
Chapter 5. Framework of an “Intelligent Machine”
While it’s helpful to think of AI in terms of doing things differently within your existing business processes, it’s also true that AI can help you explore and benefit from entirely new approaches and redefined processes. Gaining efficiency is of course a big, obvious win, but today’s new breed of intelligent algorithms enable us to engage customers and prospects in new ways, create entirely new experiences, and even develop new business opportunities we have never considered before—if you can successfully get your company behind your AI-powered vision of the future.
When we were getting started with AI in the realm of marketing automation, we found it helpful to think in terms of a framework for building an “intelligent machine.” The basic elements of this framework include:
-
An understanding of your customer journey, experience, and life cycle.
-
Creatives or content designed to impact the customer journey at different stages in their life cycle—the more variety, the better. Be sure to map multiple creatives, offers, etc. to different stages of the life cycle for optimal results.
-
Data for understanding the customer journey and breaking behavioral cohorts into targeting segments.
-
API-based access to your preferred marketing channels—Facebook, Instagram, Google, Snapchat, your email service provider, etc. to allow for campaign creation and orchestration.
-
A working feedback loop for reporting and ongoing optimization, likely running through a third-party attribution provider or coming directly from the platforms themselves.
-
An approach to optimization, which can be turned into one or more algorithms used to drive performance based on the feedback your system is getting.
This framework could be universally applied to any company considering building their own AI-powered intelligent machine to fully automate their customer acquisition efforts. It can also be used to help evaluate vendors to ensure they offer a comprehensive approach to autonomous marketing. Now, let’s get a bit smarter about the types of artificial intelligence you can explore and apply to your specific business case or needs.
It also helps to remember that—for the most part—all of these functions are simply core marketing activities that are enabled in today’s digitized world. This is about doing these things better, faster, smarter, and sometimes in entirely new ways.
Amazon founder and CEO Jeff Bezos often gets asked to predict what the future will be like in 10 years. While he’s happy to indulge audiences with his thoughts and readily admits he really can’t predict the future, Bezos often thinks about the things that won’t change in the next 10 years, and how that can impact business decisions. That way, “you can work on those things with the confidence to know that all the energy you put into them today is still going to be paying you dividends 10 years from now,” he said.
That’s good news when it comes to applying AI and machine learning to marketing. These business activities, functions, and business processes aren’t going away any time soon, but the days are numbered for the old ways of dealing with this familiar workload. Think about it this way: the work you do today to make your intelligent machine a reality will still be paying off dividends in 10 years.
Breaking Down Machine Learning for Marketing Purposes
While the study of machine learning and artificial intelligence is quite broad, there are a handful of approaches to developing effective “learning” algorithms and approaches. Consider this a primer to get you started with a good understanding of current approaches and how they apply to your AI-based marketing efforts:
- Supervised learning algorithms
-
These use properly labeled data sets to train an algorithm to make predictions. They’re great for classification, or labeling new data through a mapping function from input variables to discrete output variables. A classic use of supervised learning algorithms you can likely relate to is the classifying of emails as “spam” or “not spam” based on input variables leading to a discrete output variable (“spam” or “not spam”). A second major use of supervised learning is for regression analysis, in which the training data is used to map input variables to a continuous output variable—a real number or value, often quantities like amounts or sizes, within certain error boundaries to indicate the accuracy of the prediction.
- Unsupervised learning algorithms
-
This category takes unlabeled sets of data with no known outcomes or results and is useful for discovering the underlying structure of the data. They are typically used for clustering data within sets, detecting anomalies (like fraudulent transactions), mining for associations (understanding what types of goods are on a typical retail receipt to better merchandise products on retail shelves), reducing the number of features in a given data set, or breaking out a data set into multiple, smaller sets for further analysis.
- Semi-supervised learning algorithms
-
These use a combination of labeled and unlabeled data for training. Generally speaking, they rely on smaller labeled data sets that include outcome information used in conjunction with much larger unlabeled data sets. They’re used when you don’t have enough labeled data to produce an accurate model. With this approach, you can increase the size of your training data by applying this technique.
- Reinforcement learning
-
This one of the newest approaches to machine learning. As the name indicates, a reinforcement algorithm learns by trial and error to achieve its objective. The machine tries out lots of different things and gets rewarded or penalized based on the outcomes of its behaviors and how well they help or hinder it from reaching its objective. Google’s AlphaGo used reinforcement learning algorithms to beat the best players in the world in the complex strategy game Go.
- Deep learning
-
Architectures represent another, perhaps even more revolutionary, approach to AI-based application development—a field of data science that has also accelerated in recent years. They’re based on artificial neural networks (ANNs) and support a variety of learning approaches, including supervised, unsupervised, and semi-supervised. “Deep” refers to the number of layers through which data is transformed; in certain models, the number of transformations is fixed, and in others, known as recurrent neural networks, the number of transformations is potentially infinite. These architectures are among the most exciting in data science today and have been applied successfully to drug design, bioinformatics, social network filtering, speech recognition, computer vision, natural language processing, machine translation, audio recognition, material inspection, medical image analysis, and board game programs. In many cases, they’ve produced results comparable to or even superior to human subject-matter experts.
As you can see in Figure 5-1, many of the different approaches to machine learning described here can be applied to different applications related to marketing automation. Each application represents an order of magnitude leap from the conventional, manual approaches of days gone by thanks to the availability and sheer volume of data that we can now feed into these algorithms.
The “x” factor is deep learning, which cuts across the four major approaches to machine learning. This approach can be incorporated where the benefits of this more computationally intensive method outweigh the more lightweight methods of classical machine learning approaches.
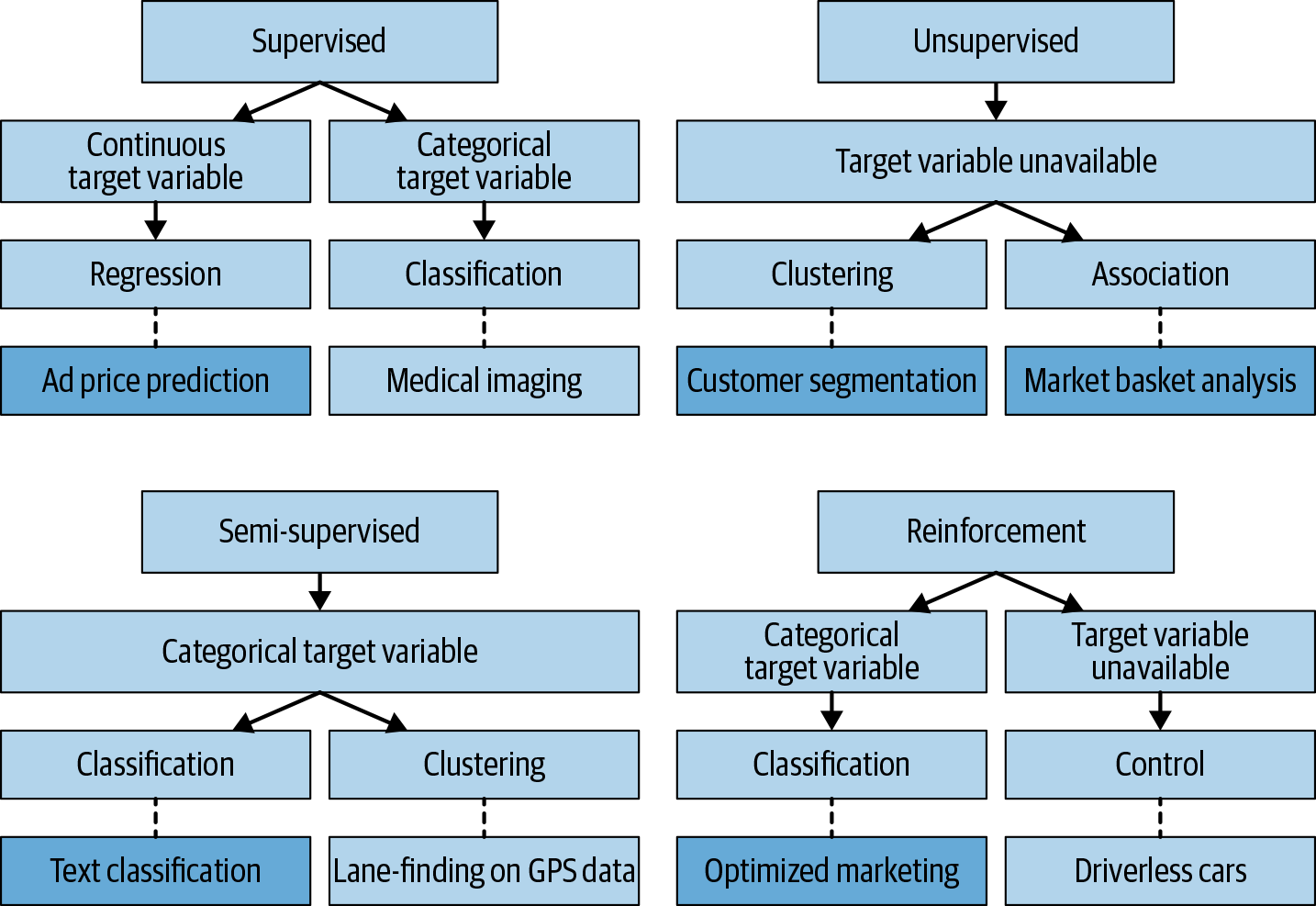
Figure 5-1. The different types of machine learning
Major Types of Supervised Learning Algorithms
As you can see in our handy chart, supervised learning algorithms can be useful in a marketing context for predicting things like ad prices in an auction, along with associated predicted yield. There are several approaches to these types of supervised learning algorithms and plenty more available online if you want to dive deeper into the math. The following sections present a primer on the four major types.
Linear Regression
Regression analysis shows the relationship between inputs and outputs in a given system. Linear regression is one of the most common types of regression analysis; in its simplest form, it uses a linear relationship to predict the value of Y for a given value of X using a straight (regression) line. It can allow us to see what factors in our marketing efforts relate to others. Exploring these relationships can help us with testing the actual cause or “causality” of certain outcomes—like what factors indicate or predict a higher probability of a click or a conversion.
One important note: linear regression requires some careful tuning to get reliable outcomes, so be careful when applying it to your modeling. You’ll need to find a fairly strong correlation between the X and the Y to have confidence going forward with this approach. Perhaps the data fails to form a natural line; there is no need in trying to use a line to fit the data and make predictions.
Logistic Regression
Logistic regression is used primarily for classification, labeling, or sorting data sets. Although similar to regular linear regression, logistic regression is aimed at gaining insight into understanding the relationship between the dependent variable with one or more independent variables provided the dependent variable is binary, or “dichotomous.”
Apart from the similarities stated before, logistic regression differs from a linear regression through the non-usage of regular least squares to plot the line of best fit, which is used in predicting the value of the dependent variable based on the information derived from the independent variable. In logistic regression, the value of y is usually set at 0 or 1 rather than being distributed along the line of best fit as seen in linear regression.
Logistic regression is an important market research tool that can be used to predict the response of a customer to a product based on certain factors. For instance, it can be used to predict if a customer will purchase a product if, say, we know their health status.
It’s important to note that logistic regression may require a certain number of participants for each set of dependent variables before the results can be processed. Most people who have used logistic regression feel that interpreting logistic regressions can be time consuming and somewhat confusing. It is therefore highly recommended that you make use of important statistic analysis tools like Intellectus, which allows you to conduct analysis and interprets the results in plain English.
k-Nearest Neighbor
Often regarded as a non-parametric technique, k-nearest neighbor (k-NN) can be described as a simple algorithm that can store all available cases and also predict the numerical target based on a similar measure (e.g., distance). This predictive, non-parametric technique is capable of predicting the future outcome of a test based on reports on how people might have reacted to the same parameters in the past. For instance, you can easily determine which product a customer is likely to go for by considering what their nearest neighbors bought.
This method is often used by growth teams to determine the most effective customer acquisition strategy and how customers are likely to respond when approached with a new product by simply considering what their nearest neighbors are likely to purchase. It creates a chance to compare the reaction of old and new customers.
Support Vector Machines
Most growth marketing processes or challenges tend to require making the right predictions of a future state or system, and this is where support vector machines (SVMs) come into play. SVMs are a type of supervised learning model that makes use of algorithms for finding a hyperplane in an N-directional space (where N is the number of features) and classifying the data points distinctively. SVMs are very important in predicting the outcomes of emerging environments like data mining, intelligent software agents, mass-produced models, and automated modeling.
Major Type of Unsupervised Learning Algorithms
There’s only one major variety of unsupervised learning algorithm that we’re going to address here: k-means.
k-Means
Simply put, this type of unsupervised learning algorithm is useful whenever there is a need to divide n observations into k clusters. More often than not, these observations may belong to a cluster with the nearest mean and can serve as a prototype of the cluster leading to the partitioning of the data space into Voronoi cells. Clustering involves dividing data or population points into a certain number of groups where data points in the same group have similar appearances and are differentiated from those outside the group. The major goal of using this algorithm is to locate groups in the data with the number of groups represented by the k variables. The algorithm can assign each data point to one of the k groups by capitalizing on the features provided.
The k-means algorithm has been successfully used in the following aspects of marketing: classification of documents, optimization of delivery routes for stores, identifying crime localities, customer segmentation, statistical analysis of fantasy leagues, detection of insurance fraud, rideshare data analysis, cyber-proofing criminals, analysis of call records, and automatic clustering of IT alerts.
Learning Algorithms That Can Be Supervised or Unsupervised
The learning algorithms can either be supervised or unsupervised using the following popular machine learning methods.
Decision Tree
Just as the name implies, a decision tree can be described as a support tool that uses a tree-like model (Figure 5-2) in reaching decisions and also determining their possible consequences such as outcomes, utility, and cost of resources. It serves as one of the most effective ways of displaying algorithms containing conditional control statements. A decision tree shares the same features as a flowchart where each internal (non-leaf) node is used to represent a test on a parameter, branches represent the test outcome, and leaves (or terminal) serve as a class label. These trees can serve as an integral part of operation research in decision analysis and play an important role in identifying a strategy that is most likely to reach a goal.
There is no denying the fact that businesses have to deal with lots of data obtained from market, competition, and customer analysis. Dealing with this data effectively to reach the right conclusion may take longer than expected, thus causing a delay. Since identifying and proffering solutions to business problems can be time consuming for most executives or managers, the use of decision trees can provide them with a simple abbreviated method of predicted outcomes for each of the split trees. A decision tree is a visual representation of the decision-making process and can be used to simplify problems as different as credit card attrition and currency exchange rates.
Figure 5-2. An example of a decision tree diagram using flowchart symbols
Naïve Bayes
Naïve Bayes can be described in a good number of ways depending on the area of use. In machine learning, it can be described as a family of simple probabilistic classifiers1 that are based on the application of Bayes’s theorem2 containing naïve (strong) independent assumptions in the features. This is one of the most popular methods of text characterization and has been in existence since the 1960s. Text characterization is the problem of judging documents as either belonging to one category or not (e.g., legitimate or spam, politics or sports, old or new, single or married, etc.). Naïve Bayes utilizes word frequencies as features.
In a learning problem, naïve Bayes classifiers might require a specific number of parameters linear in the number of variables (predictors or features). Naïve Bayes classifiers can be used in classifying customers based on certain parameters such as age, gender, nationality, and occupation, thus giving the company additional insights about their consumers.
Random Forest
Using several decision trees to determine the final result and predict possible outcomes can be better than using a single decision tree. A single tree cannot make a forest, and that’s why random forest (random decision forest algorithm) is the preferred method for regression, classification, and other tasks that need to construct a lot of decision trees during training time and release the class mode or mean prediction of these trees.3 (See Figure 5-3 for an illustration of how random forest works.)
Random forest is often used by many companies to make predictions with a process concerning machine learning. It uses multiple decision trees aimed at making a more holistic analysis of a given data set. During analysis, the random forest can build on the decision tree model and make the entire process more complicated. Most experts are of the view that these random forests represent “stochastic guessing” or “stochastic discrimination.”
A random forest algorithm can be used to test the quality of a customer growth strategy or product quality; for example, it has been used by companies to determine the quality of wine through parameters like alcohol content, sulfur dioxide level, pH, acidity, and sugar content. It can also be utilized in taking various product properties and variables to indicate the interests of customers and how best to meet their needs.
In many business settings, a random forest algorithm takes note of the random subset features for each tree and determines the most probable outcome. In this way a multitude of evaluations can be performed and the most likely outcome used to predict success.
Before using the random forest algorithm, I advise that you first isolate the predictive data utilized during production and apply it to the random forest model while using a certain set of training data.
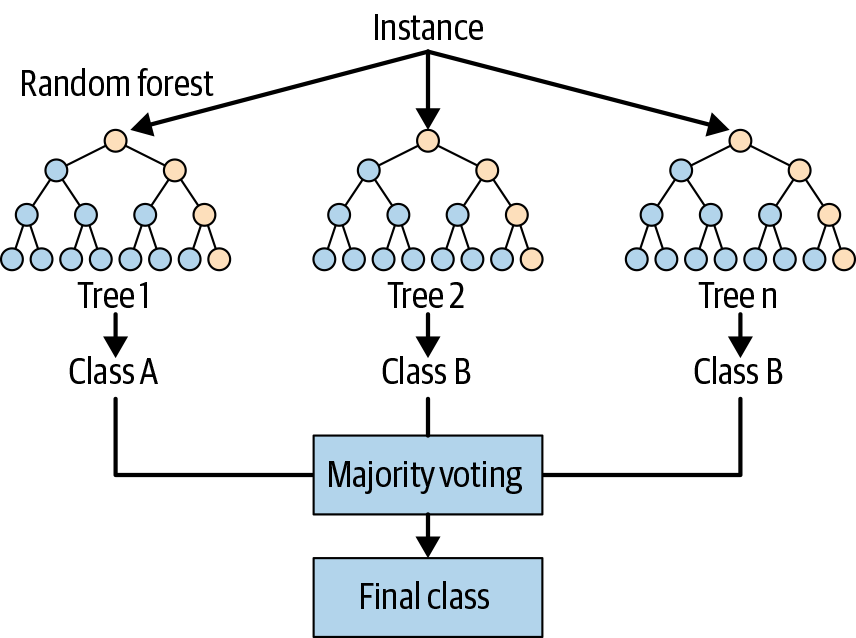
Figure 5-3. An example of a random forest simplified diagram
The Importance of Data
The most important rule to remember is that data is what powers algorithms—it’s the fuel that fires up the AI machine. So what happens when the data used to train machines is flawed? Many data scientists and others building next generation AI solutions actually spend a good amount of time scrubbing the data, cleaning it up, and putting it into a format computers can actually use. If you put garbage in, then you’ll get garbage out.
The most important rule to remember is that data is what powers algorithms—it’s the fuel that fires up the AI machine.
The best way to get clean data is to set up the right API connections from all of your key data sources and pipe them into your AI intelligent machine.4 At IMVU, we have the following data sources that were connected via API to our AI intelligent machine called Athena Prime:
-
AppsFlyer, which is our mobile attribution and marketing analytics platform. This is our source of truth for measuring success from our mobile user acquisition campaigns from different partners, including Google, Facebook, Snapchat, Apple Search, Instagram, Liftoff, InMobi, and many more. AppsFlyer, like most other attribution solutions in the space, is integrated with all the major mobile ad networks and partners so it’s seamless to track all these campaigns in one place. We also pass back all our key CRM downstream event data like new payers, revenue, and engagement. This enables AppsFlyer to pass all this valuable data back to all our advertising partners to enable them to build lookalike user segments for our systems to target on those different partner networks.
-
Leanplum is our marketing automation and CRM platform. We pass our cross-platform data into Leanplum from our backend data warehouse to help us create customized on-boarding, retargeting, and reengagement campaigns to help us better engage, retain, and monetize our users. Our goal is to ensure all new users follow similar user journeys to replicate our best lifetime value customers by influencing them to take the same user actions and behaviors.
-
All the paid user acquisition channels—Facebook, Google, Snapchat, Apple Search, Liftoff, InMobi, and many others—are connected to pass their data back to enable us to control the optimization levers like budgets, bids, and goals.
-
Creative assets are developed by the marketing team in-house at IMVU, based on an ongoing analysis of what’s working and what’s creating the most value within any given market segment. Creatives are added to each marketing channel for automated distribution.
These elements are all feeders into Athena Prime (which is the “intelligent machine” used by IMVU); we can turn over customer segments for targeting, channels for promotion, and creative elements to Athena to drive our desired marketing outcomes with maximum efficiency.
Athena Prime starts with our base business needs for any given campaign, such as marketing objective, creatives to be used within a campaign, and any additional constraints (budget, campaign dates, etc.). These parameters are fed into Athena using the UI or through programmatic API calls, providing the instructions or marching orders for the system.
As a Software as a Service (SaaS) platform, Athena Prime abstracts key components of digital media campaigns:
-
Business Needs (campaign configuration) from Audience Selection, Message Placement
-
Performance Optimization (i.e., campaign orchestration, contained in the large box below)
-
Reporting on Business Outcomes (meeting business goals, performance insights on aggregate audiences included in a campaign, and any insights into how content or ads performed)
In a generic framework sense, you can view an intelligent marketing machine in Figure 5-4, with the classes of machine learning algorithms written in white.

Figure 5-4. The intelligent machine framework
Audience Selection
In terms of Audience Selection, Athena Prime uses natural language processing, neural processing, and deep learning models to analyze ad copy and landing pages to extract interest-based targeting parameters to the extent they are made available by participating channels to improve ad relevance and performance. This feature, dubbed “Athena Sense,” does not allow for targeting on an individual level, but instead adds a contextual or interest-based component to campaign targeting without any human intervention. Athena Sense may add hundreds of additional interest-based targeting parameters to any given targeting set—something that would require an inordinate amount of work by employees or agencies to attain that level of targeting detail.
These interest-based targeting parameters are provided by platform/channel partners via programmatic APIs. These interest-based, behavioral, or demographic targeting parameters are identical to those available directly within the corresponding platform’s user interface.
For example, Athena Sense may identify that a particular ad in a campaign makes reference to Game of Thrones. Figure 5-5 shows how this targeting parameter is made available in the Facebook user interface.
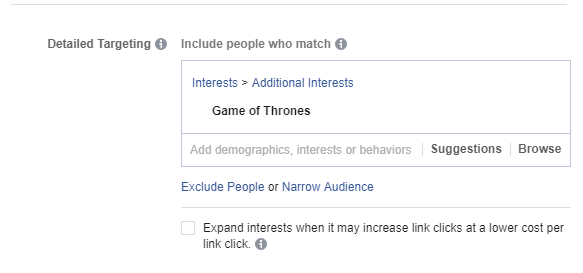
Figure 5-5. A targeting parameter in the Facebook UI
Instead of an agency or team member working through the UI of five or more marketing channels, Athena enhances targeting intelligently and automatically. This saves time, improves performance, and generates higher return on our marketing spend.
It’s also interesting to note that features like Athena Sense—which extracts meaning and context from creatives and landing pages—add valuable targeting insights that are used by the marketing platform AI on the other side of the handshake. These clues are so valuable that platforms like Facebook and Google reward advertisers that add detailed targeting enhancements to their campaigns, further boosting performance and ROI.
First-Party/CRM Data
First-party or CRM data is data collected by the advertiser through its own data-gathering systems. At IMVU, we exercise the customer engagement platform Leanplum to organize all this data into segments for optimally efficient targeting. These audiences are uploaded periodically to various marketing platforms/channels, where they are then made available to systems like Athena Prime for inclusion or exclusion in campaign targeting, but only in aggregate and in ways that prevent marketing automation providers (like Nectar9) from “reverse engineering” audiences to reveal any personally identifiable information (PII).
Custom Audiences
Custom Audiences can be created on various platforms based on a variety of methods. They are typically generated as “lookalike audiences” based on first-party or CRM data uploaded to platforms (although they can also include demographic, behavioral, or interest-based parameters as well). Custom Audiences are created directly on platform/channel providers through their user interfaces or in some cases via API calls. Regardless, Custom Audiences are aggregated in such a way so as to prevent marketing automation providers from “reverse engineering” audiences to reveal PII.
Exploration and Optimization
The final component of Athena Prime is an optimization engine that makes campaign adjustments based on performance. Athena Prime observes results being reported programmatically across channels to shift budgets to ensure maximum efficiency. This may involve shifting budgets away from certain audience segments or increasing budgets against others. It may also shift budget between different channels based on current performance against goals. But in no case does this optimization engine deal with performance on an individual user basis.
Applying Machine Learning and AI to the Customer Journey for IMVU
IMVU analyzed user journeys with our data team to explore what organic behaviors resulted in the most valuable users or purchasers. One key insight became very clear: if we can get someone to make an in-app purchase within the first seven days, this is a significant indicator of higher lifetime value. In addition, users interacting with different features and exhibiting certain behaviors within IMVU proved to be good indicators of what leads to a purchase. Our goal was to find ways to increase customer LTV and create incremental lift over organic purchases (LTV will explored in further depth in Chapter 7).
To put the insights from this study to work, we segmented our customers into three primary groupings:
-
People who installed the app, but didn’t register
-
People who were on a “First Seven Days” journey
-
Lapsed purchasers
Taking the insights from our user journey study, the marketing team then created a host of creatives for each segment grouped by where they appeared to be in their user journey. The “winners” for IMVU at each stage in the sequence are shown in Figure 5-6.

Figure 5-6. IMVU user journey creative sequence for different segments by day
Autonomous Marketing
We leveraged an AI intelligent machine platform to orchestrate and automate the delivery of sequenced ads on multiple channels in a synchronized way to get optimal results.
Typically, executing this type of sophisticated campaign with a complex array of audiences, channels, creatives, and dynamic sequencing using manual processes is challenging to say the least. But artificial intelligence is making it possible to identify the right sequencing for different cohorts of people at different stages of their life cycle.
The application of AI has allowed us to run full life cycle user acquisition and revenue generating campaigns benefiting from thousands of experiments across these cohorts. The reward of taking this approach has been an incredible 3.5X improvement in the new CAC and ROI.
Iterative Testing
The massive scale with which we can experiment, learn, and optimize messaging throughout the user journey simply isn’t possible (or worth the time and effort) without an autonomous artificial intelligence marketing engine. We can test, learn, and iterate at a much faster pace to quickly identify what works and what doesn’t across creatives, audiences, messaging, and more. It allows us to better target people with the right ads and messages based on where they are in the IMVU life cycle, encouraging them to take actions that naturally lead to higher lifetime value.
Specifically, all of this orchestration and automated learning drove a 46% lift in in-app purchases compared to the control group that was not exposed to this messaging and orchestration.
Artificial Intelligence
Let’s review the business processes at play and how the application of AI drives meaningful optimizations and outcomes through large-scale experimentation.
Starting with IMVU’s overall strategy, we set our objectives (desired outcomes), creatives, and any other campaign constraints. We then get segmentation data from our data warehouse and CRM sources, along with custom audiences we’ve developed over time. AI automates blending segmentation models with cross-channel message placement, which automatically explores, observes, and optimizes for the right business outcomes. From there, we seek further potential audience or creative insights, update our approach, and the cycle goes on. Figure 5-7 shows an example of an IMVU split test of thousands of different creative variables across different segments.
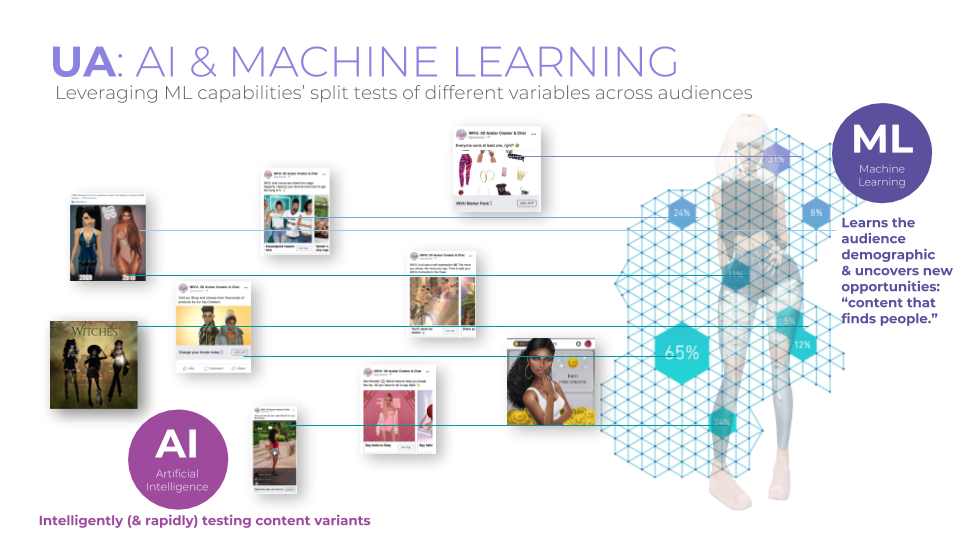
Figure 5-7. IMVU example of testing different creative variables across different segments
Rapid-Fire Experimentation
What’s happening behind the scenes as artificial intelligence orchestrates cross-channel experimentation? You can think of it like split tests of different variables across multiple digital channels—but on steroids. You’re intelligently running rapid-fire content and audience experimentation and learning in a way that uncovers new opportunities to present the right content to the right people at the right time, and taking action in the instant.
What did we take away from all this? Besides dramatically improved performance and efficiency, we gained insights into the best-performing creatives and segments.
Findings
For our lapsed purchasers segment—defined as anyone who made an in-app purchase in the last 180 days but not in the last 30 days—we learned that there were two kinds of content that worked best:
-
As a user-generated platform, IMVU benefits from an evergreen pipeline of amazing content created by its members (similar to YouTube or Soundcloud). The firm found that highlighting content from IMVU’s most influential creators delivered a showcase of novel products from the best of IMVU’s creators.
-
Weekly contests, in which users can participate to win free credits as you see in Figure 5-8, proved very popular and did a great job of attracting lapsed users back both to participate and purchase again.
We also learned that our Day 1 users were motivated by a simple message: reminding them that they can redeem free credits to get started, as you can see in Figure 5-9. This engaged them in the app and encouraged them into the flow of becoming a high lifetime value customer.
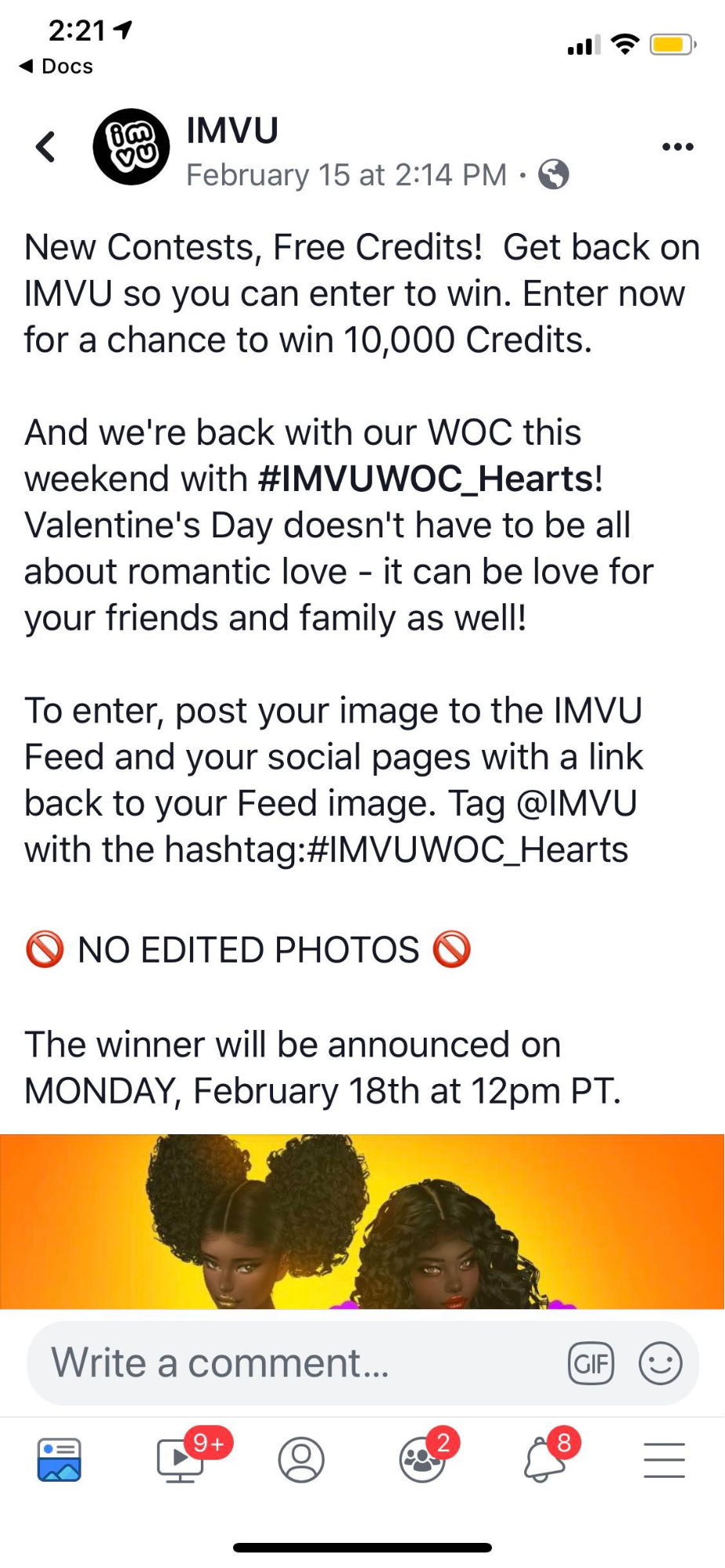
Figure 5-8. An example of the IMVU weekly contest Facebook ad
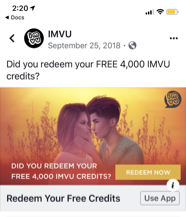
Figure 5-9. IMVU example of a retargeting ad to remind users to redeem their free credits
Bringing It All Together
Scaling growth doesn’t come easy. Let this be your road map to maximizing your customer LTV by always running sequential tests for different cohorts at different stages throughout the entire user journey. To turbocharge your performance, consider working with (or building) an intelligent AI machine to help you automate key levers like blending segmentation models with cross-channel creative placements, achieving data-driven results far beyond manual capabilities.
Now that we’ve got the basics of AI as they’re applied to marketing, and an understanding of customer life cycle marketing, we can explore options around building or buying a solution to help you turbocharge your startup’s growth.
1 In machine learning, a probabilistic classifier is a classifier that is able to predict, given an observation of an input, a probability distribution over a set of classes, rather than only outputting the most likely class to which the observation should belong.
2 In probability theory and statistics, Bayes’s theorem describes the probability of an event, based on prior knowledge of conditions that might be related to the event.
3 Random subsets of features: selecting a random set of the features when considering splits for each node in a decision tree. Random forest is an ensemble model made of many decision trees using bootstrapping, random subsets of features, and average voting to make predictions.
4 An API is a set of routines, protocols, and tools for building software applications. Basically, an API specifies how software components should interact. Additionally, APIs are used when programming graphical user interface (GUI) components. A good API makes it easier to develop a program by providing all the building blocks. A programmer then puts the blocks together.