
Chapter 8: Data Security
At AWS, we like to say that security is "job zero," in that security is more important than even priority tasks. Glue has been built from the ground up with that tenet in mind, and that, together with all the security features of AWS services, makes data security an easy – but powerful – area to cover.
The Glue security model relies and builds upon concepts common to all AWS services, such as IAM roles, policies, and S3 encryption. Throughout this chapter, we’ll cover different approaches and configurations to ensure the security of your data lake and data pipelines. This will include dealing with concepts such as encryption (both in transit and at rest), logging, and retention.
In this chapter, we will cover the following topics:
- Access control
- Encryption
- Network
Technical requirements
The code for this chapter can be found in this book’s GitHub repository at https://github.com/PacktPublishing/Serverless-ETL-and-Analytics-with-AWS-Glue.
Access control
A large part of security is determining who can access data and in which ways. In this section, we will cover how to configure access control for all the components of a Glue data lake.
IAM permissions
Much like other AWS services, AWS Glue relies on IAM (https://aws.amazon.com/iam/) to provide access control for the service itself, meaning users need to be granted access for IAM to Glue operations to manage and retrieve elements of the data lake.
All IAM permissions depend on the resource’s specifications, which in AWS are uniquely identified through an Amazon Resource Name (ARN). Within Glue, only certain types of resources get ARN identifiers. Other resources, such as workflows, for instance, do not support the use of ARNs, so permissions cannot be granted on a resource-specific basis. For a complete list of resource ARNs, please refer to the following AWS documentation page: https://docs.aws.amazon.com/glue/latest/dg/glue-specifying-resource-arns.html.
For Data Catalog resources, all permissions that have been granted to objects that depend on parents also need permission to access the parents. For instance, granting john access to glue:GetTable on the sales table will also require giving john access to the database and Data Catalog that holds the table. Additionally, all delete operations require the opposite: the user must also have permission to access all child objects. For instance, if john wants to delete the sales table, they will also need permission to delete all table versions and partitions present in the table.
Glue dependencies on other AWS services
AWS Glue relies on capabilities provided by other services, such as VPC networking or CloudWatch for logging. When using the AWS Web UI to configure Glue resources, it will list and filter results, which means access will also have to be granted to them to fully manage a data lake. This includes the following:
- IAM itself to list and assign IAM roles to Glue resources
- CloudWatch logs to list and read the execution logs of Glue resources
- VPC to list and assign network resources such as VPCs, subnets, and security groups to Glue resources
- S3 to list, read, and write buckets and objects
- Redshift to list and access clusters
- RDS to list and access databases
Without access to these permissions, the Web UI will often display error messages and incomplete results.
Resource-based versus identity-based policies
Within the AWS permissions model, IAM permissions policies can be attached to either a resource (an AWS component, such as an S3 bucket) or an identity (such as a user). With resource-based policies, the resource defines who can access or control it. Identity-based policies work the other way round: access to resources is defined by the permissions attached to a user or role.
Resource-based policies allow you to compact all access rules down to a single document, whereas identity-based policies offer more flexibility and allow for individual user management. Typically, and unless you are managing a small set of resources and entities, identity-based policies are preferred since it’s easier to associate each user or IAM role with its permissions, rather than having to modify the permissions of all resources it has to access.
In the case of Glue, only the Data Catalog accepts policies – it is not possible to attach policies to Glue databases, tables, crawlers, or jobs. Let’s say you wanted to grant john access to the payments table in the sales database. You could achieve this with either a resource-based policy attached to your catalog, or an identity-based policy attached to john. Let’s compare how both are used in their JSON form:
- Resource-based policy: The following example showcases a JSON-formatted policy attached to a Glue Data Catalog. The policy grants john access to the glue:GetTable operation, but only against the payments table within the sales database:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"glue:GetTable"
],
"Principal": {"AWS": [
"arn:aws:iam::account-id:user/john"
]},
"Resource": [
"arn:aws:glue:us-east-1:account-id:table/sales/payments"
]
}
]
}
- Identity-based policy: The following example showcases granting the same permissions but by attaching them to john rather than the Data Catalog itself:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AccessPayments",
"Effect": "Allow",
"Action": [
"glue:GetTable"
],
"Resource": "arn:aws:glue:us-east-1:account-id:table/sales/payments"
}
]
}
Managing access through a policy attached to your AWS account’s Data Catalog comes with two main limitations:
- Only one policy can be attached to the Catalog.
- This policy is limited to 10 KB.
These limitations reinforce the fact that using resource-based policies is not recommended for large accounts or organizations, as the policy will be limited in size. There are additional limitations in the clauses that can be specified in the policy, which you can find in the AWS documentation at https://docs.aws.amazon.com/glue/latest/dg/glue-resource-policies.html#overview-resource-policies.
Cross-account access
A very common strategy in large multi-account AWS organizations is to centralize all table definitions into a single Data Catalog, then use other secondary accounts to process the data in them. Much like with other AWS services, cross-account access is possible and can be configured through IAM permissions, both with resource-based and identity-based policies.
Now, let’s assume that the Data Catalog holding the sales database and the payments table is stored in one AWS account (account A) and that john is located in another (account B). The following resource-based policy will have to be attached to the Data Catalog in account A:
{"Version": "2012-10-17",
"Statement": [
{"Effect": "Allow",
"Action": [
"glue:GetTable"
],
"Principal": {"AWS": ["arn:aws:iam::account-B:user/John"
]},
"Resource": [
"arn:aws:glue:us-east-1:account-A:catalog",
"arn:aws:glue:us-east-1:account-A:table/sales/payments"
]
}
]
}
On top of that, the administrator of account B will have to grant john permission to run glue:GetTable on account A, as follows:
{"Version": "2012-10-17",
"Statement": [
{"Effect": "Allow",
"Action": [
"glue:GetTable"
],
"Resource": [
"arn:aws:glue:us-east-1:account-A:catalog",
"arn:aws:glue:us-east-1:account-A:table/sales/payments"
]
}
]
}
For identity-based policies, the best way to achieve this is through IAM role assumption (https://docs.aws.amazon.com/STS/latest/APIReference/API_AssumeRole.html). This mechanism allows a user or IAM role to assume the credentials and permissions of another IAM role. Cross-account access is granted by the owner of account A by creating an IAM role and modifying its trust policy to be allowed by john in account B. The owner of account B will then have to give john permission to assume the role in account A, after which john should have access to the table.
Accessing cross-account Data Catalog resources is always done by giving a value to the CatalogId parameter, whether it is an API call, an AWS CLI command, or code in a Glue ETL job. Keep in mind that the ID of the Data Catalog is the same as the ID of the AWS account holding it.
Unlike with S3 objects, cross-account tables and databases must be owned by the account hosting the Data Catalog rather than whoever created them. In the example given earlier, the AWS account holding the sales database will be the owner of any tables or databases created by john and will have immediate access to them.
Note that cross-account access has certain limitations, the most notable of which is the inability to use Glue crawlers with cross-account setups. For a complete list of the limitations, check out the AWS documentation at https://docs.aws.amazon.com/glue/latest/dg/cross-account-access.html#cross-account-limitations.
Tag-based access control
IAM policies support the use of conditionals to determine which resources are affected by the permissions rule. A very common practice with AWS resources is to attach tags to them and make use of those tags to determine access and permissions. For instance, given an organization with two teams (sales and marketing), each team could tag their resources with a tag that specifies their team’s name and, through that, restrict access to only themselves. Tags can also have other management purposes, such as separating billing into groups or for automated resource management.
Tags are always expressed in the form of a key/value pair. AWS Glue supports the use of tags for some of its resources, including the following:
- Connections
- Crawlers
- ETL jobs
- Development endpoints
- ML transformations
- Triggers
- Workflows
Tags can be added to any of these resource types at creation time, but they can also be added or removed for as long as the resource exists. The following is an example of an IAM policy that allows access to an ETL job’s definition based on a tag with a "team" key and a "marketing" value:
{"Effect": "Allow",
"Action": [
"glue:GetJob"
],
"Resource": "*",
"Condition": { "ForAnyValue:StringEquals": {"aws:ResourceTag/team": "marketing"
}
}
}
This covers the Glue side of permissions management. In the next section, we’ll discuss managing permissions in terms of S3.
S3 bucket policies
The previous sections described how to grant access to Glue resources. However, you will also need to restrict access to the data in your data lake. The process for this will vary, depending on where the data is stored. Java Database Connectivity (JDBC) databases can restrict access through user credentials and database permissions while DynamoDB tables can use IAM policies. In terms of S3 buckets, an effective way of restricting access is by using an S3 bucket policy.
S3 bucket policies are a form of resource-based access control where an IAM policy is attached to a bucket. This policy then determines what actions can be performed on objects within the bucket, and who can perform them. Only the bucket owner can attach a policy to the bucket, and the policy will only apply to objects owned by the bucket owner – not third accounts. For instance, the following is a bucket policy that’s been designed to give read access to a third AWS account:
{"Version": "2012-10-17",
"Statement": [
{"Sid": "AddCannedAcl",
"Effect": "Allow",
"Principal": {"AWS": [
"arn:aws:iam::111122223333:root",
"arn:aws:iam::444455556666:root"
]
},
"Action": [
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": "arn:aws:s3:::DOC-EXAMPLE-BUCKET/*"
}
]
}
In the context of Glue, using S3 bucket policies means specific access rules will need to be granted – not to the users using Glue, but to the IAM roles attached to crawlers, ETL jobs, and development endpoints.
S3 object ownership
When writing results with a Glue ETL job or development endpoint, the resulting objects will be owned by the account that owns the IAM role attached to said job or endpoint. In most scenarios, where your job or endpoint is writing to a bucket you own, this is meaningless as access will always be guaranteed. However, read access problems can arise when the destination S3 bucket is owned by a different AWS account.
When writing cross-account access, the objects will be in a bucket owned by a different account. However, each will have the writer account as its owner – resulting in access errors when they are read afterward. The best way to avoid this is by tackling the issue from both ends, as follows:
- Set the right object owner when writing.
Your ETL job or development endpoint can be configured to write objects that are owned by the same owner as the bucket containing them, avoiding the problem. To do so, a special configuration property must be passed onto the Hadoop configuration object, like so:
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
glueContext._jsc.hadoopConfiguration().set("fs.s3.canned.acl", "BucketOwnerFullControl")
Any subsequent write operations after this configuration change will address the issue.
- Forbid non-bucket-owned writes.
You can also configure the S3 buckets in your data lake to reject any writes that don’t set the object owner properly. This will not modify the owner of already-existing objects, but it will cause any future incorrect writes to fail, forcing the writer to set permissions properly and avoid situations where data must be rewritten or reassigned to a different owner.
Such a configuration can be achieved by configuring the S3 bucket policy of your buckets. The following example shows how this can be done:
{
"Version":"2012-10-17",
"Statement":[
{
"Sid":"OnlyAllowBucketOwnerFullControl",
"Effect":"Allow",
"Principal":{"AWS":"1234567890"},
"Action":"s3:PutObject",
"Resource":"arn:aws:s3:::my-bucket/*",
"Condition": {
"StringEquals": {"s3:x-amz-acl":"bucket-owner-full-control"}
}
}
]
}
With that, we have discussed permissions management from both the Glue and S3 perspectives. However, permissions can only be granted to whole tables without any other granularity. While this works, recent legal requirements that have been imposed by regulations around the world have caused use cases where users only have access to parts of a table valid. In the next section, we will discuss Lake Formation, an AWS service that provides such capabilities.
Lake Formation permissions
AWS Lake Formation is a service that provides data lake capabilities on AWS resources. Even though it is separate from AWS Glue and can be used independently, Lake Formation and Glue share the same Data Catalog and are designed to work together from the ground up.
Lake Formation provides a wide array of features to support and manage data lakes. However, in this chapter, we are going to focus on permissions. Lake Formation permissions are an additional layer on top of IAM permissions that can be used to control access to both data and metadata. Lake Formation also provides fine-grained access control to not just tables, but also the rows and columns within those tables. This is particularly powerful for any company or organization going through compliance regulations.
When using Lake Formation, the data lake administrator decides which S3 locations and Data Catalog databases/tables are part of the data lake. For any request to any resource that is part of the data lake, the necessary permissions will have to be validated against both IAM and Lake Formation – otherwise, the request will fail.
The Lake Formation permissions management system is very similar to that of relational databases, where permissions are granted or removed using the GRANT or REVOKE statements, respectively. Now, let’s discuss the different capabilities of Lake Formation and the permissions at different levels.
Data Catalog permissions
Data Catalog permissions refer to the ability to manage, create, and delete resources within the Data Catalog. These can be granted to either databases or tables, with the option of adding row/column granularity when granting access to a table. Permissions can either be granted to IAM principals in your AWS account or principals in other accounts, giving them access to your databases, tables, and their underlying data.
Permission management is done through the GrantPermissions and RevokePermissions API calls, which take in the following parameters:
- Principal: The IAM principal that the operation involves. This can be an IAM user, an IAM role, or an AWS organization.
- Resource: The Data Catalog resource (database, table, or table subset) that the operation grants/removes access to/from.
- Permissions: The list of operations being granted or revoked access. Lake Formation supports the following operations:
- SELECT
- ALTER
- DROP
- DELETE
- INSERT
- DESCRIBE
- CREATE_DATABASE
- CREATE_TABLE
- DATA_LOCATION_ACCESS
- CREATE_TAG
- ALTER_TAG
- DELETE_TAG
- DESCRIBE_TAG
- ASSOCIATE_TAG
For instance, the following AWS CLI command grants SELECT permissions to john on the sales table in the payments database:
aws lakeformation grant-permissions --principal DataLakePrincipalIdentifier=arn:aws:iam::1234567890:user/john --resource '{ "Table": {"CatalogId": "1234567890",
"DatabaseName": "payments",
"Name": "sales"
}
}' --permissions DESCRIBE
In the next section, we’ll discuss how to manage permissions for large groups of entities, typically found in large organizations.
Tag-based access control
Granting permissions to individual entities can quickly become tedious or repetitive to manage in organizations with large amounts of users and resources. This is a similar problem that happens when dealing with IAM permissions on large AWS accounts, and the typical recommendation is to group resources through tagging and then use those tags to determine access permissions.
Lake Formation offers a very similar approach with tag-based access control (or LF-TBAC). This feature allows you to manage permissions on a larger scale by granting permissions to tags and then attaching those tags to all the resources that fall under the same permissions model. For instance, if the sales department within your company has upwards of 1,000 tables, giving john the right access to all of them can become problematic and also consume a very large amount of API calls. With LF-TBAC, all these tables can be tagged under the department: sales key/value pair, and then john can be granted access to the tag. All tables with the tag will immediately inherit the permissions of the associated tag, reducing the amount of management overhead.
Keep in mind that Lake Formation tags are different than regular AWS resource tags. Lake Formation tags only exist within the domain of Lake Formation and only serve the purpose of managing Lake Formation permissions. Resources can still be attached regularly to AWS resource tags and their IAM access can be managed through those tags, regardless of their Lake Formation tags.
Granting permissions based on Lake Formation tags is similar to basing them on regular Lake Formation resources. For both the GrantPermissions and RevokePermissions API calls, the only difference is to specify a Lake Formation tag instead of a Lake Formation resource. For instance, to grant john select access on all tables with the department: sales tag, the following AWS CLI command can be executed:
aws lakeformation grant-permissions --principal DataLakePrincipalIdentifier=arn:aws:iam::1234567890:user/john --resource '{ "LFTagPolicy": {"CatalogId":"1234567890",
"ResourceType":"TABLE",
"Expression": [{"TagKey": "department","TagValues": ["sales]}]'--permissions SELECT
With this, we’ve covered all there is to Data Catalog permissions. The next section will go over data permissions.
Data – S3 permissions set
Lake Formation also requires data lake administrators to set permissions for their data locations in S3. A user with permissions for a data location will not just be able to read data from that location, but also create databases and tables that point to it. Therefore, unless a user has a very particular use case where only metadata access is needed, most users will need data access on top of metadata access – if it’s not for data reading, it’s at least to be able to create and define tables.
Granting and revoking permissions to/from an S3 data location is no different than doing so to/from a Data Catalog resource, with the only difference being the resource parameter will have to be a data location rather than a catalog resource. The following AWS CLI command shows how to grant john access to an S3 location defined by its ARN resource:
aws lakeformation grant-permissions --principal DataLakePrincipalIdentifier=arn:aws:iam::1234567890:user/john --resource '{ "DataLocation": {"CatalogId":"1234567890",
"ResourceArn":"arn:aws:s3:::bucket_name/key_name"'
--permissions DATA_LOCATION_ACCESS
Notice how the permission being granted here is DATA_LOCATION_ACCESS rather than the usual SELECT or DESCRIBE. This is a static value that must always be used with data location permissions.
Data location permissions can also be granted to a different account. The following code shows an example of the 1234567890 account granting access to the 0987654321 account:
aws lakeformation grant-permissions
--principal DataLakePrincipalIdentifier=0987654321
--permissions "DATA_LOCATION_ACCESS"
--resource '{ "DataLocation":{"CatalogId":"1234567890",
"ResourceArn":"arn:aws:s3:::bucket_name/key_name "
}}
When granting cross-account access, the receiving account can also be permitted to grant access to others by itself. This can be done through the permissions-with-grant-option parameter of the API call, as shown here:
aws lakeformation grant-permissions
--principal DataLakePrincipalIdentifier=0987654321
--permissions-with-grant-option "DATA_LOCATION_ACCESS"
--permissions "DATA_LOCATION_ACCESS"
--resource '{ "DataLocation":{"CatalogId":"1234567890",
"ResourceArn":"arn:aws:s3:::bucket_name/key_name "
}}
This concludes all Lake Formation features related to data security. In the next section, we’ll talk about the different aspects of encryption, and how they can be configured in Glue.
Encryption
Encryption is the basis of all data security policies, as it ensures critical data cannot fall into the hands of potential attackers. In recent years, encryption has also taken increased importance because of compliance and personal data protection regulations. AWS Glue offers several features to support encrypting your data both at rest and in transit. This section will cover all encryption options and features while providing examples and best practices.
Encryption at rest
When it comes to encryption at rest in Glue, it can happen at three different levels:
- Encrypting the metadata that defines your data lake, which is handled by Glue itself
- Encrypting the data auxiliary to executing Glue resources
- Encrypting the data within your data lake
In this section, we will go through each level. For encryption, Glue relies on AWS Key Management Service (KMS), an AWS service that provides serverless hosting and management of encryption keys. All encryption features support the use of KMS keys. However, Glue only supports symmetric ones – keys that are used to both encrypt and decrypt data. When specifying KMS keys for any of the encryption features, make sure you enter the ARN of a symmetric key as Glue will not validate whether it is symmetric or not before attempting to encrypt or decrypt, resulting in potential failures down the line.
Metadata encryption
Glue is capable of encrypting all metadata in your Data Catalog using a KMS key. This covers the following catalog objects:
- Databases
- Tables
- Table versions
- Partitions
- Connections
- User-defined functions
Metadata encryption works as a toggle (either it is enabled or not). Despite that, encryption only takes effect for objects created after it has been enabled and doesn’t happen retroactively. Let’s say the following happens:
- john creates a Glue table (table A) in the Data Catalog.
- The AWS account administrator enables Glue metadata encryption.
- john creates another Glue table (table B) in the Data Catalog.
- The AWS account administrator disables Glue metadata encryption.
In this scenario, table A would not be encrypted (even after the administrator has enabled encryption) and table B would be encrypted (even after the administrator has disabled encryption).
Additionally, Glue can encrypt passwords that have been used for Glue connections using a KMS key. This can be different from the one used for the Data Catalog. This will ensure connection passwords are encrypted when stored in AWS, and that any entity requesting them must also have IAM permissions to run kms:Decrypt on the KMS key used to encrypt the data.
Data Catalog and connection password encryption can be enabled using either the AWS Web Console or the SDK/CLI through the PutDataCatalogEncryptionSettings API call. This call takes parameters in the following structure:
{ "EncryptionAtRest": {"CatalogEncryptionMode": "DISABLED"|"SSE-KMS",
"SseAwsKmsKeyId": "string"
},
"ConnectionPasswordEncryption": {"ReturnConnectionPasswordEncrypted": true|false,
"AwsKmsKeyId": "string"
}
}
If no KMS key is specified for either of the encryption options, Glue will use the service’s default encryption key (aws/glue). To access any encrypted objects, the requesting entity (whether it is an IAM user or an IAM role) will need to have IAM permissions to use the kms:Decrypt, kms:Encrypt, and kms:GenerateDataKey API calls, allowing access to the KMS key that was used for encryption.
If a non-default key was configured to encrypt the Data Catalog and it is deleted from the AWS account, all objects encrypted by it will become non-decryptable permanently. Always make sure to manage KMS keys properly.
Auxiliary data encryption
When running Glue resources such as crawlers or ETL jobs, data is generated in the form of execution logs and job bookmarks. Even though this data may seem harmless at first, more often than not, it will contain critical information such as table column names or data samples, which can represent data leaks. Glue also supports encrypting these data sources so that your data lake is properly secured and fully compliant with regulations.
Encrypting Glue resources is always handled through Glue security configurations. A security configuration is a set of defined encryption rules that can be attached to a Glue crawler, a Glue ETL job, or a Glue development endpoint, determining how logs and bookmarks are encrypted for them.
Security configurations can be created through the CreateSecurityConfiguration API call, which takes parameters in the following structure:
{"S3Encryption": [
{"S3EncryptionMode": "DISABLED"|"SSE-KMS"|"SSE-S3",
"KmsKeyArn": "string"
}
...
],
"CloudWatchEncryption": {"CloudWatchEncryptionMode": "DISABLED"|"SSE-KMS",
"KmsKeyArn": "string"
},
"JobBookmarksEncryption": {"JobBookmarksEncryptionMode": "DISABLED"|"CSE-KMS",
"KmsKeyArn": "string"
}
}
For the specified KMS keys to be used, the account administrator must grant AWS KMS IAM permissions to the roles used for Glue resources. This process is described in the KMS documentation at https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/encrypt-log-data-kms.html.
Data encryption
The process of encrypting the data that resides in your data lake will be a task shared between all silos or services involved: your RDS-backed tables will have to use RDS encryption (https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.Encryption.html). DynamoDB offers similar encryption-at-rest capabilities (https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/EncryptionAtRest.html) and any S3 bucket can benefit from S3 encryption (https://docs.aws.amazon.com/AmazonS3/latest/userguide/bucket-encryption.html).
That said, Glue offers some additional features when writing data as part of the output of an ETL job. ETL jobs can be configured to write either S3-encrypted or KMS-encrypted output when the target is an S3 location, ensuring all the results of your jobs are protected, regardless of the configuration present at the storage layer.
ETL job data encryption can be enabled in two ways, depending on the type of encryption. Let’s look at these two encryption types, as follows:
- S3-based encryption (SSE-S3) is configured by passing a property to the ETL job definition, either at the time of creation (CreateJob) or when editing it (UpdateJob). This property is defined inside the DefaultArguments property of the job:
"DefaultArguments": {
"—TempDir": "s3://path/ ",
"—encryption-type": "sse-s3",
"—job-bookmark-option": "job-bookmark-disable",
"—job-language": "python"
}
- KMS-based encryption (SSE-KMS) is configured by creating a security configuration and attaching it to the ETL job, similar to how log and bookmark encryption work.
If both options are configured simultaneously, KMS encryption will be used over S3. For security configurations to take effect within an ETL job, the Job.init() statement must be executed within the job’s code:
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
This covers all the features and aspects of at-rest encryption. In the next section, we’ll discuss encryption in transit.
Encryption in transit
Glue relies on Secure Sockets Layer (SSL) encryption for encryption in transit, which means connections to other AWS services (such as when reading or writing to S3 or DynamoDB) are made securely and are encrypted. For non-AWS connections (such as when connecting to a JDBC database), Glue supports enforcing SSL connections, which will cause the crawler or ETL job trying to use the connection to fail if connecting over SSL doesn’t work.
Enforcing an SSL connection also allows you to configure the usage of custom SSL certificates to authenticate the connection, which allows users to connect securely to JDBC databases using a proprietary certificate that hasn’t been publicly validated. The connection can also be configured to pass values to the SSL_SERVER_CERT_DN (for Oracle databases) or hostNameInCertificate (for SQL Server databases) parameters of the target database, which allows you to configure custom distinguished names and domain names for the database server, respectively.
FIPS encryption
AWS offers service endpoints that use cryptographic modules compliant with Federal Information Processing Standards (FIPS) rather than standard SSL for communication. If the purposes of your Glue usage must meet such a standard, Glue offers FIPS-compliant endpoints for all North American regions, including GovCloud ones.
Development endpoint connections
Glue offers development endpoints, (https://docs.aws.amazon.com/glue/latest/dg/dev-endpoint.html), which can be used to create a static development environment in the cloud that users can log into and use to develop and test scripts for ETL jobs. Development endpoints can be accessed via SSH and do not support authentication through a user/password combination – only SSH keys are supported. The use of SSH for communication also ensures all traffic between your local computer and the development endpoint is encrypted.
When creating a development endpoint, you must provide one or more public keys. These will be used to authenticate users logging in. If the development endpoint is going to be shared among several users, it is within best practices to create individual key pairs for each one and pass all public keys to the development endpoint, thus avoiding having to share SSH keys between users.
Once the endpoint is up and running, the UpdateDevEndpoint API call allows you to add new keys and delete unused ones. Reviewing and rotating SSH keys is a good practice that will prevent unwanted access to the development endpoint.
With this, we’ve covered all aspects of encryption in AWS Glue. In the next section, we’ll discuss network security, which handles the security of all communications happening between Glue resources and external ones.
Network
Even though AWS Glue is a serverless service, understanding its network infrastructure and how it connects to resources is a critical part of guaranteeing your data’s security and your organization’s compliance. By default, Glue will always attempt to use the less public route to direct network traffic. However, it is crucial to understand how this routing works to avoid public calls that could compromise your information.
Glue network architecture
Much like with other AWS services, all AWS Glue resources are stored and executed in internal AWS accounts that are not accessible or part of any public infrastructure. This includes your Data Catalog, crawlers, ETL jobs, development endpoints, triggers, and workflows. This is shown in the following diagram:
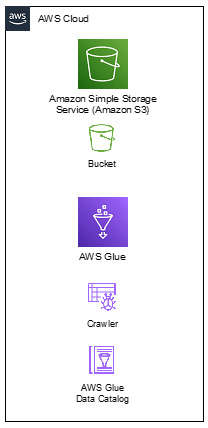
Figure 8.1 – AWS resources within the AWS cloud
If a Glue resource needs access to an S3 location, this communication happens privately and internally through the AWS infrastructure, as shown in the following diagram:
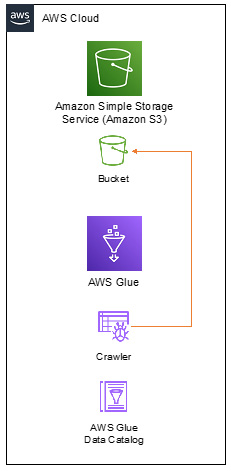
Figure 8.2 – AWS resources communicating through the AWS cloud
However, connecting to any other resource will require Glue to set up a bridge between its internal infrastructure and your AWS VPC. To make this happen, whenever a Glue resource is in execution, Glue will create Elastic Network Interfaces (ENIs) in your VPC and attach them to the nodes running your Glue resource – a process known as requester-managed network interfaces (https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/requester-managed-eni.html).
Let’s say you want to run a crawler to automatically detect the schema of your MySQL database, which is running in an EC2 instance in your account. Since you followed security best practices, this EC2 instance is running in a private subnet within your VPC, which means it is not accessible over the public internet. When you run your Glue crawler, Glue will create ENIs in your VPC, assign private IP addresses to them, and attach them to the nodes that execute the crawler process in the internal AWS infrastructure. Once the crawler finishes running, the ENIs will be detached and deleted, and their IP addresses will be released. The following diagram shows how this works:
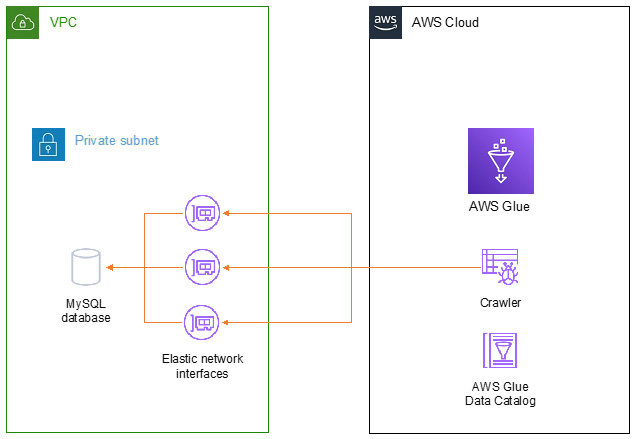
Figure 8.3 – AWS resources communicating with resources in a user’s VPC
This process allows Glue to securely and privately connect to other resources in your AWS account without ever leaving the internal AWS infrastructure. To carry it out, though, Glue will need several parameters, such as the location of your database (VPC and subnet), proper security clearance to access it (security groups), and a way to authenticate within your database. All these parameters are supplied as part of a Glue connection.
Glue connections
A Glue connection is a set of configuration parameters that define the location and way of accessing an external resource so that Glue can automate its access. These parameters include the following:
- VPC and subnet combination.
- One or more security groups.
- If authentication is required, all the necessary parameters for it. These include the following:
- The JDBC URL, which can include parameters to be passed onto the database
- Username and password combination
When creating a Glue connection, you must also specify its type. There are as many types as there are supported connection targets:
- JBDC: Connects to a relational database that supports JBDC
- MongoDB: Connects to a MongoDB or DocumentDB cluster
- Kafka: Connects to an Apache Kafka cluster
In addition to the previous types, there are also three special connection types:
- Network: This connection will simply specify a VPC and subnet without any other parameters. This is designed to route connections through a VPC rather than connecting to a specific resource within it.
- Marketplace: This connection specifies parameters for connectors that have been obtained through the AWS marketplace.
- Custom: This connection specifies parameters for custom connectors that have been created by you.
Attaching a connection to a Glue resource will cause the resource to automatically infer its properties when it is being executed. For instance, a crawler will automatically know which subnet and database to connect to and will have the right security groups to do so.
Network configuration requirements and limitations
For connections to work properly, certain requirements must be met. Let’s look at a few of these requirements, as follows:
- At least one of the security groups that’s attached to the connection must include a self-referencing inbound rule that allows all traffic. Even though such a wide permission may seem like a security issue, permission will only be granted to incoming – not outgoing – connections, and will only take effect between resources that have the security group attached. This rule is necessary to allow proper communication between all Glue resources.
- When creating ENIs to attach to Glue resources, only private IP addresses will be granted to them to guarantee their security. If your resources need to connect to endpoints over the public internet, the lack of public IP addresses will make it impossible.
- When creating a development endpoint, any attached security groups will need to include access to TCP port 22 to allow for SSH logins – otherwise, the endpoint will be inaccessible.
- Connections to databases will require the involved security groups to allow the necessary traffic. For instance, if you’re connecting to a MySQL database, you will need to allow traffic on TCP port 3306.
In the next section, we’ll discuss the requirements and considerations to connect to resources on the public internet.
Connecting to resources on the public internet
As mentioned in the previous section, Glue resources will only get private IP addresses, which makes them unable to communicate with a resource on the public internet. Although this can be a benefit in terms of security, there are situations in which you might be interested in connecting over the public internet, such as trying to reach a resource in your on-premise network or reading data from a publicly-accessible API. There are two ways to make this possible:
- VPC endpoints: If this public communication is necessary for reaching an AWS service (for instance, making an API call to AWS Secrets Manager in your ETL job code to retrieve credentials), you can use VPC endpoints (https://docs.aws.amazon.com/vpc/latest/privatelink/vpc-endpoints.html) to route it through AWS infrastructure instead of the public internet. This is shown in the following diagram:
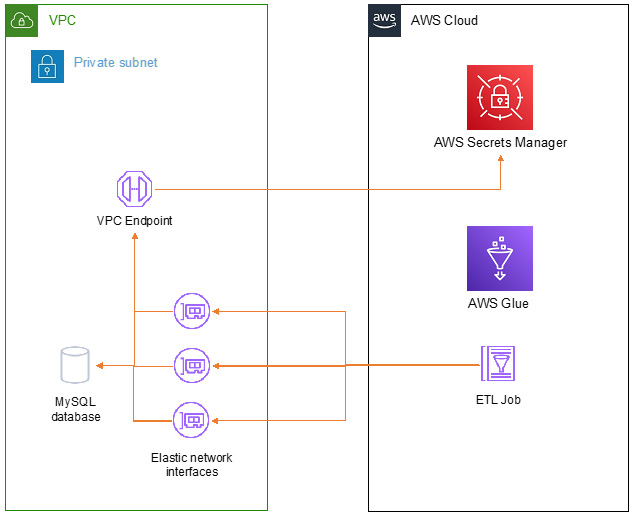
Figure 8.4 – Connecting over a VPC endpoint
Deploying a VPC endpoint in a subnet and updating its associated route table will direct traffic internally, allowing you to communicate with AWS services securely.
- NAT Gateways: If, instead of an AWS service, you are trying to reach a public resource over the internet, the only solution is to grant your resources a public IP address to communicate. VPC NAT Gateways (https://docs.aws.amazon.com/vpc/latest/userguide/vpc-nat-gateway.html) are NAT translation resources offered by AWS VPC that multiplex private IP addresses behind a public one, assigned to the gateway itself. The following diagram shows how such a connection happens:
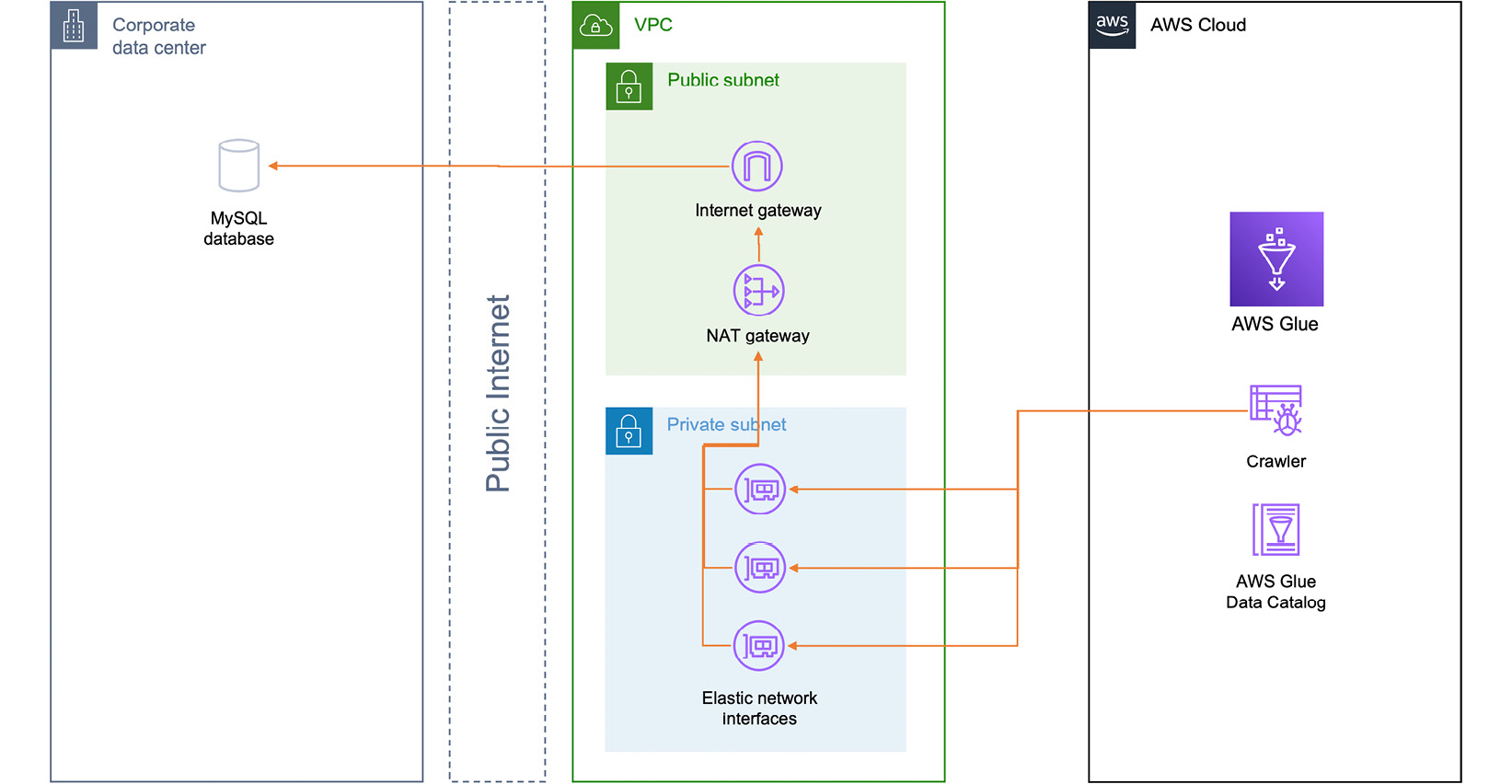
Figure 8.5 – Connecting through a NAT Gateway
When using NAT Gateways, resources can initiate connections to the public internet. However, the opposite can’t happen, which means they are still protected in your private subnet.
This covers all the ways of connecting to resources through the public internet. Next, we’ll discuss other ways to connect to resources offered by AWS VPC.
VPC peering
VPC peering (https://docs.aws.amazon.com/vpc/latest/peering/what-is-vpc-peering.html) is a VPC feature that allows traffic between two VPCs by simply adding routes between them as if they were part of the same network. This feature allows you to solve a variety of challenges that can affect your Glue connectivity.
Managing IP address pools
As mentioned previously, each ENI that’s created by Glue will be assigned an IP address from the subnet it resides in. The amount of IP addresses is directly proportional to the number of nodes that are part of the resource – for instance, in the case of ETL jobs, it will depend on the number of DPUs or workers you assigned to the job.
There are certain situations in which there may not be enough IP addresses for the resource to run properly. For instance, your VPC subnet could have a small range, or it could already have a large number of resources running within it. Alternatively, you may want to run a large ETL job that requires a significant number of addresses.
VPC peering allows you to solve this challenge by creating a new VPC subnet dedicated to Glue resources receiving IP addresses. Since communication between the VPCs is as if they were part of the same, Glue will be able to work without issues and the original VPC or its resources won’t have to be modified.
Connecting to cross-account resources
VPC peering also allows you to create a peering relationship between VPCs in different accounts. This allows for easy cross-account, private connections where a Glue resource can connect to a database owned by a different account in the same organization, for instance.
Connecting to cross-region resources
VPC peering can also bridge two VPCs placed in different regions, allowing for private connections through the AWS infrastructure and avoiding complicated setups to connect to resources in other regions.
AWS PrivateLink
AWS PrivateLink (https://docs.aws.amazon.com/whitepapers/latest/aws-vpc-connectivity-options/aws-privatelink.html) is a VPC service that allows you to publish an endpoint into a VPC, ensuring that traffic between clients on the VPC and the endpoint is always routed through the internal AWS infrastructure and never goes through the public internet. PrivateLink can be used in Glue setups to, for example, publish an endpoint to a JDBC database in the VPC where Glue resources run. PrivateLink endpoints can be published cross-account and cross-region, enabling solutions for complex setups.
Connecting to resources in your on-premise network
Glue is also capable of reaching resources in your local network, allowing, for instance, you to crawl your self-hosted JDBC databases. Just like with any other public resource, Glue can connect through the public internet via a public endpoint; however, this is not a good approach in terms of security. There are several AWS services and products that can help tackle this issue:
- AWS Direct Connect (https://aws.amazon.com/directconnect/) is an AWS service that can establish a direct link between your on-premise data center and the AWS infrastructure. This is a benefit not just in terms of security, but also that it can provide greatly increased speeds and lower latency, which makes it easier to transfer datasets, for instance.
- AWS Site-to-Site VPN (https://docs.aws.amazon.com/vpn/latest/s2svpn/VPC_VPN.html) allows you to create VPN connections between your on-premise network and your AWS VPC. This will still route traffic over the public internet, but it will be encrypted and protected as per the specifications of the VPN software of your choice.
- AWS Managed VPN (https://docs.aws.amazon.com/whitepapers/latest/aws-vpc-connectivity-options/aws-managed-vpn.html) is similar to Site-To-Site VPN in that it uses a VPN solution to encrypt traffic, but this software is managed and deployed by AWS. This may reduce or eliminate the technical overhead of managing such a solution.
- Finally, the AWS Snow Family (https://aws.amazon.com/snow/) is an alternative solution to establishing network links. These are hardware products that can be delivered to your premises and allow you to copy and deliver your datasets to AWS, who will then upload them to your account. This is a more effective solution if you are intending to upload your data to AWS and stop using your on-premises network.
This covers all the options and features for network security. Now, let’s summarize this chapter.
Summary
In this chapter, we discussed all the aspects of security within AWS Glue. We talked about limiting access through IAM permissions on both Glue and S3 and how to extend this through different AWS accounts. We also talked about fine-grained access permissions through AWS Lake Formation.
We discussed how encryption works and how Glue relies on AWS KMS keys to encrypt and decrypt data. We also discussed all the entities within Glue that can be encrypted. We saw different options for auditing access to Glue resources.
Finally, we discussed how Glue works in terms of networking and discussed the different architectures and AWS services that can be used to access resources over networks, including best practices when it comes to connecting over the public internet.
This covers all aspects of security in terms of Glue within your AWS account. The next chapter will also be related to security and permissions to some degree, as it will talk about data sharing and best practices to let others access your Glue resources.