
Little things are infinitely the most important.
—Sherlock Holmes in Sir Arthur Conan Doyle’s “A Case of Identity” (1891)
Let’s be clear: concurrency and parallelism are not exactly the same thing.
Concurrency is the execution of multiple independent and interleaving pieces of computation. Concurrent programming ensures that their composition is correct, by means of handling the need for simultaneous access to shared resources.
Parallelism distinguishes itself by having these independent computations execute simultaneously.
Concurrency allows to structure the code in independent tasks to be performed that need coordination and communication between each other.
The underlying idea is that making better independent processes work in a coordinated fashion might help in speeding up the computation. And this is true, with the right assumptions.
I am pretty sure that all of us tried at least once in our life to implement a multi-threaded application that was actually slower than its sequential version. In this chapter, we will cover the foundations of concurrent and parallel programming and what to consider in terms of performances.
Foundation of Concurrency
So far we mainly focused on classical sequential programs. Nowadays, however, we like to exploit concurrency—that is, multiple tasks executed simultaneously fighting with each other for resources to try to speed up the execution time.
This section provides underlying knowledge around concurrent programming and highlights some basic mechanisms we need to ensure in our code to make it function correctly.
CPUs and Cores
CPU vs. Core: Differences
CPU | Core |
|---|---|
Fetch, decode, execute | Fetch, decode, execute |
Circuit in a computer | Circuit in a CPU |
Multiple CPUs in a computer | Multiple core in a CPU |
Fetch gathers instructions from memory.
Decode what instructions need to be performed.
Execute the instruction.
However, a core is the basic computational unit within a CPU. CPUs can have, depending on the architecture, multiple cores. Similarly, computers can have multiple CPUs.
Usually, multicore architectures are known to be faster. However, just adding cores and/or CPUs does not make execution faster per se. We will explain it more in depth later in this chapter.
Threads Are Not Processes
Processes are the tools that the operating systems use to run programs. Threads are mini-blocks of code (sub-tasks) that can run within a process. In other words, a process can have multiple threads within it.
Threads use shared memory (processes don’t) and they cannot execute code at the same time. Indeed, processes have their own execution environment, including own memory space. As a consequence, sharing information at process level is slower than sharing it at thread level. However, thread communication requires a deeper look at design phase.
Correctness of Concurrent Code
Two main properties ensure that concurrent code is correct: safety and liveness.
Safety is the property that ensures that nothing “bad” will happen. Liveness, on the other hand, ensures that something “good” will eventually happen.
Mutual exclusion: Which means that two processes cannot interleave a certain sequence of lines of code (instructions).
Absence of deadlock: A deadlock happens when two or more processes are blocking each other. This happens if each of them is waiting for the release of a given resource (e.g., a file) from the others.
Absence of starvation: In case of starvation, a process could wait indefinitely and never run.
Fairness: Which specifies how requests are handled and served.
Thread Safety
Thread safety is a property needed to guarantee correctness in concurrent software programs. As explained in the “Foundation of Concurrency” section, threads use shared memory (namely, critical region or critical section) that needs to be accessed in a mutually exclusive manner.

Mutual exclusion
Locks (https://docs.python.org/2.0/lib/lock-objects.html) are a common mechanism used to ensure mutual exclusion by using acquire() and release( ) functions to surround and control the critical section.
Generally speaking, an object is defined thread safe if, when accessed by multiple threads, its execution is correct, independently from thread’s interleaving or scheduling.
Thus, concurrent access needs to be carefully managed. Indeed, between all, as anticipated, using locking mechanisms is not enough: we also need to ensure the absence of deadlocks. In our example, a deadlock happens if the critical section is free, but neither T1 nor T2 can access it.
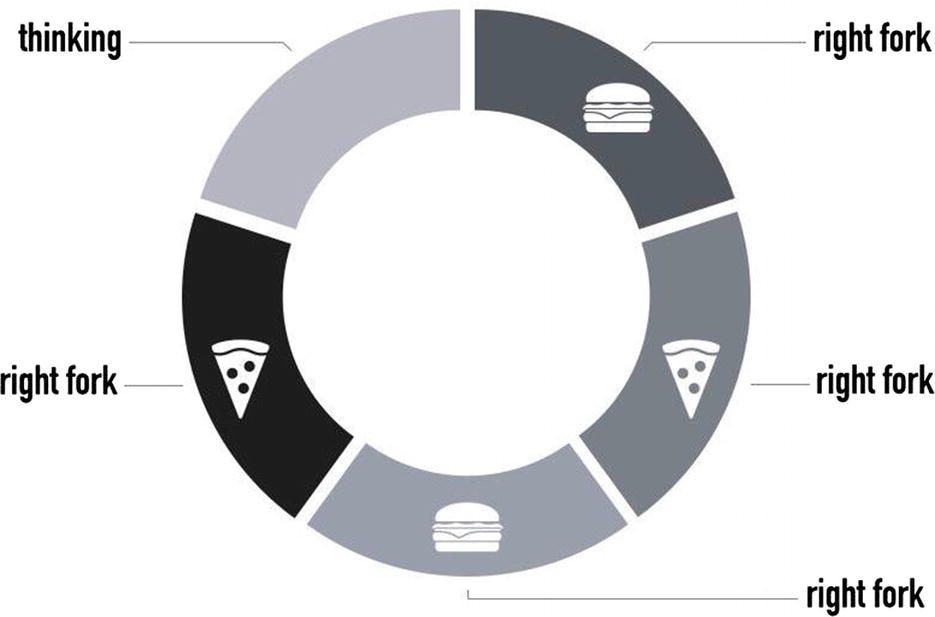
Dining philosophers problem
In the example, our philosophers are threads, while the fork is the shared resource. We can quickly deduct that a common cause of a deadlock happening is because of a lock (hence the access to the shared resource) not being properly released.
In Python, a context manager can be used to limit the possibility of a deadlock from happening.
When correctness depends on scheduling and interleaving times, like the dining philosophers problem, we have a race condition.
Immutable and Stateless
In object-oriented programming (OOP) , objects can be mutable or immutable. Intuitively, immutable objects can’t change their state after their creation.
As a consequence, immutable objects are thread safe. However, checking if an object is actually immutable when ensuring thread safety is non-negligible and oftentimes more tricky than expected.
Its state cannot be changed after creation.
All fields are declared final.
There is no escape of this from the constructor.
Contrary to Java, Python provides slightly less language directives (e.g., no final) to ensure immutability of an object. As an example, the majority of data structures (e.g., list and dict) and programmer-defined types tend to be mutable. I say the majority because exceptions exist, such as tuples which are immutable. Scalar types (e.g., int, float, string) are almost always immutable.
It is also worth to notice that the fact that an object is immutable does not mean that the reference is immutable.
Stateless objects are—of course—thread safe.
ACID Transactions
One way of managing concurrency is by means of ACID transactions. ACID transactions are operations such that atomicity, consistency, isolation, and durability are ensured.
Atomicity
Thread safety and atomicity are not the same thing. Indeed, thread safety is reached by means of atomicity. But atomicity is not enough to ensure thread safety.
An atomic operation is an operation that can’t be broken down into multiple pieces, and that—as a consequence—is always executed as a single step.
However, if single operations are atomic, it does not imply that if multiple of them are grouped together into a single invariant (i.e., they are not independent anymore), the program stays race condition-free.
As previously said, locking mechanisms need to be used in such cases. The usage of locks ensures that the entire sequence of operations is executed successfully as a single one, or the entire work is rolled back.
Consistency
Consistency ensures that each operation starts from a valid state and after its execution, the system is in a valid state as well. Transactions are often associated with ATM operations, and it is really easy to think about consistency in this context. Missed consistency means that you go for withdrawing funds from the ATM and you do not receive money back while your account is debited with the amount of the operation. Not nice, isn’t it?
Isolation
Isolation is related to the visibility of transactions. This property ensures that the output of a transaction is not visible to other transactions before it successfully completes. In other words, concurrent operations can be seen as a sequential flow of execution. Back to our banking example. If isolation is not ensured, ideally two separate bank transfers from a single account can look at the same amount of money on the account and concurrently perform the transfer. This would end up in wrong balance.
Durability
Durability means that a transaction performed on the system must persist over time. It must persist in case of crashes, in case of errors, and even in case of a zombie apocalypse if that happens.
Parallelism and Performances
When we analyze a software component, we generally consider correctness and performances.
Correctness is often inspected by means of testing and in case of concurrent programming by ensuring safety and liveness.
Guidelines on Parallel Programming
Parallel programming is generally used to improve the performances of software applications.
Not all the applications can be easily parallelized.
Amount of parallelizable computation
Task and data granularity
Locality
Load balancing
Parallelizable Computation
As we anticipated, not all the computation can actually run in parallel. Generally speaking, the nature of the problem (and data) we try to parallelize has a big impact on constraints and limitation to a successful split of simultaneous work that can be performed.
Data is split in a uniform manner across the servers.
Each server counts the occurrence of the given word in its portion of the document.
When counting has been performed by all the server, relative results are summed up to obtain the entire occurrence count.
Examples like these are generally referred to as embarrassingly parallel problems.
Other problems, instead, are inherently sequential and notoriously known for the difficulty of trying to parallelize them. A common example in cryptography is the parallelization of hashing algorithms.
Before embarking on the parallelization journey, check if you are dealing with a problem which is notoriously known to be hard to parallelize.
Task and Data Granularity
While the nature of the problem poses impediments on whether parallelization can be performed or not, task and data granularity impact its effectiveness.
Computation needed before performing the split
The split of data and tasks across computational resources and any relevant communication required
Idle times
The cost adding multiple layers of abstractions or usage of frameworks to tap into parallelization capabilities
Back to our example of word counting. It is pretty intuitive that computation alone is fairly simple; however, whether parallelization is beneficial or not really depends on the size of the data and how big the chunks of data each server tackles.
The main takeaway is to always consider the size of the data, the complexity of the computation that needs to be performed, as well as scalability requirements to understand if parallelizing your application is a burden or an improvement of performances.
Locality
We experience locality of information every day: it is applied to our computers by means of hierarchical memory systems (RAM, caches, etc.). The underlying idea is that the closer the data is, the faster it is to perform computation on it.
Whether or not a portion of data needs to be shared across multiple computational units
What amount of data can be made local (close) to each computational unit
If and which portion of data needs to be transferred from one unit to another
All these elements are fundamental to ensure that parallelization is appropriately implemented and if possible understand if and how a parallelized problem can be optimized.
Load Balancing
Back to our example of word counting and its simple solution. We inherently added the usage of a load balancer. Indeed, we considered that “data is split in a uniform manner across the servers.”
Ensuring that the workload is split in a uniform manner is fundamental, yet not always a trivial task.
Load balancers add an extra layer of complexity and, hence, a potential slowdown of our application. Since they can constitute a bottleneck, carefully monitoring health and performances of a load balancer is fundamental to maintain high performances of a parallelized application.
Measuring Performances
How data is sent across the network
If and how data is stored on disk
The amount of data transmitted
Throughput
Latency
Memory requirements
Portability
Each of them needs to be prioritized, as we already said, based on the nature of problem that needs to be solved.
Execution time
Scalability
Amdahl’s Law
Here is where the fun starts. Ideally, by adding resources—from one processor to multiple processors, multiple computers, or a grid of them—performances “should” linearly increase. In other words, going from a single computational resource to n resources, our code should run n times faster.
In reality, it never happens because of a sequential part always happening. In these cases, Amdahl’s law gives a formula in order to theoretically measure the speedup introduced by parallelization.
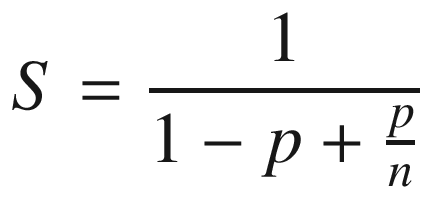
The preceding formula is the speedup definition, where p is the part of the task that can be parallelized.
Observation
One of the simple, while not simplistic, ways to capture (measure) performances is by measuring the speedup introduced by parallelization via observation. Running the parallel code and running it once is not enough to have a solid idea on how the code actually performs.
The number of processors
The size of the given problem
Asymptotic Analysis
A common way to measure algorithms’ performances is by means of asymptotic analysis. When using such type of analysis, performances are described as a limiting runtime behavior.
For a generic function f(n), the analysis considers what happens when n becomes very large (i.e., n → ∞).

as n grows, the constant becomes insignificant; thus, f(n) ∼ n2.
And f(n) is asymptotically equivalent to n2.
Even if it is commonly accepted to describe the efficiency of an algorithm, it could not appropriately represent the performance of a parallel algorithm.
To better understand why this happens, let’s consider the following runtimes in big O notation: O(n) and O(n log log n). Normally, O(n log log n) grows faster than O(n), thus resulting in a less efficient algorithm.
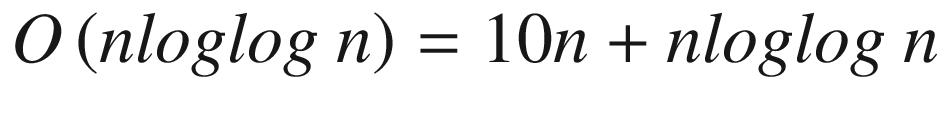
for a parallel algorithm. For n < 1023, 10 n > n log log n should be considered for actual algorithm performances (not insignificant).
The key takeaway here is that, different from sequential applications, parallelized code needs extra care when analyzing real performances.
Summary
The need for ensuring correctness and safety of concurrent applications
Common issues including deadlocks
Techniques like using ACID transactions for concurrent applications
Furthermore, we touched base with basic concepts about parallelization and fundamental techniques that can be used to measure performances.
This chapter is meant to give you enough guidance for the purpose of reviews. However, if you want to learn more about how to write Python concurrent and parallel code, please refer to the “Further Reading” section.
In the next chapter, we will introduce the secure software development lifecycle (SSDL) and guiding principles to look at during reviews.
Further Reading
This chapter only scratches the surface of a more complex and broad area. To learn further—from basics to advanced concepts—I suggest starting with The Art of Multiprocessor Programming by Maurice Herlihy and Nir Shavit (Morgan Kaufmann, 2011). A more hands-on approach on how to implement high-performing code and some of the tools that are available for Python programs can be found in High Performance Python: Practical Performant Programming for Humans by Micha Gorelick and Ian Ozsvald (O’Reilly Media, 2nd edition, 2020).
To learn more about implementing concurrency in Python, an always green reference is Python’s documentation (https://docs.python.org/3/library/concurrency.html).
Review Checklist
- 1.
Is the code thread safe?
- 2.
Are immutable object actually immutable?
- 3.
Are race conditions present?
- 4.
Is atomicity ensured?
- 5.
Are safety and liveness ensured?
- 6.
Are deadlocks avoided?
- 7.
Is starvation avoided?
- 8.
Is fairness ensured?
- 9.
Are locking mechanisms properly used?
- 10.
Is consistency ensured?
- 11.
Is isolation ensured?
- 12.
Is durability guaranteed?
- 13.
Are you trying to parallelize a problem which is notoriously known as hard to parallelize?
- 14.
Are you considering task and data granularity when parallelizing code?
- 15.
Are you considering and properly embracing locality needs in your parallelized solution?
- 16.
Is load balancing appropriately used? Is the workload uniformly split?
- 17.
Are you considering the inherent costs of parallelizing a solution into the overall performances?
- 18.
Do you have proper prioritization of performance metrics that are specific to the context your parallel application runs in?