
So far, we have discussed the basics of the ZooKeeper service and learned in detail about the data model and its attributes. We have also been acquainted with the ZooKeeper watch concept, which is an eventing mechanism that is done when any changes are made to a znode in the ZooKeeper namespace. We read how authentication and a basic security model are implemented by exposing a set of ACLs to be associated with znodes.
In this section, we will discuss and learn about the lifetime of a client's interaction with a ZooKeeper service by introducing the concept of ZooKeeper sessions. We will also read in detail how ZooKeeper works internally by describing its protocols. It is important to know about the inner workings to gain a deep insight, which will help in designing distributed applications with ZooKeeper and understanding the intricacies of the things associated with it.
Let's start with how clients interact with a ZooKeeper service. In order for distributed applications to make use of the ZooKeeper service, they have to use APIs through a client library. ZooKeeper client libraries have language bindings for almost all popular programming languages. The client library is responsible for the interaction of an application with the ZooKeeper service. We will learn about ZooKeeper APIs in the next chapter.
An application's interaction with the ZooKeeper service is illustrated in the following image:
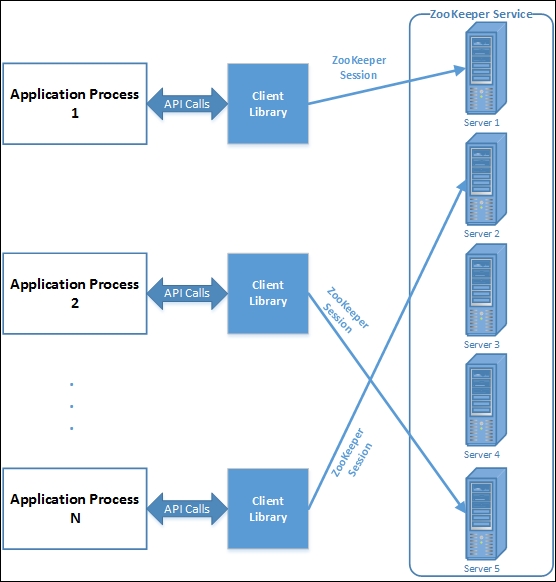
An image that represents how an application interacts with the ZooKeeper service through client libraries
The ZooKeeper service can run in two modes: standalone and quorum. In the standalone mode, there is a single ZooKeeper server. On the other hand, the quorum mode means that ZooKeeper runs in a replicated mode on a cluster of machines, also known as an ensemble.
Note
The standalone mode is useful only for evaluation and to test application code, but should not be used in production as it's a potential single point of failure. In the quorum mode, ZooKeeper achieves high availability through replication and can provide a service as long as a majority of the machines in the ensemble are up.
A ZooKeeper quorum constitutes majority of replica nodes that store the most recent state of the ZooKeeper service among all servers in the ensemble. It's basically the minimum number of server nodes that must be up and running and available for client requests. Any update done to the ZooKeeper tree by the clients must be persistently stored in this quorum of nodes for a transaction to be completed successfully.
For example, in a five-node ensemble, any two machines can fail, and we can have a quorum of three servers, and the ZooKeeper service will still work. At a later time, if the other two failed nodes come up, they can sync up the ZooKeeper service state by getting the most recent state from the existing quorum.
Let's look at an example to see why this makes sense. Suppose we have a ZooKeeper ensemble of five servers. If any two servers fail, the ensemble can still function because a quorum can be formed out of the remaining three nodes. Thus, a five-node ZooKeeper ensemble can tolerate failure of up to two nodes.
Now, for a six-node ensemble, the ZooKeeper service can tolerate a failure of only up to two nodes. This is because with three nodes failing, a quorum can't be formed; a majority consensus can't be achieved there for the ensemble. Again, ZooKeeper quorums must guarantee that any transaction that is acknowledged to the client as a success should be durable and visible across the nodes that form the quorum.
If a ZooKeeper quorum is not formed with the majority nodes in the ensemble, there can be inconsistencies in the state of the ZooKeeper namespace, leading to incorrect results. Apart from node failures, network partitions between the nodes in an ensemble can lead to inconsistent operations as the quorum members won't be able to communicate updates among themselves. This leads to a common problem seen in distributed clusters, called split-brain.
Split-brain is a scenario when two subsets of servers in the ensemble function independently. It leads to an inconsistent state in the whole ZooKeeper service, and different clients get different results for the same request, depending upon the server they are connected to. By having a ZooKeeper cluster running with odd numbers of nodes, we can reduce the chance of such errors to a probabilistic minimum.
A client that is connecting to ZooKeeper can be configured with a list of servers that form a ZooKeeper ensemble. A client tries to connect to the servers in the list by picking up a random server from the list. If the connection fails, it tries to connect to the next server, and so on. This process goes on until all the servers in the list have been tried or a successful connection is established.
Once a connection between the client and the ZooKeeper server has been established, a session is created between the client and the server, represented as a 64-bit number, which is assigned to the client. The concept of sessions is very important for the operation of ZooKeeper. A session is associated with every operation a client executes in a ZooKeeper service.
Sessions play a very important role in ZooKeeper. For example, the whole notion of ephemeral znodes is based on the concept of sessions between the client and the ZooKeeper server. Ephemeral znodes have the lifetime of a session being active between a client and ZooKeeper; when this session ends, these nodes are automatically deleted by the ZooKeeper service.
A session has a timeout period, which is specified by the application or the client while connecting to the ZooKeeper service. The client sends a requested timeout as a parameter in the create connection call to create a ZooKeeper, which is specified in milliseconds. If the connection remains idle for more than the timeout period, the session might get expired. Session expiration is managed by the ZooKeeper cluster itself and not by the client. The current implementation requires that the timeout be a minimum of two times the tickTime (see Chapter 1, A Crash Course in Apache ZooKeeper) and a maximum of 20 times the tickTime.
Specifying the right session timeout depends on various factors, such as network congestion, complexity of the application logic, and even the size of the ZooKeeper ensemble. For example, in a very busy and congested network, if the latency is high, having a very low session timeout will lead to frequent session expiration. Similarly, it's recommended to have a larger timeout if your ensemble is large. Also, if the application sees frequent connection loss, increasing the session timeout can be useful. However, another caution to that is that it should not have an inadvertent effect on the application's core logic.
Sessions are kept alive by the client sending a ping request (heartbeat) to the ZooKeeper service. These heartbeats are sent automatically by the client libraries, and hence, an application programmer need not worry about keeping alive the sessions. Sessions between a client and a ZooKeeper server is maintained using a TCP connection. The interval between two subsequent heartbeats should be kept low, such that connection failure between the client and the ZooKeeper server can be detected quite early and a reconnection attempt can be made. Reconnection to another ZooKeeper server is usually done by the client library in a transparent way. When a reconnection to a different server of the same ensemble is done, the existing sessions and associated ephemeral znodes created by the client remains valid. For single sessions maintained between the client and the server, ZooKeeper guarantees the order, which is typically in the FIFO order.
While reconnect attempts are being made to another ZooKeeper server, the application will receive notifications of disconnections and connections to the service. During this failover, watch notifications are not delivered to the client as the client is typically in a disconnected mode. However, all pending event notifications are dispatched in order when the client successfully reconnects to the service. Also, any client operations are not honored during the reconnection time, and hence, operations will fail. So, it's very important to handle connection-loss scenarios while developing applications with ZooKeeper.
As mentioned in the previous section, an application establishes a session with the ZooKeeper service using a client library. A handle that represents the connection object is returned to the application by the ZooKeeper client API. This ZooKeeper connection object transitions through different states during the period between its creation and its end. The connection object lasts till the connection of the client program is closed gracefully or the session expires because of a timeout.
Once the connection object is created, it starts with the CONNECTING state, and the client library tries to connect to one of the servers in the ZooKeeper ensemble. When connected to the ZooKeeper service, the object transitions to the CONNECTED state. On account of events such as session expiration and authentication failures, or if the application gracefully closes the connection using the library calls, the object's state moves to the CLOSED state.
The state transitions of a ZooKeeper client's session are illustrated in the following image:
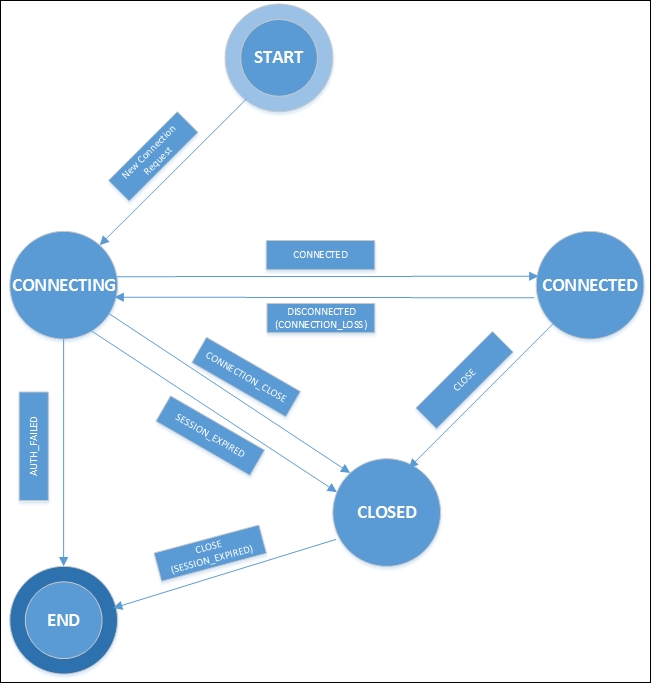
An image that represents the transitions of the ZooKeeper client state
From the previous sections, we have seen how ZooKeeper runs on an ensemble of servers and how clients connect to these servers, establish a session, and carry out an operation in the ZooKeeper service. Among the ensemble of servers, a server is elected as a leader, and all the remaining servers are made followers. The leader handles all requests that change the ZooKeeper service. Followers receive the updates proposed by the leader, and through a majority consensus mechanism, a consistent state is maintained across the ensemble. The ZooKeeper service takes care of replacing leaders on failures and syncing followers with leaders, and the whole process is fully transparent to client applications.
The service relies on the replication mechanism to ensure that all updates are persistent in all the servers that constitute the ensemble. Each server maintains an in-core database, which represents the entire state of the ZooKeeper namespace. To ensure that updates are durable, and thus recoverable in the event of a server crash, updates are logged to a local disk. Also, the writes are serialized to the disk before they are applied to the in-memory database.
ZooKeeper uses a special atomic messaging protocol called ZooKeeper Atomic Broadcast (ZAB). This protocol ensures that the local replicas in the ensemble never diverge. Also, the ZAB protocol is atomic, so the protocol guarantees that updates either succeed or fail.
The replicated database and the atomic broadcast protocol together with the leader election mechanism form the heart of the ZooKeeper service implementation. An update or a write in the ZooKeeper service namespace, along with a read, is handled by these core components, as you can see in this image (you can also refer to this image at http://zookeeper.apache.org/doc/r3.4.6/zookeeperOver.html#fg_zkComponents):
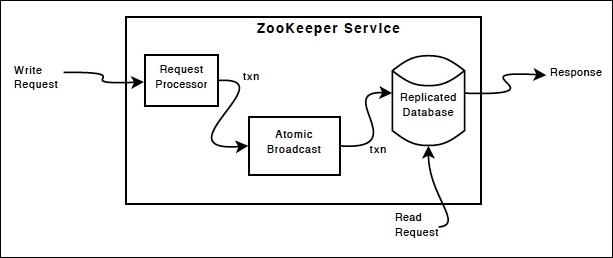
An image that represents the ZooKeeper Service Components
In a ZooKeeper implementation, read requests such as exists, getData, and getChildren are processed locally by the ZooKeeper server where the client is connected. This makes the read operations very fast in ZooKeeper. Write or update requests such as create, delete, and setData are forwarded to the leader in the ensemble. The leader carries out the client request as a transaction. This transaction is similar to the concept of a transaction in a database management system.
A ZooKeeper transaction also comprises all the steps required to successfully execute the request as a single work unit, and the updates are applied atomically. Also, a transaction satisfies the property of isolation, which means that no transaction is interfered with by any other transaction. A transaction in the ZooKeeper service is idempotent. Transactions are identified by a transaction identifier (zxid), which is a 64-bit integer split into two parts: the epoch and the counter, each being 32 bits.
Transaction processing involves two steps in ZooKeeper: leader election and atomic broadcast. This resembles a two-phase commit protocol, which also includes a leader election and an atomic broadcast.
The servers in an ensemble go through a process of electing a master server, called the leader. The other servers in the ensemble are called followers.
Each server that participates in the leader election algorithm has a state called LOOKING. If a leader already exists in the ensemble, the peer servers inform the new participant servers about the existing leader. After learning about the leader, the new servers sync their state with the leader.
When a leader doesn't exist in the ensemble, ZooKeeper runs a leader election algorithm in the ensemble of servers. In this case, to start with, all of the servers are in the LOOKING state. The algorithm dictates the servers to exchange messages to elect a leader. The algorithm stops when the participant servers converge on a common choice for a particular server, which becomes the leader. The server that wins this election enters the LEADING state, while the other servers in the ensemble enter the FOLLOWING state.
The message exchanged by the participant servers with their peers in the ensemble contains the server's identifier (sid) and the transaction ID (zxid) of the most recent transaction it executed. Each participating server, upon receiving a peer server's message, compares its own sid and zxid with the one it receives. If the received zxid is greater than the one held by the server, the server accepts the received zxid, otherwise, it sets and advertises its own zxid to the peers in the ensemble.
At the end of this algorithm, the server that has the most recent transaction ID (zxid) wins the leader election algorithm. After the algorithm is completed, the follower servers sync their state with the elected leader.
The next step to leader election is leader activation. The newly elected leader proposes a NEW_LEADER proposal, and only after the NEW_LEADER proposal is acknowledged by a majority of servers (quorum) in the ensemble, the leader gets activated. The new leader doesn't accept new proposals until the NEW_LEADER proposal is committed.
All write requests in ZooKeeper are forwarded to the leader. The leader broadcasts the update to the followers in the ensemble. Only after a majority of the followers acknowledge that they have persisted the change does the leader commit the update. ZooKeeper uses the ZAB protocol to achieve consensus, which is designed to be atomic. Thus, an update either succeeds or fails. On a leader failure, the other servers in the ensemble enter a leader election algorithm to elect a new leader among them.
Tip
ZAB: High-performance broadcast for primary-backup systems by Junqueira, F.P; Reed, B.C; Serafini. M
(LADIS 2008, in: Proceedings of the 2nd Workshop on Large-Scale Distributed Systems and Middleware)
Readers can access the paper on ZAB from IEEE Xplore in this link: http://bit.ly/1v3N1NN
ZAB guarantees strict ordering in the delivery of transactions as well as in the committing of the transactions. Pictorially, the processing of transactions through atomic messaging can be illustrated as follows:
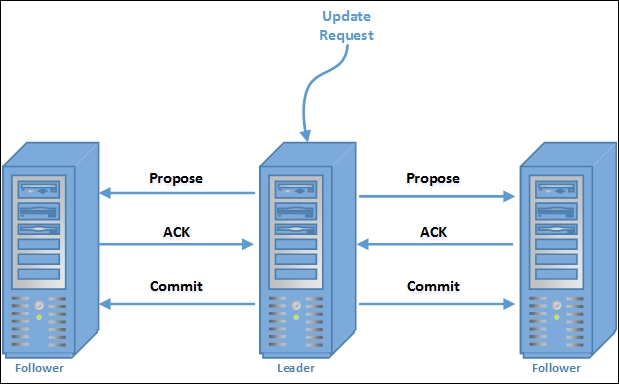
An image that represents the transaction commit protocol of ZooKeeper
The two-phase commit guarantees the ordering of transactions. In the protocol, once the quorum acknowledges a transaction, the leader commits it and a follower records its acknowledgement on disk.
Tip
Apart from leaders and followers, there can be a third personality of a server in a ZooKeeper ensemble, known as observers. Observers and followers are conceptually similar as they both commit proposals from the leader. However, unlike followers, observers do not participate in the voting processes of the two-phase commit process. Observers aid to the scalability of read requests in a ZooKeeper service and help in propagating updates in the ZooKeeper ensemble that span multiple data centers.
ZooKeeper servers use local storage to persist transactions. The transactions are logged to transaction logs, similar to the approach of sequential append-only log files used in database systems. ZooKeeper servers use pre-allocated files to flush transactions onto disk media. In the two-phase protocol for transaction processing in ZooKeeper, a server acknowledges a proposal only after forcing a write of the transaction to the transaction log. Since ZooKeeper transaction logs are written at great speed, it's very important for the transaction logs to be configured in a disk separate from the boot device of the server.
The servers in the ZooKeeper service also keep on saving point-in-time copies or snapshots of the ZooKeeper tree or the namespace onto the local filesystem. The servers need not coordinate with the other members of the ensemble to save these snapshots. Also, the snapshot processing happens asynchronous to normal functioning of the ZooKeeper server.
The ZooKeeper snapshot files and transactional logs enable recovery of data in times of catastrophic failure or user error. The data directory is specified by the dataDir parameter in the ZooKeeper configuration file, and the data log directory is specified by the dataLogDir parameter.