
DevOps is a discipline that brings together people, processes, and products to enable continuous delivery of value to end users. It does so by helping to bridge the gap between development, operations, and management. From a developer standpoint, probably the most important aspect of the DevOps discipline is the focus on having a healthy CI/CD pipeline. Continuous Integration (CI) and Continuous Deployment (CD) are two processes that help to support development agility while assuring product quality and stability.
CI/CD: Definitions and concepts
Continuous Integration means that you continuously push and merge the changes you have done to the codebase of the solution you’re working on, so that they can be integrated with changes made by other developers in your team, tested, and verified. Automation tools to build and test the solution are part of this process to make it seamless and as automated as possible. The goal is to have a codebase that is healthy and tested and that could be released in production almost anytime.
Continuous Deployment is a process that deals instead with the deployment of new code into production, helping to make a very delicate and critical process more automated, repeatable, and less error-prone. The goal here is the same as the previous one but approached from a different perspective: the deployment process. Even if you have perfectly working code in your repository, deploying it in production is a non-trivial task. Continuous Deployment helps to make sure an organization is able to deploy in production the latest available, tested, working code at any time.
As you may have already figured out, DevOps and CI/CD, along with Agile principles, are a cornerstone for modern development. In fact, for a modern developer, adopting the DevOps discipline right from the start is without a doubt a best practice and, nowadays, a consolidated behavior.
CI/CD and Azure SQL
Applying the DevOps discipline to a database is for sure more challenging, as the database is only partially code: the biggest part of a database is, in fact, data. What does it mean to test a database? And how do you deal with data? How to continuously deploy and evolve the database without damaging existing data integrity and performances ? There aren’t any clear and globally accepted answers here. The DevOps discipline is relatively young (first formal mention was in 2009!), and its application to the data space is even younger, so there is still a lot to learn before being able to define a globally accepted set of best practices. What is clear, is that it needs to be done. Luckily for us, there are several tools that can help in the process. In this chapter, we’ll discuss two of these tools: GitHub Actions and Azure DevOps and how they can be used in the context of Azure SQL. They both have a graphical UI but also support code-based (via YAML) configuration and definition for maximum flexibility. Once we know what the two tools can do for us and how they allow the creation of a CI/CD pipeline, we will go more in details of specific principles and solutions to deal with the added database and data complexity.
We’ll assume that you are already familiar with the concept of Source Code Control Management and git. If not, you can start learning this fundamental development skill using the free git eBook Pro Git at https://aka.ms/gitbookv2.
GitHub Actions
GitHub is the most popular and highly-used code repository. It provides a wide range of features for free, and one called GitHub Actions has been recently released, and it has been specifically designed to help in DevOps. More specifically, it allows you to implement a CI/CD pipeline right from your repository. GitHub Actions allow the creation of a custom software development life cycle via the usage of a series of small tasks, called actions. Actions can be combined and orchestrated via a custom defined workflow to cover all the aspects of building, testing, and deploying your solution.
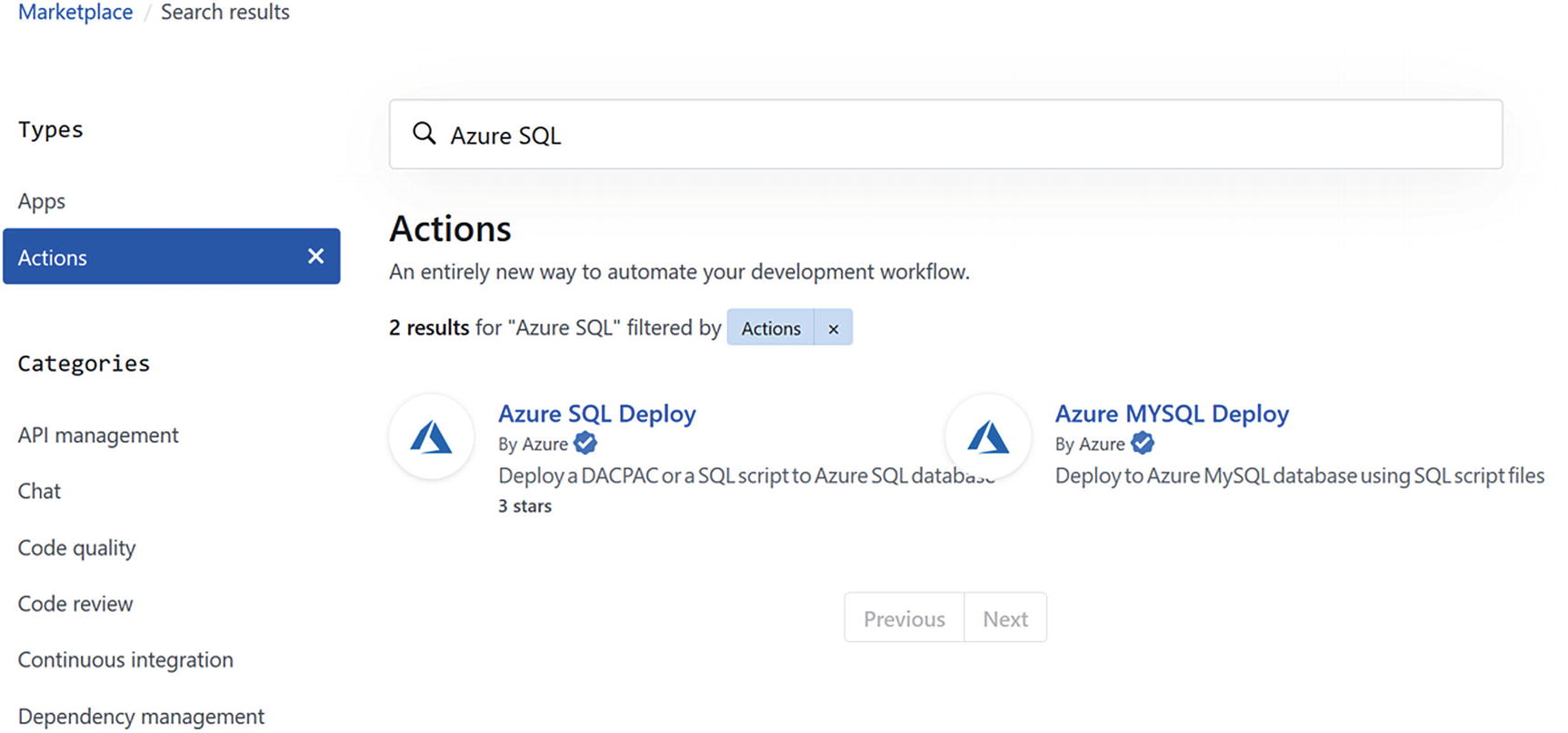
GitHub Actions Marketplace
The GitHub actions marketplace is available at this link: https://aka.ms/ghmas.
Thanks to the Azure SQL deploy action, you can create a workflow that, after someone has pushed its code to the repository, will deploy the script to a target Azure SQL database, run any test you may have configured using your preferred testing framework , and notify you about the results.
Azure DevOps
Azure DevOps is a full-featured suite of products that can support a team in all DevOps aspects. It includes a git-compatible code repository, a pipeline to build and release the generated solution, a set of test tools to automate tests, an artifact store to locally and manage packages, and an agile planning and issue tracking system to make sure that work can be properly tracked, assigned, and monitored.
If you’re working on a new project and the team is small, Azure DevOps can be a great choice as the first five users are free.
After you have pushed your code into the Azure DevOps source code repository, you can instruct the build pipeline to deploy the Azure SQL code into a specified Azure SQL database as part of your deployment.
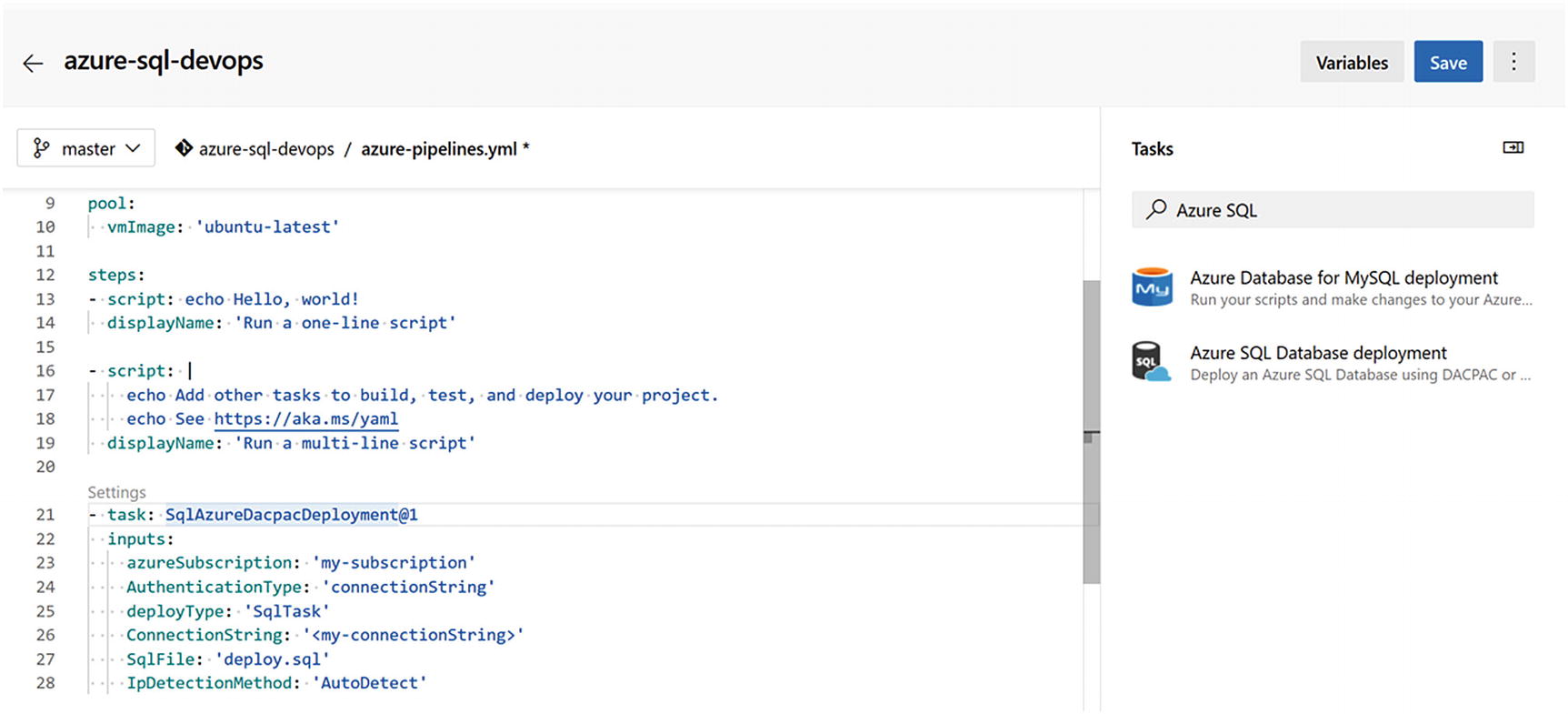
Database migrations
Now that you know where you can create your CI/CD pipeline, it’s time to start to figure out how a database can be part of that pipeline too. The main challenge is that you have to deal with the fact that when you want to deploy the changes in an existing database, you may need to preserve the existing data already stored in the database. If that database is a production database, usually the “may” becomes a “must.” All challenges start from this pivotal aspect of the database and are true for any database, relational or not. Extending the schema by adding a new column is easy and doesn’t come with any particular complexity usually. The challenges arise when you need to change the schema used by existing data. And this challenge is always true no matter if you are using a schema-on-read or schema-on-write approach. With a schema-on-write, you need to make changes to the database so that all existing data will be updated to adapt to the new schema. With a schema-on-read, for example, if you are storing data into JSON documents, you may be able to reduce drastically the complexity of the operations needed to be done on the database, but you’ll be moving that complexity into the application logic, which would need to be able to deal with different versions of the schema.
There is no such thing as a Schemaless solution. Martin Fowler cleared out this concept once and for all in his Schemaless Data Structures presentation, available to everyone for free online: www.martinfowler.com/articles/schemaless/. He introduced the concept of Implicit Schemas, which is the correct way to name what is known as Schemaless. Schemaless remains as a colloquial term, as it is so widespread, but to allow something to be manipulated, a schema must exist. And unless there are specific reasons to avoid that, an explicit schema is preferable.
Practically speaking, the challenge of dealing with database changes into a CI/CD pipeline is that usually you have a source database that has the evolved schema that your updated application is using, and you have the target database that has an existing schema that needs to be updated to become the new one. The problem is how can you create the T-SQL scripts that will bring the target database from the existing schema to the new one? And, aside from how, who will do that? And if the target database is not empty, what will be the performance implication of executing that update operation? Also, how can we be sure that data will be correctly preserved if something goes wrong? Yes, you always have transactions that can be rolled back, and in the worst case, you have a database backup available in Azure SQL for you, so at least on that side you are covered. But restoring a database may involve minutes or hours, and staying offline for that much time may not be an option you have.
To solve this challenge, it’s better to split it into two parts, and let’s do the same also with the CI/CD pipeline. It is very helpful to create two pipelines to target two different use cases.
Synthetic environment
The first pipeline will be used to make sure all changes applied to the database will be tested in a synthetic environment: an environment where the database is created from scratch every time, and the data contained in such database is a well-known set of data that represent the data we expect we’ll have to manage, plus all the data that may create unexpected and undesired condition that we have learned over time we must deal with. For example, you may not expect to have a negative number as a result of a Stored Procedure that calculates updated products costs, but this happens if the input data, read from several different tables, has certain specific values. Along with the regular, correct data you expect to have in your database, you should make sure that the dataset that generates such a condition is present in this synthetic environment database, so you can correctly verify that such a situation is correctly handled over time.
These values, the correct ones plus the issue-related ones, will grow over time, as you should add new data to this set as soon as you receive feedback and issues from testers or users. By doing so, you will have a valuable reference dataset that will grow over time and that will be extremely helpful to keep your solution free of regression bugs and issues.
Create a new database.
Deploy the schema and objects.
Load the reference dataset.
Run the tests.
Integration environment
If all the tests in the synthetic environment are executed successfully and without errors, you can then start the execution of a more complex pipeline. Now that you know your changes produce the desired results, you need to make sure that you can safely deploy them against a production database. The main goal here is to make sure that the scripts that will be used to update the existing schema and data to the new one are correct and run with the desired time.
Faker is available both for .NET and Python (and PHP, Perl, and Ruby if you really want to use some exotic languages).
Mimesis is a Python Library.
MockNeat for Java.
Faker.js for Node.
Bogus is a Faker.js port to .NET.
Restore the reference database.
Generate the T-SQL code needed to migrate the reference database to the target schema and update the existing objects while preserving existing data.
Run the generated script.
Run tests to verify results.
Database migration tools
Generating the scripts to migrate a database from an existing schema to another can involve different steps and technologies depending on which development philosophy you decided to adopt. Code first or Database first?
Code First
Code first means that you decided to drive database creation, change, and evolution directly via application code. No T-SQL script to execute manually, and no separate tools like SQL Server Management Studio or Azure Data Studio to be used.
and it will apply all the migrations. Keep in mind that this approach assumes that no changes have been done manually and externally to the database. For example, if someone manually added a column to a database that is target of the migration , without using the provided tool, the migration could fail as it does not check the current status of the object; it just assumes that the database is exactly in the same state, from a schema perspective, it was the last time a migration was applied.
Django is a full-featured web framework: if you need just an Object-Relational Mapper (ORM) to use in any Python application, SQLAlchemy also supports migrations via the Alembic package.
.NET Core also supports Code First and migrations, via Entity Framework , the native tool that comes with .NET Core.
What if you need or want to manually intervene in the migration process to make sure it can fit your needs? Automation is great, but often, some manual intervention is needed to take care of some situation that is more complex than what the automation tool can handle alone.
Luckily, all the most common Code First solutions provide a way to customize the migration steps. Depending on the language and framework you are using, there will be different strategies to apply the customization you need to have, but if, for example, you need to initialize the database with some data that must be present in the database to make your application work correctly or even make more complex changes, you are covered.
ORM and database migration tools are available almost for any platforms as a stand-alone object or embedded in frameworks; no matter what language or platform you want to use to code, if you like the idea of developing the database using a Code First approach, you can be quite sure that you’ll find a tool that will help you with that.
Executing the migration as part of the CI/CD pipeline is pretty simple as you only have to execute the same tool you used to generate and apply the migrations in the pipeline tool.
In this case, you don’t need any specialized Azure SQL Actions or Tasks in the CI/CD pipeline as you don’t need to execute any T-SQL script. You just need to be able to invoke the migration tool, which usually is a command-line application, and for that, you just use the native support to run an arbitrary command (just keep in mind that you may need to install the chosen tool in the CI/CD environment) in both GitHub Actions or Azure DevOps.
Database First
Database First means that you want to model and evolve your database independently of the applications that are using it. The term is usually tied with ORM usage . Within the ORM context, it means that you’ll have some tool that will create some of the classes you’ll be using in your application starting from the existing database tables and objects. As you can see, this is completely opposite of the Code First approach, where you have the code taking care of creating the database and the related objects.
If we take the idea of “Database First” out of the ORM context and use it in a more generic and broad sense, it just means that you want to work on the database manually, using its own tools and languages to create and evolve it. In Azure SQL case, this means that you want to write and use T-SQL and that you’ll be taking care of connecting the application and the database together, maybe using an ORM, maybe using a Micro-ORM, or maybe just doing it completely manually.
This option gives you as much as freedom you want. Once you have made all the changes to your development database, you have to create the script so that they can be applied to a target database to evolve it to the desired schema too. Again, you have a lot of freedom here: you can choose to have tools that generate the scripts automatically for you or you can provide the script by yourself.
DACPAC
If you prefer to have a tool that takes the development database you have worked on and compare it to a target database, calculate the differences, generate the needed scripts to migrate the target database to the new schema (without losing any data), and finally apply those scripts for you, you’re lucky as such tool exists, is free, and is the same tool you have already used to restore a database in Azure SQL: SqlPackage.
The ability to generate the script is useful if you want to customize it to add some initialization data, as it was happening for the Code First scenario, or just want to save the script into your code repository so that you know exactly what would be executed in the CI/CD pipeline. In this case, you may want to use the Azure SQL Action or Task in GitHub or DevOps to execute that script.
Another option could be to execute the SqlPackage directly in the CI/CD pipeline, using the specialized Azure SQL Action or Task, to apply the changes without even generating the script. This approach could be more risky, as you don’t have full control of what’s happening, and thus is not the recommended approach on average, but it is surely the most flexible as it will automatically figure out what are the needed changes to bring the target database to the desired state.
Comparison tools
SQL Server Data Tools (Visual Studio workload extension)
Redgate SQL Compare (commercial)
ApexSQL SQL Compare (commercial)
DbUp
DbUp (https://dbup.github.io/) is an open source .NET library that helps in deploying scripts in a database, making sure that the same script is not deployed twice. This little tool is incredibly useful if you want to have total control on which scripts are deployed to the database, and you are keeping a list of scripts that must be executed in order, so that the changes that you wrote will be applied in the correct sequence, thus updating the database to the latest evolution. This approach is the one that gives you the highest level of control and works very well if you prefer to write the migration scripts by yourself. In a complex and critical system, this is quite always the case.
Connect to the target database.
Create, if doesn’t exist already, a table named $__schema_journal that will track the deployed scripts.
Read all the T-SQL script available in the sql folder.
Send the log to console.
Run the scripts, saving which script has been executed in the journal table.


As this is a regular .NET application, deploying it into a CI/CD pipeline doesn’t require any special Task or Action, aside those already used to have the .NET framework available in the pipeline.
Database testing
How do you properly test a database? That’s another huge topic for which, frankly, there isn’t yet a very good answer. Testing a database is a complex challenge as test results will completely depend on the data stored in the database. In addition to that, there aren’t widely adopted testing frameworks focusing on this specific issue.
There is one community-supported unit testing framework that supports Azure SQL: tSQLt. With tSQLt, you can define tests by just using T-SQL code. It supports assertions for expected results, both scalar and tabular, and it also can create some mock objects to help you isolate dependencies.
But as a developer, my favorite method of testing a database is creating a test class using a common testing framework (like NUnit or XUnit for .NET, pytest for Python or Mocha for Node) and using the flexibility of these tools to get a nice testing experience.
It is widely known that a test must be self-contained, independent, and idempotent. The aforementioned testing frameworks all allow the execution of custom code before and after running the test, so that test data and environment can be prepared and then cleaned up.
I know that a pure Unit Test should not have any external dependency, and to test the database, we are actually introducing a dependency on the database itself. Still, I find the solution of using existing unit testing framework a good compromise that gives the needed flexibility in exchange for a small deviation from the perfect approach. Given that there aren’t universally accepted unit test frameworks for databases, we have to do the best with what we have.
Ideally for each test you want to create, you’ll generate one or more sets of data that will cover the possible scenario in which the query or the Stored Procedure you want to test will be used.
Usually to check that a query returns the expected result, you can use a small data sample, maybe even created with completely mocked values, so that you don’t have to deal with Personal Identifiable Information and all the security issues that go with it. In the most complex scenarios, before running the test, you may need to restore a reference dataset or even an entire database, so that you’ll have a well-known starting point for running the tests and thus having deterministic results.
Once you have created your tests, so that you have a solid pipeline to deploy and test the changes against a small but representative dataset, you can then instruct your pipeline to deploy your code on a bigger database, maybe containing a representative subset of production data, opportunely obfuscated, to run integration and performance tests. At this stage, you’ll focus on query performances. Several frameworks allow you to also specify that a test must be executed within a defined amount of time in order to consider a successful execution.
At this point, usually your team will execute integration and performance tests, where the database and all the code that needs to interact with it will be tested as a whole. If you are creating an API solution, you may be already using tools like Locust.io or K6 to perform a stress test and verify that the changes you have just completed are behaving as expected also from a performance, scalability, and resource consumption point of view.
Putting everything together
Creating a full, end-to-end, CI/CD pipeline can be a bit complex the first time. That’s why in the code accompanying this book, you can find an end-to-end sample that shows how to create a simple C# REST API, backed by an Azure SQL Database, and deployed on Azure using Azure Web App. The CI/CD pipeline is created using GitHub and DbUp, and the testing framework used is NUnit.
If you want to know more
Annual State of Database DevOps report – www.red-gate.com/solutions/overview
Evolutionary Database Design – www.martinfowler.com/articles/evodb.html
Agile Database Techniques – www.amazon.com/Agile-Database-Techniques-Effective-Strategies/dp/0471202835
Introduction to DevOps: DevOps and the Database – www.red-gate.com/simple-talk/sql/database-devops-sql/introduction-to-devops-devops-and-the-database/
Azure SQL Database Deployment task – https://docs.microsoft.com/azure/devops/pipelines/tasks/deploy/sql-azure-dacpac-deployment
GitHub Action for deploying updates to Azure SQL database – https://github.com/marketplace/actions/azure-sql-deploy
Django: Migrations – https://docs.djangoproject.com/en/3.0/topics/migrations/
Django: Writing Migrations – https://docs.djangoproject.com/en/3.0/howto/writing-migrations/
Entity Framework Core – https://docs.microsoft.com/ef/core/
Code First Migrations – https://docs.microsoft.com/ef/ef6/modeling/code-first/migrations/
Synchronization via SQLPackage.exe and PowerShell – www.mssqltips.com/sqlservertip/4759/sql-server-database-schema-synchronization-via-sqlpackageexe-and-powershell/
Unit testing in .NET Core and .NET Standard – https://docs.microsoft.com/dotnet/core/testing/