
No man burdens his mind with small matters unless he has some very good reason for doing so.
—Sherlock Holmes in Sir Arthur Conan Doyle’s “A Study in Scarlet” (1887)
Software engineering is an old art.
The Analytical Engine has no pretensions whatever to originate any thing. It can do whatever we know how to order it to perform.
—Ada Lovelace (1842)
Legend has it that, at that time, developers cried and screamed, running in circles because they were not able to set clear objectives and to deal with customers' expectations.
Code smells
Software development life cycle (SDLC)
Improving quality with code reviews
This will set the base for the book, serving as a first glance to the details in further chapters: from the nitty-gritty code details to general principles and more complex scenarios including security.
Code Smells
The term code smell was introduced by Kent Beck back in the 1990s and became more popular with its introduction in Martin Fowler’s book, Refactoring.1 A code smell can be defined as “a surface indication that usually corresponds to a deeper problem in the system.”2
The purpose of sniffing around for code smells is to find areas that can be improved in the code and eventually identify where refactoring is needed. Code smells are all about improving the overall quality of the software or system under development. And this should be done as early as possible. A smell you think is minor now could become your monster after a while. We are trying to prevent our cute baby code monster from growing into a terrifying code monster with 13 asymmetric legs, 4 heads, and gigantic hands and smelling like it did not have a shower.
Bad habits when writing code range from different causes, including human beliefs (such as the excuse that the code does not need to be perfect) to ignoring decades of old good practices and standards, but they all have the same impact: low maintainable and error-prone code.
Even if writing good code is, and always will be, an incremental process and perfection is a unicorn, we cannot use it as an excuse to not put an effort into writing the best code we possibly can in a given context. Code reviews are also a great tool for learning from more experienced programmers; however, it should not be used as an excuse to write—consciously or unconsciously—bad code knowing that someone will eventually fix it later in a review.
Failing is okay, and we all started with not so great code. However, writing good code is also a matter of attitude, not only skills.
Hence, it is important to put more and more effort into improving code quality. This book looks at different aspects of code quality, from using your instincts to smelling the code to more formal approaches to fix defects and remedying them as soon as they emerge.
- 1.
Poor readability: A code which is not readable is a code that is more difficult to reuse, extend, and evolve.
- 2.
Low productivity: A peer who is unfamiliar with the code will surely take more time to understand what the code is trying to achieve. Furthermore, you might end up spending more time fixing bugs rather than focusing on the core values added by the software you are implementing.
- 3.
Bug pollution: Bugs can grow in size and number when not promptly addressed.
- 4.
Delays in releases: All the defects in the code start to increase, overlap, and mess up the system. Deadlines might be delayed because of bugs you ignored so far.
- 5.
Poor maintainability: The code is difficult to read. Thus, the development process is slowed down by bugs. Furthermore, it is difficult to know how long it will take to implement new functionalities because of other defects in the system.
At a certain point, you might be even tempted to throw everything away and start from scratch. But please stop! That’s not the right way, and there is a solution for this; not the Holy Grail, but it will help—a lot!
Software Development Life Cycle
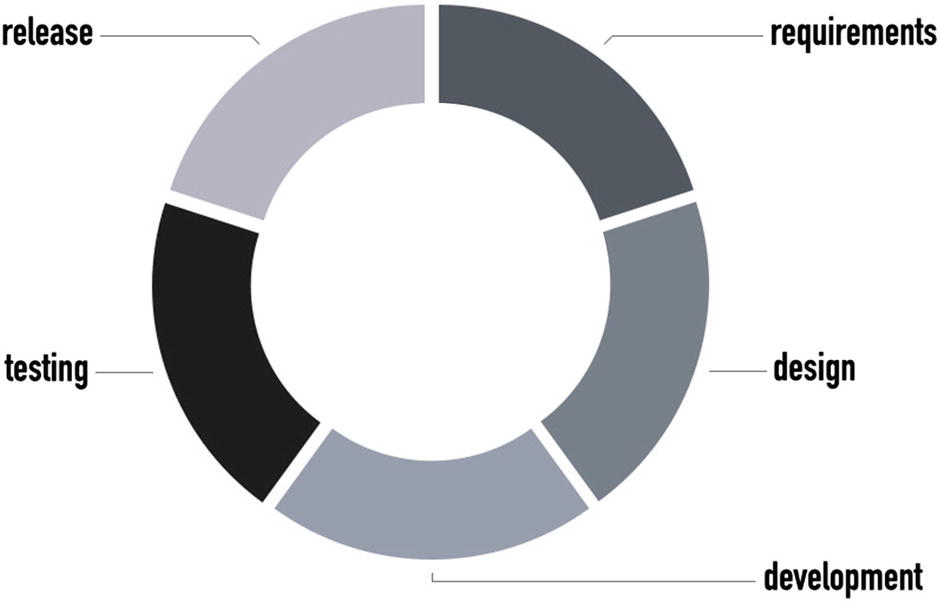
Software development life cycle (SDLC)
The requirements phase embraces the planning and requirements gathering and analysis processes. The information gathered is used to shape the project in terms of approach, feasibility study, and operational and technical aspects. In this phase, planning for quality of service (QoS) is also performed together with risk identification and their impact. As output of this phase, all the requirements (both functional and nonfunctional) are gathered into the software requirement specification (SRS) document.
The design phase aims at defining the software architecture, together with coding guidelines, languages, tools, frameworks, and platforms. It starts with the SRS document as input and produces a design document specification (DDS) document as output.
The development phase aims at actually developing the code accordingly to what has been outlined in the DDS document.
The testing phase is, in reality, scattered on the other phases, and it refers to testing the product searching, reporting, monitoring, and fixing defects.
The release phase is the ultimate stage where the product is released in the market.
Waterfall: In which all the phases are executed in isolation and sequentially. This means that one phase is started only after the previous one is complete.
Iterative: In which the phases are executed sequentially like the waterfall model. However, it starts from a subset of the requirements and the product is iteratively improved until the entire system is implemented.
Agile: Can be seen as an extension of the iterative model, where the entire work is broken down into small, time-constrained tasks, each of them meant to deliver specific features. This model is also incremental, which means that every release is a buildup in terms of features released.
Prototype: Aims at building a small set of product’s feature to showcase and evaluate proposals.
Oftentimes, prototypes, by nature, do not focus on performances and security. However, I strongly encourage you to still keep an eye on them and take them into account during the design phase.
Prototypes are also often strongly impacted by the “ship it fast, that’s just a prototype” mentality. Unfortunately, it implies “I don’t really care about its quality.”
Is this the right way to proceed? My answer is yes and no.
If your prototype takes really little effort to code and mainly runs in isolation, it might be okay to not overstress on its overall quality. However, some of them take months or years to be developed and still called prototypes, with a lot of interactions with other components. Not ensuring good enough quality in this case will surely lead to slowdowns in the development process, which might impact also other components depending on such a low-quality code. A slowdown also means potentially missed deadlines and money.
Don’t use the SDLC you are embracing to justify how bad smelling the code is. It is surely more harm and time consuming than good.

Code reviews—SDLC
Improving Quality with Code Reviews
One of the ways I suggest to improve quality is embedding code reviews into the development process.
Informal reviews are the more naïve way to check the code for defects. This kind of review usually involves no particular preparation nor planned metrics to measure the effectiveness of the review. They are usually performed by one or more peers, typically for brainstorming ideas.
Walkthrough reviews are slightly more formal than informal reviews. They can be performed by a single person (e.g., the author of the code) or by multiple participants. Defects are usually pointed out and discussed. This type of review is more about querying for feedback and comments from participants rather than actually correcting defects.
Inspection reviews are well planned and structured. It aims at finding and logging defects, gathering insights, and communicating them within the team. The process is supported by a checklist and metrics to gather the effectiveness of the review process. It is usually not performed by the author.

Types of code reviews
Peer reviews are probably the most common way of performing code reviews that you have been going through and that you performed in your engineering career. They do not show in the pyramid because, even if they help in spotting some inconsistencies within the code as well as bugs, achieving clean code cannot be confined to small features, especially with software growing at scale. The guidance provided in this book can surely be applied also to peer reviews. However, the suggestion is to periodically take a step away from small portions of code and look at the code in its broader form and cleanness, hence, the approaches presented in Figure 1-2 and the structure of this book.
Code inspection is a broader review because it focuses on different aspects of code quality, from obvious logic errors including coding standards and style guidelines. And since we care about the quality of the software we produce, this book will focus and provide practical guidance, on this type of review.
Reviews should be well integrated into any existing development process, and it should be done fairly early in the development process. As the proverb goes, those who start well are half away from achieving their goal.
Next, we’ll introduce manual and automated code reviews and provide a glance at the benefits brought to the table when performing them.
Manual vs. Automated
A lot of times nowadays I hear about automation. We want to automate reviews. Automate tests. Automate deployments. Automate behavior. We just want to automate everything to cut down costs and make the programmer's life a bit easier, which is the ultimate goal.
However, we should never put automation first and quality after. Quality is the priority. Bad code will fail, no matter how many tests you automated. If it does not fail because of actual bugs, it will fail for readability, maintainability, usability, extensibility, security, and performances. It will eventually fail because of all the defects we will explore in this book. Focus on quality, and automation will follow.
Automation is a big friend in our programming life—from automated formatting and styles. It saves a lot of time that otherwise would be wasted for manual repetitive tasks. Automated tests are also a fundamental piece that helps, if done correctly, to quickly spot if any change breaks something else in the codebase. The key takeaway here is: even the best tests can spot breaking changes but will not ensure clean code.
Certain aspects of code reviews can be automated and are often referred to as static code analysis. Finding performance issues or a standard violation, as an example, might and should be automatized. However, even if a good rule of thumb is to automatize as much as possible to achieve faster and repeatable processes, you should surely not neglect manual code reviews (hence this book). For instance, as we’ll discuss later, long methods are oftentimes the signal that something wrong might be happening: it might be the case of a method implementing more than a single functionality or behavior. In this case, a reviewer needs to look at the actual code to understand if there is a problem or the code is just fine as it is.
- 1.
Better insights around the overall quality of the software
- 2.
Less false positive/negatives
- 3.
Clear suggestions on corrective actions to fix defects
- 4.
Prioritizing and clearly defining the risks deriving from defects found
Impact
- 1.
Return of investment (ROI): Code reviews have an amazing return of investment. They not only pay for themselves immediately, but they will keep working and will be cost-effective in the long run. In the short term, resolving defects found will improve how quickly the following features can be implemented. In the long run, the more you keep the code nice and clean, the less time expensive the following reviews will likely be.
- 2.
Agility: They fit (very) well agile processes. They allow the development process to fully embrace changes. By iterating reviews, changes, defects discovery, and fixing them, teams are continuously set for success. Ensuring good quality as you keep developing translates into long-term maintainability. The only way for code reviews (quality code in general) and agile not to go hand in hand is if they are looked from the eyes of those who do not have a real grasp of both.
- 3.
Productivity: No matter if a defect is a bug (e.g., a logic error you found in the code) or there is a readability issue coming from a not so well-written code, the productivity of the team increases.
- 4.
Impact on other processes: Embedding code reviews also positively impacts other processes including testing and refactoring. Furthermore, testing by itself does not ensure quality code. Yes, the functionality might not crack, but there is no assurance that the code is in good shape.
- 5.
Learning: Code reviews can be a good learning experience. They don’t need to be a boring process—and they are actually not. They really can be a fun way to brainstorm and solve issues.
- 6.
Lesson learned: As the code grows and new requirements (functional or nonfunctional) are developed, lesson learned and good insights for future implementations can be gathered.
- 7.
Branding: Releasing good quality code speaks about ourselves and about the company. We can’t produce perfect code, but we can put our best effort to be happy about the code we show to the world. At the end of the day, it is not just what you do; it is how you do it.
Summary
In this chapter, we went over the importance of building and maintaining clean code and introduced basic knowledge around software development life cycle. In the next chapters, we will examine each of the phases in the SDLC and see how they can benefit from code reviews. Before continuing, let’s summarize the takeaways from this chapter to take with you on your journey to become a better software engineer:
- 1.
Clean code is not only a matter of skills: it’s also about having the right attitude. Always put the best effort you can when writing code.
- 2.
Code reviews are not only beneficial during the entire SDLC: they are necessary to maintain clean code over time.