
Before we set off on building an anomaly detector, it is important to understand what, specifically, an anomaly is. The first part of this chapter provides us with a basic understanding of anomalies. Then, in the second part of the chapter, we will look at use cases for anomaly detection across a variety of industries. In the third part of the chapter, we enumerate the three classes of anomaly detection that we will return to throughout the book, gaining a high-level understanding of each in preparation for deeper dives later. Finally, we will end this chapter with a few notes on what we should consider when building an anomaly detector of our own.
Defining Anomalies
Before we can begin building an anomaly detector, we need to understand what an anomaly is. Similarly, before we can define the concept of an anomaly, we need to understand outliers.
Outlier
Completion times for the Men’s 200 meters competition during the 2008 Summer Olympics (Source: https://w.wiki/4CpZ (Wikipedia))
Athlete | Time (s) |
|---|---|
Usain Bolt | 19.30 |
Shawn Crawford | 19.96 |
Walter Dix | 19.98 |
Brian Dzingai | 20.22 |
Christian Malcolm | 20.40 |
Kim Collins | 20.59 |
Based on this information, it is clear that Bolt’s time was an outlier. The next question is, was it an anomaly?
Noise vs. Anomalies
Within the category of outliers, we define two subcategories: noise and anomalies. The difference between the two terms is ultimately a matter of human interest. Noise is an outlier that is not of interest to us, whereas anomalies are outliers that are interesting. This definition of anomalies matches the definition in Aggarwal (1–4) but is by no means universal—for example, Mehrotra et al. use the terms “outlier” and “anomaly” synonymously (Mehrotra et al., 4).
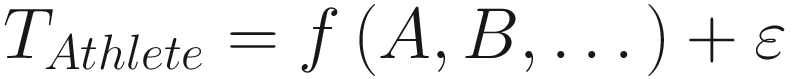
Occasionally, we might see a quarter-second difference from our expected time given some set of input values and the actual time. If we believe that this particular run still follows the same underlying function and the entirety of the difference is due to the error term, then the difference between our estimate and the actual time is, properly speaking, noise.
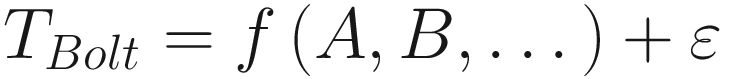
This function provides considerably lower estimates of time than the run-of-the-mill Olympic athlete (if such a thing is possible!). If we use this function and get a result that is a quarter of a second faster than data points using the normal model, the outcome makes a lot of sense. If we were expecting the normal athlete output and ended up with the Bolt output, however, the result would be an anomaly: a result that is different from the norm and of interest to us because of the difference in underlying function used to generate the result.
In practice, this understanding of an anomaly is more probabilistic than concrete, as we do not necessarily know the particular function that generated any given data points, and this makes it difficult to separate noise from anomalies. In the Bolt case, we can expect that this is an anomaly rather than noise, not only because Bolt set a new world record for the event but also because his time was so much lower than the times of other world-class athletes, giving credence to the idea that he was a class apart.
Diagnosing an Example

A dot plot plots the points scored versus passing yards. Some of the estimated values are (160, 24), (310, 34), (330, 32), (380, 34), (430, 44).
Points scored vs. yards passing by the NFL team during one week in 2020
As humans, we have certain innate and trained capabilities for analyzing this information and drawing conclusions from it, which we will cover in much greater detail in Chapter 2. For now, suffice it to say that there appears to be a positive correlation between number of passing yards and points scored in this plot.
Given the information available, we could imagine a fairly tight band that estimates the number of points scored for a given number of yards passing, drawing a thick line that comes close to or outright covers the majority of data points. Doing so would lead us to estimate that a team whose quarterback passes for 300 yards might score approximately 28–35 points on a normal day.
Having posited this theoretical model, we can then turn to the two outliers, in which the teams scored only 17 points despite their quarterbacks throwing for approximately 290 and 335 yards, respectively. This leads to two critical questions we need to answer—at least provisionally—in order to move forward with the process of anomaly detection. The first question is, is our model good enough to separate inliers from outliers properly? If the answer to this is “yes,” then the second question is, how likely is it that the outlier data points follow a completely different process from the inliers?
Over the course of the book, we will look at ideas and techniques that will help us answer these two questions. That said, the second question may be quite difficult conclusively to answer, as it hinges on our understanding of the inner workings of the process that generates these data points.
This leads to another important consideration: domain knowledge is not necessary for outlier detection, but it is for anomaly detection. Drawing back to the example in Figure 1-1, a person with no knowledge of American football can perceive the relationship in the data as well as the two outliers in the dataset. What that person cannot do, however, is to draw a conclusion as to whether these data points are merely noise or if they imply a separate pattern of behavior. Making this concrete, if those teams only scored 17 points due to bad luck, missed field goals, or facing superior red zone defenses, these factors would point toward the outliers being noise. If, on the other hand, these teams have inefficient coaching strategies that move the ball down the field but consistently fail to convert that offensive momentum into points, then we may properly call these points anomalies. A domain expert with sufficient information could help us separate the two outcomes. As we will see later in this chapter, our intent in building an anomaly detector is to provide enough information for such a domain expert to analyze, interpret, and then act upon the signals we relay.
What If We’re Wrong?
Outcomes based on outlier predictions vs. a data point’s actual status as an anomaly
Predicted Outlier | Predicted Non-outlier | |
|---|---|---|
Actual anomaly | Correct(true positive) | Type II error(false negative) |
Actual Non-anomaly | Type I error(false positive) | Correct(true negative) |
Looking at this table, we see two dimensions: whether a given data point was actually an anomaly or not and whether the prediction we made on that data point was positive (that yes, this is an outlier) or negative (no, this is not an outlier). When we correctly determine that an outlier is in fact an anomaly or a non-outlier is in fact a non-anomaly, we note that the classification was correct and can move on. There are two separate ways, however, in which we could go wrong. The first way we could go wrong is if we predicted that a data point would be an outlier, but it turned out not to be an anomaly—it was just noise. This is also known as a Type I error or a false positive. The converse of this is if we failed to state that some data point was an outlier despite its being an actual anomaly. The latter failure is known as a Type II error or a false negative. To the greatest extent possible, we want to avoid either type of error, but an interesting question arises from the fact that we classify these errors separately: Which of the two is worse?
The answer is the consultant’s famous standby: it depends. In this case, the key consideration involves the negative ramifications of missing at least one actual anomaly and not taking action on it vs. receiving alerts or performing research on data points that turn out to be completely normal but were misclassified by our detection service. How many false positives you are willing to accept to limit the likelihood of a false negative will depend on a few factors, such as the frequency of false-positive activity, the level of effort needed to determine if a predicted outlier is actually an anomaly or not, and the cost of a false-negative result. Factors such as these will help you make the decision on how strict your outlier detector should be, though we will see an alternative approach starting in Chapter 4 that can help with this problem.
Anomalies in the Wild
In this section, we will briefly cover several industries in which anomaly detection plays an important role in decision-making. A detailed analysis of any of these industries is well beyond the scope of this work, but even a brief summary should suffice in laying out the thesis that anomaly detection is a cross-industry concern.
Finance

A line and dot plot titled GameStop Average Price Anomalies. The graph plots for price, anomaly, and change point. Price has an increasing trend.
Daily closing prices for GameStop Corporation (GME) from April 13, 2020, through September 24, 2021. Anomaly determinations come from the ML.NET library
Relatively few stocks experience the turmoil that we saw with GameStop over a multimonth period, but based on information we have available at the time of writing this work, many of the outlier data points tie back to media campaigns (whether they be mass or social), due dates for options, and market movers taking sides on one of the largest market events of this generation.
Asset pricing is not the only place where anomaly detection makes sense in the financial industry. Another situation in which anomaly detection can be important is forensic accounting, that is, the review of accounting practices and financial documentation to determine if members at an organization have performed fraudulent actions. Forensic accounts do a lot more than pore over balance sheets and journal entries, but when they do look into financial documents, they are looking for patterns and anomalies.

A dot plot plots frequency versus digit, to depict the distribution of the number sequence. It has a concave-up decreasing curve.
A visual depiction of the distribution of the first digit of a sequence of numbers if it follows Benford’s Law
Not all datasets will follow this pattern, but a quick “rule-of-thumb” approach is that if a dataset includes data points spread across at least three (or preferably more) orders of magnitude, then it is likely to follow Benford’s Law. This rule of thumb holds because many of the types of distributions that do adhere to Benford’s Law—such as exponential or log-normal distributions—typically include a variety of values spread across several orders of magnitude, whereas distributions that do not adhere to Benford’s Law—uniform and Gaussian distributions being the most common—often do not. For a detailed dive into the math behind Benford’s Law, I recommend Hall (2019).
For our purposes, however, it is enough to understand that Benford’s Law can provide a forensic accountant with expectations of how the distributions of certain datasets should look, particularly datasets such as the collection of journal entries for a corporation or governmental bureau. Considerable deviation from Benford’s Law is not in itself proof of malfeasance, but it is a red flag for an auditor and typically merits further investigation to understand why this particular dataset is not typical.
Medicine
Anomaly detection is critical to the field of medicine. There exists a tremendous body of research on what constitutes healthy vs. unhealthy body measures. Examples of these measures include blood pressure, body temperature, blood oxygen saturation, and electrocardiogram (ECG) data. We can adduce that a person is currently in an unhealthy state based on significant changes in that person’s measurements vs. the norm. Note that this norm could come as a result of aggregating and averaging data from a large population of individuals or it could come from cases in which the individual is in a state of known good health.
With modern electronics, we can collect and compare data in ways previously impossible outside of a hospital room. One example of a consumer product filling this niche is the Apple Watch, which is capable of tracking heart rate data and displaying it via an ECG app. This device can notify on abnormally high or low heart rates, as well as irregular heart rhythm. Mehrotra et al. provide other examples of where anomaly detection can be valuable in the field of medicine (11–12).
Sports Analytics
Sports is a big business around the world, with Forbes rating 12 sports franchises as worth at least $3.5 billion as of 2020. Further, depending on the sport, a team may invest $200 million or more per season in player salaries. In order to maximize this return on investment, teams have spent considerable time and money in the field of sports analytics. With this emphasis on analytics, it is important to analyze and understand outliers in order not to be fooled into thinking that statistical success in one season will necessarily carry over into the next.
A $23 Million Mistake

A dot plot plots B A B P I on the horizontal axis. The dots are plotted as a straight line parallel to the horizontal axis.
Chris Johnson led Major League Baseball in 2013 with a BABIP of .394
That Johnson led the league and had a BABIP of at least 60 points (i.e., 0.060) above the norm is important because there is considerable evidence that defenses are primarily responsible for determining whether a ball in play becomes an out, not the batter himself. There are exceptions to this general principle, but the implication is that typically, a player who has a very high BABIP in one season is unlikely to replicate this in the next season. In Johnson’s case, he dropped from .394 in 2013 to .345 in 2014. Lacking considerable talents at hitting for power or getting on base, Johnson was more dependent on batting average for his offensive output than most players, and this reversion to a value closer to the mean was responsible for his offensive collapse. Had the Braves understood just how far of an outlier Johnson was in this important metric, they might not have offered him a bad contract after his 2013 season, letting some other team make that mistake instead.
A Persistent Anomaly
Greg Maddux is one of the greatest pitchers of all time. He continually stymied batters for 23 seasons in the major leagues, thanks to the incredible control of his pitches and an almost-unparalleled ability to change speeds on pitches without tipping it off to batters. Maddux also holds the honor of being the pitcher with the greatest differential between his Earned Run Average (ERA) and his Fielding Independent Pitching (FIP) ratings for players between 1988 and 2007, a range that covers the point in which Maddux turned the corner as a young starter to the year before he hung up the cleats for good.
FIP as a measurement originated in research on understanding just what factors a pitcher is able to control vs. his defense. The result of this research is that pitchers are primarily responsible for three things: walks, strikeouts, and home runs. Otherwise, the majority of contribution to batted balls in play lands squarely on the defense—just like what we saw with BABIP in the prior section.

A dot plot plots E R A - F I P versus E R A. It has an increasing trend.
ERA is plotted on the X axis and the difference between ERA and FIP on the Y. Greg Maddux’s seasons with the Atlanta Braves, during the peak of his career, are highlighted in black

A dot plot plots E R A - F I P on the horizontal axis. The dots are plotted as a straight line parallel to the horizontal axis.
Career summations of ERA-FIP for all pitchers between 1998 and 2007
In this case, we once again see an outlier: Maddux consistently outperformed on his ERA compared to FIP expectations, something very few pitchers can claim. Based on the body of work he put up, this is a case in which Maddux’s outlier status is an anomaly: his behavior patterns were different enough from other pitchers that it would be fair to say he followed a different performance function to most other pitchers.
Web Analytics
Website analytics is a great field for anomaly detection for two reasons. First, websites tend to generate enough traffic that a human could not parse through the data in any reasonable time. This necessitates the use of log aggregation and analytics tools to simplify the job, but even with these tools, the time requirements for a thorough analysis may be daunting. The second reason is even more important: there exists a constant undercurrent of errors on any site. Automated tools constantly scan websites and public IP addresses for known, common vulnerabilities. This can lead to 404 (file not found) errors from requests for a file like index.php on a .NET-hosted site. These are not legitimate requests and are frequent enough that they will overload with noise in any naïve system that broadcasts alerts assuming you do not filter these messages out.
It may be enough to filter out illegitimate errors, but there exist at least two more classes of uninteresting error: outdated links and accidental errors. For an example of the former, suppose I send an email with a link to a photograph I have put online. Some number of years later, I have deleted the photograph from the website, but you still have the link in your email. If you open that link, you will get a 404 (file not found) error, as the resource no longer exists. For an example of the latter, I may attempt to access a URL from memory and, during the process, accidentally strike the wrong key, leading to a typo. This could lead to a 404 error as well. Similarly, I might accidentally click on a protected link, be prompted for credentials, and then select Cancel, leading to a 403 (not authorized) error. These are legitimate errors, but from the standpoint of a systems administrator, this is normal and expected behavior. There is nothing for the systems administrator to “fix” because everything is working as designed.
Where anomaly detection can be interesting is in finding errors above and beyond the “background radiation of the Internet” (with credit to Steve Gibson for the analogy) and common miscues. Suppose a new product release goes out and the development team has enabled a feature flag that sends 1% of traffic over to a new page, leaving 99% to stay on the existing page. Suppose further that there is a problem on the new page, such that some percentage of people receive 404 errors pertaining to missing resources on the page. Now we have a different pattern of behavior—it is no longer one or two failed requests for a given resource, nor is it broad-based noise. An anomaly detection system that can find these sorts of errors and alert on them while filtering out most of the preceding noise can save systems administrators and development teams considerable time while still finding code release issues before a customer issues a trouble ticket.
And Many More
By this point, it should be clear that anomaly detection is not limited to a single industry or field of study but instead is broadly applicable. Furthermore, it turns out that there are a common set of anomaly detection techniques that are independent of field or industry, meaning that the techniques we learn in this book will be applicable regardless of your industry.
Now that we have completed a brief survey of anomalies in the wild, the next step is to look at the three classes of anomaly detection.
Classes of Anomaly Detection
There are three broad classes of anomaly detection technique available to us. We will look at each in turn, based on the order in which they appear in subsequent chapters. All three techniques are valuable in their own domains, making it worthwhile to understand the key components of each in order to apply the best approach to a given problem.
Statistical Anomaly Detection
The first class of techniques for anomaly detection is statistical anomaly detection techniques. With these techniques, we assume that the data follows some particular underlying distribution—for now, think of this as the shape of a dataset—but other than the distribution of the data, we make no assumptions about what this data “should” look like. In other words, we do not have a model in which, given some set of inputs, we will get some specific predicted output.
For statistical anomaly detection techniques, outliers are cases that are significantly distant from the center of our distribution—that is, they are far enough away from the center that we can expect that they aren’t really part of the same distribution. The definitions of “significantly different” and “far enough away” are necessarily loose, as they may be user-configurable and likely depend on the domain.
Chapters 6 through 8 focus on incorporating statistical techniques into a generalized anomaly detection service.
Clustering Anomaly Detection
The second class of techniques for anomaly detection focuses on clustering. The concept of clustering is that we group together points based on their distance from one another. When points are sufficiently close to one another, we call those groupings clusters. We make no assumptions regarding underlying relationships in the data—that is, how individual data points end up clustered together. We do not assume that the data follows any particular distribution, nor do we attempt to build a model of inputs relating to outputs. Instead, we are concerned only with the outputs and the clusters they form.
When performing outlier detection using clustering techniques, we consider a data point to be an outlier if it is sufficiently far from any given cluster. This makes sense given our definition of an outlier as a point sufficiently distant from the norm but requires us to expand our understanding of “the norm” from a single point—like the center of a distribution—to a set of points, each of which may be independent of the others.
Chapters 9 through 11 will focus on incorporating clustering techniques into a generalized anomaly detection service, and Chapter 12 introduces an interesting variant on clustering.
Model-Based Anomaly Detection
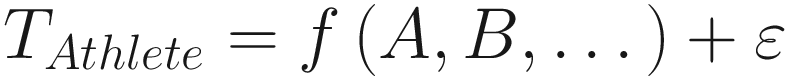
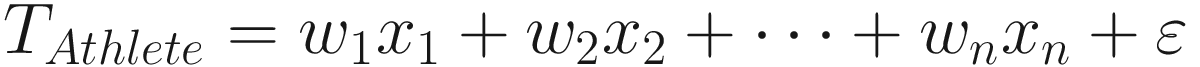
Outliers in this case are cases in which the actual calculated data point is substantially different from the predicted data point. Going back to the case of Usain Bolt, we might plug in our sets of weighted inputs and (for example) get a time of 20.10 seconds for the Men’s 200 meters competition. When he runs it in 19.30 seconds, our prediction is far enough off that Bolt’s time becomes an outlier. Then, we can make the leap in intuition that Bolt does not follow our normal model but instead follows a different model, one that might have different weights on the input variables or may even include variables not relevant to others. Whatever the case may be, once we assume that Bolt follows a different model, we can now assert that those outliers are in fact anomalies: they were generated from a different process than the one that generates the majority of our data.
Making this leap requires one key assumption: the model we select fits the behavior of the underlying phenomenon sufficiently well in the large majority of cases. If our model is not good at predicting results, we will end up with incorrect depictions of outliers, as the model is insufficiently good at determining what constitutes normal behavior. If that is the case, we should not trust the model to tell us that something is an outlier.
Chapters 13 through 17 focus on one particularly interesting variant of model-based anomaly detection: time series analysis.
Building an Anomaly Detector
Now that we have a high-level idea concerning what an anomaly is and what techniques we might use to find anomalies, it is time to begin the process of building an anomaly detection service, something we will work toward throughout this book. Before we write a line of code or dive into research papers, however, we need to gain a better understanding of how our customers might make use of an anomaly detection service. For now, we will look at three key design concepts.
Key Goals
The first thing we will need to understand is, what is the purpose of our anomaly detection service? There are several reasons why a person might want to make use of an anomaly detection service. The first reason is to alert a human when there is a problem. For example, going back to the web analytics case, we want to alert systems administrators and developers when there is a problem causing people not to see relevant web resources. At the same time, we do not want to alert staff to things like automated bots poking for common vulnerabilities (and failing to find them) or people mistyping URLs.
A second reason, entirely separate from alerting, is to test a conjecture. Table 1-1 showed us just how fast Usain Bolt was during the 2008 Olympics, and we could see that the difference in times between Bolt and the rest of the competitors was drastic. That said, we may wish to see a more objective analysis of the data, something that might determine the probability that a normal Olympic athlete could run 200 meters in Bolt’s 19.30 seconds. This backward-looking analysis does not necessarily lead to some subsequent alerting requirement, marking it as a separate use case.
A third reason why we might want to use an anomaly detection service does follow from the alerting scenario in the first use case, but it also goes one step further: we could use an anomaly detection service to allow a program to fix an issue without human intervention. For example, suppose you sell high-end computer monitors with an average retail value of $1,500 USD. A major holiday is coming up and you want to discount the cost of your monitor by $150 USD, selling it for a total of $1,350 USD. Unfortunately, in trying to apply the discount, you set the price to $150 USD, and a large number of orders come in as people find this monitor marked at 90% off its retail price. This leaves the company in a bad position, needing either to allow the orders and absorbing a major loss or cancelling the orders and potentially raising the ire of customers as well as the shopping platform—in the latter case, potentially jeopardizing the customer’s relationship with the platform to the point where the customer gets banned from selling on that platform. An alerting service might indicate that the price range for this monitor has never strayed from $1300–1500 USD and this new price is radically different. We could imagine a system that prevents the price change from going out before a human confirms that this is, in fact, the intended price.
Finally, we may not even know what “normal” looks like and wish to discover this. For example, suppose we wish to find out what type of person is most likely to purchase a $1,500 monitor. Given demographic details, we might find that there are certain clusters of individuals who tend to purchase our monitors and we might market toward those customers. The outliers from this process will also be interesting because they might be indicative of potential groups of customers who have not purchased our monitor but might be inclined to if we understand more about their desires. Given information on outliers, our analysts may perform market research and determine if there are untapped segments of the market available and, if so, how to reach these people.
How Do Humans Handle Anomalies?
The next consideration is to ask yourself, how will the humans who use your anomaly detection service handle reports of outliers and determine whether a given outlier is actually an anomaly or if it is merely noise? For example, is there a specific investigative process that a human should follow? In a manufacturing scenario, we might imagine anomaly detection on sensors such as machine temperature or the amount of pressure a given machine exudes to press and fold a box. Suppose that a human observes the machine temperature and, if the temperature rises beyond an acceptable level, the human presses a button to dispense a cooling agent. If that action does not lower the temperature to an acceptable level, the human then presses another button to slow down the operation. Finally, if the temperature still remains well outside of normal parameters, the human presses yet another button to halt the line until the machine has cooled down or a technician has completed an investigation of the machine.
The reason it is important to understand how people will use your anomaly detection service is that you might be able to help them automate certain processes. In the preceding scenario, we could easily imagine a system feeding temperature data to our anomaly detection service and, upon receipt of a certain number of outliers in a given time frame, automatically perform each of the three steps. Providing a more nuanced solution, perhaps the service would automate the dispensation of a cooling agent while writing a warning to a log. Then, if the system slows down the operation, it might alert the technicians on staff to make them aware of the problem, leaving the option of complete shutdown to a human.
In the event that we cannot automate this kind of activity, users may still find value in having an anomaly detection service because it could provide the basis for an investigation. Returning to the website analytics example, an abnormal number of errors—whether that be an abnormally large number of errors in general or an abnormal number of a particular class of error like 404 (file not found) or 403 (not authorized)—could give systems administrators enough information to dive into the logs and track down what might have caused a change in behavior, be it a code deployment, infrastructure change, or failing service.
In between these two levels of interactivity, we could also anticipate having a service that depends on the anomaly detection service and, upon receipt of an outlier, queues something for manual review. An example of this would be manual review of automated price changes on products. The large majority of the time, we might not want manual reviews of changes because the number of products changed can be quite large. An incident in which the price of a product is dramatically different from its norm, however, would be a great case for manual review before the actual price change occurs. This might save a company considerable pain down the line.
When trying to discern the specific intentions of the callers of your service, the most important question is, what domain knowledge is necessary in humans when you alert them to a potential anomaly? An anomaly is, using our accepted definition, necessarily interesting. What information does a human have that makes this thing interesting and not just another incident of noise? Furthermore, how much of that information can we automate or transfer to machines? Not everything is amenable to automation, whether due to a lack of appropriate equipment or because of the amount of disparate, subjective knowledge in the heads of a variety of people preventing an automated solution from being viable. That said, the typical reason for existence of an anomaly detection service is to provide information on potential anomalies for subsequent investigation and potential action.
Known Unknowns
As we wrap up this discussion of anomalies, we have one final consideration: How much information do we already have on existing anomalies? Suppose that we have a history of all temperature recordings for a given machine. Further, an expert has combed through each of those recordings and determined whether or not the machine behaved incorrectly, allowing us to correlate high temperature with improperly machined products that we needed to repair or scrap. Armed with this information, we can perform supervised learning, a subset of machine learning that uses known good information to draw conclusions on unknown information. Supervised learning is a particularly popular class of machine learning in the business world—the majority of machine learning problems tend to fit supervised learning scenarios, and there exists a wealth of tooling and research into supervised learning techniques.
Unfortunately for us, anomaly detection tends not to fit into the world of supervised learning, as we rarely have the luxury of experts building comprehensive datasets for us. Most often, we have to perform unsupervised learning, another class of machine learning in which we do not have known good answers as to whether a particular data point was an anomaly. Instead, it is up to us to discover whether that given data point was anomalous. As we will see throughout this book, there are plenty of techniques we can use for unsupervised learning, but all of them come with the caveat that we cannot easily determine how correct (or incorrect) our anomaly detector is, as we do not have good information on what constitutes an anomaly vs. a non-anomaly.
Sometimes, we may have knowledge of some prior anomalous scenarios. This is a middle ground between the two variants known as semi-supervised learning. The idea here is that we may have a tiny amount of known good data, such as a recorded history of some anomalies, and use this information to train a model as we do in the supervised scenario. From this tiny sample, we use clustering techniques to determine which data points are sufficiently similar to our known anomalies and proceed to label these similar data points as anomalies. We can show those points marked as outliers to humans and have them tell us whether our predictions were right or not, thereby expanding our known input data without using a lot of time and energy to review large amounts of data. Semi-supervised learning is typically more accurate than unsupervised learning, assuming you have enough valid data to create an initial model.
Conclusion
Over the course of this first chapter, we laid out the nature of outliers, noise, and anomalies. Outliers are values that differ sufficiently from the norm. Noise and anomalies are partitions of the set of outliers. Outliers that are not of interest are noise, whereas interesting outliers are anomalies. Anomaly detection is important wherever there is statistical analysis of problems, meaning that anomaly detection has a home in a wide array of industries and fields.
There are three classes of anomaly detection technique that we will focus on throughout the book: statistical, clustering, and model-based techniques. Each class of technique brings its own assumptions of the data and scenario, and each is valuable in its own regard. We will see that certain types of problems are more amenable to one class of technique than the others, so having a good understanding of all three classes is important.
Finally, we looked at the human element of anomaly detection. No matter how well your service detects anomalies, it is useful inasmuch as it provides value to humans. To that extent, understanding the needs of those who use your service can help you build something of great value. Although we will focus on the technical aspects of outlier detection and software development, be sure to keep your end user in mind when developing the real thing.