
5
Selection of Cloud Computing Services: Contribution of Intelligent Methods
Ahmed Khalid Yassine SETTOUTI
Abou Bekr Belkaid University, Tlemcen, Algeria
5.1. Introduction
Nowadays, each electronic device generates data related to its use, environment or state. Once generated, data are and will always be important for their generator and/or user.
The Web boom was immediately followed by a sudden increase in the use of computer devices. As a direct consequence, there is a growing amount of data generated by these devices. This rapid expansion gave rise to new needs and requirements in terms of resources for the management of generated information. This is how cloud computing emerged.
Later, the number of cloud computing providers continued to grow. Consequently, choosing one of them became a complex task, especially when unconventional requirements are involved. Furthermore, each provider has its own fees, quality measures, advantages and drawbacks. Therefore, choosing a provider or service became even more difficult.
This chapter is a state of the art focusing on the selection, composition, evaluation or recommendation of cloud computing services. The objective, approach or method of the surveyed works must be related to artificial intelligence (AI). The literature features many attempts such as Ahmed et al. (2019), who prefers to focus on the selection of cloud computing services in the case of heterogeneous cloud federation, while Whaiduzzaman et al. (2014) aims at approaches using multiple choice-based multidecision methods. A similar approach is adopted by Le et al. (2014) limiting the set of surveyed works to those using fuzzy logic. Finally, Papathanasiou et al. (2015) resumed the work of Whaiduzzaman et al. (2014) and added an analytical comparison.
This chapter aims to give the readers an overview on the current works dedicated to cloud computing services that use AI. The objective is to save bibliographic research time for researchers in the field and to facilitate introduction for researchers in need of clarification.
The rest of this chapter is structured as follows:
- – section 5.2 presents several general notions required for the comprehension of this chapter;
- – section 5.3 lists several similar works in the field of cloud computing services selection;
- – section 5.4 presents the monitored works, submits them to critical analysis and offers several improvement suggestions;
- – section 5.5 reviews the research advances in the selection of cloud computing services using AI and proposes work that could be conducted in the near future.
5.2. Scientific and technical prerequisites
This section describes several scientific or technical notions required for the comprehension of this chapter. First, a simple, but quite thorough definition of cloud computing is provided. At the end, the concept of AI is presented, including an explanation of what it is and what it is not.
5.2.1. Cloud computing
This section briefly presents the concept of cloud computing (definition, characteristics, deployment models and levels of services).
Cloud computing is a model enabling access to remotely configurable (physical or virtual) resources (Mell and Grance 2011).
On the one hand, access must be ubiquitous and on customers demand. On the other hand, it should require minimal customer efforts and no interaction with the service provider (Mell and Grance 2011).
The computerized cloud is expected to provide customers with a certain quality, such as a minimal availability rate (generally 99.95%) (Hayes 2008; Mell and Grance 2011).
5.2.1.1. Cloud computing characteristics
Although the previous definition (see section 5.2.1) lists a set of characteristics that distinguish cloud computing from other models and architectures (such as virtualization, on-demand computing and ubiquitous computing), it is important to independently describe each criterion. The following segments provide details on cloud computing properties.
5.2.1.1.1. On-demand service
The customer can allocate as many resources as needed. They can do this at any moment with no service provider intervention (Ahmad et al. 2017).
5.2.1.1.2. Access via Internet
All the resources of the cloud are accessible through the Internet (Armbrust et al. 2010). Whether heavy (desk applications) or light (web applications), they are available to any Internet user (Mell and Grance 2011).
5.2.1.1.3. Resource grouping
Various resources are grouped for a set of customers (Syntec Numérique 2012). Depending on the processes load and number, resources are allocated and released (Hayes 2008).
Consumers have no knowledge on the exact location of their processing (Mell and Grance 2011). However, they can choose the datacenter where their services are processed, but not a specific server (Armbrust et al. 2010).
5.2.1.1.4. Rapid elasticity
Resources can be provisioned, deleted, expanded or reduced as easily and rapidly as possible (Mell and Grance 2011). The customers’ perception is that resources are unlimited, accessible and modifiable at any moment and from any connected location, as if they were local (Hayes 2008).
5.2.1.1.5. Measured service
Users pay only for what they use, so the service is measured by its use (Syntec Numérique 2012). This may vary depending on the type of service, but the principle is the same. For example, a storage service (Google Drive, which is free up to 10 GB and available after payment beyond that) can measure the allocated space, without billing the other resources such as the processor and the bandwidth, while a database service (Heroku, for example, which is free for a given database size, but chargeable larger sizes) can measure the size of tables, without including the cost of their creation and/or processing.
5.2.1.2. Deployment models
There are four different ways for deploying a computerized cloud. The main differentiation criterion is the targeted audience.
5.2.1.2.1. Public cloud

Figure 5.1. Public deployment of cloud computing. For a color version of this figure, see www.iste.co.uk/benmammar/network.zip
Although managed by a private company (such as Microsoft, which manages its Azure service for the general public), the cloud computing model for the general public can be accessed by any connected Internet user (Mell and Grance 2011). Consequently, though the least secured, it is not the least used (Hayes 2008).
Figure 5.1 gives an illustration of cloud computing model for the general public. A public cloud service is always accessible. The only condition to be met by the customer is being connected to the Internet.
As with any equipment, it has to be managed by an organization, a company, etc., but this can be done locally or via the Internet.
5.2.1.2.2. Private cloud
Cloud infrastructure or part of the cloud is dedicated to a specific company (Ahmad et al. 2017). An Internet user who is not related to the company cannot access equipment considered private (Mell and Grance 2011). However, the infrastructure can be managed by the respective company (customer) or by a third party (manager) (Syntec Numérique 2012).

Figure 5.2. Private deployment of cloud computing. For a color version of this figure, see www.iste.co.uk/benmammar/network.zip
Figure 5.2 illustrates an example of private deployment of cloud computing. A member of the client company can access dedicated equipment, while another cannot. On the other hand, the equipment can be managed by a third organization (managing company) or by the company itself (client).
5.2.1.2.3. Community cloud
The (entire or partial) cloud infrastructure is dedicated to a community of companies sharing the same requirements and preferences specified in their Service Level Agreements (Mell and Grance 2011).
The respective infrastructure can be managed by the whole community, a part of it, a member company or a third party organization (Syntec Numérique 2012).

Figure 5.3. Community deployment of cloud computing. For a color version of this figure, see www.iste.co.uk/benmammar/network.zip
Figure 5.3 illustrates a community deployment model. The infrastructure can be managed by the company outside the community (managing company), by the entire community or a part of it. Therefore, a group of companies must share a minimum of requirements and/or to draw a maximum of benefits from the model.
5.2.1.2.4. Hybrid model
The infrastructure is a mixture of at least two previously mentioned models (Ahmad et al. 2017).
5.2.1.3. Levels of Cloud Computing services
5.2.1.3.1. Infrastructure-as-a-service
Accessible and shared resources are provided to users, such as computing units, storage media, and communication means (network) (Mell and Grance 2011). Using these resources, the consumers can remotely run their own software and tools (Hayes 2008). This means that the customer controls the operating system, the applicative aspect and the storage (Syntec Numérique 2012), but does not manage the low layers, such as the infrastructure and the material network (Hayes 2008). Nevertheless, he/she may sometimes partially manage the network software (if authorized by the provider), such as the choice of firewall (Armbrust et al. 2010).
5.2.1.3.2. Software-as-a-service
The objective is to use web applications that run on cloud servers (Hayes 2008). The software can be accessed by various customers, across the globe (Mell and Grance 2011). These customers control only those parameters specifically left open by the service provider (Ahmad et al. 2017), and have no control on the management of infrastructure, operating system, network, and the application itself (Syntec Numérique 2012).
5.2.1.3.3. Platform-as-a-service
An intermediate level between the two previously mentioned levels is platform-as-a-service (PaaS) (Ahmad et al. 2017). The client can deploy customer-created applications on the tools offered or proposed by the provider (Mell and Grance 2011). These may include databases and programming languages (Hayes 2008). The consumer does not manage the lower layers such as servers and operating systems (Syntec Numérique 2012), but is however in control of the deployed applications and is able to configure their hosting environment (Armbrust et al. 2010).
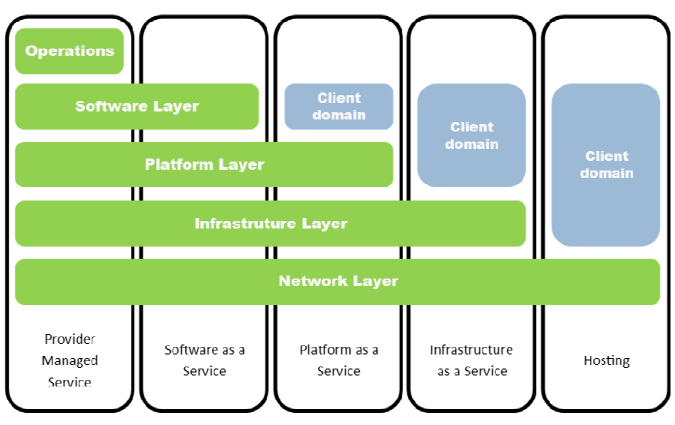
Figure 5.4. Distribution of customer/provider management in a cloud computing environment depending on service level (Syntec Numérique 2012)
Figure 5.4 shows the way in which Syntec Numérique (2012) distinguishes between levels of cloud computing services. For example, Facebook and most Google products are the most famous software-as-a-service (SaaS).
PaaS level is quite difficult to understand, given the ambiguity of customer and provider shared control. For example, the customer may control only logic data such as Heroku service, or a real DataBase Management System (DBMS) in a cloud environment such as My Structured Query Language (MySQL) cloud. Finally, the customer may control a whole integrated development environment such as Salesforce (the service gives its customers the possibility to create a complex website in several steps).
Infrastructure-as-a-service (IaaS) level enables the customer to control a remote virtual machine. Consequently, the customer has a distant computer that he/she does not physically possess, but which is always available for him/her.
5.2.2. Artificial intelligence
AI refers to intelligence manifest in machines, unlike natural intelligence possessed by human beings or animals (Russel and Norvig 2016).
AI is a science that studies intelligent agents (Legg 2007), which are entities simultaneously capable of perceiving the environment in which they exist and of making decisions in order to maximize the chances of reaching their objectives (Kaplan and Haenlein 2019).
This is the most simple and common definition in the field, as many researchers estimate that people amalgamate everything under the umbrella of AI (McCorduck 2009). Furthermore, this phenomenon is referred to as “AI effect” (McCorduck
2009). As an example, many researchers in the field of AI do not consider optical character recognition as being part of AI. This is due to the deterministic and optimal algorithms solving this type of problems (Schank 1991).
5.2.2.1. Subjects
The subjects dealt with in the field of AI are diverse and various. The most widely known is (reasoning-based) problem resolution (Poole et al. 1998). Since reasoning is one of the facets of natural intelligence, AI researchers took a step-by-step approach to the implementation of reasoning in machines (Nilsson 1998).
The concept has steadily evolved, but the run time of currently proposed algorithms increases (exponentially) as soon as the problem exceeds a certain level of complexity (Russel and Norvig 2016). It is easier to solve such problems of significant complexity with natural intelligence, because human beings use shortcuts (such as intuition and memory) most of the time (Foss and Dodwell 1966).
Since AI studies intelligent agents able to perceive their environments, it is obvious that perception itself is a theme in the field (Nilsson 1998; Russel and Norvig 2016). Further examples are voice recognition (Russel and Norvig 2016), facial recognition and object recognition (Russel and Norvig 2016), which are subthemes related to the integration of sensors in intelligent agents.
AI covers many themes. Those explained in this section are in no way a representation of the whole range of themes.
Indeed, some problems are better considered as methods (such as machine learning) or applications (such as language recognition).
5.2.2.2. Approaches
In order to cope with the previously mentioned problems, AI has a broad range of approaches at its disposal. While several researchers thought that machines should feel emotions, others preferred them to find the very essence of solving logic and varied problems (Crevier 1993; McCorduck 2009) (as knowledge representation, planning and learning).
Further approaches can be mentioned, such as intelligent computing. This studies the integration of artificial neural networks in computing (Crevier 1993; McCorduck 2009) and is used to find low-certainty solutions to problems that do not necessarily require an optimal (global) solution.
AI uses many approaches that are beyond the scope of a chapter that does not deal specifically with the field. Therefore, the approaches that are briefly explained in this section do not represent all the possible approaches in AI. Moreover, certain approaches are better considered as being domains (such as cybernetics) or even subdomains (systems of intelligent agents).
5.2.2.3. Tools
Each domain has its problems, and each problem needs tools to be solved.
Among the most commonly used tools in AI, artificial neural networks should be being mentioned. They are heavily inspired by the architecture and behavior of human brain. They are known as a set of interconnected nodes. Each node is associated with a weight in order to vote for a decision it is expected to activate (Domingos 2015). The only drawback of an artificial neural network is that it needs a certain time in order to learn from examples. Furthermore, though less probable, it is not impossible to learn a false decision.
On the other hand, some researchers use probabilistic methods for uncertain reasoning. These are algorithms that do not have all their inputs. These methods include Bayesian networks (Nilsson 1998), Markov models (Russel and Norvig 2016) and Kalman filters (Russel and Norvig 2016).
A description of all the methods used in the selection of cloud computing services is beyond the scope of this section. The reader should find it more interesting to inspect a review (short description) of the currently used methods and contributions to the selection of cloud computing services. Consequently, further details on the tools used by these contributions are provided in section 5.4.
5.3. Similar works
This section offers a brief presentation of already published surveys for cloud computing services selection contributions. After introducing each work, we review it and explain why the paper is recommended.
Beloglazov et al. (2012) monitored the heuristics used for the discovery and allocation of datacenter resources in cloud computing environment, while reducing the energy consumption and providing the negotiated quality of service. To achieve this, researchers divided their works along three distinct axes. The first one focuses on computerized cloud architectures enabling energy consumption reduction or control. The second axis is dedicated to planning policies and algorithms that provide a previously determined quality of service, while reducing energy consumption. The third and last axis is more interested in problems than in solutions. It presents the currently open problems while trying to allocate the resources of a computerized cloud, reduce energy consumption and provide the required (negotiated) quality of service.
The above quoted work is strongly recommended for any researcher (either non-initiated, beginner or expert) willing to contribute to resource allocation in computerized clouds.
Some works applied multiple choice decision making methods for IaaS cloud service selection. At first, Rehman et al. (2012) deployed a specific number of methods on the same set of IaaS cloud services. Then they compared the results found. In another research paper, the same authors added quality of services to their research criteria (Rehman et al. 2014).
The two excellent reports quoted above are of interest for any researcher willing to contribute to cloud computing service selection using neural networks. This is all the more so, as most approaches requiring learning generally rely on multiple-choice decision-making methods.
During the same year, Mandal et al. (2013) compared the approaches in order to discover, evaluate and select cloud computing services for large data flow applications. The authors first presented an architecture, and then compared the results of their work with the topical results. It is worth mentioning that all their contributions rely on trees.
Although quite outdated, the respective article is an excellent introduction to the discovery of cloud computing services using intelligent agents.
Le et al. (2014) proposed a multicriteria decision-making approach based on fuzzy logic for the selection of the best cloud computing services. For this purpose, researchers proposed an approach based on both interpretive structure modeling (ISM) and analytic network process (ANP). The first served for modeling interactive relations between evaluation criteria, while the second served for the management of uncertain data. Given that the objective was to maximize the useful results, an optimal result was perceived as a service maximizing the utility function. It is worth being mentioned that the authors ignored the time required to get to such results.
Some AI applications focus on the prediction of uncertain data. An uninitiated researcher looking for a contribution from this perspective will find this report highly recommended.
Sun et al. (2014) summarized the scientific advances accomplished in 2014 in cloud computing services selection. They then proposed several directions for the near future. The authors ignored the experimental side of the studied works, but they nevertheless summarized the evolution of problems during the period 2009–2014.
In Sun et al. 2014, we found an excellent introduction to cloud computing services selection if the researcher does not yet have a clearly defined problem.
Whaiduzzaman et al. (2014) proposed a survey of the works selecting cloud computing services by multiple-choice multi-criteria methods (MCMC). To reach their objective, they first drew a synthesis of MCMC techniques (including AI). Then they analyzed the approaches in their study domain. Finally, they highlighted certain aspects of MCMC methods in the selection of cloud computing services. Many of the proven facts rely on AI.
The above-mentioned paper focuses on MCMC, but this type of approach often heavily relies on AI. Consequently, the paper written by Whaiduzzaman et al. (2014) is recommended to researchers that are not initiated in the field of AI and are willing to contribute to the selection of cloud computing services.
Papathansiou et al. (2015) resumed the work of Whaiduzzaman et al. (2014) in order to add an analytical comparison in terms of objectives and performances. Researchers had to implement the surveyed processes to achieve that, and then submit them to evaluation and results comparison. In addition to the article by Whaiduzzaman (2014), Papathanasiou et al. (2015) is a stronger recommended reference.
Lastly, Ahmed et al. (2019) proposed a survey as well as an analysis of the requirements for the approaches selecting cloud computing services for cloud federation (or federation of cloud computing services). First, researchers started by defining the characteristics of federated computerized clouds, as well as services in federated clouds. Then, they proposed their own definition of level of trust for a cloud computing service. Therefore, they compared their measures of trust to those proposed in the literature. Finally, they highlighted the advantages of their proposal compared to the proposals in the field of the cloud computing services federation.
Although the work of Ahmed et al. (2019) looks more like a contribution than a survey, it was considered like a state of the art because the researchers explicitly mention it. However, a researcher may not necessarily be interested in the federation of computerized clouds; this work is recommended for the composition of cloud computing services (general case).
Finally, there is implicitness in the field. Some works are positioned on the customer side, and others on the provider side. The latter deal with billing diagrams (Aishwarya and Muzammil 2017), energy consumption efficiency (Sharma et al. 2016b), task planning (Singh et al. 2017), profit maximization (Das et al. 2014) and resource management (Liaqat 2017) (this list of objectives is not exhaustive).
On the other hand, the works on the customer side rather focus on cost optimization (Pandey et al. 2011), migration of applications toward cloud computing (Andrikopoulos et al. 2013), risk management (Gupta et al. 2015) and data confidentiality (Xu et al. 2016) (this list of objectives is not exhaustive).
5.4. Surveyed works
This section covers a certain number of works in the selection of cloud computing services using AI (problems, tools, approaches, fields application, etc.).
To improve its readability, the set of surveyed works is divided into families, according to the used processes (subdomains of AI). The objective is to reduce the number of contributions per subsection, and to facilitate a more detailed discussion of subdomain specific problems.
5.4.1. Machine learning
This section reviews work in cloud computing services selection using machine learning for this purpose. It is a known fact that AI is an implementation of human intelligence by machines, and learning by examples is a form of natural intelligence.
Machine learning enables intelligent agents to learn from examples before confronting real cases.
Kang et al. (2013) proposed an approach for the selection of a virtual machine in a cloud environment in order to plan and distribute user processes tasks. The objective was to maximize the best virtual machine prediction, as well as its performances, before seeing the price or quality, while learning on a set of examples. Despite the interest of the contribution, learning requires a certain time in order to get to a useful stage; the authors in fact neglected this aspect (time required for learning).
Xiaogang et al. (2015) proposed a dynamic approach for the selection of the best cloud computing service. For this purpose, they implemented a strategy known as dynamic cloud service (DCS) in each broker. The strategy relies on machine learning and its objective is real time provision of the best service, irrespective of previous changes. Researchers tested the performance of their contribution in terms of success percentage and failure probability. Although interesting, well explained and presented, the work should be more appropriately evaluated in terms of failure (or success) percentage and time required for taking into account the change in the price of a cloud computing service that provides the best service (since a real-time response is just a very rapid answer).
Sharma et al. (2016b) proposed an approach to predict the parameters that support (attract or motivate) cloud computing adoption. As a first step to reach their objective, the researchers improved two techniques, which rely on multiple linear regressions and on neural networks. Even though the authors tested the two improved techniques via study cases, they did not find the same order of importance of the parameters (for the same set of criteria at the beginning). Moreover, the authors did not analyze the reasons behind such a difference.
Li et al. (2017) proposed a decision method in conjunction with the multiple choice method in order to compose cloud computing services for previously determined purposes (cloud manufacturing). To do so, researchers first determined their selection criteria. In other terms, they stated how a single service would be evaluated. Then, the authors used neural networks, fuzzy logic, hierarchic analysis process, TOPSIS, etc., in order to select, compose and evaluate cloud computing services composition. Although their work is well explained, illustrated and presented, researchers nevertheless ignored a performance evaluation of the proposed contribution, as well as the comparison with other similar approaches. Furthermore, this article is not recommended for a researcher who is not an expert in the used methods, since certain implicitness was detected in relation to combinations of the latter.
Alipoufard et al. (2017) proposed a full system selecting IaaS cloud computing instances for big data analyses. To do so, researchers used statistical learning and Bayesian optimization. The work is well explained, nicely illustrated and rigorously presented. Moreover, the authors could experiment on real examples of IaaS cloud computing services and could also evaluate the performances of their approach, but they did not deem it necessary to compare their contribution to similar works. However, the article is still recommended to any researcher interested in cloud computing services selection using statistical learning or Bayesian algorithms.
Wassim et al. (2018) proposed an analysis of the factors using unsupervised machine learning in order to evaluate cloud computing services. For this purpose, researchers considered two types of quality metrics, the first being customer feedback and the second server feedback. Then they analyzed the criteria of cloud computing services based on machine learning. They used customer feedback in order to have objective and subjective quality measures. At the end, they were able to rigorously calculate a score for cloud computing services. This contribution is very well explained and the authors’ efforts to evaluate their approach are worth mentioning. However, the researchers did not compare their work to similar works.
The works quoted in this section are not an exhaustive list of scientific articles in the selection of cloud computing services using machine learning. Given the wide extent of AI in the world of computer science, it is impossible to mention all the articles, but it can be noted that they all ignore the time required for learning. Researchers are often not interested in evaluating the time required for learning in their approaches. In other terms, researchers have a tendency to evaluate their proposed approaches in terms of success rate (very often), accuracy (quite often), failure rate (not frequent), but they consistently ignore the evaluation of the time required for their approaches to learn.
5.4.2. Heuristics
In order to solve problems related to optimization, research or both, certain researchers use heuristics and metaheuristics. It is worth noting that in everyday life human beings eliminate certain cases during their researches in order to save time. Knowing that the eliminated solutions may be correct (valid) and/or optimal, such situations are generally eliminated for lack of time. It is the very principle of heuristics.
Gao et al. (2012) proposed a technique for balancing the loads of processes between mobile customers and their services in a computerized cloud. For this purpose, researchers first reviewed several required theoretical concepts (such as Cloudlet, Coordinated Mobile Device, etc.). Then, they presented their model. This has the characteristics of processes, networks, etc. After that, they proposed an algorithm with heuristics aimed at balancing the loads of processes for customers and services. The algorithm produces offloading plans verifying certain previously established utility functions. Heuristics distinguishes between an optimal and a less optimal solution during the research. Taking a look at the contribution performance tests conducted by the authors themselves, it can be noted that the approach was not compared to other similar approaches. Moreover, researchers ignored energy consumption on both sides (customer and server), cost of service in computerized cloud, etc. The work is nevertheless interesting. Consequently, it is recommended to any researcher interested in load balancing (in cloud computing, grid computing, etc.).
Nacsimento et al. (2016) proposed an improvement and a facilitation of the scaling of virtual instances in computerized clouds. For this purpose, they first investigated the efficiency of machine learning techniques for scaling up. Then, they proposed a set of heuristics to improve the learning algorithms. However, the objective to be optimized is not very clear (such as the time for starting the virtual instance, maximization of the number of virtual machines for each physical machine, etc.). It is also worth noting that the work was neither compared, nor evaluated, but the authors made an effort to thoroughly explain the problem and conduct a case study.
Hoang et al. (2016) proposed an approach to customer query management in a cloud computing environment, relying on ant colony heuristics and the particle swarm optimization (PSO). For this purpose, researchers first established several objectives (they can play the role of utility functions) as follows: system overall cost minimization, meeting the measures of quality of service and profit maximization for cloud computing services providers. The work is well explained, nicely illustrated, evaluated, but it was not compared to other similar approaches. The article is nevertheless interesting and it is highly recommended to researchers interested in customer query planning, scheduling and management in a cloud computing environment.
Similarly, Xue et al. (2016) proposed an approach to process scheduling in a computerized cloud. Relying on PSO and heuristics, researchers set a single objective, namely maximization of the quality of service. The authors made an effort to explain their work, evaluate their approach and compare their contribution to similar ones. However, researchers expressed their objective (maximization of the quality of service) in terms of minimization of the total time of customer query execution, while the quality of service can be the minimization of the average time for customer task completion.
Moreover, Samieifar and Mardukhi (2017) proposed an approach aiming at the dynamic resource allocation in a computerized cloud. Assuming the problem was NP-Hard, researchers proposed a metaheuristic combining genetic algorithms and colonial competition. The authors explained the concepts very well, appropriately illustrated the architecture and the research context, and compared their contribution to similar works. Even though the authors took into account the execution time and the cost of services, a researcher can evaluate its approach in terms of services resources consumption. Consequently, this work is recommended to any researcher willing to contribute to the allocation of resources in computerized clouds.
Finally, Hajlaoui et al. (2017) proposed a system discovering and selecting IaaS cloud computing services. For this purpose, they introduced two heuristics, namely Hungarian and Volgenant-Jonker algorithms. Then, they used the graph theory, linear programming, as well as symmetric linear transformation in order to calculate the quality of the discovered services. Finally, to prove the efficiency of their approach, the authors compared the employed concepts, instead of the proposed approaches. The article is however interesting, and recommended for any researcher willing to contribute to the discovery and/or selection of cloud computing services.
This section presented several works using heuristics or metaheuristics for the selection, evaluation, composition or discovery of cloud computing services. This list of contributions is far from being exhaustive, but offers examples of ideas for future researches. Moreover, it is worth noting that works proposing one or more heuristics ignore one aspect. In general, researchers do not compare the approaches using their proposed heuristics to approaches using standard heuristics (already proposed in the literature). The purpose is to separately evaluate the heuristics and the algorithm.
5.4.3. Intelligent multiagent systems
Intelligent multiagent systems are the first alternative used by AI researchers in studying the impact one agent has on the others. As an example, let us consider N intelligent customer agents and M intelligent agents providing cloud computing services. Let us assume that among the proposed services, a provider has a prominent position due to its optimal quality and reduced price (denoted by mi). The demands of N customer agents for the service offered by mi are increasing.
Consequently, the provider needs to take precautions (or measures, in general) to prevent their servers from being overloaded. For example, it can add material servers (which tends to increase the price), or increase the number of virtual servers for each physical machine (which tends to lower the quality of service), etc. In all cases, the measures taken may affect the customers, who may choose another provider.
This is a simple example among others of intelligent multiagent systems applications in the selection of cloud computing services. This section presents several contributions using AI and multiagent systems for the discovery, selection, evaluation or composition of cloud computing services.
Rabbani et al. (2014) proposed a method that uses intelligent agents for the selection of cloud computing services. As researchers noted, if sufficiently trained, the agents would at the end be able to observe the similarities and differences between services and select them. Given that the objective was to best meet the customer requirements, it would be interesting to see the evaluation of such an approach in terms of learning time, relevance of results, etc., but the authors do not provide an evaluation or comparison of their work.
Chichin et al. (2014) proposed an intelligent agent-based market for cloud computing services. Their principle relies on the simulation of cases by intelligent agents (software) according to several policies, various situations, etc. If a customer wants to use the proposed platform, the authors recommend the agent that is best adapted to its needs and situation.
This work is quite remarkable, given that researchers evaluated their approach and compared it to several other similar contributions. Moreover, the comparison criteria are diverse and varied. This article is highly recommended to any researcher willing to contribute to the selection of cloud computing services using intelligent agents.
Lacheheub et al. (2016) proposed an approach to cloud computing services selection, relying on intelligent agents. First, the agents discover cloud computing services gradually. Then, each agent hierarchically groups them. Therefore, the customers select services that are closest to their former services (provider change) or their local applications (migration to computerized clouds).
Among all surveyed contributions, Lacheheub and Maamrin (2016) is the best in terms of explanation, illustrations and evaluation. Besides explaining and illustrating their approach, the authors studied an example, unfolded the process to be followed (from mathematical, graphical and linguistic perspectives), evaluated their approach and compared it to other contributions. Consequently, this article is recommended to any researcher willing to contribute to the selection of cloud computing services using intelligent agents.
Jahani et al. (2017) proposed a system known as ARank, selecting the cloud computing services and relying on intelligent multiagents system. First, each agent takes several cloud computing services. Then, each agent evaluates its candidates according to the quality of service. Their evaluation includes the customer level of satisfaction history for each cloud computing service. The principle is easy to understand, as the authors thoroughly explain the concept. However, there is a certain inconsistency between objective and evaluation (comparison between the proposed approaches, Analytic Hierarchy Process (AHP)) Singular Value Decomposition (SVD). As the researchers state, the customer’s wait time is optimized, as they compare their contribution to others in terms of evaluation time with respect to the total number of cloud computing services. In this case, the reader may understand that services are not evaluated at the selection moment, but that the opposite is true.
5.4.4. Game theory
Mathematical and/or computing problems are often expressed in the form of games following a mathematical model for the study of decision makers in their environments. The predator–prey model is a good start in understanding the interest of game theory. Let us consider the example of a determined area containing a predator set and a prey set. It can be immediately noted that the two groups of players are competing. For example, lions hunt buffalos and they are competing. Lions cannot do without hunting, as it is a matter of survival. Buffaloes have to protect themselves to avoid extinction or herd weakness. Therefore, the predator is always confronted with its prey resistance, to which they are beneficial. If buffaloes stopped defending themselves, the lions would more easily and frequently attack the herd. Consequently, the herd would be weakened or become extinct. In these cases, if the buffalo do not become extinct, they will be forced to migrate to a safer place. This renders them vulnerable during the trip and weakens the predating lions (the latter have fewer sources of nutrition). On the other hand, if the lions stopped hunting buffaloes, they would certainly become extinct and buffaloes would have more chances to reproduce and strengthen their herd. But, buffaloes are also predators for other species in the studied area. If their sources of nutrition become insufficient, they would also become extinct.
Game theory is not limited to the simple study of the decision maker (either in a game or in reality). It also studies the impact of a decision on the players (the other decision makers) in the same environment (case of sharing material resources in a computerized cloud).
Hassan et al. (2014) proposed an approach allocating cloud computing resources in a context of dynamic horizontal federation of computerized clouds. For this purpose, the researchers first presented the architecture of a system for horizontal and dynamic federation of cloud computing services. Then they studied two cases of utility function maximization for resource allocation according to the presented context. They next proposed an algorithm that selects resources depending on their prices. The work is well presented, illustrated and explained, but the authors did not find it necessary to include a comparison of their approach with already existing contributions. Moreover, their evaluation (utility function maximization, social wellbeing maximization, minimization of the number of virtual machines per cloud computing provider, etc.) does not match the objectives of their approach (robustness maximization and time reduction).
Do et al. (2015) presented an interclient cooperation model for the selection of the best cloud computing service. For this purpose, they first divided the set of customers into groups. Then, they set things such that each customer randomly chooses a provider at the start. After that, each customer communicates the characteristics of his/her provider to other customers that belong to the same group. At this moment, the discovered phase is completed and the customers have to change their provider if they are communicated the characteristics of a better one. Given that the study aimed to present a comprehensive definition of the heterogeneous cloud computing services markets, in our opinion the objective was largely fulfilled, as the researchers proposed a mathematical modeling of the problem, as well as a numerical evaluation. Therefore, the authors did not deem it necessary to compare their approach to other similar works (if they still exist).
Ardagna et al. (2015) proposed an approach to income maximization and cost minimization for providers of SaaS cloud computing services, who in turn are customers of IaaS cloud computing services. For this purpose, they proposed a Nash game model in which providers of SaaS cloud computing services bet on the resources allocated at IaaS level. Researchers could prove the existence of a certain Nash equilibrium point, and the fact that convergence occurs in a limited number of iterations. Therefore, the authors mentioned that they compared their approach to other similar techniques in the state of the art, but we could not find it in the paper. The researchers just evaluated the quality of service during a certain lapse of time.
Liu et al. (2016) proposed a study of the impact of invoicing model communication on the speed of convergence toward equilibrium state in a provider/customer environment in a computerized cloud. For this purpose, researchers first formalized the problem and presented the Stackelberg game model. Then, they presented strategies that are optimal for both customers and providers in order to maximize their utility (the authors also proved such strategies are optimal). Therefore, they could reach the Stackelberg equilibrium point by unfolding optimal strategies presented in a computerized cloud environment. Finally, the researchers modified several parameters of the simulation in order to see the impact on the equilibrium and the time required for its attainment. Nevertheless, a comparison with similar approaches or at least a Nash game-based approach would be highly appreciated.
Wu et al. (2016) proposed a mechanism for resource allocation in self-organized computerized clouds. For this purpose, the researchers proposed two new economic strategies allocating resources based on architecture and prices. More specifically, they used the modified Vickrey double auction when resources were sufficient and the continuous double auction when resources were insufficient. Despite the authors’ remarkable explanation, they did not deem it necessary to compare their approach with other similar techniques. Furthermore, the researchers evaluated their contribution in terms of cost for resource procurement with respect to the number of providers and execution efficiency. However, there are many other important parameters such as procurement delay, the number of virtual machines compared to the number of physical machines, etc.
This section presented a set of works in the selection of cloud computing services relying on AI in game theory. It is worth noting that collective intelligence is involved, since the majority of contributions consider customers and/or providers as players. Each has an objective to achieve and they must share the same material resources. In technical terms, researchers tried first to prove the existence of a certain point of equilibrium (explicitly or implicitly). Then they tried to find a way to reach it. Finally, the authors simply had to prove that the equilibrium point could be reached through a finite number of iterations (a more or less limited time). Some untapped research opportunities were highlighted, such as an equilibrium point not being manifest even though it previously existed, the heterogeneity of players (customers and/or providers), their final objectives, their strategies, etc.
Genetic algorithms are another example of AI techniques that were used for the selection of cloud computing services. They include algorithms such as the ant colonies algorithm (Gao 2014), the bee colonies algorithm (Tian et al. 2013; Seghir et al. 2016; Xu et al. 2017; Zhou and Yao 2017), the crow search algorithm (Satpathy et al. 2017), etc.
AI covers a broad range of methods, techniques and processes, in order to best address its problems. It is beyond the scope of this chapter to mention all the contributions in the field, or even one contribution per each subdomain of AI.
5.5. Conclusion
This chapter presents a state of the art in the selection, composition, evaluation or recommendation of cloud computing services using AI. It offers an overview of the problems considered, approaches followed and tools used in the two domains, with the mention that such survey studies are seldom precise and/or detailed.
Our near-future objective is to focus on a comparison in addition to the survey so that the reader would have access to the performance test results of the surveyed approaches (besides the critical review).
A further objective is to integrate the limits of AI in the selection of cloud computing services. In other words, it is our intent to integrate the impact of AI limits on the surveyed studies.
Moreover, given the broad range of game theory-based works, a more in-depth survey of the latter is intended. As an example, the bidirectional bet technique is often used in game theory through AI.
5.6. References
Ahmad, I., Bakht, H., and Mohan, U. (2017). Cloud computing – A comprehensive definition. Journal of Computing and Management Studies (JCMS). 1(1), 1–8.
Ahmed, U., Raza, I., and Hussain, S.A. (2019). Trust evaluation in cross-cloud federation: Survey and requirement analysis. ACM Computing Surveys (CSUR), 52(1), 19.
Aishwarya, S. and Muzammil, H. (2017). Pricing schemes in cloud computing: a review. International Journal of Advanced Computer Research, 7(29), 60.
Alipourfard, O., Liu, H. H., Chen, J., Venkataraman, S., Yu, M., and Zhang, M. (2017). Cherrypick: Adaptively unearthing the best cloud configurations for big data analytics. Symposium on Networked Systems Design and Implementation (NSDI). 27–29 March. Boston. USA.
Andrikopoulos, V., Song, Z., and Leymann, F. (2013). Supporting the migration of applications to the cloud through a decision support system. IEEE Sixth International Conference on Cloud Computing. IEEE, Santa Clara, 565–572.
Ardagna, D., Ciavotta, M., and Passacantando, M. (2015). Generalized Nash equilibria for the service provisioning problem in multi-cloud systems. IEEE Transactions on Services Computing, 10(3), 381–395.
Beloglazov, A., Abawajy, J., and Buyya, R. (2012). Energy-aware resource allocation heuristics for efficient management of data centers for cloud computing. Future Generation Computer Systems, 28(5), 755–768.
Chichin, S., Chhetri, M.B., Vo, Q.B., Kowalczyk, R., and Stepniak, M. (2014). Smart cloud marketplace-agent-based platform for trading cloud services. IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT). IEEE/WIC/ACM, Warsaw, Poland.
Crevier, D. (1993). AI: The Tumultuous History of the Search for Artificial Intelligence. Basic Books, New York.
Das, A.K., Adhikary, T., Razzaque, M.A., Cho, E.J., and Hong, C.S. (2014). A QoS and profit aware cloud confederation model for IaaS service providers. 8th International Conference on Ubiquitous Information Management and Communication. ACM, Siem Reap.
Do, C.T., Tran, N.H., Huh, E.N., Hong, C.S., Niyato, D., and Han, Z. (2015). Dynamics of service selection and provider pricing game in heterogeneous cloud market. Journal of Network and Computer Applications, 69, 152–165.
Domingos, P. (ed.) (2015). How does your Brain Learn? The Master Algorithm: How the quest for the ultimate learning machine will remake our world. Basic Books, New York.
Foss, B. and Dodwell, P.C. (1966). New Horizons in Psychology. Penguin Books, London.
Gao, B., He, L., Liu, L., Li, K., and Jarvis, S.A. (2012). From mobiles to clouds: Developing energy-aware offloading strategies for workflows. ACM/IEEE 13th International Conference on Grid Computing. ACM/IEEE, Beijing.
Gao, Z. (2014). The allocation of cloud computing resources based on the improved ant colony algorithm. Sixth International Conference on Intelligent Human-Machine Systems and Cybernetics. IHMSC, Hangzhou.
Gupta, S., Muntes-Mulero, V., Matthews, P., Dominiak, J., Omerovic, A., Aranda, J., and Seycek, S. (2015). Risk-driven framework for decision support in cloud service selection. 15th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing. IEEE/ACM, Shenzhen.
Hajlaoui, J.E., Omri, M.N., Benslimane, D., and Barhamgi, M. (2017). QoS based framework for configurable Iaas cloud services discovery. IEEE International Conference on Web Services (ICWS). IEEE, Hawaii.
Hassan, M.M., Hossain, M.S., Sarkar, A.J., and Huh, E.N. (2014). Cooperative game-based distributed resource allocation in horizontal dynamic cloud federation platform. Information Systems Frontiers, 16(4), 523–542.
Hayes, B. (2008). Cloud computing. Communications of the ACM, 51, 9–11.
Hoang, H.N., Le Van, S., Maue, H.N., and Bien, C.P.N. (2016). Admission control and scheduling algorithms based on ACO and PSO heuristic for optimizing cost in cloud computing. In Studies in Computational Intelligence, Hoang, H.N., Le, V.S. et al. (eds). Springer, Berlin.
Jahani, A., Derakhshan, F., and Khanli, L.M. (2017). A Rank: A multiagent based approach for ranking of cloud computing service. Scalable Computing: Practice and Experience, 18(2), 105–116.
Kang, D.S., Liu, H., Singh, M.P., and Sun, T. (2013). Adaptive process execution in a service cloud: Service selection and scheduling based on machine learning. IEEE 20th International Conference on Web Services. IEEE, Santa Clara.
Kaplan, A. and Haenlein, M. (2019). Siri, Siri, in my hand: Who’s the fairest in the land? On the interpretations, illustrations, and implications of artificial intelligence. Business Horizons, 62(1), 15–25.
Lacheheub, M.N. and Maamrin, R. (2016). Towards a construction of an intelligent business process based on cloud services and driven by degree of similarity and QoS. Information Systems Frontiers, 18(6), 1085–1102.
Le, S., Dong, H., Hussain, F.K., Hussain, O.K., Ma, J., and Zhang, Y. (2014). Multicriteria decision making with fuzziness and criteria interdependence in cloud service selection. International Conference on Fuzzy Systems (FUZZ-IEEE). IEEE, Beijing.
Legg, S., and Hutter, M. (2007). A collection of definitions of intelligence. Frontiers in Artificial Intelligence and Applications, 157, 17.
Li, L., Hang, J., Sun, H., and Wang, L. (2017). A conjunctive multiple-criteria decision-making approach for cloud service supplier selection of manufacturing enterprise. Advances in Mechanical Engineering, 9(3), 1–15.
Liaqat, M., Chang, V., Gani, A., Ab Hamid, S.H., Toseef, M., Shoaib, U., and Ali, R.L. (2017). Federated cloud resource management: Review and discussion. Journal of Network and Computer Applications, 77, 87–105.
Liu, C., Wang, S., Wang, C., Bie, R., and Shin, D. (2016). Stackelberg game based optimal workload allocation and pricing mechanism in crowdsourcing. 2016 IEEE International Conferences on Big Data and Cloud Computing (BDCloud), Social Computing and Networking (SocialCom), Sustainable Computing and Communications (SustainCom) (BDCloud-SocialCom-SustainCom). IEEE, Atlanta.
Mandal, A.K., Changder, S., and Sarkar, A. (2013). Selection of services for data-centric cloud applications: A QoS based approach. International Conference on Advanced Computing, Networking and Security. IEEE, Mangalore, 102–107.
McCorduck, P. (2009). Machines Who Think: A Personal Inquiry into the History and Prospects of Artificial Intelligence. AK Peters/CRC Press, Natick.
Mell, P. and Grance, T. (2011). The NIST definition of cloud computing. Computer Security Division, Information Technology Laboratory, National Institute of Standards and Technology, 800(145), 1–7.
Michael, A., Armando, F., Rean, G., Anthony, J., Randy, K., Andy, K., Gunho, L., David, P., Ariel, R., Ion, S., Matei, Z. (2010). A view of cloud computing. Communications of the ACM, 53(4), 50–58.
Nascimento, D.C., Pires, C.E., and Mestre, D.G. (2016). Applying machine learning techniques for scaling out data quality algorithms in cloud computing environments. Applied Intelligence, 45(2), 530– 548.
Nilsson, N.J. (1998). Artificial Intelligence: A New Synthesis. Morgan Kaufmann, Burlington.
Pandey, G., Rao, V. N., Srivastava, A. K., Banerjee, U., and Narasimhan, E. (2011). Current cloud scenario review and cost optimization by efficient resource provisioning. The Fourth Annual ACM Bangalore Conference. ACM, Bangalore.
Papathanasiou, J., Kostoglou, V., and Petkos, D. (2015). A comparative analysis of cloud computing services using multicriteria decision analysis methodologies. International Journal of Information and Decision Sciences, 7(1), 51–70.
Poole, D., Mackworth A., Goebel R. (1998). Computational Intelligence: A Logical Approach. Oxford University Press, New York.
Rabbani, I.M., Muhammad, A., and AM, M.E. (2014). Intelligent cloud service selection using agents. 9th International Conference on Computing and Information Technology (IC2IT2013). IC2IT, Bangkok.
Rehman, Z.U., Hussain, O.K., and Hussain F.K. (2012). Iaas cloud selection using MCDM methods. IEEE 9th International Conference on e-Business Engineering. IEEE, Hangzhou.
Rehman, Z.U., Hussain, O.K., and Hussain, F.K. (2014). Time series QoS forecasting for management of cloud services. Ninth International Conference on Broadband and Wireless Computing, Communication and Applications. IEEE, Guangdong.
Russel, S.J. and Norvig, P. (2016). Artificial Intelligence: A Modern Approach. Pearson Education Limited, Harlow.
Samieifar, S. and Mardukhi, F. (2017). Dynamic resource allocation in cloud computing using a combination of meta-heuristic algorithms. International Journal of Computer Science and Network Security (IJCSNS), 17, 332.
Satpathy, A., Addya, S.K., Turuk, A.K., Majhi, B., and Sahoo, G. (2017). A resource aware VM placement strategy in cloud data centers based on crow search algorithm. 4th International Conference on Advanced Computing and Communication Systems. ICACCS, Coimbatore.
Schank, R.C. (1991). Where’s the AI? AI Magazine, 12(4), 38–38.
Seghir, F., Khababa, A., Gaber, J., Chariete, A., and Lorenz, P. (2016). A new discrete imperialist competitive algorithm for QoS-aware service composition in cloud computing. The International Symposium on Intelligent Systems Technologies and Applications. ISTA, Jaipur.
Sharma, S.K., Al-Badi, A.H., Govindaluri, S.M., and Al-Kharusi, M.H. (2016a). Predicting motivators of cloud computing adoption: A developing country perspective. Computers in Human Behavior, 62, 61–69.
Sharma, Y., Javadi, B., Si, W., and Sun, D. (2016b). Reliability and energy efficiency in cloud computing systems: Survey and taxonomy. Journal of Network and Computer Applications, 74, 66–85.
Singh, P., Dutta, M., and Aggarwal, N. (2017). A review of task scheduling based on meta-heuristics approach in cloud computing. Knowledge and Information Systems, 52(1), 1–51.
Sun, L., Dong, H., Hussain, F.K., Hussain, O.K., and Chang, E. (2014). Cloud service selection: State-of-the-art and future research directions. Journal of Network and Computer Applications, 45, 134–150.
Syntec Numérique (2012). Cloud Computing: nouveaux modèles! White Book, Syntec Numérique, Paris.
Tian, S., Liu, Q., Xu, W., and Yan, J. (2013). A discrete hybrid bees algorithm for service aggregation optimal selection in cloud manufacturing. 14th International Conference on Intelligent Data Engineering and Automated Learning. IDEAL, Hefei.
Wang, X., Cao, J., and Xiang, Y. (2015). Dynamic cloud service selection using an adaptive learning mechanism in multi-cloud computing. Journal of Systems and Software, 100, 195–210.
Wasim, M.U., Ibrahim, A.A., Bouvry, P., and Limba, T. (2018). Cloud service providers optimized ranking algorithm based on machine learning and multi-criteria decision analysis. Preprints, 2018010125 (doi: 10.20944/preprints201801.0125.v1).
Whaiduzzaman, M., Gani, A., Anuar, N.B., Shiraz, M., Haque, M.N., and Haque, I.T. (2014). Cloud service selection using multicriteria decision analysis. The Scientific World Journal (TSWJ). 459375, 1–10.
Wu, X., Liu, M., Dou, W., Gao, L., and Yu, S. (2016). A scalable and automatic mechanism for resource allocation in selforganizing cloud. Peer-to-Peer Networking and Applications, 9(1), 28–41.
Xu, X., Liu, Z., Wang, Z., Sheng, Q. Z., Yu, J., and Wang, X. (2017). S-ABC: A paradigm of service domain-oriented artificial bee colony algorithms for service selection and composition. Future Generation Computer Systems, 68, 304–319.
Xu, Y., Li, M., Hu, X., Wang, Y., and Zhang, H. (2016). Survey on privacy preserving for intelligent business recommendation in cloud. In Wireless Communications, Networking and Applications, Shi, G. and Ming, Y. (ed.). Springer India, New Delhi.
Xue, S., Shi, W., and Xu, X. (2016). A heuristic scheduling algorithm based on PSO in the cloud computing environment. International Journal of u- and e-Service, Science and Technology, 9, 349–362.
Zhou, J. and Yao, X. (2017). A hybrid artificial bee colony algorithm for optimal selection of QoS-based cloud manufacturing service composition. The International Journal of Advanced Manufacturing Technology, 88(9/12), 3371–3387.