
Reputation-Based Security
Internet users are under attack, and an increasingly common characteristic of malware is the presence of a URL that a user must visit as part of the attack. Organized criminals methodically and invisibly exploit vulnerabilities in websites and browsers to infect computers, stealing valuable information (login credentials, credit card numbers, and intellectual property), and turning both corporate and consumer networks into unwilling participants in propagating spam and malware. Simply allowing a user to visit their favorite website, or clicking a link from their top ten search results, is all it takes for the malware infection process to unknowingly begin.
For most malware creators, recognition for creating a clever piece of malware is no longer the point. With a thriving, maturing malware economy in place, it’s more valuable to create malicious code that generates revenues for online criminal networks—for example, through click-fraud, massive spam campaigns, or identity and data theft.
To be successful, the malware must be both easy to distribute to as many victims as possible and difficult to detect. That makes the Internet an attractive malware delivery mechanism. Originally, malware was delivered directly through email, but the visibility of large attachments and the store-and-forward nature of email made it relatively simple to stop. The near-real-time nature of Internet websites, with threats hidden directly in the content, makes malware exponentially more difficult to stop.
The growing significance of the Web as a threat delivery mechanism is shown by the fact that more than 80 percent of spam messages include URLs, which can direct a user to a web server where malware is located. That percentage is even higher for malicious emails, such as phishing campaigns. These URLs are intended to lure readers to websites that engage them in questionable transactions or download malware onto their computers.
Typically, both the spam messages and the malicious websites the messages refer to use a combination of social engineering and software vulnerabilities to compromise users. Malicious websites, specifically created to distribute malware, are not the only sites compromising users. Hackers are now frequently distributing malware through legitimate websites that have been compromised, taking advantage of security flaws in web applications.
More often, malware writers are targeting legitimate, trusted websites as the starting point for malware distribution. Both BusinessWeek.com and MSNBCsports.com had portions of their websites used for distributing malware. Although no threat is present on these websites today, users became infected simply by visiting trusted sites. Knowing these websites are trusted by millions of users makes them easy targets for malware writers.
As Figure 5-10 shows, the attacker’s traffic mixes with that of trusted visitors. If the attackers gain control of the site, they often insert attacks to those trusted users.
Figure 5-10 Criminals Compromise Legitimate Websites to Infect Unsuspecting Users

Reactive Filtering Can’t Keep Up
Traditional methods of protection are usually not fast, accurate, or comprehensive enough to assess and protect users from these new, dynamic web-based threats, which are growing in record numbers.
IP blacklists and URL-filtering solutions typically cover only a small percentage of all URLs and IP addresses—and only the known bad ones. They are also normally binary, offering only “block/malicious” or “allow/safe” options for the URLs and IP addresses they do cover, instead of providing detailed, granular information about any possibly suspicious URL, IP address, or object—even those that haven’t been known offenders before.
Even with security categories enabled, these URL-filtering solutions can’t help when a legitimate, normally trustworthy website has been turned into a redirection hub for malware distribution. The website’s URL is trusted and not on any blacklist. Consequently, acceptable-use policies designed to protect a network by preventing access to certain sites can’t prevent users from getting infected on acceptable websites. Because traditional URL-filtering technologies are concerned only with the initial domain request, they don’t examine the additional objects needed to load the web page correctly or their origins, and thus don’t observe the malicious redirection. When a web page has an average of 150 objects, traditional URL-filtering technologies simply can’t keep up. This was the case on September 13, 2009, for visitors to NYTimes.com; a trusted source often categorized by URL filtering lists as “news.” A seemingly legitimate advertisement (inserted via a single object on the site—when there are so many objects linked to each web page) began presenting a pop-up, alerting visitors that a virus had infected their system. Victims were then redirected to a malware site that offered legitimate-looking antivirus software, which was actually a malicious Trojan.
The sophistication, innovation, rapid pace, and dynamic nature of these attacks often render traditional defenses useless. URL filtering and IP blacklisting are reactive and cannot adequately assess new or previously uncompromised sites in a timely fashion, whereas signature-based scanning solutions have trouble keeping up with the constant mutation of malware. Protecting users from today’s web-based threats requires a layered, holistic, and integrated approach that uses multiple advanced methodologies to assess each threat and type of network traffic. The solution to this new threat asks a simple but powerful question:
“What is the reputation of this URL?”
When assessing the trustworthiness of a URL, a great deal can be determined by analyzing data that is hard to forge, such as how long the domain has been registered, in what country the website is hosted, whether the domain is owned by a Fortune 500 company, whether the web server is using a dynamic IP address, and more.
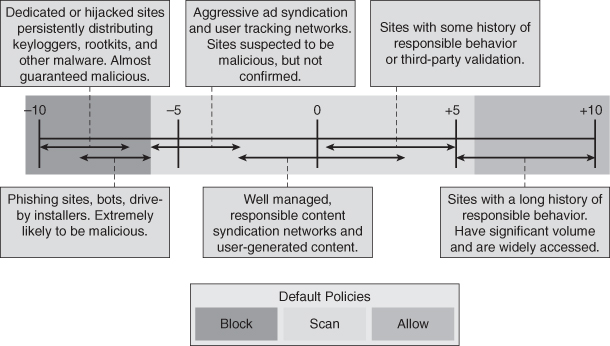
For example phishing site creators can spoof the content of their websites to perfectly replicate legitimate banking and e-commerce sites. Phishing sites cannot, however, spoof the URL on which they are located. The reputation of the URL assigns a reliability score to the vast majority of URLs and can therefore protect users. Analyzing data, even the most difficult to manipulate elements, can reveal much about the trustworthiness of a URL. Data analysis can determine how long a domain has been registered, whether it was registered by machine or manually, who owns it, whether it is associated with an IP address that has previously been associated with a web-based threat, whether the IP address is dynamic or static, what country the website is hosted in, and more. By gathering this information and assigning a score to each category when a user attempts to access a URL, this score is calculated, and access is either permitted or denied. As shown in Figure 5-11, sophisticated algorithms analyze and correlate threats with more than 200 different web traffic- and network-related parameters (Cisco products only) to accurately evaluate a web object’s malware risk. Using this data, a dynamic score ranging from +10 to –10 is generated for web reputation. The same technology in senderbase.org, now sensorbase, has been adapted to intrusion prevention system (IPS) technologies, but the scoring assumes the attack is malicious and is –1 to –10 as an additional anomaly detection over and above traditional methods.
Figure 5-11 URL Reputation Examples
Cisco Web Reputation Solution
Cisco Web Reputation Filters are the world’s premier reputation system, in part because of the Cisco acquisition of Ironport. Powered by the Cisco Security Intelligence Operations and the Sensor Base network, Cisco Web Reputation Filters have visibility into more than 100,000 global networks—including Cisco IPS, with more than 30 percent of the world’s email and real-time traffic insights from customer participation. Cisco built the Sensor Base reputation database from more than 800,000 sensors deployed by customers globally. Each sensor now has the capability to anonymously contribute what it is detecting directly to Cisco Sensor Base.
Unlike traditional URL-filtering solutions, Cisco Web Reputation Filters examine every request made by the browser. Instead of just looking at the initial HTML request, they also analyze all subsequent data requests, considering each element on a web page and its origins—including live data (such as JavaScript, ads, and widgets), which might be fed from different domains. This enables Cisco Web Reputation Filters to give users a much more precise and accurate assessment and block web content in a far more fine-grained way than URL-filtering and IP-blacklisting solutions.