
Because Play uses explicit concurrency control, controllers are also responsible for using the right execution context to run their action's code. Generally, as long as your actions do not invoke heavy computations or blocking APIs, the default execution context should work fine. However, if your code is blocking, it is recommended to use a distinct execution context to run it.
An application with two execution contexts (represented by the black and grey arrows). You can specify in which execution context each action should be executed, as explained in this section
Unfortunately, there is no non-blocking standard API for relational database communication (JDBC is blocking). It means that all our actions that invoke code executing database queries should be run in a distinct execution context so that the default execution context is not blocked. This distinct execution context has to be configured according to your needs. In the case of JDBC communication, your execution context should be a thread pool with as many threads as your maximum number of connections.
The following diagram illustrates such a configuration:
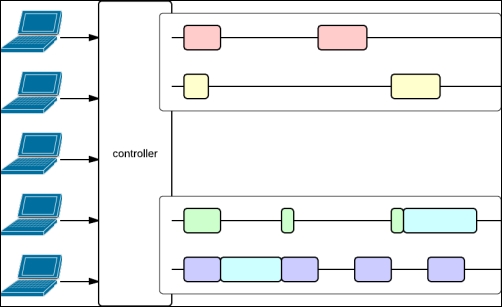
This preceding diagram shows two execution contexts, each with two threads. The execution context at the top of the figure runs database code, while the default execution context (on the bottom) handles the remaining (non-blocking) actions.
In practice, it is convenient to use Akka to define your execution contexts as they are easily configurable. Akka is a library used for building concurrent, distributed, and resilient event-driven applications. This book assumes that you have some knowledge of Akka; if that is not the case, please do some research on it. Play integrates Akka and manages an actor system that follows your application's life cycle (that is, it is started and shut down with the application). For more information on Akka, visit http://akka.io.
Here is how you can create an execution context with a thread pool of 10 threads, in your application.conf file:
jdbc-execution-context {
thread-pool-executor {
core-pool-size-factor = 10.0
core-pool-size-max = 10
}
}You can use it as follows in your code:
import play.api.libs.concurrent.Akka
import play.api.Play.current
implicit val jdbc =
Akka.system.dispatchers.lookup("jdbc-execution-context")The Akka.system expression retrieves the actor system managed by Play. Then, the execution context is retrieved using Akka's API.
The equivalent Java code is the following:
import play.libs.Akka;
import akka.dispatch.MessageDispatcher;
import play.core.j.HttpExecutionContext;
MessageDispatcher jdbc =
Akka.system().dispatchers().lookup("jdbc-execution-context");Note that controllers retrieve the current request's information from a thread-local static variable, so you have to attach it to the execution context's thread before using it from a controller's action:
play.core.j.HttpExecutionContext.fromThread(jdbc)
Finally, forcing the use of a specific execution context for a given action can be achieved as follows (provided that my.execution.context is an implicit execution context):
import my.execution.context
val myAction = Action.async {
Future { … }
}The Java equivalent code is as follows:
public static Promise<Result> myAction() {
return Promise.promise(
() -> { … },
HttpExecutionContext.fromThread(myExecutionContext)
);
}Does this feel like clumsy code? See Chapter 7, Scaling Your Codebase and Deploying Your Application, to learn how to reduce the boilerplate!