
6
A Comparison of Machine Learning and Deep Learning Models with Advanced Word Embeddings: The Case of Internal Audit Reports
Gustavo FLEURY SOARES1 and Induraj PUDHUPATTU RAMAMURTHY2
1 Brazilian Office of the Comptroller General (CGU), Brazil
2 CYTech, Cergy, France, and University of India, India
When conducting an audit, the ability to make use of all the available information relating to the audit universe or subject could improve the quality of results. Classifying text documents in the audit (unstructured data) could enable the use of additional information to improve existing structured data, leading to better knowledge to support the audit process. To provide better automated support for knowledge discovery, natural language processing (NLP) could be applied. This chapter compares the results of classical machine learning and deep learning algorithms, combined with advanced word embeddings in order to classify the findings of internal audit reports.
6.1. Introduction
Internal Audits, as defined by the IIA (2012), are “an independent, objective assurance and consulting activity designed to add value and improve an organization’s operations”. To achieve this, the internal auditor endeavors to collect all available information relating to the organization – internal or external. This can be in the form of either structured or unstructured data, which the auditor analyzes in order to provide useful insights. Considering the volume of data created nowadays, it is crucial for data tools to be used efficiently.
Data science is widely used in the areas of finance and accounting, evidenced by various related articles and research work. Typically, a number of different financial parameters are used for fraud detection. However, over the last decade, research has been conducted using NLP by making use of textual information. Auditing, however, is behind in making use of these methods, compared to other lines of research (Gepp et al. 2018).
Deep learning (DL), undoubtedly the driving force behind artificial intelligence, has accelerated the quality of automated systems, employing deep hierarchical neural networks within which complex and abstract features – mostly unidentifiable by classic machine learning (ML) algorithms – are easily detectable. Use of textual analytics that leverage the power of DL is continuing to grow within the field of auditing, in particular for the automation of fraud detection. The auditing profession has recognized the need for textual big data analysis in order to enhance the quality and relevance of audits (EY_Reporting 2015). Deloitte, one of the Big Four audit firms, uses DL within its “document review” platform which it has developed in-house. Similarly, EY (formerly Ernst & Young) uses applied artificial intelligence (AI) for the analysis of lease contracts. It is important to note that EY’s fraud detection system has 97% accuracy according to a Forbes report. Furthermore, Deloitte’s “Kira” platform is used within its audit business, under the name D-ICE. In view of the novel methods used by fraudsters, 84% of financial statement preparers, 76% of audit committees and 70% of financial statement users who participated in Deloitte’s Audit of the Future Survey 2016 expressed the need for advanced technologies (EY_Reporting 2015).
As auditing becomes more prevalent, and an increasing number of financial fraud instances is being exposed, the techniques used for committing this type of fraud are becoming more advanced and more prolific. The most common technique, used to deceive stakeholders and other associated entities, was impression management (Jaafar et al. 2018). However, since most firms tend to engage in impression management (as a means of enhancing and engaging in retrospective sensemaking regardless of financial position), tracking fraudulent firms by using their impression management techniques is difficult.
In general, a mass of documents in the real word are not labeled or only a small portion have been classified. The need to apply unsupervised or semi-supervised algorithms to these documents – to automatically classify them as fraudulent or non-fraudulent – is therefore mandatory. However, the complexity of grouping these documents and the risk of misclassification remain.
A number of works in ML, DL and textual data have been suggested to identify fraudulent firms using standard financial ratios. However, writing styles, assessment techniques, analysis techniques and reporting procedures all vary. Therefore, in the case of internal auditing, only focusing on financial aspects in an attempt to isolate areas that require further investigation – addressing discrepancies and implementing corrective action – is not possible.
Consequently, in this chapter, we only use textual information in combination with state-of-the-art techniques that have been developed in recent years. We present an extensive comparison of different combinations of machine learning algorithms with advanced word embeddings. This comparison brings to light the fastest and most effective techniques for automating the process of identifying risky and non-risky sections within a document, or within a multitude of documents.
The automated classification of whole documents or content within documents as “risky” or “non-risky” will be an effective tool for auditors to create a risk ranking for documents or audit objects that require further manual analysis.
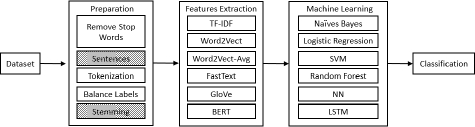
Our primary focus is comparing the performance of ML and DL models using classical word embedding techniques, for example bigram and TF-IDF. We also test performance using advanced state-of-the-art word embeddings such as Word2Vec, Word2Vec-Avg, FastText and GloVe. We demonstrate our experiments using classical ML classification algorithms and DL models, namely, CNN (convolutional neural network), LSTM (long short-term memory) and BERT (Bidirectional Encoder Representations from Transformers).
This chapter is organized as follows. Section 6.2 discusses related works and briefly elaborates on word embeddings, classical ML and DL model architecture, indicating the most common algorithms and recent related research. Section 6.3 outlines the experiments and provides an evaluation. Results, conclusions and future work are addressed in section 6.4.
6.2. Related work
To process textual information using computer technology, several different NLP approaches can be used, the simplest being the one where the textual input is represented by a vector of weighted word counts (Manning and Schütze 1999). Feature representation based on the Bag of Words (BoW) model or exquisitely designed patterns are typically extracted as features; nevertheless these feature representation methods ignore word order, and thus, contextual information as well. Considering the curse of dimensionality posed by the BoW model, TF-IDF and Word2Vec is a better choice for forming a word vector matrix. Word embeddings are efficient in capturing context similarity, that is, analogies, and have generated state-of-the-art results in a wide range of NLP tasks (Turney and Pantel 2010; Lilleberg et al. 2015; Cambria et al. 2017). Using Word2Vec yields more satisfactory results compared to TF-IDF in the random forest classifier when compared to logistic regression (Waykole and Thakare 2018). Furthermore, these authors suggest experimentation using the GloVe word embedding, which we include in our research.
Classical ML techniques like the artificial neural network (ANN) and the decision tree (DT) were used by Albashrawi (2016), along with auditor opinions and other financial variables; these included the company’s liquidity ratio and its operating efficiency, which were subjected to Kolmogorov–Smirnov, Shapiro–Wilk and Mann–Whitney tests. Another research experiment using DT, NN and the Bayesian belief network was conducted on a dataset comprising 76 Greek manufacturing firms, 38 of which were classified as fraudulent by the auditors. The neural classifier had 100% accuracy (Desai and Deshmukh 2013).
Another study used data mining techniques such as the multilayer feed forward (MLFF) neural network, support vector machines (SVM), genetic programming (GP), group method of data handling (GMDH), logistic regression (LR) and the probabilistic neural network (PNN) on 202 Chinese firms with and without feature selection (Ravisankar et al. 2011). Similarly, Yim (2011) took account of the financial ratios of 100 Turkish firms and used classifiers such as the decision tree and NN.
Yim (2011) adapted a new approach to labeling which involves fraud scoring. Fraud scoring assignments conducted on 72 firms were used to label them as either fraudulent or non-fraudulent. With nine financial properties, methods such as linear regression, NN, KNN, SVM, Decision Stump, M5P Tree and the Decision Table were tested. Random forest was found to be the best performing model (Yim 2011).
Abulaish and Sah (2019) propose a data augmentation approach with n-grams, the Latent Dirichlet Allocation (LDA) technique and the DL technique of a CNN to identify class specific phrases for enrichment of the underlying corpus to increase classifier performance; this approach enriches the corpus based on class labels.
Certain research (Mahmoud Hussein 2016) has suggested that the non-stemmed corpus achieved 87.79% and 88.54% accuracy with SVM and Naive Bayes, respectively. In contrast, the stemmed corpus achieved lower accuracy of 84.49% and 86.35%. Hence, we try traditional machine learning algorithms with stemmed and non-stemmed corpuses in order to verify their performance in the case of internal audit document classification.
The DL models prove to be more suitable than the classical ML for text classification (Yin et al. 2017; Young et al. 2017; Menger et al. 2018) and compares NN, NB, SVM, DT with Recurrent Neural Network (RNN) and CNN using bigram, TF-IDF, word embedding and document embedding. RNN was found to outperform other techniques, and the same holds true for other researchers (Yin et al. 2017). Fair comparison of Word2Vec, CNN, Gated Recurrent Unit (GRU) and long short-term memory (LSTM) in sentiment analysis of Russian tweets was conducted (Arkhipenko et al. 2016) and it was found that GRU outperforms LSTM and CNN, while Chung (2014) and Jozefowicz and Zaremba (2015) state that there is no clear winner between GRU and LSTM.
The bias problem posed by RNN can be alleviated by using an unbiased CNN model (Lai et al. 2015). The RNN captures text semantics via a tree structure but it is difficult to represent the relationship between two sentences using this structure. Although RNN can capture semantics of long text, later words are more dominant than earlier words, thus pose limitations during the capture of semantics of whole documents.
Data augmentations like synonym replacement, random insertion, random swap and random deletion are performed for smaller datasets and the performances of CNN and LSTM are compared (Wei and Zou 2019). However, our dataset is bigger and the maximum length of certain individual corpora approximates to 1 million characters.
Various metrics such as accuracy, precision, recall and F1 score are used by many researchers, depending on the problem addressed by modeling. Interestingly we find that accuracy is not a preferred performance measure for imbalanced datasets (Anand et al. 2010), because the classifier will result in high predictive accuracy. Hence, we consider other metrics such as precision, recall and F1 score, as well as accuracy, for evaluating the goodness of the classifier.
The two significant problems of data quality and data governance have to be taken into account (Claudiu et al. 2018); the use of data augmentation for text (Wei and Zou 2019) could lead to some improvement in quality, even for less intensive ML methods. In our dataset, we have highly imbalanced data, which needed oversampling before the ML classifier and DL models were trained.
Inspired by these research works, we experimented using classical ML algorithms such as Naive Bayes (NB), Logistic Regression (LR), NN, SVM and Random Forest; we also incorporated DL models such as CNN, LSTM and BERT. We tested these different algorithms with respect to different classical word feature extraction techniques, such as TF-IDF, Word2Vec, Word2Vec-Avg, as well as advanced word embedding techniques, namely, FastText and GloVe. The results of the training of machine learning models and deep learning models with different word embeddings are detailed in section 6.3.
6.2.1. Word embedding
As well as testing our algorithms with classical feature representations like Bag of Words (BoW) and TF-IDF, we test them using advanced word embedding like Word2Vec, Word2Vec-Avg, FastText and GloVe.
Word2vec focuses on increasing the quality of word representation while using the neural network language model with a linear projection layer and nonlinear hidden layers. Distributed representation of words learned by neural networks preserves linear regularities among words and is found to be better than Latent Semantic Analysis (LSA) and LDA (Mikolov et al. 2013). Word2Vec with a weighted average is a variation to try to improve the model. It is possible to use the TF-IDF parameter to measure the importance of the word in the context (Djaballah et al. 2019).
On the other hand, unlike Word2Vector, FastText is provided as a black box to the end user. However, Bojanowski et al. (2017) and Joulin et al. (2016a, 2016b) fairly depict their working principles. FastText is faster than any word embedding. It is possible to train it on more than one billion words in less than 10 minutes using a standard multicore CPU, and to classify half a million sentences into 312k classes in less than a minute (Joulin et al. 2016b).
The most recent word embedding method is known as GloVe (Global Vectors for Word Representation). Developed by Stanford (Pennington et al. 2014), it is an unsupervised learning algorithm for obtaining vector representations for words. It takes a corpus of text and intuitively transforms it into a matrix, formulated by considering the context in which the word appears. GloVe takes advantage of the global matrix factorization method (i.e. the LSA) and the local context window method (i.e. skip-gram).
6.2.2. Deep learning models
6.2.2.1. CNN architecture
A CNN is a multilayer neural network architecture, developed specifically for image classification by accepting two-dimensional (2D) input representing pixel and color channels of images. We adapt the CNN architecture for text classification where the input is a 1D sequence of features. We compute index mapping words to known embedding by parsing the data dump of pre-trained embeddings. This embedding index and word index are used further to compute the embedding matrix.
We built our five-layer CNN architecture with output filters set to 200 and the kernel size of each layer incrementing from two to six; each layer is followed by a pooling layer. The nonlinear function ReLu (rectified linear unit) is applied in all layers for faster convergence and for backpropagation. Finally, we used a flatten layer to flatten the outputs and feed them to a dense layer. The output layer is employed with the softmax function.
6.2.2.2. BERT architecture
Implementation of the BERT architecture is performed in two stages: pre-training and fine-tuning. At the pre-training stage, masked language modeling (MLM) and next sentence prediction (NSP) are used (Devlin et al. 2018). BERT is a bidirectional deep neural network model that is based on the Transformer architecture. A transformer only makes use of an attention mechanism and replaces the recurrent layers commonly used in encoder–decoder implementations (Vaswani et al. 2017). Transformers function in parallel and require fewer computing resources compared to RNN solutions. Our BERT implementation involved text preprocessing to add necessary tokens [CLS] and [SEP] for each text followed by BERT layer and pooling layer. The output layer has been implemented to make use of the sigmoid activation function.
6.2.2.3. LSTM architecture
Recurrent neural networks look at the current input xt as well as the previous output ht-1 at each time step, but they struggle to learn long-term dependencies; this has led to the development of the LSTM architecture. LSTM consists of a recurrent network with the main blocks of input and output, as well as three gates: the input gate, the output gate and the forget gate.
The block input receives the signal from the last recurrent block. The input gate is the new value from data, and the output gate is a filtered version of the block output. The forget gate applies a function to “forget” some elements. We used an embedding layer with an embedding size of 32, an embedding dimension of 300 with bidirectional LSTM layer and a flattening layer, followed by an output layer with a softmax activation function. For each case of word embeddings like GloVe and FastText, we extract the appropriate embedding weights and feed them into our architecture.
6.3. Experiments and evaluation
The internal audit reports of the Brazilian government are public and are available on the Internet as PDF files. Similarly, there is a significant amount previous output of information relating to the various sub-entities of the government which could add value.
In order to locate this information, we created a model defining the type and the limits of all of the data under consideration. Since the Brazilian Government Internal Audit Reports (CGU)1 uses JavaScript, it was not possible to simply use the “wget” tool to retrieve a list of links in order to download the documents. To download this data (typically PDF files, as mentioned) we used the Selenium Automation Framework, which comes with the headless web browser, PhantomJS. The next step was to parse the PDF files in order to retrieve the information needed. There are several different libraries and tools for converting PDFs to plain text files. We achieved the best results, in terms of performance and quality, with the Tika Parser from the Apache Software Foundation. As the reports were text in the PDFs, it was not necessary to perform the OCR process.
Each audit report contained one or more findings which were initially classified as “informação” (information), “constatação” (finding) and “conclusão” (conclusion). We parsed a total of 89k documents and compiled structured data by extracting the necessary segments from the documents with regex (regular expressions).
Due to the unavailability of a Brazilian Portuguese lemmatizer, we used stemming; identifying parts of speech for semantic processing was therefore not possible. Stemming leads to words in a sentence losing their contextual meaning and therefore, in this research, we consider both the stemmed and non-stemmed version of the corpora to verify the results in both cases.
We segmented our dataset of 89,000 documents by year, selecting 2016–2019 so as to work with the latest corpora and apply our tests to modern day scenarios.
As in fraud detection datasets, labels in audit report datasets are very imbalanced. The percentage of high risk findings is only 3% (approximately). When we use imbalanced datasets to train the standard ML algorithms, the data corresponding to the dominant class will influence the result and the result is not an accurate and representative of the whole dataset.
After oversampling the train dataset, we extracted features using the bag of words model, TF-IDF, Word2Vec and Word2Vec-Avg; we trained our ML models using techniques such as Naive Bayes, logistic regression, SVM, random forest and neural networks. As well as experimenting with classical feature extraction techniques, we also used popular word embeddings, namely, FastText and GloVe. The train and test sets were partitioned in the ratio of 70:30 and all of our ML models were trained and tested. To experiment with DL models, based on CNN and LSTM architectures discussed in the previous section, we again used FastText and GloVe word embeddings with the same dimensions. In addition, we also conducted tests using BERT by applying it to our scenario.
In the following paragraphs, we discuss experiments using classical ML techniques with classical word embeddings. At first glance, it could appear that random forest and neural network techniques are better, yet the results are in fact not good, as detailed below.
The random forest method achieved accuracy, precision, recall and an F1 score of 100% in the training set, which is better than any other algorithm. The test set had 78% accuracy and an F1 score of 6%. Such high accuracy alongside a very low F1 score can be explained by the fact that the dataset is very much imbalanced with more “low” risk labels than “high”, resulting in most of the test sets being correctly labeled “low” thus resulting in high accuracy; in reality, this is not a good result. The same is also true for other algorithms. The accuracy of logistic regression and SVM seems better than naive Bayes, but they also suffer from the same problem of model overfitting.
Table 6.1. Results for composition Extract Features and ML algorithms – Simple Extraction Features on NB, LR and SVM
|
Extracted Features |
Naive Bayes (NB) |
Logistic Regression (LR) |
Support Vector Machines (SVM) | ||||
Acc | F1 | Acc | F1 | Acc | F1 | ||
|
TF-IDF | Train | 0.51 | 0.51 | 0.51 | 0.53 | 0.61 | 0.67 |
Test | 0.48 | 0.06 | 0.51 | 0.06 | 0.44 | 0.06 | |
|
Word2Vector | Train | 0.66 | 0.63 | 0.94 | 0.94 | 0.94 | 0.95 |
Test | 0.70 | 0.11 | 0.88 | 0.21 | 0.88 | 0.21 | |
Train | 0.66 | 0.63 | 0.93 | 0.93 | 0.93 | 0.93 | |
Word2Vector-Avg | Test | 0.70 | 0.11 | 0.87 | 0.20 | 0.86 | 0.19 |
Table 6.2. Results for composition Extract Features and ML algorithms – Simple Extraction Features on RF, NN and LSTM
|
Extracted Features |
Random Forest (RF) |
Neural Network (NN) |
Long Short-Term Memory (LSTM) | ||||
Acc | F1 | Acc | F1 | Acc | F1 | ||
|
TF-IDF | Train | 1.00 | 1.00 | 0.99 | 0.99 | 1.00 | 1.00 |
Test | 0.78 | 0.06 | 0.80 | 0.06 | 0.80 | 0.06 | |
|
Word2Vector | Train | 1.00 | 1.00 | 0.99 | 0.99 | 0.86 | 0.85 |
Test | 0.97 | 0.18 | 0.94 | 0.27 | 0.88 | 0.09 | |
Train | 0.99 | 0.99 | 0.99 | 0.99 | 0.86 | 0.85 | |
Word2Vector-Avg | Test | 0.96 | 0.18 | 0.93 | 0.24 | 0.88 | 0.08 |
Table 6.3. Results for composition Extract Features and ML algorithms – FastText and GloVe Extraction Features on NB, LR and SVM
Extracted Features |
Naive Bayes |
Logistic Regression |
SVM | ||||
Acc | F1 | Acc | F1 | Acc | F1 | ||
| Train | 0.71 | 0.10 | 0.80 | 0.57 | 0.82 | 0.61 | |
Fastiext | Test | 0.97 | 0.30 | 0.93 | 0.21 | 0.94 | 0.24 |
| Train | 0.70 | 0.03 | 0.80 | 0.59 | 0.82 | 0.63 | |
GloVe | Test | 0.97 | 0.06 | 0.92 | 0.21 | 0.92 | 0.20 |
Table 6.4. Results for composition Extract Features and ML algorithms – FastText and GloVe Extraction Features on RF, NN and LSTM
|
Extracted Features |
|
RF |
NN |
LSTM | |||
Acc | F1 | Acc | F1 | Acc | F1 | ||
|
FastText | Train | 1.00 | 1.00 | 0.97 | 0.98 | 0.70 | 0.82 |
Test | 0.97 | 0.20 | 0.96 | 0.98 | 0.96 | 0.98 | |
|
GloVe | Train | 1.00 | 1.00 | 0.96 | 0.97 | 0.99 | 0.99 |
Test | 0.97 | 0.20 | 0.89 | 0.94 | 0.96 | 0.98 | |
Table 6.5. Results for composition Extract Features and ML algorithms – BERT
|
Extracted Features |
BERT NN | ||
Acc | F1 | ||
|
BERT | Train | 0.70 | 0.82 |
Test | 0.96 | 0.98 | |
The following confusion matrix exemplifies this result. From a total of 6,084, the predictions for “low risk” are 5,888 (97%) and just 196 for “high risk”. Hence, the accuracy of any given algorithm tends to be very high and yet other metrics come out very low.
|
True Category | |||
Low Risk | High Risk | ||
|
Assigned Category | Low Risk | TP = 4714 | FP =1174 |
High Risk | FN = 145 | TN = 51 | |
The major difference presented by the metrics of the training and test datasets exposes the overfitting of classical ML algorithms. The random forest technique presents a “perfect” classification for TF-IDF (accuracy, precision, recall and F1 score all are 100%). When applied to the test dataset, however, similarly good metrics are not produced. To prevent this overfitting, modifications could be made to the parameters of the algorithm or a different testing approach could be used.
We have shown that classical ML models, combined with different classical word embeddings, are not the best choice for automating the process of identifying particular sections within internal audit documents that may pose potential risks. However, significant improvements were observed when using advanced word embeddings with DL models. Training DL models such as CNN, LSTM and BERT with the advanced word embeddings FastText and GloVe produced better results without the problem of overfitting. We obtained better results in the training set and very similar results in the test sets without having to account for bias and variance. It is evident that CNN and LSTM both perform extraordinarily well compared to BERT and other algorithms. The choice of whether to use CNN or LSTM comes down to the speed of the algorithm. In our experiments, we found LSTM to be noticeably faster than CNN, but this does largely depend on the architecture of the deep learning model constructed. For the architecture presented in this chapter, we found LSTM to be better. It is important to note, however, that the training speed of both CNN and LSTM was quite a bit faster when using FastText as the word embedding.
6.4. Conclusion and future work
The results show that it is possible to use machine learning algorithms to discern the level of risk posed by audit findings. The best model can be used to automate classification of external reports to support ongoing audits or the selection of audit objects in annual planning.
The DL models prove to be more suitable than the classical ML techniques for this type of text classification. These results are corroborated by similar research work conducted by Young et al. (2017) and Yin et al. (2017). We have proved, however, that the accuracy of the model, as well as the F1 score, are significantly better when using recently released, advanced word embeddings such as GloVe and FastText. Furthermore, the classical ML approaches used are unable to create a good classifier model. Conversely, the DL models produced impressive metrics. The difference between CNN and LSTM is not statistically relevant. Therefore, in real-world applications, deciding which of the discussed DL methods to use depends largely on requirements relating to response time and available resources.
To train our models, we used a dataset spanning from 2016 to 2019, with approximately 17,000 occurrences. This dataset is in fact relatively small for training DL models. Our decision to use this filtered dataset was based on limited availability of computational resources. Training DL algorithms using larger datasets would likely result in the model producing an even better generalization.
The speed of the training model and the performance metrics are very important parameters that need to be considered in any research of this kind. In our research, we found that FastText with LSTM and CNN was faster when training the model – while also producing excellent performance metrics – whereas BERT took many hours of fine-tuning to achieve the text classification for our particular case, with equivalent performance metrics.
For this project, we used two strategies. In the first strategy, all the text was within a single audit finding as an individual training sample. In the second strategy, we divided each of the sentences within each audit finding into individual samples and labeled each one according to the category they fell under. However, initial comparison tests showed that the model trained using data prepared using the second strategy performed the worst. Further research could help in understanding the reason for these results.
In order to deal with label imbalance, we worked with oversampling which produced reasonably good results. Further study on the impact of other sampling methodologies to solve this type of imbalance could be interesting. The use of data augmentation for text, such as synonym insertion or evolutionary algorithms (Wei and Zou 2019), could lead to some improvement in quality, primarily for less intensive ML methods.
Other advanced ensemble algorithms could also be tried. Furthermore, fine-tuning the hyperparameters of the DL models would provide better performance. An important aspect would be to verify if the quality of model improves while keeping the time and computational cost justifiable.
As an extension to our research, hybrid DL architectures like CNN-BILSTM and LSTM-CNN can be used with model parameter tuning. Some research also suggests using a 2D max pooling layer with LSTM whereas we used 1D max pooling layers. Once lemmatizers for Portuguese become available, tokenizing the sentences with POS and using fine-tuned versions of text as inputs could provide newer dimensions to the results obtained.
6.5. References
Abulaish, M. and Sah, A.K. (2019). A text data augmentation approach for improving the performance of CNN. 11th International Conference on Communication Systems & Networks (COMSNETS), 625–630.
Albashrawi, M. (2016). Detecting financial fraud using data mining techniques: A decade review from 2004 to 2015. Journal of Data Science, 14, 553–570.
Anand, A., Pugalenthi, G., Fogel, G.B., Suganthan, P.N. (2010). An approach for classification of highly imbalanced data using weighting and undersampling. Amino Acids, 39, 1385–1391.
Arkhipenko, K., Kozlov, I., Trofimovich, J., Skorniakov, K., Gomzin, A., Turdakov, D. (2016). Comparison of neural network architectures for sentiment analysis of Russian tweets. Proceedings of the International Conference on Computational Linguistics and Intellectual Technologies, 50–58.
Bojanowski, P., Grave, E., Joulin, A., Mikolov, T. (2017). Enriching word vectors with subword information. Transactions of the Association for Computational Linguistics, 5, 135–146.
Cambria, E., Poria, S., Gelbukh, A., Thelwall, M. (2017). Sentiment analysis is a big suitcase. IEEE Intelligent Systems, 32(6), 74–80.
Chung, J., Gulcehre, C., Cho, K., Bengio, Y. (2014). Empirical evaluation of gated recurrent neural networks on sequence modeling. NIPS 2014 Deep Learning and Representation Learning Workshop [Online]. Available at: https://nips.cc/Conferences/2014/Schedule?type=Workshop.
Claudiu, B., Muntean, M., Didraga, O. (2018). Intelligent decision support in auditing: Big Data and machine learning approach. 17th International Conference on INFORMATICS in ECONOMY (IE 2018), Education, Research & Business Technologies, 425–430.
Desai, A.B. and Deshmukh, R. (2013). Data mining techniques for fraud detection. International Journal of Computer Science and Information Technologies, 4, 1–4.
Devlin, J., Chang, M.-W., Lee, K., Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 1, 4171–4186.
Djaballah, K.A., Boukhalfa, K., Boussaid, O. (2019). Sentiment analysis of Twitter messages using Word2vec by weighted average. Sixth International Conference on Social Networks Analysis, Management and Security (SNAMS), 223–228.
EY_Reporting (2015). How big data and analytics are transforming the audit [Online]. Available at: https://www.ey.com/en_gl/assurance/how-big-data-and-analytics-are-transforming-the-audit.
Gepp, A., Linnenluecke, M.K., O’Neill, T.J., Smith, T. (2018). Big Data techniques in auditing research and practice: Current trends and future opportunities. Research Methods & Methodology in Accounting eJournal, 40, 102–115.
IIA (2012). International Standards for the Professional Practice of Internal Auditing. Institute of Internal Auditors, Altamonte Springs, FL.
Jaafar, H., Halim, H.A., Ismail, R., Ahmad, A.S. (2018). Fraudulent financial reporting and impression management: An examination of corporate accounting narratives. International Journal of Academic Research in Business and Social Sciences, 8, 824–837.
Joulin, A., Grave, E., Bojanowski, P., Douze, M., Jégou, H., Mikolov, T. (2016a). FastText.zip: Compressing Text Classification Models. ICLR 2017, arXiv:1612. 03651v1.
Joulin, A., Grave, E., Bojanowski, P., Mikolov, T. (2016b). Bag of tricks for efficient text classification. Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, 427–431.
Jozefowicz, R. and Zaremba, W. (2015). An empirical exploration of recurrent network architectures. ICML’15: Proceedings of the 32nd International Conference on Machine Learning, 37, 2342–2350.
Lai, S., Xu, L., Liu, K., Zhao, J. (2015). Recurrent convolutional neural networks for text classification. Proceedings of the 29th AAAI Conference on Artificial Intelligence, 29(1), 2267–2273.
Lilleberg, J., Zhu, Y., Zhang, Y. (2015). Support vector machines and Word2vec for text classification with semantic features. Proceedings of the 14th International Conference on Cognitive Informatics and Cognitive Computing, IEEE, Beijing.
Manning, C. and Schütze, H. (1999). Foundations of Statistical Natural Language Processing, 1st edition. MIT Press, Cambridge, MA.
Menger, V., Scheepers, F., Spruit, M. (2018). Comparing deep learning and classical machine learning approaches for predicting inpatient violence incidents from clinical text. Applied Sciences, 8(6), 981.
Mikolov, T., Chen, K., Corrado, G., Dean, J. (2013). Efficient estimation of word representations in vector space. 1st International Conference on Learning Representations, arXiv:1301.3781.
Pennington, J., Socher, R., Manning, C. (2014). GloVe: Global vectors for word representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1532–1543.
Ravisankar, P., Ravi, V., Rao, G., Bose, I. (2011). Detection of financial statement fraud and feature selection using data mining techniques. Decision Support Systems, 50, 491–500.
Stanton, G. (2012). Detecting fraud-utilizing new technology to advance the audit profession. Thesis, Univeristy of New Hampshire, Durham [Online]. Available at: https://scholars.unh.edu/honors/18.
Turney, P.D. and Pantel, P. (2010). From frequency to meaning: Vector space models of semantics. Journal of Artificial Intelligence Research, 141–188.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J. (2017). Attention is all you need. NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, 6000–6010.
Wahbeh, A., Al-Kabi, M., Al-Radaideh, Q., Al-shawakfa, E., Alsmadi, I. (2011). The effect of stemming on Arabic text classification: An empirical study. International Journal of Information Retrieval Research (IJIRR), 1(3), 54–70.
Waykole, R.N. and Thakare, A.D. (2018). A review of feature extraction methods for text classification. International Journal of Advance Engineering and Research Development, 5(4), 351–354.
Wei, J. and Zou, K. (2019). EDA: Easy Data Augmentation techniques for boosting performance on text classification tasks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 6382–6388.
Yim, A. (2011). Fraud detection and financial reporting and audit delay. Paper, Munich Personal RePEc Archive, Munich.
Yin, W., Kann, K., Yu, M., Schütze, H. (2017). Comparative study of CNN and RNN for natural language processing. arXiv:1702.01923v1.
Young, T., Hazarika, D., Poria, S., Cambria, E. (2017). Recent trends in deep learning based natural language processing. IEEE Computational Intelligence Magazine, 13, 55–75.