migration. These tools are based on the Management Data Warehouse, and they provide you with a set of data collectors and reports that can help identify the objects that would benefit the most from the migration. While those tools can be beneficial during the initial analysis stage, you should not make a decision based solely on their output. Take into account all of the other factors and considerations we have already discussed in this book.
![]() Note We will discuss migration tools in detail in Appendix D.
Note We will discuss migration tools in detail in Appendix D.
New development, on the other hand, is a very different story. You can design a new system and database schema taking In-Memory OLTP limitations into account. It is also possible to adjust some functional requirements during the design phase. As an example, it is much easier to store data in a case-sensitive way from the beginning compared to changing the behavior of existing systems after they were deployed to production.
You should remember, however, that In-Memory OLTP is an Enterprise Edition feature, and it requires powerful hardware with a large amount of memory. It is an expensive feature due to its licensing costs. Moreover, it is impossible to “set it and forget it.” Database professionals should actively participate in monitoring and system maintenance after deployment. They need to monitor system memory usage, analyze data and recreate hash indexes if bucket counts need to be adjusted, update statistics, redeploy natively compiled stored procedures, and perform other tasks as well.
All of that makes In-Memory OLTP a bad choice for Independent Software Vendors who develop products that need be deployed to a large number of customers. Moreover, it is not practical to support two versions of a system—with and without In-Memory OLTP—due to the increase in development and support costs.
Addressing In-Memory OLTP Limitations
Let’s take a closer look at some of the In-Memory OLTP limitations and the ways to address them. Obviously, there is more than one way to skin a cat, and you can work around these limitations differently.
8,060-Byte Maximum Row Size Limit
The 8,060-byte maximum row size limit is, perhaps, one of the biggest roadblocks in widespread technology adoption. This limitation essentially prevents you from using (max) data types along with CLR and system data types that require off-row storage, such as XML, geometry, geography and a few others. Even though you can address this by changing the database schema and T-SQL code, these changes are often expensive and time-consuming.
When you encounter such a situation, you should analyze if LOB data types are required in the first place. It is not uncommon to see a column that never stores more than a few hundred characters defined as (n)varchar(max). Consider an Order Entry system and DeliveryInstruction column in the Orders table. You can safely limit the size of the column to 500-1,000 characters without compromising the business requirements of the system.
Another example is a system that collects some semistructured sensor data from the devices and stores it in the XML column. If the amount of semistructured data is relatively small, you can store it in varbinary(N) column, which will allow you to move the table into memory.
![]() Tip It is more efficient to use varbinary rather than nvarchar to store XML data in cases when you cannot use the XML data type.
Tip It is more efficient to use varbinary rather than nvarchar to store XML data in cases when you cannot use the XML data type.
Unfortunately, sometimes it is impossible to change the data types and you have to keep LOB columns in the tables. Nevertheless, you have a couple options to proceed.
The first approach is to split data between two tables, storing the key attributes in memory-optimized and rarely-accessed LOB attributes in on-disk tables. Again, consider the situation where you have an Order Entry system with the Products table defined as shown in Listing 11-1.
As you can guess, in this scenario, it is impossible to change the data types of the Picture and Description columns, which prevents you from making the Products table memory-optimized.
You can split that table into two, as shown in Listing 11-2. The Picture and Description columns are stored in an on-disk table while all other columns are stored in the memory-optimized table. This approach will improve performance for the queries against the ProductsInMem table and will allow you to access it from natively compiled stored procedures in the system.
Unfortunately, it is impossible to define a foreign key constraint referencing a memory-optimized table, and you should support referential integrity in your code.
You can hide some of the implementation details from the SELECT queries by defining a view as shown in Listing 11-3. You can also define INSTEAD OF triggers on the view and use it as the target for data modifications; however, it is more efficient to update data in the tables directly.
As you should notice, the view is using an outer join. This allows SQL Server to perform join elimination when the client application does not reference any columns from the ProductAttributes table when querying the view. For example, if you ran the query from Listing 11-4, you would see the execution plan as shown in Figure 11-1. As you can see, there are no joins in the plan and the ProductAttributes table is not accessed.

Figure 11-1. Execution plan of the query
You can use a different approach and store LOB data in memory-optimized tables, splitting it into multiple 8,000-byte chunks. Listing 11-5 shows the table that can be used for such a purpose.
Listing 11-6 demonstrates how to insert XML data into the table using T-SQL code in interop mode. It uses an inline table-valued function called dbo.SplitData that accepts the varbinary(max) parameter and splits it into multiple 8,000-byte chunks.
Figure 11-2 illustrates the contents of the LobData table after the insert.

Figure 11-2. Dbo.LobData table content
![]() Note SQL Server limits the CTE recursion level to 100 by default. You need to specify OPTION (MAXRECURSION 0) in the statement that uses the SplitData function in case of very large input.
Note SQL Server limits the CTE recursion level to 100 by default. You need to specify OPTION (MAXRECURSION 0) in the statement that uses the SplitData function in case of very large input.
You can construct original data using the code shown in Listing 11-7. Alternatively, you can develop a CLR aggregate and concatenate binary data there.
The biggest downside of this approach is the inability to split and merge large objects in natively compiled stored procedures due to the missing (max) parameters and variables support. You should use the interop engine for this purpose. However, it is still possible to achieve performance improvements by moving data into memory even when the interop engine is in use.
This approach is also beneficial when memory-optimized tables are used just for the data storage, and all split and merge logic is done inside the client applications. We will discuss this implementation in much greater depth later in this chapter.
Lack of Uniqueness and Foreign Key Constraints
The inability to create unique and foreign key constraints rarely prevents us from adopting new technology. However, these constraints keep the data clean and allow us to detect data quality issues and bugs in the code at early stages of development.
Unfortunately, In-Memory OLTP does not allow you to define foreign keys or unique indexes and constraints besides a primary key. To make matter worse, the lock-free nature of In-Memory OLTP makes uniqueness support in the code tricky. In-Memory OLTP transactions do not see any uncommitted changes done by other transactions. For example, if you ran the code from Table 11-1 in the default SNAPSHOT isolation level, both transactions would successfully commit without seeing each other’s changes.
Table 11-1. Inserting the Duplicated Rows in the SNAPSHOT Isolation Level
Session 1 | Session 2 |
|---|---|
set transaction isolation level snapshot | |
begin tran | |
if not exists ( select * from dbo.ProductsInMem where ProductName = 'Surface 3' ) | set transaction isolation level snapshot begin tran |
insert into dbo.ProductsInMem (ProductName) values ('Surface 3') | if not exists ( select * from dbo.ProductsInMem where ProductName = 'Surface 3' ) |
commit | |
insert into dbo.ProductsInMem (ProductName) values ('Surface 3') | |
commit |
Fortunately, this situation can be addressed by using the SERIALIZABLE transaction isolation level. As you remember, In-Memory OLTP validates the serializable consistency rules by maintaining a transaction scan set. As part of the serializable rules validation at commit stage, In-Memory OLTP checks for phantom rows, making sure that other sessions do not insert any rows that were previously invisible to the transaction.
Listing 11-8 shows a natively compiled stored procedure that runs in the SERIALIZABLE isolation level and inserts a row into the ProductsInMem table we defined earlier. Any inserts done through this stored procedure guarantee uniqueness of the ProductName even in a multi-user concurrent environment.
The SELECT query builds a transaction scan set, which will be used for serializable rule validation. This validation will fail if any other session inserts a row with the same ProductName while the transaction is still active. Unfortunately, the first release of In-Memory OLTP does not support subqueries in natively compiled stored procedures and it is impossible to write the code using an IF EXISTS construct.
You can validate the behavior of the stored procedure by running it in two parallel sessions, as shown in Table 11-2. Session 2 successfully inserts a row and commits the transaction. Session 1, on the other hand, fails on commit stage with Error 41325.
Table 11-2. Validating dbo.InsertProduct Stored Procedure
Session 1 | Session 2 | |
|---|---|---|
begin tran declare @ProductId int exec dbo.InsertProduct 'Surface 3' ,'Microsoft Tablet' ,@ProductId output commit | ||
declare @ProductId int exec dbo.InsertProduct 'Surface 3' ,'Microsoft Tablet' ,@ProductId output -- Executes and commits successfully | ||
Error: Msg 41325, Level 16, State 0, Line 62 The current transaction failed to commit due to a serializable validation failure. |
Obviously, this approach will work and enforce the uniqueness only when you have full control over the data access code in the system and have all INSERT and UPDATE operations performed through the specific set of stored procedures and/or code. The INSERT and UPDATE statements executed directly against a table could easily violate uniqueness rules. However, you can reduce the risk by revoking the INSERT and UPDATE permissions from users, giving them EXECUTE permission on the stored procedures instead.
You can use the same technique to enforce referential integrity rules. Listing 11-9 creates the Orders and OrderLineItems tables, and two stored procedures called InsertOrderLineItems and DeleteOrders enforce referential integrity between those tables there. I omitted the OrderId update scenario, which is very uncommon in the real world.
It is worth noting that the InsertOrderLineItems procedure is using the REPEATABLE READ isolation level. In this scenario, you need to make sure that the referenced Order row has not been deleted during the execution and that REPEATABLE READ enforces this with less overhead than SERIALIZABLE.
Case-Sensitivity Binary Collation for Indexed Columns
As discussed, the requirement of having binary collation for the indexed text columns introduces a breaking change in the application behavior if case-insensitive collations were used before. Unfortunately, there is very little you can do about it. You can convert all the data and search parameters to uppercase or lowercase to address the situation; however, this is not always possible.
Another option is to store uppercase or lowercase data in another column, indexing and using it in the queries. Listing 11-10 shows such an example.
Unfortunately, memory-optimized tables don’t support calculated columns and you will need to maintain the data in both columns manually in the code.
However, in the grand scheme of things, binary collations have benefits. The comparison operations on the columns that store data in binary collations are much more efficient compared to non-binary counterparts. You can achieve significant performance improvements when a large number of rows need to be processed.
One such example is a substring search in large tables. Consider the situation when you need to search by part of the product name in a large Products table. Unfortunately, a substring search will lead to the following predicate WHERE ProductName LIKE '%' + @Param + '%', which is not SARGable, and SQL Server cannot use an Index Seek operation in such a scenario. The only option is to scan the data, evaluating every row in the table, which is significantly faster with binary collation.
Let’s look at an example and create the table shown in Listing 11-11. The table has four text columns that store Unicode and non-Unicode data in binary and non-binary format. Finally, we populate it with 65,536 rows of random data.
As the next step, run queries from Listing 11-12, comparing the performance of a search in different scenarios. All of the queries scan primary key hash index, evaluating the predicate for every row in the table.
The execution time of all queries in my system are shown in Table 11-3. As you can see, the queries against binary collation columns are significantly faster, especially in the case of Unicode data.
Table 11-3. Binary Collation Performace: Test Results

Finally, it is worth noting that this behavior is not limited to memory-optimized tables. You will get a similar level of performance improvement with on-disk tables when binary collations are used.
Thinking Outside the In-Memory Box
Even though the limitations of the first release of In-Memory OLTP can make refactoring an existing systems cost-ineffective, you can still benefit from it by using some In-Memory OLTP components.
Importing Batches of Rows from Client Applications
In Chapter 12 of my book Pro SQL Server Internals, I compare the performance of several methods that inserted a batch of rows from the client application. I looked at the performance of calling individual INSERT statements; encoding the data into XML and passing it to a stored procedure; using the .Net SqlBulkCopy class; and passing data to a stored procedure utilizing table-valued parameters. Table-valued parameters became the clear winner of the tests, providing performance on par with the SqlBulkCopy implementation plus the flexibility of using stored procedures during the import. Listing 11-13 illustrates the database schema and stored procedure I used in the tests.
Listing 11-14 shows the ADO.Net code that performed the import in case of table-valued parameter.
You can improve performance even further by replacing the dbo.tvpData table-valued type to be memory-optimized, which is transparent to the stored procedure and client code. Listing 11-15 shows the new type definition.
The degree of performance improvement depends on the table schema, and it grows with the size of the batch. In my test environment, I got about 5-10 percent improvement on the small 5,000-row batches, 20-25 percent improvement on the 50,000-row batches, and 45-50 percent improvement on the 500,000-row batches.
You should remember, however, that memory-optimized table types cannot spill to tempdb, which can be dangerous in case of very large batches and with servers with an insufficient amount of memory. You should also define the bucket_count for the primary key based on the typical batch size, as discussed in Chapter 4 of this book.
![]() Note You can download the test application from this book’s companion materials and compare the performance of the various import methods.
Note You can download the test application from this book’s companion materials and compare the performance of the various import methods.
Using Memory-Optimized Objects as Replacements for Temporary and Staging Tables
Memory-optimized tables and table variables can be used as replacements for on-disk temporary and staging tables. However, the level of performance improvement may vary, and it greatly depends on the table schema, workload patterns, and amount of data in the table.
Let’s look at a few examples and, first, compare the performance of a memory-optimized table variable with on-disk temporary objects in a simple scenario, which you will often encounter in OLTP systems. Listing 11-16 shows stored procedures that insert up to 256 rows into the object, scanning it afterwards.
Table 11-4 illustrates the execution time of the stored procedures called 10,000 times in the loop. As you can see, the memory-optimized table variable outperformed on-disk objects. The level of performance improvements growth with the amount of data when on-disk tables need to allocate more data pages to store it.
Table 11-4. Execution Time of Stored Procedures (10,000 Executions)

It is also worth mentioning that performance improvements can be even more significant in the systems with a heavy concurrent load due to possible allocation pages contention in tempdb.
You should remember that memory-optimized table variables do not keep index statistics, similar to on-disk table variables. The Query Optimizer generates execution plans with the assumption that they store just the single row. This cardinality estimation error can lead to highly inefficient plans, especially when a large amount of data and joins are involved.
![]() Important As the opposite of on-disk table variables, statement-level recompile with OPTION (RECOMPILE) does not allow SQL Server to obtain the number of rows in memory-optimized table variables. The Query Optimizer always assumes that they store just a single row.
Important As the opposite of on-disk table variables, statement-level recompile with OPTION (RECOMPILE) does not allow SQL Server to obtain the number of rows in memory-optimized table variables. The Query Optimizer always assumes that they store just a single row.
Memory-optimized tables can be used as the staging area for ETL processes. As a general rule, they outperform on-disk tables in INSERT performance, especially if you are using user database and durable tables for the staging.
Scan performance, on the other hand, greatly depends on the row size and number of data pages in on-disk tables. Traversing memory pointers is a fast operation and it is significantly faster compared to getting a page from the buffer pool. However, on-page row access could be faster than traversing long memory pointers chain. It is possible that with the small data rows and large number of rows per page, on-disk tables would outperform memory-optimized tables in the case of scans.
Query parallelism is another important factor to consider. The first release of In-Memory OLTP does not support parallel execution plans. Therefore, large scans against on-disk tables could be significantly faster when they use parallelism.
Update performance depends on the number of indexes in memory-optimized tables, along with update patterns. For example, page splits in on-disk tables significantly decrease the performance of update operations.
Let’s look at a few examples based on a simple ETL process that inserts data into an imaginary Data Warehouse with one fact, FactSales, and two dimension, the DimDates and DimProducts tables. The schema is shown in Listing 11-17.
Let’s compare the performance of two ETL processes utilizing on-disk and memory-optimized tables as the staging areas. We will use another table called InputData with 1,650,000 rows as the data source to reduce import overhead so we can focus on the INSERT operation performance. Listing 11-18 shows the code of the ETL processes.
I have repeated the tests in four different scenarios, varying row size, with and without Placeholder columns and the existence of nonclustered indexes on Product columns. Table 11-5 illustrates the average execution time in my environment for the scenarios when tables don’t have nonclustered indexes. Table 11-6 illustrates the scenario with additional nonclustered indexes on the Product column.
Table 11-5. Execution Time of the Tests: No Additional Indexes

Table 11-6. Execution Time of the Tests: With Additional Indexes

As you can see, memory-optimized table INSERT performance can be significantly better compared to the on-disk table. The performance gain increases with the row size and when extra indexes are added to the table. Even though extra indexes slow down the insert in both cases, their impact is smaller in the case of memory-optimized tables.
On the other hand, the performance difference during the scans is insignificant. In both cases, the most work is done by accessing DimProducts and inserting data into the FactSales on-disk tables.
Listing 11-19 illustrates the code that allows us to compare UPDATE performance of the tables. The first statement changes a fixed-length column and does not increase the row size. The second statement, on the other hand, increases the size of the row, which triggers the large number of page splits in the on-disk table.
Tables 11-7 and 11-8 illustrate the average execution time of the tests in my environment. As you can see, the page split operation can significantly degrade update performance for on-disk tables. This is not the case with memory-optimized tables, where new row versions are generated all the time.
Table 11-7. Execution Time of Update Statements: No Additional Indexes
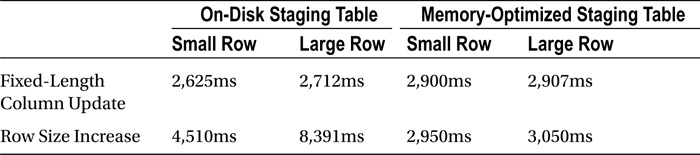
Table 11-8. Execution Time of Update Statements: With Additional Indexes

Nonclustered indexes, on the other hand, do not affect update performance of on-disk tables as long as their key columns were not updated. It is not the case with memory-optimized tables where multiple index chains need to be maintained.
As you can see, using memory-optimized tables with a Data Warehouse workload completely fits into the“It depends” category. In some cases, you will benefit from it, while in others performance is degraded. You should carefully test your scenarios before deciding if memory-optimized objects should be used.
Finally, it is worth mentioning that all tests in that section were executed with warm cache and serial execution plans. Physical I/O and parallelism could significantly affect the picture. Moreover, you will get different results if you don’t need to persist the staging data and can use temporary and non-durable memory-optimized tables during the processes.
Using In-Memory OLTP as Session - or Object State-Store
Modern software systems have become extremely complex. They consist of a large number of components and services responsible for various tasks, such as interaction with users, data processing, integration with other systems, reporting, and quite a few others. Moreover, modern systems must be scalable and redundant. They need to be able to handle load growth and survive hardware failures and crashes.
The common approach to solving scalability and redundancy issues is to design the systems in a way that permits to deploy and run multiple instances of individual services. It allows adding more servers and instances as the load grows and helps you survive hardware failures by distributing the load across other active servers. The services are usually implemented in stateless way, and they don’t store or rely on any local data.
Most systems, however, have data that needs to be shared across the instances. For example, front-end web servers usually need to maintain web session states. Back-end processing services often need to have shared cache with some data.
Historically, there were two approaches to address this issue. The first one was to use dedicated storage/cache and host it somewhere in the system. Remember the old ASP.Net model that used either a SQL Server database or a separate web server to store session data? The problem with this approach is limited scalability and redundancy. Storing session data in web server memory is fast but it is not redundant. A SQL Server database, on the other hand, can be protected but it does not scale well under the load due to page latch contention and other issues.
Another approach was to replicate content of the cache across multiple servers. Each instance worked with the local copy of the cache while another background process distributed the changes to the other servers. Several solutions on the market provide such capability; however, they are usually expensive. In some cases, the license cost for such software could be in the same order of magnitude as SQL Server licenses.
Fortunately, you can use In-Memory OLTP as the solution. In the nutshell, it looks similar to the ASP.Net SQL Server session-store model; however, In-Memory OLTP throughput and performance improvements address the scalability issues of the old on-disk solution.
You can improve performance even further by using non-durable memory-optimized tables. Even though the data will be lost in case of failover, this is acceptable in most cases.
However, the 8,060-byte maximum row size limit introduces challenges to the implementation. It is entirely possible that a serialized object will exceed 8,060 bytes. You can address this by splitting the data into multiple chunks and storing them in multiple rows in memory-optimized table.
You saw an example of a T-SQL implementation earlier in the chapter. However, using T-SQL code and an interop engine will significantly decrease the throughput of the solution. It is better to manage serialization and split/merge functional on the client side.
Listing 11-20 shows the table and natively compiled stored procedures that you can use to store and manipulate the data in the database. The client application calls the LoadObjectFromStore and SaveObjectToStore stored procedures to load and save the data. The PurgeExpiredObjects stored procedure removes expired rows from the table, and it can be called from a SQL Agent or other processes based on the schedule.
The client implementation includes several static classes. The ObjStoreUtils class provides four methods to serialize and deserialize objects into the byte arrays, and split and merge those arrays to/from 8,000-byte chunks. You can see the implementation in Listing 11-21.
The ObjStoreDataAccess class shown in Listing 11-22 loads and saves binary data to and from the database. It utilizes another static class called DBConnManager, which returns the SqlConnection object to the target database. This class is not shown in the listing.
Finally, the ObjStoreService class shown in Listing 11-23 puts everything together and manages the entire process. It implements two simple methods, Load and Save, calling the helper classes defined above.
Obviously, this is oversimplified example, and production implementation could be significantly more complex, especially if there is the possibility that multiple sessions can update the same object simultaneously. You can implement retry logic or create some sort of object locking management in the system if this is the case.
It is also worth mentioning that you can compress binary data before saving it into the database. The compression will introduce unnecessary overhead in the case of small objects; however, it could provide significant space savings and performance improvements if the objects are large.
I did not include compression code in the example, although you can easily implement it with the GZipStream or DeflateStream classes.
![]() Note The code and test application are included in companion materials of this book.
Note The code and test application are included in companion materials of this book.
Using In-Memory OLTP in Systems with Mixed Workloads
In-Memory OLTP can provide significant performance improvements in OLTP systems. However, with a Data Warehouse workload, results may vary. The complex queries that perform large scans and aggregations do not necessarily benefit from In-Memory OLTP.
In-Memory OLTP is targeted to the Enterprise market and strong SQL Server teams. It is common to see separate Data Warehouse solutions in those environments. Nevertheless, even in those environments, some degree of reporting and analysis workload is always present in OLTP systems.
The situation is even worse when systems do not have dedicated Data Warehouse and Analysis databases, and OLTP and Data Warehouse queries run against the same data. Moving the data into memory could negatively impact the performance of reporting queries.
One of the solutions in this scenario is to partition the data between memory-optimized and on-disk tables. You can put recent and hot data into memory-optimized tables, keeping old, historical data on-disk. Moreover, it is very common to see different access patterns in the systems when hot data is mainly customer-facing and accessed by OLTP queries while old, historical data is used for reporting and analysis.
Data partitioning also allows you to create a different set of indexes in the tables based on their access patterns. In some cases, you can even use columnstore indexes with the old data, which significantly reduces the storage size and improves the performance of Data Warehouse queries. Finally, you can use partitioned views to hide partitioning details from the client applications.
Listing 11-24 shows an example of such implementation. The memory-optimized table called RecentOrders stores the most recent orders that were submitted in 2015. The on-disk LastYearOrders table stores the data for 2014. Lastly, the OldOrders table stores the old orders that were submitted prior to 2014. The view Orders combines the data from all three tables.
As you know, memory-optimized tables do not support CHECK constraints, which prevent Query Optimizer from analyzing what data is stored in the RecentOrders table. You can specify that in a where clause of the first SELECT in the view. This will allow SQL Server to eliminate access to the table if queries do not need data from there. You can see this by running the code from Listing 11-25.
Figure 11-3 shows the partial execution plan of the query. As you can see, the query does not access the memory-optimized table at all.
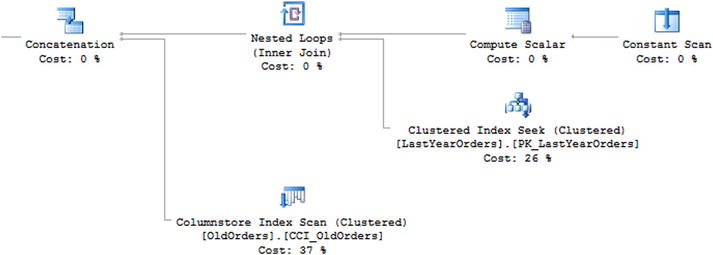
Figure 11-3. Execution plan of the query
The biggest downside of this approach is the inability to seam lessly move the data from a memory-optimized table to an on-disk table as the operational period changes. With on-disk tables, it is possible to make the data movement transparent by utilizing the online index rebuild and partition switches. However, it will not work with memory-optimized tables where you have to copy the data to the new location and delete it from the source table afterwards.
This should not be a problem if the system has a maintenance window when such operations can be performed. Otherwise, you will need to put significant development efforts into preventing customers from modifying data on the move.
![]() Note Chapter 15 in my book Pro SQL Server Internals discusses various data partitioning aspects including how to move data between different tables and file groups while keeping it transparent to the users.
Note Chapter 15 in my book Pro SQL Server Internals discusses various data partitioning aspects including how to move data between different tables and file groups while keeping it transparent to the users.
Summary
In-Memory OLTP can dramatically improve the performance of OLTP systems. However, it can lead to large implementation cost especially when you need to migrate existing systems. You should perform a cost/benefits analysis, making sure that the implementation cost is acceptable. It is still possible to benefit from In-Memory OLTP objects even when you cannot utilize the technology in its full scope.
Some of the In-Memory OLTP limitations can be addressed in the code. You can split the data between multiple tables to work around the 8,060-byte maximum row size limitation or, alternatively, store large objects in multiple rows in the table. Uniqueness and referential integrity can be enforced with REPEATABLE READ and SERIALIZABLE transaction isolation levels.
You should be careful when using In-Memory OLTP with a Data Warehouse workload and queries that perform large scans. While it can help in some scenarios, it could degrade performance of the systems in others. You can implement data partitioning, combining the data from memory-optimized and on-disk tables when this is the case.