
In this chapter, we will analyze two important metrics for cipher and plaintext analysis: the chi-squared statistic and searching for patterns (monograms, bigrams, and trigrams). When working with classic and modern cryptography, text characterization as technique is a very important part of the cryptanalysis bag of tricks.
Chi-Squared Statistic
The chi-squared statistic is an important metric that computes the similarity percent between two probability distributions. There are two situations when the results of the chi-squared statistic is equal with 0: it means that the two distributions are similar, and if the distributions are very different, a higher number will be outputted.
ChiSquaredDistribution Source Code
Chi-distribution output
How does the chi-squared distribution example help us in cryptanalysis and cryptography?
The first step that has to be made is to compute the frequency of the characters within the ciphertext. The second step is to compare the frequency distribution of the assumed language used for encryption (e.g. English) with shifting the two frequency distributions related to one another. In this way, we can find the shift that was used during the encryption process. This procedure is a standard and simple procedure that can be used on ciphers, such as a Caesar cipher. This take place when the frequency of the English characters is lined up with the frequency of the ciphertext. We are aware of the probabilities of the occurrences for English characters
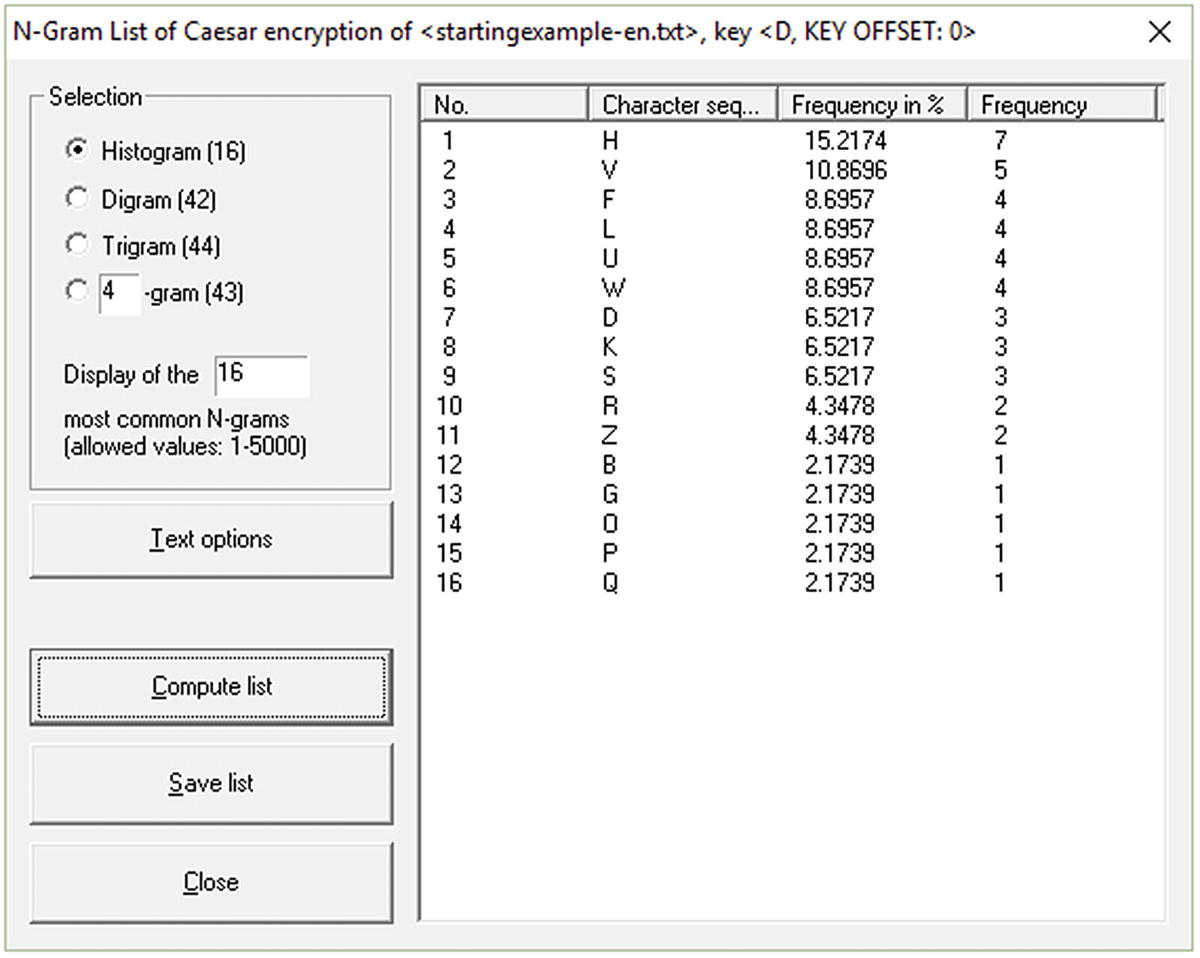
Letter frequency for encrypted text
To compute the count expected, the length of the ciphertext has to be multiplied by the probability. The cipher from above has a total of 46 characters. Following the statistic with E from above, our expectation is for the E letter to occur 46 · 0.127 = 5.842 times.
In order to solve the Caesar cipher, we need to use each of the possible 25 keys, using the letter or the position of the letter within the alphabet. For this, it’s very important how the count starts, from 0 or from 1. The chi-squared has to be computed for each of the keys. The process consists of comparing the count number of a letter with what we can expect the count to be if the text is in English.
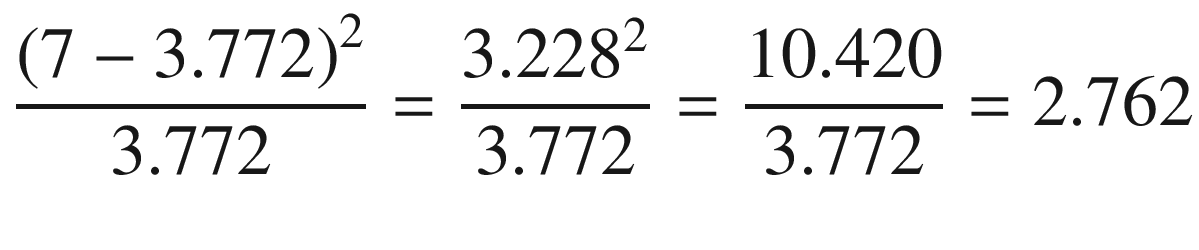
This procedure is done for the rest of the letters and making addition between all the probabilities (see Figure 23-3).
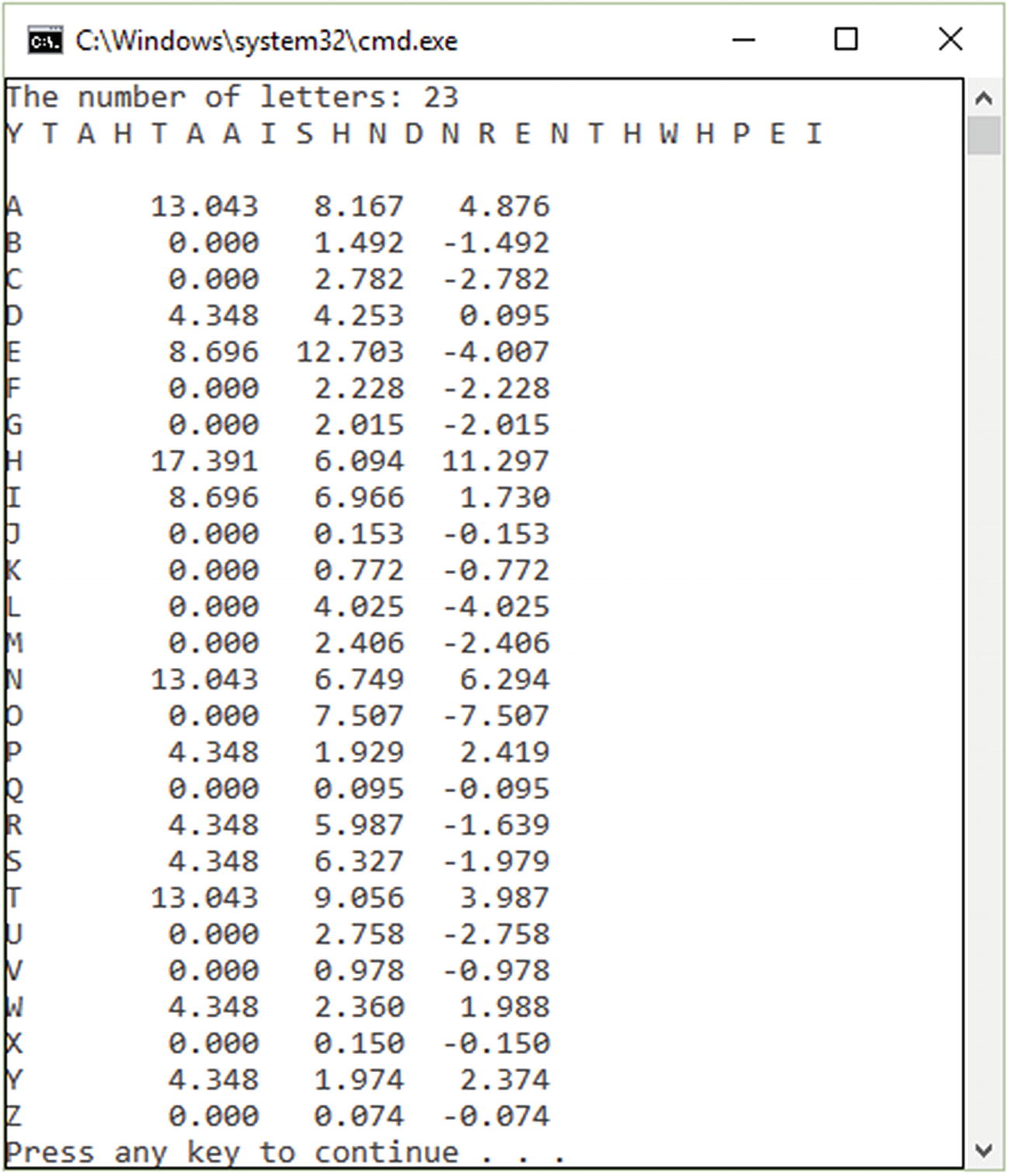
Encryption letter frequency (%)2
Cryptanalysis Using Monogram, Bigram, and Trigram Frequency Counts
Frequency analysis is one of the best practices for finding the number of ciphertext characters occurrence with the goal of breaking the cipher. Pattern analysis can be used to measure and count the characters as bigrams (or digraphs), a method for measuring pairs of characters that occurs within the text. There is also trigram frequency analysis, which measures the occurrence of combinations formed out of three letters.
In this section, we will focus on text characterization with bigrams and trigrams as opposed to resolving ciphers, such as Playfair.
Counting Monograms
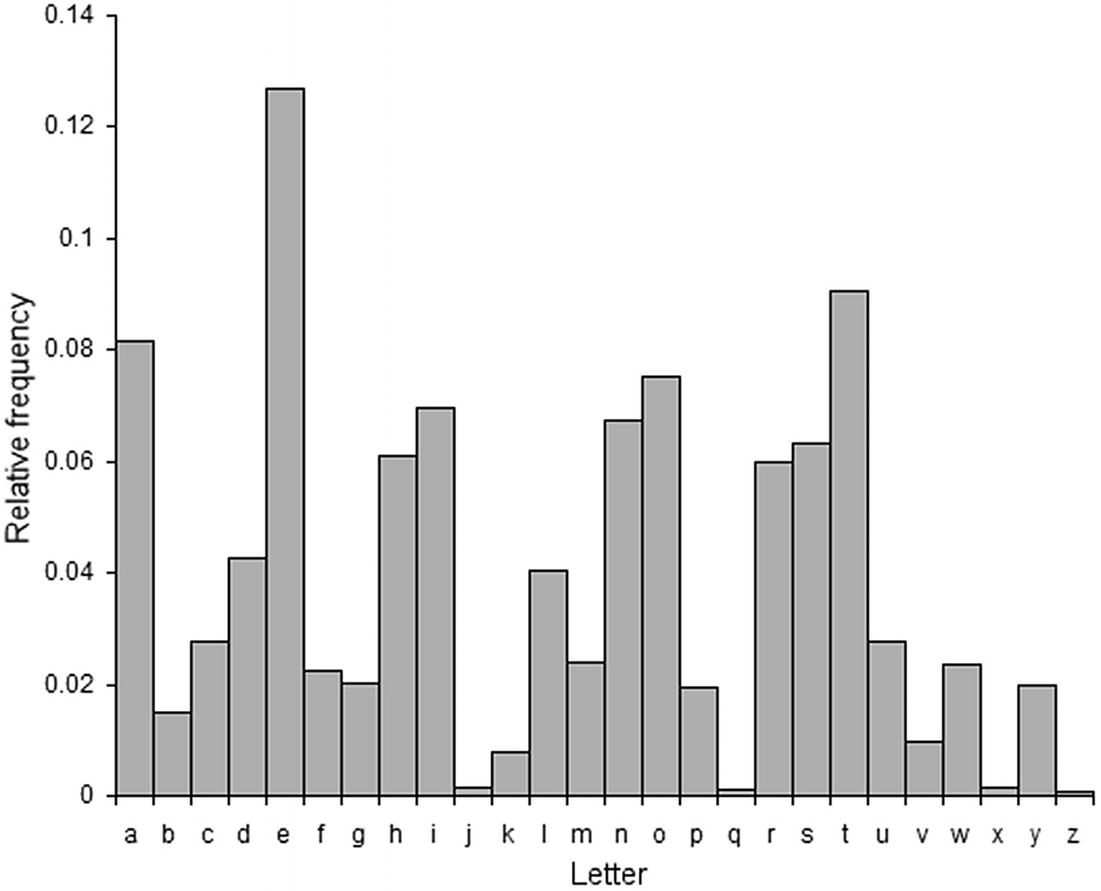
Letter frequency for the English language
Counting Monograms

Output of counting monograms
Lambda LINQ Expression for Counting Letter Frequencies
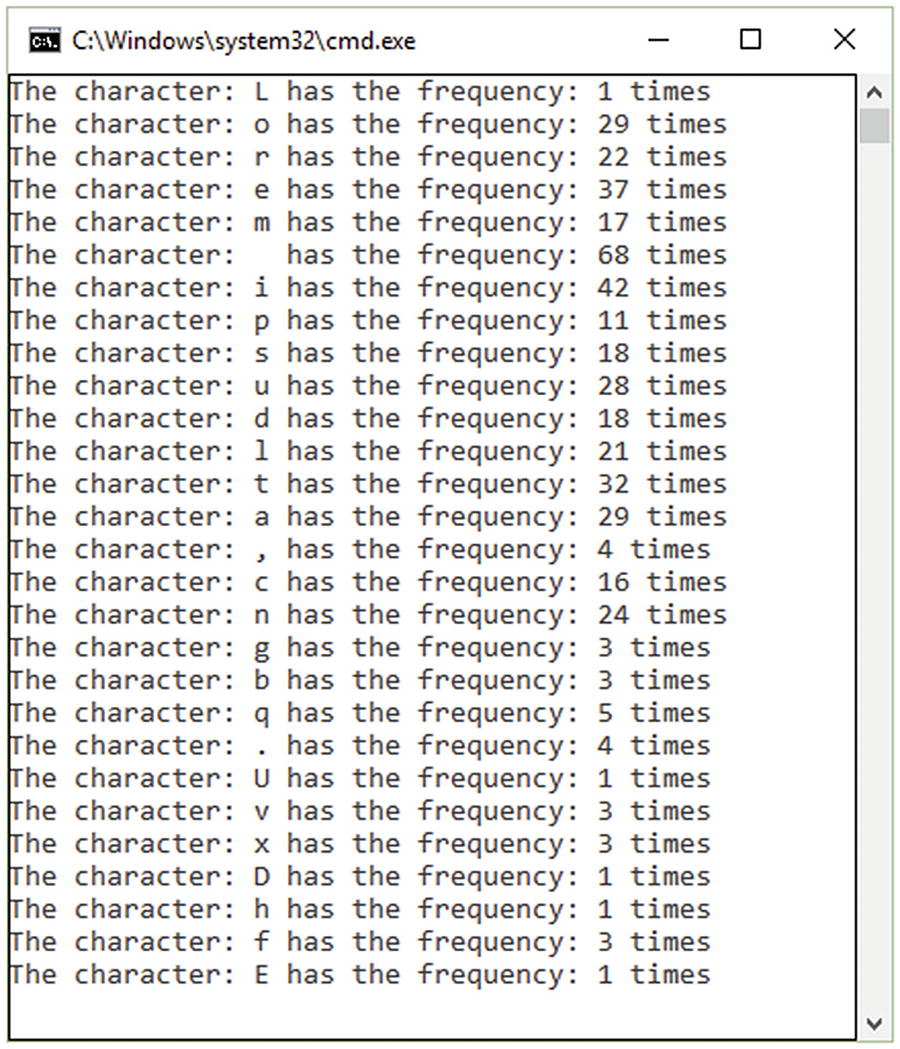
Character frequencies using LINQ and lambda expressions
Counting Bigrams
The method for counting bigrams is based on the same idea as counting monograms. Instead of counting the occurrence of single characters, counting bigrams means counting the occurrence frequency for pairs of characters.
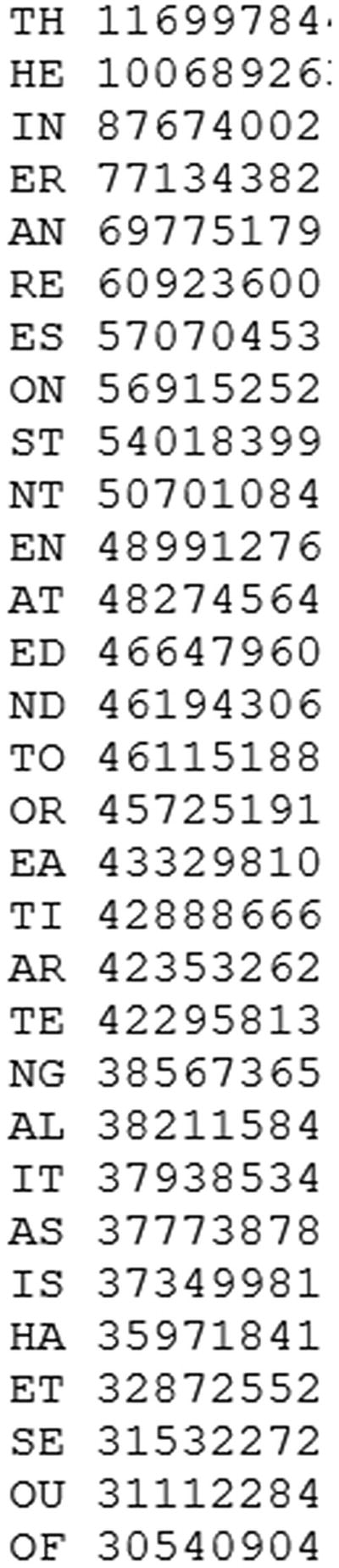
Examples of bigrams
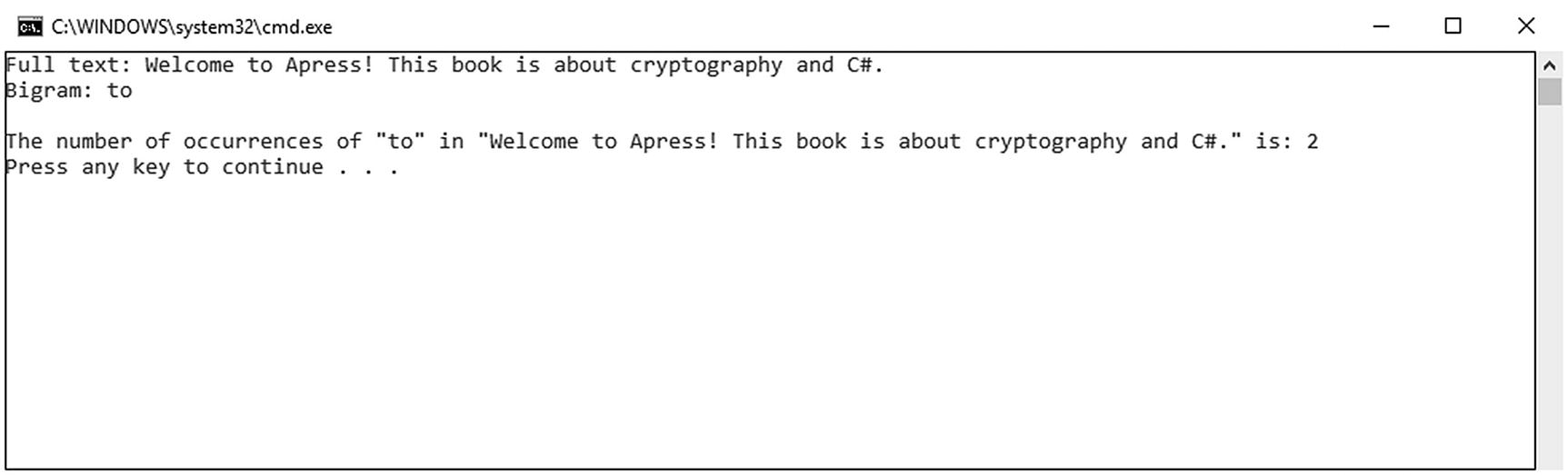
The output from Listing 23-4
Computing Bigrams
Counting Trigrams
Trigram counting uses the same principle as bigram counting. The difference consists in counting triple characters.

Examples of trigrams

The output from Listing 23-5
Counting Trigrams
Generate Letter Frequency
The array wikiFrequencies stores the frequencies (which are a relative percentage of the letters) as listed on Wikipedia3 (see Listing 23-6). The provided example interprets the number as a percentage. As an example, letter “A” appears 8.167% of the time.
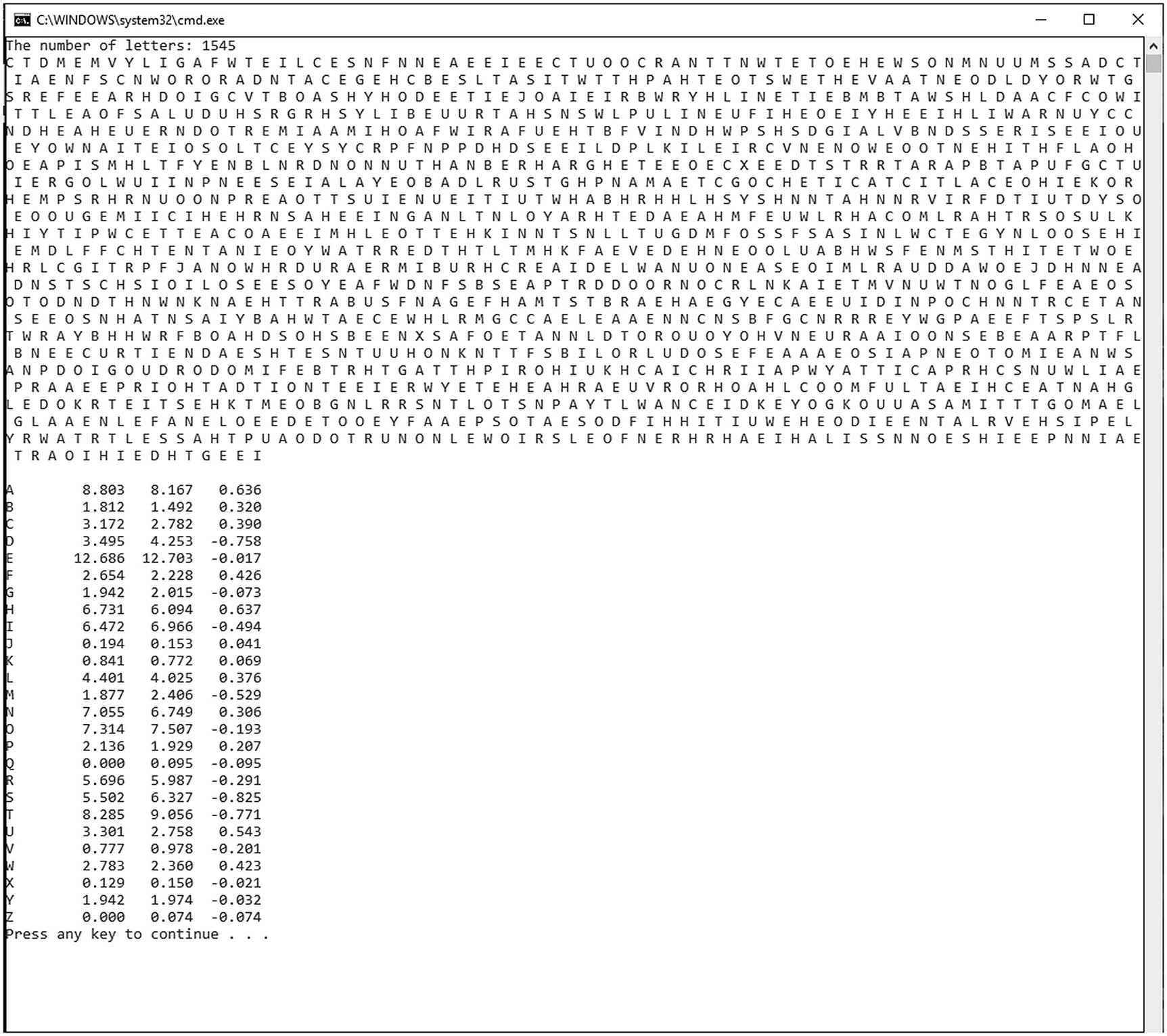
Generation of the letter frequencies
Randomly Generating Letter Frequencies
Conclusion
The concept of text characterization
Working with monograms, digrams, and trigrams
The implementation of chi-squared statistic
Monogram, digram, and trigram implementations
Bibliography
- [1]
Simon Singh, The Code Book: The Science of Secrecy from Ancient Egypt to Quantum Cryptography. ISBN 0-385-49532-3. 2000.
- [2]
Helen F. Gaines, Cryptanalysis: A Study of Ciphers and Their Solutions. 1989.