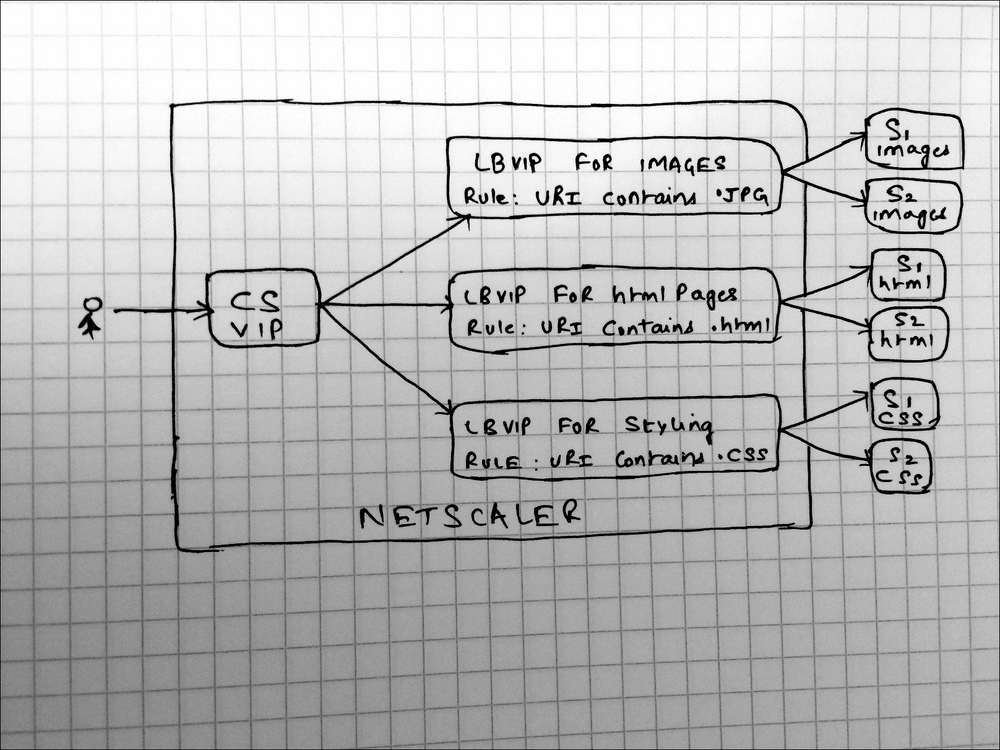
In this section, we will look at troubleshooting Content Switching. CS, as it is called in short, can be thought of as the single IP face of an infrastructure that is large and complex in the background. The idea is to have the CS vServer use Administrator configured rules to choose target LB vServers that each handle load balance for a particular type of content. The rules are the main value offered here as they can get very granular in identifying minute differences between two requests.
As such, troubleshooting CS in the vast majority of cases comes down to verifying two things:
- You have the right policies in place
- The LB vServers that are bound are up
I have a CS VIP (cs-vip) that choses either the vServer base-vip, containing only HTML, or the vServer image-vip, containing only images by looking at the URL.

I try to access the VIP, and instead of the page with images that I expected to see, I land on a Service Unavailable error.

Now, let's investigate. As a first check, I verify that my VIP is active.

Then, a quick look at a trace shows a 503 error. In http, all 500 series errors indicate a failure on the part of the server.

Looking at the trace, however, the response is coming directly from the NetScaler, notice that there are no server side packets. This implies that NetScaler is the source of the 503 errors. This will happen when the NetScaler encounters a request for which there are no matching rules. Here, the base page / doesn't have an .htm, .jpg, or .png extension. The key is thus to have a rule for every occasion.
We might not be able to foresee every single extension there is on the site. So it is important to have a default LB vServer that catches all exceptions. I proceed to add a default LB vServer that catches this request, and now the page loads without an error.

We can also encounter content switching timeout errors that are not related to configuration.

From the error, I can already tell that this is a low-level failure, since the connection timed out. Logically, I proceed to check the status of my CS VIP, which shows no problems.

In fact, I can even ping it:

Given the experience from the previous issue, I verify the policies, which seem to be all okay, and proceed to take a trace. On filtering the trace with the Client IP, we see the problem. There is no response to the TCP connection requests.

Since the CS vServer is up, we turn our attention to the backend servers for this CS VIP, that is, the LB vServers. Here, we see the problem, the VIPs are all down, including the base-vip, which is my catch-all.

So why is the content switching vServer not alerting us to this by changing its state to down? The answer to this puzzle lies in the –stateupdate parameter; by default, it is disabled.