
Chapter 4: Key Features and Use Cases – Focusing on Performance and Security
The chapter you are about to undertake will further enhance your understanding of the ShardingSphere ecosystem and empower your decision-making to assemble your ideal database solution.
We are going to introduce you to the remaining major features of ShardingSphere, namely high availability, data encryption, and observability.
ShardingSphere is built with flexibility in mind, and the desire to empower you to build a solution that best works for you without imposing undesired bloatware on you. Our community has developed these features for those looking to improve and monitor performance as well as enhance their system's security.
In this chapter, we will cover the following topics:
- Understanding High Availability
- Introducing data encryption and decryption
- User authentication
- SQL authority
- Database and app online tracing
- Database gateway
- Distributed SQL
- Understanding the cluster mode
- Cluster management
- Observability
You can find the complete code file here:
https://github.com/PacktPublishing/A-Definitive-Guide-to-Apache-ShardingSphere
Understanding High Availability
High Availability (HA) is one of the important factors that must be considered in the architecture design of distributed systems. The HA of distributed systems ensures that the system can provide services stably. How we minimize the time of service unavailability through design is the goal of HA. As a distributed database service solution, Apache ShardingSphere can provide a distributed capability for the underlying database.
In addition to a HA scheme that can be flexibly compatible with each database and real-time perception of the state changes of the underlying database cluster, the HA of its own services also needs to be guaranteed in the deployment of the production environment.
In the following sections, we will introduce you to HA in general, or refresh your memory if you are already somewhat familiar with the concept. Once complete, you will dive into ShardingSphere's HA.
Database HA
The database is the infrastructure of the software system architecture. The HA of the database is the basis to ensure the security and continuity of business data. For any database, there are many HA schemes for you to choose from. Usually, the HA schemes of the database aim to solve the following list of problems:
- In the case of unexpected downtime or an interruption to the database, the downtime can be reduced as much as needed to ensure that the business will not be interrupted due to the failure of the database.
- The data of the primary node and the backup node shall maintain real-time or final consistency.
- When the database role is switched, the data before and after switching should be consistent.
Currently, read/write splitting is also an essential step for internet software in the data architecture layer. When integrating traditional database HA solutions, usually, it is necessary to deal with the scenario of read/write splitting.
ShardingSphere HA
Apache ShardingSphere adopts the architecture mode of separation of computing and storage. The storage layer is the underlying database cluster managed by ShardingSphere, and the computing layer relies on part of the computing power provided by the underlying database cluster to realize powerful incremental functions. Therefore, the HA of ShardingSphere depends on whether the computing layer and storage layer can provide stable services at the same time. In ShardingSphere, the database clusters of the storage layer are called storage nodes, while the ShardingSphere-Proxy deployment of the computing layer is called computing nodes.
Taking ShardingSphere-Proxy as an example, the following diagram presents the overall topography of a typical system:
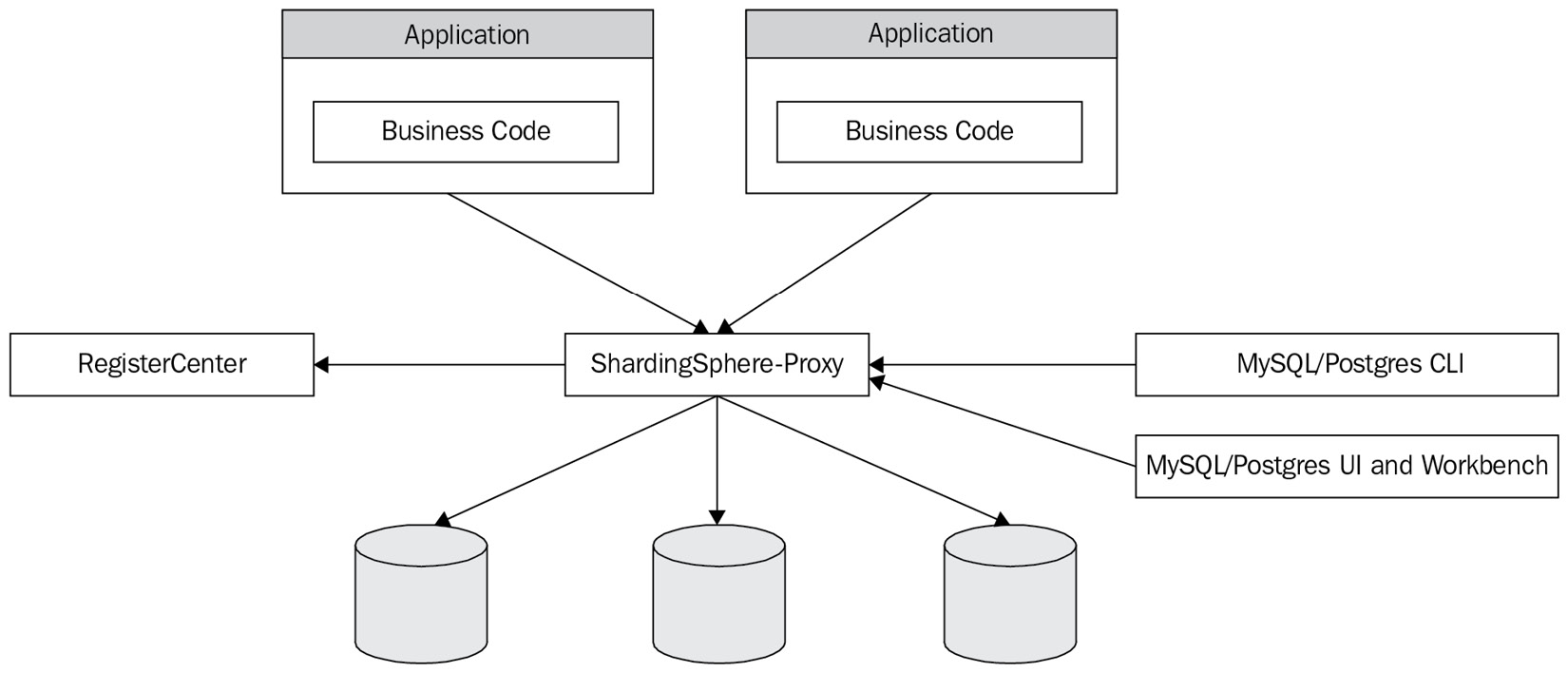
Figure 4.1 – The ShardingSphere-Proxy topography
Thanks to the powerful pluggable architecture of ShardingSphere, the read/write splitting function provided by ShardingSphere can be flexibly combined with HA functions. When the primary-secondary relationship of the underlying database changes, ShardingSphere can automatically route the corresponding SQL to the new database.
With this, in the following sections, let's dive deeper into learning more about computing and storage nodes, how they work, and their application in real-life scenarios.
Computing nodes
As a computing node, ShardingSphere-Proxy is stateless. Therefore, in the same cluster, you can expand the cluster horizontally by adding computing nodes in real time to improve the throughput of the entire ShardingSphere distributed database service. During a low-peak period, users can also release resources by offline computing nodes in real time.
For the HA of the computing node, load balancing software such as haproxy or keepalived can be deployed on the upper layer of the computing node.
Storage nodes
ShardingSphere's storage node is the underlying database node. The HA of the storage node is guaranteed by the underlying database itself. For MySQL, it can use its own MySQL Group Replication (MGR) plugin or third-party orchestrator and other HA schemes, while ShardingSphere can easily integrate the HA schemes of these databases through flexible configuration. Through the internal exploration mechanism, the status information of the underlying database is queried in real time and updated to the ShardingSphere cluster.
How it works
ShardingSphere uses the standard Serial Peripheral Interface (SPI) to integrate the HA schemes of various databases. Each scheme needs to implement the interface of database discovery. During initialization, ShardingSphere will use the user-configured HA scheme to create a scheduling task based on ElasticJob, and by default, execute this task every 5 seconds to query the underlying database status, and update the results to the ShardingSphere cluster in real time.
Application scenarios
In real application scenarios, usually, the HA of the ShardingSphere storage nodes is combined with the read/write splitting function to realize the real-time management of the status of primary-secondary nodes. ShardingSphere can automatically handle scenarios such as primary-secondary switching, having the primary database online, and having the secondary database offline. The following configurations show the scenarios of the combination of read/write splitting and HA:
rules:
!DB_DISCOVERY
dataSources:
pr_ds:
dataSourceNames:
- ds_0
- ds_1
- ds_2
discoveryTypeName: mgr
discoveryTypes:
mgr:
type: MGR
props:
groupName: 92504d5b-6dec-11e8-91ea-246e9612aaf1
zkServerLists: 'localhost:2181'
keepAliveCron: '0/5 * * * * ?'
discoveryTypes:
mgr:
type: MGR
props:
groupName: 92504d5b-6dec-11e8-91ea-246e9612aaf1
The preceding code is the perfect example of a combination of read/write splitting and HA. Now you have acquired the necessary knowledge to move on to more complex features such as encryption.
Introducing data encryption and decryption
Information technology has become increasingly widespread and advanced, making more and more corporations aware of the value of their data assets and the importance of data security.
The need for data encryption and decryption has naturally become commonplace in various enterprises, and data protection methods where you would encode information with an encryption key can allow you to safely manage data.
Considering the current industry demands and pain points, Apache ShardingSphere provides an integrated plan for data encryption. The low-cost, transparent, and safe solution can help all businesses meet their demands for data encryption and decryption.
In the next sections, first, you will gain an understanding of what data encryption is, its application scenarios in both new and established businesses, and finally, move on to ShardingSphere's encryption feature and its workflow.
What are data encryption and decryption?
Data encryption is based on encryption rules and algorithms to transform data and protect user data privacy, while data decryption uses decryption rules to decode encrypted data. Apache ShardingSphere's encryption and decryption module can get the fields that you want to encrypt from SQL, call the encryption algorithm to encrypt the fields, and then store them in a database.
Later, when the user sends a query, ShardingSphere can call the decryption algorithm, decrypt the encrypted column, and return the plaintext data to the user. During the whole process, users do not need to perceive encryption and decryption. Additionally, the module provides complete solutions for both new and established businesses.
In practice, if we were to clarify the differences between new and established businesses, we would find two business scenarios for data encryption. The first business scenario reveals the difficulty of upgrading an old encryption method. Now imagine that Company A is a new business. Everything is new in Company A. If it requires data encryption, its developer team will probably choose a simple data encryption solution just to meet the basic encryption requirements. However, Company A grows rapidly, so the original encryption scheme is not good enough to meet the requirements found in its new business scenarios. Now, it's time for Company A to transform the business system on a large scale, but the cost is too high.
The other scenario describes how hard it will be for a piece of software to be available for use without data encryption to add the data encryption feature into its mature business system. In the past, some businesses chose to store data in plain text, but they now need data encryption. To add data encryption, they have to solve a series of problems such as old data migration encryption (or data cleaning) and recreating related SQL. It's a really complex process, not to mention zero downtime. To support zero-downtime upgrades of a key business, programmers have to establish a pre-release environment and prepare a rollback plan, leading to skyrocketing costs.
Key components
To understand Apache ShardingSphere's encryption and decryption feature, we expect you to understand the related rules and configurations, as shown in the following diagram:
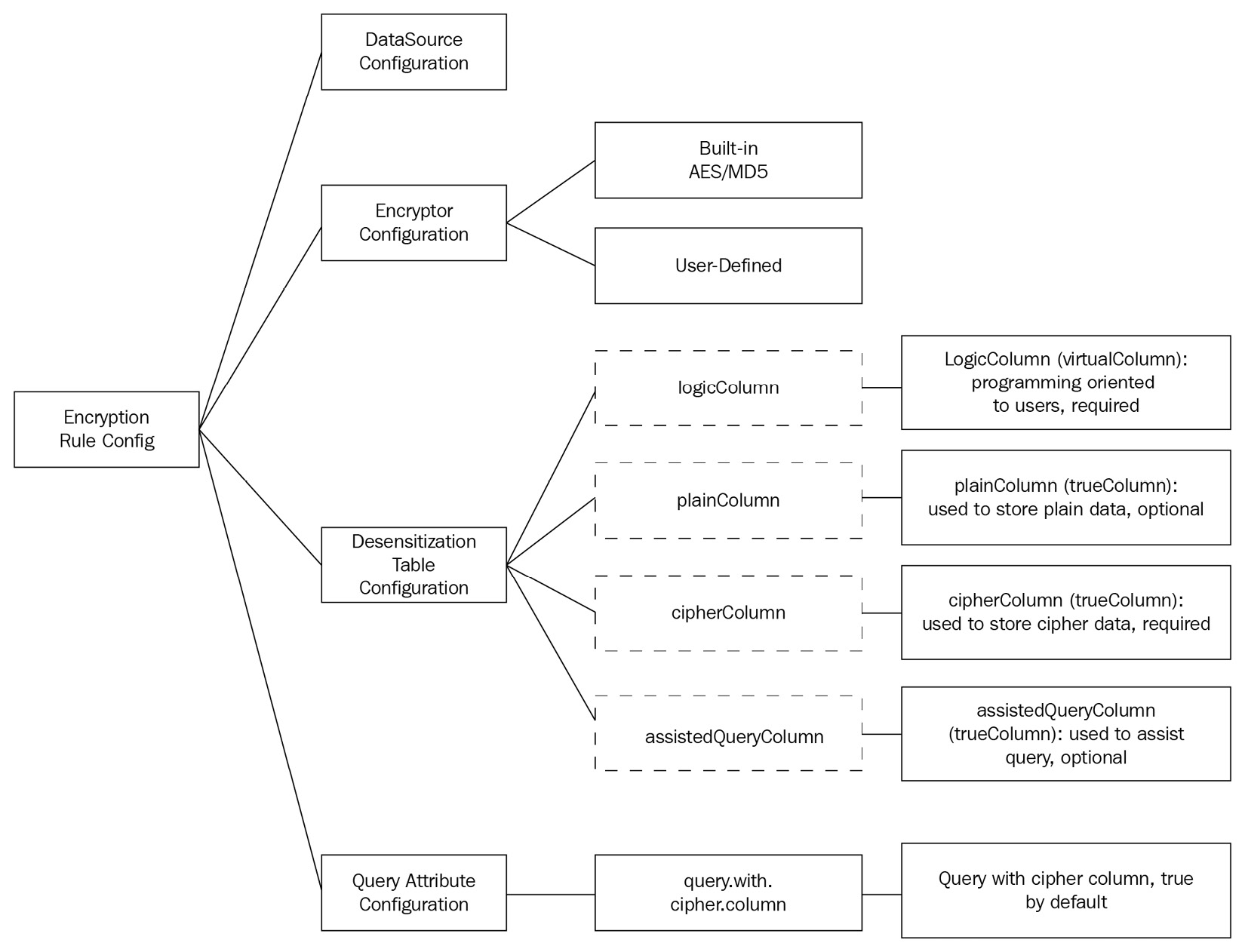
Figure 4.2 – Encryption rule configuration
Let's dig deeper and get an understanding of the terms presented in the preceding diagram:
- Data Source Configuration: This is used to configure the data source.
- Encryption Algorithm Configuration: This refers to the chosen encryption algorithm. Now, ShardingSphere has two built-in encryption algorithms, that is, advanced encryption standard (AES) and message-digest algorithm (MD5). Of course, when necessary, users can leverage the API to develop a custom encryption algorithm.
- Encryption Table Configuration: This is used to show the following:
- Which column is the cipher column storing encrypted data
- Which column is the plain column storing unencrypted data
- Which column is the logic column where the user writes SQL statements
- Logic Column: This is the logical name used to calculate an encryption/decryption column. It's also the logical identifier of the column in SQL. Logical columns include cipher columns (required), assisted query columns (optional), and plaintext columns (optional).
- Cipher Column: This is the encrypted column.
- Assisted Query Column: Literally, the assisted query column is designed to facilitate queries. In terms of some non-idempotent encryption algorithms with higher security levels, ShardingSphere also provides queries with an irreversible idempotent column.
- Plain Column: This is the type of column that stores plaintext. It can still provide services during an encrypted data migration process. The user can delete it when data cleaning ends.
Now we can proceed to understand what implementing encryption with Apache ShardingSphere will look like.
Workflow
In Apache ShardingSphere, the workflow of the encryption and decryption feature is shown in the following diagram:
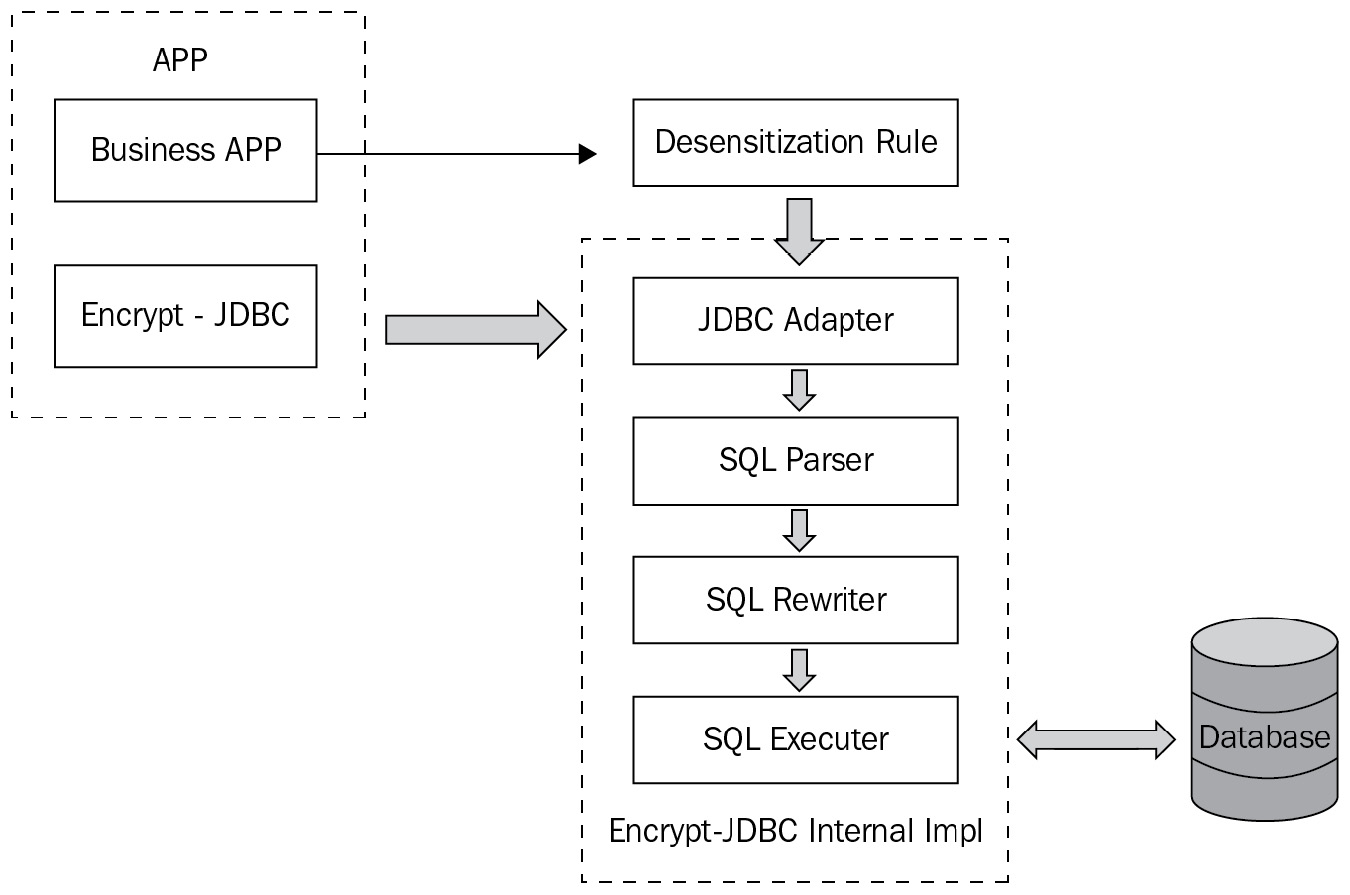
Figure 4.3 – The encryption workflow
At first, the SQL Parser Engine parses your SQL input and extracts the contextual information. Then, SQL Rewriter Engine rewrites the SQL according to the contextual information and the configuration rules of encryption and decryption. During the process, it rewrites logical columns and encrypts the plaintext. Then, the results are executed efficiently and securely by SQL Executor Engine. As you can see, the entire encryption and decryption process is completely transparent to users and perfect for safe data storage:
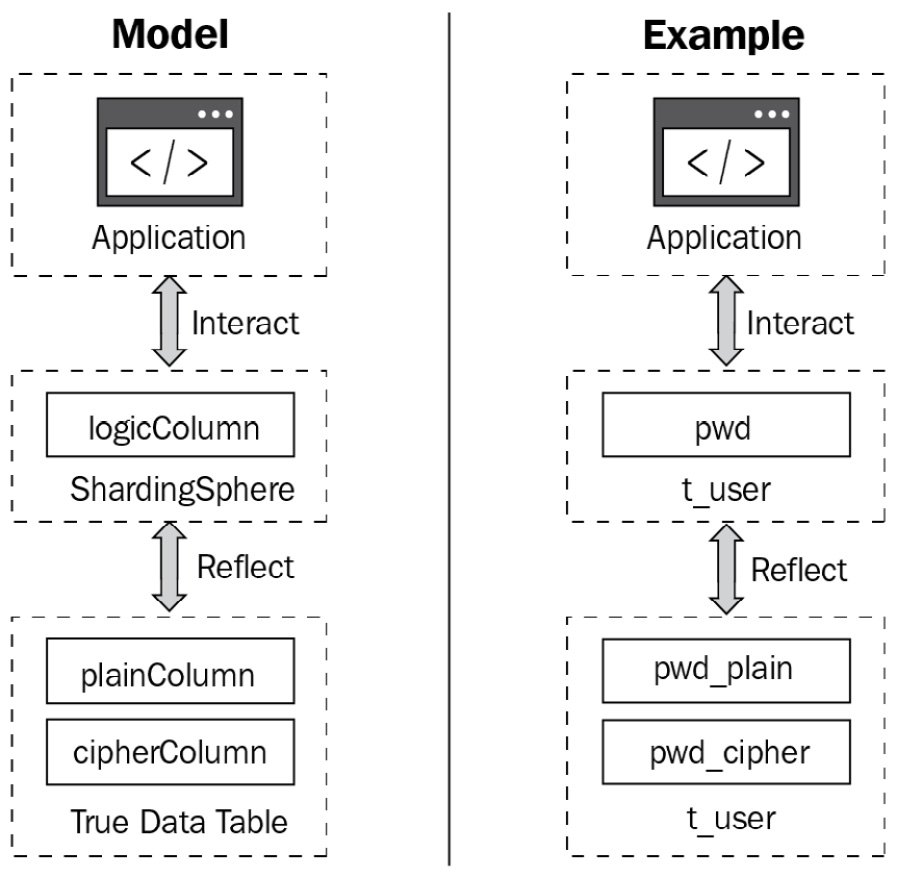
Figure 4.4 – The encryption and decryption process
The workflow process of encryption and decryption is showcased in the following example. Now, let's assume that there is a t_user table in your database. This table contains two fields: pwd_plain (to store plaintext data, that is, the fields to be encrypted) and pwd_cipher (to store ciphertext data, that is, the encrypted fields). At the same time, it's required to define logicColumn as pwd. As the user, you should write the following SQL command: INSERT INTO t_user SET pwd = '123'.
When Apache ShardingSphere receives the SQL command, it will complete the conversion process (as shown in Figure 4.4) to rewrite the actual SQL. From Figure 4.4, you can understand how addition, deletion, modification, and querying work in the encryption module.
Figure 4.5 illustrates the processing flows and logic of the conversion:
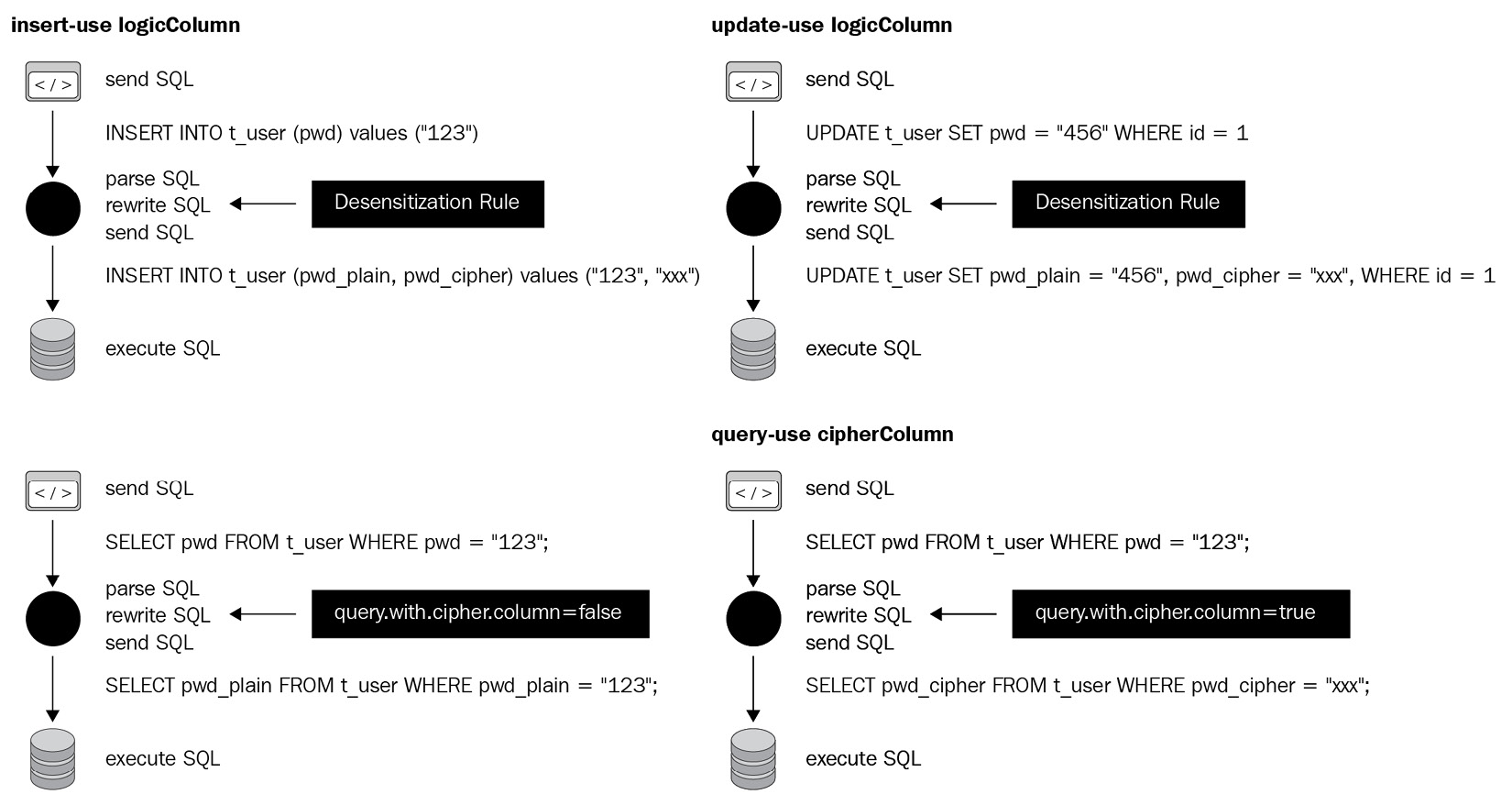
Figure 4.5 – Conversion flow and logic
Let's look at some application scenarios where you would apply the encryption workflow.
Application scenarios
Apache ShardingSphere's encryption and decryption module has already provided users with an integrated solution for encryption and decryption. Both newly launched products and mature products can easily access the encryption and decryption module.
Given that it's not necessary for newly-released products to adopt data migration and data transformation, users only need to access the encryption and decryption module and create relevant configurations and rules. After you select the right encryption algorithm (for example, AES), you just need to configure logical columns (which are used to write user-oriented SQL) and cipher columns (which are used to store encrypted data in data tables). The logical column and the cipher column don't have to be the same. The configuration is shown as follows:
-!ENCRYPT
encryptors:
aes_encryptor:
type: AES
props:
aes-key-value: 123456abc
tables:
t_user:
columns:
pwd:
cipherColumn: pwd
encryptorName: aes_encryptor
When you access Apache ShardingSphere's encryption feature, the encrypted pwd field will be automatically stored in the database. When you send a query, ShardingSphere will automatically help you to decrypt it and obtain the plaintext. Later, if a user wants to change the encryption algorithm, they only need to modify some related configuration.
So, how does the encryption feature help mature businesses? The answer is that ShardingSphere adds a plaintext column configuration and a cipher column query configuration to smooth the entire encryption transformation process and minimize the costs. Apache ShardingSphere's encryption plan for JD Technology is a good case in point. We'd like to showcase how ShardingSphere solves the encryption transformation issues of JD Technology's mature system.
In this case, the table to be encrypted is t_user, and the field to be encrypted is pwd. The unencrypted field is now stored in the database. At first, we need to replace the standard JDBC with Apache ShardingSphere JDBC. Since Apache ShardingSphere JDBC per se is a standard JDBC API, such change almost costs nothing. Then, we need to add the pwd_cipher field (that is, the field we want to encrypt) to the original table and complete the configuration, as shown in the following code block:
-!ENCRYPT
encryptors:
aes_encryptor:
type: AES
props:
aes-key-value: 123456abc
tables:
t_user:
columns:
pwd:
plainColumn: pwd
cipherColumn: pwd_cipher
encryptorName: aes_encryptor
queryWithCipherColumn: false
As shown in the preceding configuration, we set logicColumn as pwd so that users don't need to change the relevant SQL statements. Next, we restart the configuration. At the stage of data insertion, the unencrypted data is still stored in the pwd field, while the encrypted field is stored in the pwd_cipher field. In addition, queryWithCipherColumn is configured as False. Thus, the unencrypted pwd field can still be used for queries and other operations. The next step is encrypted migration of old data, that is, data cleaning. However, Apache ShardingSphere has not provided a tool for migration and data cleaning yet, so users still have to process old data by themselves.
After data migration, users can set queryWithCipherColumn as True, and perform a query or another operation on the encrypted data. At this point, we have completed the majority of the transformation and formed an encrypted dataflow system where plaintext is a backup for rollback. Even if a system failure occurs later, we only need to set queryWithCipherColumn as False again to form a plaintext dataflow system.
After the system runs stably for a period of time, we can remove the plaintext configuration and delete the unencrypted fields in the database to complete the encryption transformation. The final configuration is as follows:
-!ENCRYPT
encryptors:
aes_encryptor:
type: AES
props:
aes-key-value: 123456abc
tables:
t_user:
columns:
pwd:
cipherColumn: pwd_cipher
encryptorName: aes_encryptor
In Apache ShardingSphere, the encryption and decryption module provides you with an automated and transparent encryption method in order to free you from having to go through the encryption implementation details. With Apache ShardingSphere, you can easily use its built-in encryption and decryption algorithms to meet your requirements for data encryption. Of course, you can also develop your own encryption algorithms via an API. Impressively, both new systems and mature systems can easily access the encryption and decryption module.
In addition, Apache ShardingSphere's encryption module provides users with an enhanced encryption algorithm that is more complex and safer than regular encryption algorithms. When you use the enhanced algorithm, even two identical pieces of data can be encrypted differently. The principle of the enhanced algorithm is to encrypt/decrypt original data and variables together. A timestamp is one of the variables. However, since identical data has different encryption results, it's impossible for queries with cipher data to return all of the data. To solve this issue, Apache ShardingSphere creates the Assisted Query Column concept, which can store the original data in an irreversible encryption process: when a user queries encrypted fields, the Assisted Query Column concept can assist the user in a query. Of course, all of this is completely transparent to the user.
As Apache ShardingSphere is transparent, automated, and scalable, it enables you to complete low-cost encryption transformation, and even if security requirements change later, you can quickly and conveniently adjust to the changes.
While remaining on the theme of data safety and protection, you might be wondering about another fundamental aspect – user authentication. The next section will teach you everything there is to know about user authentication and Apache ShardingSphere.
User authentication
Identity authentication is the cornerstone of database security protection: only authenticated users are allowed to operate databases. On the other hand, databases can also check the user's identity to determine whether the current operation has been authorized or not.
As the distributed database succeeds the centralized Database Management System (DBMS), user authentication is facing new challenges.
This section will help you understand the authentication mechanism of distributed databases and related features of Apache ShardingSphere.
Authentication of DBMS versus distributed database
The following section introduces you to user ID storage and the differences in its implementation between a DBMS and a distributed database. You might already be familiar with DBMS user ID storage as it's the most widespread, which makes this distinction even more important for you to understand before moving forward.
First, we will start with the main differences and then move on to the mechanism, configuration, and workflow.
User ID storage
In centralized DBMS, user authentication information is often stored in a special data table. For example, as a famous centralized database by design, MySQL stores user information in the mysql.user system table:
mysql> select Host, User from mysql.`user`;
+-----------+---------------+
| Host | User |
+-----------+---------------+
| % | root |
| localhost | mysql.session |
| localhost | mysql.sys |
| localhost | root |
+-----------+---------------+
4 rows in set (0.00 sec)
Accordingly, when the client side establishes a connection to MySQL, the MySQL server will match the request information with the data in the mysql.user table to determine whether the user is allowed to connect. Of course, this table also contains encrypted user password strings because a user cannot be authenticated without their matching password.
However, given database clusters managed by ShardingSphere-Proxy or other distributed systems, the story is totally different.
The number of database resources managed by ShardingSphere-Proxy might be zero or even several thousand. In this situation, if you still insist on using tables in centralized databases such as mysql.user to store ID data, you might face the following questions:
- Without resources, where is ID data stored?
- If you have thousands of resources, where is the ID data stored?
- When resources increase or decrease, should the ID data be synchronized?
Now that we have clarified the user ID storage differences between DBMS and a distributed database, we should also consider the differences in their protocols and encryption algorithms. The next section clarifies everything you should consider when it comes to both protocols and encryption algorithms.
Different protocols and encryption algorithms
In addition to the issue of user ID information storage, protocol adaptation is another difficult problem facing distributed databases.
ShardingSphere-Proxy has already supported different database protocols such as MySQL and PostgreSQL, so users can directly connect MySQL's client side or PostgreSQL's client side to ShardingSphere-Proxy.
When different database client sides initiate TCP handshakes to establish connections, they will encrypt user passwords with different rules. To solve this issue, ShardingSphere-Proxy has been developed to recognize different database protocols and use respective encryption algorithms to verify passwords along with user IDs. The following sections introduce the user ID information starting from the mechanism, then moving to the workflow and configuration, and finally, to the application scenarios.
Mechanism
When we talk about mechanisms, we actually mean that there are a few different points that you should get familiar with, in order to understand the mechanism. The following subsections will introduce you to the user ID information storage and the adaptation of different protocols.
Storing your user ID information
Of course, it is not appropriate to store user ID information in one or several database resources. Distributed databases need to provide a centralized ID information storage space. In fact, storing the data within a registry center is a good idea:
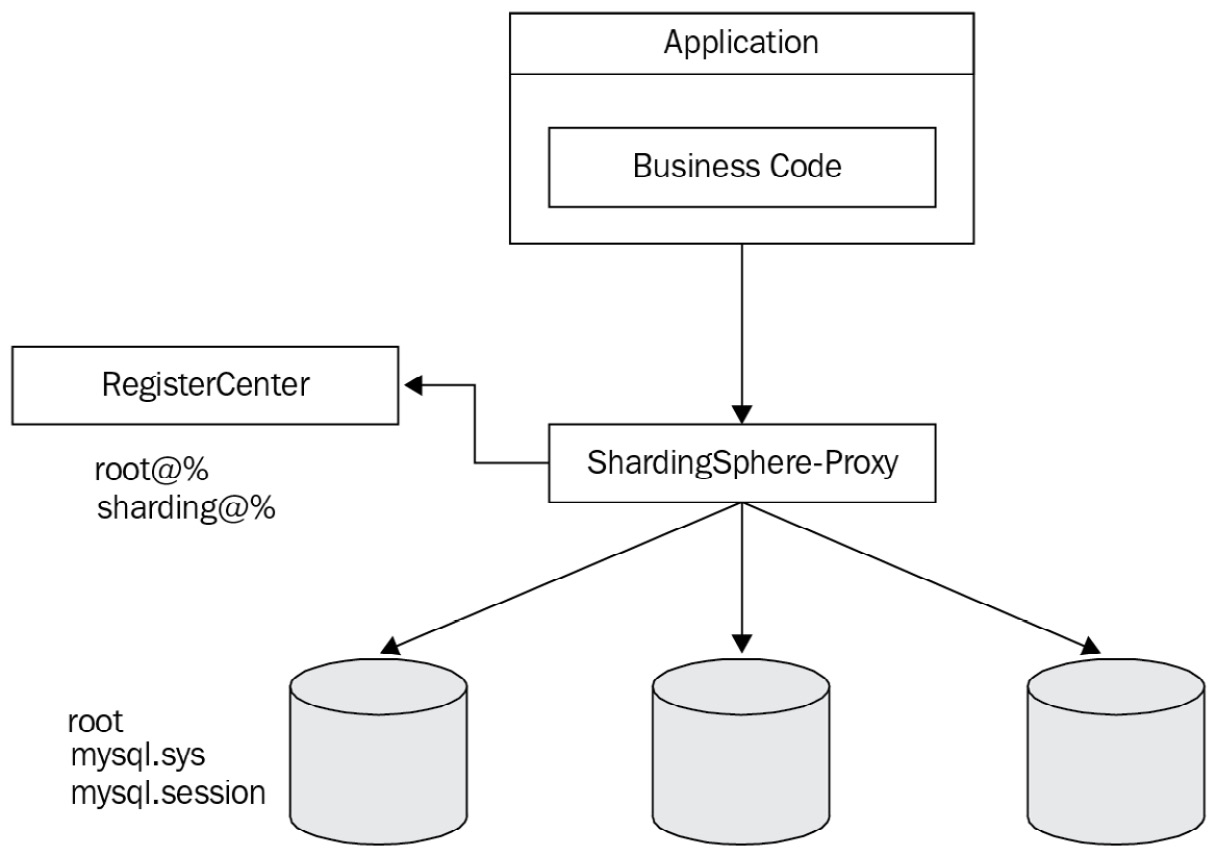
Figure 4.6 – Registry center data storage
As shown in the preceding diagram, when a distributed database system has just been established, each DBMS still has its own user information that is used to establish its connections with ShardingSphere-Proxy. When an application wants to use the distributed database, it uses the user and password data stored in the registry center and connects to ShardingSphere-Proxy. That's how ID authentication in a distributed database becomes real.
Adaptation of different protocols
Apache ShardingSphere is known for its powerful SPI mechanism. The mechanism is beneficial for fixing the protocol adaptation issue: ShardingSphere-Proxy provides different types of authentication engines for different database protocols. Each authentication engine adopts the native implementation method, that is, different encryption algorithms are implemented for each type of database to ensure the best customer experience after database migration. Figure 4.7 gives you an overview of the compatibility of ShardingSphere with different protocols:
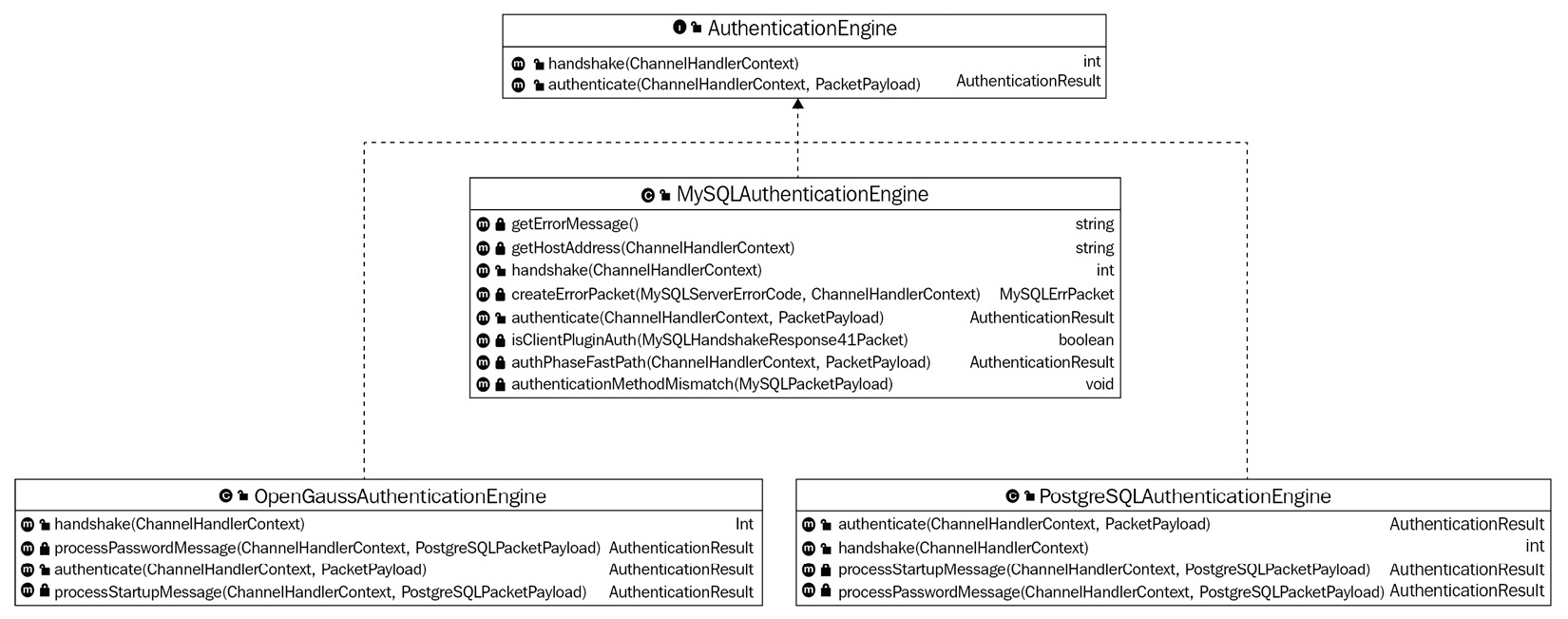
Figure 4.7 – ShardingSphere protocol adaptability
The previous screenshot illustrates the protocols that Apache ShardingSphere is compatible with, and this gives you a complete overview of the mechanisms that make up the user authentication feature. Now, let's move on to the workflow and application scenarios of this feature.
Workflow
Apache ShardingSphere abstracts rules from many capabilities and loads the rules in the form of SPIs on the kernel. Such design largely extends custom capabilities.
The global authority rule is an indispensable rule for ShardingSphere-Proxy booting. Currently, ShardingSphere provides users with a default AuthorityRule implementation.
Now, let's jump into the configuration aspect so that you can set up your user ID storage with your ShardingSphere ecosystem.
Configuration
First, the user needs to set up the initial user in server.yaml under the working directory of ShardingSphere-Proxy:
rules:
- !AUTHORITY
users:
- root@%:root
- sharding@:sharding
provider:
type: ALL_PRIVILEGES_PERMITTED
In the preceding configuration, you can see that Proxy initializes two users, root@% and sharding@. Their respective initial passwords are root and sharding.
Note that % in root@% means that ShardingSphere-Proxy can be connected to via any host address. When nothing follows @, the default value is %. You can also use user1@localhost to restrict user1 to local logins only.
Initialization
When ShardingSphere-Proxy boots, first, it persists local configuration information to the registry center (if the Overwrite value of Mode is set as True). After that, the required configuration information is obtained from the registry center to construct ShardingSphere-Proxy's metadata, including the user ID information that we just configured.
According to the provider configuration, ShardingSphere uses the specified authority provider to build user metadata, including user ID and authorization information stored in memory in the form of a map. Therefore, when a user requests to connect or to obtain authorization, the system can quickly respond to their request, that is, there's no second query via the registry center.
Implementing ID authorization
One of the possible requirements you might have is to implement ID authorization. This section will guide you through Apache ShardingSphere's ID authorization.
In terms of MySQL client-side logins, ShardingSphere performs the following operations for the user:
- Uses the username entered by the user to search whether the user exists in metadata; if not, refuses the connection.
- Compares the host address that the user logs in to determine whether it complies with user configuration; if not, rejects the connection.
- Based on the encryption algorithm, it encrypts the user password in the metadata. Then, it compares the encrypted password with the received one. If the two are inconsistent, it rejects the connection.
- If the user specifies a schema, it queries the user authorization list to check whether they have the permission to connect to the schema; if not, it refuses the connection.
- After the preceding processes have been completed, the user can finally log in and connect to the specified logical schema.
In this section, we discussed why Apache ShardingSphere's user ID authentication mechanism is the first step toward achieving database security protection. By configuring different users and restricting different login addresses, ShardingSphere can provide enterprises with varied data security degrees.
In the future, with the help of its active community, Apache ShardingSphere is expected to have more security mechanisms, such as configuration encryption and custom encryption algorithms. Of course, the flexible SPI mechanism of ShardingSphere allows users to develop custom authentication plugins and build their own access control system of distributed databases.
In the next section, we will introduce you to the SQL Authority feature and its scalability. This is an essential feature if you are interested in securing your data and distributed database.
SQL Authority
It's understood that by following the evolution from centralized databases to distributed ones, the user ID authentication mechanism has undergone dramatic changes. Similarly, any logic database provided by Apache ShardingSphere does not exist in a certain database resource, so ShardingSphere-Proxy is required to centralize the processing of user permission verification.
In the previous chapter, in terms of user login authentication, we explained that if the user specifies the schema to be connected, ShardingSphere can determine whether the user has the permissions based on the authorization information. How can it do that?
In this chapter, we will showcase Apache ShardingSphere's SQL Authority feature and its scalability.
Defining SQL Authority
We can describe SQL Authority like this: after receiving a user's SQL command, Apache ShardingSphere checks whether the user has authority based on the data type and data scope requested by the command. It then decides to allow or reject the operation.
Mechanism
In the User authentication section, we described AuthorityRule and AuthorityProvider. In fact, in addition to user ID information, user authorization information is also controlled by AuthorityProvider.
Currently, aside from the default ALL_PRIVILEGES_PERMITTED type, Apache ShardingSphere also provides the AuthorityProvider SCHEMA_PRIVILEGES_PERMITTED type to control schema authorization.
To use SCHEMA_PRIVILEGES_PERMITTED, the configuration method is as follows:
rules:
- !AUTHORITY
users:
- root@:root
- user1@:user1
- [email protected]:user1
provider:
type: SCHEMA_PRIVILEGES_PERMITTED
props:
user-schema-mappings: root@=test, [email protected]=db_dal_admin, user1@=test
The configuration contains the following key points:
- When the user root connects to ShardingSphere from any host, they have permission to access the schema named test.
- When user1 connects to ShardingSphere from 127.0.0.1, they have the authority to access the schema named db_dal_admin.
- When user1 connects to ShardingSphere from any host, they have the right to use the schema named test.
When other unauthorized situations occur, any connection will be refused, such as the following:
- show databases
- use database
- select * from database.table
Apart from the login scenario, a schema permission check is also performed when a user enters the following SQL statements:
- show databases
- use database
- select * from database.table
When the SQL Authority engine finds that the SQL statement input requests the database resource, it will use the interface provided by AuthorityProvider to perform permission checks to protect user data security from various angles.
Planned development
Since AuthorityProvider is one of the ShardingSphere SPIs, its future development is given a lot of room with multiple possible avenues.
Besides database-level authorization control, the community might develop fine-grained authorization methods such as table-level authorization and column-level authorization.
In the future, AuthorityRule will be linked with DistSQL, a new feature just released in version 5.0.0 to explore more flexible user and authorization management methods and make it even more convenient for users.
Application scenarios
User authentication plus SQL Authority contributes to Apache ShardingSphere's integrated database-level security solution.
Concurrently, ShardingSphere abstracts complete top-level interfaces that enable the community and users to implement various levels of data security control and provide technical support for SQL auditing and other application security management scenarios such as password protection and data encryption.
You now have acquired a foundational understanding of data encryption and how Apache ShardingSphere implements data encryption and decryption. You may or may not require this feature, and keeping in mind that ShardingSphere is built on a completely pluggable architecture, you may or may not include it in your version of Apache ShardingSphere.
Database and app online tracing
The distributed tracing system is designed based on the Google Dapper paper. There are already many relatively mature applications of the system, such as Zipkin by Twitter, SkyWalking by Apache, and CAT by Meituan-Dianping.
The following sections will introduce you to how a database and app online tracing work, and then show you how Apache ShardingSphere implements this feature.
How it works
A distributed scheduling chain turns one distributed request into multiple scheduling chains. In the scheduling of one distributed request, such as time consumption on each node, the machine receives the request and the status of the request on each service node can be seen in the backend.
The following is a diagram of one distributed request scheduling chain quoted in Google's paper Dapper, A Large-Scale Distributed Systems Tracing Infrastructure:
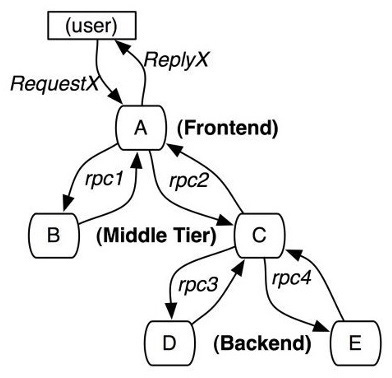
Figure 4.8 – A distributed request scheduling chain
Citation
Dapper, a Large-Scale Distributed Systems Tracing Infrastructure, Benjamin H. Sigelman and Luiz André Barroso and Mike Burrows and Pat Stephenson and Manoj Plakal and Donald Beaver and Saul Jaspan and Chandan Shanbhag, 2010, https://research.google.com/archive/papers/dapper-2010-1.pdf, Google, Inc.
As you can see in Figure 4.8, a request made by a user takes a path that goes through various nodes, going all the way from the frontend to the backend and back. Monitoring all of these nodes means having total monitoring over your system. In the next sections, we will introduce you to the monitoring solution that you can integrate into your ShardingSphere solution.
A total synthetic monitoring solution
This section will introduce you to synthetic monitoring solution, another feature of ShardingSphere's pluggable architecture. You will learn what we mean and how we implement database monitoring, tracing, and the shadow database.
The feature includes three layers for a comprehensive solution. The following list introduces you to each layer and its function:
- Gateway layer (cyborg-flow-gateway): This is achieved by Apache APISIX. It is able to tag data and distribute and pass tags to the context of link scheduling.
- Tracing service (cyborg-agent, cyborg-dashboard): This is achieved by Apache SkyWalking and can pass stress testing tags throughout the link.
- Shadow database (cyborg-database-shadow): This is achieved by Apache ShardingSphere and can isolate data based on stress testing tags.
When a stress testing request is made to the gateway layer (cyborg-flow-gateway), tags will be made to stress testing data according to the configuration within the configuration file. The tags will be passed to distributed link system and flow information will be seen (cyborg-dashboard) throughout the whole link. Before requesting the database, the link tracing service will add stress testing tags to execute SQL through HINT:
INSERT INTO table_name (column1,...) VALUES (value1...) /*foo:bar,...*/;
When requests are made to the database proxy layer (cyborg-database-shadow), they will be routed to the corresponding shadow databases according to stress testing tags.
Now that you understand ShardingSphere's interpretation of database monitoring, we can proceed to understand the database gateway.
Database gateway
Unified operation of backend heterogeneous databases through the database gateway can minimize the impact of a fragmented database.
In addition to high performance, fusing, rate limit, blacklisting, and whitelisting, among other capabilities, the database gateway should also have capabilities such as unified access, transparent data access, SQL dialect conversion, and routing decisions. Furthermore, the quintessence of database proxy sustainability lies in an open ecosystem and flexible extensibility.
In this section, we will follow our pattern by introducing the mechanism, to then dive deeper into the components. However, this time, first, we should start with a little background. Considering the significant transformations that databases have been undergoing recently, we need to gain an understanding of what a database gateway is. The next section allows you to do just that.
Understanding the database gateway
Currently, as the distributed database is in its transformation period, although unified products remain the goal pursued by database providers, fragmented databases are becoming the trend. Leveraging their advantages in their respective fields is key for database products to gain a foothold in the industry.
Growing the diversity of the database brings new demands. Neutral gateway products can be built on top of databases to effectively reduce use costs brought by the differences between heterogeneous databases, ultimately allowing you to fully leverage diverse databases' strengths.
Gateway is not a new product. It should have standard capabilities including fusing, rate limits, blacklisting, and whitelisting. Considering their functions of traffic bearing and traffic allocation, gateway products should have non-functional features such as stability, high performance, and security. The database gateway further enhances database functions based on an existing gateway. The biggest difference between a database gateway and a traffic gateway is the diversity of access protocols and the statefulness of target nodes.
A deep dive into the database gateway mechanism
Apache ShardingSphere provides the basic functions of the database gateway mechanism, and other functions that are required to be a digital gateway will be completed in its future version. The database gateway includes major functions such as support for heterogeneous databases, database storage adaptor docking, SQL dialect conversion, routing decisions, and flexible extension. In this section, the major functions and realization mechanisms of the database gateway and the relative route planning of Apache ShardingSphere will be briefly discussed.
Support for heterogeneous databases
Apache ShardingSphere now supports multiple data protocols and SQL dialects.
Engineers can access Apache ShardingSphere through MySQL and PostgreSQL. Additionally, other databases that support similar protocols, such as MariaDB and TiDB, which support the MySQL protocol, and openGauss and CockroachDB, which support the PostgreSQL protocol, can also be directly accessed. Apache ShardingSphere simulates the target database through the realization of the binary interactive protocol of the database.
Engineers can use MySQL, PostgreSQL, Oracle, SQL Server, and SQL dialects that meet SQL92 standards to access Apache ShardingSphere. The SQL grammar file is defined by ANTLR, generated through code, and translates SQL into an abstract syntax tree and visitor model through the classic Lexer + Parser plan.
Database storage adaptor docking
Currently, Apache ShardingSphere supports access to the backend database through JDBC. JDBC is a standard interface that allows Java to access databases, supports multiple databases, and can support databases using JDBC protocol without modifying any code in theory.
In practice, although JDBC has a unified interface at the code level, the SQL used to access the databases hasn't been unified. Therefore, in addition to supporting backend databases that support SQL, databases with SQL that are not supported by Apache ShardingSphere can be accessed through SQL92 standards. In other words, except for MySQL, PostgreSQL, Oracle, SQL Server, and databases that support similar dialects that are supported by Apache ShardingSphere, other databases could encounter access errors if they do not enable their dialects to support SQL92 standards. Additionally, if other databases support extra functions in addition to the SQL92 dialect, they will not be recognized by Apache ShardingSphere. Based on meeting the basic requirements of backend databases, engineers can easily access these backend databases through the required SQL dialects.
Although most relational databases and some NoSQL databases support access through JDBC, there are still some databases that do not support access through JDBC. In Apache ShardingSphere's route planning, access models that are targeted at specific databases will be supported, which strive to provide diverse support for databases.
SQL dialect conversion
While accessing a specific database through certain database protocols and SQL dialects could achieve the basic functions of a database protocol, it does not remove the barriers between databases. In Apache ShardingSphere's route planning, the SQL dialect conversion function will be provided to remove the barriers between heterogeneous databases.
For example, engineers could access the data in the HBase cluster through the MySQL protocol and SQL dialect so that they can truly achieve HTAP. Additionally, they could visit other relational databases through the PostgreSQL protocol and SQL dialect, realizing low-cost database migration. In practice, Apache ShardingSphere regenerates the SQL by matching the parsed SQL Abstract Syntax Tree (AST) with the conversion rules of other database SQL dialects.
Indeed, SQL conversion cannot entirely achieve dialect conversion among all databases. Operators and functions exclusive to a certain database can only be thrown an UnsupportedOperationException exception. Nevertheless, the ability of dialect conversion can make correspondence and collaboration between heterogenous databases more convenient. This way, the database gateway is no longer oriented to a single database statically. Instead, it dynamically chooses a suitable database protocol parser and SQL parsing engine according to the database protocol and SQL dialect, making it a truly unified access of hybrid deployment for heterogeneous databases.
Routing decision
Dynamically unified access allows the database gateway to parse requests to suitable databases more intelligently by understanding the SQL syntax, thereby empowering heterogeneous database clusters with hybrid deployments to enjoy stronger computing capability.
Routing decisions are mainly decided by two factors, namely where the data is and which database can better address the existing request.
By matching our metadata information with SQL AST, the heterogeneous database cluster where the data copy is stored can be identified. When data is stored in multiple heterogeneous databases, the database used to address the query request can be decided by recognizing the SQL features and matching the attribute tags of the heterogeneous database; for example, routing aggregations and grouping operations to OLAP-natured databases or routing transaction queries based on the primary key to OLTP-natured databases. Making decisions via rules or query costs is a relatively effective routing decision strategy.
Routing decision capability is the reverse function of SQL dialect conversion capability. Currently, it is not available in Apache ShardingSphere. Apache ShardingSphere has not taken into consideration the capability of its route planning. Therefore, further development plans will be considered after the SQL dialect conversion function has been completed.
Extensibility
Different from the traffic gateway, open and fast docking with diverse databases is an important function of the database gateway. The traffic gateway can route requests to the backend service by identifying a protocol and allocating weights. The biggest difference between the database gateway and stateless service nodes is that the statefulness of the database in the database gateway requires routing requests with precision. In addition, in terms of extensibility, the traffic gateway does not need to understand the contents it transmits or attend to the backend resource operations. In comparison, the database gateway needs to match the detailed operations of different databases.
In terms of what's been done so far, Apache ShardingSphere's extensibility is represented by the database protocol and the extensible SQL dialect. On the to-do list, Apache ShardingSphere's extensibility is represented by the database operation and SQL dialect conversion; in terms of what has not been planned, the routing decision strategy can be determined and developed by engineers.
Developers can achieve docking with new databases and routing decisions through SPI without changing the core code. Apache ShardingSphere always embraces an open source ecosystem and diverse heterogeneous databases with a neutral stance.
The overall architecture of the database gateway is as follows:
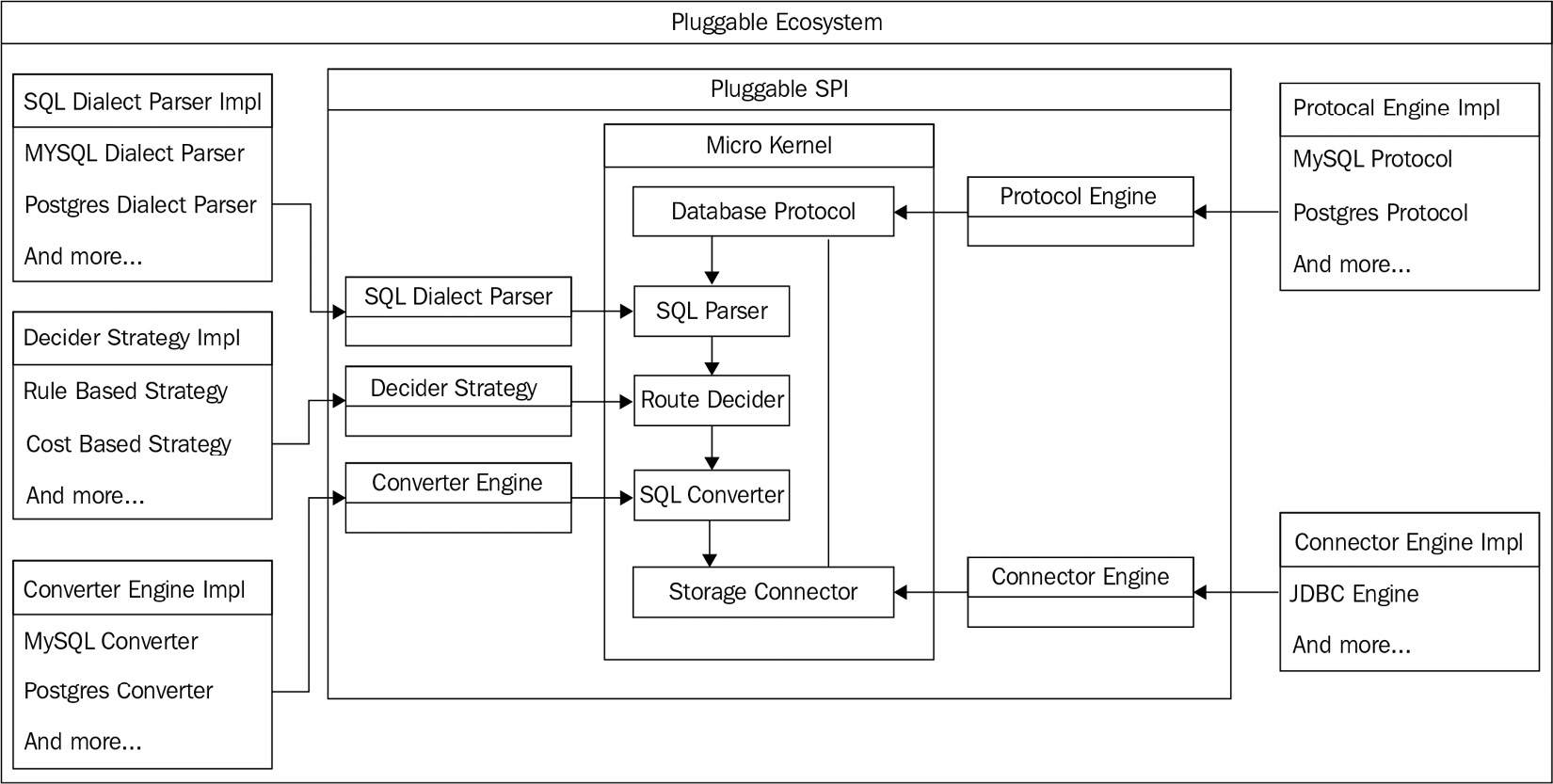
Figure 4.9 – The database gateway architecture
With a database protocol and SQL dialect identification, AST can be routed to the appropriate data source by the routing decision engine, and SQL can be converted into the corresponding data source dialect and executed.
Five top accesses are or will be extracted in Apache ShardingSphere for database protocols, SQL dialect parsing, routing decision strategies (this feature is under development), SQL dialect converters (this feature is under development), and data executor.
Values
The values of the database gateway are unified database access, transparent heterogeneous data access, shielding the database implementation details, and allowing engineers to use all sorts of heterogeneous database clusters such as using a database.
Unified database access
In terms of programming access, with the heterogeneous database protocol, support for SQL dialects and SQL dialect conversion, engineers can switch between different databases by programming in the database gateway. The database gateway is not product-oriented to a single database only. It is neutral, and offers unified access to heterogeneous databases.
Transparent heterogeneous data access
In terms of data storage, engineers do not need to attend to detailed storage space or methods. The database gateway can manage backend databases automatically by matching a powerful routing decision engine with transparent database storage access.
When considering the database gateway, it is important not to confuse the gateway with extensibility. Now you have an understanding of the differences between the two terms and what to expect from the two features.
Distributed SQL
In ShardingSphere 4.x and earlier versions, just like other middleware, people needed to use configuration files to manage ShardingSphere to perform operations such as telling it which logic databases to create, how to split the data, which fields to encrypt, and more. Although most developers are accustomed to using configuration files as a tool to manage middleware, as the entrance to distributed databases, ShardingSphere also serves a large number of operations engineers and DBAs who are more familiar with SQL execution than editing configuration files.
The Database Plus concept is the impetus for Apache ShardingSphere 5.0.0's new interactive language: Distributed SQL (DistSQL).
DistSQL is the built-in language of ShardingSphere that allows users to manage ShardingSphere and all rule configurations through a method that is similar to SQL. This is so that users can operate Apache ShardingSphere in the same way as SQL database operations.
DistSQL contains three types, namely RDL, RQL, and RAL:
- Resource & Rule Definition Language (RDL): This is used to create, modify, and delete resources and rules.
- Resource & Rule Query Language (RQL): This is used to query resources and rules.
- Resource & Rule Administration Language (RAL): This is used to manage features such as hint, transaction type switch, execution plan query, and elastic scaling control.
The following sections will guide you through DistSQL's advantages, along with its implementation in ShardingSphere, and conclude with some application scenarios that'll allow you to see it in action.
Introduction to DistSQL
Without DistSQL, if we want to use ShardingSphere-Proxy for data sharding, we need to configure a YAML file, as follows:
# Logic Database Name Used for External Services
schemaName: sharding_db
# Actual Data Source in Use
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:3306/db0
username: root
password:
If we take data sharding as an example of the task we want to accomplish with DistSQL, the input code we would use would look like the following:
# Specify the Sharding Rule; The example codes means split data tables in the database into 4 shards
rules:
- !SHARDING
autoTables:
t_order:
actualDataSources: ds_0
shardingStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_hash_mod
shardingAlgorithms:
t_order_hash_mod:
type: HASH_MOD
props:
sharding-count: 4
If the YAML configuration file is completed, we can deploy ShardingSphere-Proxy and start using it. If we still need to adjust any resources or rules, we have to update the configuration file and restart Proxy to implement an effective configuration.
With DistSQL, users don't have to configure the files again. They can directly boot ShardingSphere-Proxy and execute the following SQL commands:
# Create a Logic Database
CREATE DATABASE sharding_db;
# sharding_db Connect to sharding_db
USE sharding_db;
# Add Data Resource
ADD RESOURCE ds_0 (
HOST=localhost,
PORT=3306,
DB=db0,
USER=root
);
# Create Sharding Rules
CREATE SHARDING TABLE RULE t_order (
RESOURCES(ds_0),
SHARDING_COLUMN=order_id,TYPE(NAME=hash_mod,PROPERTIES("sharding-count"=4)));
After we enter the preceding DistSQL command, the rule configuration equivalent to the file operations will be completed. Afterward, you don't need to restart because you can use DistSQL to dynamically add, modify, or delete any resources and rules.
DistSQL considers the habits of database developers and operation engineers and learns from standard SQL's grammar to ensure readability and usability, making DistSQL preserve ShardingSphere features to the greatest extent.
Application scenarios
Distributed SQL is a powerful tool that is also extremely versatile and has a very friendly learning curve. It is applicable to virtually any scenario where normal SQL would be. The following section gives you a few application scenarios to ensure you are familiar with the application scenarios for DistSQL.
First, let's look at Figure 4.10:
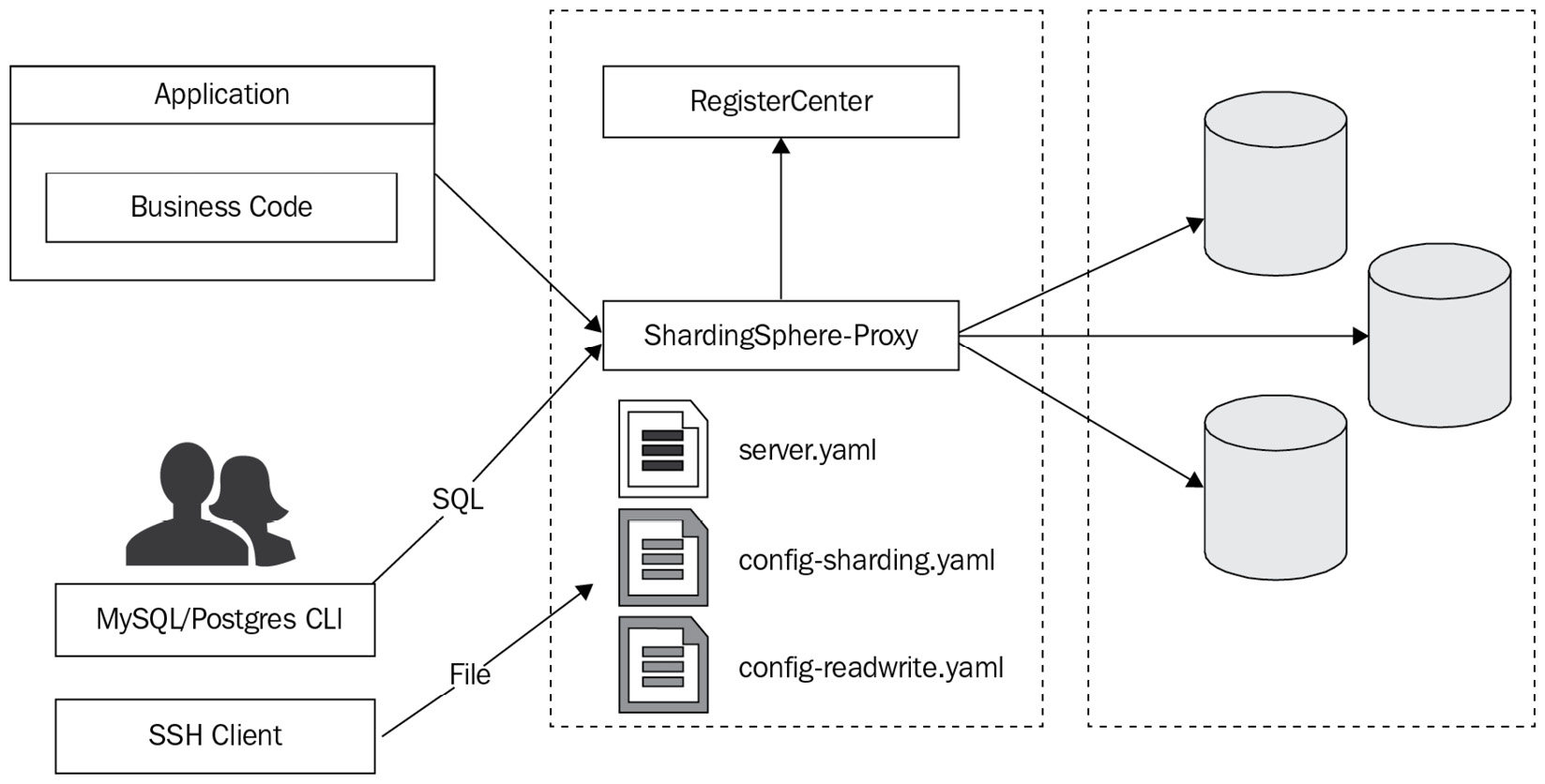
Figure 4.10 – The application system without DistSQL
Without DistSQL, the prevalent condition is detailed as follows:
- An application system is connected to ShardingSphere-Proxy, and data is read and written through the SQL commands.
- Developers or operation engineers connect their SQL client side to ShardingSphere-Proxy and use SQL commands to view data.
- At the same time, they connect the SSH client to the server where the proxy is located in order to perform file-editing operations and configure the resources and rules used by ShardingSphere-Proxy.
- Editing files remotely is not as simple as editing local files.
- Each logic database uses a different configuration file. There might be a lot of files on the server, which makes remembering their locations and differences a challenge.
- As for file updates, it's necessary to restart ShardingSphere-Proxy to make the new configuration effective, but this could interrupt the system.
DistSQL glues ShardingSphere-Proxy onto databases, making them one unit, as shown in the following diagram:
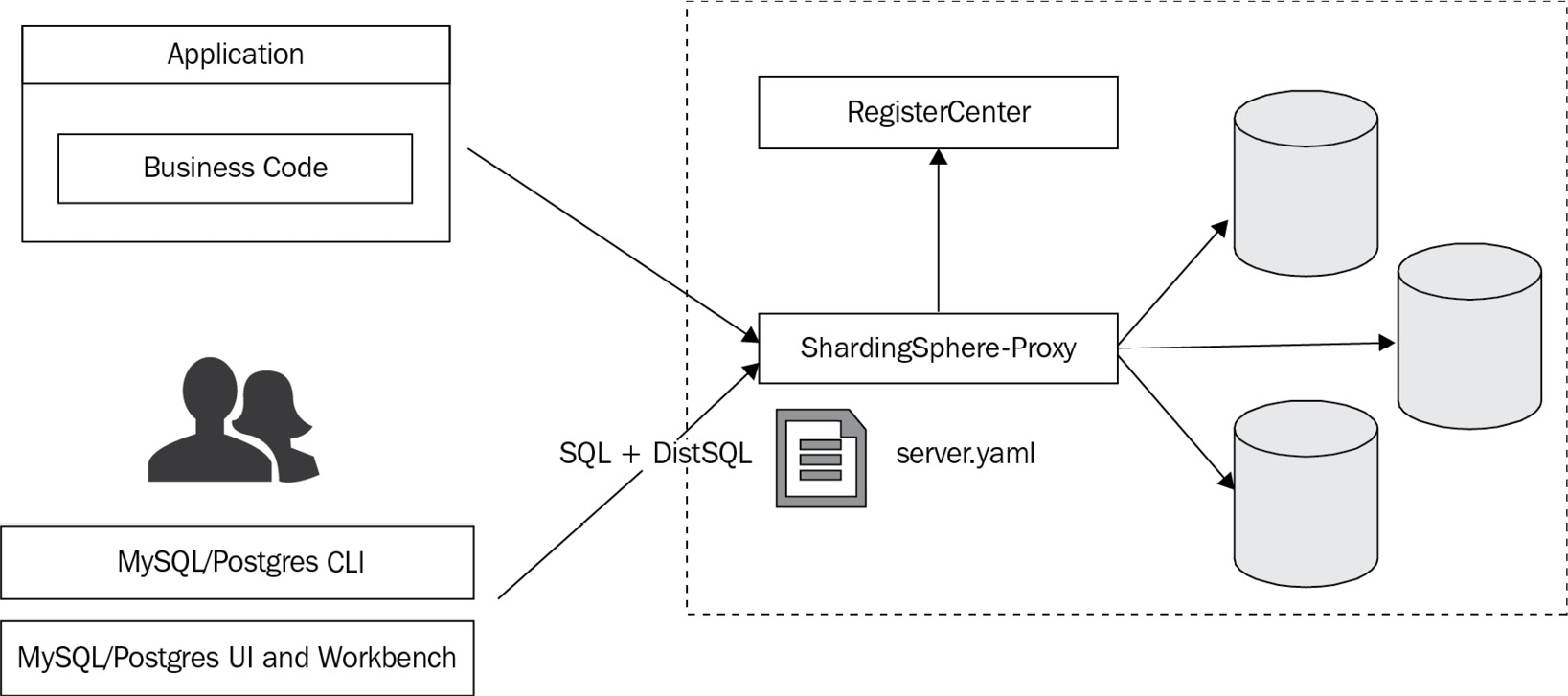
Figure 4.11 – The application system including DistSQL
Once we include DistSQL, the situation changes and we practically eliminate a layer by closing the gap between databases and ShardingSphere-Proxy.
The application system is still connected to ShardingSphere-Proxy, and data is read and written through SQL commands.
Developers or ops engineers no longer need two different tools. They only need to open the SQL client side to view data and manage ShardingSphere at the same time:
- No file editing is required.
- There is no need to worry about the potentially explosive growth of files.
DistSQL can execute real-time update operations; therefore, users don't have to restart ShardingSphere-Proxy and worry about system interruptions.
Additional notes for DistSQL
The previous case where we used data sharding as an example of a task we'd like to accomplish showcased how RDL defines resources and rules. Now, let's explore other impressive features of DistSQL on the basis of these rules:
- View added resources (RQL) allows you to query the system and have an immediate overview of the resources included:
> SHOW SCHEMA RESOURCES;
+------+-------+-----------+------+------+-----------+
| name | type | host | port | db | attribute |
| ds_0 | MySQL | 127.0.0.1 | 3306 | db0 | ... |
+------+-------+-----------+------+------+-----------+
1 rows in set (0.01 sec)
- View sharding rules (RQL) allows you to conveniently understand the current sharding rules of the system:
> SHOW SHARDING TABLE RULES;
mysql> show sharding table rules;
+---------+---------------------+---------------------+-----------------------+-------------------------------+--------------------------------+
| table | actual_data_sources | table_strategy_type | table_sharding_column | table_sharding_algorithm_type | table_sharding_algorithm_props |
+---------+---------------------+---------------------+-----------------------+-------------------------------+--------------------------------+
| t_order | ds_0 | hash_mod | order_id | hash_mod | sharding-count=4 |
+---------+---------------------+---------------------+-----------------------+-------------------------------+--------------------------------+
1 row in set (0.01 sec)
- Preview distributed execution plans (RAL) in ShardingSphere can output the execution plans parsed by logical SQL, but it does not actually execute these SQL statements:
> PREVIEW select * from t_order;
+------------------+------------------------------------------------+
| data_source_name | sql |
+------------------+------------------------------------------------+
| ds_0 | select * from t_order_0 ORDER BY order_id ASC |
| ds_0 | select * from t_order_1 ORDER BY order_id ASC |
| ds_0 | select * from t_order_2 ORDER BY order_id ASC |
| ds_0 | select * from t_order_3 ORDER BY order_id ASC |
+------------------+------------------------------------------------+
4 rows in set (0.01 sec)
Aside from these features, DistSQL also supports rule definitions and queries in scenarios such as read/write splitting, data encryption, database discovery, and shadow database stress testing, with the aim to cover all scenarios.
Implications for ShardingSphere
DistSQL was designed with the aim to redefine the boundaries between middleware and a database, which would ultimately allow developers such as yourself to utilize ShardingSphere in the same manner you usually operate your databases.
It was designed with the goal to redefine the boundary between middleware and databases, allowing you and other developers to use Apache ShardingSphere in the same way as database operations. The syntax system of DistSQL acts as a bridge between ShardingSphere and the distributed databases. In the future, when more creative ideas come true, DistSQL is destined to become more powerful and help ShardingSphere become a better database infrastructure.
Understanding cluster mode
Considering user deployment scenarios, Apache ShardingSphere provides three operating modes: cluster mode, memory mode, and standalone mode. Cluster mode is the production deployment method recommended by ShardingSphere. With cluster mode, horizontal scaling is achieved by adding computing nodes, while multi-node deployment is also the basis for high service availability.
In the following sections, you will understand what cluster mode is, as well as its compatibility with other ShardingSphere modes so that you can better integrate it into your pluggable system.
Cluster mode definition
Apart from cluster mode, ShardingSphere also provides its counterpart, that is, its standalone mode deployment. With standalone mode, users can also deploy multiple computing nodes, but unlike with cluster mode, configuration sharding and state coordination cannot be performed among multiple computing nodes in standalone mode. Any configuration or metadata changes only work on the current node, that is, other nodes cannot perceive the modification operations of other computing nodes.
In cluster mode, the feature registry center allows all computing nodes in the cluster to share the same configuration information and metadata information. Therefore, when the shared information changes, the register center can push these changes down to all computing nodes in real time to ensure data consistency in the entire cluster.
Kernel concepts
In the following subsection, we will introduce you to the kernel concept for all the modes, including the registry center, and the mechanism to enable cluster mode.
Operating modes
Cluster mode is one of the ShardingSphere operating modes. The mode is suitable for a production environment deployment. In addition to cluster mode, ShardingSphere also provides memory mode and standalone mode, which are used for integration testing and local development testing, respectively. Unlike standalone mode, memory mode does not persist any metadata and configuration information, in which all modifications take effect in the current thread. The operating modes cover all use scenarios spanning development to testing and production deployment.
The registry center
The registry center is the foundation of the cluster mode implementation. ShardingSphere can share metadata and configurations in cluster mode because it integrates the third-party register components of Zookeeper and Etcd. Concurrently, it leverages the notification and coordination capabilities of the register center to ensure the cluster synchronization of shared data changes in real time.
The mechanism to enable cluster mode
To enable cluster mode in a production environment, we need to configure the mode tag in server.yaml:
mode:
type: Cluster
repository:
type: ZooKeeper
props:
namespace: governance_ds
server-lists: localhost:2181
retryIntervalMilliseconds: 500
timeToLiveSeconds: 60
maxRetries: 3
operationTimeoutMilliseconds: 500
overwrite: false
Next, to add multiple computing nodes to the cluster, it is necessary to ensure that the configurations of namespace and server-lists are kept the same. Therefore, these computing nodes function in the same cluster.
If users need to use local configuration to initialize or overwrite the configuration in the cluster, they can configure overwrite: true.
Compatibility with other ShardingSphere features
The core capability of cluster mode is to ensure the configuration and data consistency of ShardingSphere in a distributed environment, which is the cornerstone of ShardingSphere's enhanced features in the distributed environment. In terms of DDL, which modifies metadata, after a user executes DDL on a certain computing node, the computing node will update the metadata change to the register center; the coordination function of the register center is used to send the changed message to other computing nodes in the cluster, making the metadata information of all computing nodes in the cluster consistent.
Cluster mode is the foundation for ShardingSphere's production deployment, and it also endows ShardingSphere with distributed capabilities that lay the groundwork for the internet software architecture. Core features such as horizontal scaling and HA that are provided by cluster mode are also inseparable for distributed systems.
With this knowledge, let's move on to learn how to manage the cluster.
Cluster management
As technologies advance, we not only require big data computing but also 24/7 system services. Accordingly, the old single-node deployment method cannot meet our needs anymore, and the multi-node cluster deployment method is the trend. Additionally, deploying multi-node clusters faces many challenges.
On the one hand, ShardingSphere needs to manage storage nodes, computing nodes, and underlying database nodes in the cluster while it also needs to refresh: it detects the latest node changes in real time and adopts the heartbeat detection mechanism to ensure the correctness and availability of the storage, computing, and database nodes. On the other hand, ShardingSphere needs to solve two issues:
- How do you keep consistency among configurations and statuses of different nodes in the cluster?
- How do you guarantee collaborative work between nodes?
ShardingSphere not only integrates the third-party components of Apache Zookeeper and Etcd but also provides the ClusterPersistRepository interface for custom extensions. Additionally, we can use other configuration register components that we like. ShardingSphere leverages the characteristics of Apache Zookeeper and etcd to synchronize different node strategies and rules in the same cluster. Apache Zookeeper and Etcd are used to store configurations of data sources, rules and strategies, and the states of computing nodes and storage nodes, to better manage clusters in ShardingSphere.
Computing nodes and storage nodes are the most important aspects of ShardingSphere. Computing nodes handle switch-on and the fusing of running instances, while storage nodes manage the relationships between primary databases and secondary databases plus the database status (enable or disable). Now, let's see the differences between the two and how to work with them.
Computing nodes
Two subnodes of the /status/compute_nodes computing node are listed as follows:
- /status/compute_nodes/online stores online running instances.
- /status/compute_nodes/circuit_breaker stores breaker running instances.
For both online and breaker running instances, the identity of the running instance is the same: it is composed of the host's IP and port number. When a running instance goes online, it will automatically record its own IP and port number under the /status/compute_nodes/online computing node to become a member of the cluster.
Similarly, when the running instance is broken, the instance will also be removed from the /status/compute_nodes/online computing node and record its IP and port number in the /status/compute_nodes/circuit_breaker computing node.
Storage nodes
The two sub nodes of the /status/storage_nodes storage node are listed as follows:
- /status/storage_nodes/disable stores the current disabled secondary database.
- /status/storage_nodes/primary stores the primary database.
To modify the relationship between the primary database and the secondary database or to disable the secondary database, we can use DistSQL or high availability to automatically sense the primary-secondary relationship and disable/enable the database.
Configuration
In ShardingSphere, cluster management can centralize rule configuration management:
- The /rules node saves global rule configurations, including the authority configuration of usernames and passwords in ShardingSphere-Proxy, distributed transaction type configurations, and more.
- The /props node stores global configuration information such as printing SQL logs and enabling cross-database queries.
- The /metadata/${schemeName}/dataSources node keeps data source configurations including database links, accounts, passwords, and other connection parameters.
- The /metadata/${schemeName}/rules node saves the rule configuration. All function rule configurations of ShardingSphere are stored under the node, such as data sharding rules, read/write splitting rules, data desensitization rules, and HA rules.
- The /metadata/${schemeName}/schema node stores metadata information, along with the table names, columns, and data types of logical tables.
State coordination
To share the rules and strategies of different computing nodes in the same cluster, ShardingSphere chooses a monitoring notification event mechanism to ensure such sharing. Users only need to execute SQL statements or ShardingSphere's DistSQL statements on one running instance and other running instances in the same cluster will also perceive and synchronize the operations.
To conclude, cluster management is essential for stable and correct services with HA: in terms of standalone deployment, downtime has an immeasurable impact on the system, but cluster deployment can ensure service availability.
Observability
Observability debuted in the industrial field: first, people used sensor devices to measure volumetric flow rate and substances of liquid mixtures. Then, the data was transmitted to a visual dashboard that provides operators with monitoring data, which greatly improved work efficiency.
In recent years, observability has been widespread in information technology and software systems. In particular, new IT concepts such as Cloud native, DevOps, and Intelligent ops accelerated the popularity of observability in IT. Instead of observability, in the past, people often used the concept of monitoring.
In particular, ops management often stresses the importance of a monitoring system. So, what is the difference between a monitoring system and observability? In simple terms, monitoring is a subset of observability. Monitoring highlights that the internal system is not known by the observer (that is, it only focuses on the black box), while observability emphasizes the observer's initiative and connection with a system (that is, it cares about the white box).
The concept of observability might be new to you, but the next section gives you its definition, followed by its usage scenarios.
Clarifying the concept of observability
What is observability? Observability refers to the characteristics of quantifiable data that a system can observe. It reflects the nature of the system itself and the real ability of the system. In IT systems, observability places its emphasis on integrating this capability into the whole system development process from design to implementation. If observability is seen as a business requirement, it should be parallel with other system development requirements such as availability and scalability.
Often, observability data is displayed via the Application Performance Monitoring (APM) system. The system can collect, store, and analyze observability data to perform system performance monitoring and diagnosis, and its functions include but are not limited to the performance indicator monitor, call-chain analysis, and application topology.
Applying observability to your system
In IT systems, there are three methods in which to practice observability: metrics, link tracing, and logging:
- Metrics leverage data aggregation to display observability and reflect the system state and trends; however, they fail to reflect system details (for example, counter, gauge, histogram, and summary).
- Link tracing can record data of all requests and related calls from the beginning to the end, to better show the process details.
- Logging logs system execution to provide detailed system operation information, but the method may cost a significant amount of resources.
In practice, system observability is shown by combining several methods. In addition, it's necessary to equip observability with a good user interface, so it is also often associated with visualization.
Mechanisms
Two mechanisms can be used to technically implement observability: one is that the internal system uses the API to provide external observable data, and the other is to collect observable data via a non-invasive probe method. The second method is quite common for developing an observability platform because its development and deployment can be independent of the system itself, which is perfect for decoupling:
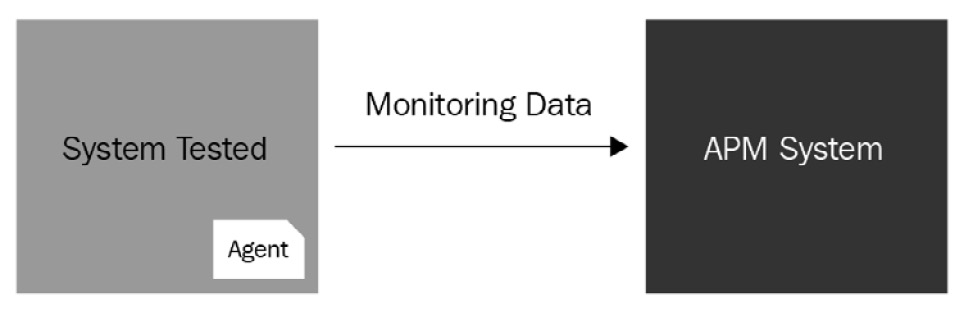
Figure 4.12 – The probe method
Metrics, link tracing, and observability will certainly be of use to you at some point. With the focus now firmly placed on increasing efficiency across industries, this holds true for the desire to have an efficient database system. Observability not only allows you to gain an understanding of how your system is performing, but it will also provide you with insights to pinpoint exactly where you can improve it.
Application scenarios
With observability, you can use the data to analyze and solve online problems in IT systems. You can analyze system performance, locate slow requests, and track and audit security events. Additionally, observability can give a system action-based features such as warning and predict, to influence a user's management changes and help them make better decisions. Figure 4.13 presents the module architecture of ShardingSphere-Proxy and its agent's plugin connection:
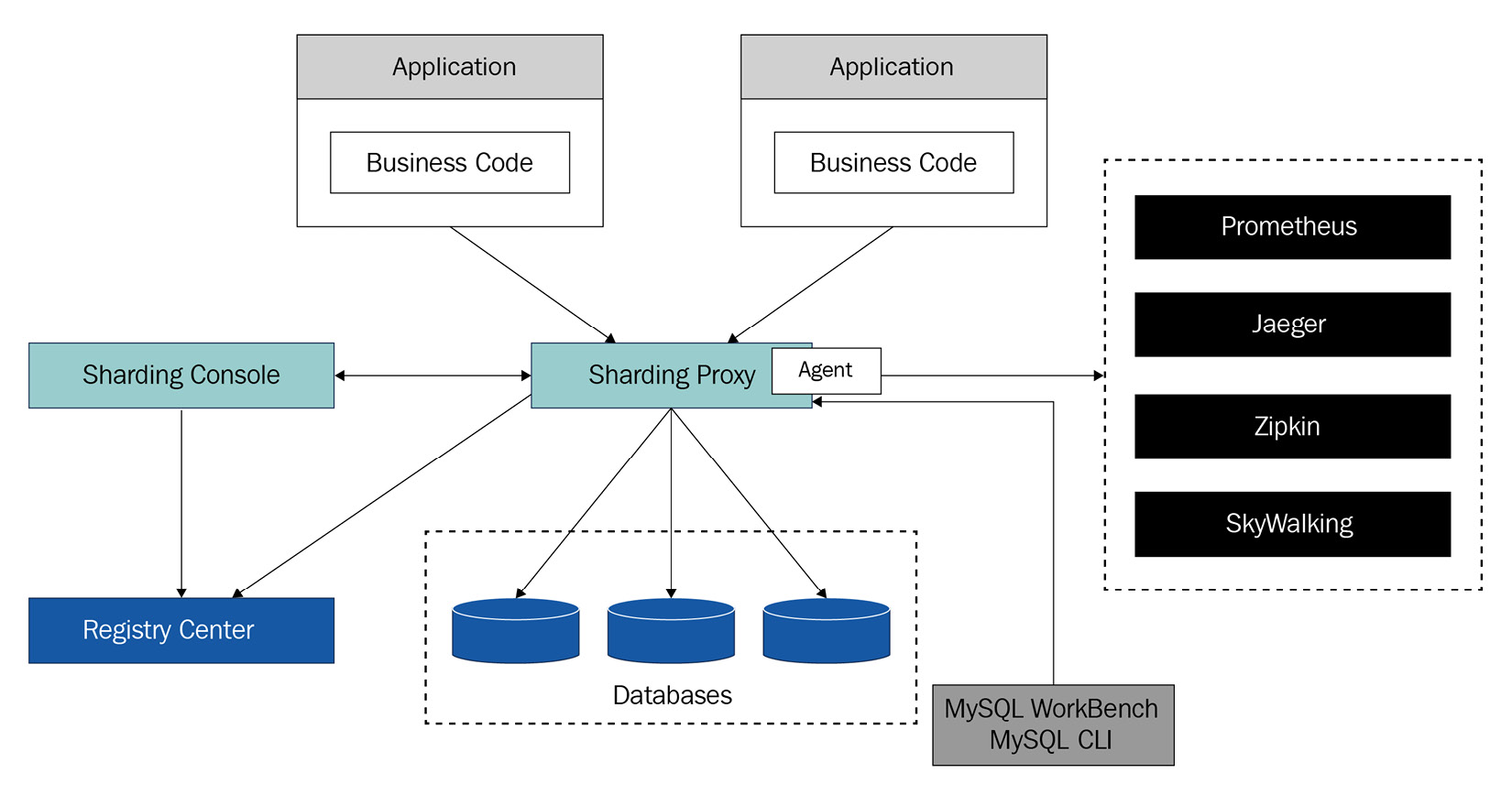
Figure 4.13 – The ShardingSphere agent module architecture
Apache ShardingSphere supports observability features, for instance, metrics, tracing, and logging. Instead of including built-in features, Apache ShardingSphere presents these features as extensible plugins so that users can develop custom plugins for Apache ShardingSphere agents and implement specific data collection, storage, and display methods. Currently, Apache ShardingSphere's default plugin supports Prometheus, SkyWalking, Zipkin, Jeager, and OpenTelemetry. Thanks to its agent module architecture, you will find that implementing observability in your version of Apache ShardingSphere is simple, and we are sure that you will find it to be a useful feature.
Summary
You have now gained a full picture of Apache ShardingSphere's features, how they are built into the system, and their use cases.
This chapter's takeaways, coupled with the knowledge that you have cumulated so far thanks to the previous three chapters, will have given you a better understanding of the architecture and the features that you can choose from. You are probably already thinking about the possible deployment options that are at your disposal and how they could help you solve your pain points.
You are now missing the last piece of the puzzle: understanding the clients that make up ShardingSphere and their deployment architectures. These are Proxy, JDBC, and hybrid deployment.
In the next chapter, we will introduce you to ShardingSphere-Proxy and ShardingSphere-JDBC deployments, along with their concurrent deployment thanks to a hybrid architecture.