
Chapter 2. After The Inflection Point
The only way to make sense out of change is to plunge into it, move with it, and join the dance.
Alan Watts
Standing at an inflection point is a magical experience. It’s where we learn and depart from the past and choose a new path. It’s a point where we have a choice to turn to a new direction. The rest of this book provides instructions on how to move toward this new direction with Data Mesh. We will discuss what constitutes Data Mesh in Part II, how to architect it in Part III, and how to begin executing it in Part IV. However, before we dive into that, in this chapter, I’d like to introduce Data Mesh based on its impact on organizations, given the environmental conditions it operates in, and the issues from the past solutions it must address.
Data Mesh must accept the environmental conditions that we discussed in Chapter 1, as the default starting point. It must assume, by default, the ubiquitous nature of the data. Data can be of any origin, it can come from systems within an organization, or outside, beyond the boundary of organizational trust. It can be physically served by any underlying platform on one cloud hosting or another. Data Mesh must embrace the diversity of the use cases and their unique modes of access to data. The use cases range from historical data analysis and reporting, training machine learning models and data-intensive applications. Each needs to read data in a different format, in the spectrum of graphs, files, tables and events. An ever increasing complexity of the business landscape--its diversity of functions, continuous change, and need for real-time decision making in volatile times--is the organizational reality within which Data Mesh must succeed.
Data Mesh must learn from the past solutions and address their shortcomings. It must reduce points of centralization that act as coordination bottlenecks. It must find a new way in decomposing the data architecture that, unlike technology-driven decomposition, does not slow the organization down with multi-point synchronizations. It must remove the gap between where the data originates and where it gets used in its analytical form, and remove all the accidental complexities - aka pipelines - that happen in between the two planes of data. Data Mesh must depart from data myths such as a single source of truth, or one tightly-controlled canonical model.
Ultimately, Data Mesh’s goal is to enable organizations to thrive in the face of the growth of data sources, growth of data users and use cases, and the increasing change in cadence and complexity. Adopting Data Mesh, organizations must thrive in agility, creating data-driven value while embracing change.
Figure 2-1 lists the expected organizational outcomes applying Data Mesh, as the organization size and complexity grows, as the diversity of data and organization’s data aspirations scale.

Figure 2-1. Data Mesh outcomes for organizations
In this chapter we look at the top-level outcomes that your organization achieves by adopting Data Mesh, the impact of Data Mesh and why you should care about it. For each of these outcomes, I discuss how Data Mesh accomplishes them, what shifts it creates. In discussing the shifts I give you a brief description of the foundational principles of Data Mesh -- Domain Data Ownership, Data as a Product, Self-serve Data Platform, Computational Federated Governance.You will see these in action and I point you to Part II and Part III of the book where you can get all the details.
Embrace Change in a Complex, Volatile and Uncertain Business Environment
Businesses are complex systems, composed of many domains that each have their own accountability structure, goals, and each changing at a different pace. The behavior of the business as a whole is the result of an intricate network of relationships between its domains and functions, their interactions and dependencies. The volatility and rapid change of the markets and regulations within which the businesses operate compounds the complexity.
How can businesses manage the impact of such complexity on their data? How can organizations keep going through change while continuing to get value from their data? How can businesses avoid increased cost of managing the change of their data landscape? How can they provide truthful and trustworthy data without disruption, in the face of continuous change? This comes down to embracing change in a complex organization.
In this section I discuss a few ways Data Mesh achieves embracing change despite increased complexity of the business.
Align Business, Tech and Now Analytical Data
One way to manage complexity is to break it down into independently managed parts . Businesses do this by creating domains. For example, Daff Inc. breaks down its business domains according to relatively independent outcomes and functions--including managing podcasts, managing artists, player applications, playlists, payments, marketing, etc.
This allows the domains to move fast without tight synchronization dependencies to other parts of the business.
Just as a business divides its work through business domains, technology can, and should, align itself to these business divisions. We see the best organizations orienting their technology staff around their business units, allowing each business unit to be supported by a dedicated technology capability for that unit’s work. The recent movement towards Microservices is largely about performing this kind of decomposition. As part of this we see business units controlling and managing their operational applications and data.
The first principle of data mesh carries out the same decomposition for analytic data, resulting in the Domain Ownership of Data. Each business unit takes on the responsibility for analytic data ownership and management. This is because the people who are closest to the data are best able to understand what analytic data exists, and how it should best be interpreted.
Domain ownership distribution results in a distributed data architecture, where the data artifacts - datasets, code, metadata, and data policies - are maintained by their corresponding domains
Figure 2-2 is demonstrating the concept of organizing technology (services), analytical data aligned with business.

Figure 2-2. Aligning business, tech and data to manage complexity
See Chapter 4, The Principle of Domain Ownership for further details.
Close The Gap Between Analytical and Operational Data
To make good decisions in the moment, analytical data must reflect business truthfulness. They must be as close as possible to the facts and reality of the business at the moment the decision is made. As we saw in Chapter 1, this can’t be achieved with two separate data planes - analytical and operational data planes - that are far from each other and connected through fragile data pipelines and intermediary data teams. Data pipelines must dissolve and give way to a new way of providing the analytical data and capabilities as close to the source as possible.
Changes in the business, such as adding a new feature to a product, introducing a new service, or optimizing a workflow, must be reflected near real time in both the state of the business captured by operational data as well as its temporal view captured by the analytical data.
Data Mesh suggests that we continue to recognize and respect the differences between these two planes: the nature and topology of the data, the differing use cases, their unique personas of consumers, and ultimately their diverse access patterns. However Data mesh connects these two planes under a different structure - an inverted model and topology based on domains and not technology stack - where each domain extends its responsibilities to not only provide operational capabilities but also serve and share analytical data as a product.
Data Mesh principles of Data as a Product introduces an accountability for the domains to serve their analytical data as a product and delight the experience of data consumers; streamlining their experience discovering, understanding, trusting, and ultimately using quality data. Data as a product principle is designed to address the data quality and the age-old siloed data problem, and their unhappy data consumers. See Chapter 6, The Principle of Data as a Product for more on this.
Implementing this approach introduces a new architectural unit, called data product quantum that will embed all the structural components needed to maintain and serve data as a product. The structural components include the code that maintains the data, additional information, metadata, to make data discoverable and usable, and a contract to access the data in a variety of access modes native to the data consumers.
Figure 2-3 demonstrates a different integration model between operational and analytical planes. You have seen these planes in chapter 1, integrated through clever and complex data pipelines. Here, the planes are divided by business domains. The integration between data product quantums, the analytical data plane, and their corresponding domain’s operational plane services are rather simple and unintelligent. A simple movement of data. Data product quantums will embed and abstract the intelligence and code required to transform the operational data into its analytical form.
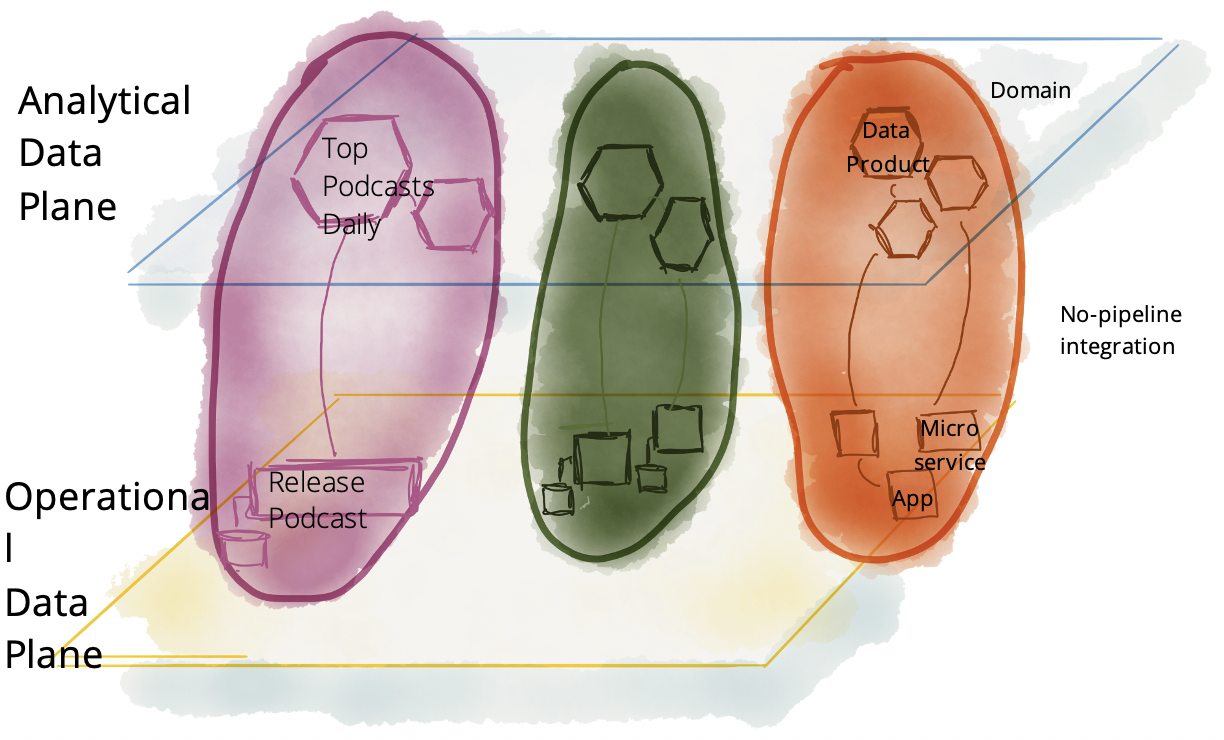
Figure 2-3. Closing the gap between operational and analytical data
Differences in today’s available technology to manage the two archetypes of data should not lead to the separation of organizations, teams, and people who work on them. I believe that our technologies will evolve at some point in the future to bring these two planes even closer together, but for now, I suggest we keep their concerns separate. The primary focus of this book, and Data Mesh itself, is on the analytical plane and its integration with the operational plane.
Localize Data Change to Business Domains
Data Mesh must allow for data models to change continuously without fatal impact to downstream data consumers, or slowing down access to data as a result of synchronizing change of a shared global canonical model. Data Mesh achieves this by localizing change to domains by providing autonomy to domains to model their data based on their most intimate understanding of the business without the need for central coordinations of change to a single shared canonical model.
Data Mesh imposes contracts, well-defined and guaranteed interfaces, to share data. This liberates domains to change their data models, given that they still support the older revisions of their contracts, until they gracefully migrate their data users to the new revisions. Data Mesh introduces a set of discovery APIs that allow data product users to locate and consume data according to the guarantees of the data discovery APIs. See Chapter 4, The Principle of Domain Ownership and Chapter 5, The Principle of Data as a Product for more on this.
Reduce Accidental Complexity of Pipelines and Copying Data
As Fred Brooks laid out in his widely popular paper, “No Silver Bullet – Essence and Accident in Software Engineering”, there are two types of complexity when building software systems. First, the essential complexity: the complexity that is essential and inherent to the problem space. This is the business and domain complexity we discussed earlier. And second, the accidental complexity: the complexity that we - engineers, architects and designers - create in our solutions and can be fixed.
The world of analytical solutions is full of opportunities to remove and fix accidental complexities. Let’s talk about a few of those accidental complexities that Data Mesh must reduce.
Today, we keep copying data around because we need the data for yet another mode of access, or yet another model of computation. We copy data from operational systems to a data lake for data scientists. We copy the data again into lakeshore marts for data analyst access and then into the downstream dashboard or reporting databases for the last mile. We build complex and brittle pipelines to do the copying. The copying journey continues across one technology stack to another and across one cloud vendor to another. Today, to run analytical workloads you need to decide upfront which cloud provider copies all of your data in its lake or warehouse before you can get value from it.
Data Mesh addresses this problem by creating a new architectural unit that encapsulates a domain-oriented data semantic, but yet provides multiple modes of access to the data suitable for different use cases and users. This architectural unit is called the Data Product Quantum. It will have a clear contract and guarantees to its readers, and meet their native access mode, SQL, files, events, etc. Data product quantum can be accessed anywhere across the internet and it provides access control and policy enforcement necessary at the time of access, locally at its interface. Data product quantum encapsulates the code that transforms and maintains its data. With abstraction of transformation code inside a data product quantum, and accessing data through data product quantum interfaces, the need for pipelines will go away. Removing the brittle concept of pipeline reduces the opportunity for failure in case of an upstream data change. Data Mesh introduces standardized interfaces to discover and access every data product enabled by a self-serve infrastructure. See Chapter 8 on the logical architecture of Data Mesh, and Chapter 9 for more details on the data product quantum and Chapter 6, on self-serve data infrastructure.
Sustain Agility in the Face of Growth
Today, businesses’ successes are predicated on multi-faceted growth--new acquisitions, new service lines, new products, geolocation expansions and so on. All this leads to new sources of data to manage and new data-driven use cases to build. Many organizations slow down or plateau in the speed of delivering value from their data, onboarding new data, or serving the use cases as they grow.
Data Mesh’s approach to sustain agility in the face of growth can be summarized in a few techniques that aim to reduce bottlenecks, coordination, and synchronization. Agility relies on business domains’ ability to achieve outcomes autonomously and with minimal dependencies.
Remove Centralized and Monolithic Bottlenecks of the Lake or the Warehouse
A centralized data team, managing a monolithic data lake or warehouse limits agility, particularly as the number of sources to onboard or number of use cases grow. Data Mesh looks carefully for centralized bottlenecks, particularly where they are the focal point of multi-party synchronization, both from the human communication perspective and architecture. These bottlenecks include data lakes and data warehouses.
Data Mesh proposes an alternative, a peer-to-peer approach in data collaboration when serving and consuming data. The architecture enables consumers to directly discover and use the data right from the source. For example, an ML training function or a report, can directly access independent data products, without the intervention of a centralized architectural component such as a lake or a warehouse, and without the need for an intermediary data (pipeline) team. See chapter 9 for details of peer-to-peer data consumption through data product quantum’s output data ports and input data ports.
Figure 2-4 demonstrates the conceptual shift. Each data product provides versioned interfaces that allow peer-to-peer consumption of domain-data to compose aggregates or higher-order data products.

Figure 2-4. Removing centralized bottlenecks
Reduce Coordination of Data Pipelines
Over the last decades, the technologies that have exceeded in their operational scale have one thing in common, they have minimized the need for coordination and synchronization. Asynchronous IO has scaled the throughput of networked applications over blocking IO. Reactive applications, for example, have resulted in faster parallel processing of messages. Apache Hadoop scaled data processing by running MapReduce functional programming model across many servers distributedly. Using choreographed event-driven microservices over centrally orchestrated ones has allowed us to scale our business workflows.
Despite our relentless effort to remove coordination and synchronization from our core technologies in order to achieve scale and speed, we have, for the most part, neglected organizational and architectural coordination. As a result, no matter how fast our computer systems run, achieving outcomes have fallen behind coordinating activities of teams and humans.
Data Mesh addresses two of the main coordination issues in the data management processes and architecture. A technically-divided architecture of a pipeline - ingestion, processing, serving, etc. - results in the coordination of these functions to deliver a new data source, or serve a new use case. Data Mesh moves away from technical-partitioning of data management, to domain-oriented partitioning. Domain-oriented data products must be able to develop and evolve independently of other data products. The domain-oriented decomposition reduces the need for coordination to achieve an outcome. For the most part, a new data source or a new use case can be served by a domain-oriented data product team. In cases where a new use case requires access to a new data product outside of the domain, the consumer can make progress by utilizing the standard contracts of the new data product, mocks, stubs, or synthetic data interfaces until the data product becomes available. This is the beauty of contracts, easing the coordination between consumer and provider during development. See chapter 4, The Principle of Domain Ownership for more on this.
Reduce Coordination of Data Governance
Today, another major coordination bottleneck is the central function of data governance. Data governance coordination is necessary to provide access to data users, approve the quality of datasets, and validate the conformance of data changes with the organization’s policies.
Data Mesh introduces a federated and computational data governance model, where the governance team is composed of the individual domain data product owners, the main owners of the data products. The governance function aims to embed policy execution into every data product in a computational and automated fashion. This vastly improves the function of governance today, which is one of the main synchronization points for discovering data, approving data, and making sure it follows the necessary policies.
As you can imagine, the autonomy of the domains can have undesirable consequences if not checked; isolation of domains, incompatibility and disconnection of one domain’s data product from others, and a fragmented experience when consuming multiple domains’ data. Data Mesh governance heavily relies on the automation of governance concerns for a consistent, connected and trustworthy experience using the domains’ data products.
See Chapter 7, The Principle of Federated Computational Governance.
Enable Autonomy
The correlation between team autonomy and team performance has been the subject of team management studies. Empirical studies show that teams’ freedom in decision making to fulfill their mission can lead to better team performance. On the other hand, too much autonomy can result in inconsistencies, duplicated efforts and team isolation.
Data Mesh attempts to strike a balance between team autonomy and inter-term interoperability and collaboration, with a few complementary techniques. It gives domain teams autonomy to have control of their local decision making, such as choosing the best data model for their data products. While it uses the computational governance policies to impose a consistent experience across all data products; for example, standardizing on the data modeling language that all domains utilize.
Domain teams are given autonomy to build and maintain the lifecycle of their data products. While Data Mesh places a domain-agnostic data platform team who empowers the domain teams with self-serve capabilities to manage the lifecycle of data products declaratively and consistently, to prevent team isolation and decrease cost of autonomy.
The principles of self-serve data platform, essentially makes it feasible for domain teams to manage the lifecycle of their data products with autonomy, and utilize the skillsets of their generalist developer to doso.
These self-serve data infrastructure APIs allow data product developers to build, deploy, monitor and maintain their data products. The APIs allow data consumers to discover, learn, access, and use the data products. The self-serve infrastructure makes it possible for the mesh of data products to be joined, correlated and used as a whole, while maintained independently by the domain teams.
See Chapter 6, The Principle of Self-serve Data Platform, for more.
Increase the Ratio of Value from Data to Investment
Industry reports, such as the NewVantage Partner I shared in chapter 1, and my personal experience, point to the fact that we are getting little value from data compared to the investments we are making in data management. If we compare the value we get from our data teams and data solutions, compared to other technical developments such as infrastructure, mobile and application development, it’s evident that we are facing headwinds when it comes to data.
Data Mesh looks at ways to improve the ratio of value over effort in analytical data management: creation of a new archetype of data platform that abstracts today’s technical complexity, through open data interfaces that enable sharing data across organizational trust boundary or physical location, and through applying product thinking to remove friction across all stages of the value stream that gets analytical data from the points of origin to the hands of data scientists and analysts.
Abstract Technical Complexity with a Data Platform
Today’s landscape of data management technology is undoubtedly too complex. The litmus test for technical complexity is the ever growing need for data engineers and data technology experts. We don’t seem to ever have enough of them. Another litmus test is the low value to effort ratio of data pipeline projects. Much effort is spent with little value returned - getting access to baseline datasets with quality.
Data Mesh looks critically at the existing technology landscape, and reimagines the technology solutions as a data-product-developer(or consumer)-centric platform. In chapter 6, The Principle of Self-Serve Data Platform, we will see how Data Mesh arrives at a set of self-serve data platform capabilities to remove friction and complexity from the workflows of data product developers and data product users. Data Mesh intends to remove the need for data specialists and enable generalist experts to develop data products.
Additionally, Data Mesh defines a set of open interfaces for different affordances of data products - discovering, querying, serving data, etc. - to enable a more collaborative ecosystem of tools. This is in contrast to a heavily proprietary data technology landscape with a high cost of integration across vendors. See chapter 9 on data products’ open interfaces.
Embed Product Thinking Everywhere
Data Mesh introduces a few shifts to get us laser focused on the value, as perceived by the data users. It shifts our thinking from data as an asset to data as a product. It shifts how we measure success from the volume of the data to measure to the happiness and satisfaction of the data users. See chapter 5, The Principle of Data as a Product, for more details on achieving this shift.
Data is not the only component of a Data Mesh ecosystem that is treated as a product. The self-serve data platform itself is also a product. In this case, it serves the data product developers and data product consumers. Data Mesh shifts the measure of success of the platform from the number of its capabilities, to the impact of its capabilities on improving the experience of data product development, the reduced lead time to deliver, or discover and use of a data product. See chapter 5, The Principle of Self-Serve Data Platform for more on this.
Go Beyond The Boundaries
The value that a business unit can generate almost always requires data beyond the unit’s boundary, requiring data that comes from many different business domains. Similarly, the value that an organization can generate serving its customers, employees, and partners often requires access to data beyond the data that the organization generates and controls.
Consider Daff Inc. In order to provide a better experience to the listeners with auto-play music, it not only requires data from listeners’ playlist, but also their network, as well as their social and environmental influences and behaviors. It requires data from many corners of Daff Inc, and beyond including news, weather, social platforms, etc.
Multi-domain and multi-org access to data is an assumption built into Data Mesh. Data Mesh’s data product concept can provide access to data no matter where the data physically resides. Data product quantum provides a set of interfaces that essentially allow anyone with the proper access control, discover, and use the data product independent of its physical location. The identification schema, access control and other policy enforcement assumes using open protocols that can be enabled over the internet. See chapter 8, Data Mesh Logical Architecture for more on this.
Recap
After reading this chapter you might assume that Data Mesh is a silver bullet. Quite the contrary. Data Mesh is an important piece of the puzzle. It enables us to truly democratize access to data. However to close the loop of deriving value from data, there is much more that needs to be done beyond just getting access to data. We must be able to continuously deliver analytical and ML-based solutions. However bootstrapping this closed loop, requires access to data at scale, which is a focus of Data Mesh.
The Data Mesh goals listed in this chapter, invites us to reimagine data, how to architect solutions to manage it, how to govern it, and how to structure our teams . The expectation to become resilient to business complexity, to sustain agility in the face of growth, and accelerate getting value from data pushes us to work with the reality of increasing complexity, growth and volatility instead of fighting to control it.
In the next chapter, I will give an overview of what has happened before the inflection point. Why the data management approach that got us here, won’t take us to the future.