
Chapter 11. Agile Security Testing
One of the most fundamental changes in Agile development is in how testing is done. Because Agile teams move so fast, testing relies heavily, and often exclusively, on automation. If you are delivering working software every week, or if you’re pushing each change to production immediately in continuous deployment, manual testing isn’t a viable option.
Throwing code over to an independent test team at the end of a sprint is an anti-pattern in Agile. Testing has to be done in phase as changes are made. Hardening sprints, where the team blocks off time to focus on testing, debugging, and patching the code before it can be deployed to production, is another practice that most modern teams avoid.
Organizations that depend on independent test teams for quality assurance, and on manual penetration testing gates or scheduled scans or audits for security, need to change the way that they think and work.
How Is Testing Done in Agile?
In many Agile and DevOps teams, there are no testers. Developers take on the responsibility for testing their own code, because they have to. The Product Owner or someone else on the team playing the role of the “customer” may write acceptance test scenarios using tools supplied by the team. But developers are responsible for writing all the other tests and making sure that they pass. Testing becomes an integral part of coding, instead of a separate Waterfall phase.
Because developers are constantly making iterative changes to code as they run experiments, refactor, and respond to feedback, they need to protect themselves from accidentally breaking existing system behavior. They do this by building up a safety net of automated regression tests which they will run several times each day. These tests must be:
-
Cheap and easy for the team to run often
-
Fast and efficient so that the team will run them often
-
Repeatable and predictable so that the team can rely on the results
The same requirements apply to security testing. Security tests need to be fast, repeatable, efficient, and automated as much as possible. As much as possible, security testing should fit into engineering workflows like the other testing that the team is doing, without causing unnecessary delays or adding unnecessary costs.
If You Got Bugs, You’ll Get Pwned
We know that there is a strong connection between code quality and security. The more bugs you have, the more security problems you will have.
Research has found that up to half of software security vulnerabilities are caused by simple coding mistakes. Not design oversights or misunderstanding security black magic. Just silly, sloppy things like copy-and-paste or merge errors, not checking input parameters, bad—or no—error handling, brackets in the wrong spot.
Carnegie Mellon’s Software Engineering Institute has found that between 1% and 5% of all software defects are security vulnerabilities.1 This means that you can get a good idea of how secure your application is, based on how many bugs there are in your code.
Given that most software has somewhere between 15 and 50 bugs in every 1,000 lines of code (this is even after the code has been reviewed and tested), a small mobile application or web application with, say, 50,000 lines of code could easily have over 100 vulnerabilities.2 Remember that almost all modern applications contain a lot of open source code, so even if you are doing everything right when it comes to writing secure code, you can’t be sure that all the open source contributors were as careful, so you should lean toward an even higher number of vulnerabilities. Software quality problems—and security risk—increase significantly with the size of the code base. Large systems have much higher defect densities, which means these systems are increasingly more vulnerable.
Many high-profile security vulnerabilities, including Heartbleed and the Apple “goto fail” (EX1-A) SSL bugs, were caused by coding mistakes that could have and should have been caught in code reviews or through disciplined unit testing. No security wizardry required. Just solid defensive coding and close attention to testing.
Example 11-1. Apple Goto Fail…can you spot the bug?
staticOSStatusSSLVerifySignedServerKeyExchange(SSLContext*ctx,boolisRsa,SSLBuffersignedParams,uint8_t*signature,UInt16signatureLen){OSStatuserr;...if((err=SSLHashSHA1.update(&hashCtx,&serverRandom))!=0)gotofail;if((err=SSLHashSHA1.update(&hashCtx,&signedParams))!=0)gotofail;gotofail;if((err=SSLHashSHA1.final(&hashCtx,&hashOut))!=0)gotofail;...fail:SSLFreeBuffer(&signedHashes);SSLFreeBuffer(&hashCtx);returnerr;}
It’s clear that your team’s security program needs to build on its quality program, on the reviews and testing that are already in place, or that should be put into place. Let’s look at the structure of how testing is done in Agile development, and where security needs to be considered.
The Agile Test Pyramid
We introduced the Agile Test Pyramid earlier in this book. Now let’s drill down into how it actually works, as shown in Figure 11-1:
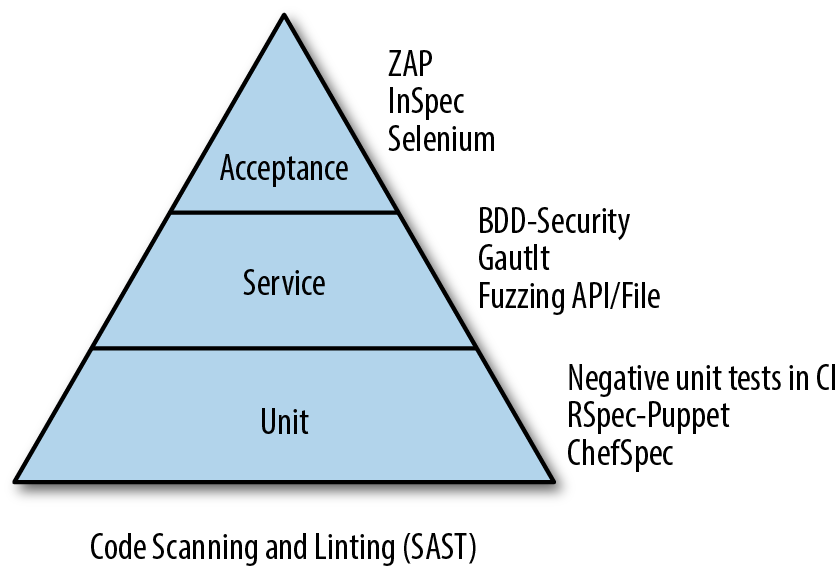
Figure 11-1. Security testing mapped to the Agile Test Pyramid
The test pyramid emphasizes lots (thousands, or tens of thousands) of low-level, automated unit tests at the base. These are white-box tests at the method or function level, written by developers to ensure that the code does what they expect it to do, using a test framework like xUnit (JUnit for Java) or TestNG.
Unit tests are the cheapest tests to write, the cheapest to run, and the easiest to change (which is good, because these are the tests that need to be changed most often).
Unit Test Doubles, Mocks, and Stubs
To create unit tests, developers write test code for each method or function, and create test fixtures or test doubles—mocks and stubs—to swap out dependencies with test implementations.
A stub simply replaces an existing dependency for the function being tested. It returns hardcoded responses, and might record what it receives from the function being tested. There may be more than one stub for each test.
A mock is a smart, fake object that decides whether the unit test passes or fails. It checks whether the function under test did what was expected and will fail the test if results don’t meet expectations.
The middle of the pyramid is made up of black-box API and integration tests, “subcutaneous” tests that assert behavior at the service level and that test published APIs between services. These tests may be written using frameworks like FitNesse or Cucumber or JBehave.
Because tools like Cucumber can also drive higher-level acceptance tests through the user interface, the boundaries between layers can sometimes be blurred. The key thing to think about here is that this level of testing doesn’t focus on the user experience, but rather on interaction between services and on testing service APIs and domain logic at higher levels of abstraction than unit tests.
At the top of the pyramid are UI-level acceptance tests: fat, high-value user-facing tests that check the important features and key use scenarios in the application. Acceptance tests are end-to-end tests that demonstrate to users and owners of the system that it is ready and working. These are the most expensive tests to write and run, and the most brittle (because they test so many different moving parts), so you want to keep the number of these tests to a minimum.
Some teams will script acceptance tests using a test tool like Selenium WebDriver, Sahi, or Watir. These scripts may be written by the Product Owner or a business analyst, or by a tester, and implemented by the development team. Acceptance tests may also be done manually, in demos with the customer, especially where the tests are expensive or inconvenient to automate.
The Agile Test Pyramid is a different way of thinking about where and how to focus your testing effort, as opposed to the traditional “Test Ice Cream Cone,” which depends on a lot of manual or record/playback tests at the UI level executed by an independent test team, and few or no automated tests written by developers at lower levels.
Let’s look at how to include security testing in each one of these layers.
Unit Testing and TDD
Starting at the base of the pyramid, we need to understand how and why developers write unit tests, and what this means to system security.
Developers write unit tests to prove to themselves that the code does what they thought it was supposed to do. They usually write these tests after they make coding changes, and run the tests before checking their code in. The tests are checked in along with the code so that they can be shared with the team—and run in continuous integration.
Many developers will write one or more unit tests as a first step in fixing a bug: write the test to duplicate the bug, run the test to prove that the test catches the bug, fix the bug, and run the test again to prove that the fix worked (and to catch the bug if comes back again by accident, as part of your regression testing going forward).
Some teams (especially XP teams) are “test obsessed” and take this approach further in what is called test-first, or test-driven development (TDD). Before writing any code, they write tests that specify what the code is supposed to do. They run the tests, prove that the tests fail, then write the code and run the tests again, filling in the code until the tests pass, switching back and forth between incrementally writing tests and writing code. The tests guide their thinking and their coding.
They can then rely on this testing safety harness to catch mistakes later as they refactor the code, restructure and clean it up, or make other changes.
Teams working this way naturally end up with higher levels of automated unit testing coverage than teams who work “test last,” and there is evidence that test-first development can result in better quality code that is easier to understand and change.3
What Unit Testing Means to System Security
But even in test-obsessed environments, there are limits to what unit testing can do for security. This is because unit testing tests what the developer knows to look for: they assert, or reassert, expected behavior. Security problems, like the Spanish Inquisition, are rarely, if ever, expected.
There are some security vulnerabilities that can be caught in unit testing—if you take unit testing seriously enough.
For example, both the OpenSSL Heartbleed bug and Apple’s Goto Fail vulnerabilities could have been caught by careful unit testing, as Mike Bland, a former Test Mercenary at Google, explained in a post about testing culture on Martin Fowler’s blog.
These high-profile vulnerabilities were caused by small, careless, low-level coding mistakes in security-sensitive code that got past smart developers, including the entire open source community. They were caused by not checking the length of a data parameter for Heartbleed, and a copy-and-paste or merge error in the case of Goto Fail. Bland wrote a set of straightforward but well-thought-out unit tests which showed how these problems could be caught, and that also helped to make the code simpler and easier to follow by refactoring the code to make it testable.
Unfortunately, as we’ll see, unit testing is rarely done this thoroughly—and certainly wasn’t done thoroughly at Apple or by the OpenSSL team.
Other security vulnerabilities are caused by fundamental oversights or ignorance. You missed implementing a control completely because you didn’t know you were supposed to include it in the first place. Forgetting an access control check, trusting data when you shouldn’t have, not parameterizing database queries to prevent SQL injection.
You can’t find these mistakes through unit testing. Because if you don’t know you are supposed to do something, you won’t write a test to check for it. You will have to depend on somebody else who knows more about secure coding to find these mistakes in a code review, as we discussed in the previous chapter, or hope that they will get caught by a scanner or in pen testing.
Get Off the Happy Path
Most (if not all) tests that developers write are positive, “happy path” tests, because developers want to prove to themselves, and to the user, that the code works. And the best way to do that is to write a test that shows just this.
QA (if there is QA) in most organizations often works the same way, spending most of their time writing and running through acceptance test checklists which prove to themselves, and the customer, that the features work as specified.
So we end up with a set of tests covering at least some of the main success scenarios through the application, and not much else.
The problem is that attackers don’t stay on the happy path. They hack their way in by purposefully trying to step around, over, and into parts of the code in ways that developers did not expect.
It is really, really hard to get developers to think and work like attackers, because they aren’t trained to do this, and they don’t get paid to do this. Developers have enough of a challenge understanding and visualizing what the system is supposed to do and getting the code to do that. Unlike hackers, they don’t—and can’t afford to—spend hours thinking about how to abuse or break the system and look for small mistakes or inconsistencies. Most of the time, developers barely have time to write tests to prove that the code works.
This has serious consequences for security. Let’s go back to Dr. David Wheeler’s paper on “How to Prevent the Next Heartbleed” to look at unit testing from a security point of view:
Many developers and organizations almost exclusively create tests for what should happen with correct input. This makes sense, when you think about it; normal users will complain if a program doesn’t produce the correct output when given correct input, and most users do not probe what the program does with incorrect input. If your sole goal is to quickly identify problems that users would complain about in everyday use, mostly-positive testing works.
Even test-driven development or test-first development emphasizes writing tests that describe what the function should do—not what it should not do. With TDD, developers will end up writing a lot of tests, but almost all of these tests will be around success cases, and possibly some basic exception checking.
High levels of test coverage for positive tests aren’t good enough to provide assurance. To meet security requirements, we also need to do negative testing (more from Wheeler):
Mostly-positive testing is practically useless for secure software...You should include invalid values in your regression test suite to test each input field (in number fields at least try smaller, larger, zero, and negative), each state/protocol transition, each specification rule (what happens when this rule is not obeyed?), and so on.
As a security professional, or a developer or tester who cares about security, it’s important to ensure that comprehensive negative testing like this is done for security libraries (such as crypto code), and other important platform code and high-risk features, if you want to have confidence in your tests.
Now let’s move up the testing pyramid, and think about other places where security testing can and should be added in continuous integration or continuous delivery.
Service-Level Testing and BDD Tools
In addition to low-level unit tests, we want to have a set of meaningful integration tests and service-level tests that exercise the APIs of the system. These are black-box tests that check the important functions to ensure that they work under real-world conditions.
A common way to write these kinds of tests is using a behavior-driven development framework. Behavior-driven development (BDD) starts with specifications written in high-level English-like language: business stories that are understandable to the customer and testable.
There are a couple of BDD frameworks written specifically for security testing that can be run in CI or CD pipelines to execute automated tests and checks every time that a change to code or configuration is made.
Gauntlt (“Be Mean to Your Code”)
Gauntlt is a Ruby-based BDD test framework that makes it easy to write security tests and checks against your application and its configuration. It comes packaged with attack adaptors that wrap the details of using security pen testing tools, and several sample attack files:
-
Checking your SSL configuration using sslyze
-
Testing for SQL injection vulnerabilities using sqlmap
-
Checking network configuration using nmap
-
Running simple web app attacks using curl
-
Scanning for common vulnerabilities using arachni and dirb and garmr
-
Checking for specific serious vulnerabilities like Heartbleed
You can extend or customize these attacks, or use them as examples to build new attacks. Gauntlt also includes a generic attack adaptor that can be used to execute any command-line-driven tool that uses stdin/stdout. This makes it relatively easy to create new custom attacks of your own.
BDD-Security
BDD-Security is another open source high-level automated security testing framework, written in Java. It includes a predefined set of tests for SSL checking (again using sslyze) and scanning for runtime infrastructure vulnerabilities using Nessus.
But one of the most powerful capabilities of BDD-Security is that it integrates nicely with Selenium WebDriver, a popular tool for automating functional tests. It includes templates and sample code that you can use to create your own automated tests for authentication and access control, and to automatically scan web applications using OWASP ZAP as part of your automated functional testing.
Let’s Look Under the Covers
Both Gauntlt and BDD-Security use Cucumber, an automated testing tool, under the covers. In Cucumber, you write tests in a Ruby DSL (Domain Specific Language) called Gherkin, following this syntax:
Given {preconditions}
When {execute test steps}
Then {results should/not be}
Each test returns a clear pass/fail result, which makes it easy to plug these tests into your CI or CD pipelines.
Now let’s look at how Gauntlt attacks work in a bit more detail.
A Gauntlt attack file is any file with an .attack suffix. Each attack file contains one or more scenarios, each consisting of multiple Given/When/Then steps:
Feature:Attack/Check descriptionBackground:set up tests for all scenariosScenario: specific attack logic in Given/When/Then formatGiven“tool” is installedWhenI launch a “tool” attack with:“””whatever steps“””Thenit should pass with/should contain/and should not contain:“””results“””
The command:
gauntlt –-steps
lists the pre-built steps and attack aliases for common scenarios that you can use in your attacks:
launch a/an “xxxxx” attack with: the file should (not) contain
Output parsing is done using regex to determine pass/fail status.
Gauntlt and BDD-Security help security teams and developers work together by providing a common and simple language to describe tests and easy-to-use tools. For teams that are already following behavior-driven development, these tools should be a natural fit.
Other teams that have already invested in their own tooling and test frameworks, or that don’t buy in to the BDD approach and prefer to stay closer to the technical details, can write their own scripts to do the same kind of things. The goal should be to come up with a set of automated tests that probe and check security configurations and runtime system behavior for security features that will execute every time the system is built and every time it is deployed.
Acceptance Testing
Acceptance tests are generally done at the UI level by driving a browser or mobile client to execute a set of tests which exercise the key features of the application. Automated acceptance tests need to be written for security features such as authentication and user and password management, as well as for key functional workflows that handle money or private data. These are features that must work every time, which means that they need a high level of test coverage. They are also features which should rarely change, which makes them good candidates for automated acceptance testing.
This can be done with a test tool like Selenium WebDriver, PhantomJS, or Sahi. These tools allow you to programmatically launch and control a browser or web client, navigate to pages, locate elements on the UI, perform UI actions like entering data or clicking on buttons, and ask questions about the state of the UI objects or data.
Functional Security Testing and Scanning
Application pen testers use a variety of tools to understand and attack a system, including the following:
-
Proxies to intercept traffic between a browser or mobile client and the application, letting them examine and tamper with the requests and responses
-
Web spiders to crawl the application and search out all the links, mapping out the attack surface
-
Application vulnerability scanners which use this information to attack the application by injecting malicious payloads against every parameter and field, trying out common attacks
Penetration testing tools like Arachni or Burp, or on-demand scanning services from companies like WhiteHat or Qualys, are good at finding vulnerabilities like SQL injection or XSS, as well as other kinds of vulnerabilities that static code analysis scanners can’t find. These include weaknesses in session management such as CSRF, serious runtime configuration mistakes, and access control violations.
You don’t need to be a pen tester to take advantage of these tools as part of your own security testing program. But you will need to find tools that can be easily automated, that are simple to set up and use, and that will provide fast feedback to developers on security problems.
ZAP Tutorial
A good place to start with is the OWASP Zed Attack Proxy, aka ZAP, a popular open source security testing tool.
Although ZAP is powerful enough to be used by professional pen testers, it was originally written for developers and testers who don’t have security expertise. Which means that it is simple to understand and run—at least for a security tool.
We’ll look at ZAP and how it fits into rapid testing cycles, because it will illustrate the challenges of trying to use scanning in continuous integration and continuous delivery, and because the patterns that we’ll describe can be used with other tools.
The simplest way to try out ZAP and see how it works is its “Quick Start” mode. ZAP will ask for a URL, spider the application, and run basic canned attacks against what it finds. This will attack only the publicly-exposed attack surface of the system—it won’t be able to attack any functions that require the user to be authenticated. The Quick Start will give you a taste of what ZAP can do. If it finds any serious vulnerabilities at this early stage of testing, you need to fix them immediately: if it was this easy for ZAP to find them, you can bet that an attacker can find them too, or already has.
If you want to get a better understanding of ZAP and do a better job of testing your application, you can configure ZAP as an intercepting proxy, and then run some functional tests against the application: log in to the application and navigate through some of the key forms and functions of the application.
ZAP will record what you do and build up a model of the application and how it works. While it is doing this, it will inspect responses from the application and look for common, simple mistakes—this is called passive scanning. Once you have finished your set of manual tests, you can tell ZAP to run an active scan against the pages that you’ve just tested. ZAP will try to inject malicious payloads into every field and parameter that it has seen, and observe how the system responds to these canned attacks.
As ZAP finds problems, it will report alerts, showing the request and response as proof of a successful attack, an explanation of the attack scenario, and other information to help you understand what happened and how to fix the problem.
The steps to do this are relatively straightforward:
-
Make sure that you have a recent version of ZAP so that you can take advantage of the latest capabilities and scanning rules—ZAP is updated weekly, so you can decide to take the weekly build (and try out the alpha or beta rules), or you can stick with the most recent official, stable release.
-
Start ZAP.
-
Fiddle a bit with the browser configuration to set up ZAP as a proxy (the ZAP user guide will help you with this).
-
Log in to the application and navigate to where you want to test, then walk through test scenarios for that form. If the feature that you want to test supports multiple user types, you will want to repeat these steps for each type of user.
-
Review the passive scanning results. ZAP will check HTTP headers, cookies, and parameter return values for common security mistakes.
-
Run an active scan and review the alerts. ZAP will execute a set of canned attacks against the fields and parameters that it has seen.
-
Compare the alerts against previous findings to identify anything new, and filter out false positives.
-
If you want to go further, you can try to spider the rest of the application, and run active scanning against those pages as well. You can also look at using some of the more advanced pen testing and fuzzing features in ZAP, to dig deeper.
But all of this takes time: time to set up ZAP and the browser configuration, time to run the manual scenarios, time to review the results and filter out the noise. This is time that developers, especially developers on Agile teams, do not have.
ZAP in Continuous Integration
A better way to run ZAP is automatically, in your continuous integration or continuous delivery pipeline.
Start with a simple set of smoke tests, using the ZAP Baseline Scan. The Baseline Scan is a Docker container that comes pre-packaged with the latest version of ZAP and the latest rules, set up to execute an abbreviated Quick Start test of your application. By default it spiders your app for one minute, runs passive scans, and reports back the results in a few minutes at most.
The Baseline Scan is designed to act as a health check that you can run frequently in your build and deployment pipeline (and even in production) to make sure that the application is configured safely, including HTTP headers and other security policies. This is how it is used at Mozilla, for example, where it was developed.
You can also include security checks as part of automated acceptance testing, following the same approach as you would in manual testing. Take a set of automated functional acceptance tests written using a tool like Selenium WebDriver, and proxy the test run through a ZAP instance running in headless mode.
This will give you confidence that at least the main user functions of your application don’t have any obvious security problems.
All of these steps can be scripted and automatically executed by your CI/CD server.
You can use Javascript or ZAP’s ZEST scripting language, its command-line interface, or its REST API to instruct ZAP to report passive scan findings, optionally spider the application and wait for the spider to finish, set scanning policies and alert thresholds, and run active attacks.
ZAP can report the results in HTML, XML, or JSON format, which means you can write scripts to examine the results, filter out false positives, and compare the results to previous runs to identify new findings.
If you are using Jenkins, for example, you can take advantage of ZAP’s Official Jenkins plug-in, which makes it easy to execute ZAP commands directly from Jenkins and to check the results in your build pipeline.
BDD-Security and ZAP Together
Or you can use a higher-level test framework like BDD-Security, which we have already looked at briefly. BDD-Security wraps execution of ZAP scans and Selenium tests inside a behavior-driven design framework. Using BDD-Security, you write security stories in Cucumber’s high-level Given/When/Then format. The test framework takes care of the details of setting up and running the test tools, parsing the results, filtering results, and determining pass/fail status.
Example 11-2 is a sample story included with BDD-Security for executing a scan with ZAP and checking for SQL injection.
Example 11-2. BDD-Security Story
@app_scanFeature:Automated Application Security ScanningRun automated application level tests against the application using OWASP ZAPBackground:Givena new scanning sessionAnda scanner with all policies disabledAndall existing alerts are deletedAndthe application is navigatedAndthe application is spidered@cwe-89Scenario:The application should not contain SQL injection vulnerabilitiesAndthe SQL-injection policy is enabledAndthe attack strength is set to HighAndthe alert threshold is set to LowWhenthe scanner is runAndthe following false positives are removed|url|parameter|cweId|wascId|Andthe XML report is written to the file build/zap/sql_injection.xmlThenno medium- or higher-risk vulnerabilities should be present
BDD-Security comes with stories for different kinds of scans as well as SQL injection, server-side include and server-side injection attacks, remote OS command injection, CRLF injection, external redirect, LDAP injection, xpath injection, and generic padding oracle attacks.
BDD-Security, together with Selenium, can be used to write and execute acceptance-level tests for authentication features to check that authentication is properly set up and to test negative error handling cases. It can also write access control checks to ensure that users can only see or do what they are authorized for. To do this you’ll need to modify the sample Java code that comes packaged with BDD-Security.4
Scanning APIs
OWASP ZAP and BDD-Security (with a bit of custom coding to extend some test plumbing classes) can also be used to scan REST APIs. The approach is roughly the same as testing a web app, using ZAP as an intercepting proxy while you exercise API functions with other tools, and running passive and active scans against the exposed surface of your APIs.
A more comprehensive and accurate approach to scanning APIs would be to take advantage of ZAP add-ons for SOAP and OpenAPI/Swagger to import API definitions and help ZAP understand and explore your API.
Another option is to use use Tinfoil, a commercial application security scanner which automatically builds up a complete model of your REST APIs using Swagger or similar frameworks, and then does deep scanning and smart fuzzing of your APIs and authentication scheme to find security bugs and other runtime problems.
Challenges with Application Scanning
How much you get out of scanning depends on the following factors:
-
How good the tool is, and whether you have set it up correctly
-
How much of the application your automated acceptance tests cover, or how well the spider works (if you invoke it to crawl for other links)
-
What rules you choose
-
How much time that you have to run the tests
It can take a long time to crawl an application, trying to identify all the pages and parameters, and then more time to run attacks against the entry points that the scanner finds. It may not be practical or even possible to automatically spider and actively scan large web applications as part of your build pipeline. Automated tools can often lose their way, hang or time out, or even crash during long scans.
As we’ve already described, targeting scans against the key parts of the application that you’ve explored with automated functional testing is more efficient and probably more effective than brute-force spidering and scanning. But even these tests can take a long time to run.
There are some obvious steps that you can take to speed up scanning:
-
Scanning requires lots of CPU and memory. The more machine power you can throw behind the scanner and the system under test, the faster your scans will run.
-
Adjust the rule set. For example, by default, ZAP will run its full set of active scanning rules against every parameter, with medium strength. This may not always be necessary. For example, if your application does not use a SQL database, there’s no reason to run SQL injection attacks.
-
Break scans down and run them in parallel. Take advantage of rapid provisioning to stand up multiple instances of the application and run scans using different rules or targeting different functions.
-
Run incremental scans only against new or changed URLs, rather than scanning code that hasn’t been, or at least shouldn’t have been, changed.
Another problem that you need to solve is accuracy. Black-box application scanners, like static analysis scanners, will often report hundreds or thousands of false positive findings and other warnings that you will need to review and filter out.
Some scanners still have problems today with complex Javascript code or other dynamic content in the UI, and get lost or don’t find problems when they should.
You may need to try out a few different scanners before you find the tool and plug-ins that work best for your project. Spend time understanding the scanning tool and how it works, and make sure that it is set up correctly, before you try to wire it into your build pipeline.
Modern testing tools like ZAP are flexible and extensible through APIs, scripting languages, and plug-ins. Lots of people have taken advantage of this flexibility to implement automated scanning in different ways, which is reassuring, but also confusing. There is no “best practice” for scanning your apps. You’ll need to Google for ideas and examples and run some experiments to see what works best for you.
Get Your Pipeline Working First
Getting security scanning set up and working correctly in an automated pipeline isn’t easy. You need success with setting up your CI/CD server and build workflows, and experience automating functional testing, before you should consider introducing security scanning.
Another tricky problem that you’ll need to solve is getting the tool to automatically authenticate with your application, especially if you want to try and take advantage of spidering or if you want to test access controls. An unauthenticated scan will only hit the publicly exposed features or pages of your application, which are not usually the most interesting or valuable parts to you—or to attackers.
Most tools have different authentication modes to help with this. ZAP, for example, supports common authentication methods and a script-based method to support complex or custom authentication schemes and reauthentication steps. You can also manually walk through authentication steps in ZAP and save the resulting session information to your code repository to be reused in later automated scans.
Scanning Is Not the Same as Pen Testing
Understand that automated scanning like this is not the same as pen testing. Tools like ZAP run through a canned set of well-known attacks and look for well-known vulnerabilities and common mistakes.
This is just one of the first, and one of the easiest, things that a good pen tester will do.
But passing a set of automated scans should add to your level of confidence, and it will make pen testers—and attackers—work harder to find real problems in your system.
If you want to learn about pen testing, a good place to start is OWASP’s Testing Guide.
This guide explains how to set up and conduct a pen test. It provides checklists and techniques for reconnaissance, mapping the environment and the application, and fingerprinting the technology stack. It also offers tests for identity management, authentication functions, session management, authorization, different kinds of injection attacks, and how to find holes in business logic.
Testing Your Infrastructure
New tools such as Docker and Vagrant and Packer and Ansible make it fast and easy for developers to package up and provision their own development and test environments. Instead of waiting days or weeks for sys admins to build a system, developers can pull down community-built Chef cookbooks or Ansible playbooks or public Docker images, and spin up temporary instances in private or public clouds, with the complete runtime stack and all the tools that they need, ready to run, in minutes.
The advantages to an Agile development team of being able to self-provision development and test environments like this are obvious. They get control over how their environments are set up and when it gets done. They don’t have to wait days or weeks to hear back from ops. They can try out new tools or platforms easily and cheaply, run technical experiments and iterate quickly. And they can eliminate the “works on my machine” problem by making sure that development and testing are done using the same runtime configurations.
But this also introduces a new set of risks that need to be managed:
-
Like any other open source code, Docker images or other configuration recipes or templates, especially ones downloaded from community hubs, can contain mistakes, outdated packages, and other vulnerabilities, which developers can easily miss.
-
To save time—and because they may not understand the technical details or don’t care about them—developers will often take advantage of default configurations, which is almost never the safe thing to do.
-
When developers self-provision their infrastructure, ops and security are taken out of the loop on purpose, which means that changes happen without their oversight or understanding.
-
These insecure configurations can potentially become a target for attackers, and worse, can find their way into production.
The configuration specifications for these tools—Dockerfiles, Ansible playbooks, Chef recipes, and cloud templates—are code. Which means that infrastructure configuration can be automatically scanned and tested like any other code.
You can scan configuration code or images to look for common mistakes and vulnerabilities, and for compliance risks. There are a range of tools, for example, that you can use to statically scan Docker images and containers, including the following:
-
Docker Bench for Security scans Docker containers for compliance with the CIS Benchmark for Docker.
-
Docker Security Scanning is an add-on service from Docker to scan images in private repos for known vulnerabilities.
-
Clair is an open source vulnerability scanner for Docker images from CoreOS.
You can also write your own tests to do the following:
-
Help guide your design in test-driven infrastructure: defining the end state of configuration in tests before writing the configuration code, in the same way that developers working in test-driven development write tests before they write code.
-
Catch coding mistakes early: syntax checking and unit testing is important for configuration code with dynamic content, because many mistakes can’t otherwise be caught until runtime.
-
Catch regressions as engineers refactor (clean up and restructure) the code, update to new versions of tools, or move to new platforms.
-
Check the health of system configurations, ensure consistency between systems and environments, and catch snowflakes (one-off setups).
-
Act as documentation for the configuration.
-
Enforce policies and guidelines: operational policies, compliance policies, security policies, and hardening guidelines.
And just like the application testing pyramid, there are tools and approaches for different levels of testing infrastructure code.
Linting
Linting tools perform syntax checking, and checking for formatting and good coding practices. These tools help ensure that your code runs correctly, and are particularly important for dynamic scripting languages:
-
Puppet parser validate, Puppet-lint
-
Foodcritic, Rubocop for Chef
-
Ansible-lint
Code checking is of minimal value from a security perspective.
Acceptance Testing
Acceptance tests are the best place to add security and compliance checks. Spin up a clean test environment, execute the recipe or playbook code, and compare the actual results to expected results. Like application acceptance tests, these tests are more expensive to run, providing slower, but more complete feedback:
-
Bats—Bash Automated Testing System
-
Beaker for Puppet
-
Goss
-
Serverspec
-
InSpec—Tests which can explicitly trace back to compliance requirements
-
RSpec—Roll your own test framework instead of using Serverspec’s DSL
Let’s look at some popular tools that can be used to test different configuration languages or specifications on a range of platforms. This is especially useful in larger enterprises where teams may use many different configuration management approaches, because they can all standardize on the same testing framework; and it also makes it easier to transition from one configuration management stack to another.
Test Kitchen
Test Kitchen is a pluggable test management framework that you can use to set up and run tests for infrastructure code. From the “kitchen” name, it was obviously built to test Chef recipes, but it can be extended through plug-ins to test code for Puppet, Ansible, SaltStack, or other configuration management tools.
Test Kitchen allows you to write tests using different test frameworks, including Serverspec, RSpec, Bats, and Cucumber. It also allows you to run tests on Linux and Windows, supporting Vagrant, Docker, and most cloud platforms.
Serverspec
Serverspec is an extension of Ruby’s RSpec testing framework, with specific support for testing infrastructure state. Using Serverspec you can write high-level acceptance tests which validate that the state of the system configuration (e.g., files, users, packages, services, and ports) match expectations. These tests can be run before or after changes are made.
Because Serverspec checks the end state, it doesn’t matter what tool or tools you use to make configuration changes.
ServerSpec connects to each system using SSH, runs a set of passive checks on the configuration, and returns the results for comparison. This means that it can be safely run in test, as well as to audit production to help meet compliance requirements. Here is a simple example of Serverspec check:
describe package('httpd'), :if => os[:family] == 'redhat' do
it { should be_installed }
end
There is a Serverspec variant called AWSpec designed to execute similar tests on Amazon’s AWS.
We’ll look more at how to use tools like Serverspec to write security tests and runtime checks in Chapter 13, Operations and OpSec.
Creating an Automated Build and Test Pipeline
The velocity at which Agile and DevOps teams deliver keeps increasing. Scrum teams that used to work in one-month sprints now commonly deliver working code every week. DevOps teams following continuous deployment can make changes directly to production several times a day. At the extreme edge of this, at Amazon, thousands of developers working in small, “two pizza” teams continuously and automatically push out thousands of changes to their systems every day.
Working at this speed requires a different approach to designing systems and ways of building code and deploying changes that are optimized for rapid, incremental change. But all of this still builds on Agile and Lean ideas and fundamentals.
Let’s look at the steps involved in moving toward rapid or continuous deployment, and what this means from a testing and security perspective.
Nightly Build
In order to move faster, teams will find that they need to build the system on a frequent basis: the longer between merges and builds, the more risk of conflicts and misunderstandings.
Back in the 1990s, Microsoft popularized the practice of a “nightly build.” Developers were encouraged to check in changes each day, and each night a job would run to build the software so that the latest changes were available for everyone on the team to use the next morning. Over time, teams added tests after the build steps to catch common mistakes. Anyone who “broke the build” with a bad check-in would have to buy pizza or serve some other punishment, including babysitting the build until somebody else broke it.5
A lot of work can be required to get a system, especially a large legacy system, to build without mistakes. Being able to do this every day is a big step forward. A regular working build of the system provides a heartbeat for the team, increasing visibility into the state of development and confidence in the team’s ability to deliver. And it gives everyone on the team a chance to catch mistakes and incorrect assumptions early.
Continuous Integration
The next step to improving visibility and velocity is continuous integration.
Developers learn to check in small changes frequently, often several times a day, to ensure that everyone on the team can always see and work with everyone else’s changes. Each time that code is checked in, a continuous integration server (like Jenkins or Travis) is triggered and automatically builds the code and checks to make sure that the developer’s change hasn’t broken the build.
This is done by executing a suite of automated tests, mostly unit tests. These tests have to run quickly: the faster they run, the more often that developers will check in changes.
The following steps outline an example of a continuous integration workflow:
-
Code inspections done inline in the developer’s IDE
-
Manual code review before check-in or merge to mainline
-
Compile and check warnings
-
Build checks
-
Incremental static analysis checking executed by the CI server
-
Unit testing
-
Tag the build artifacts in an artifact repository such as Apache Archiva, Artifactory, or Sonatype Nexus
These steps should be enough to provide confidence that the changes are safe and the build is sound. Then we need to check that system is in a releasable state.
Continuous Delivery and Continuous Deployment
DevOps teams build on continuous integration practices and tools to implement continuous delivery, or continuous deployment, pipelines.
In continuous delivery, changes are pushed from development to testing and then finally to production in a sequence of automated steps, using a consistent set of tools and providing an end-to-end audit trail. At any point in time, the system is proven to be production ready.
Continuous deployment takes this all the way to production: developers check in a fix or a change, and if it passes the automated steps and checks in the pipeline, it is deployed immediately to production. This is how teams at Netflix, Amazon, and Etsy work.
Each change to code or configuration automatically kicks off continuous integration, building the code and running through the fast set of automated tests. If the build is good, the build artifacts are automatically packaged up and then deployed to a test environment for integration and acceptance testing.
If these tests pass, the code is promoted to staging to rehearse deployment in a production-like environment, and for system testing:
-
Execute through the preceding continuous integration steps.
-
Take the latest good build from the artifact repository, and package it.
-
Provision a test environment (using an automated tool like Chef or Puppet, Vagrant, Docker or CloudFormation).
-
Deploy to test (rehearse deployment steps).
-
Start the application (check for errors).
-
Run smoke tests and environment health checks.
-
Run acceptance tests.
-
Run integration tests.
If these steps all pass:
-
Provision a staging environment.
-
Deploy to staging (rehearse deployment and release steps in production-like environment).
-
Repeat steps to start the application, smoke tests, acceptance tests, and integration tests.
-
Load tests and operational tests.
This proves that the change is safe and that all the steps to deploy the change are working correctly.
Out-of-Band Testing and Reviews
Some tests and reviews have to be done outside of the continuous delivery pipeline because they take too long, or require manual handoffs, or both. The results of these tests and checks can be checked and fed back into the team’s backlog. Some tests and reviews must be done outside of the continuous delivery pipeline because they take too long, or require manual handoffs, or both. Any findings need to be fed back into the team’s backlog, creating another, larger feedback for the team. Out-of-band tests and reviews include:
Promoting to Production
Once the build, test, and deployment steps and checks pass, your latest changes are ready to be promoted to production. This step is done automatically in continuous deployment, or after manual approvals and other checks are completed if you are following continuous delivery.
Either way, you want to use the same artifacts, the same tools, and the same steps that you’ve used in the previous stages to deploy to production, because you have rehearsed them, debugged them, and proven that they work many times before you finally use them in production. This takes most of the pain and risk out of deployment.
Guidelines for Creating a Successful Automated Pipeline
Pipeline stages build on each other, moving progressively from simple tests and checks in simple environments to more real-world tests and checks done in more real-world environments.
You build and package a release candidate once early in the pipeline, store the build artifacts in a safe place, and promote this candidate through subsequent steps until you’ve overcome the objections to releasing it.
Even if you aren’t ready for continuous integration or continuous delivery yet, you should design your testing program so that tests can be run automatically. This means that tests need to be repeatable and deterministic: they need to provide the same results each time that they are run. And they need to provide unambiguous pass/fail results that can be checked at runtime.
To save time, stack the sequence of tests so that you run the the most important tests as early as possible: tests that check important functions and tests that break often. If you have tests that are flakey or that have intermittent timing issues or other problems, isolate them so that they don’t break the build.
As you add more tests and scanning steps, you’ll need to start breaking them out into parallel streams and fan them out, taking advantage of public or private clouds to create test farms and scanning grids, so that you can execute a few hours worth of tests and checks in minutes of elapsed time.
Where Security Testing Fits Into Your Pipeline
We’ve already looked at how security testing can be automated. Once automated, these tests can be wired into different stages of your CI/CD pipeline.
Checks and tests to conduct before continuous integration:
-
IDE static code inspections before code is checked in, using built-in code checkers or tool plug-ins
-
Pre-merge check-in scanning for secrets
-
Code reviews
Security tests and checks in continuous integration:
-
Build checks, including detecting new components and components with known vulnerabilities (something we already looked at in Chapter 6, Agile Vulnerability Management).
-
Unit testing, especially negative unit tests for key functions.
-
Incremental static analysis, linting, and custom code checks for banned functions and other dangerous practices.
-
Security smoke testing: fast, simple, security sanity checks, scripted using a tool like Gauntlt.
Security tests and checks in continuous delivery:
-
Targeted application scanning (using ZAP, Arachni, or another DAST tool).
-
Automated attacks with Gauntlt.
-
Automated acceptance tests for security features (authentication, access control, identity management, auditing, and crypto) using BDD-Security and/or Selenium WebDriver.
Before adding security testing into your pipeline, make sure that the pipeline is set up correctly and that the team is using it correctly and consistently.
-
All changes are checked into the code repository.
-
Team members check in frequently.
-
Automated tests run consistently and quickly.
-
When tests fail, the team stops and fix problems immediately before making more changes.
Tip
If the team isn’t already relying on the automated build pipeline when it pushes changes out, and if it doesn’t respond seriously to test failures in the pipeline, then adding security checks to the pipeline won’t accomplish much.
As you automate security scans and tests, start by running them in a separate stream of the pipeline so that test failures won’t cause the team’s build to fail right away. Review the test results to set failure thresholds, and tune the tools so that they don’t slow down the build too much and so that the team won’t waste time chasing down false positive findings. Once this is working, then you can make these security checks a blocking factor to the main pipeline.
A Place for Manual Testing in Agile
Although Agile and especially DevOps emphasize automated testing because of the need for fast feedback and rapid cycling, there is still an important place for manual testing—and manual testers—in Agile development, especially when it comes to security.
Manual regression testing doesn’t scale in high-velocity Agile environments and is a waste of people’s time. In Agile development, waste is something that must be eliminated. But there are other cases where manual testing adds value. For example, usability testing needs to be done by real people: testers, or developers dog-fooding, or beta users in production.
Another kind of manual testing that can provide a lot of value is exploratory testing.
Exploratory testing is about learning how the application works and finding where its breaking points are. Exploratory testers try to push the system to its limits, to find bugs before users—or attackers—do.
It’s not scripted, or perhaps only loosely scripted. Exploratory testers might start with walking through the acceptance criteria for a story, but then they will take off along paths that they think are interesting or important.
They may try to do steps out of order, push buttons that they maybe shouldn’t push, fiddle with links and data, go backward and forward again to see what happens. Exploratory testers play and improvise as they test, and as they build up their understanding of how the system works. And all along the way they record what they did, what they found, and what went wrong so that they can report defects.
How to Break Software
To understand more about exploratory testing, it’s worth reading James Bach’s seminal essay, “Exploratory Testing Explained”.
James Whittaker’s books How to Break Software (Pearson), How to Break Web Software (Addison-Wesley Professional), and How to Break Software Security (Addison Wesley) will teach you how to take an adversarial approach to testing your applications.
While some of the specific tools may be out of date, the approach and attack models that Whittaker describes are still relevant. URL jumping attacks in web apps, for example, are a simple way to test out controls in key workflows. Jump into, around, or over steps by browsing directly to a page. Try moving backward, skip over approval steps. If the application doesn’t catch you, you’ve found an important bug that attackers or fraudsters can exploit.
Penetration testing is an extreme and specialized form of exploratory testing, where the tester takes on the role of an attacker. Pen testers use intercepting proxies and scanners and other tools to identify vulnerabilities, and then try to exploit them. This requires specific technical skills and experience to do effectively.
While most teams won’t have good penetration testing skills in-house, they can still get a lot from adversarial exploratory testing. It can be done in an informal, lightweight way, with developers paired up with testers or with each other to explain the feature and to look into problems as they come up.
Exploratory testing should be done on security features like login and forgot password, and important business workflows like online shopping and online banking or payments handling.
And as we saw in the ZAP tutorial, manual exploratory testing is a useful and necessary first step in test automation, in order to understand the application and tools, and to identify important scenarios to be automated.
Adversarial exploratory testing, asking testers and developers to think out of the box, or trying to hack into your own systems, provides information that you can’t get from structured, repetitive, automated testing. You can find serious usability and reliability and security bugs by testing this way. But what’s more important is that it can tell you where you have weaknesses in the system and in your processes. When you find serious security and reliability bugs through exploratory testing, you need to look closer at the code and the design, and at the rest of your reviews and testing work to understand what else you could be missing, and what else might need to be fixed.
This kind of testing is expensive and can’t scale. It takes time to do right, and it is highly dependent on the individual skills, experience, and instincts of the testers. Take advantage of it as much as you can, but recognize that you can’t depend on manual testing to keep your system safe and secure.
How Do You Make Security Testing Work in Agile and DevOps?
To make security testing work, you need to recognize the limitations and constraints that Agile development and continuous delivery force on you.
There’s not enough time to do exhaustive gate-based testing and audits. You need to break testing down into small steps that can be automated so that they can be run every time a change is made. Focus on tests that will catch common and important mistakes early.
Test automation is hard to do right. You need to understand the domain and the design of the system and the runtime platform, and how to build and configure them correctly in order to stand up the system for security testing. You need to understand testing tools and continuous integration, and how to code and script tests, work out how to respond to test failures when they happen, and how to rule out false positives.
All of this has to be done at high velocity to keep up with the team members and with the changes that they are continuously making.
You need a strong combination of technical and testing and security skills to do this, which requires bringing the security team, developers, and testers together in the following ways:
-
The security team can help developers write acceptance criteria and test scenarios for security stories.
-
Security can review unit tests for high-risk code and automated tests for infrastructure playbooks.
-
Try a test-driven security approach: have security engineers write tests for the team before they write the code, and make these tests part of the team’s acceptance goals.
-
Security can help the team to implement black-box application scanning and infrastructure scanning in the build pipeline.
-
Security can participate in exploratory testing, especially on security features, and show the team how to turn an exploratory testing session into a security test, by introducing an attack proxy like ZAP into the test.
Look for ways to simplify and share tests. Take advantage of templates provided by tools like Gauntlt and BDD-Security to create standard tests that can be shared across teams and across systems.
Look for ways to get developers involved in writing security tests and owning the outcome. Make security testing self-service, something simple that developers can spin up and run on their own. Nothing flakey, no warnings that need an expert to decide whether there is a real problem or not.
Review and improve as you go. Fill in gaps in your testing as you need to: when you find vulnerabilities; when the team makes a change in direction, arrives at a new design, or upgrades the technology; or when the threat landscape changes.
Key Takeaways
In Agile teams, developers are effectively responsible for testing their own work, and rely heavily on test automation and continuous integration to catch problems quickly:
-
Most developer testing is done along “happy path” success scenarios to demonstrate that features work. However, adversaries step off of this path to find edge cases and weaknesses in design and coding that can be exploited.
Developers need to understand the importance of negative testing, especially for security libraries and other high-risk code.
-
Black-box dynamic scanning using tools like OWASP ZAP can be wired into continuous delivery pipelines to catch common security vulnerabilities in web applications and mobile apps. But this is not easy.
-
Start small. Run some experiments. Learn how your tools work inside out before you push them onto a development team.
-
Test-driven development (writing automated tests before writing the code) can be followed by security teams to start injecting security into testing for the application and for infrastructure.
-
Automated security test frameworks like Gauntlt and BDD-Security provide test templates that can be used to build security smoke tests, and shared across multiple teams and systems.
-
Test your infrastructure as well as your application. Tools like Serverspec and InSpec can be used to check that infrastructure is set up properly and safely.
-
Automated tests, including scanning, have to be implemented so that the tests run quickly and provide clear pass/fail feedback to developers.
-
Manual acceptance testing won’t scale in Agile environments. But manual exploratory testing and pen testing can find important problems that automated tests may miss, and provide valuable information to the team members about weaknesses and risks in the system and in their processes.
Security testing needs to be part of the team’s Definition of Done: the contract that the team has with one another and with the organization to deliver working software in each release. The team needs to understand its compliance and security obligations, and agree on what testing needs to be done to meet these obligations. What kinds of security tests and scans need to be run, and how often? What kind of findings will break the build? What level of automated test coverage is needed for security libraries and other high-risk code?
1 Carol Woody, Ph.D.; Robert Ellison, Ph.D.; and William Nichols, Ph.D.; “Predicting Software Assurance Using Quality and Reliability Measures” Software Engineering Institute, Technical Note, December 2014.
2 Vinnie Murdico, “Bugs per lines of code”, Tester’s World, April 8, 2007.
3 Laurie Williams, Gunnar Kudrjavets, and Nachiappan Nagappan, “On the Effectiveness of Unit Test Automation at Microsoft”, 2009 20th International Symposium on Software Reliability Engineering (2009): 81-89.
4 For more on how to use BDD-Security and ZAP together, watch Michael Brunton-Spall’s presentation, “Building securely with agile”.
5 Joel Spolsky, “The Joel Test: 12 Steps to Better Code”, Joel on Software, August 9, 2000.