
HA Failover-related issues are generally considered to be very serious. There are broadly of four types:
- HA node state issues
- Heartbeats not being seen
- New primary not handling traffic
- Sync and propagation issues
Let's take a look at these one by one.
Sometimes when you do a show node, you might see the status Not UP. This means the node is not ready to process traffic, if it were to become primary. This can be because of the following reasons:
- Critical interfaces are down
- The SSL card is down
- High Availability is disabled (on the remote node)
- The unit is still booting up or rebooting
There is a very handy list of the various node states and what they mean in article CTX118519. I sourced the following tables from the article as they will greatly help with understanding what the Node state is complaining about.
Node States seen on Primary:
|
Value |
Meaning |
|---|---|
|
|
The appliance is initializing. |
|
|
The appliance is working as expected. |
|
|
One or more interfaces on which |
|
|
All the interfaces of the appliance are not working. |
|
|
The |
Node States seen on Secondary:
|
Value |
Meaning |
|---|---|
|
|
This is the receipt of the message stating that the peer is initializing. |
|
|
This is the receipt of the message stating that the peer is working as expected. |
|
|
This is the receipt of the message stating that one or more interfaces of the peer on which |
|
|
If the appliance is not working, then the peer stat is unknown. |
|
|
The monitoring failed on all links of the peer node. |
Source: Citrix Knowledge Base
Heartbeats, which use UDP port 3003, are used by each NetScaler in the pair to let the peer know how they are doing. You can spot them in a Wireshark trace by using the filter udp.port==3003, as shown by the following screenshot:

The default rate of heartbeats is 5 per interface per second. This can be changed by adjusting the Hello Interval:
The dead interval specifies when a secondary unit should take over. The default is 3 seconds. In other words, missing 15 heartbeats in succession on an interface marked as critical will result in a Failover. In the following screenshot, pay attention to interfaces causing partial failure in the show node output:
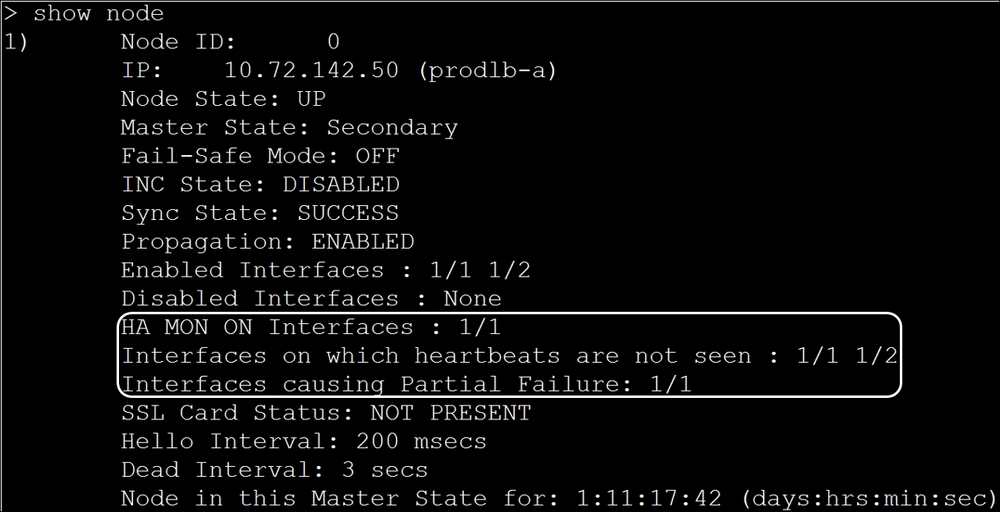
This will list any interfaces that NetScaler deems as critical, but doesn't see heartbeats on. In the above image, the node is in a secondary state after failing over because it's not seeing heartbeats on 1/1, which has HA monitoring enabled on it.
NetScaler will also complain about missing heartbeats on interfaces that are enabled but not plugged in. A common misconception about heartbeats is that they are only sent on interfaces with HAMON enabled, which isn't true. Heartbeats are sent on all enabled interfaces and are expected on all enabled interfaces. So, the correct way to remedy the heart beats not seen error on an unused interface is to disable the interface.
The shell command nsconmsg –g ha_tot_pkt –d current shows you the number of heartbeat packets sent and received, as shown in the following screenshot:

Using nsconmsg to verify HA heartbeat exchange
Note
Sometimes the heartbeats are not received because the peer unit has crashed. If this crash happens on the primary, a Failover will result. Crashes are discussed in the Chapter 8, System-Level Issues.
When a Failover does happen, you can identify timelines and why the Failover happened by looking at the events. There are various ways to get this information:


VLAN issues are a common reason for heartbeats to not be seen. Let's look at some important points about VLANs in the context of heartbeats:
- Heartbeats are by default sent untagged and use the
NSVLAN, which by default is1. - The untagged command is important to note, as it means that for heartbeats to work properly by default, the switch needs to accept untagged traffic, and some switches might be set up not to do so.
- If untagged packets are not accepted on the switch, the packets will need to be tagged using the
–tagall ONinterface command. But withtagall ON, the heartbeats will be tagged with VLAN 1 by default. Switches in general drop packets tagged with VLAN 1. This leaves us with two choices to achieve a working configuration:- Option 1: You can change the default VLAN of the interfaces by using the
set nsconfig –nsvlancommand (the change needs a reboot):
- Option 2: You can change the membership of the interface by binding a different VLAN (for example
100) without the tagged option. Then you set thetagalloption on the interface, as shown in the following screenshot:

- Option 1: You can change the default VLAN of the interfaces by using the
There are several reasons why this issue could happen:
- ARP issues
- stay secondary being set
- Health issues
- Split brain
Let's discuss them in more detail.
When a secondary NetScaler becomes the primary, it has to inform the upstream devices that it is now responsible for all of the VIPs. It does so by sending out gratuitous ARPs at a rate of two per VLAN per interface per second, as shown in the following screenshot. Note that the opcode of these GARPs is set to request by default:

The problem usually arises with firewalls, or IDS or IPS devices, that might not like GARP and hence drop these announcements. There are two ways to deal with this problem:
- Try with a different GARP opcode. Some devices prefer the opcode reply to request. You can set this by using the below command.
> set l2param -garpReply ENABLED - The use of VMACs (Virtual MACs) will keep the MAC address constant. Upstream devices thus do not need to know that the MAC address has changed, which is where the regular GARP-based method runs into delays or fails. The Failover as a result using this method is much faster.
Note, however, that for VMACs to work the switches need to support them as well, since the switch suddenly sees the MAC address move to a different port, and this might be disallowed by default on some switches. CTX121681 covers VMAC configuration in detail.
There is a HA misconfiguration and the backup node was set to stay secondary, in which case it will never attempt to become the primary.
If the new primary itself has some HA node issues and it sees itself as less than healthy, the Failover might not happen when needed. You can avoid this situation by enabling the failsafe setting. The command to do this will be:
>set ha node –failsafe ON
Enabling failsafe mode will ensure that even if both devices fail the HA health check, at least one of them will assume the primary role.
The term "split brain" is used to describe a situation where both devices in the HA pair are trying to become primary because neither device receives heartbeats from the other, yet both are active on the network. Neither node handles traffic because there are constant Failovers.
The troubleshooting to employ here is the same as for heartbeats not being seen. For example, correct the VLAN settings on the NetScaler and the switch.
Depending on the severity of the impact to service, you might want to take one node immediately off the network as a first step while you try to resolve the configuration issue.
Synchronization and propagation are very important aspects of High Availability. If they don't function, the NetScalers could end up with different configurations, which will lead to a service impact when a Failover does happen.
The following is a list of reasons that can lead to synchronization and propagation failures:
- The ports needed, 3008/3009/3010/3011, are blocked. However, this is generally rare, given that the pair are generally only separated by a switch.
- The versions or hardware don't match. This condition can be identified in the show node output. The
AUTO DISABLEDpart indicates that there is a mismatch:
This is the reason why you should always have the primary and secondary on the same version, except momentarily when upgrading software, when one of the nodes will have to be on newer code.
- RPC settings are used by each NetScaler to authenticate to its peer during HA and GSLB exchanges. If in doubt, do a quick comparison of the RPC node entries on the two NetScalers. You can do this using the
>show rpcnodecommand on each NetScaler in the High Availability pair and compare the settings on primary and secondary.
To make the most of a NetScaler investment, it is utilized mostly for its layer 4 to layer 7 magic, while relying on an external router or firewall for routing. The NetScaler integration with the network is thus mainly at layer 2. The issues in this area are key, both from a reachability and performance perspective, when working with NetScaler, and are the main focus of this section. The topics we will cover specifically in this section are:
- Interface error conditions and interface buffer issues
- Network loops and VLAN issues
- Unsupported SFPs
- Channeling issues
We will also look at a couple of source IP-related issues before wrapping up.
Before we dive into more specific points, let's quickly discuss how NetScaler makes its packet handling decisions. NetScaler in its default configuration listens to packets in what is referred to as promiscuous mode. In this mode, it accepts all packets whether or not they are intended for one of its MAC addresses. This behavior is necessary so NetScaler can support modes such as L2 mode, where it behaves like a switch. After picking up all packets it can see on the network, NetScaler drops those packets not addressed to it in software if L2 mode is disabled.
Note
While promiscuous mode for listening is always on, L2 mode itself is disabled by default and there should be a very good reason for you to change that setting, such as a deployment very specifically asking for it. Unless considered carefully, L2 mode can introduce the risk of a loop by collapsing broadcast domains.
The following diagram taken from Citrix eDocs is extremely helpful in demonstrating the decision path that NetScaler follows when trying decide between processing and dropping a packet:

Source: Citrix eDocs
With this understanding of the decision process, let's take a look at some layer 2 issues.
We've talked about how NetScaler picks up all packets it can see on the network before dropping those that don't fit its configured mode. A question that comes up often is around the Drops field in the show interface output. It is customary in networking to use interface drops as a measure of how healthy an interface is. However, in the case of NetScaler, for the reasons we've discussed, this field doesn't really help as we will most likely see a large count here, as L2 is disabled by default. So in the screenshot that follows, you can ignore the Drops counter that's showing a huge value:

However, there are several others in this screenshot that warrant attention if seen going up. Here's a quick description of what each of these indicate:
- InDisc and OutDisc: The
Discpart signifies discards. These going up indicates that the interface had to discard packets; this could well be because the interface has run out of buffers. We will talk about buffer issues shortly. - Fctls: This means NetScaler has received some flow control pause frames from the peer interface. It is generally an indication of integration issues with the connected switch or NIC congestion.
- Stalls: These indicate that packets in the buffer are unable to get out within a certain amount of time in one of the directions (RX or TX). They could be due to physical or software issues; you need to work with Citrix support for such cases. If stalls happen often enough, the interface will be reset.
- Hangs: NIC states are polled periodically to see if they are responsive. If the NIC doesn't respond to this polling, it is considered a hang. Citrix support needs to be engaged for such cases.
- Mutes: This is very likely because of a network loop resulting from the lack of a necessary broadcast domain such as a VLAN. When the MAC address that represents a server or a peer NetScaler IP is constantly seen on more than one interface within the same VLAN, one of the interfaces is disabled temporarily to stop the loop condition; at this point the
mutescount is increased. We will also talk about loops in a moment.
A NetScaler interface always has a finite buffer, which operates in a FIFO (First in-First Out) fashion. Running out of buffer space means an NIC has to drop packets. Due to the nature of TCP, any sustained dropping of packets will severely impact performance.
This situation can be identified by using the counter –g nic_err_rx_nobufs, as shown in the following screenshot. Here the 0/1 and 0/2 interfaces are running out of buffers:

NIC reporting no buffers when trying to receive a packet
The most common reasons why this could happen are:
- Management NICs are being used for production traffic. The interfaces
0/1and0/2are meant to handle management traffic, which is generally low in volume. They are also missing some of the driver optimizations present on the1/xand10/xinterfaces and hence are not suitable for handling production traffic. - There is a mismatch between incoming and outgoing bandwidth. To resolve this issue, consider adding interfaces with more bandwidth (such as
10/xinterfaces) or creating an LA channel, which also provides redundancy. This needs to be done in the direction where theDisccounters are going up. - The NetScaler is having a CPU crunch or a CPU tight loop, due to which all incoming packets are getting queued and are waiting for processing. If you are seeing resource usage shoot up, you need to work with Citrix to identify the underlying reason.
When two interfaces from NetScaler are plugged into the same switch and are not part of a channel, they will effectively be in the same broadcast domain, and naturally a network loop will occur. This situation can be detected using the following command:
nsconmsg –g nic_tot_bdg_mac_moved –d current
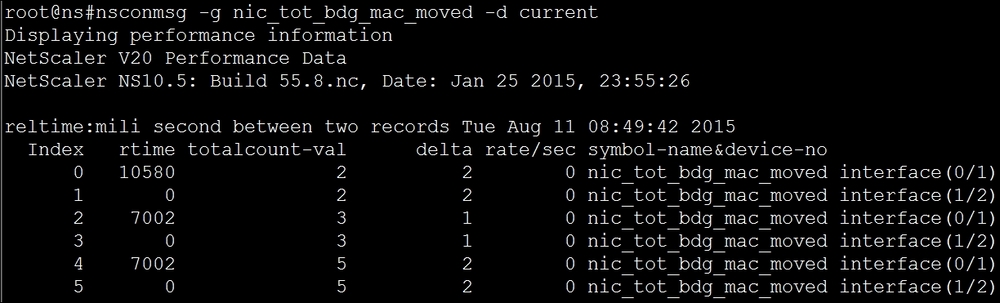
A resolution to this would be to use VLAN techniques to separate out the broadcast domains. For production interfaces, you can also consider bundling the interfaces into a channel.
While the VLAN implementation on NetScaler is pretty much standards-based, and as a topic is usually well understood, configuration issues are still relatively common. They sometimes arise because application delivery controllers, such as NetScaler, often require an uncommon overlap between networking-level and application-level skillsets.
Let's start with a quick review of VLANs, touching on areas that we didn't look at when discussing them in the context of High Availability, and then we'll delve into troubleshooting:
- VLANs are used to break down L2 domains.
- VLANs can be proprietary (Cisco ISL) or standards-based (such as 802.1Q, or simply dot1Q). NetScaler uses 802.1Q.
- VLAN tags are how frames are identified as being part of a particular VLAN.
- Any packet that doesn't contain a VLAN tag is assumed to belong to the Native VLAN of the interface picking up the packet.
- For VLANs to work correctly, either the packets need to be tagged with the right VLAN or the interface accepting the packet must have its native VLAN set to the correct one. Otherwise, it will drop the packet.
- When an interface is bound to a VLAN without the
–taggedconfiguration option, the interface's native VLAN changes to the most recent bound VLAN. This is how you change an interface's native VLAN on NetScaler. - To find out what VLAN a particular packet belongs to when looking at a trace (taken in
nstraceformat), expand theNetScaler Packet Tracenode:
NetScaler format trace showing VLAN and other custom info
If NetScaler is dropping packets due to VLAN mismatches on the incoming packets, the nic_err_vlan_promisc_tag_drops counters go up. You can use the following command to detect this situation: nsconmsg –g nic_err_vlan_promisc_tag_drops –d current:

If a newly installed SFP constantly shows its status as DOWN, it is possible that the SFP is not being recognized. Verify that the interfaces are indeed Citrix-provided ones.
It is tempting to reuse SFPs from a decommissioned device, such as a switch; however, there will be compatibility issues in doing so. To ensure performance stays top notch, Citrix develops custom driver code that integrates tightly with specific tested interface models. Thus, when an interface that the code is not written for is plugged in, it can result in poor performance and also in error conditions, and is hence unsupported.
If the interface is instead a DAC cable, verify that it is a Citrix-approved one. CTX137259 lists the currently supported ones, which are as follows:
10GBASE-CU SFP+ Cable 1 Meter, passive P/N 10GBASE-CU SFP+ Cable 3 Meter, passive P/N 10GBASE-CU SFP+ Cable 5 Meter, passive P/N
Unsupported NICs can be identified by looking at dmesg.boot:

While on the topic of SFP compatibility, the following text taken from the Citrix documentation is also good to note:
"While the SFP and SFP+ ports share the same physical dimensions, the 1GE SFP transceivers are not compatible to the SFP+ ports, and the 10 GE SFP+ transceivers are not compatible to the SFP ports. Do not install a 10 GE SFP+ transceiver in a 1 GE SFP port, and vice versa. The size of the socket enables you to install 1 GE SFP as well as 10 GE SFP+ transceivers. However, the NIC does not recognize the mismatched transceiver, the interface is not available, and the port LED lights are not switched on."
On NetScaler, there are two ways of aggregating multiple interfaces, manual aggregation and LACP. Issues with aggregation most commonly arise in LACP environments. This could be either due to a mismatch in channel settings, or due to the switch/NetScaler not negotiating LACPDUs (Link Aggregation Control Protocol Data Units) or LACP messages as it should. The starting point for these issues should be to look at the LACPDU counters. In the following screenshot taken from a healthy environment, we see LACPDUs exchanged periodically:

LACPDUs sent and received on NetScaler
We talked about USIP in our opening chapter. When enabled, it preserves the client's source IP address (instead of substituting it with the SNIP) all the way to the server. If strategically used, this can increase the throughput of NetScaler by bypassing it on its return. Direct Server Return (CTX110501) is a configuration that uses USIP for this benefit. USIP does however pose two challenges that we need to be aware of:
- When USIP is enabled one of the following needs to be done:
- NetScaler needs to be present in the return path to proxy the response
- The server needs to use the VIP as its source IP if it is indeed going back to the client using Direct Server Return
If neither is in place, any firewall, or the client itself, which is not expecting to see the Server's source IP, will drop the connection. If you are seeing issues where the application doesn't launch with USIP enabled, but works otherwise, take a trace on the Client and Server to verify that the return packets to the client match the VIP IP.
- A second problem with USIP is that of performance scalability. NetScaler can reuse TCP connections to the Server, as we discussed in the Load balancing section Chapter 2, Traffic Management Features. To be able to perform this optimization, NetScaler maintains a reuse pool where it keeps these warm optimized TCP connections, which can then be used agnostically for different clients. The use of USIP fragments the reuse pools, thereby reducing how much reuse is achievable.
So USIP should be considered only if the deployment is one that really needs it, such as in the case of Direct Server Return deployments.
For a lot of enterprises, NetScaler straddles the external and internal environments. It sits in the DMZ, potentially behind a firewall and almost certainly in front of another. It is very well understood that the NSIP is used to manage NetScaler. A little less obvious is that NSIP (and not the SNIP) is also the default source IP used to access authentication Servers. This can pose problems since network security policies don't allow management IPs such as the NSIP to be able talk to backend servers such as the authentication Servers.
There are two ways to mitigate this challenge:
- Replace the LDAP server with an LB vServer that load balances the server. With this configuration, the source IP used changes to SNIP instead of NSIP.
- Use network profiles to specify the IPs you want to use to talk to certain servers. You can even specify a range of addresses using an IPSET to control exactly what IPs you want to talk to which Services/Servers.
In the following example, we are telling NetScaler which three IPs (3 SNIPs in this case) to use to talk to a service configured for authentication. This way you can always have NetScaler choose its IPs carefully, in order to play well with your firewall rules.
