
Recipe 1. Consumer complaint classification
Recipe 2. Customer reviews sentiment prediction
Recipe 3. Data stitching using record linkage
Recipe 4. Text summarization for subject notes
Recipe 5. Document clustering
Recipe 6. Search engine and learning to rank
We believe that after 4 chapters, you are comfortable with the concepts of natural language processing and ready to solve business problems. Here we need to keep all 4 chapters in mind and think of approaches to solve these problems at hand. It can be one concept or a series of concepts that will be leveraged to build applications.
So, let’s go one by one and understand end-to-end implementation.
Recipe 5-1. Implementing Multiclass Classification
Let’s understand how to do multiclass classification for text data in Python through solving Consumer complaint classifications for the finance industry.
Problem
Each week the Consumer Financial Protection Bureau sends thousands of consumers’ complaints about financial products and services to companies for a response. Classify those consumer complaints into the product category it belongs to using the description of the complaint.
Solution
The goal of the project is to classify the complaint into a specific product category. Since it has multiple categories, it becomes a multiclass classification that can be solved through many of the machine learning algorithms.
Once the algorithm is in place, whenever there is a new complaint, we can easily categorize it and can then be redirected to the concerned person. This will save a lot of time because we are minimizing the human intervention to decide whom this complaint should go to.
How It Works
Let’s explore the data and build classification problem using many machine learning algorithms and see which one gives better results.
Step 1-1 Getting the data from Kaggle
Go to the below link and download the data. https://www.kaggle.com/subhassing/exploring-consumer-complaint-data/data
Step 1-2 Import the libraries
Step 1-3 Importing the data
Step 1-4 Data understanding

Debt collection and Mortgage have the highest number of complaints registered.
Step 1-5 Splitting the data
Step 1-6 Feature engineering using TF-IDF
Step 1-7 Model building and evaluation
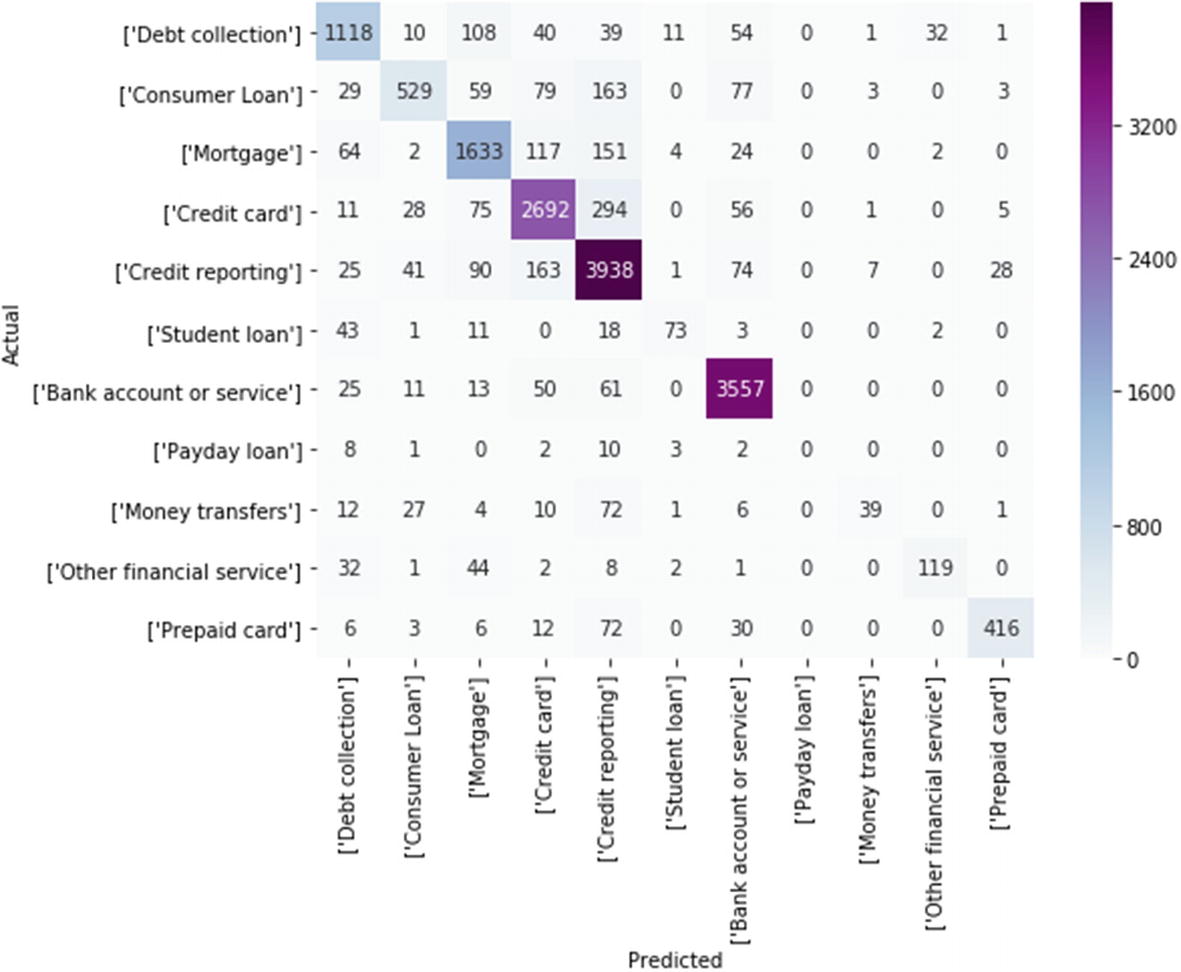
Reiterate the process with different algorithms like Random Forest, SVM, GBM, Neural Networks, Naive Bayes.
Deep learning techniques like RNN and LSTM (will be discussed in next chapter) can also be used.
In each of these algorithms, there are so many parameters to be tuned to get better results. It can be easily done through Grid search, which will basically try out all possible combinations and give the best out.
Recipe 5-2. Implementing Sentiment Analysis
In this recipe, we are going to implement, end to end, one of the popular NLP industrial applications – Sentiment Analysis. It is very important from a business standpoint to understand how customer feedback is on the products/services they offer to improvise on the products/service for customer satisfaction.
Problem
We want to implement sentiment analysis.
Solution
The simplest way to do this by using the TextBlob or vaderSentiment library. Since we have used TextBlob previously, now let us use vader.
How It Works
Let’s follow the steps in this section to implement sentiment analysis on the business problem.
Step 2-1 Understanding/defining business problem
Understand how products are doing in the market. How are customers reacting to a particular product? What is the consumer’s sentiment across products? Many more questions like these can be answered using sentiment analysis.
Step 2-2 Identifying potential data sources, collection, and understanding
Step 2-3 Text preprocessing
Step 2-4 Exploratory data analysis
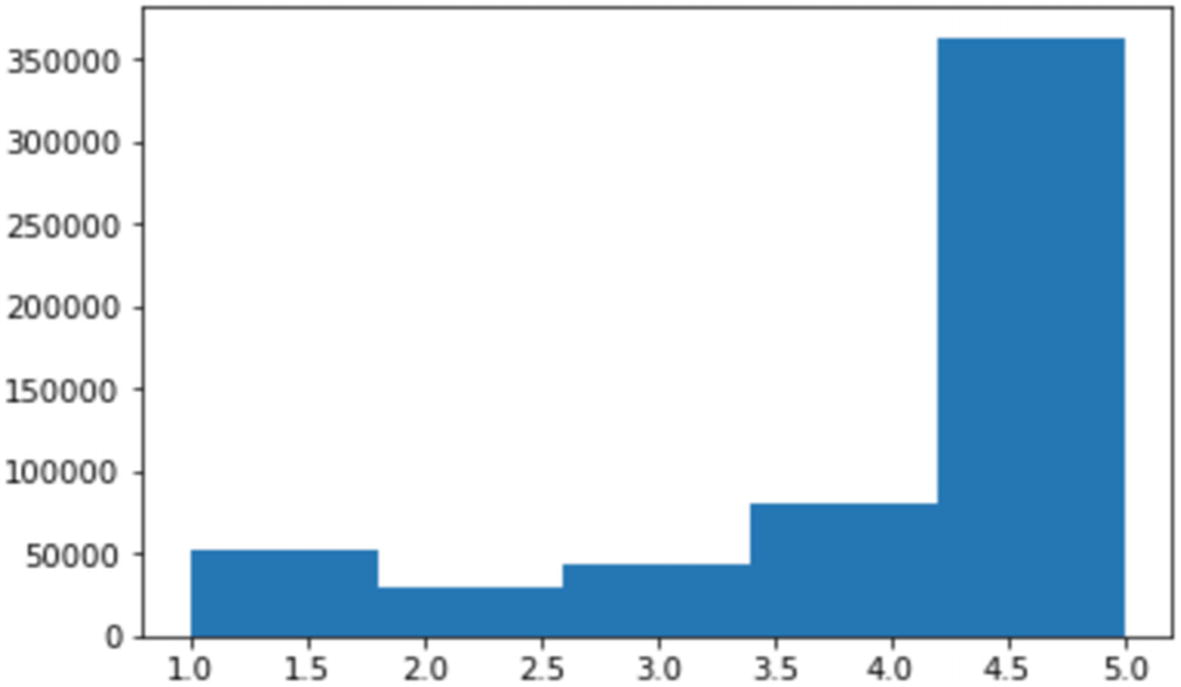
Score <= 2: Negative
Score = 3: Neutral
Score > =4: Positive


Step 2-5 Feature engineering
This step is not required as we are not building the model from scratch; rather we are using the pretrained model from the library vaderSentiment.
If you want to build the model from scratch, you can leverage the above positive and negative classes created while exploring as a target variable and then training the model. You can follow the same steps as text classification explained in Recipe 5-1 to build a sentiment classifier from scratch.
Step 2-6 Sentiment scores
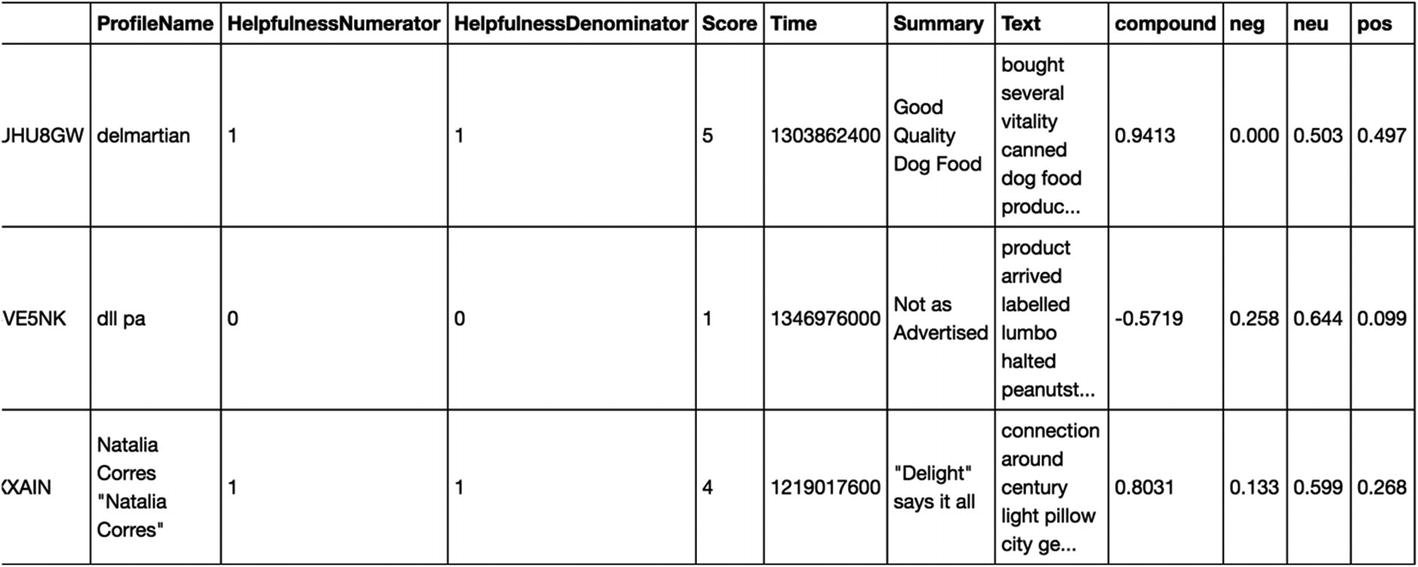
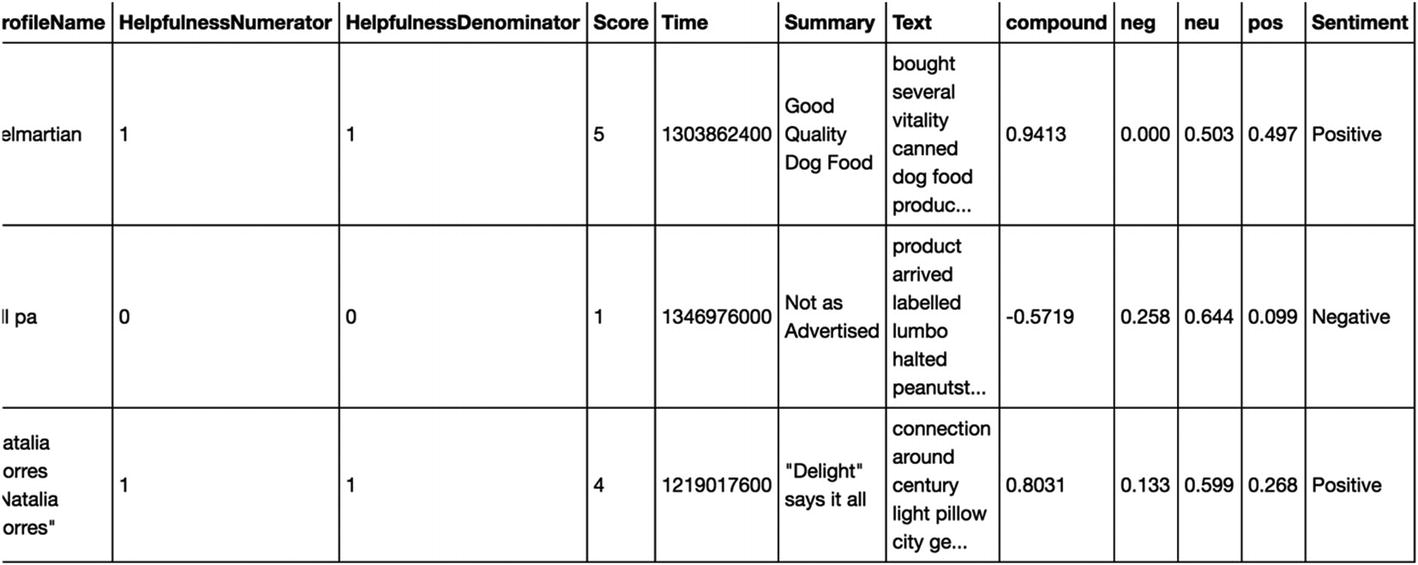
Step 2-7 Business insights
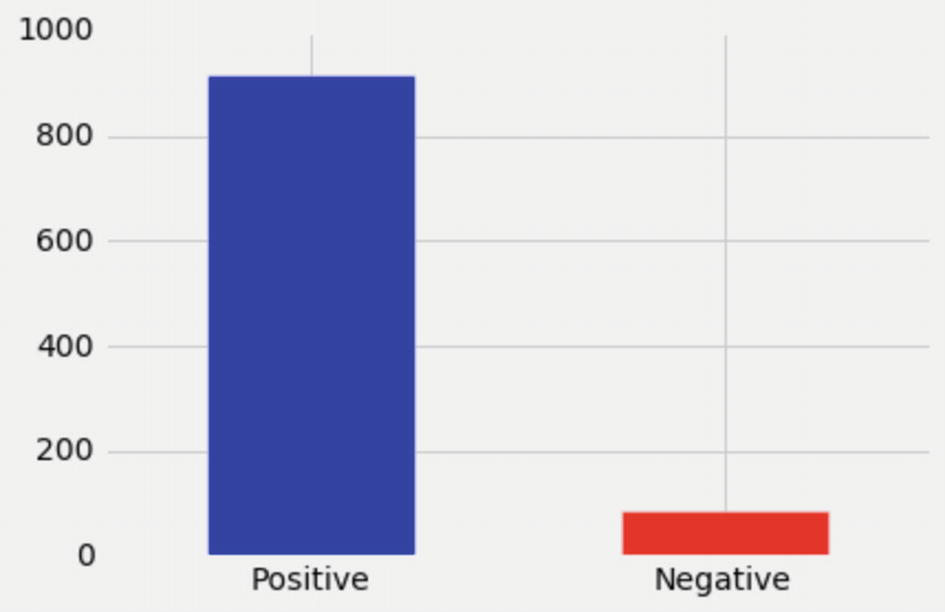
We just took a sample of 1000 reviews and completed sentiment analysis. If you look, more than 900 (>90%) reviews are positive, which is really good for any business.
Similarly, we can analyze sentiments by month using the time column and many other such attributes.
Recipe 5-3. Applying Text Similarity Functions
This recipe covers data stitching using text similarity.
Problem
Customer information scattered across multiple tables and systems.
No global key to link them all together.
A lot of variations in names and addresses.
Solution
This can be solved by applying text similarity functions on the demographic’s columns like the first name, last name, address, etc. And based on the similarity score on a few common columns, we can decide either the record pair is a match or not a match.
How It Works
Let’s follow the steps in this section to link the records.
Huge records that need to be linked/stitched/deduplicated.
Records come from various systems with differing schemas.
Multiple records of the same customer at the same table, and you want to dedupe.
Records of same customers from multiple tables need to be merged.
For Recipe 3-A, let’s solve scenario 1 that is deduplication and as a part of Recipe 3-B, let’s solve scenario 2 that is record linkage from multiple tables.
Deduplication in the same table
Step 3A-1 Read and understand the data
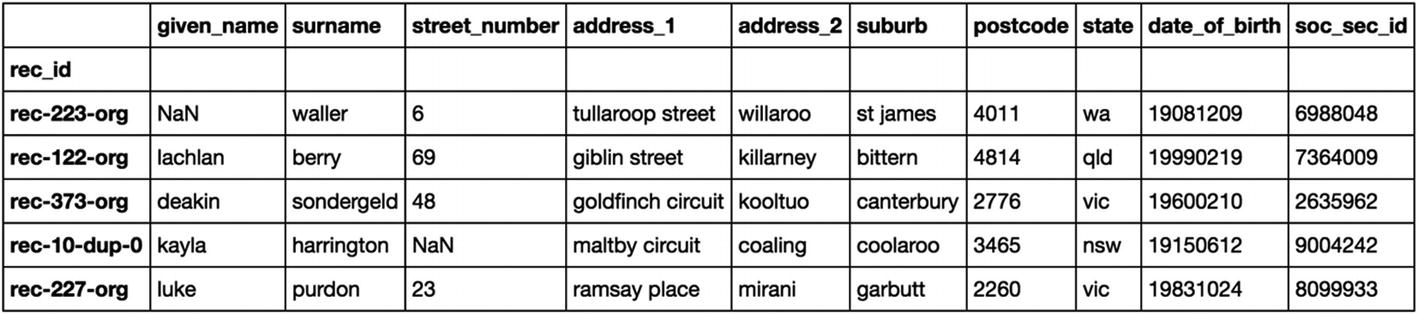
Step 3A-2 Blocking
Here we reduce the comparison window and create record pairs.
Suppose there are huge records say, 100M records means (100M choose 2) ≈ 10^16 possible pairs
Need heuristic to quickly cut that 10^16 down without losing many matches
Record: first name: John, last name: Roberts, address: 20 Main St Plainville MA 01111
Blocking key: first name - John
Will be paired with: John Ray … 011
Won’t be paired with: Frank Sinatra … 07030
Generate pairs only for records in the same block
Below is the blocking example at a glance: here blocking is done on the “Sndx-SN,” column which is nothing but the Soundex value of the surname column as discussed in the previous chapter.
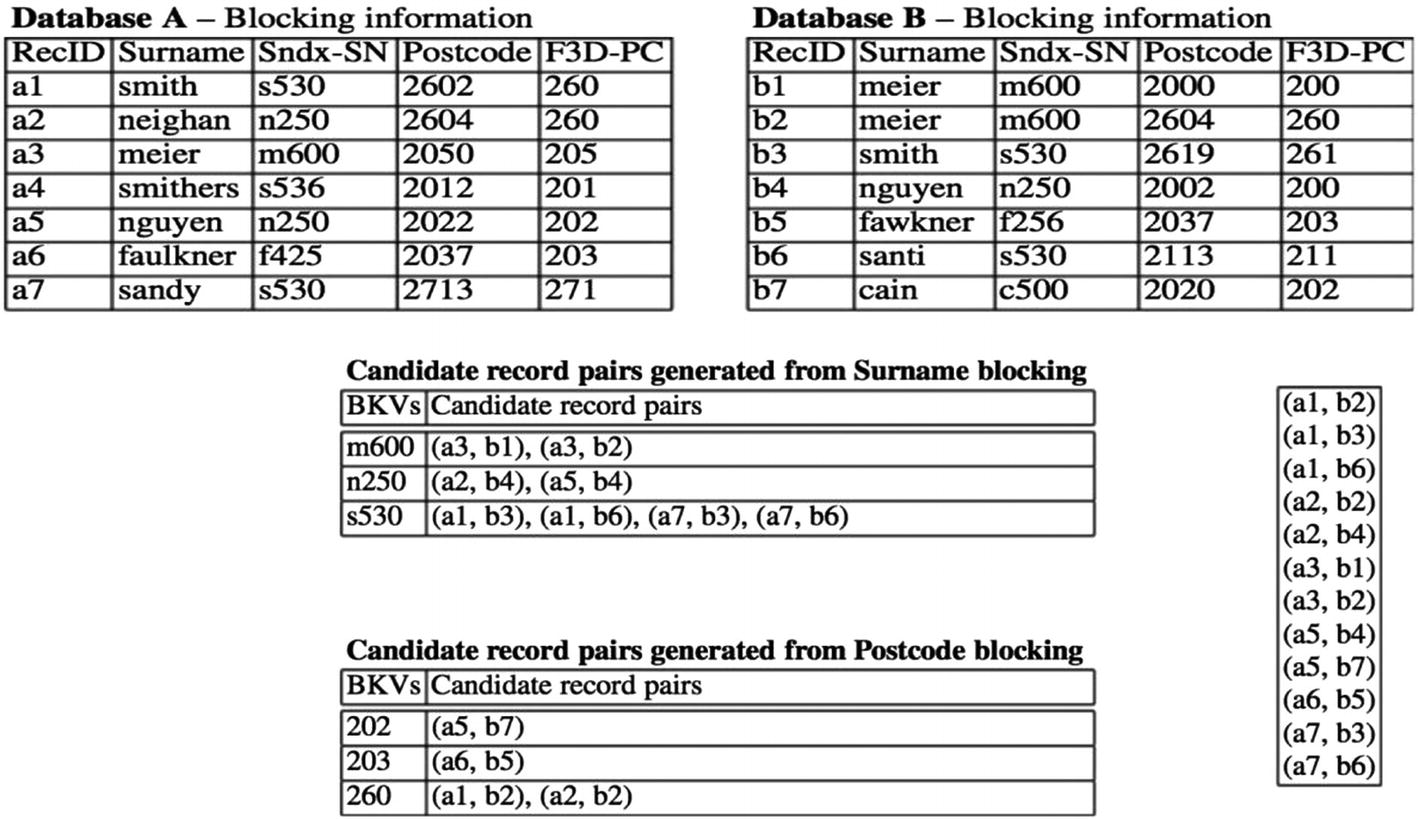
- Standard blocking
Single column
Multiple columns
Sorted neighborhood
Q-gram: fuzzy blocking
LSH
Canopy clustering
Step 3A-3 Similarity matching and scoring
Here we compute the similarity scores on the columns like given name, surname, and address between the record pairs generated in the previous step. For columns like date of birth, suburb, and state, we are using the exact match as it is important for this column to possess exact records.
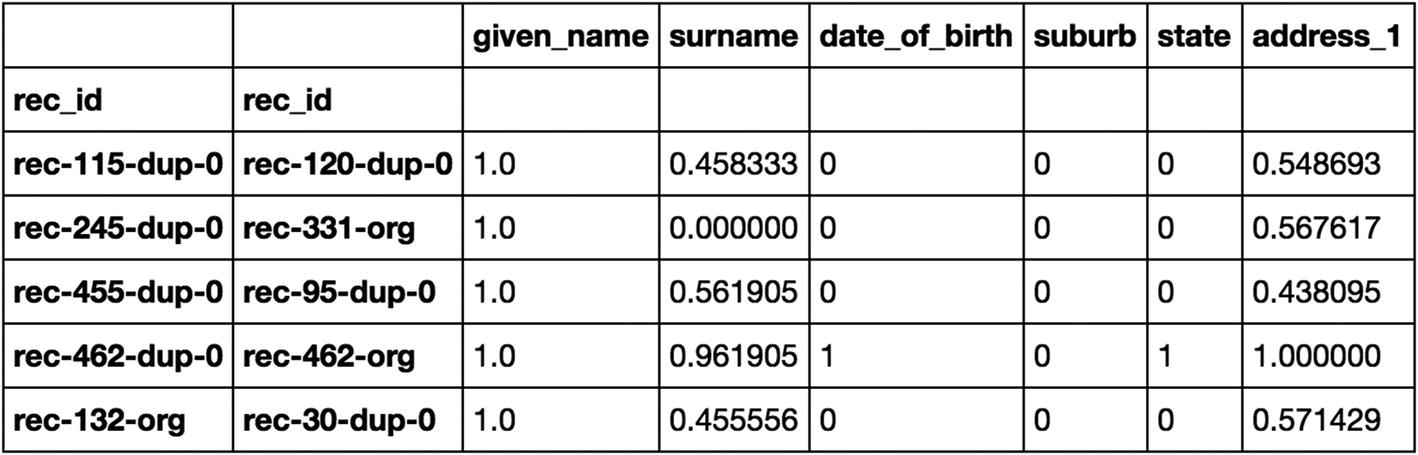
So here record “rec-115-dup-0” is compared with “rec-120-dup-0.” Since their first name (blocking column) is matching, similarity scores are calculated on the common columns for these pairs.
Step 3A-4 Predicting records match or do not match using ECM – classifier
The output clearly shows that “rec-183-dup-0” matches “rec-183-org” and can be linked to one global_id. What we have done so far is deduplication: identifying multiple records of the same users from the individual table.
Records of same customers from multiple tables
Next, let us look at how we can solve this problem if records are in multiple tables without unique ids to merge with.
Step 3B-1 Read and understand the data
Step 3B-2 Blocking – to reduce the comparison window and creating record pairs
Step 3B-3 Similarity matching
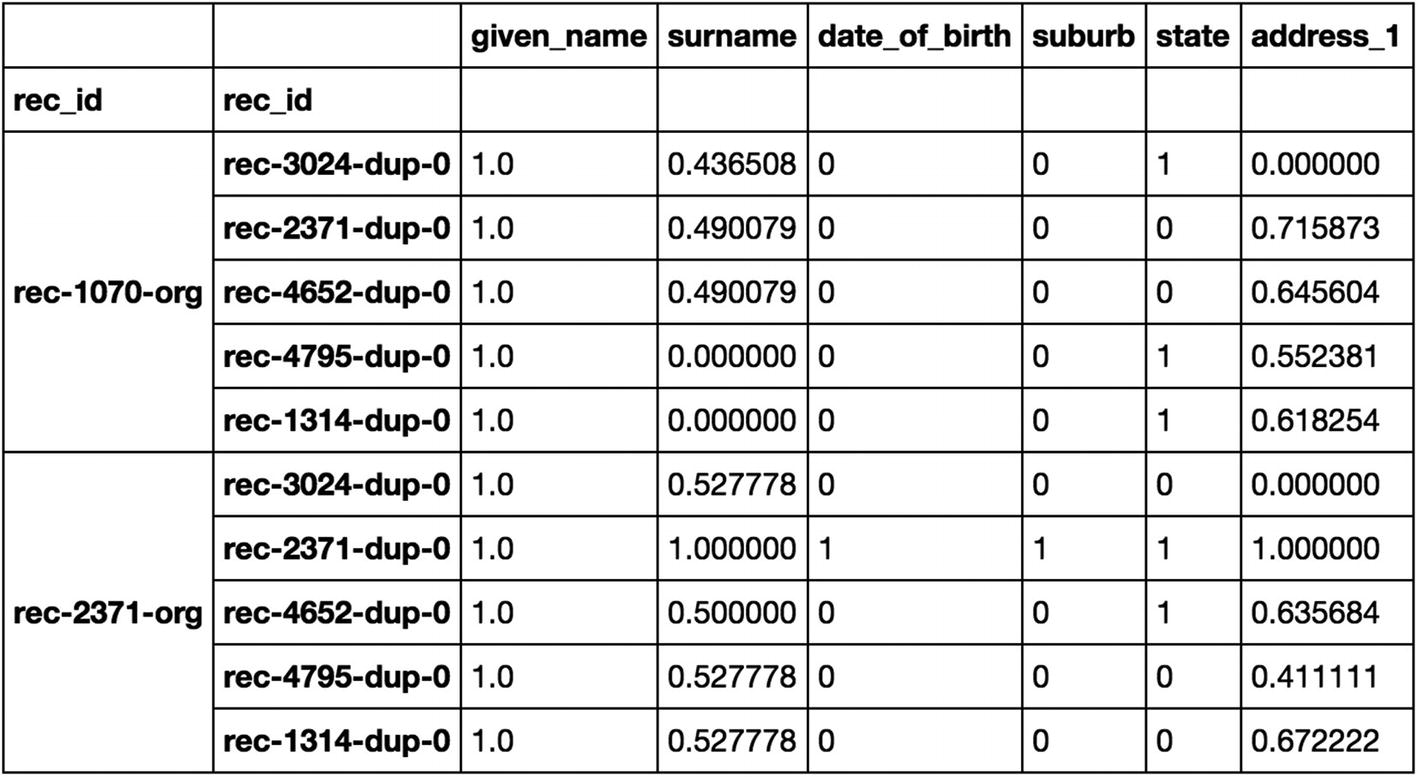
So here record “rec-1070-org” is compared with “rec-3024-dup-0,” “rec-2371-dup-0,” “rec-4652-dup-0,” “rec-4795-dup-0,” and “rec-1314-dup-0, since their first name (blocking column) is matching and similarity scores are calculated on the common columns for these pairs.
Step 3B-4 Predicting records match or do not match using ECM – classifier
The output clearly shows that “rec-122-dup-0” matches “rec-122-org” and can be linked to one global_id.
In this way, you can create a data lake consisting of a unique global id and consistent data across tables and also perform any kind of statistical analysis.
Recipe 5-4. Summarizing Text Data
If you just look around, there are lots of articles and books available. Let’s assume you want to learn a concept in NLP and if you Google it, you will find an article. You like the content of the article, but it’s too long to read it one more time. You want to basically summarize the article and save it somewhere so that you can read it later.
Well, NLP has a solution for that. Text summarization will help us do that. You don’t have to read the full article or book every time.
Problem
Text summarization of article/document using different algorithms in Python.
Solution
TextRank: A graph-based ranking algorithm
Feature-based text summarization
LexRank: TF-IDF with a graph-based algorithm
Topic based
Using sentence embeddings
Encoder-Decoder Model: Deep learning techniques
How It Works
We will explore the first 2 approaches in this recipe and see how it works.
Method 4-1 TextRank
TextRank is the graph-based ranking algorithm for NLP. It is basically inspired by PageRank, which is used in the Google search engine but particularly designed for text. It will extract the topics, create nodes out of them, and capture the relation between nodes to summarize the text.
Let’s see how to do it using the Python package Gensim. “Summarize” is the function used.
Method 4-2 Feature-based text summarization
Your feature-based text summarization methods will extract a feature from the sentence and check the importance to rank it. Position, length, term frequency, named entity, and many other features are used to calculate the score.
Problem solved. Now you don’t have to read the whole notes; just read the summary whenever we are running low on time.
We can use many of the deep learning techniques to get better accuracy and better results like the Encoder-Decoder Model. We will see how to do that in the next chapter.
Recipe 5-5. Clustering Documents
Document clustering, also called text clustering, is a cluster analysis on textual documents. One of the typical usages would be document management.
Problem
Clustering or grouping the documents based on the patterns and similarities.
Solution
- 1.
Tokenization
- 2.
Stemming and lemmatization
- 3.
Removing stop words and punctuation
- 4.
Computing term frequencies or TF-IDF
- 5.
Clustering: K-means/Hierarchical; we can then use any of the clustering algorithms to cluster different documents based on the features we have generated
- 6.
Evaluation and visualization: Finally, the clustering results can be visualized by plotting the clusters into a two-dimensional space
How It Works
Step 5-1 Import data and libraries
Step 5-2 Preprocessing and TF-IDF feature engineering
Step 5-3 Clustering using K-means
Step 5-4 Identify cluster behavior
Step 5-5 Plot the clusters on a 2D graph

That’s it. We have clustered 200 complaints into 6 groups using K-means clustering. It basically clusters similar kinds of complaints to 6 buckets using TF-IDF. We can also use the word embeddings and solve this to achieve better clusters. 2D graphs provide a good look into the cluster's behavior and if we look, we will see that the same color dots (docs) are located closer to each other.
Recipe 5-6. NLP in a Search Engine
In this recipe, we are going to discuss what it takes to build a search engine from an NLP standpoint. Implementation of the same is beyond the scope of this book.
Problem
You want to know the architecture and NLP pipeline to build a search engine.
Solution
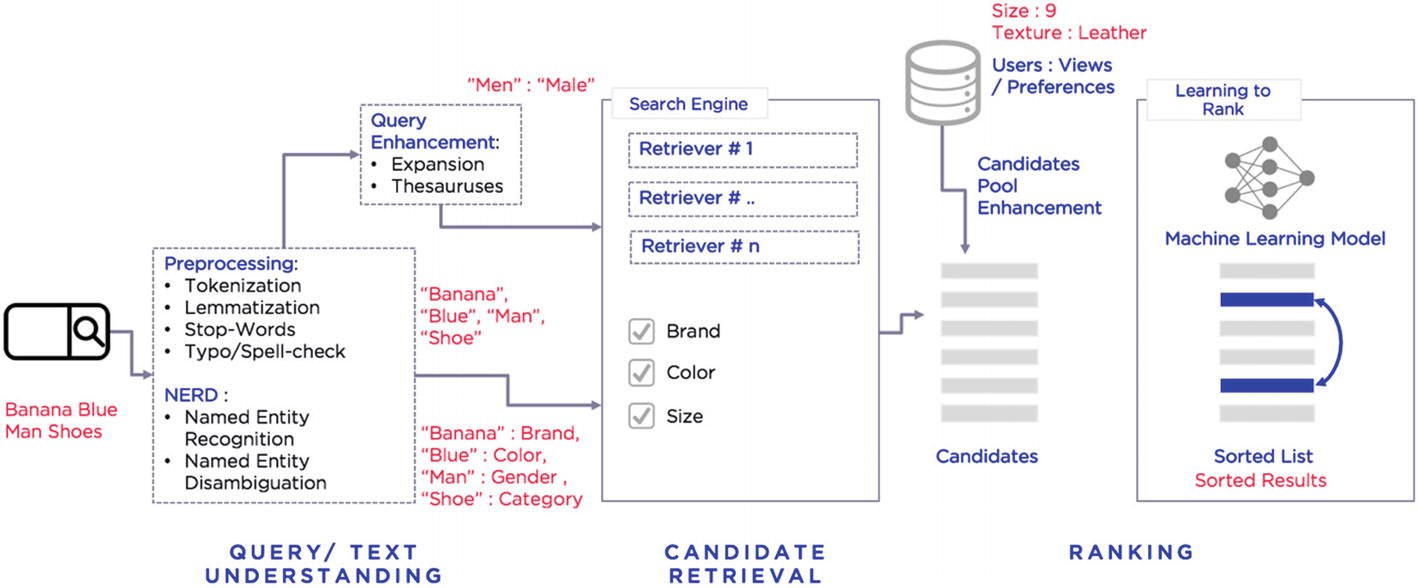
The NLP process in a search engine
How It Works
Let’s follow and understand the above architecture step by step in this section to build the search engine from an NLP standpoint.
Step 6-1 Preprocessing
- 1.
Removal of noise and stop words
- 2.
Tokenization
- 3.
Stemming
- 4.
Lemmatization
Step 6-2 The entity extraction model
Output from the above pipeline is fed into the entity extraction model . We can build the customized entity recognition model by using any of the libraries like StanfordNER or NLTK.
Or you can build an entity recognition model from scratch using conditional random fields or Markov models.
Gender
Color
Brand
Product Category
Product Type
Price
Size
Also, we can build named entity disambiguation using deep learning frameworks like RNN and LSTM. This is very important for the entities extractor to understand the content in which the entities are used. For example, pink can be a color or a brand. NED helps in such disambiguation.
Data cleaning and preprocessing
Training NER Model
Testing and Validation
Deployment
Named Entity Recognition and Disambiguation
Stanford NER with customization
Recurrent Neural Network (RNN) – LSTM (Long Short-Term Memory) to use context for disambiguation
Joint Named Entity Recognition and Disambiguation
Step 6-3 Query enhancement/expansion
It is very important to understand the possible synonyms of the entities to make sure search results do not miss out on potential relevance. Say, for example, men’s shoes can also be called as male shoes, men’s sports shoes, men’s formal shoes, men’s loafers, men’s sneakers.
Use locally-trained word embedding (using Word2Vec / GloVe Model ) to achieve this.
Step 6-4 Use a search platform
Search platforms such as Solr or Elastic Search have major features that include full-text search hit highlighting, faceted search, real-time indexing, dynamic clustering, and database integration. This is not related to NLP; as an end-to-end application point of view, we have just given an introduction of what this is.
Step 6-5 Learning to rank
Once the search results are fetched from Solr or Elastic Search, they should be ranked based on the user preferences using the past behaviors.