
Chapter 2: Introduction to Important AWS Glue Features
In the previous chapter, we talked about the evolution of different data management strategies, such as data warehousing, data lakes, the data lakehouse, and data meshes, and the key differences between each. We introduced the Apache Spark framework, briefly discussed the Spark workload execution mechanism, learned how Spark workloads can be fulfilled on the AWS cloud, and introduced AWS Glue and its components.
In this chapter, we will discuss the different components of AWS Glue so that we know how AWS Glue can be used to perform different data integration tasks.
Upon completing this chapter, you will be able to define data integration and explain how AWS Glue can be used for this. You will also be able to explain the fundamental concepts related to different features of AWS Glue, such as AWS Glue Data Catalog, AWS Glue connections, AWS Glue crawlers, AWS Glue Schema Registry, AWS Glue jobs, AWS Glue development endpoints, AWS Glue interactive sessions, and AWS Glue triggers.
In this chapter, we will cover the following topics:
- Data integration
- Integrating data with AWS Glue
- Features of AWS Glue
Now, let’s dive into the concepts of data integration and AWS Glue. We will discuss the key components and features of AWS Glue that make it a powerful data integration tool.
Data integration
Data integration is a complex operation that involves several tasks – data discovery, ingestion, preparation, transformation, and replication. Data integration is the very first step in deriving insights from data so that data can be shared across the organization for collaboration and faster decision-making.
The data integration process is often iterative. Upon completing a particular iteration, we can query and visualize the data and make data-driven business decisions. For this purpose, we can use AWS services such as Amazon Athena, Amazon Redshift, and Amazon QuickSight, as well as some other third-party services. The process is often repeated until the right quality data is obtained. We can set up a job as part of our data integration workflow to profile the data obtained against a specific set of rules to ensure that it meets our requirements. For instance, AWS Glue DataBrew offers built-in capabilities to define data quality rules and allows us to profile data based on our requirements. We will be discussing AWS Glue DataBrew Profile jobs in detail in Chapter 4, Data Preparation. Once the right quality data is obtained, it can be used for analysis, machine learning (ML), or building data applications.
Since data integration helps drive the business forward, it is a critical business process. This also means there is less room for error as this directly impacts the quality of the data that’s obtained, which, in turn, impacts the decision-making process.
Now, let’s briefly explore how data integration can be simplified using AWS Glue.
Integrating data with AWS Glue
AWS Glue was initially introduced as a serverless ETL service that allows users to crawl, catalog, transform, and ingest data into AWS for analytics. However, over the years, it has evolved into a fully-managed serverless data integration service.
AWS Glue simplifies the process of data integration, which, as discussed earlier, usually involves discovering, preparing, extracting, and combining data for analysis from different data stores. These tasks are often handled by multiple individuals/teams with a diverse set of skills in an organization.
As mentioned in the previous section, data integration is an iterative process that involves several steps. Let’s take a look at how AWS Glue can be used to perform some of these tasks.
Data discovery
AWS Glue Data Catalog can be used to discover and search data across all our datasets. Data Catalog enables us to store table metadata for our datasets and makes it easy to query these datasets from several applications and services. AWS Glue Data Catalog can not only be used by AWS services such as AWS Glue, AWS EMR, Amazon Athena, and Amazon Redshift Spectrum, but also by on-premise or third-party product implementations that support the Hive metastore using the open source AWS Glue Data Catalog Client for Apache Hive Metastore (https://github.com/awslabs/aws-glue-data-catalog-client-for-apache-hive-metastore).
AWS Glue Crawlers enable us to populate the Data Catalog with metadata for our datasets by crawling the data stores based on the user-defined configuration.
AWS Glue Schema Registry allows us to manage and enforce schemas for data streams. This helps us enhance data quality and safeguard against unexpected schema drifts that can impact the quality of our data significantly.
Data ingestion
AWS Glue makes it easy to ingest data from several standard data stores, such as HDFS, Amazon S3, JDBC, and AWS Glue. It allows data to get ingested from SaaS and custom data stores via custom and marketplace connectors.
Data preparation
AWS Glue enables us to de-duplicate and cleanse data with built-in ML capabilities using its FindMatches feature. With FindMatches, we can label sets of records as either matching or not matching and the system will learn the criteria and build an ETL job that we can use to find duplicate records. We will discuss FindMatches in detail in Chapter 14, Machine Learning Integration.
AWS Glue also enables us to interactively develop, test, and debug our ETL code using AWS Glue development endpoints, AWS Glue interactive sessions, and AWS Glue Jupyter Notebooks. Apart from notebook environments, we can also use our favorite IDE to develop and test ETL code using AWS Glue development endpoints or AWS Glue local development libraries.
AWS Glue DataBrew provides an interactive visual interface for cleaning and normalizing data without writing code. This is especially beneficial to novice users who do not have Apache Spark and Python/Scala programming skills. AWS Glue DataBrew comes pre-packed with over 250 transformations that can be used to transform data as per our requirements.
Using AWS Glue Studio, we can develop highly scalable Apache Spark ETL jobs using the visual interface without having in-depth knowledge of Apache Spark.
Data replication
The Elastic Views feature of AWS Glue enables us to create views of data stored in different AWS data stores and materialize them in a target data store of our choice. We can create materialized views by using PartiQL to write queries.
At the time of writing, AWS Glue Elastic Views currently supports Amazon DynamoDB as a source. We can materialize these views in several target data stores, such as Amazon Redshift, Amazon OpenSearch Service, and Amazon S3.
Once materialized views have been created, they can be shared with other users for use in their applications. AWS Glue Elastic Views continuously monitors changes in our dataset and updates the target data stores automatically.
In this section, we mentioned several AWS Glue features and how they aid in different data integration tasks. In the next section, we will explore the different features of AWS Glue and understand how they can help implement our data integration workload.
Features of AWS Glue
AWS Glue has different features that appear disjointed, but in reality, they are interdependent. Often, users have to use a combination of these features to achieve their goals.
The following are the key features of AWS Glue:
- AWS Glue Data Catalog
- AWS Glue Connections
- AWS Glue Crawlers and Classifiers
- AWS Glue Schema Registry
- AWS Glue Jobs
- AWS Glue Notebooks and interactive sessions
- AWS Glue Triggers
- AWS Glue Workflows
- AWS Glue Blueprints
- AWS Glue ML
- AWS Glue Studio
- AWS Glue DataBrew
- AWS Glue Elastic Views
Now that we know the different features and services involved in executing an AWS Glue workload, let’s discuss the fundamental concepts related to some of these features.
AWS Glue Data Catalog
A Data Catalog can be defined as an inventory of data assets in an organization that helps data professionals find and understand relevant datasets to extract business value. A Data Catalog acts as metadata storage (or a metastore) that contains metadata stored by disparate systems. This can be used to keep track of data in data silos. Typically, the user is expected to provide information about data formats, locations, and serialization deserialization mechanisms, along with the query. Metastores make it easy for us to capture these pieces of information during table creation and can be reused every time the table is used. Metastores also enable us to discover and explore relevant data in the data repository using metastore service APIs. The most popular metastore product that’s used widely in the industry is Apache Hive Metastore.
AWS Glue Data Catalog is a persistent metastore for data assets. The dataset can be stored anywhere – AWS, on-premise, or in a third-party provider – and Data Catalog can still be used. AWS Glue Data Catalog allows users to store, annotate, and share metadata in AWS. The concept is similar to Apache Hive Metastore; however, the key difference is that AWS Glue Data Catalog is serverless and there is no additional administrative overhead in managing the infrastructure.
Traditional Hive metastores use relational database management systems (RDBMSs) for metadata storage – for example, MySQL, PostgreSQL, Derby, Oracle, and MSSQL. The problem with using RDBMS for Hive metastores is that relational database servers need to be deployed and managed. If the metastore is to be used for production workloads, then we need to factor high availability (HA) and redundancy into the design. This will increase the complexity of the solution architecture and the cost associated with the infrastructure and how it’s managed. AWS Glue Data Catalog, on the other hand, is fully managed and doesn’t have any administrative overhead (deployment and infrastructure management).
Each AWS account has one Glue Data Catalog per AWS region and is identified by a combination of catalog_id and aws_region. The value of catalog_id is the 12-digit AWS account number. The value of catalog_id remains the same for each catalog in every AWS region. For instance, to access the Data Catalog in the North Virginia AWS region, aws_region must be set to 'us-east-1' and the value of the catalog_id parameter must be the 12-digit AWS account number – for example, 123456789012.
AWS Glue Data Catalog is comprised of the following components:
- Databases
- Tables
- Partitions
Now, let’s dive into each of these catalog item types in more detail.
Databases
A database is a logical collection of metadata tables in AWS Glue. When a table is created, it must be created under a specific database. A table cannot be present in more than one database.
Tables
A table in a Glue Data Catalog is a resource that holds the metadata for any given dataset. The following diagram shows the metadata of a table stored in the Data Catalog:
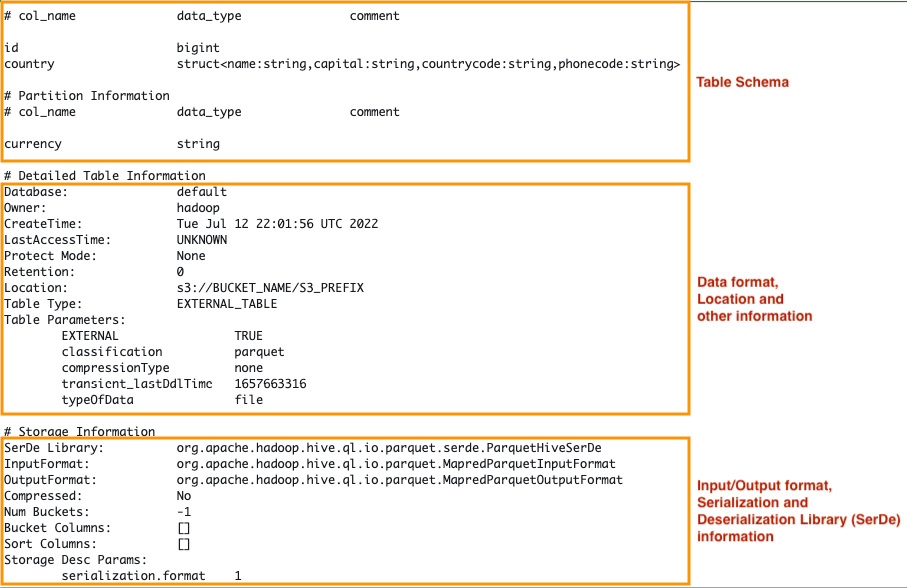
Figure 2.1 – Metadata of a table stored in a Data Catalog
All tables contain information such as the name, input format, output format, location, and schema of the dataset, as well as table properties (stored as key-value pairs – primarily used to store table statistics, the compression format, and the data format) and Serializer-Deserializer (SerDe) information such as SerDe name, the serialization library, and SerDe class parameters.
The SerDe library information in the table’s metadata informs the query processing engine of which class to use to translate data between the table view and the low-level input/output format. Similarly, InputFormat and OutputFormat specify the classes that describe the original data structure so that the query processing engine can map the data to its table view. At a high level, the process would look something like this:
- Read operation: Input data | InputFormat | Deserializer | Rows
- Write operation: Rows | Serializer | OutputFormat | Output data
Table Versions
It is important to note that AWS Glue supports versioning catalog tables. By default, a new version of the table is created when the table is updated. However, we can use the skipArchive option in the AWS Glue UpdateTable API to prevent AWS Glue from creating an archived version of the table. Once the table is deleted, all the versions of the table will be removed as well.
Partitions
Tables are organized into partitions. Partitioning is an optimization technique by which a table is further divided into related parts based on the values of a particular column(s). A table can have a combination of multiple partition keys to identify a particular partition (also known as partition_spec).
For instance, a table for sales_data can be partitioned using the country, category, year, and month columns.
The following is an example query for this:
SELECT *
FROM sales_data
WHERE country='US' AND category='books' AND year='2021' AND month='10'
Over time, as data grows, the number of partitions that can be added to a table can grow significantly based on the partition keys defined in the table. Fetching metadata for all these partitions can introduce a huge amount of latency. To address this issue, Glue allows users to add indexes for partition keys (refer to https://docs.aws.amazon.com/glue/latest/dg/partition-indexes.html) and when the GetPartitions API is called by the query processing engine with a particular query expression, the API will try to return a subset of partitions instead of all partitions. By default, if partition indexes are not defined on a table, the GetPartitions API will return all the partitions and perform filtering on the returned API response.
Now, let’s consider an example database setup, as shown in the following diagram. If partition indices idx_1, idx_2, and idx_3 are not defined, all the partitions in the table are returned when the GetPartitions API is called on the table_1 or table_2 table in the catalog_database database. However, if the partition indices are defined, only the partitions for a specific table with indices that match the values passed in the query will be returned. This reduces the effort involved by the query engine in fetching partition metadata:
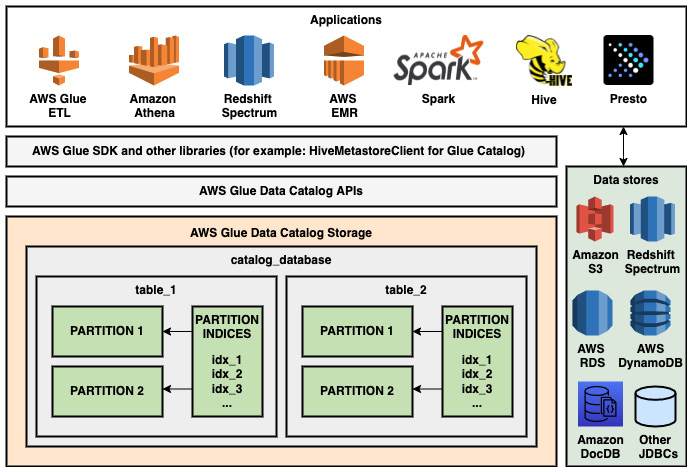
Figure 2.2 – Structure of AWS Glue Data Catalog
Limitations of Using Partition Indexes
Once a partition index has been added to a table in Glue Data Catalog, index keys’ data types will be validated for all new partitions added to this table. It is important to make sure the values for the columns listed as partition indexes adhere to the data type defined in the schema. If this is not the case, the partition won’t be created. Once a table has been created, the names, data types, and the order of the keys registered as part of the partition index cannot be modified.
Now that we understand the fundamentals of AWS Glue Data Catalog, in the next section, we’ll explore AWS Glue connections and understand how they enable communication with VPC/on-premise data stores.
Glue connections
AWS Glue connections are resources stored in AWS Glue Data Catalog that contain connection information for a given data store. Typically, an AWS Glue connection contains information such as login credentials, connection strings (URIs), and VPC configuration (VPC subnet and security group information), which are required by different AWS Glue resources to connect to the data store. The contents of an AWS Glue connection differ from one connection type to another.
Aws Glue Connection is a feature available in AWS Glue that is not present in traditional Hive Metastores. Connections enable AWS Glue workloads (crawlers, ETL Jobs, development endpoints, and interactive sessions) to access data stores that are typically not exposed to the public internet – for example, RDS database servers and on-premise data stores.
Glue users can define connections that can be used to connect to data sources or targets. At the time of writing, there are eight types of Glue connections, each of which is designed to establish a connection with a specific type of data store: JDBC, Amazon RDS, Amazon Redshift, Amazon DocumentDB, MongoDB, Kafka, Network, and Custom/Marketplace connections.
The parameters required for each connection type are different based on the type of data store the connection will be used for. For instance, the JDBC connection type requires SSL configuration, JDBC URI, login credentials, and VPC configuration.
The Network connection type is useful when users wish to route the traffic via an Amazon S3 VPC endpoint and do not want their Amazon S3 traffic to traverse the public internet. This pattern is usually used by organizations for security and privacy reasons. The Network connection type is also useful when users wish to establish connectivity to a custom data store (for example, an on-premise Elasticsearch cluster) within the ETL job and not define connection parameters in a Glue connection.
When a Glue connection is attached to any Glue compute resource (Jobs, Crawlers, development endpoints, and interactive sessions), behind the scenes, Glue creates EC2 Elastic Network Interfaces (ENIs) with the VPC configuration (subnet and security groups) specified by the user. These ENIs are then attached to compute resources on the server side. This mechanism is used by AWS Glue to communicate with VPC/on-premise data stores.
Elastic Network Interfaces (ENIs)
An ENI is essentially a virtual network interface that facilitates networking capabilities for compute resources on AWS.
Let’s use the following diagram to understand how Glue uses ENIs to communicate with VPC/on-premise data stores:
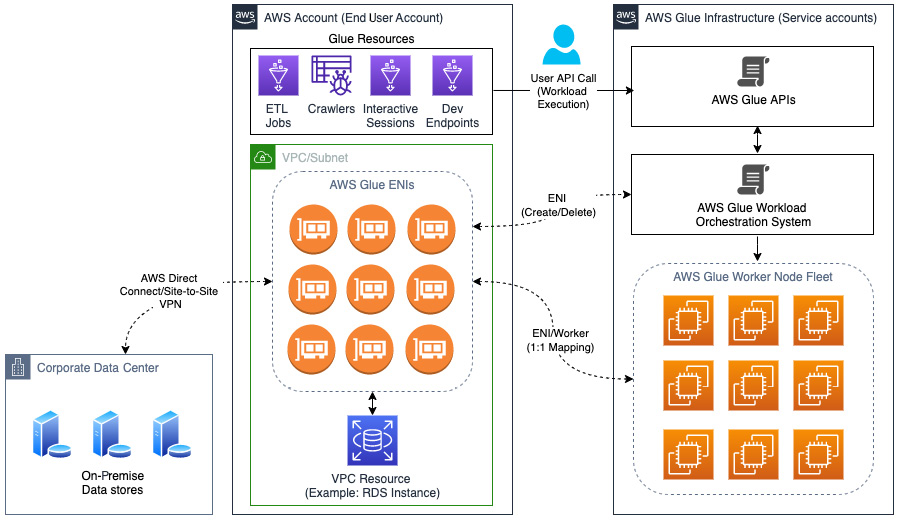
Figure 2.3 – VPC-based data store access from AWS Glue using ENIs
Here, when a user makes an API call to execute the AWS Glue workload, the request is submitted to the AWS Glue workload orchestration system, which will calculate the amount of compute resources required and allocates workers from the worker node fleet.
If the workload being executed requires VPC connectivity, ENIs are created in the end user AWS account and are attached to worker nodes. There is a 1:1 mapping between the worker nodes and the ENIs; the worker nodes use these ENIs to communicate with the data stores. These data stores can be present in an AWS account or they could be present in the end user’s corporate data center.
ENIs that are created during workload execution are automatically cleared by AWS Glue (this can take up to 10 to 15 minutes). AWS Glue uses the same IAM role that’s used for workload execution to delete ENIs once the workload has finished executing. If the IAM role is not available during ENI deletion (for instance, if the IAM role was deleted immediately after workload execution), the ENIs will stay active indefinitely until they are manually deleted by the user.
Note
It is important to make sure that the subnet being used by the Glue connection has enough IP addresses available as each Glue resource creates multiple ENIs (each of which consumes one IP address) based on the compute capacity required for workload execution.
At the time of writing, a Glue resource can only use one subnet. If multiple connections with different subnets are attached, the subnet settings from the first connection will be used by default. However, if the first connection is unhealthy for any reason – for instance, if the availability zone is down – then the next connection is used.
In the next section, we will explore Glue Crawlers and classifiers and how they aid in data discovery.
AWS Glue crawlers
A Crawler is a component of AWS Glue that helps crawl the data in different types of data stores, infers the schema, and populates AWS Glue Data Catalog with the metadata for the dataset that was crawled.
Crawlers can crawl a wide variety of data stores – Amazon S3, Amazon Redshift, Amazon RDS, JDBC, Amazon DynamoDB, and DocumentDB/MongoDB to name a few. This is a powerful tool that’s available for data discovery in AWS Glue.
Glue Connections for Crawlers
For a crawler to crawl a VPC resource or on-premise data stores such as Amazon Redshift, JDBC data stores (including Amazon RDS data stores), and Amazon DocumentDB (MongoDB compatible), a Glue connection is required.
Crawlers are capable of crawling S3 buckets without using Glue connections. However, a Network connection type is required if you must keep S3 request traffic off the public internet.
For a crawler with a Glue connection, it is recommended to have at least 16 IP addresses available in the subnet. When a connection is attached to a Glue resource, multiple ENIs are created to run the workload.
Now that we know what data stores are supported by AWS Glue crawlers, let’s explore how they work. Take a look at the following diagram:
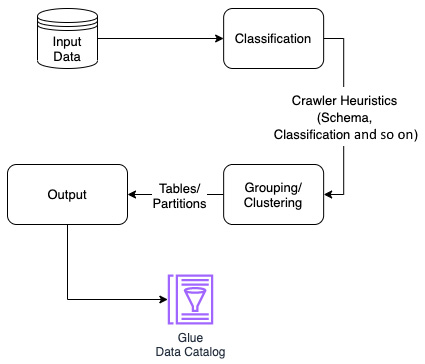
Figure 2.4 – Workflow of a Glue crawler
The workflow of a crawl can be divided into three stages:
- Classification: In this stage, the crawler traverses the input data store and uses classifiers (built-in/custom) to classify the source data. When a crawler is created, users can choose one or more custom classifiers that will be used by the crawler during classification to identify the format of the data to infer the schema. Input data is evaluated against the list of classifiers in the same order; the certainty=1.0 value (100% certainty) is returned for the first classifier to successfully recognize the data store. This will be used for schema inference. If none of the custom classifiers are successful in recognizing the data store, the crawler will move on to evaluate the data store against a list of built-in classifiers (https://docs.aws.amazon.com/glue/latest/dg/add-classifier.html#classifier-built-in). Finally, the certainty score decides how the data store is classified. If none of the classifiers return certainty=1.0, the output of the classifier with the highest certainty value will be used by Glue for table creation. If no classifier returned a certainty value that was higher than 0.0, Glue creates a table with the UNKNKOWN classification. The crawler will use the selected classifier to infer the schema of the dataset.
- Clustering/Grouping: The output from the classification stage is used by the crawler and the data is grouped based on crawler heuristics (schema, classification, and other properties). Table or partition objects are created based on clustered data using Glue crawler’s internal logic wherein schema similarity, compressionType, directory structure, and other factors are considered.
- Output: In this stage, the table or partition objects that were created in the clustering stage will be written to Glue Data Catalog using Glue API calls. If the table(s) already exists and this is the first run of the crawler, a new table with a hash string suffix will be created. However, if the crawler is running on an existing catalog table or if this is the crawler’s subsequent run, updates to catalog table(s) will be handled according to the crawler’s SchemaChangePolicy settings. (In some edge cases, the SchemaChangePolicy property will be ignored and new tables and partitions might be created. This depends on the data source type defined in the crawler.) The tables created by the crawler are placed in the database that’s been nominated. If no database has been set up in the crawler settings, the tables will be placed in the default database.
Note
At the time of writing, the maximum runtime for any crawler is 24 hours. After 24 hours, the crawler’s run is automatically stopped with the CANCELLED status.
Users are allowed to specify a table prefix in the crawler’s settings. The length of this prefix cannot exceed 64 characters.
The maximum length of the name of the table cannot exceed 128 characters. The crawler automatically truncates the names generated to fit this limit.
If the name of the table that’s generated is the same as the name of an existing table, the Glue crawler automatically adds a hash string suffix to ensure that the table name is unique.
For Amazon S3 data store crawls, the crawler will read all the files in the path specified by default. The crawler will classify each of the files available in the S3 path and persist the metadata to the crawler’s service side storage (not to be confused with AWS Glue Data Catalog). Metadata gets reused and the new files are crawled during the subsequent crawler runs and the metadata stored on the service side is updated as necessary.
Note
When a new version of an existing file is uploaded to Amazon S3 after a crawl, a subsequent crawl will consider this a new file. Then, the new file will be included in the new crawl.
For plain text file formats (CSV, TSV, JSON), it is not feasible to crawl the entire file for larger files to evaluate the schema. Therefore, the crawler will read the initial 1 to 10 MB of data of each file, depending on the file format, and ensure that at least one record is read (if the record’s size is greater than 1 MB). The schema is inferred based on the data read into the buffer.
For the JDBC, Amazon DynamoDB, and Amazon DocumentDB (with MongoDB compatibility) data stores, the stages of the crawler workflow are the same, but the logic that’s used for classification and clustering is different for each data store type. The classification of the table(s) is decided based on the data store type/database engine.
For JDBC data stores, Glue connects to the database server, and the schema is obtained for the tables that match the include path value in the crawler settings. Similar logic is used for DocumentDB/MongoDB data stores and the schema of MongoDB collections is inferred.
In the next section, we’ll explore some of the key features of AWS Glue crawlers.
Key features of Glue crawlers
AWS Glue crawlers have several features and configuration options that make it easy to discover data and populate the Data Catalog. In the following sub-sections, we will look at some of the features of AWS Glue crawlers that help optimize the data discovery process.
Data sampling – DynamoDB and DocumentDB/MongoDB
By default, Glue performs a full scan of the DynamoDB table and MongoDB collection to infer the schema. This operation can be time-consuming when the table is not a high throughput table. To address this issue, we can enable the Data sampling feature. When sampling is enabled, Glue will scan a subset of the data rather than perform a full scan.
Data sampling – Amazon S3
By default, Glue will read all the files in the Amazon S3 data store. The Data sampling feature is available for Amazon S3 data stores as well. This will reduce crawler runtime significantly. Users can specify the number of objects (in a value range of 1 to 249) in each leaf directory to be crawled. This feature is helpful when the users have prior knowledge of data formats and the schemas in the directories do not change.
Amazon S3 data store – incremental crawl
In Amazon S3, crawlers are used to scan new data and register new partitions in Glue Data Catalog. This can be further optimized by enabling the Incremental Crawls feature (https://docs.aws.amazon.com/glue/latest/dg/incremental-crawls.html). This feature is best suited for datasets that have stable schemas. When this feature is enabled, only new directories that have been added to the dataset are crawled. This feature can be enabled in the AWS Glue console by selecting the Crawl new folders only checkbox.
Amazon S3 data store – table-level specification
While discussing the Clustering/Grouping stage in the crawler workflow, we talked about how crawlers use internal logic based on data store properties (schema similarity, compression, and directory structure) to decide whether a directory that’s stored in Amazon S3 is a partition or a table. In some use cases, two or more tables can have a similar schema, which causes the crawler to mark these tables as partitions of the same tables instead of creating separate tables. Using the TableLevelConfiguration option in the Grouping policy, we can inform the crawler of where the tables are located and how we want the partitions to be created. Let’s consider an example.
Imagine that we have the following directory structure in an Amazon S3 bucket:
s3://myBucket/prefix/data/year=2021/month=10/day=08/hour=12/file1.parquet
s3://myBucket/prefix/data/year=2021/month=11/day=10/hour=12/file2.parquet
All the Parquet files in the S3 location have the same schema. If we point the crawler to s3://myBucket/prefix/data/ and run the crawler, it will create a single table and four partition keys – year, month, day, and hour. However, consider a scenario where we want to create separate tables for each month. Typically, the solution is to add multiple include_path for the crawler to crawl – for example, s3://myBucket/prefix/data/year=2021/month=10/ and s3://myBucket/prefix/data/year=2021/month=11/. Now, if there are hundreds of such paths and we want to create a table for all of them, it would not be feasible to add all the paths to the crawler configuration.
The same outcome can be achieved by using the Table level feature. We can set the Table Level parameter to 5 in crawler output settings. This will instruct the crawler to create the tables at level 5 from root (which corresponds to month in the directory structure specified previously). Now, the crawler will create two tables called month_10 and month_11.
In this section, we discussed some of the key features of Glue crawlers that can be enabled to enhance the performance or precision of the crawler. Please refer to the AWS Glue documentation for an exhaustive list of available crawler features.
Custom classifiers
While discussing the different stages in the crawler workflow, we mentioned it is possible to add custom classifiers to Glue crawlers. Classifiers are responsible for determining the file’s classification string (for example, parquet) and the schema of the file. When built-in classifiers are not capable of crawling the dataset or the table that’s been created requires customization, users can define custom classifiers and crawlers that will use the logic defined to create schema based on the type of classifier.
Note
If a custom classifier definition gets changed after a crawl, any data that was previously crawled will not be reclassified as the crawler keeps track of metadata for previously crawled data. If a mistake was made during classifier configuration, just fixing the classifier configuration will not help. The only way to reclassify already classified data is to delete and recreate the crawler with the updated classifier attached.
At the time of writing, users can define the following types of custom classifiers:
- Grok classifiers: Grok patterns are named sets of regular expressions that can match one line of data at a time. When the dataset matches the grok pattern specified, the structure of the dataset is determined and the data is tokenized and mapped to fields defined in the pattern specified. The GrokSerDe serialization library is used for tables created in Glue Data Catalog.
- XML classifiers: XML classifiers allow users to define the tag in the XML files that contains the records. For instance, let’s consider the following XML sample:
<?xml version="1.0"?>
<catalog>
<book id="bk101">
<author>Gambardella, Matthew</author>
<title>XML Developer's Guide</title>
</book>
<book id="bk102">
<author>Ralls, Kim</author>
<title>Midnight Rain</title>
</book>
</catalog>
In this case, using book as the XML row tag will create a table containing two columns – author and title.
Note
It is important to note that an element that holds the record cannot be self-closing. For example, <book id="bk102"/> will not parse. Empty elements should have a separate starting and closing tag; for example, <book id="bk102"> </book>.
- JSON Classifiers: Using JSON classifiers, users can specify the JSON path where individual records are present. This classifier uses JsonPath expressions as input and accesses the items in the JSON based on the path specified. The syntax for JsonPath can be found in https://docs.aws.amazon.com/glue/latest/dg/custom-classifier.html#classifier-values-json.
Let’s consider the following sample JSON dataset:
{
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
}
]
}
To extract individual books as records, we can use the $.book[*] JSON path.
- CSV Classifiers: CSV classifiers allow users to specify different options to crawl delimited files. Users can specify custom delimiters, quote symbols, options about the header, and validations (this allows files with a single column – trim whitespace before column identification).
In the next section, we will discuss the AWS Glue Schema Registry (GSR) and how we can handle evolving schemas to stream data stores centrally.
AWS Glue Schema Registry
With organizations’ growing need for real-time analytics, streaming data processing is becoming more and more important in an enterprise data architecture. Organizations collect real-time data from a wide variety of sources, including IoT sensors, user applications, application/security logs, and geospatial services. Collecting real-time data gives organizations visibility into aspects of their business and customer activity and enables them to respond to emerging situations. For example, sensors in industrial equipment send data to streaming applications. The application monitors the data that’s been sent by the sensors and detects any potential faults in the machinery.
Over time, as organizations grow, more data sources (for example, additional sensors or trackers) can be used to enrich the data streams with additional information that’s vital to the business. This creates a problem for all the downstream applications that already consume these data streams as they must be upgraded to handle these schema changes. Schema registries can be used to address the issues caused by schema evolution and allow streaming data producers and consumers to discover and manage schema changes, as well as adapt to these changes based on user settings.
GSR is a feature available in AWS Glue that allows users to discover, control, and evolve schema for streaming data stores centrally. Glue Schema registries support integrations with a wide variety of streaming data stores such as Apache Kafka, Amazon Kinesis Data Streams, Amazon Managed Streaming for Apache Kafka (MSK), Amazon Kinesis Data Analytics for Apache Flink, and AWS Lambda by allowing users to enforce and manage schemas.
AWS Glue Schema Registry is fully managed, serverless, and available for users free of cost. At the time of writing, GSR supports the AVRO, JSON, and protocol buffer (protobuf) data formats for schemas. JSON schema validation is supported by the Everit library (https://github.com/everit-org/json-schema).
Note
The AWS Glue Schema Registry currently supports the Java programming language. Java version 8 (or above) is required for both producers and consumers.
Schema registries use serialization and deserialization processes to help stream data that producers and consumers enforce a schema on records. If a schema is not available in the schema registry, it must be registered for use (auto-registration of the schema can be enabled for any new schema to be auto-registered).
Upon registering a schema in the schema registry, a schema version identifier will be issued to the serializer. If the schema is already available in the GSR and the serializer is using a newer version of the schema, the GSR will check the compatibility rule to make sure that the new version is compatible. The schema will be registered as a new version in the GSR.
When a producer has its schema registered, the GSR serializer validates the schema of the record with where the schema is registered. If there is a mismatch, an exception will be returned. Producers typically cache the schema versions and match the schema against the versions available in the cache. If there is no version available in the cache that matches the schema of the record, GSR will be queried for this data using the GetSchemaVersion API.
If the schema is validated using a version in the GSR, the schema version ID and definition will be cached locally by the producer. If the record’s schema is compliant with the schema registered, the record is decorated with the schema version ID and then serialized (based on the data format selected), compressed, and delivered to the destination.
Once a serialized record has been received, the deserializer uses the version ID available in the payload to validate the schema. If the deserializer has not encountered this schema version ID before, the GSR is queried for this and the schema version is cached in local storage.
If the schema version IDs in the GSR/cache match the version in the serialized record, the deserializer decompresses and deserializes the data and the record is handed off to the consumer application. However, if the schema version ID doesn’t match the version IDs available in cache or the GSR, the consumer application can log this event and move on to other records or halt the process based on user configuration.
SerDe libraries can be added to both producer and consumer applications by adding the software.amazon.glue:schema-registry-serde Maven dependency (https://mvnrepository.com/artifact/software.amazon.glue/schema-registry-serde). Refer to https://docs.aws.amazon.com/glue/latest/dg/schema-registry-integrations.html for example producer and consumer implementations.
In the next section, we will explore one of the key components of AWS Glue: ETL jobs.
AWS Glue ETL jobs
ETL is one of the main components of data integration. Designing an ETL pipeline to ingest and transform data can be time-consuming as data grows over time. Setting up, managing, and scaling the infrastructure takes up most of the effort in a typical on-premise data engineering project. Glue ETL almost eliminates the effort involved in setting up infrastructure as it is fully managed and serverless. All the effort involved in setting up hosts, configuration management, and patching is handled behind the scenes by the Glue ETL engine so that the user can focus on developing ETL scripts and managing the necessary dependencies. Of course, Glue ETL is not a silver bullet that eliminates all the challenges involved in running an ETL workload, but with the right design and strategy, it can be a great fit for almost all organizations.
At the time of writing, Glue allows users to create three different types of ETL jobs – Spark ETL, Spark Streaming, and Python shell jobs. The key differences between these job types are in the libraries/packages that are injected into the environment during job orchestration on the service side and billing practices.
During job creation, users can use the AWS Glue wizard to generate an ETL script for Spark and Spark Streaming ETL jobs by choosing the source, destination, column mapping, and connection information. However, for Python shell jobs, the user will have to provide a script. At the time of writing, Glue ETL supports Scala 2 and PySpark (Java and R jobs are currently not supported) for Spark and Spark Streaming jobs and Python 3 for Python shell jobs.
When Glue ETL was introduced, Python 2 support was available in Glue ETL v0.9 and 1.0. However, since Python 2 was sunsetted by the open source community, ETL job environments that used Python 2 were phased out. This is specified in the policy available in the Glue EOS milestones documentation (https://docs.aws.amazon.com/glue/latest/dg/glue-version-support-policy.html#glue-version-support-policy-milestones).
Note
AWS Glue allows multiple connections to be attached to ETL jobs. However, it is important to note that a Glue job can use only one subnet for VPC jobs. If multiple connections are attached to a job, only the first connection is attached to the ETL job.
There are some advanced features that users can select during job creation, such as job bookmarks, continuous logging, Spark UI, and capacity settings (the number of workers and worker type). Glue allows users to inject several job parameters (including Spark configuration parameters) so that they can alter the default Spark behavior.
Glue ETL introduces quite a lot of advanced Spark extensions/APIs and transformations to make it easy to achieve complex ETL operations. Let’s look at some of the important extensions/features that are unique to Glue ETL.
GlueContext
The GlueContext class wraps Apache Spark’s SparkContext object and allows you to interact with the Spark platform. GlueContext also serves as an entry point to several Glue features – DynamicFrame APIs, job metrics, continuous logging, job bookmarks, and more. The GlueContext class provides methods to create DataSource and DataSink variables, which is essential in reading/writing Glue DynamicFrames. GlueContext is also helpful in setting the number of output partitions (the default is 20) in a DynamicFrame when the number of output partitions is below the minimum threshold (the default is 10).
GlueContext can be initialized using the following code snippet:
sc = SparkContext()
glueContext = GlueContext(sc)
Once the GlueContext class has been initialized, we can use the object created to extract the SparkSession object:
spark = glueContext.spark_session
DynamicFrame
DynamicFrame is a key functionality of Glue that enables users to perform ETL operations efficiently. As defined in the AWS Glue documentation (https://docs.aws.amazon.com/glue/latest/dg/glue-etl-scala-apis-glue-dynamicframe-class.html), a DynamicFrame is a distributed collection of self-describing DynamicRecord objects (comparable to a Row in Spark DataFrame, but DynamicRecords do not require them to adhere to a set schema). Since the records are self-describing, DynamicFrames do not require a schema to be created and can be used to read/transform data with inconsistent schemas. SparkSQL performs two passes over the dataset to read data since a Spark DataFrame expects a well-defined schema for data ingestion – the first one to infer the schema from the data source and the second to load the data. Even though SparkSQL supports schema inference, it is still limited in its capabilities. Glue infers the schema for a given dataset at runtime when required and does not pre-compute the schema. Any schema inconsistencies that are detected are encoded as choice (or union) data types that can be later resolved to make the dataset compatible with targets that require a fixed schema.
DynamicFrames can be created using different APIs, depending on the use case. The following syntax can be used to create a DynamicFrame using a Glue Data Catalog table in PySpark (documentation on this can be found at https://docs.aws.amazon.com/glue/latest/dg/aws-glue-api-crawler-pyspark-extensions-dynamic-frame-reader.html#aws-glue-api-crawler-pyspark-extensions-dynamic-frame-reader-from_catalog):
datasource0 = glueContext.create_dynamic_frame.from_catalog(name_space='my_database', table_name='my_table', transformation_ctx='datasource0')
This statement will create a DynamicFrame object called datasource0 for the my_table table in the my_database database. This statement will use the GlueContext object, which uses the Glue SDK, to connect to Glue Data Catalog and fetch the data store classification and properties to create the object. Additionally, users can pass additional options into this statement by using the additional_options parameter and a pushdown predicate filter expression to apply filters to the dataset while it is being read using the push_down_predicate parameter.
In the preceding source code example, we used the from_catalog method to create datasource0. Similarly, DynamicFrames can be created using the following methods:
- from_options: This method allows users to create DynamicFrames by manually specifying the connection type, options, and format. This method provides users with the flexibility to customize options for a data store.
- from_rdd: This method allows users to create DynamicFrames using Spark Resilient Distributed Datasets (RDDs).
The DynamicFrame class provides several transformations that are unique to Glue and also allows conversion to and from Spark DataFrames. This makes it incredibly easy to integrate the existing source code and take advantage of the operations that are available in Spark DataFrames but not yet available in Glue DynamicFrames. Users can convert a DynamicFrame into a Spark DataFrame using the following syntax:
df = datasource0.toDF()
Here, datasource0 is the DynamicFrame and df is the Spark DataFrame that was returned.
Similarly, a Spark DataFrame can be converted into a Glue DynamicFrame using the following code snippet:
from awsglue.dynamicframe import DynamicFrame
dyf = DynamicFrame.fromDF(dataframe=df, glue_ctx=glueContext, name="dyf")
Both Spark DataFrames and Glue DynamicFrames are high-level Spark APIs that interact with Spark RDDs. That being said, the structure of a DynamicFrame is significantly different from that of a DataFrame.
While a DynamicFrame provides a flexible set of APIs to access and transform datasets, there are some areas where DataFrames outshine DynamicFrames. For instance, since DynamicFrames are based on raw RDDs and not Spark DataFrames, it does not take advantage of Spark’s catalyst optimizer. This is the reason why some aggregation operations (such as joins) perform better with Spark DataFrames than Glue DynamicFrames. In such cases, we can convert it into Spark DataFrame to take advantage of the performance boost offered by the catalyst optimizer. Also, some functions/classes are only available for Spark DataFrames, such as Spark MLlib and SparkSQL functions.
It is important to note that converting a Glue DynamicFrame into a Spark DataFrame requires a full Map stage in Spark. This should only be used when necessary. DynamicFrame to DataFrame conversion blocks Spark from optimizing workloads based on upstream code and dramatically reduces efficiency.
Job bookmarks
Bookmarking is a key feature available in Glue ETL that allows users to keep track of data that was processed and written. During the next job run, only new data will be processed. This is an extremely useful option that helps in processing large datasets that are constantly growing. While specifying the syntax for DynamicFrame creation from the Data Catalog table earlier, the transformation_ctx parameter (https://docs.aws.amazon.com/glue/latest/dg/monitor-continuations.html#monitor-continuations-implement-context) was mentioned in the code snippet. This parameter is used as the identifier for the job bookmark’s state, which is persisted across job runs. Job bookmarks are supported for S3 and JDBC-based data stores. At the time of writing, the JSON, CSV, Apache Avro, XML, Parquet, and ORC file formats are supported with S3 data stores. For an Amazon S3 data source, job bookmarks keep track of the last modified timestamp of the objects processed. This information is then persisted in the bookmark storage on the service side. During the next jobRun, the information that was collected by the bookmark in the previous jobRun will be used to filter out already processed objects; then, new objects are processed.
Note:
A new version of an already existing object is still considered a new object and will be processed in the new jobRun.
At the time of writing, Glue DynamicFrames only support Spark SaveMode.Append mode for writes. So, if a new version of an object was added to the data store, there is a possibility of data duplication in the target data store. This must be handled by the user with custom logic in the ETL script.
For JDBC data stores, job bookmarks use key(s) specified by the user and the order of the keys to track the data being processed. If no keys are specified by the user, Glue will use the primary key of the JDBC table. It is important to note that Glue will not accept the primary key, which is not sequential (there shouldn’t be gaps in the values). In such cases, we just have to specify the column manually as the key in the jobBookmarkKeys parameter in additional_options (connection_options for the from_options API). This will force Glue to use the key for bookmarking.
Note – Bookmarking with JDBC Data Stores
If more than one key is specified, Glue will combine the keys to form a single composite key. However, if a key is not specified, Glue will use the primary key of the JDBC table as the key (only if the key is increasing/decreasing sequentially). If keys are specified by the user, gaps are allowed for these keys. However, the keys have to be sorted – either increasing or decreasing.
GlueParquet
Parquet is one of the most popular file formats used for data analytics workloads. We already know that DynamicFrames contain self-describing dynamic records with flexible schema requirements – the same principle can be applied while writing parquet datasets. By setting the output format as glueparquet, users can take advantage of the custom-built parquet writer, which computes the schema dynamically during write operations.
This writer computes a schema for the dataset that’s available in memory. Performing a pass over the dataset in memory is computationally cheaper compared to performing a pass over the data in disk or Amazon S3. A buffer is created for each column that’s encountered in this pass and data is inserted into these buffers. If the writer comes across a new column, a new buffer is initialized and data is written into it. When the file is to be written to the target, the buffers for all the columns are aggregated and flushed. This approach helps avoid schema computation during a parquet write to the target.
This writer can be used by setting format="glueparquet" or format=parquet along with the format_option parameter, where useGlueParquetWriter is set to true. The data that’s written to the target data store is still in parquet format, however, the writer uses different logic to write data to the target.
It is important to note that the GlueParquet writer only supports schema evolution – that is, adding/removing columns – and does not support changing data types for existing columns. The glueparquet format can only be used for write operations. To read the data written by this writer, we still have to use format=parquet.
Now that we understand the fundamentals of AWS Glue ETL Jobs, we will explore Glue development endpoints, which can be used by end users to develop ETL scripts for ETL Jobs.
Glue development endpoints
When Glue ETL was introduced, the orchestration service on the service side provisioned Spark clusters on-demand and configured them. This approach introduced a significantly high cold-start of about 10 to 15 minutes (with a timeout of 25 minutes). However, this all changed with the introduction of Glue v2.0, which used a different infrastructure provisioning mechanism. This cut down the cold-start from 10 to 15 minutes to 10 to 30 seconds (with a timeout of 5 minutes).
Glue ETL is a heavily customized environment with a lot of proprietary classes and libraries pre-packaged and ready for use. Developing Glue ETL scripts proved to be a challenge as Glue ETL was not initially designed for instant feedback. One mistake in the ETL script during development can take up to 10 to 15 minutes for the job to start running – only then will the user be able to see the mistake. This can be a bit frustrating and lead to poor developer experience.
Glue development endpoints were introduced to address this pain point. This feature allows users to create an environment for Glue ETL development wherein the developer/data engineer can use Notebook environments (Jupyter/Zeppelin), read-eval-print loop (REPL) shells, or IDEs to develop ETL scripts and test them instantly using the endpoint.
Glue development endpoints are essentially long-running Spark clusters that run on the service side with all the pre-packaged libraries and dependencies available in the ETL environment ready for use. Apache Livy and Zeppelin Daemon are also installed in a development environment, which enables users to use Jupyter and Zeppelin notebook environments for ETL script development.
While Glue development endpoints provided a mechanism for users to develop and test Glue ETL scripts, it required users to create and manage development endpoints and notebook servers. Glue interactive sessions made this process easier by allowing users to use their own notebook environments.
In the next section, we’ll explore interactive sessions in more detail.
AWS Glue interactive sessions
Glue interactive sessions introduced the optimizations that are used for Glue ETL v2.0 infrastructure provisioning to development environments. This can be used by users via custom-built Jupyter kernels. Glue interactive sessions are not long-running Spark clusters and can be instantaneously created or torn down (using the %delete_session magic command). The cold-start duration is significantly less (approximately 7 to 30 seconds) compared to development endpoints (10 to 20 minutes).
Interactive sessions make it easier for users to access the session from Jupyter notebook environments hosted anywhere (the notebook server can be running locally on a user workstation as well) with minimal configuration. The session is created on-demand when the user starts the session in the notebook using the %new_session magic command and can be configured to auto-terminate when there is no user activity for a set period (with the %idle_timeout magic variable).
To set up Glue interactive sessions, all we need is a Jupyter environment with Python 3.6 or above with Glue kernels installed and connectivity to AWS Glue APIs. We can follow the steps available at https://docs.aws.amazon.com/glue/latest/dg/interactive-sessions.html to set up an interactive sessions environment.
The configuration for the interactive session (similar to the ETL job configuration) can be done using the magic variables that are available in Glue kernels. An exhaustive list of the magic variables that are available in Glue kernels can be found at https://docs.aws.amazon.com/glue/latest/dg/interactive-sessions-magics.html.
As we can see, with minimal setup, we can start developing ETL scripts from any Jupyter environment, so long as Glue kernels are installed and connectivity to Glue APIs is available.
In the next section, we will explore Glue triggers, which allow us to orchestrate complex Glue workloads since we can execute Glue jobs or crawlers on-demand, based on a schedule or the outcome of a condition.
Triggers
Triggers are Glue Data Catalog objects that can be used to start (manually or automatically) one or more crawlers or ETL jobs. Triggers allow users to chain crawlers and ETL jobs that depend on each other.
There are three types of triggers:
- On-demand triggers: These triggers allow users to start one or more crawlers or ETL jobs by activating the trigger. This can be done manually or via an event-driven API call.
- Scheduled triggers: These time-based triggers are fired based on a specified cron expression.
- Conditional triggers: Conditional triggers fire when the previous job(s)/crawler(s) satisfy the conditions specified. Conditional triggers watch the status of the jobs/crawlers specified – success, failed, timeout, and so on. If the list of conditions specified is satisfied, the trigger is fired.
Note
A scheduled/conditional trigger must be in the ACTIVATED state (and not in the CREATED/DEACTIVATED state) for the trigger to start firing based on a schedule or a specific condition. This is the first thing that the user can check if a scheduled/conditional trigger is not firing as expected.
When multiple glue resources are chained using triggers, the dependent job/crawler is started, provided that the previous job/crawler was started by a trigger.
If we are designing a chain of dependent jobs/crawlers, it is important to make sure that all the jobs and crawlers in the chain are descendants of the same scheduled/on-demand trigger.
Triggers can be part of a Glue workflow or they can be independent. We can design a chain of dependent jobs and crawlers. However, Glue workflows are preferable while designing complex multi-job ETL operations. We will discuss Glue workflows and blueprints in detail later in this book.
Summary
In this chapter, we introduced different AWS Glue microservices, including Glue Data Catalog, crawlers, classifiers, connections, ETL jobs, development endpoints, the schema registry, and triggers. We also discussed the key features of each of those different microservices to understand how they aid in different stages of data integration.
Then, we explored the structure of Glue Data Catalog, Glue connections, and the mechanisms used by crawlers and classifiers for data discovery. We also talked about the different classes/APIs that are available in AWS Glue ETL that help with data preparation and transformation. After this, we briefly explored development endpoints and interactive sessions, which make it easy for data engineers/developers to test and write ETL jobs. Then, we explored AWS Glue Triggers and understood how they help us orchestrate complex ETL workflows by allowing Glue users to chain crawlers and ETL jobs based on specific conditions or a schedule.
In the next chapter, we will discuss some of the key features of AWS Glue ETL jobs in detail and explore how they can be used to prepare and ingest data from different types of data stores.