
Example of the Prediction Profiler
This example uses the Tiretread.jmp sample data table. There are three factors (SILICA, SILANE, and SULFUR) and four responses (ABRASION, MODULUS, ELONG, and HARDNESS). The goal is to find the optimal combination of the three factors in the development of a tire tread compound. See Derringer and Suich (1980).
1. Select Help > Sample Data Library and open Tiretread.jmp.
2. Select Graph > Profiler.
3. Select Pred Formula Abrasion and click Y, Prediction Formula.
Figure 3.2 Completed Profiler Launch Window

4. Click OK.
Figure 3.3 Profiler Report Window

The profiler is interactive. The vertical red lines correspond to the current value of the factors. The current value of each factor is also shown in red below the horizontal axis. The red value on the vertical axis is the predicted response based on the current values of the factors. Click and drag the vertical red lines to change the current values of the factors. Click a factor’s red value to set the factor to a specific value. To maximize ABRASION, set all factors to their highest levels. For details about optimizing the response see “Desirability Profiling and Optimization”.
Launch the Prediction Profiler Platform
The Prediction Profiler can be accessed in the following ways:
• The Prediction Profiler can be accessed directly from the Graph menu. When you access the Prediction Profiler in this way, the Prediction Profiler launch window appears. See “Profiler Launch Windows” in the “Introduction to Profilers” chapter for details.
• The Prediction Profiler can be accessed as a red triangle menu option in many modeling platforms. See “Where to Find JMP Profilers” in the “Introduction to Profilers” chapter for details about the availability of the Prediction Profiler in different platforms.
• The Prediction Profiler can be accessed from the Model Comparisons platform. Select Profiler from the Model Comparisons red triangle menu.
•  The Prediction Profiler can be accessed from the Formula Depot platform. Select Profiler from the Formula Depot red triangle menu.
The Prediction Profiler can be accessed from the Formula Depot platform. Select Profiler from the Formula Depot red triangle menu.
Prediction Profiler Options
The red triangle menu on the Prediction Profiler title bar has the following options:
Optimization and Desirability
Submenu that consists of the following options:
Desirability Functions
Shows or hides the desirability functions. Desirability is discussed in “Desirability Profiling and Optimization”.
Maximize Desirability
Sets the current factor values to maximize the desirability functions. Takes into account the response importance weights.
Note: If a factor has a Design Role column property value of Discrete Numeric, it is treated as continuous in the optimization of the desirability function. To account for the fact that the factor can assume only discrete levels, it is displayed in the profiler as a categorical term and an optimal allowable level is selected.
Maximize and Remember
Maximizes the desirability functions and remembers the associated settings.
Maximization Options
Opens the Maximization Options window where you can refine the optimization settings.
Figure 3.4 Maximization Options Window

Maximize for Each Grid Point
Used only if one or more factors are locked. The ranges of the locked factors are divided into a grid, and the desirability is maximized at each grid point. This is useful if the model that you are profiling has categorical factors. Then the optimal condition can be found for each combination of the categorical factors.
Save Desirabilities
Saves the three desirability function settings for each response, and the associated desirability values, as a Response Limits column property in the data table. These correspond to the coordinates of the handles in the desirability plots.
Set Desirabilities
Opens the Response Goal window where you can set specific desirability values.
Figure 3.5 Response Goal Window

Save Desirability Formula
Creates a column in the data table with a formula for Desirability. The formula uses the fitting formula when it can, or the response variables when it cannot access the fitting formula.
Assess Variable Importance
Provides different approaches to calculating indices that measure the importance of factors to the model. These indices are independent of the model type and fitting method. Available only for continuous or binary responses. For details, see “Assess Variable Importance”.
Bagging
(Available only when the Prediction Profiler is embedded in certain modeling platforms.) Launches the Bagging window. Bootstrap aggregating (bagging) enables you to create multiple training data sets by sampling with replacement from the original data. For each training set, a model is fit using the analysis platform, and predictions are made. The final prediction is a combination of the results from all of the models. This improves prediction performance by reducing the error from variance. For details, see “Bagging”.
Simulator
Launches the Simulator. The Simulator enables you to create Monte Carlo simulations using random noise added to factors and predictions for the model. A typical use is to set fixed factors at their optimal settings, and uncontrolled factors and model noise to random values. You then find out the rate of responses outside the specification limits. For details, see the “Simulator” chapter.
Interaction Profiler
Shows or hides interaction plots that update as you update the factor values in the Profiler. Use this option to help visualize third degree interactions by seeing how the plot changes as current values for the factors change. The cells that change for a given factor are the cells that do not involve that factor directly.
Confidence Intervals
Shows or hides confidence intervals in the Profiler plot. The intervals are drawn by bars for categorical factors, and curves for continuous factors. These are available when the profiler is used inside certain fitting platforms or when a standard error column has been specified in the Profiler launch dialog.
Prop of Error Bars
(Appears when a Sigma column property exists in any of the factor and response variables.) This option displays the 3σ interval that is implied on the response due to the variation in the factor. Propagation of error (POE) is important when attributing the variation of the response in terms of variation in the factor values when the factor values are not very controllable. See “Propagation of Error Bars”.
Sensitivity Indicator
Shows or hides a purple triangle whose height and direction correspond to the value of the partial derivative of the profile function at its current value (see Figure 3.6). This is useful in large profiles to be able to quickly spot the sensitive cells.
Figure 3.6 Sensitivity Indicators

Profile at Boundary
When analyzing a mixture design, JMP constrains the ranges of the factors so that settings outside the mixture constraints are not possible. This is why, in some mixture designs, the profile traces turn abruptly.
When there are mixture components that have constraints, other than the usual zero-to-one constraint, a new submenu, called Profile at Boundary, appears on the Prediction Profiler red triangle menu. It has the following two options:
Turn At Boundaries
Lets the settings continue along the boundary of the restraint condition.
Stop At Boundaries
Truncates the prediction traces to the region where strict proportionality is maintained.
Reset Factor Grid
Displays a window for each factor enabling you to enter a specific value for the factor’s current setting, to lock that setting, and to control aspects of the grid. See the section “Set or Lock Factor Values” for details.
Figure 3.7 Factor Settings Window

Factor Settings
Submenu that consists of the following options:
Remember Settings
Adds an outline node to the report that accumulates the values of the current settings each time the Remember Settings command is invoked. Each remembered setting is preceded by a radio button that is used to reset to those settings.
Set To Data in Row
Assigns the values of a data table row to the X variables in the Profiler.
Copy Settings Script
Copies the current Profiler’s settings to the clipboard.
Paste Settings Script
Pastes the Profiler settings from the clipboard to a Profiler in another report.
Append Settings to Table
Appends the current profiler’s settings to the end of the data table. This is useful if you have a combination of settings in the Profiler that you want to add to an experiment in order to do another run.
Link Profilers
Links all the profilers together. A change in a factor in one profiler causes that factor to change to that value in all other profilers, including Surface Plot. This is a global option, set, or unset for all profilers.
Set Script
Sets a script that is called each time a factor changes. The set script receives a list of arguments of the form:
{factor1 = n1, factor2 = n2, ...}
For example, to write this list to the log, first define a function:
ProfileCallbackLog = Function({arg},show(arg));
Then enter ProfileCallbackLog in the Set Script dialog.
Similar functions convert the factor values to global values:
ProfileCallbackAssign = Function({arg},evalList(arg));
Or access the values one at a time:
ProfileCallbackAccess = Function({arg},f1=arg["factor1"];f2=arg["factor2"]);
Unthreaded
Enables you to change to an unthreaded analysis if multithreading does not work.
Default N Levels
Enables you to set the default number of levels for each continuous factor. This option is useful when the Profiler is especially large. When calculating the traces for the first time, JMP measures how long it takes. If this time is greater than three seconds, you are alerted that decreasing the Default N Levels speeds up the calculations.
Output Grid Table
Produces a new data table with columns for the factors that contain grid values, columns for each of the responses with computed values at each grid point, and the desirability computation at each grid point.
If you have a lot of factors, it is impractical to use the Output Grid Table command, because it produces a large table. A memory allocation message might be displayed for large grid tables. In such cases, you should lock some of the factors, which are held at locked, constant values. To get the window to specify locked columns, ALT- or Option-click inside the profiler graph to get a window that has a Lock Factor Setting check box.
Output Random Table
Prompts for a number of runs and creates an output table with that many rows, with random factor settings and predicted values over those settings. This is equivalent to (but much simpler than) opening the Simulator, resetting all the factors to a random uniform distribution, then simulating output. This command is similar to Output Grid Table, except it results in a random table rather than a sequenced one.
The prime reason to make uniform random factor tables is to explore the factor space in a multivariate way using graphical queries. This technique is called Filtered Monte Carlo.
Suppose you want to see the locus of all factor settings that produce a given range to desirable response settings. By selecting and hiding the points that do not qualify (using graphical brushing or the Data Filter), you see the possibilities of what is left: the opportunity space yielding the result that you want.
Some rows might appear selected and marked with a red dot. These represent the points on the multivariate desirability Pareto Frontier - the points that are not dominated by other points with respect to the desirability of all the factors.
Alter Linear Constraints
Enables you to add, change, or delete linear constraints. The constraints are incorporated into the operation of Prediction Profiler. See “Linear Constraints”.
Save Linear Constraints
Enables you to save existing linear constraints to a table script called Constraint. See“Linear Constraints”.
Conditional Predictions
Appears when random effects are included in the model. The random effects predictions are used in formulating the predicted value and profiles.
Appearance
Submenu that consists of the following options:
Arrange in Rows
Enter the number of plots that appear in a row. This option helps you view plots vertically rather than in one wide row.
Reorder X Variables
Opens a window where you can reorder the model main effects by dragging them to the desired order.
Reorder Y Variables
Opens a window where you can reorder the responses by dragging them to the desired order.
Adapt Y Axis
Re-scales the Y axis if the response is outside the axis range, so that the range of the response is included.
Desirability Profiling and Optimization
You can define a desirability function for a single response variable or for several response variables. When you are optimizing relative to several responses, there can often be competing criteria. For example, you might want to maximize one response, minimize another, and keep a third response close to some target value.
In desirability profiling, you specify a desirability function for each response. The overall desirability for all responses is defined as the geometric mean of the desirability functions for the individual responses. See Derringer and Suich (1980) for information about combining responses.
To use desirability profiling, select Optimization and Desirability > Desirability Functions from the Prediction Profiler red triangle menu.
Note: If the response column has a Response Limits property, desirability functions are turned on by default.
This command appends a new row to the bottom of the plot matrix, dedicated to graphing desirability. The row has a plot for each factor showing its desirability trace, as illustrated in Figure 3.8. It also adds a column that has an adjustable desirability function for each Y variable. The overall desirability measure shows on a scale of zero to one at the left of the row of desirability traces.
Figure 3.8 The Desirability Profiler
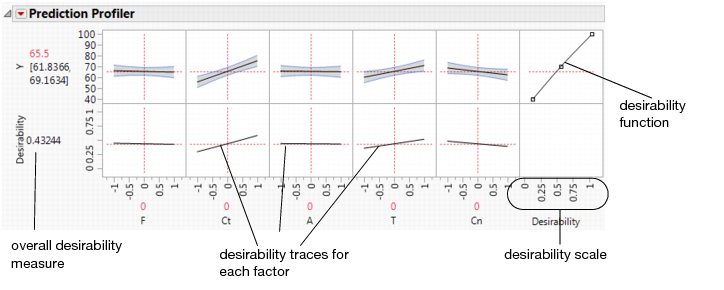
Construction of Desirability Functions
The individual desirability functions are smooth piecewise functions that are crafted to fit the control points.
• The Minimize and Maximize functions are three-part piecewise smooth functions that consist of interpolating cubics between the defining points (Low, Middle, High) and exponentials in the tails.
• The Target function is a piecewise function that is a scale multiple of a normal density on either side of the Middle value (with different curves on each side), which is also piecewise smooth and fit to the control points. Exponential functions are fit to the tails.
• The None function enables you to specify an arbitrary desirability function. In particular, you can specify desirability to be lower at the Middle value than at the Low and High values. You can also construct custom desirability functions using formulas. See “Customized Desirability Functions”.
The control points are not allowed to reach all the way to zero or one at the tail control points. This approach to constructing the desirability functions results in good behavior as the desirability values switch between the maximize, target, and minimize values.
Note: JMP does not use the Derringer and Suich (1980) functional forms. Because they are not smooth, they do not always work well with JMP’s optimization algorithm.
Desirability Function for Multiple Optimization
When multiple responses are to be optimized, an overall desirability function is constructed and optimized. The overall desirability for all responses is defined as the geometric mean of the desirability functions for the individual responses.
Denote the individual desirability functions for k responses by d1, d2, ..., dk. Then the overall desirability function is the geometric mean of the individual desirability functions:
If Importance values are defined as part of the Response Limits column property or are defined in the Response Goal window, they are integrated into the overall desirability function. The Importance values are scaled so that they sum to 1. Denote the scaled importance values by w1, w2, ..., wk. Then the overall desirability is defined as a weighted geometric mean of the individual desirability functions:
Optimization Algorithm
Optimization of the overall desirability function, or of the single desirability function if there is only one response, is conducted as follows.
• For categorical factors, a coordinate exchange algorithm is used.
• For continuous factors, a gradient descent algorithm is used.
• In the presence of constraints or mixture factors, a Wolfe reduced-gradient approach is used.
How to Use the Desirability Function
To use a variable’s desirability function, drag the function handles to represent a response value.
As you drag these handles, the changing response value shows in the area labeled Desirability to the left of the plots. The dotted line is the response for the current factor settings. The overall desirability shows to the left of the row of desirability traces. Alternatively, you can select Optimization and Desirability > Set Desirabilities to enter specific values for the points.
Figure 3.9 shows steps to create desirability settings.
Maximize
The default desirability function setting is maximize (“higher is better”). The top function handle is positioned at the maximum Y value and aligned at the high desirability, close to 1. The bottom function handle is positioned at the minimum Y value and aligned at a low desirability, close to 0.
Figure 3.9 Maximizing Desirability

Target
You can designate a target value as “best.” In this example, the middle function handle is positioned at Y = 70 and aligned with the maximum desirability of 1. Y becomes less desirable as its value approaches either 40 or 100. The top and bottom function handles at Y = 40 and Y = 100 are positioned at the minimum desirability close to 0.
Figure 3.10 Defining a Target Desirability

Minimize
The minimize (“smaller is better”) desirability function associates high response values with low desirability and low response values with high desirability. The curve is the maximization curve flipped around a horizontal line at the center of plot.
Figure 3.11 Minimizing Desirability

Note: Dragging the top or bottom point of a maximize or minimize desirability function across the y-value of the middle point results in the opposite point reflecting. A Minimize becomes a Maximize, and vice versa.
The Desirability Profile
The last row of plots shows the desirability trace for each factor. The numerical value beside the word Desirability on the vertical axis is the geometric mean of the desirability measures. This row of plots shows both the current desirability and the trace of desirabilities that result from changing one factor at a time.
For example, Figure 3.12 shows desirability functions for two responses. You want to maximize ABRASION and MODULUS. The desirability plots indicate that you could increase the desirability by increasing any of the factors.
Figure 3.12 Prediction Profile Plot with Adjusted Desirability and Factor Values

Customized Desirability Functions
It is possible to use a customized desirability function. For example, suppose you want to maximize using the following function.
Figure 3.13 Maximizing Desirability Based on a Function

First, create a column called Custom Desirability that contains the above formula. Then, select Graph > Profiler to launch the platform. Select all the Pred Formula columns and the Custom Desirability column and select Y, Prediction Formula. Turn on the desirability functions by selecting Optimization and Desirability > Desirability Functions from the red triangle menu. All the desirability functions for the individual effects must be turned off. To do this, first double-click in a desirability plot window, and then select None in the window that appears (Figure 3.14). Set the desirability for Custom Desirability to be maximized.
Figure 3.14 Selecting No Desirability Goal

At this point, selecting Optimization and Desirability > Maximize Desirability uses only the custom Custom Desirability function.
Figure 3.15 Maximized Custom Desirability

Assess Variable Importance
For continuous and binary responses, the Variable Importance report calculates indices that measure the importance of factors in a model in a way that is independent of the model type and fitting method. The fitted model is used only in calculating predicted values. The method estimates the variability in the predicted response based on a range of variation for each factor. If variation in the factor causes high variability in the response, then that effect is important relative to the model.
Note: Assess Variable Importance is not available for categorical responses with more than two levels.
Assess Variable Importance can also be accessed in the Profiler that is obtained through the Graph menu.
For statistical details, see “Assess Variable Importance”. See also Saltelli, 2002.
Note: Assess Variable Importance requires that all columns reside in the same data table.
The Assess Variable Importance Report
The Assess Variable Importance menu has the following options that address the methodology used in constructing importance indices:
Independent Uniform Inputs
For each factor, Monte Carlo samples are drawn from a uniform distribution defined by the minimum and maximum observed values. Use this option when you believe that your factors are uncorrelated and that their likely values are uniformly spread over the range represented in the study.
Independent Resampled Inputs
For each factor, Monte Carlo samples are obtained by resampling its set of observed values. Use this option when you believe that your factors are uncorrelated and that their likely values are not represented by a uniform distribution.
Dependent Resampled Inputs
Factor values are constructed from observed combinations using a k-nearest neighbors approach, in order to account for correlation. This option treats observed variance and covariance as representative of the covariance structure for your factors. Use this option when you believe that your factors are correlated. Note that this option is sensitive to the number of rows in the data table. If used with a small number of rows, the results can be unreliable.
Linearly Constrained Inputs
For each factor, Monte Carlo samples are drawn from a uniform distribution over a region defined by linear constraints. The linear constraints can be defined in the Profiler or constructed in connection with a designed experiment. In addition, the samples are restricted to fall within the minimum and maximum observed values. Use this option in the presence of linear constraints, when you believe that these constraints impact the distribution of the inputs.
The speed of these algorithms depends on the model evaluation speed. In general, the fastest option is Independent Uniform Inputs and the slowest is Dependent Resampled Inputs. You have the option to Accept Current Indices when the estimation process is unable to complete instantaneously.
Note: In the case of independent and linearly constrained inputs, variable importance indices are constructed using Monte Carlo sampling. For this reason, you can expect some variation in importance index values from one run to another.
Variable Importance Report
Each Assess Variable Importance option presents a Summary Report and Marginal Model Plots. When the Assess Variable Importance report opens, the factors in the Profiler are reordered according to their Total Effect importance indices. When there are multiple responses, the factors are reordered according to the Total Effect importance indices in the Overall report. When you run several Variable Importance reports, the factors in the Profiler are ordered according to their Total Effect indices in the most recent report.
Summary Report
For each response, a table displays the following elements:
Column
The factor of interest.
Main Effect
An importance index that reflects the relative contribution of that factor alone, not in combination with other factors.
Total Effect
An importance index that reflects the relative contribution of that factor both alone and in combination with other factors. The Total Effect column is displayed as a bar chart. See “Weights”.
Main Effect Std Error
The Monte Carlo standard error of the Main Effect’s importance index. This is a hidden column that you can access by right-clicking in the report and selecting Columns > Main Effect Std Error. By default, sampling continues until this error is less than 0.01. Details of the calculation are given in “Variable Importance Standard Errors”. (Not available for Dependent Resampled Inputs option.)
Total Effect Std Error
The Monte Carlo standard error of the Total Effect’s importance index. This is a hidden column that you can access by right-clicking in the report and selecting Columns > Total Effect Std Error. By default, sampling continues until this error is less than 0.01. Details of the calculation are given in “Variable Importance Standard Errors”. (Not available for Dependent Resampled Inputs option.)
Weights
A plot that shows the Total Effect indices, located to the right of the final column. You can deselect or reselect this plot by right-clicking in the report and selecting Columns > Weights.
Proportion of function evaluations with missing values
The proportion of Monte Carlo samples for which some combination of inputs results in an inestimable prediction. When the proportion is nonzero, this message appears as a note at the bottom of the table.
Note: When you have more than one response, the Summary Report presents an Overall table followed by tables for each response. The importance indices in the Overall report are the averages of the importance indices across all responses.
Marginal Model Plots
The Marginal Model Plots report (see Figure 3.35) shows a matrix of plots, with a row for each response and columns for the factors. The factors are ordered according to the size of their overall Total Effect importance indices.
For a given response and factor, the plot shows the mean response for each factor value, where that mean is taken over all inputs to the calculation of importance indices. These plots differ from profiler plots, which show cross sections of the response. Marginal Model Plots are useful for assessing the main effects of factors.
Note that your choice of input methodology impacts the values plotted on marginal model plots. Also, because the plots are based on the generated input settings, the plotted mean responses might not follow a smooth curve.
The red triangle options enable you to show or hide the following aspects of the plots:
Estimate
A smoothed estimate of the mean of the simulated values calculated as a function of the factor values.
Note: The estimates of the mean are simulated, so the values change when you rerun the analysis.
Confidence Interval
A 95% confidence band for the simulated means. This band is often narrow and might not be visible unless you expand the scale. Not available for Dependent Resampled Inputs.
Note: The confidence bounds are simulated, so the bands change when you rerun the analysis.
Data
The actual (unsimulated) values of the response plotted against the factor values.
Variable Importance Options
The Variable Importance report has the following red triangle options:
Reorder factors by main effect importance
Reorders the cells in the Profiler in accordance with the importance indices for the main effects (Main Effect).
Reorder factors by total importance
Reorders the cells in the Profiler in accordance with the total importance indices for the factors (Total Effect).
Colorize Profiler
Colors cells in the profiler by Total Effect importance indices using a red to white intensity scale.
Note: You can click rows in the Summary Report to select columns in the data table. This can facilitate further analyses.
Bagging
Bootstrap aggregating (bagging) is a technique to improve predictive performance while also gaining insight into the reliability of predictions. Bagging is especially useful in unstable methods, including neural networks, classification trees, and regression trees.
Bagging creates M training data sets by sampling with replacement from the original data. All training data sets are of the same size as the original. For each training data set, a model is fit using the analysis platform, and predictions are made. Therefore, there are a total of M predictions for each observation in the original data set. The final prediction is the average of the M predictions.
Bagging is available in many analysis platforms. To use bagging, select Save Bagged Predictions from the Prediction Profiler red triangle menu. A window appears with the following options for Bagging:
Number of Bootstrap Samples
Sets the number of times that you want to resample the data and build a model. A larger number results in more precise predictions. By default, the number of bootstrap samples is 100.
Random Seed
Sets a random seed that you can re-enter in subsequent runs of the bagging analysis to duplicate your current results. By default, no seed is set.
Fractional Weights
Performs a Bayesian bagging analysis. In each bootstrap iteration, each observation is assigned a nonzero weight. The model that makes the predictions uses the weighted observations. By default, the Fractional Weights option is not selected, and a simple bagging analysis is conducted.
Tip: Use the Fractional Weights option if the number of observations that are used in your analysis is small or if you are concerned about separation in a logistic regression setting.
Suppose that Fractional Weights is selected. For each bootstrap iteration, each observation that is used in the report is assigned a nonzero weight. These weights sum to n, the number of observations used in the model. For more information about how the weights are calculated and used, see “Calculation of Fractional Weights” in the “Bootstrapping” chapter.
Save Prediction Formulas
For each bagged prediction, this option saves the formula used to make that prediction in the column properties. This option is available in only a subset of the analysis platforms that offer bagging.
Bagging automatically creates new columns in the original data table. All M sets of bagged predictions are saved as hidden columns. The final prediction is saved in a column named “Pred Formula <colname> Bagged Mean”. The standard deviation of the final prediction is saved in a column named “<colname> Bagged Std Dev”. The standard error of the bagged mean is saved in a column named “StdError <colname> Bagged Mean.” The standard error is the standard deviation divided by  . Here, <colname> identifies the column in the report that was bagged.
. Here, <colname> identifies the column in the report that was bagged.
The standard error gives insight about the precision of the prediction. A very small standard error indicates a precise prediction for that observation. For more information about bagging, see Hastie et al. (2009).
Figure 3.16 Bagging Columns

Additional Examples of the Prediction Profiler
This section contains additional examples illustrating various aspects of the Prediction Profiler platform and the Prediction Profiler embedded in many analysis platforms.
Example of Desirability Profiling for Multiple Responses
A desirability index becomes especially useful when there are multiple responses. The idea was pioneered by Derringer and Suich (1980), who give the following example. Suppose there are four responses, ABRASION, MODULUS, ELONG, and HARDNESS. Three factors, SILICA, SILANE, and SULFUR, were used in a central composite design.
The data are in the Tiretread.jmp table in the sample data folder. Use the RSM For 4 responses script in the data table, which defines a model for the four responses with a full quadratic response surface. The summary tables and effect information appear for all the responses, followed by the prediction profiler shown in Figure 3.17. The desirability functions are as follows:
1. Maximum ABRASION and maximum MODULUS are most desirable.
2. ELONG target of 500 is most desirable.
3. HARDNESS target of 67.5 is most desirable.
Figure 3.17 Profiler for Multiple Responses before Optimization
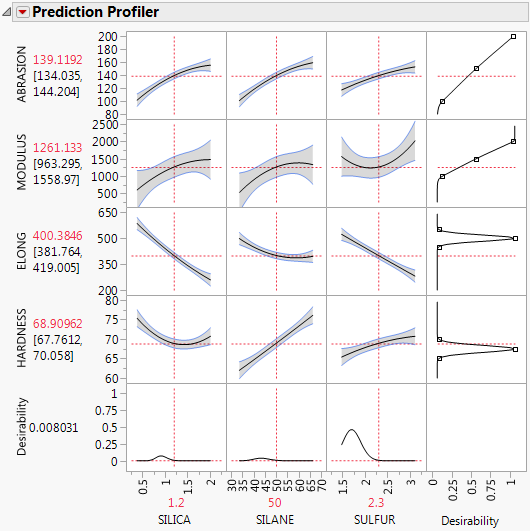
Select Optimization and Desirability > Maximize Desirability from the Prediction Profiler red triangle menu to maximize desirability. The results are shown in Figure 3.18. The desirability traces at the bottom decrease everywhere except the current values of the effects, which indicates that any further adjustment could decrease the overall desirability.
Figure 3.18 Profiler after Optimization

Example of a Noise Factor in the Prediction Profiler
As an example, use the Tiretread.jmp sample data set. This data set shows the results of a tire manufacturer’s experiment whose objective is to match a target value of HARDNESS= 70 based on three factors: SILICA, SILANE, and SULFUR content. Suppose the SILANE and SULFUR content are easily (and precisely) controllable, but SILICA expresses variability that is worth considering.
For comparison, first optimize the factors for hardness without considering variation from the noise factor.
1. Select Graph > Profiler to launch the Profiler.
2. Assign Pred Formula HARDNESS to the Y, Prediction Formula role.
3. Click OK.
4. Select Optimization and Desirability > Desirability Functions in the Prediction Profiler menu.
5. Double-click in the Desirability plot to open the Response Goal window. Select Match Target from the list.
6. Select Optimization and Desirability > Maximize Desirability to find the optimum factor settings for our target value of HARDNESS.
We get the following Profiler display. Notice that the SILICA factor’s optimum value is on a sloped part of a profile curve. This means that variations in SILICA are transmitted to become variations in the response, HARDNESS.
Note: You might get different results from these because different combinations of factor values can all hit the target.
Figure 3.19 Maximizing Desirability for HARDNESS

Now, we would like to not just optimize for a specific target value of HARDNESS, but also be on a flat part of the curve with respect to Silica. So, repeat the process and add SILICA as a noise factor.
1. Select Graph > Profiler.
2. Select Pred Formula HARDNESS and click Y, Prediction Formula.
3. Select SILICA and click Noise Factors.
4. Click OK.
5. Change the Pred Formula Hardness desirability function as before.
The resulting profiler has the appropriate derivative of the fitted model with respect to the noise factor, set to be maximized at zero, its flattest point.
Figure 3.20 Derivative of the Prediction Formula with Respect to Silica

6. Select Optimization and Desirability > Maximize Desirability to find the optimum values for the process factor, balancing for the noise factor.
This time, we have also hit the targeted value of HARDNESS, but our value of SILICA is on its flatter region. This means variation in SILICA does not transmit as much variation to HARDNESS.
Figure 3.21 Maximize Desirability

You can see the effect this has on the variance of the predictions by following these steps for each profiler (one without the noise factor, and one with the noise factor):
1. Select Simulator from the platform menu.
2. Assign SILICA to have a random Normal distribution with a standard deviation of 0.05.
Figure 3.22 Setting a Random Normal Distribution

3. Click Simulate.
4. Click the Make Table button under the Simulate to Table node.
Doing these steps for both the original and noise-factor-optimal simulations results in two similar data tables, each holding a simulation. In order to make two comparable histograms of the predictions, we need the two prediction columns in a single data table.
5. Copy the Pred Formula HARDNESS column from one of the simulation tables into the other table. They must have different names, like Without Noise Factor and With Noise Factor.
6. Select Analyze > Distribution and assign both prediction columns as Y.
7. When the histograms appear, select Uniform Scaling from the Distribution main title bar.
Figure 3.23 Comparison of Distributions with and without Noise Factors

The histograms show that there is much more variation in Hardness when the noise factor was not included in the analysis.
It is also interesting to note the shape of the histogram when the noise factor was included. In the comparison histograms above, note that the With Noise Factor distribution has data trailing off in only one direction. The predictions are skewed because Hardness is at a minimum with respect to SILICA, as shown in Figure 3.24. Therefore, variation in SILICA can make only HARDNESS increase. When the non-robust solution is used, the variation could be transmitted either way.
Figure 3.24 Profiler Showing the Minima of HARDNESS by SILICA

Example of Variable Importance for One Response
The Boston Housing.jmp sample data table contains data on 13 factors that might relate to median home values. You fit a model using a neural network. Because neural networks do not accommodate formal hypothesis tests, these tests are not available to help assess which variables are important in predicting the response. However, for this purpose, you can use the Assess Variable Importance profiler option.
Note that your results might differ from, but should resemble, those shown here. There are two sources of random variability in this example. When you fit the neural network, k-fold cross validation is used. This partitions the data into training and validation sets at random. Also, Monte Carlo sampling is used to calculate the factor importance indices.
1. Select Help > Sample Data Library and open Boston Housing.jmp.
2. Select Analyze > Predictive Modeling > Neural.
3. Select mvalue from the Select Columns list and click Y, Response.
4. Select all other columns from the Select Columns list and click X, Factor.
5. Click OK.
6. In the Neural Model Launch panel, select KFold from the list under Validation Method.
When you select KFold, the Number of Folds defaults to 5.
7. Click Go.
8. From the red triangle menu for the Model NTanH(3) report, select Profiler.
The Prediction Profiler is displayed at the very bottom of the report. Note the order of the factors for later comparison.
Because the factors are correlated, you take this into account by choosing Dependent Resampled Inputs as the sampling method for assessing variable importance.
9. From the red triangle menu next to Prediction Profiler, select Assess Variable Importance > Dependent Resampled Inputs.
The Variable Importance: Dependent Resampled Inputs report appears (Figure 3.25). Check that the Prediction Profiler cells have been reordered by the magnitude of the Total Effect indices in the report. In Figure 3.25, check that the Total Effect importance indices identify rooms and lstat as the factors that have most impact on the predicted response.
Figure 3.25 Dependent Resampled Inputs Report

You might be interested in comparing the importance indices obtained assuming that the factors are correlated, with those obtained when the factors are assumed independent.
10. From the red triangle menu next to Prediction Profiler, select Assess Variable Importance > Independent Resampled Inputs.
The resampled inputs option makes sense in this example, because the distributions involved are not uniform. The Variable Importance: Independent Resampled Inputs report is shown in Figure 3.26. Check that the two factors identified as having the most impact on the predicted values are lstat and rooms. Note that the ordering of their importance indices is reversed from the ordering using Dependent Resampled Inputs.
Figure 3.26 Independent Resampled Inputs Report

Example of Variable Importance for Multiple Responses
The data in the Tiretread.jmp sample data table are the result of a designed experiment where the factors are orthogonal. For this reason, you use importance estimates based on independent inputs. Suppose that you believe that, in practice, factor values vary throughout the design space, rather than assume only the settings defined in the experiment. Then you should choose Independent Uniform Inputs as the sampling scheme for your importance indices.
1. Select Help > Sample Data Library and open Tiretread.jmp.
2. Run the script RSM for 4 Responses.
The Prediction Profiler is displayed at the very bottom of the report.
3. From the red triangle menu next to Prediction Profiler, select Assess Variable Importance > Independent Uniform Inputs.
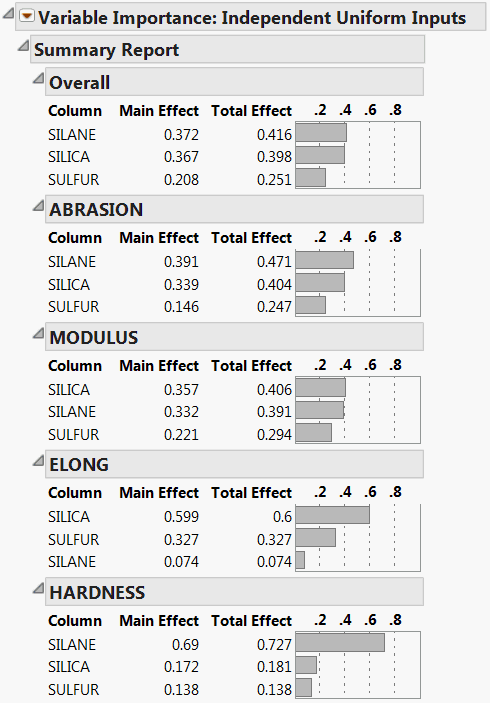
The Summary Report is shown in Figure 3.27. Because the importance indices are based on random sampling, your estimates might differ slightly from those shown in the figure.
The report shows tables for each of the four responses. The Overall table averages the factor importance indices across responses. The factors in the Profiler (Figure 3.28) have been reordered to match their ordering on the Overall table’s Total Effect importance.
Figure 3.27 Summary Report for Four Responses
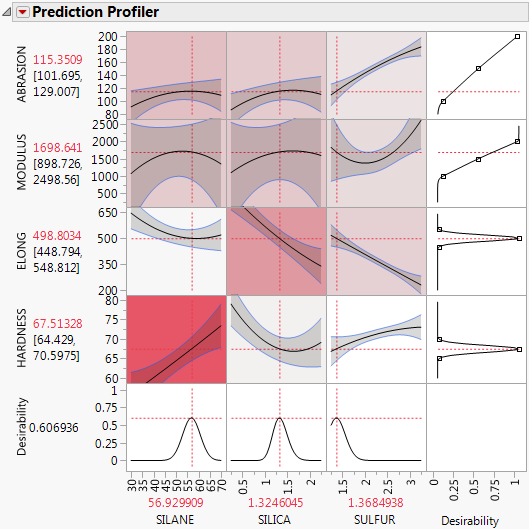
4. From the red triangle menu next to Variable Importance: Independent Uniform Inputs, select Colorize Profiler.
Colors from a red to white intensity scale are overlaid on profiler panels to reflect Total Effect importance. For example, you easily see that the most important effect is that of Silane on Hardness.
Figure 3.28 Profiler for Four Responses
The Marginal Model Plots report (Figure 3.29) shows mean responses for each factor across a uniform distribution of settings for the other two factors.
Figure 3.29 Marginal Model Plots for Four Responses

Example of Bagging to Improve Prediction
Bagging is used in a number of situations, one of which is improving predictive power. Bagging is especially helpful for unstable models. This example uses the Tiretread.jmp sample data table. There are three factors (SILICA, SILANE, and SULFUR) and four responses (ABRASION, MODULUS, ELONG, and HARDNESS). First, you fit a neural network model to simultaneously predict the four response variables as a function of the three factors. Then, you perform bagging on the neural network model. Last, you compare the predictions to show the improvements obtained through bagging.
Fit Neural Network Model
1. Select Help > Sample Data Library and open Tiretread.jmp.
2. Select Analyze > Predictive Modeling > Neural.
3. Select ABRASION, MODULUS, ELONG, and HARDNESS and click Y, Response.
4. Select SILICA, SILANE, and SULFUR and click X, Factor.
5. Click OK.
6. (Optional) Enter 2121 next to Random Seed.
Note: Results vary due to the random nature of choosing a validation set in the Neural Network model. Entering the seed above enables you to reproduce the results shown in this example.
7. Click Go.
8. Select Save Formulas from the red triangle menu next to Model NTanH(3).
Note: This option saves the predicted values for all response variables from the neural network model to the data table. Later, these values are compared to the predictions that are obtained from bagging.
Perform Bagging
Now that the initial model has been constructed, you can perform bagging using that model. Access the Bagging feature through the Profiler.
1. From the red triangle menu next to Model NTanH(3), select Profiler.
The Prediction Profiler appears at the bottom of the report.
2. From the red triangle menu next to Prediction Profiler, select Save Bagged Predictions.
3. Enter 100 next to Number of Bootstrap Samples.
4. (Optional) Enter 2121 next to Random Seed.
Note: Results vary due to the random nature of sampling with replacement. To reproduce the exact results in this example, set the Random Seed.
5. Click OK.
Return to the data table. For each response variable, there are three new columns denoted as Pred Formula <colname> Bagged Mean, StdError <colname> Bagged Mean, <colname> Bagged Std Dev. The Pred Formula <colname> Bagged Mean columns are the final predictions.
Figure 3.30 Columns Added to Data Table After Bagging

Compare the Predictions
To see how bagging improves predictive power, compare the predictions from the bagged model to the original model predictions. Use the Model Comparison platform to look at one response variable at a time.
1. Select Analyze > Predictive Modeling > Model Comparison.
2. Select Predicted ABRASION and click Y, Predictors.
3. Select Pred Formula ABRASION Bagged Mean and click Y, Predictors.
4. Click OK.
A window that contains a list of columns appears.
5. Select ABRASION and click OK.
6. From the red triangle menu next to Model Comparison, select Plot Actual by Predicted.
Figure 3.31 Comparison of Predictions for ABRASION

The Measures of Fit report and the Actual by Predicted Plot are shown in Figure 3.31. The predictions that were obtained from bagging are shown in blue. The predictions that were obtained from the original neural network model are shown in red. In general, the bagging predictions are closer to the line than the original model predictions. Because the bagging predictions are closer to the line, the RSquare value of 0.6699 for the bagged predictions is higher than the RSquare value for the original model predictions. You conclude that bagging has improved predictions for ABRASION.
This example compared the predictions for ABRASION. To compare predictions for another response variable, follow step 2 through step 6, replacing ABRASION with the desired response variable. As another example, Figure 3.32 shows the Measures of Fit report for HARDNESS. The report shows similar findings as the Measures of Fit report for ABRASION. The RSquare value for the bagged predictions is slightly higher than the RSquare value for the original model predictions, which indicates a better fit and improved predictions.
Figure 3.32 Comparison of Predictions for HARDNESS

Example of Bagging to Indicate the Accuracy of Predictions
Bagging is also used to indicate the accuracy of the prediction through standard errors and other distributional measures. In platforms where the Save Predicted Formulas option is available in Bagging, you can make predictions on new observations and determine how accurate they are. The Save Predicted Formulas option is available in the Standard Least Squares, Generalized Regression, and Generalized Linear Models platforms.
In the Tiretread.jmp data table, suppose that you are interested in only predicting ABRASION as a function of the three factor variables. In this example, you fit a generalized regression model to predict ABRASION. Then, you perform bagging on that model. Last, you make a prediction for a new observation and investigate the accuracy of that prediction. This is done by obtaining a confidence interval for the prediction.
Fit a Generalized Regression Model
1. Select Help > Sample Data Library and open Tiretread.jmp.
2. Select Analyze > Fit Model.
3. Select ABRASION and click Y.
4. Select Generalized Regression from the Personality list.
5. Select SILICA, SILANE, and SULFUR and click Add.
6. Click Run.
7. Click Go.
Perform Bagging
1. Select Profilers > Profiler from the red triangle menu next to Adaptive Lasso with AICc Validation.
The Prediction Profiler appears at the bottom of the report.
2. From the red triangle menu next to Prediction Profiler, select Save Bagged Predictions.
3. Enter 500 next to Number of Bootstrap Samples.
4. (Optional) Enter 4321 next to Random Seed.
Note: Results vary due to the random nature of sampling with replacement. To reproduce the exact results in this example, set the Random Seed.
5. Confirm that Save Prediction Formulas is selected.
6. Click OK.
Note: This might take longer to run than the “Example of Bagging to Improve Prediction”. The larger number of samples gives a better estimate of the prediction distributions.
Return to the data table. For each response variable, there are three new columns denoted as Pred Formula <colname> Bagged Mean, StdError <colname> Bagged Mean, <colname> Bagged Std Dev. The Pred Formula ABRASION Bagged Mean column is the final prediction.
Prediction for a New Observation
You now have predictions for ABRASION for each observation in the data table, as well as the standard errors for those predictions. Suppose that you have an observation with new values of 0.9, 43, and 2 for SILICA, SILANE, and SULFUR, respectively. You can predict the ABRASION response and obtain a confidence interval for that prediction because the Save Prediction Formulas option saves the regression equation for each bagged model. Therefore, M predictions are made with the new factor values to create a distribution of possible predictions. The mean is the final prediction, but analyzing the distribution tells you how accurate the prediction is.
1. In the data table, select Rows > Add Rows.
2. Enter 1 in the How many rows to add box and click OK.
3. Under the SILICA column, type 0.9 in the box for the new row.
4. Under the SILANE column, type 43 in the box for the new row.
5. Under the SULFUR column, type 2 in the box for the new row.
The prediction columns for the new row are automatically calculated.
Figure 3.33 Values for New Row

6. Select Tables > Transpose.
7. Select ABRASION Bags (500/0) and click Transpose Columns.
8. Click OK.
9. Select Analyze > Distribution.
10. Select Row 21 and click Y, Columns.
Note: Row 21 corresponds to the predictions from the new observation.
11. Click OK.
12. From the red triangle menu next to Row 21, select Display Options > Horizontal Layout.
Figure 3.34 Distribution Report

The Distribution Report in Figure 3.34 contains information about the distribution of the predicted values of ABRASION from each bagged model. The final prediction of ABRASION for the new observation is 104.45, which is the mean of all the M bagged predictions. This prediction has a standard error of 4.56. You can also create confidence intervals for the new prediction using the quantiles. For example, a 95% confidence interval for the new prediction is 95.89 to 113.00.
Statistical Details for the Prediction Profiler
This section contains statistical details for options available in the Prediction Profiler platform.
Assess Variable Importance
The details that follow relate to the how the variable importance indices are calculated.
Background
Denote the function that represents the predictive model by f, and suppose that x1, x2, ..., xn are the factors, or main effects, in the model. Let y = f(x1, x2 ..., xn).
• The expected value of y, E(y), is defined by integrating y with respect to the joint distribution of x1, x2, ..., xn.
• The variance of y, Var(y), is defined by integrating (y – E(y))2with respect to the joint distribution of x1, x2, ..., xn.
Main Effect
The impact of the main effect xj on y can be described by Var(E(y |xj)). Here the expectation is taken with respect to the conditional distribution of x1, x2, ..., xn given xj, and the variance is taken over the distribution of xj. In other words, Var(E(y |xj)) measures the variation, over the distribution of xj, in the mean of y when xj is fixed.
It follows that the ratio Var(E(y |xj))/Var(y) gives a measure of the sensitivity of y to the factor xj. The importance index in the Main Effect column in the Summary Report is an estimate of this ratio (see “Adjustment for Sampling Variation”).
Total Effect
The Total Effect column represents the total contribution to the variance of y = f(x1, x2 ..., xn) from all terms that involve xj. The calculation of Total Effect depends on the concept of functional decomposition. The function f is decomposed into the sum of a constant and functions that represent the effects of single variables, pairs of variables, and so on. These component functions are analogous to main effects, interaction effects, and higher-order effects. (See Saltelli, 2002, and Sobol, 1993.)
Those component functions that include terms containing xj are identified. For each of these, the variance of the conditional expected value is computed. These variances are summed. The sum represents the total contribution to Var(y) due to terms that contain xj . For each xj , this sum is estimated using the selected methodology for generating inputs. The importance indices reported in the Total Effect column are these estimates (see “Adjustment for Sampling Variation”).
Consider a simple example with two factors, x1 and x2. Then the Total Effect importance index for x1 is an estimate of:
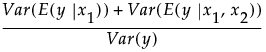
Adjustment for Sampling Variation
Due to the fact that they are obtained using sampling methods, the Main Effect and Total Effect estimates shown in the Summary Table might have been adjusted. Specifically, if the Total Effect estimate is less than the Main Effect estimate, then the Total Effect importance index is set equal to the Main Effect estimate. If the sum of the Main Effect estimates exceeds one, then these estimates are normalized to sum to one.
Variable Importance Standard Errors
The standard errors that are provided for independent inputs measure the accuracy of the Monte Carlo replications. Importance indices are computed as follows:
• Latin hypercube sampling is used to generate a set of data values.
• For each set of data values, main and total effect importance estimates are calculated.
• This process is replicated until the estimated standard errors of the Main Effect and Total Effect importance indices for all factors fall below a threshold of 0.01.
The standard errors that are reported are the standard error values in effect when the replications terminate.
Propagation of Error Bars
Propagation of error (POE) is important when attributing the variation of the response in terms of variation in the factor values when the factor values are not very controllable.
In JMP’s implementation, the Profiler first looks at the factor and response variables to see whether there is a Sigma column property (a specification for the standard deviation of the column, accessed through the Cols > Column Info dialog box). If the property exists, then the Prop of Error Bars command becomes accessible in the Prediction Profiler drop-down menu. This displays the 3σ interval that is implied on the response due to the variation in the factor.
Figure 3.35 Green Propagation of Errors Bars in the Prediction Profiler

The POE is represented in the graph by a green bracket. The bracket indicates the prediction plus or minus three times the square root of the POE variance. The POE variance can be expressed as:

where σy is the user-specified sigma for the response column, and σx is the user-specified sigma for the factor column.
Currently, these partial derivatives are calculated by numerical derivatives:
centered, with δ=xrange/10000
POE limits increase dramatically in response surface models when you are over a more sloped part of the response surface. One of the goals of robust processes is to operate in flat areas of the response surface so that variations in the factors do not amplify in their effect on the response.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.