
Recipe 1. Information retrieval using deep learning
Recipe 2. Text classification using CNN, RNN, LSTM
Recipe 3. Predicting the next word/sequence of words using LSTM for Emails
Introduction to Deep Learning
Deep learning is a subfield of machine learning that is inspired by the function of the brain. Just like how neurons are interconnected in the brain, neural networks also work the same. Each neuron takes input, does some kind of manipulation within the neuron, and produces an output that is closer to the expected output (in the case of labeled data).
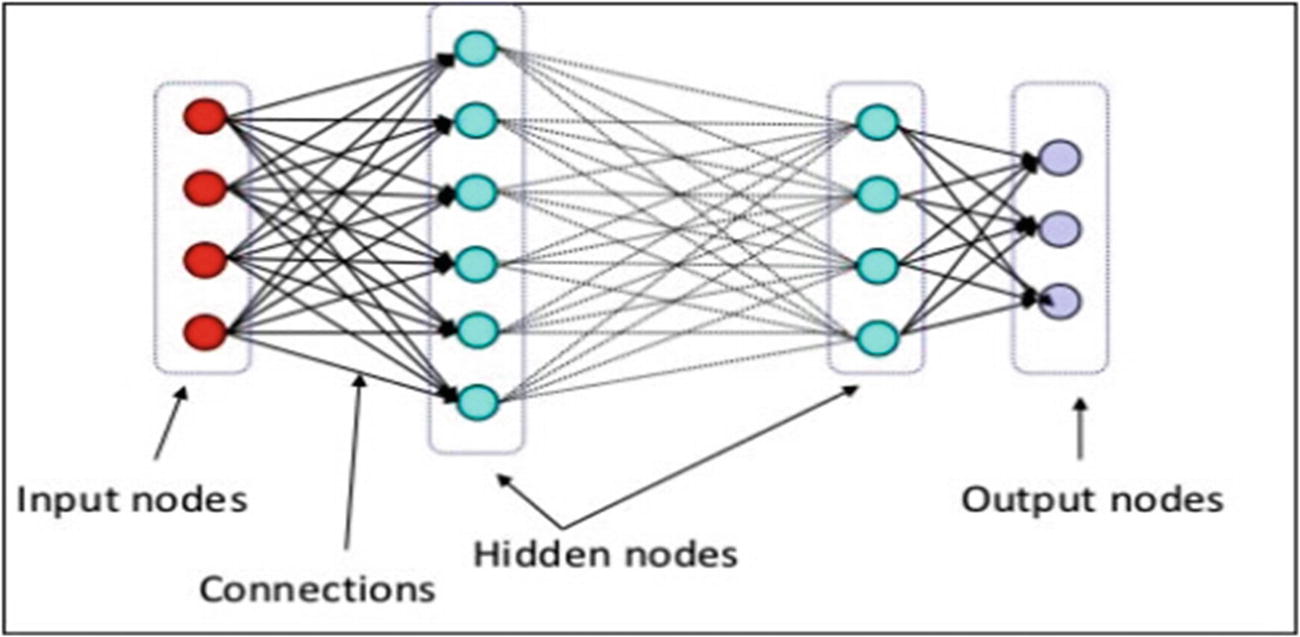
What happens within the neuron is what we are interested in: to get to the most accurate results. In very simple words, it’s giving weight to every input and generating a function to accumulate all these weights and pass it onto the next layer, which can be the output layer eventually.
Input layer
Hidden layer/layers
Output layer
Linear Activation functions: A linear neuron takes a linear combination of the weighted inputs; and the output can take any value between -infinity to infinity.
- Nonlinear Activation function: These are the most used ones, and they make the output restricted between some range:
Sigmoid or Logit Activation Function: Basically, it scales down the output between 0 and 1 by applying a log function, which makes the classification problems easier.
Softmax function: Softmax is almost similar to sigmoid, but it calculates the probabilities of the event over ‘n’ different classes, which will be useful to determine the target in multiclass classification problems.
Tanh Function: The range of the tanh function is from (-1 to 1), and the rest remains the same as sigmoid.
Rectified Linear Unit Activation function: ReLU converts anything that is less than zero to zero. So, the range becomes 0 to infinity.
We still haven’t discussed how training is carried out in neural networks. Let’s do that by taking one of the networks as an example, which is the convolutional neural network.
Convolutional Neural Networks
Convolutional Neural Networks (CNN) are similar to ordinary neural networks but have multiple hidden layers and a filter called the convolution layer. CNN is successful in identifying faces, objects, and traffic signs and also used in self-driving cars.
Data
Image: Computer takes an image as an array of pixel values. Depending on the resolution and size of the image, it will see an X Y x Z array of numbers. For example, there is a color image and its size is 480 x 480 pixels. The representation of the array will be 480 x 480 x 3 where 3 is the RGB value of the color. Each of these numbers varies from 0 to 255, which describes the pixel intensity/density at that point. The concept is that if given the computer and this array of numbers, it will output the probability of the image being a certain class in case of a classification problem.
Text: We already discussed throughout the book how to create features out of the text. We can use any of those techniques to convert text to features. RNN and LSTM are suited better for text-related solutions that we will discuss in the next sections.
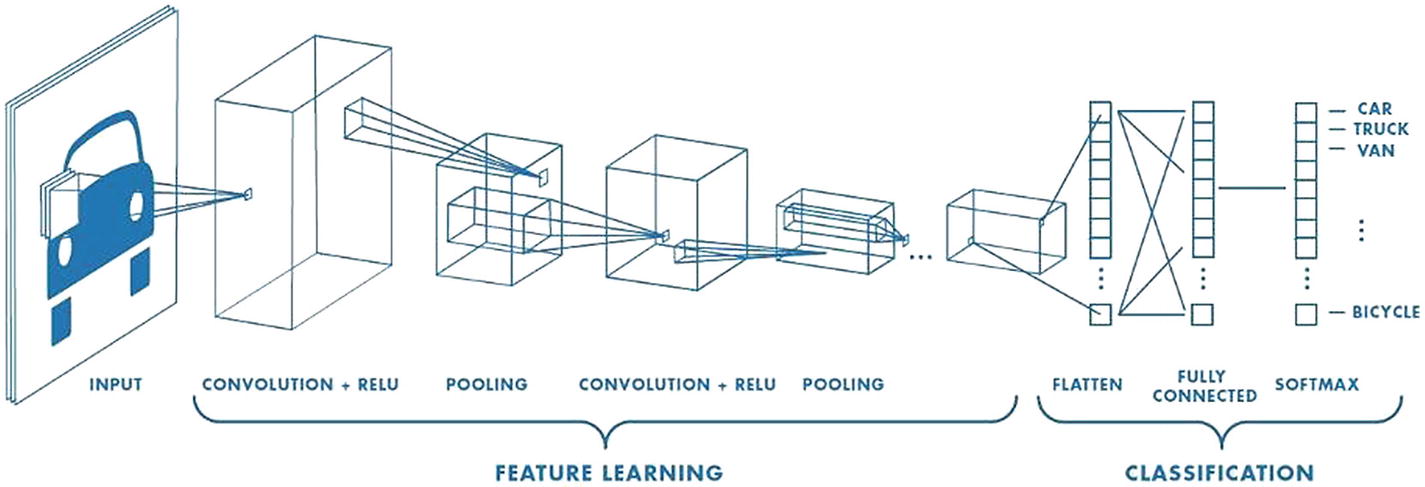
Architecture
CNN is a special case of a neural network with an input layer, output layer, and multiple hidden layers. The hidden layers have 4 different procedures to complete the network. Each one is explained in detail.
Convolution
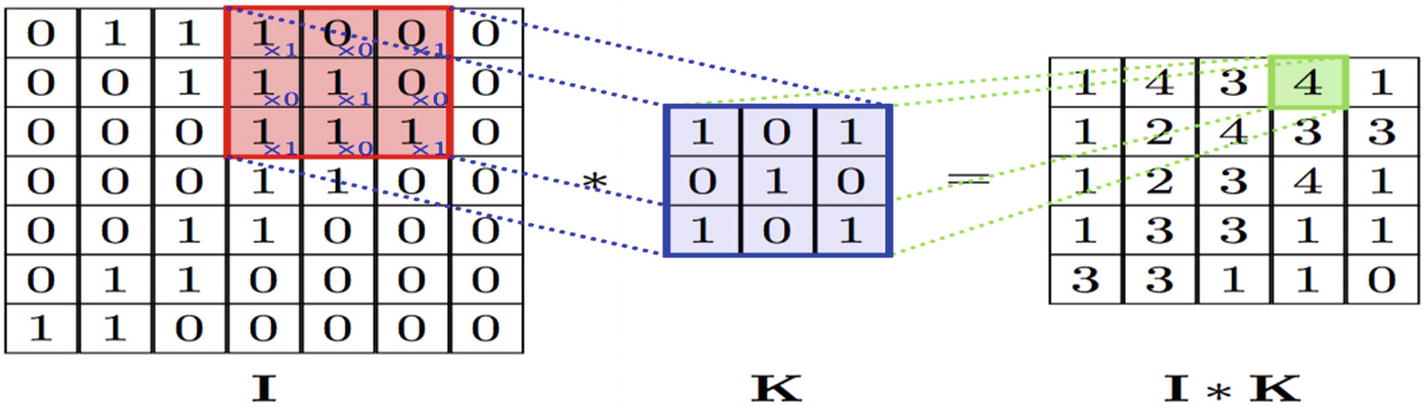
The Convolution layer is the heart of a Convolutional Neural Network, which does most of the computational operations. The name comes from the “convolution” operator that extracts features from the input image. These are also called filters (Orange color 3*3 matrix). The matrix formed by sliding the filter over the full image and calculating the dot product between these 2 matrices is called the ‘Convolved Feature’ or ‘Activation Map’ or the ‘Feature Map’. Suppose that in table data, different types of features are calculated like “age” from “date of birth.” The same way here also, straight edges, simple colors, and curves are some of the features that the filter will extract from the image.
During the training of the CNN, it learns the numbers or values present inside the filter and uses them on testing data. The greater the number of features, the more the image features get extracted and recognize all patterns in unseen images.
Nonlinearity (ReLU)

ReLU (Rectified Linear Unit) is a nonlinear function that is used after a convolution layer in CNN architecture. It replaces all negative values in the matrix to zero. The purpose of ReLU is to introduce nonlinearity in the CNN to perform better.
Pooling
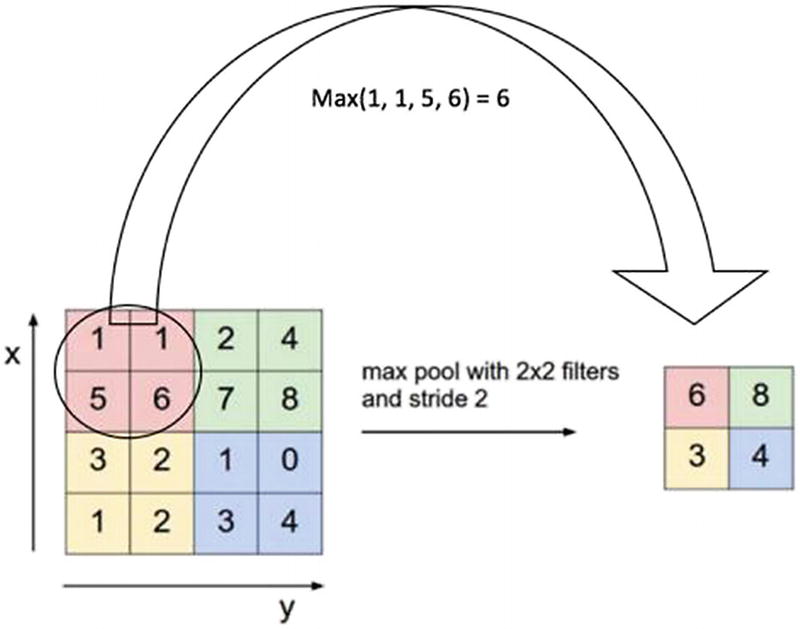
Pooling or subsampling is used to decrease the dimensionality of the feature without losing important information. It’s done to reduce the huge number of inputs to a full connected layer and computation required to process the model. It also helps to reduce the overfitting of the model. It uses a 2 x 2 window and slides over the image and takes the maximum value in each region as shown in the figure. This is how it reduces dimensionality.
Flatten, Fully Connected, and Softmax Layers
The last layer is a dense layer that needs feature vectors as input. But the output from the pooling layer is not a 1D feature vector. This process of converting the output of convolution to a feature vector is called flattening. The Fully Connected layer takes an input from the flatten layer and gives out an N-dimensional vector where N is the number of classes. The function of the fully connected layer is to use these features for classifying the input image into various classes based on the loss function on the training dataset. The Softmax function is used at the very end to convert these N-dimensional vectors into a probability for each class, which will eventually classify the image into a particular class.
Backpropagation: Training the Neural Network
In normal neural networks, you basically do Forward Propagation to get the output and check if this output is correct and calculate the error. In Backward Propagation, we are going backward through your network that finds the partial derivatives of the error with respect to each weight.
Let’s see how exactly it works.
The input image is fed into the network and completes forward propagation, which is convolution, ReLU, and pooling operations with forward propagation in the fully Connected layer and generates output probabilities for each class. As per the feed forward rule, weights are randomly assigned and complete the first iteration of training and also output random probabilities. After the end of the first step, the network calculates the error at the output layer using
Total Error = ∑ ½ (target probability – output probability) 2
Now, your backpropagation starts to calculate the gradients of the error with respect to all weights in the network and use gradient descent to update all filter values and weights, which will eventually minimize the output error. Parameters like the number of filters, filter sizes, and the architecture of the network will be finalized while building your network. The filter matrix and connection weights will get updated for each run. The whole process is repeated for the complete training set until the error is minimized.
Recurrent Neural Networks
CNNs are basically used for computer vision problems but fail to solve sequence models. Sequence models are those where even a sequence of the entity also matters. For example, in the text, the order of the words matters to create meaningful sentences. This is where RNNs come into the picture and are useful with sequential data because each neuron can use its memory to remember information about the previous step.
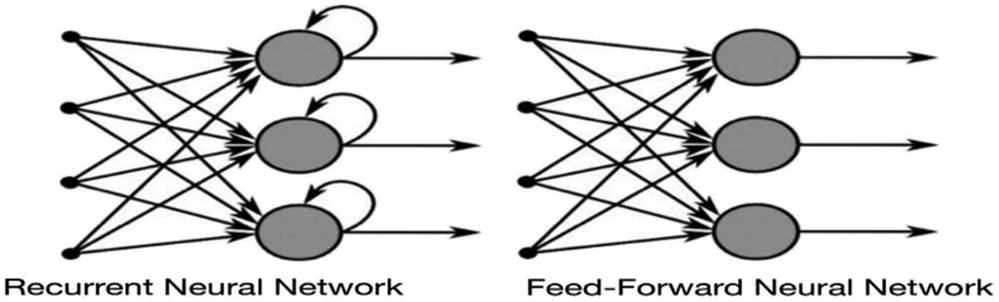
It is quite complex to understand how exactly RNN is working. If you see the above figure, the recurrent neural network is taking the output from the hidden layer and sending it back to the same layer before giving the prediction.
Training RNN – Backpropagation Through Time (BPTT)
We know how feed forward and backpropagation work from CNN, so let’s see how training is done in case of RNN.
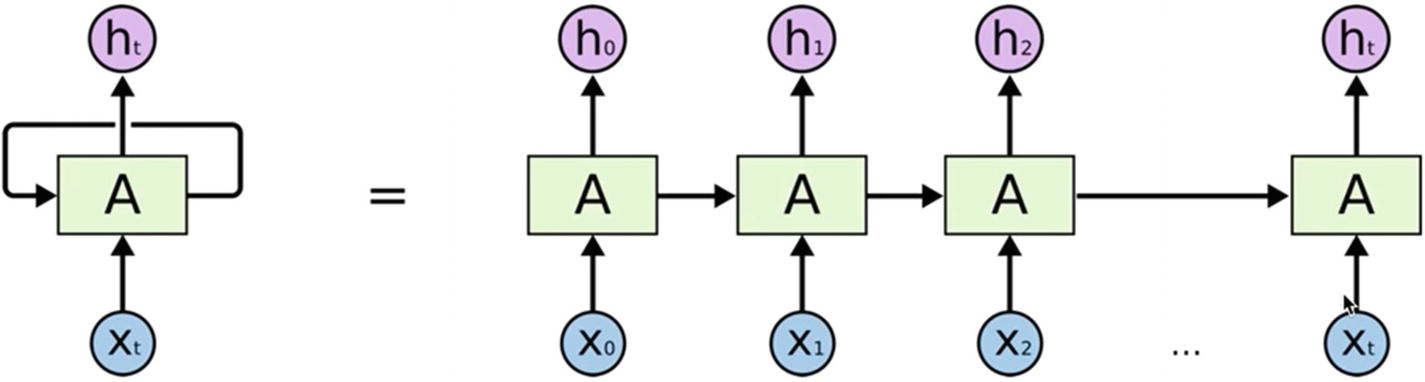
If we just discuss the hidden layer, it’s not only taking input from the hidden layer, but we can also add another input to the same hidden layer. Now the backpropagation happens like any other previous training we have seen; it’s just that now it is dependent on time. Here error is backpropagated from the last timestamp to the first through unrolling the hidden layers. This allows calculating the error for each timestamp and updating the weights. Recurrent networks with recurrent connections between hidden units read an entire sequence and then produce a required output.
When the values of a gradient are too small and the model takes way too long to learn, this is called Vanishing Gradients. This problem is solved by LSTMs.
Long Short-Term Memory (LSTM)
LSTMs are a kind of RNNs with betterment in equation and backpropagation, which makes it perform better. LSTMs work almost similarly to RNN, but these units can learn things with very long time gaps, and they can store information just like computers.
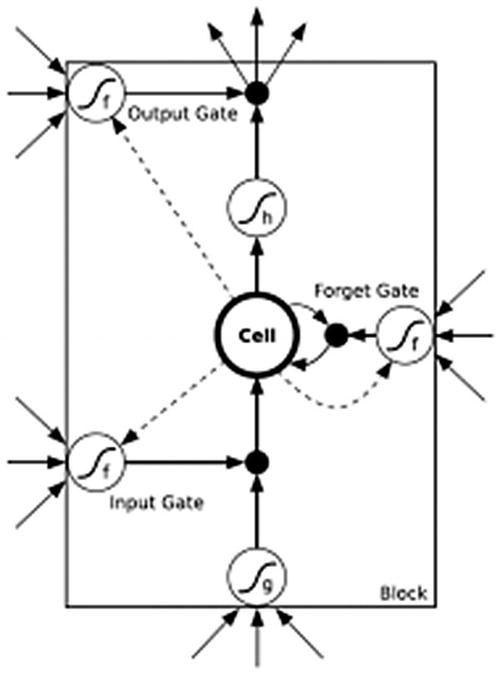
The algorithm learns the importance of the word or character through weighing methodology and decides whether to store it or not. For this, it uses regulated structures called gates that have the ability to remove or add information to the cell. These cells have a sigmoid layer that decides how much information should be passed. It has three layers, namely “input,” “forget,” and “output” to carry out this process.
Going in depth on how CNN and RNNs work is beyond the scope of this book. We have mentioned references at the end of the book if anyone is interested in learning about this in more depth.
Recipe 6-1. Retrieving Information
Information retrieval is one of the highly used applications of NLP and it is quite tricky. The meaning of the words or sentences not only depends on the exact words used but also on the context and meaning. Two sentences may be of completely different words but can convey the same meaning. We should be able to capture that as well.
An information retrieval (IR) system allows users to efficiently search documents and retrieve meaningful information based on a search text/query.
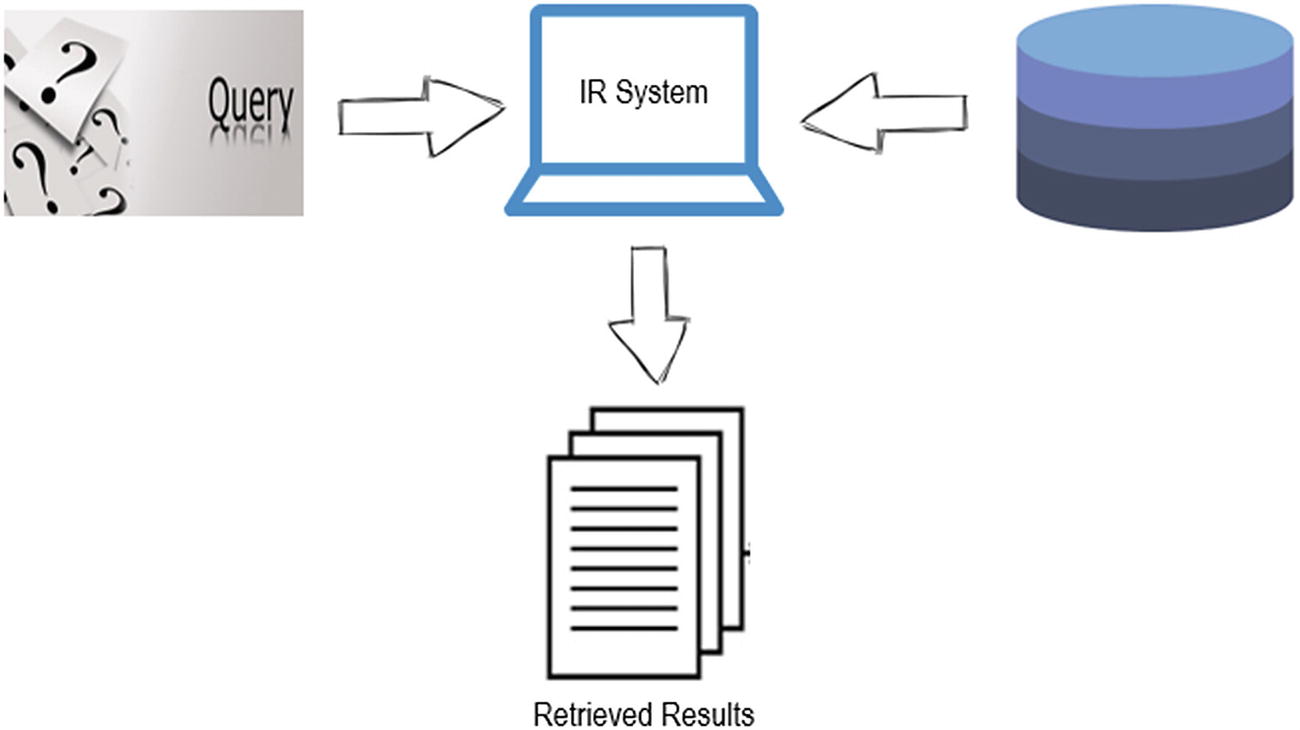
Problem
Information retrieval using word embeddings.
Solution
There are multiple ways to do Information retrieval. But we will see how to do it using word embeddings, which is very effective since it takes context also into consideration. We discussed how word embeddings are built in Chapter 3. We will just use the pretrained word2vec in this case.
How It Works
Step 1-1 Import the libraries
Step 1-2 Create/import documents
Step 1-3 Download word2vec
Step 1-4 Create IR system
Step 1-5 Results and applications
If you see, doc4 (on top in result), this will be most relevant for the query “cricket” even though the word “cricket” is not even mentioned once with the similarity of 0.449.
Again, since driving is connected to transport and the Motor Vehicles Act, it pulls out the most relevant documents on top. The first 2 documents are relevant to the query.
We can use the same approach and scale it up for as many documents as possible. For more accuracy, we can build our own embeddings, as we learned in Chapter 3, for specific industries since the one we are using is generalized.
Search engines
Document retrieval
Passage retrieval
Question and answer
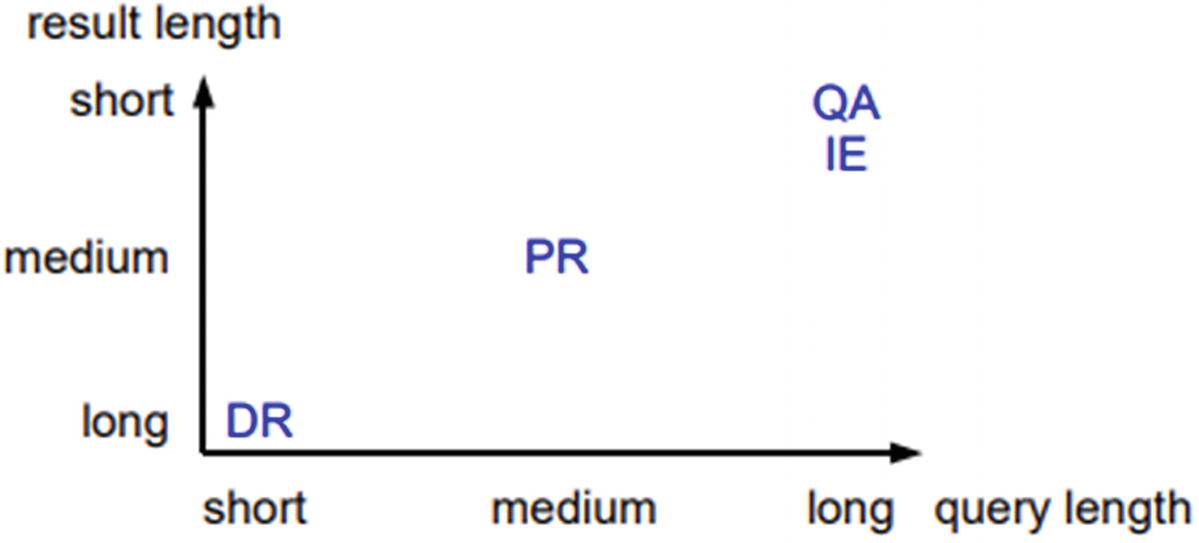
It’s been proven that results will be good when queries are longer and the result length is shorter. That’s the reason we don’t get great results in search engines when the search query has lesser number of words.
Recipe 6-2. Classifying Text with Deep Learning
In this recipe, let us build a text classifier using deep learning approaches.
Problem
We want to build a text classification model using CNN, RNN, and LSTM.
Solution
The approach and NLP pipeline would remain the same as discussed earlier. The only change would be that instead of using machine learning algorithms, we would be building models using deep learning algorithms.
How It Works
Let’s follow the steps in this section to build the email classifier using the deep learning approaches.
Step 2-1 Understanding/defining business problem
Email classification (spam or ham) . We need to classify spam or ham email based on email content.
Step 2-2 Identifying potential data sources, collection, and understanding
Step 2-3 Text preprocessing
Step 2-4 Data preparation for model building
Step 2-5 Model building and predicting
We are building the models using different deep learning approaches like CNN, RNN, LSTM, and Bidirectional LSTM and comparing the performance of each model using different accuracy metrics.
We can now define our CNN model.

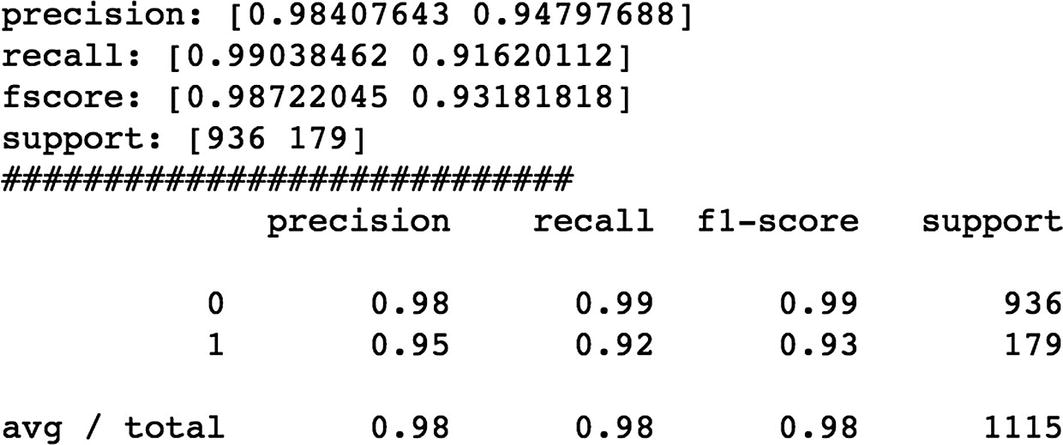

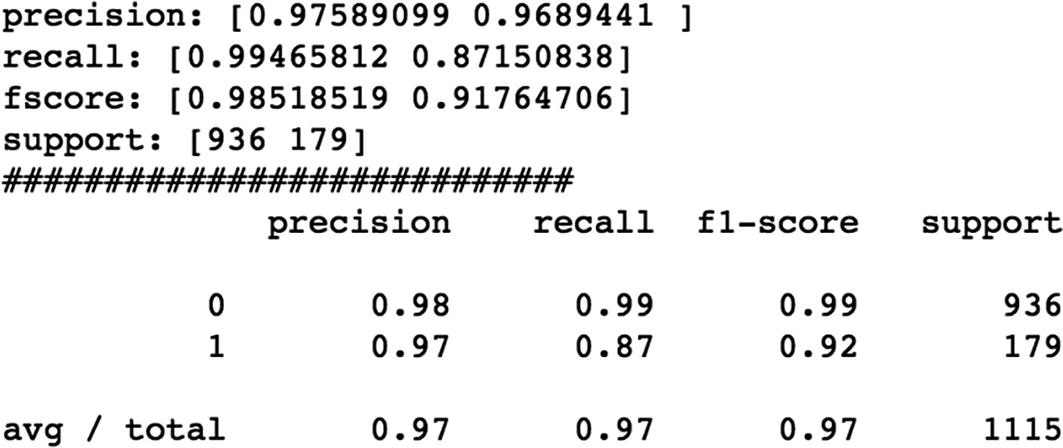

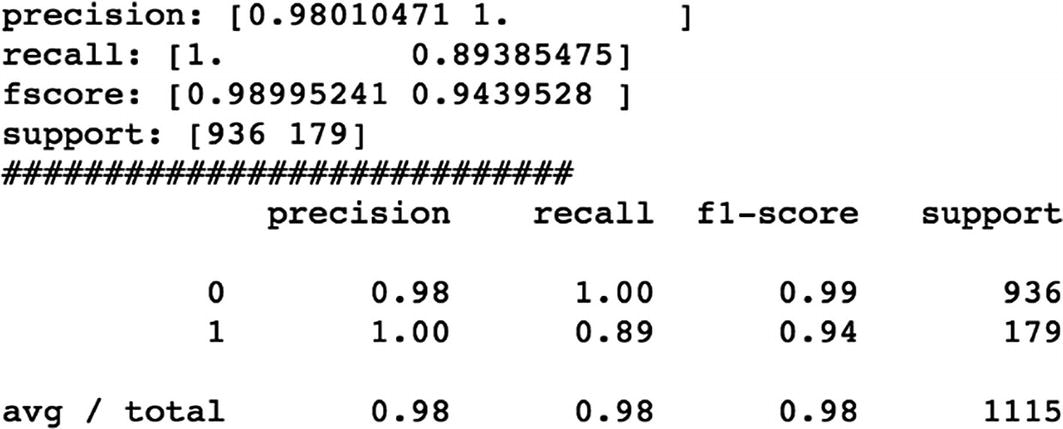
Finally, let’s see what is Bidirectional LSTM and implement the same.

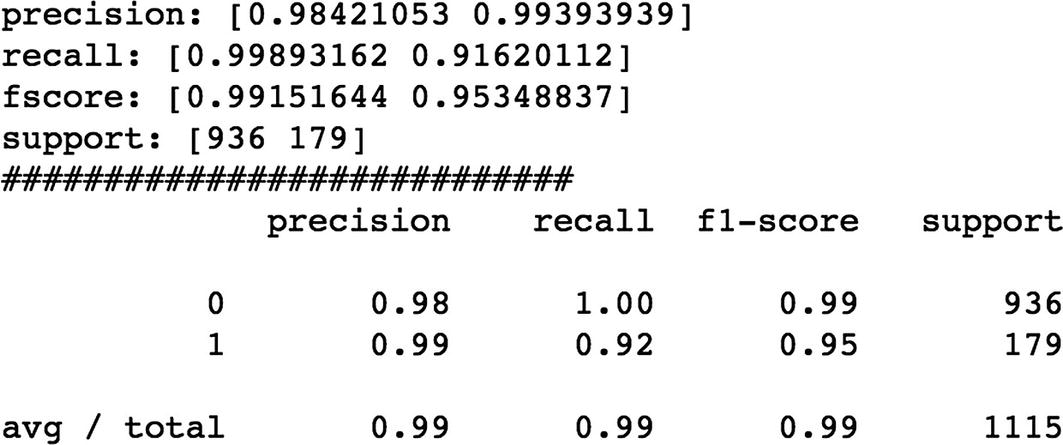
We can see that Bidirectional LSTM outperforms the rest of the algorithms.
Recipe 6-3. Next Word Prediction
Autofill/showing what could be the potential sequence of words saves a lot of time while writing emails and makes users happy to use it in any product.
Problem
You want to build a model to predict/suggest the next word based on a previous sequence of words using Email Data.
Like you see in the below image, language is being suggested as the next word.
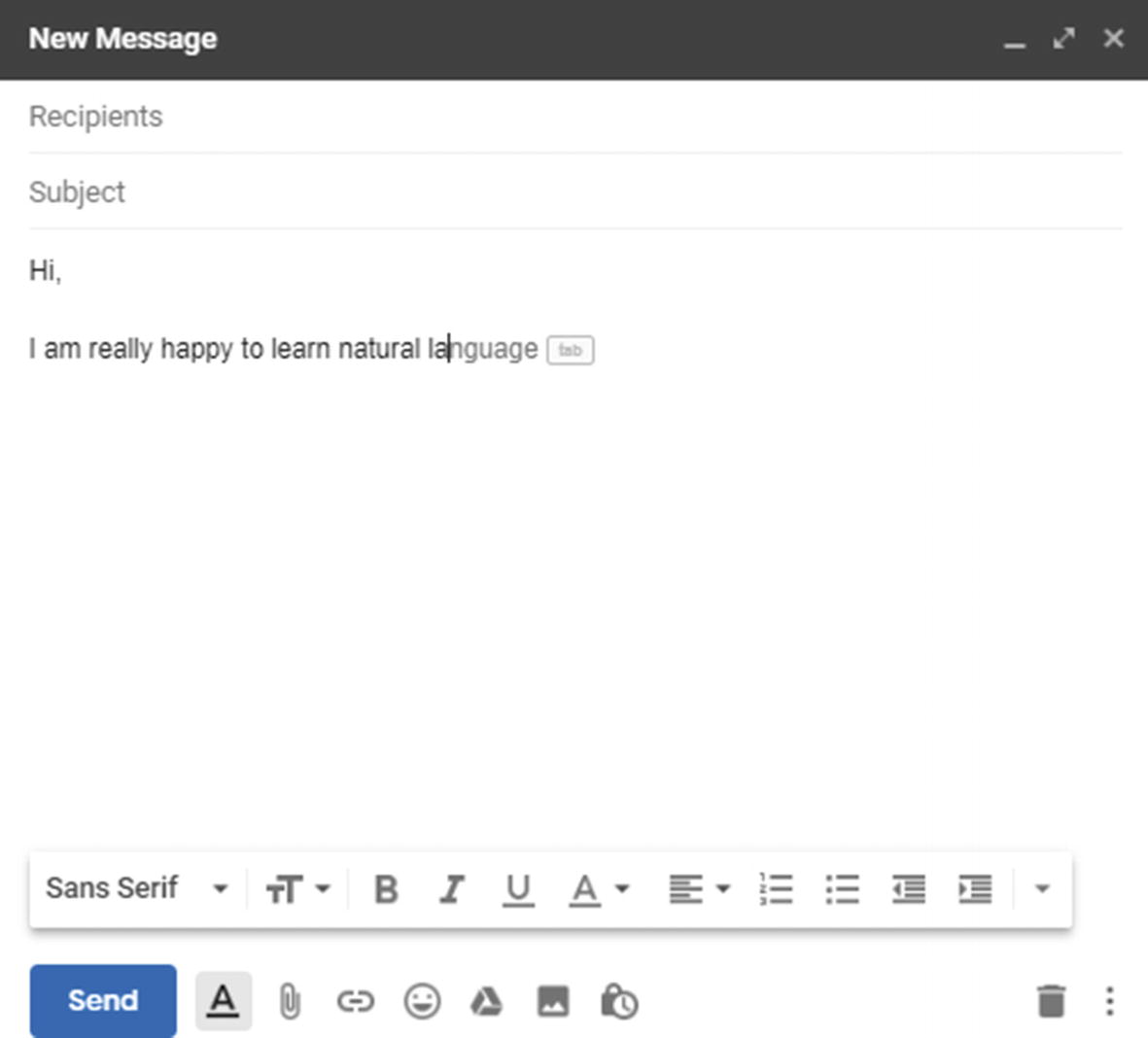
Solution
In this section, we will build an LSTM model to learn sequences of words from email data. We will use this model to predict the next word.
How It Works
Let's follow the steps in this section to build the next word prediction model using the deep learning approach.
Step 3-1 Understanding/defining business problem
Predict the next word based on the sequence of words or sentences.
Step 3-2 Identifying potential data sources, collection, and understanding
Step 3-3 Importing and installing necessary libraries
Step 3-4 Processing the data
Step 3-5 Data preparation for modeling
Step 3-6 Model building
Note
We have not split the data into training and testing data. We are not interested in the accurate model. As we all know, deep learning models will require a lot of data for training and take a lot of time to train, so we are using a model checkpoint to capture all of the model weights to file. We will use the best set of weights for our prediction.

Step 3-7 Predicting next word
So, given the 25 input words, it's predicting the word “shut” as the next word. Of course, its not making much sense, since it has been trained on much less data and epochs. Make sure you have great computation power and train on huge data with high number of epochs.