
Chapter 1 explained that a functional language like Haskell is characterized by its profuse use of functions as parameters or return values. However, Chapter 2 didn’t mention anything about this topic. I’ll rectify that here. In this chapter, you will focus on not one but three ways in which Haskell allows for a great amount of reuse.
One of the ways in which Haskell shines in the area of reusability is through the creation of functions that can work over values of any type that respects a certain form, or design. List functions such as head can operate on any type of the form [T], whatever type T is. This concept is also applicable to data types that can store values on any possible type, which is known as parametric polymorphism .
Another way in which Haskell allows for reuse is this ability of using functions as any other value of the language. Functions that manipulate other functions are called higher-order functions. In contrast, the concepts in the previous chapter belong to first-order Haskell.
The third way in which code can be reused (and shared) is by taking functions or data types from one module and applying them in another. You will learn how to do that from both sides: exporting definitions to make them available and importing them later.
Most of the examples in this chapter focus on lists and the functions in the module Data.List. The intention is twofold: lists illustrate the new concepts to be introduced, and at the same time they are practical tools in daily programming with Haskell. As proof of their importance, the language includes special syntax to create and manage them, namely, the syntax of comprehensions. I’ll explain how to use the syntax before moving to the last stop of the list train: how to fold and unfold lists properly.
Parametric Polymorphism
You may have noticed that in previous chapters all the functions defined operated on some particular data type. However, some built-in functions such as head or empty seem to be able to operate on any kind of list: [Integer], [Client], and so forth. A fair question is, are list functions somehow treated differently by the compiler and interpreter, or do I also have the power to create such functions that can operate on any type? The correct answer is the latter: you could have defined the list functions by yourself with no problem. You do have the power.
In the previous chapter you learned that type names must start with an uppercase letter. However, you can see a lowercase identifier in this particular signature. If you remember the conventions, you know lowercase identifiers are reserved for function definitions, bindings, and parameters. Indeed, that identifier refers to a type variable that can be bound to different types depending on each use.

Inferring the type of head "Hello"
Functions such as head are said to work for any value of the type parameter a: they don’t care about the shape of the inner elements. This is parametric polymorphism, and it allows multiple (“poly”) types (μορφή – morphé is Ancient Greek for “shape”) as parameters. The etymology for the concept is actually a bit misleading because a polymorphic function must work for all types, not just for some. Haskell also allows functions to be applicable for just a subset of all types. That is referred to as ad hoc polymorphism and will be presented in the next chapter.
Note
Parametric polymorphism is available in many programming languages under different names; for example, templates in C++ and generics in Java or C# provide similar functionality.
When you supply a concrete tuple to fst, the type of (a, b) is inferred from the types within that tuple. For example, you can supply the tuple ([3,8], "Hello"), and the type (a, b) becomes ([Integer], [Char]).
Polymorphism is available not only in functions but also in data types. This assumption was implicit when you wrote [T] to refer to a list of any possible type T. As you can see from the examples, a polymorphic type is written with its name along with a list of all its type parameters, like Maybe Integer. The definition of polymorphic types is similar to that of basic types, but after the name of the type, you write the names of the type parameters for that declaration. Later, you can use those names in the constructors in the position of any other type. For example, you may decide to give a unique identifier to each client in your program, but it does not matter which kind of identifier you are using (integers or strings are usual choices) because you never manipulate the identifier directly.
A value like SamePair 1 2 will have type SamePair Integer, not SamePair Integer Integer. Admittedly, the fact that the same identifier is usually reused for both the type name and its constructor adds more confusion to the mix, but it’s something you must get used to. Exercise 3-1 will help you.
Exercise 3-1. A New Life As Type Checker
Remember that you can use GHCi to check your answers. Refer to Chapter 2 if you need a reminder on how to do that.
Functions As Parameters
This is finally the point where we explain how to treat functions as any other value in Haskell. You may already be familiar with this idea, as the concept of “function as parameter” has permeated to many other languages, not necessarily functional. For example, Java or C# includes them as a language feature.
As mentioned at the beginning of the chapter, most of the examples relate to lists. Lists are one of the basic data structures in functional programming, especially while learning. Many more complex concepts, such as functor or fold, are generalizations of patterns that can be found when working with lists.
Higher-Order Functions
Caution
It may be the case that the interpreter shows warning messages about Defaulting the following constraint(s) to type `Integer'. I mentioned in the previous chapter that a constant like 1 is polymorphic on the number type, so the interpreter makes a choice in order to run the code. The warning is telling you that Integer is its default choice. You can safely ignore these warnings, or you can disable them by running the interpreter using ghci -fno-warn-type-defaults. In the rest of the book, I will omit this kind of warning in the output.
You can see the notation for functions, a -> b, but now in the position of a parameter. This type signature encodes the fact that map takes a function from a to b and a list of a’s, and it returns a list of b’s. Functions such as map, which take other functions as parameters, are known as higher-order functions .
Anonymous Functions
Note
The notation ... -> ... comes from a mathematical theory of computation called lambda calculus . In that formalism, an expression like x -> x + 2 is called an abstraction and is written λx. x + 2 (Haskell designers chose the symbol because it resembles λ but it’s easier to type). Because of these historical roots, anonymous functions are sometimes called lambda abstractions , or simply abstractions.
As you can see, the function multiplyByN 5 “remembers” the value given to n when it is applied. You say that the function encloses the values from the surrounding environment (in this case, only n) along with the body. For that reason, these functions are usually known as closures in almost all languages supporting functional features.
Exercise 3-2. Working With Filters
filterOnes, which returns only the elements equal to the constant 1.
filterANumber, which returns only the elements equal to some number that is given via a parameter.
filterNot, which performs the reverse duty of filter. It returns only those elements of the list that do not fulfill the condition.
filterGovOrgs, which takes a list of Clients (as defined before) and returns only those that are government organizations. Write it using both an auxiliary function isGovOrg and a case expression.
Hint: search for documentation of the function not :: Bool -> Bool.1
Partial Application of a Function
That is, if given a list of integers, it will return a new list of integers.
Caution
The usual warnings about commutatively of operations apply here. You must be careful about where you are omitting the parameter because it may make a huge difference in the result.
Let’s look at map with these new glasses. Previously, I spoke about map as taking a function and a list and applying the function to the list. But, if now the type is written as (a -> b) -> ([a] -> [b]), there’s a new view: map takes a function and returns a version of that function that works over a list!
As a reminder, functions are written backward in comparison to other notations: you write first the outermost function that will be applied to the result of the innermost. This comes again from the roots of the language in lambda calculus and mathematics, where composition is denoted this way.
In many cases an expression can be written in point-free style as a sequence of transformations over some data, rendering the code clear once you become accustomed to the notation.
Note
Both the language Haskell and the term curried function take their names from the American logician Haskell Brooks Curry (1900–1982), who studied a field called combinatory logic that provided the groundwork for later developments in functional programming.
More on Modules
In the previous chapter you learned how to create modules to organize your functions and data types. The next logical step is being able to get the definitions in one module to be used in another. This is called importing a module, and it’s similar to importing packages in Java or namespaces in C#.
Module Imports
Note
Even though Haskell modules have a hierarchical structure, importing a module does not bring into scope any child modules. For example, importing Data won’t provide any access to Data.List.permutations because permutations lives in module Data.List, and Data.List was not imported.
As you can see, you can combine the selection of a subset of functions with the qualification of the module. Indeed, those concepts are orthogonal, and you can combine them freely.
The Prelude
By default, any Haskell module always imports without qualification the module named Prelude. This module contains the most basic and used functions in the Haskell Platform, such as (+) or head. This automatic import is essential to your being able to write Haskell code without worrying about importing every single function you invoke. You have actually been benefiting from Prelude throughout all the examples so far in this book.
In rare cases you may need to disable this automatic import. You can do so in GHC by enabling the language extension NoImplicitPrelude. Remember that, in this case, if you need to use any function in Prelude, you need to import it explicitly.
Smart Constructors and Views
Of course, you can also control which data types and type constructors will be exported. As with importing lists, you have several options for exporting a data type: merely exporting the type but no constructor (thus disallowing the creation of values by directly calling the constructors), exporting just some subset of constructors, or exporting all of them.
This idea of hiding the constructors of a given data type opens the door to a new design pattern, usually called smart constructors . The use case is as follows: sometimes not all the values that can be obtained using a constructor are correct values for the concept you are modeling. In those cases, you want to make sure that the developer can only construct values in the correct space.
Note
error is a built-in function that can be used anywhere to signal a point at which the program cannot continue and should be halted, showing the specified error message. This is one of several possibilities for dealing with errors in Haskell. You will explore other ways to signal errors throughout the book.
The syntax is a big cumbersome, though. A bidirectional pattern synonym is composed of three parts. The first one is a type signature, which coincides with the Range constructor. In general, the arguments refer to each of the positions in the pattern. The next element is the matcher: in this case, I declare that matching over R a b is equivalent to writing a pattern match of the form Range a b. The trick comes in the final element, after the where keyword, which declares that using R x y in a building position is equivalent to calling the range function. Note that this is not Range, the constructor, but the smart constructor which checks the invariant.
Finally, this is a solution to the problem of not exposing constructors for creating values, while at the same time not harming the ability to use pattern matching for working on it.
Diving into Lists
You have already learned about two of the most common list functions, namely, map and filter. In this section, you will see more examples of higher-order functions on lists and discover some patterns such as folds that are useful in Haskell code. Most of these functions live in the Prelude module, so you don’t need to explicitly import them. The rest of them live in the Data.List module.
Diving Into Lists Code
While reading this section, try to write the definition of each list function once its description has been introduced. Doing so is a good exercise to cement the concepts of parametric polymorphism and higher-order functions in your mind. You can start by writing the filter function.
Folds
The first function you will look at is foldr, which introduces you to the world of folds. A fold over a data structure such as a list is a function that aggregates or combines all the values contained in that structure to produce a single result. Folds are an expressive and powerful tool, often underestimated. Examples of folds are summing all integers in a list and finding the maximum of the values in the nodes of a tree (I will speak more about trees later).
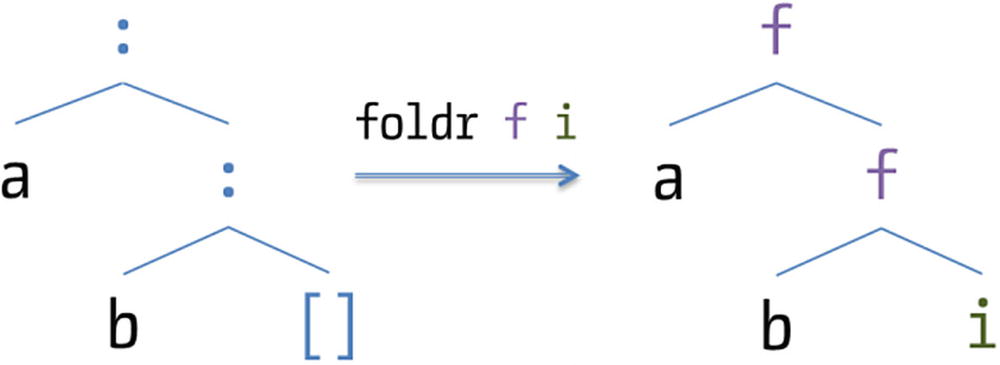
Visual description of foldr
Another example of fold is maximum, which finds the largest value from a list. In this case, the initial value is a bit more elusive because you must consider what the maximum of an empty list is. To help in answering that question, you need to recall the other property that is wanted for the initial value: it should not change the outcome of the binary operation, which in this case is max. This means you have to find a value z such that max(z,x) = max(x,z) = x any value x. You can check that the value that satisfies that property is negative infinity (-∞).
By making the type polymorphic, you allow for the possibility of using the type for more than just integers. The immediate problem requires just infinite integer values, but future problems might require, say, infinite floating-point values. Polymorphism here is an investment in the future.
The result value of the fold in the examples so far does not depend on whether it is performed to the right or to the left . But for this to hold, the aggregation operator that is chosen must be commutative. In other words, the following must hold true: f(x,y) = f(y,x)f(x, y) = f(y, x). So long as the order in which parameters are input does not matter, you can make it so that folding left or right also does not matter.
Exercise 3-3. Your First Folds
Write the functions using pattern matching, without resorting to any higher-order function.
Write the functions as folds. In each case, first try to find the aggregation operation and from that derive a sensible initial value.
Can you find the structure that all these functions share when written in the first style? In which cases is it true that using foldr and foldl give the same results?
Extra: Try to write a minimumBy function such that the order is taken by first applying a function g on the result. For example, minimumBy (x -> -x) [1,2,3] should return 3.
Lists and Predicates
Note
Remember you need to enable the LambdaCase extension for the previous code to be accepted by GHC.
A related function is break, which does the same work as span but negates the predicate before. Actually, break could be defined as span (not . p).
Note
nub and nubBy are not very performant functions because they must check for equality between all possible pairs of elements. This means the order of the function is quadratic. In the next chapter, you will learn a faster way to remove duplicates from a list.
This example also shows an interesting feature of Haskell syntax: infix notation. Each time you have a two-argument function that doesn’t have a name made only of symbols (such as union or intersect), you can write the name between the arguments surrounding it by back quotes, ``.
Mini-exercise
Write elem using find and pattern matching.
It may become handy when performing analytics to group clients depending on some characteristic. The function groupBy, with type (a -> a -> Bool) -> [a] -> [[a]], puts in a single list all those elements for which the equivalence predicate returns True; that is, they must be in the same group.
Haskell is Declarative
You may wonder why Haskell provides so many different functions on lists, whereas other programming languages do fine with constructs such as iterators or for loops. The idea is that instead of explicitly transforming a list element by element, you declare transformations at a higher level of abstraction. Languages supporting this idea, such as Haskell, are called declarative.
A classical fear when programming in Haskell is that this higher level of abstraction hurts performance. However, compilers of declarative languages are able to apply a wider range of optimizations because they can change the code in many more ways while retaining the same behavior. A typical example takes the form map f . map g. This code performs multiple passes over the data but can safely be converted by the compiler to map (f . g), which performs the same duty in just one pass over the data.
Lists Containing Tuples
Another family of list functions is the one that considers lists that have tuples inside. These list types will all ultimately be founded on some instance of the type [(a,b)]. I’ve already mentioned that default comparisons work on tuples lexicographically. Set functions such as nub and sorting functions such as sort work in that same way.
Previously in the book you wrote a function converting two lists into a list of tuples. This function is known as zip because it interleaves elements like a zipper does. One use of zip is to include the position of each element next to the element itself. For example, applying zip to ['a', 'b', 'c'] would give you [(1,'a'),(2,'b'),(3,'c')]. This involves zipping the original list with a list from the number 1 to the length of the list itself. Picture two sides of a zipper, one corresponding to the list of numbers and the second to the list of characters. As you pull up the fastener, each number is associated to a character, one by one.
Caution
You have seen how a list can be used to represent sets and maps. However, those implementations are inefficient because they require traversing a list for most operations. In the next chapter, you will look at other containers such as those found in the modules Data.Set and Data.Map. These other containers are especially suited for their particular uses and have highly performant implementations.
List Comprehensions
List comprehensions have two parts, separated by | and wrapped by square brackets. The first part is the expression, which defines a transformation to apply to all the elements that will be returned. The second part consists a list of qualifiers and specifies from whence the elements will come and the constraints upon them.
Note
If you know Scala, list comprehensions in Haskell will be familiar to you. The changes are merely syntactic: [ e | q ] becomes for (q) yield e;, and the generators are written the same. Local bindings are introduced without any keyword, whereas guards must be preceded by if.
You have looked at comprehensions as coming from mathematical notation for sets. But if you look closer, they also look a bit like SQL. The notation [ x | x <- list, b x ] can be seen in SQL as select x from list where b=x. However, if you want to have a full-fledged query language, you need also grouping and sorting. The great news is that GHC already provides those operations; you need only to enable the TransformListComp extension.
The final extension concerns grouping. The syntax is then group by e using f, where f is a function of the type (a -> b) -> [a] -> [[a]]. In the most common case, you use as groupWith, also in GHC.Exts, which computes e for each element in the list and groups together those values for which e returns the same result. After a grouping qualifier, all the previous bindings are considered to be lists made up of the previous elements. This is important because all the transformations to the grouped elements should be done prior to that point. In many cases, all grouped elements will be equal, so GHC provides a the function that takes just one element from the list.
Notice how this code computes the product of the items before the grouping using let m = x*y. Then you group according to the value m > 0, and at this point you have the list [([False,False,False,False,False,False],[-1,-2,-3,-2,-4,-6]),([True,True,True],[1,2,3])]. Finally, you apply the to conflate the first components to a single element.
Note
These comprehensions resemble the query expressions introduced in the C# language in version 3.0.
Haskell Origami
Origami is the Japanese art of folding and unfolding paper in order to create beautiful pieces of art. You have already looked at list folds. In this section you will look at them and meet their colleagues, the unfolds. The goal is gaining some deeper understanding of the structure of list functions and how this huge set of functions I have described can be fit into a small family of schemas. Since these schemas are based on fold and unfold functions, they are known as Haskell origami . This section contains some optional and more advanced material. Don’t worry if you don’t understand this upon first read; just come try it again after some time.5
But, how to ensure that the definition of filter using regular pattern matching and recursion on lists and this definition using a fold are equivalent? The answer lies in induction and equational reasoning, a technique for formally verifying code that manipulates equations between functions. In this particular case, you need to prove that both ways to define filtering work in the same way for the empty list (this is called the base case) and that by assuming that they are equal for a list xs you can prove that they are equal for a longer list x:xs (this is called the inductive step).
By induction, the equality between both ways to write the function is now proven, in the mathematical sense of the word.
Exercise 3-4. Proof For Map
Using the same techniques as we used for filter, prove that the usual map definition and the one given in terms of foldr are equal.
As in the case of filter, we see that the final expressions have the same structure. Remember that we can assume that the equality already holds for is while proving the inductive step. If we call such common expression js, in both cases we obtain f (g i) js. The proof is finished.
Note
Knowing these laws may seem like just a theoretical exercise. However, they have important applications for Haskell programs because the compiler uses them to transform the code into a more efficient one, while ensuring the same behavior. For example, map (f . g) traverses a list only once, whereas map f . map g does it twice and needs an intermediate data structure in memory. So, the compiler aims to replace each instance of the latter with the former.
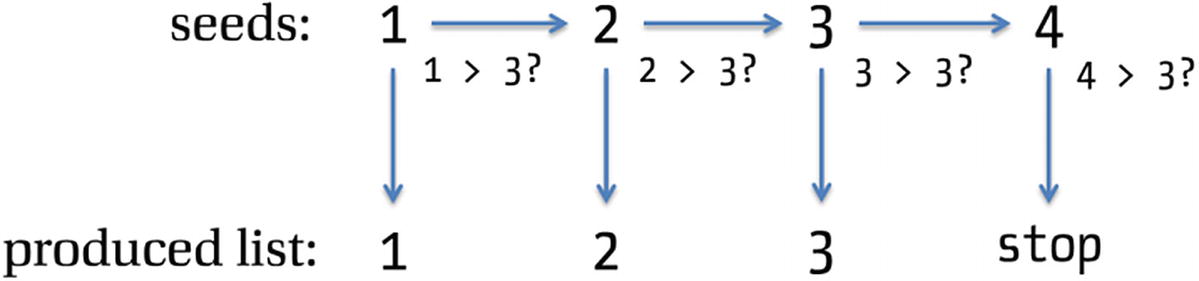
Evaluation steps for enumUnfold 1 3
Why Are Folds And Unfolds Duals?
I find this duality elegant and an example of how higher-order functions allow you to find relations between different abstractions.
Summary
You got in touch with the idea of parametric polymorphism, which allows you to define functions operating on several types and also write data types that may contain values of different types.
You learned how to use functions as parameters or return values, giving rise to higher-order functions, which greatly enhance the reusability of your code.
Anonymous functions were introduced as a way to write some code directly in place instead of having to define a new function each time you want to pass it as an argument.
You saw how the idea of functions returning functions permeates the Haskell language and saw the syntax for partially applying them.
You looked at the point-free programming style, which encourages the use of combinators between functions to write more concise code. In particular, the focus was on the (.) composition operator.
The chapter covered the import and export of definitions in other modules in a project. In particular, you saw how hiding definitions allows for the smart constructors pattern.
You walked through the most important functions in the Data.List module, introducing the important concept of a fold.
In many cases, list comprehensions provide an intuitive syntax for list transformations. You delved into its basic characteristics and the particular GHC extensions providing sorting and grouping à la SQL.
Finally, you saw how fold and unfolds are at the core of most list functions, and you learned how to use them and reason with them.