
Chapter 2. Modeling APIs
When building applications, start by first modeling your APIs. Then write the application(s) to back those APIs. Modeling APIs involves selecting the representation format (typically JSON or XML), defining the various resources (objects like /Product, /StoreLocator, etc.), modeling each resource’s attributes (e.g., key/value pairs like productId="12345"), and finally modeling relationships to other resources (e.g., <link rel = "customer" uri = "/Customer/c12345" />) It’s similar to defining an entity relationship diagram (ERD) for your database before writing a monolithic application.
When you model APIs first, you’ll find that it’s easier to write the application. Often, individual resources (e.g., /Product) map back neatly to individual microservices. If you start by writing your application and then retroactively expose functionality and data through APIs, you’ll end up with APIs that mirror your application’s idiosyncrasies rather than a well-thought-out API that is easy for developers to consume.
Note
How granular should your APIs be? Check out Eric Evans’ iconic 2003 book, Domain-Driven Design: Tackling Complexity in the Heart of Software (Addison-Wesley Professional). In it, he makes the case for a pattern called Bounded Contexts whereby APIs and the underlying applications should be modeled as closely as possible to mirror the data and behavior of your business domain. For example, Eric would call for separate product and pricing APIs, as the two are distinct business domains, even though the two have a direct relationship to each other and could be modeled as one API.
A perpetual issue in software development is parallelizing development. If you get all of the stakeholders in a room and have them centrally plan the APIs, you can then parcel out the development of the APIs to internal teams and systems integrators. A clearly documented API is easier for a team to implement when compared to an application whose API is unknown.
Your end goal should be to have an enterprise-wide catalog of APIs that anyone can consume, inside or outside your organization (Figure 2-1). A single API could be used by dozens, hundreds, or even thousands of different clients. Your API is your product.
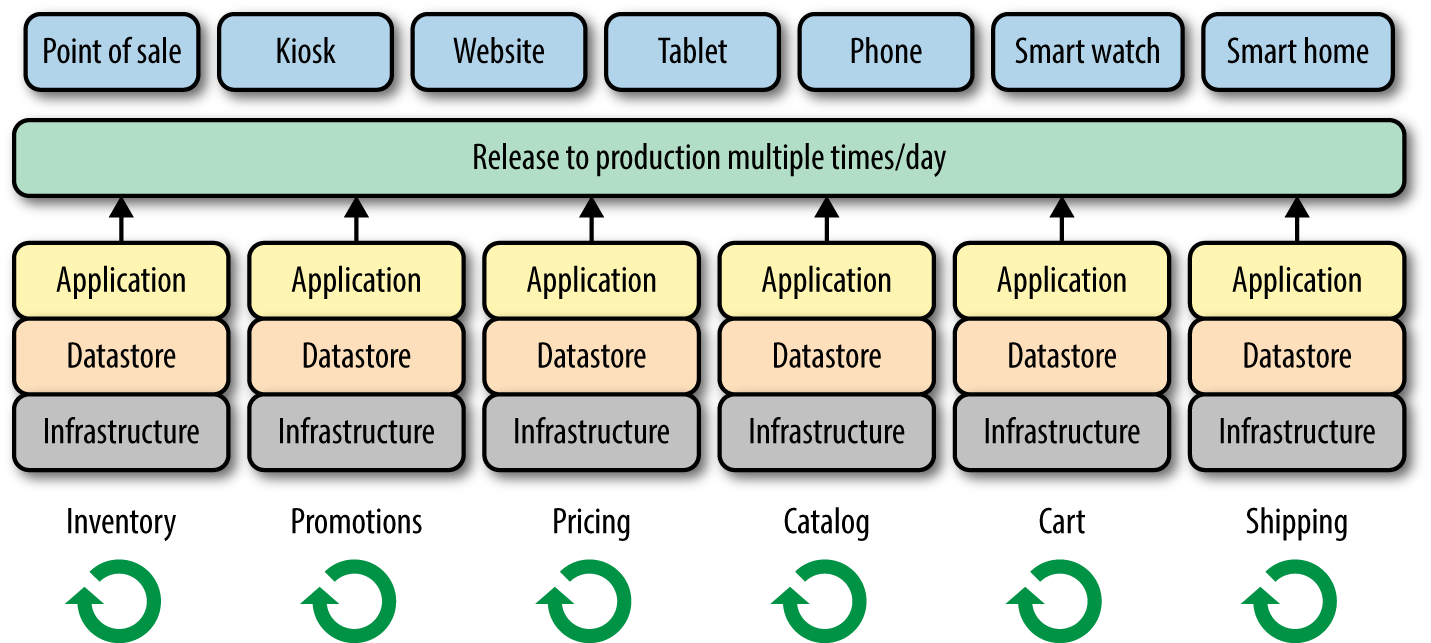
Figure 2-1. A vision of the future: a catalog of independently developed and consumed APIs
This catalog of APIs can then be handed to a systems integrator or creative agency to build a new experience for the latest consumer electronic device, for example.
Now that we’ve discussed why it’s important to model your APIs first, let’s step back a little and discuss REST.
The Case for REST
REST is assumed to be the default style because of its universality, flexibility, large supporting ecosystem of technology, and friendliness to both producers and consumers of APIs.
Why? Fundamentally, REST APIs are analogous to the web itself. REST was defined by Roy Fielding (one of the principal authors of the HTTP specification) in his 2000 PhD dissertation, “Architectural Styles and the Design of Network-Based Software Architectures,” at UC Irvine. In it, he stated:
Representational State Transfer (REST) is intended to evoke an image of how a well-designed Web application behaves: a network of web pages (a virtual state-machine), where the user progresses through an application by selecting links (state transitions), resulting in the next page (representing the next state of the application) being transferred to the user and rendered for their use.
What Roy describes could easily be equated to the World Wide Web Tim Berners-Lee conceived of in the early 1990s.
Let’s clarify some terms before we go any further:
- Resource
-
Is an entity that can be interacted with using HTTP verbs, like
GET,POST,DELETE, etc. It can be singular (/Product/{id}) or plural (/Products). Roy describes it in his dissertation as “the intended conceptual target of a hypertext reference.” - Resource identifier
-
A URL used to access the resource. https://api.<yourcompany>.com/Product or
/Productwould be the resource identifiers. - Representation
-
The format of the data returned when an API is called. Often, it’s XML or JSON.
- Resource operation
-
Maps back to HTTP verbs, like
GET,POST,DELETE, etc. - Client
-
Refers to whoever is calling the API, whether it’s another enterprise application or a mobile application belonging to the end consumer.
The web has proven to be an extremely successful model for APIs to follow. It’s only natural for APIs to adopt the principles from the web that work and to build on top of its infrastructure (HTTP, TCP, XML/JSON, etc.). The use of HTTP specifically is crucial because our digital world is built on top of it. Content delivery networks, web application firewalls, API gateways, and authorization and authentication frameworks all rely on the HTTP infrastructure. There’s a prescribed set of verbs (GET, DELETE, etc.) for dealing with resources. As a principal author of the HTTP specification, REST was a natural next step for Roy.
Note
Which format is preferred—JSON or XML?
JSON is more compact but also more difficult to read, especially when data is complex and hierarchical. XML is best for structured data, but it’s more verbose than JSON. All modern tooling will work with JSON and XML. The XML ecosystem tends to be richer but is suffering from a lack of investment as JSON becomes dominant.
Either will work just fine. Don’t get pulled into endless debates. Use whichever you feel comfortable with and what works best for your organization. What matters is that you pick a format and use it consistently across your organization.
Serialization Frameworks
While REST is the default, its primary drawback is performance. The HTTP stack is well known for not being efficient. The documents must be parsed in their entirety and sometimes validated before data they contain can be accessed. Field names are stored in the documents. There are many “filler” characters, such as tabs, spaces, and special characters such as < and }. In short, REST is universally understood by humans and easy to work with, but the performance is sometimes lacking.
There are situations where high performance is an absolute requirement, including:
-
Special use cases, like high-frequency trading
-
Retrieval of a large amounts of data, like retrieving all orders placed in the past week
-
Architecture that forces synchronous calls between microservices
It’s important to note that you should rarely if ever make synchronous HTTP calls between microservices, especially if the client is waiting on the response. However, there are situations when synchronous calls are necessary. For example, your shopping cart may need to make a real-time call to validate inventory for a given product before checkout is initiated. In that case, your shopping cart now needs to call your inventory synchronously.
For the absolute best performance, you can use binary-level serialization frameworks. Examples include Apache Thrift, Apache Avro, and Google Protocol Buffers. These bypass the entire HTTP stack (including TCP), don’t rely on text and therefore parsing, don’t store field names, don’t have extemporaneous characters, and don’t need intermediary SDKs. These stacks are built for speed and they deliver on that promise. For example, Protocol Buffers from Google are 3 to 10 times smaller and 20 to 100 times faster than XML. Most of the time, the performance bottleneck is with the application you’re calling as opposed to the overhead that REST introduces.
If you’re a provider of APIs, you’ll generally want to expose REST APIs publicly. These binary-level serialization frameworks offer very little support for security, readability, or a larger ecosystem, though these areas are improving over time. Binary is meant to be used when speed is your primary requirement.
Note
Google has estimated that 74% of all publicly accessible APIs are REST. Given its popularity, consider rest as the default when APIs are discussed henceforth.
API Modeling Best Practices
When modeling an API, look at who your consumers are. Are they internal or external? How technical are they? Who are your clients, and where are they making API calls from? These are all important considerations which we will cover next and in future chapters.
Here are some best practices that should be followed regardless of who your consumers and clients are.
Documented Using a Specification
All APIs require documentation. Documentation includes:
-
Resources
-
Attributes
-
Relationships between resources
-
Representation formats
-
Supported verbs
-
Error response codes
APIs also require an application that does what the API promises. They can optionally offer an SDK or some other form of client-side code to make it easier for clients to call the API. The problem for those building APIs is that the API documentation, server-side implementation and client-side SDKs must match at all times. If a “currency” attribute is added to your pricing resource, it must be available in the documentation, the server-side implementation, and any client-side SDKs.
There are a number of standards available that allow you to model your APIs using a high-level markup language like YAML. OpenAPI (formerly known as Swagger) and RAML have emerged as the two most commonly used standards for documenting REST APIs (Figure 2-2).
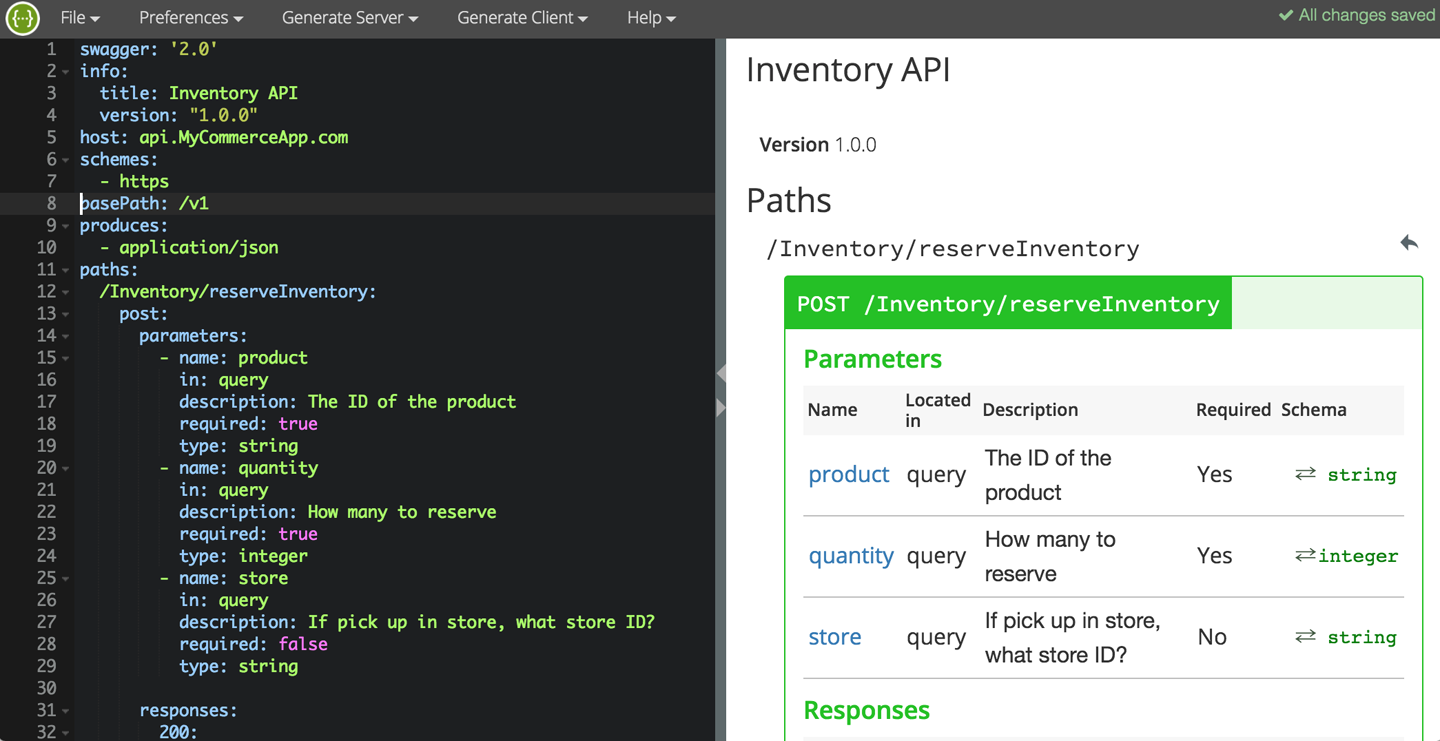
Figure 2-2. Inventory API modeled using OpenAPI
Once APIs are modeled using the specification, you can then automatically generate client and server stubs in the language of your choice (Figure 2-3).
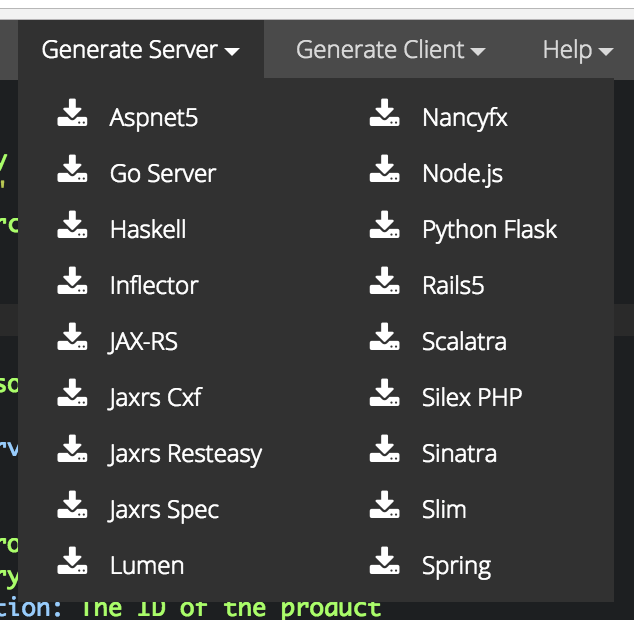
Figure 2-3. Client and server auto-generation
Being able to auto-generate documentation, server stubs, and client stubs dramatically simplifies the development of APIs because all three pieces are generated simultaneously from the same high-level markup language. These definitions should be checked in and treated as source code.
Though the technology and architecture backing each API can change, you should pick a specification and use it across your company. What matters most is that you use it consistently.
Independently Callable
APIs should be independently callable, meaning you shouldn’t have to call one API before you call another. For example, many 2000s-era commerce APIs required that clients authenticate and authorize a customer (often as two separate calls) before an action was performed against that user’s account, like adding an item to their shopping cart. While it does make sense that the client authenticate and authorize the user, requiring one or two API calls as a pre-condition doesn’t make a lot of sense. It requires putting too much intelligence into the client. Imagine having to maintain that business logic across 10 different clients managed by 10 different development teams.
These hard dependencies between APIs are often introduced due to idiosyncrasies in the monolithic application because APIs were bolted on after the application was built. That’s why it’s best to start by modeling your APIs first, and then writing individual microservices to back each API.
Stateless
The applications backing each API should be stateless, meaning that no single client request is dependent on the server-side state of a previous request. This allows a call to the API to be served by any instance of the application. You could implement a round-robin load balancing strategy, for example.
As an example of why it’s best to be stateless, consider that many top celebrities have more than 100 million followers on social media platforms. Individuals with large followings regularly pitch products to their followers (see Figure 2-4).

Figure 2-4. Celebrity-driven product endorsements
If someone with 100 million followers posts a link to your product detail page, your auto-scaling should kick in and create a few thousand instances of the applications that back your product, inventory, pricing, and other microservices used to render that page. If you have stateful sessions, you’ll have to slowly wait for your application instances to be free of sessions, which could take many hours. If your instances are stateless, your auto-scaling mechanism can simply kill off the unnecessary instances following the rush.
Easy to Call
APIs should be written so that they are easily callable by any client. This primarily means modeling the APIs at the outset, offering SDKs in a variety of languages, and making the APIs as performant as possible. Let’s look at all three.
First, as we’ve discussed, ensure that the APIs are modeled first, before any code is written. Then write your application to back the API you’ve modeled, preferably with a 1:1 relationship between the API and a backing application/microservice. This will help to ensure that your APIs are intuitively modeled and free of the idiosyncrasies of the implementation of your application. As we’ve also discussed, it’s best to use a formal specification like OpenAPI or RAML (Figure 2-5). This ensures that your clients can leverage the specification’s large ecosystem of tooling.
Figure 2-5. RAML ecosystem
But you can only leverage all that tooling if your API conforms to a specification.
Next, offer SDKs to make it easier for clients to access your APIs. While REST is a necessary common denominator, it’s not very easy or performant to work with large JSON or XML documents.
For example, here’s how you’d retrieve the products from the product service using raw JSON:
URLurl=newURL("https://api.yourcompany.com/Product");try(InputStreamis=url.openStream();JsonReaderrdr=Json.createReader(is)){JsonObjectobj=rdr.readObject();JsonArrayresults=obj.getJsonArray("products");for(JsonObjectresult:results.getValuesAs(JsonObject.class)){System.out.println("Product Name="+result.getJsonObject("product").getString("name"));....}}
There are a few issues with this:
-
There’s no type safety. If your developer accidentally typed “prodducts” instead of “products,” the compiler wouldn’t flag the error.
-
Developers aren’t able to use auto-complete features in modern IDEs.
-
You have to manually handle authentication and authorization if that’s required. That code can get complicated.
Rather than interacting with XML or JSON directly, you can use the tooling of the specification you chose to generate a client. It takes two mouse clicks from the API modeling UI to generate a standalone library (product-service-java-client-1.0.0.jar in this example; see Figure 2-6).
Figure 2-6. SDK generation using OpenAPI tooling
Simply import the library and interact with resources in your native language, rather than text-based documents:
for(Productproduct:newDefaultApi().productGetAll()){System.out.println("Product Name="+product.getName());}
Developers love native libraries because they simplify development through the use of auto-complete in IDEs (see Figure 2-7).
Figure 2-7. Auto-complete in IDE through the use of an SDK
Beyond auto-generating clients from a specification, an SDK can abstract away all the security for developers.
Consider offering client-side libraries for a variety of popular languages. As a provider, you should furnish all the client-side tooling that you can in order to entice developers to consume your APIs.
Finally, don’t forget about performance. The worst thing you can do is provide an API with response times in the hundreds of milliseconds. It puts a big burden on client-side developers who then have to code around the poor performance.
Cacheable
To improve performance, it’s important to aggressively cache API calls. The vast majority of calls from your frontend translate to HTTP GET requests, whether you use REST directly or indirectly through a native SDK. An HTTP GET call is easily cacheable by any intermediate layer between your frontend and your backend.
To cache properly, you’ll need to represent resources by proper URIs. An HTTP request for /Cart/{id} is very easily cacheable but an HTTP GET to /Cart/current or some other ambiguous URI is not. Similarly, it’s also more difficult to cache when resources aren’t defined independently. If you’re HTTP POSTing to a /ProductCatalog URI to retrieve products, you’ll have a harder time than if you’re referencing individual resources by URI, like /ProductCatalog/Product/12345.
As individual resources, you have more control over caching policy. You could easily define a "max-age=180" HTTP request header for products and "max-age=5" for inventory, for example.
You’ll also be able to cache more if you make full use of HTTP verbs, like GET, POST, DELETE, etc. Many developers take shortcuts and route all API calls over HTTP POST. When this is done, HTTP is used more as a tunneling mechanism, which reduces cacheability. It’s far easier to cache GETs because you know they’re read-only and therefore cacheable. A POST is hard to cache because you don’t know if it’s creating, reading, updating, or deleting data, or executing some functionality remotely.
Once you have a well-defined API, it’s easy to cache through the use of standard HTTP-level caching techniques. Google and many others have great guides showing how to configure HTTP caching.
As for where to cache, you have a lot of freedom based on your environment. You could cache at the edge (often part of your content delivery network), an API load balancer and/or API gateway, a standalone caching proxy, a web server, a reverse proxy, or any one of the intermediaries between the client and the originating application backing the API. The leading content delivery networks even auto-cache by default, as seen in Figure 2-8, an example of Amazon Web Service’s CloudFront.
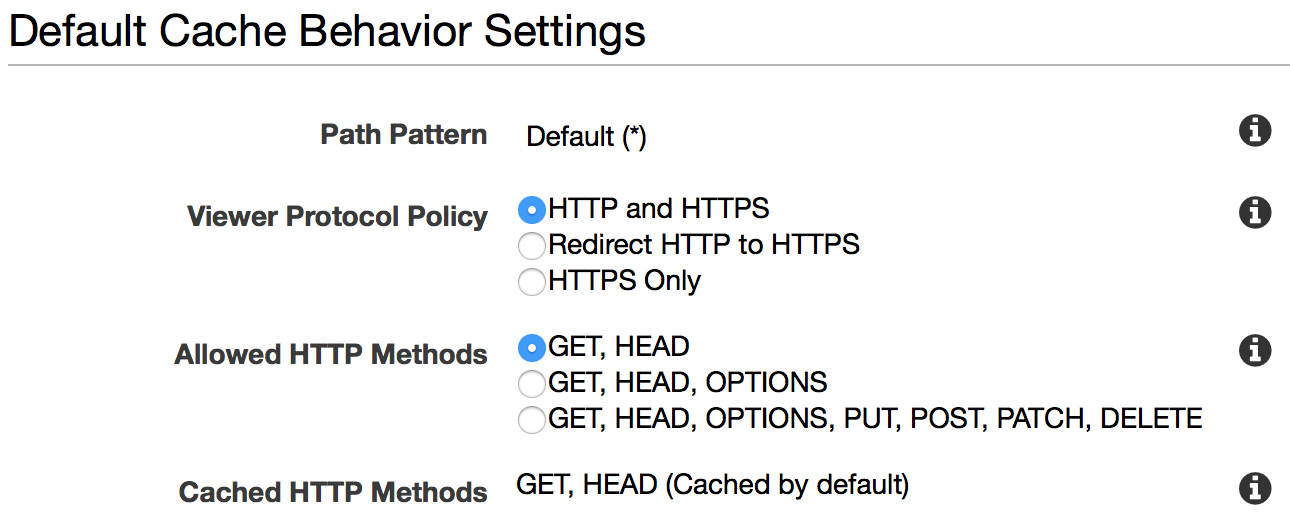
Figure 2-8. Auto-caching HTTP requests at the edge
The ability to have intelligent intermediary layers is one of the key advantages of using HTTP for your API calls rather than the binary-level protocols, which are almost entirely point to point.
Intuitive
The World Wide Web (linking through HTML) is the layer that made the internet a fixture in business and at home. That model succeeded because it made it easy for normal people to find information. A web page displaying a company’s stock price also includes a link to view that company’s balance sheet, for example. The value is in the connections.
Good API designers adopt many of the same principles as the web, often under the umbrella term Hypermedia as the Engine of Application State (HATEOAS). While arguably not the nicest sounding acronym, the principle is solid. HATEOAS means each response includes links to other related resources. Here’s an example of an order object showing the caller how to delete the order:
<orderid="{id}">...<linkrel ="delete"uri ="/Order/{id}/delete"/></order>
HATEOAS is like the web today with browsers, but applied to APIs instead. The value of this approach is as follows:
-
It allows developers to much more easily consume functionality and data.
-
Developers can code to the link named “delete,” allowing the API paths to change.
-
It eliminates hardcoded API paths and other business logic.
-
It helps developers model APIs.
You can take HATEOAS further and also use it to control application state. For example, a cart could prevent the submission of an order by not having a confirm rel present when billing and payment details haven’t been provided yet in the application state.
Try for HATEOAS as much as possible.
Idempotent
Idempotency means that an action (such as add to cart, increment inventory, or create product) can be performed multiple times without causing problems. For any number of reasons, an API may be invoked multiple times. Invoking an API multiple times should result in the same output every time.
For example, an API expecting the following input is not idempotent:
HTTP POST /Cart/{id}
{"add":{"skuId":"12345","quantity":1}}
Every time this is invoked, one SKU will be added to the cart. If the API is accidentally executed 10 times, the customer will end up with 10 of SKU 12345 in their shopping cart.
The following input, on the other hand, would be idempotent:
{"add":{"skuId":"12345","totalQuantity":"1"}}
This could be executed 1,000 times and the result would still be the same: the customer would have only one SKU 12345 in their shopping cart.
It is best practice to assume that the plumbing between your client and your server is unreliable. APIs may be invoked multiple times when only one invocation was anticipated.
Final Thoughts
It should be clear why APIs should first be modeled before writing a single line of code. Don’t get too dogmatic about which specification you use. What matters is that you use one and stick to it.
Next, let’s explore the code-level implementation of the APIs.