
I mentioned in the first chapter that the code called by controllers must be thread-safe. We also noticed that the result of calling an action has type Future[Result] rather than just Result. This chapter explains these subtleties and gives answers to questions such as "How are concurrent requests processed by Play applications?"
More precisely, this chapter presents the challenges of stream processing and the way the Play framework solves them. You will learn how to consume, produce, and transform data streams in a non-blocking way using the Iteratee library. Then, you will leverage these skills to stream results and push real-time notifications to your clients. By the end of the chapter, you will be able to do the following:
- Produce, consume, and transform streams of data
- Process a large request body chunk by chunk
- Serve HTTP chunked responses
- Push real-time notifications using WebSockets or server-sent events
- Manage the execution context of your code
The streaming programming model provided by Play has been influenced by the execution model of Play applications, which itself has been influenced by the nature of the work a web application performs. So, let's start from the beginning: what does a web application do?
For now, our example application does the following: the HTTP layer invokes some business logic via the service layer, and the service layer does some computations by itself and also calls the database layer. It is worth noting that in our configuration, the database system, as implemented in Chapter 2, Persisting Data and Testing, runs on the same machine as the web application but this is, however, not a requirement. In fact, there are chances that in real-world projects, your database system is decoupled from your HTTP layer and that both run on different machines. It means that while a query is executed on the database, the web layer does nothing but wait for the response. Actually, the HTTP layer is often waiting for some response coming from another system; it could, for example, retrieve some data from an external web service (Chapter 6, Leveraging the Play Stack – Security, Internationalization, Cache, and the HTTP Client, shows you how to do that), or the business layer itself could be located on a remote machine. Decoupling the HTTP layer from the business layer or the persistence layer gives a finer control on how to scale the system (more details about that are given further in this chapter). Anyway, the point is that the HTTP layer may essentially spend time waiting.
With that in mind, consider the following diagram showing how concurrent requests could be executed by a web application using a threaded execution model. That is, a model where each request is processed in its own thread.
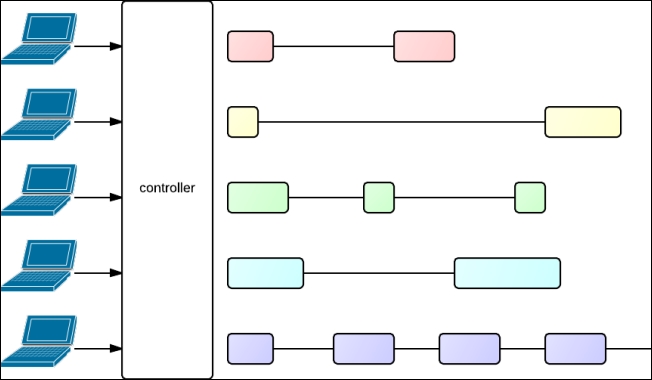
Threaded execution model
Several clients (shown on the left-hand side in the preceding diagram) perform queries that are processed by the application's controller. On the right-hand side of the controller, the figure shows an execution thread corresponding to each action's execution. The filled rectangles represent the time spent performing computations within a thread (for example, for processing data or computing a result), and the lines represent the time waiting for some remote data. Each action's execution is distinguished by a particular color. In this fictive example, the action handling the first request may execute a query to a remote database, hence the line (illustrating that the thread waits for the database result) between the two pink rectangles (illustrating that the action performs some computation before querying the database and after getting the database result). The action handling the third request may perform a call to a distant web service and then a second one, after the response of the first one has been received; hence, the two lines between the green rectangles. And the action handling the last request may perform a call to a distant web service that streams a response of an infinite size, hence, the multiple lines between the purple rectangles.
The problem with this execution model is that each request requires the creation of a new thread. Threads have an overhead at creation, because they consume memory (essentially because each thread has its own stack), and during execution, when the scheduler switches contexts.
However, we can see that these threads spend a lot of time just waiting. If we could use the same thread to process another request while the current action is waiting for something, we could avoid the creation of threads, and thus save resources. This is exactly what the execution model used by Play—the evented execution model—does, as depicted in the following diagram:
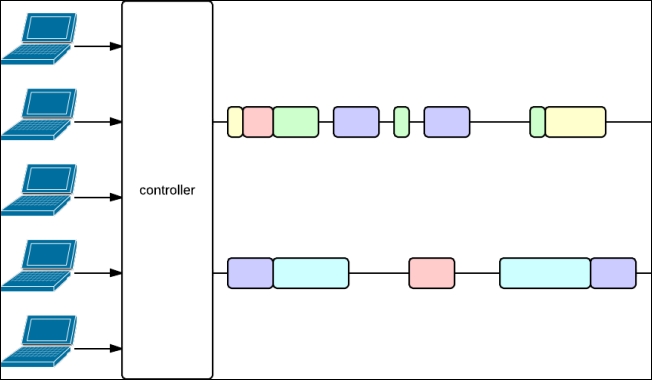
Evented execution model
Here, the computation fragments are executed on two threads only. Note that the same action can have its computation fragments run by different threads (for example, the pink action). Also note that several threads are still in use, that's why the code must be thread-safe. The time spent waiting between computing things is the same as before, and you can see that the time required to completely process a request is about the same as with the threaded model (for instance, the second pink rectangle ends at the same position as in the earlier figure, same for the third green rectangle, and so on).
Note
A comparison between the threaded and evented models can be found in the master's thesis of Benjamin Erb, Concurrent Programming for Scalable Web Architectures, 2012. An online version is available at http://berb.github.io/diploma-thesis/.
An attentive reader may think that I have cheated; the rectangles in the second figure are often thinner than their equivalent in the first figure. That's because, in the first model, there is an overhead for scheduling threads and, above all, even if you have a lot of threads, your machine still has a limited number of cores effectively executing the code of your threads. More precisely, if you have more threads than your number of cores, you necessarily have threads in an idle state (that is, waiting). This means, if we suppose that the machine executing the application has only two cores, in the first figure, there is even time spent waiting in the rectangles!