
Chapter 4: Reading Data from Text Files
Some Basic Rules of SAS Programs
Writing a Program to Read a Text File Where Data Values Are Separated by Delimiters
Reading Text Files with Other Delimiters
Setting the Length of Character Variables
Reading Text Data in Fixed Columns
Introduction
You may have data in text files, either separated by delimiters or arranged in columns. In order to import data of this type, you will need to write a SAS program. Don't panic. It's not that hard to do, and at some point in your education, you may need to go beyond what the SAS Studio point-and-click environment can do for you.
If your data is in one of the formats described in the last chapter (Excel, CSV, Access, SPSS, etc.), you can skip this chapter. However, this chapter also covers some basics of SAS programming that will be useful if you need to do more advanced data manipulation or if you work in a company or university where SAS Studio is not available and you have to write your own programs. For a more detailed discussion of SAS programming, please take a look at Learning SAS by Example (Cody, 2007) or Introduction to SAS University Edition (Cody, 2015), both available from SAS Press (support.sas.com/cody).
Understanding the Work Area
So far in this book, you have been exploring the Navigation pane on the left side of the SAS Studio screen. It's now time to shift your attention to the work area on the right side of the screen. Below is an expanded view of the work area (Figure 1 below):
Figure 1: Expanded View of the Work Area

There are three tabs: CODE, LOG, and RESULTS. The CODE tab is where you write your SAS programs. After you run a program, the LOG tab displays your program, any syntax errors that you made, information about data being read or written, and some information about CPU time and other resources that were used. Finally, the RESULT tab is where the output (tables, statistical tables, graphs, etc.) appear.
SAS programs consist of two main sections: DATA steps, where you read, write, and process data, and PROC (short for procedure) steps where you provide information to built-in procedures that create reports, graphs, or perform statistical tests. DATA steps begin with the keyword DATA and usually end with a RUN statement; PROC steps begin with the keyword PROC and usually end with a RUN or QUIT statement.
Some Basic Rules of SAS Programs
As with all programming languages, SAS has syntax and logic rules that must be followed. The first rule is that every SAS statement ends with a semicolon.
This is a good place to mention that one of the most common programming mistakes, especially with beginning SAS programmers, is to forget a semicolon at the end of a statement. This sometimes leads to confusing error messages.
When you write a program, you can place several statements on a single line if you end each statement with a semicolon. (Note: This practice is not recommended—it makes programs hard to read.) Next, a SAS statement can use as many lines as necessary. Many SAS programmers leave blank lines between sections of their programs to make the program easier to read.
Next, there are some naming conventions for data set names, SAS column (variable) names, and other entities that you will encounter later. Most SAS names comply with the following rule:
SAS names are a maximum of 32 characters in length. They must begin with a letter or underscore (_). The remaining characters in a SAS name are letters, numbers, or underscores. Spaces are not allowed in any SAS name.
If you are introducing a new column name in a program, you are free to use uppercase, lowercase, or mixed case. SAS names are not case-sensitive. However, SAS remembers the case that you used the first time the column or variable name is written and will use that case in all of the reports and listings produced by the program, even if you write the column name differently elsewhere in the program.
Here are some examples of valid and invalid SAS names:
| Valid SAS Names |
| My_Data HeightWeight X123 _123 Price_per_pound |
| Invalid SAS Names |
|
| My Data 123xyz Temperature-Data Group% |
Contains an invalid character (space) Starts with a digit Contains an invalid character (-) Contains an invalid character (%) |
Writing a Program to Read a Text File Where Data Values Are Separated by Delimiters
In the last chapter, you saw how to read CSV (comma-separated values) files using the Import task under the Utilities tab. When the first row of the file contains column names, SAS can use those names when creating the SAS data set. When the first row of the file does not contain column names, SAS names the columns Var1, Var2, Var3, and so forth.
There are two reasons to write a SAS program to read delimited data: First, if your CSV file does not have column names in the first row and you do not want SAS to name your columns Var1, Var2, Var3, etc., you can write a short program to read the file and assign your own column names. Second, you may have a file with other delimiters such as spaces or pipes (the | symbol) instead of commas.
To demonstrate this process, a file called Health_List.txt was created in a folder called c:SASUniversityEditionmyfolders (the shared folder that is created if you follow the installation instructions for SAS University Edition). The file uses spaces as delimiters and contains some demographic and health data. A description of the file is shown in Figure 2:
Figure 2: Description of the Blank Delimited File Helth_List.txt
| Valid SAS Names | Description |
| Subj | Subject number |
| Gender | Gender (M or F) |
| Age | Age in years |
| HR | Heart rate |
| SBP | Systolic blood pressure |
| DBP | Diastolic blood pressure |
| Chol | Total cholesterol |
A listing of the file is shown in Figure 3:
Figure 3: File Health_List.txt (located in c:SASUniversityEditionmyfolders)
001 M 23 68 120 90 128
002 F 55 72 180 90 170
003 F 18 58 118 72 122
004 M 80 82 . . 220
005 F 34 62 128 80 .
006 F 38 78 108 68 220
There are several important features of this text file. First, one or more successive spaces represent a single delimiter. Next, a period was used to represent a missing value. These two properties of this text files are what SAS uses as defaults in a type of input called List Input.
You can write a very short program to read this text file and create a SAS dataset. Here is the beginning of such a program, written under the CODE tab in SAS Studio (Figure 4):
Figure 4: Starting to Write a Program to Read the Text File Helth_List.txt and Create a SAS Data Set
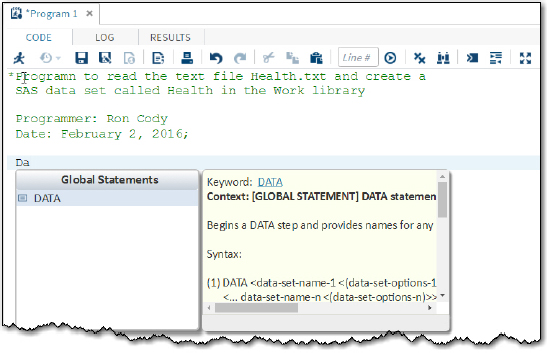
The first six lines of this program constitute a comment statement. If you have written programs in other computer languages, you are, no doubt, familiar with comment statements. Comment statements are ignored by the computer (they are not compiled or interpreted) but are very useful for you or someone else trying to understand what the program does, who wrote it, and when.
SAS COMMENT statements begin with an asterisk (*) and end with a semicolon. Following the rules about SAS statements mentioned earlier, the COMMENT statement above uses several lines and even contains a blank line.
Following the comment, you see the first two letters of the word data. DATA is the keyword that begins a DATA step, the place where you read and write data and perform computations and/or logical actions. As you begin to type the word "data", the SAS Studio editor causes a syntax box to appear, giving you information about the syntax of the statement that you are starting to type.
Once you are familiar with SAS programming, you may want to turn off the Auto-Complete feature of SAS Studio. Here's how to do this (along with setting a few additional editor options):
First click the Menu icon (Figure 5):
Figure 5: The Menu Icon

This brings up the following screen:
Figure 6: The Preferences Menu

Click Editor in the list of options:
Figure 7: List of Editor Preferences

You can select or deselect any of these options, as well as choose the number of spaces to indent when you press the Tab key; the font size; and an option concerning the Autosave feature. The next figure shows this author's preferences:
Figure 8: Changing the Editor Preferences

You see that autocomplete and Enable hint are turned off; the tab width is set to 3 (this author's usual choice); the option to substitute spaces for tabs is selected; and the Font size is set to 16. Once you are finished with the Editor options, click the SAVE box at the bottom of the screen.
Now, back to the program. Figure 9 shows a listing of the completed program:
Figure 9: Completed Program

You have already seen the COMMENT statement. The DATA statement lets you choose a name for the SAS data set that you want to create (Health in this example). The INFILE statement tells the program where to find the text file Health_List.txt. Remember that the actual location for this file was c:SASUniversityEditionmyfolders. This is a shared folder and you refer to it in your program as /folders/myfolders/Health_List.txt. The shared folder name is placed in either single or double quotation marks.
Finally, the INPUT statement lists the names of each of the columns in the data set that you are creating. This type of INPUT statement (there are other types) is called ‘list input'. Unless you indicate otherwise, SAS treats multiple delimiters (such as multiple blanks or commas in a row) as a single delimiter.
Because Gender is a character value, you indicate this to SAS by following the column name with a dollar sign ($). You end the DATA step with a RUN statement.
By default, placing a dollar sign in an INPUT statement when you are reading delimited data, allows you to read up to eight characters.
You will see shortly how to change the default length to a length appropriate for your character values. It's time to run your program. Click the Run icon.
Figure 10: Click the Run Icon

You should see the following:
Figure 11: The RESULTS Window

Here you see all the columns selected and a display of the data. (Before this screen shot was taken, the author right-clicked on the top line (where you see the column names) and the option "Size grid columns to contents" was selected.)
Before you celebrate, you should (always) check the SAS log. Click the LOG tab to do this. It looks like this:
Figure 12: Inspecting the Log

The very top of the log show Errors, Warnings, and Notes. If you have any errors or warnings, you can scroll down to view them. As an alternative, you double-click the errors or warnings heading to display a list of all the errors or warnings. You will see a demonstration of this later in this chapter.
Because your program ran successfully, it's time to save it. Click the File Save icon, select the folder where you want the program to be stored, name the file, and click Save (Figure 13):
Figure 13: Saving and Naming Your Program

Viewing Errors and Warnings
To demonstrate how the Errors and Warnings indicators work, an error was introduced in the program (the data set name was changed to 123Health, an invalid name). Here is the log from the modified program:
Figure 14: Log Showing an Error
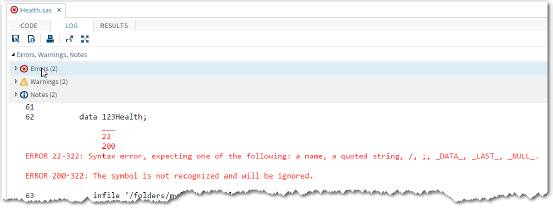
Because this program has so few lines, the error shows up without your having to scroll down. However, when you write longer programs, you can see each of the errors by placing the cursor on the Errors heading (as shown in Figure 14) and double-clicking. This brings up a list of errors like this:
Figure 15: Double-click the Errors Heading

You can click on any of the errors to jump to the portion of the program where the error occurred.
One hint about error messages: One single error can often result in several error messages, making them difficult to interpret. If you fix one error, it is possible that other error messages disappear when you run the program again.
Reading CSV Files
Commas are one of the most popular delimiters. In the previous chapter, you saw how to use the Import Data task to read CSV files. CSV files use commas as delimiters; and if there are two commas together, it is assumed that there is a missing value for that column.
The same data contained in the Health_List.txt file was converted to a CSV file called Health.csv and is listed below:
Figure 16: Listing of File Health.csv
001,M,23,68,120,90,128
002,F,55,72,180,90,170
003,F,18,58,118,72,122
004,M,80,82,,,220
005,F,34,62,128,80,,
006,F,38,78,108,68,220
Because this is a CSV file where two commas together represent a missing value, there is no need to use a period to represent a missing value as was the case with the space-delimited file.
You could read this file using the Import Utility, but the column names would be Var1, Var2, etc. (You would also have to uncheck the option to generate SAS names when using the utility.) You can write a short SAS program, similar to the program you used to read the Health_List.txt file. The only change you need to make is to add the DSD (Delimiter-Sensitive Data) option in the INFILE statement. You place INFILE options after you specify the file location. The DSD option performs several actions: One is to use commas as delimiters; the other is to interpret two successive commas to mean that there is a missing value for the next value being read. Here is a program that can read the Health.csv file:
Figure 17: Program to Read the Health.csv File

The resulting data set is identical to the one previously created from the Health_List.txt file.
Reading Text Files with Other Delimiters
You may encounter files with delimiters other than blanks or commas. These files may follow the rule that you treat multiple delimiters as a single delimiter (as with the program in Figure 9), or they may follow the rule that multiple delimiters represent missing values (as with CSV files).
You can address both of these issues easily. First, you can add an INFILE option called DLM= to specify one or more delimiter characters (even non-printing ones such as tabs) that were used in the file. Next, if your delimiters are treated similar to the way commas are treated in CSV files, add the option DSD as well.
Here are several examples of INFILE statements to demonstrate how to use these two options:
• You have a comma-delimited file, but you want multiple commas to be treated as a single delimiter:
INFILE '/folders/myfolders/your_file' DLM=',';
• You have a file where tabs are the delimiters, and you want multiple tabs to be treated as a single delimiter:
INFILE '/folders/myfolders/your_file' DLM='09'x;
Because tabs are non-printing characters, you refer to them using what is called a hexadecimal constant. In ASCII, a tab is coded as 09. You represent this value in a SAS DATA step by placing the '09' in single or double quotation marks and following it with an upper- or lowercase x.
• You have a file where commas, question marks, and dollar signs are delimiters, and you want to treat any two delimiters together to indicate a missing value (as with CSV files):
INFILE '/folders/myfolders/your_file' DLM=',?$' DSD;
In this example, you use both the DLM= and DSD options. DLM= lets you supply the list of possible delimiters, and the DSD option treats multiple delimiters together to indicate that there are multiple missing values. Remember, without the DLM= option, using DSD assumes the default delimiter is a comma (it was created specifically to read CSV files).
Setting the Length of Character Variables
In the previous program, you placed a dollar sign after the column Gender to tell the program that Gender was a character variable. Although the program runs OK, the storage length for Gender is eight bytes (characters) because that is the default length for list input when a length is not defined. In most cases, you want to specify an appropriate length for every character variable in your data set. Why? Two reasons: If your variable is shorter than eight (Gender is only a single character), you are wasting storage space. If your character variable is longer than eight characters, it will be truncated.
One way to specify the length of each character column (variable) is to add a LENGTH statement before the INPUT statement. The syntax for the LENGTH statement is:
LENGTH Column-Name(s) $ n Column-Name(s) $ n;
where Column-Names(s) is a single column name or a list of column names (if they are all going to have the same length). The 'n' in the $n part of the statement is the length assigned to the preceding column name(s). For example, to assign a length of one to Gender, the LENGTH statement would read:
Length Gender $ 1;
It is important that the LENGTH statement come before the INPUT statement. Here's the reason: SAS determines the length of all columns by first scanning the program, looking for column names. The first time it sees a column name, it assigns a length, based on how the column is referenced. If you do not use a LENGTH statement as in Figure 17, SAS uses a default length of eight. If you placed the LENGTH statement after the INPUT statement, the length would already have been set to eight and the LENGTH statement would be ignored.
As a further example, the following LENGTH statement sets a length of one for the columns Ques1-Ques10, a length of 15 for column Last_Name, and a length of 11 for the column SS:
LENGTH Ques1-Ques10 $ 1 Last_Name $ 15 SS $ 11;
By the way, as you probably guessed, the notation Ques1-Ques10 refers to 10 columns Ques1, Ques2, up to Ques10.
If you want to modify the program displayed in Figure 17 to define a length of one for Gender, the entire program would look like this:
Figure 18: Adding a LENGTH Statement

Reading Text Data in Fixed Columns
The last section of this chapter shows you how to read text data where the data values are placed in predefined columns. A data definition for a file that contains the same information as the Health_list.txt and Health.csv files is listed below:
Columns in the Health Data File
| Variable Name | Description | Starting Column | Number of Columns |
| Subj | Subject number | 1 | 3 |
| Gender | Gender (M or F) | 4 | 1 |
| Age | Age in years | 5 | 2 |
| Heart Rate | Heart rate | 7 | 2 |
| SBP | Systolic blood pressure | 9 | 3 |
| DBP | Diastolic blood pressure | 12 | 3 |
| Chol | Total cholesterol | 16 | 3 |
The data file looks like this:
123456789012345678901234567890 (Ruler – this line is not in the file)
001M2368120 90128
002F5572180 90170
003F1858118 72122
004M8082 220
005F3462128 80
006F3878108 68220
With this information, you can now write an INPUT statement. One way of writing such a statement is called "formatted input." It looks like this:
Input @1 Subj 3.
@4 Gender $1.
@5 Age 2.
@7 Heart_Rate 2.
@9 SBP 3.
@12 DBP 3.
@16 Chol 3.;
Before each column name, you see an @ sign followed by a number. SAS calls this a column pointer. For example, @7 means "go to column 7." Following the column pointer, you enter a valid column name followed by what SAS calls an INFORMAT. Informats tell the program how to read and interpret the data in the columns following the column pointer. This INPUT statement uses only two informats. The numbers without any dollar signs are numeric informats. They tell the program how many columns of numeric data to read. The numbers (actually only one here) with a dollar sign before them are character informats. They tell the program how many columns of character data to read. Note, that using a character informat in the INPUT statement also defines the storage length for that column.
A complete program to read the file Health.txt is shown next:
Figure 19: Reading Column Data

Notice one additional option (PAD) that was added to the INFILE statement. The PAD option is needed in case there are some short records in the file. The PAD option says to pad each record with blanks. For example, the line of data for subject 005 is missing a value for cholesterol, and there is a carriage return following the value for diastolic blood pressure (80). If you did not include the PAD option, the program would try to read a value for Chol starting in column 16. This would cause a serious error.
If you have short records and you do not use the PAD option, SAS will go to the next line to read values. The only way you will know this happened is to read the SAS log and see a note that says that SAS went to a new line.
You can read more about the INPUT statement in An Introduction to SAS University Edition (Cody) and Learning SAS by Example (Cody), both published by SAS Press.
Conclusions
If you always have data in a standard format such as Excel workbooks, CSV files (with column headings in the first row), or other data types that the Import Utility can read directly, you could have skipped most or all of this chapter. However, there are two good reasons why it was worth your time reading this chapter. First, you now have the tools to read almost any type of raw data file. Second, you now know a little bit about SAS programming and how to use the Code window to write SAS programs.
Even though the Statistics Tasks built into SAS Studio can perform just about any statistical test that you may need, there will be times when you need to manipulate the data or tweak the SAS procedures written by SAS Studio to obtain your result.
Problems
4-1: Write a short DATA step to read the text file Diabetes_No_Varnames.csv and create a temporary SAS data set called Diabetes. The data in this file is the same as the data in the Diabetes.xls file except that the first row does not contain variable (column) names. Use the names Insulin, Subj, Diet_Drinks, and Glucose for the variables. You may decide to make the variable Subj character or numeric, your choice. Use a LENGTH statement to set a length of 1 for the variable Insulin and a length of 9 for Diet_Drinks.
Hint: your INFILE statement should read:
Infile '/folders/myfolders/problems/Diabetes_No_Varnames.csv' DSD;
4-2: The file Diabetes.txt is a text file with the following layout:
| Column Name | Starting Column | Length | Type |
| Subj | 1 | 2 | Character |
| Insulin | 3 | 1 | Character |
| Diet_Drinks | 4 | 9 | Character |
| Glucose | 13 | 3 | Numeric |
Write a DATA step to read this text file and create a temporary SAS data set called Diabetes. Hint:
Your INFILE statement should read:
infile '/folders/myfolders/problems/Diabetes.txt' pad;
4-3: (Advanced) The file Blood_Pressure.txt is a tab-delimited file that contains these variables:
| Column Name | Type | Maximum Length |
| Drug | Character | 7 |
| Subj | Numeric | |
| Gender | Character | 1 |
| SBP | Numeric | |
| DBP | Numeric |
The first row does not contains column names. Also, two tabs together indicate a missing value (hint DSD option).
Here are the first few rows of the file (remember, the delimiter is a tab—not multiple spaces):
Placebo 1 F 138 86
Placebo 2 M 124 82
Placebo 3 F 150 72
Placebo 4 136 84
Placebo 5 F
Placebo 6 M 132 84
Write a DATA step to read this file and create a temporary SAS data set called Blood_Pressure. Remember that a tab is represented by the Hexidecimal constant '09'x. Make sure that the length for the character variables matches the maximum length in the table above.
Use the List data task to list the first 10 rows of this table.